







1,kafka的下载
下载地址
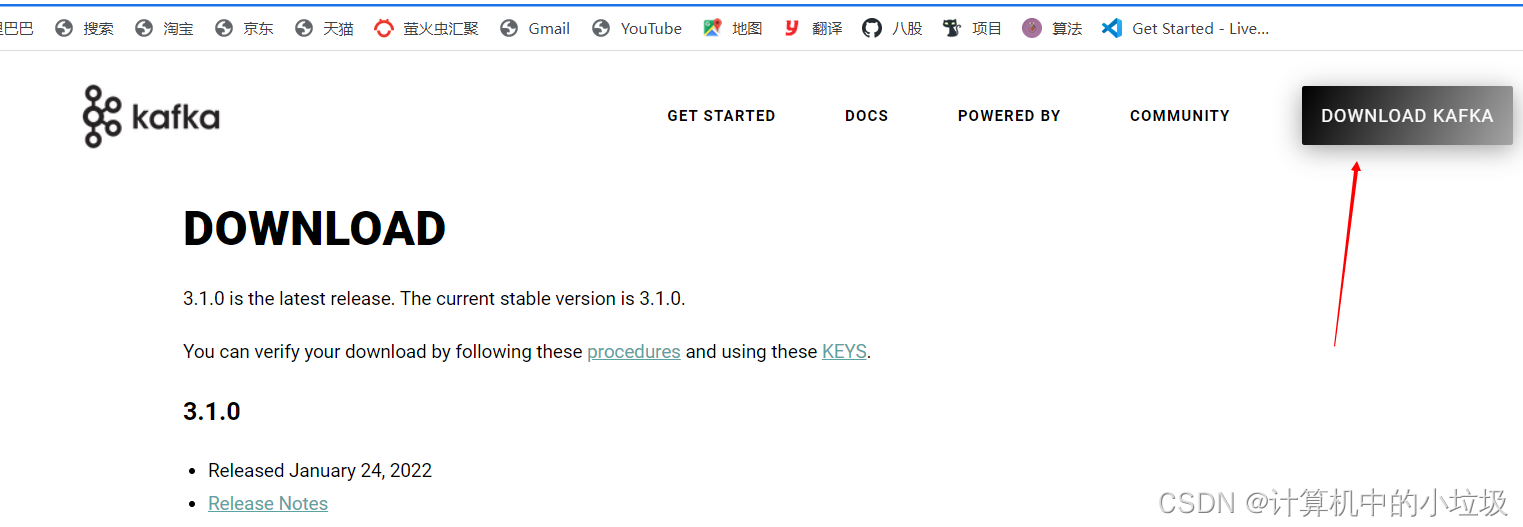
(1)点击下载
 (2)下载箭头所指
(2)下载箭头所指
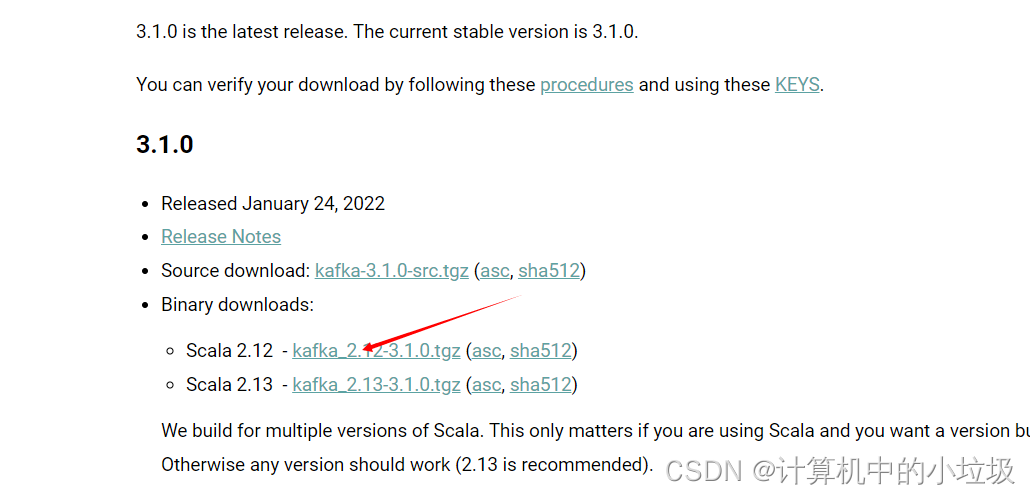
(3)两个都可以下载
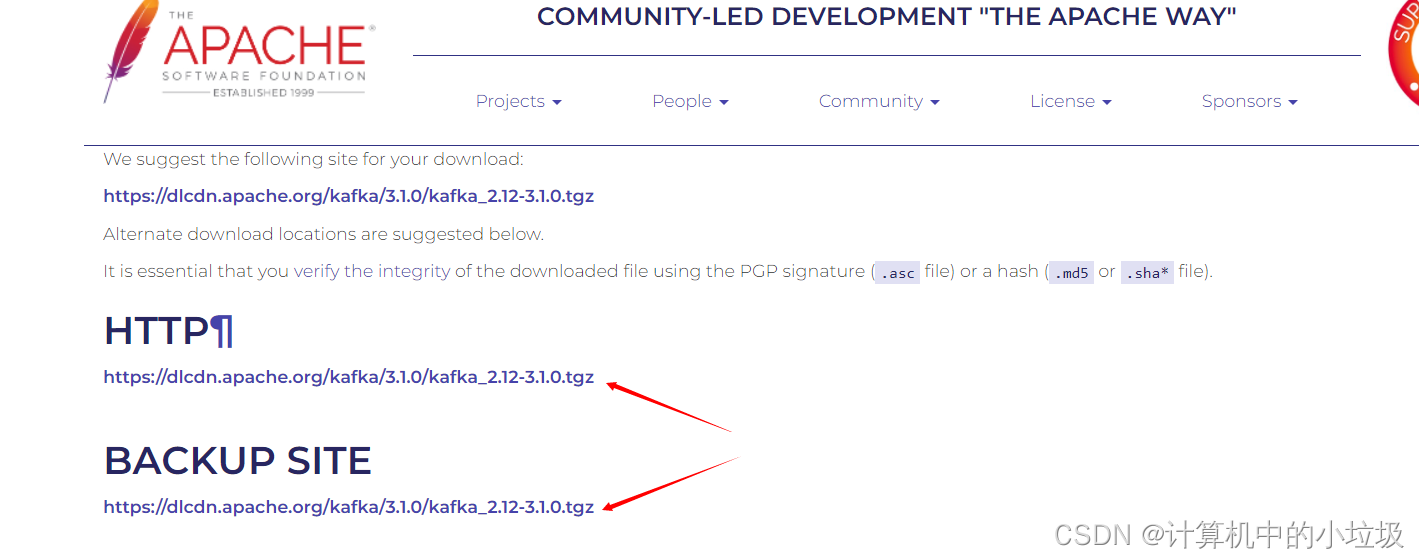
(4),下载后用xftp把包导入linux中

2,kafka的安装
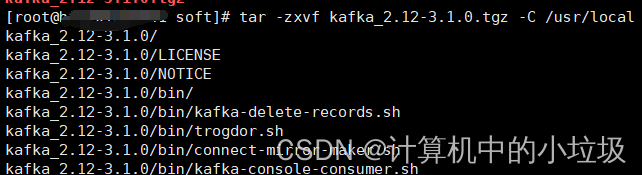
(1),解压
tar -zxvf kafka_2.12-3.1.0.tgz -C /usr/local
//这里/usr/local是我自己解压创建好的目录,你可以自己换
(2),查看是否解压完好,并且修改名称。(可以不修改,只是为了方便)

(3)进入config文件进行配置(主要有三个位置需要配置)

a,配置多个kafka的集群的时候,一定要保证这个id唯一
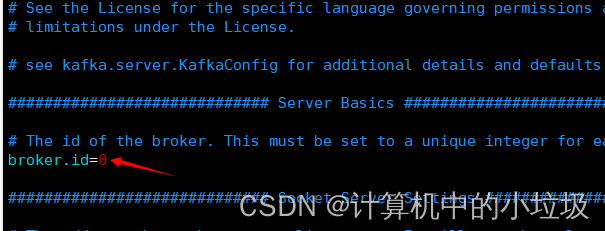
b,kafak的数据信息,是默认的存储在一个临时空间,会被回收,所以放在修改成自己想要存放的地方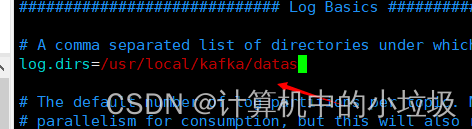
c,修改zookeeper(遮住的是主机名)
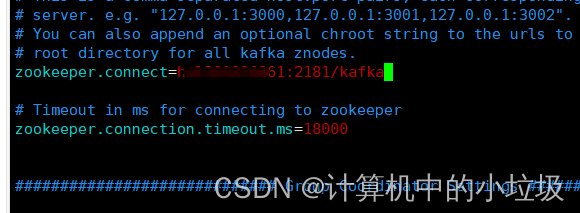
(3)你可以分发到其他节点,应为我只弄了一个节点(这里的xsync,是之前写的脚,具体的可以去看海哥的Hadoop)

(3)配置环境变量
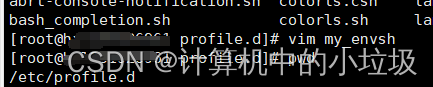
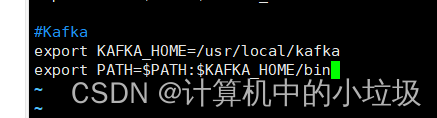
执行:source /etc/profile
3,kafka的启动
启动之前需要先启动zookeeper才行(电脑不行,没建立多个虚拟机,就不演示了)后序可以看海哥的kafka的视频















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









