






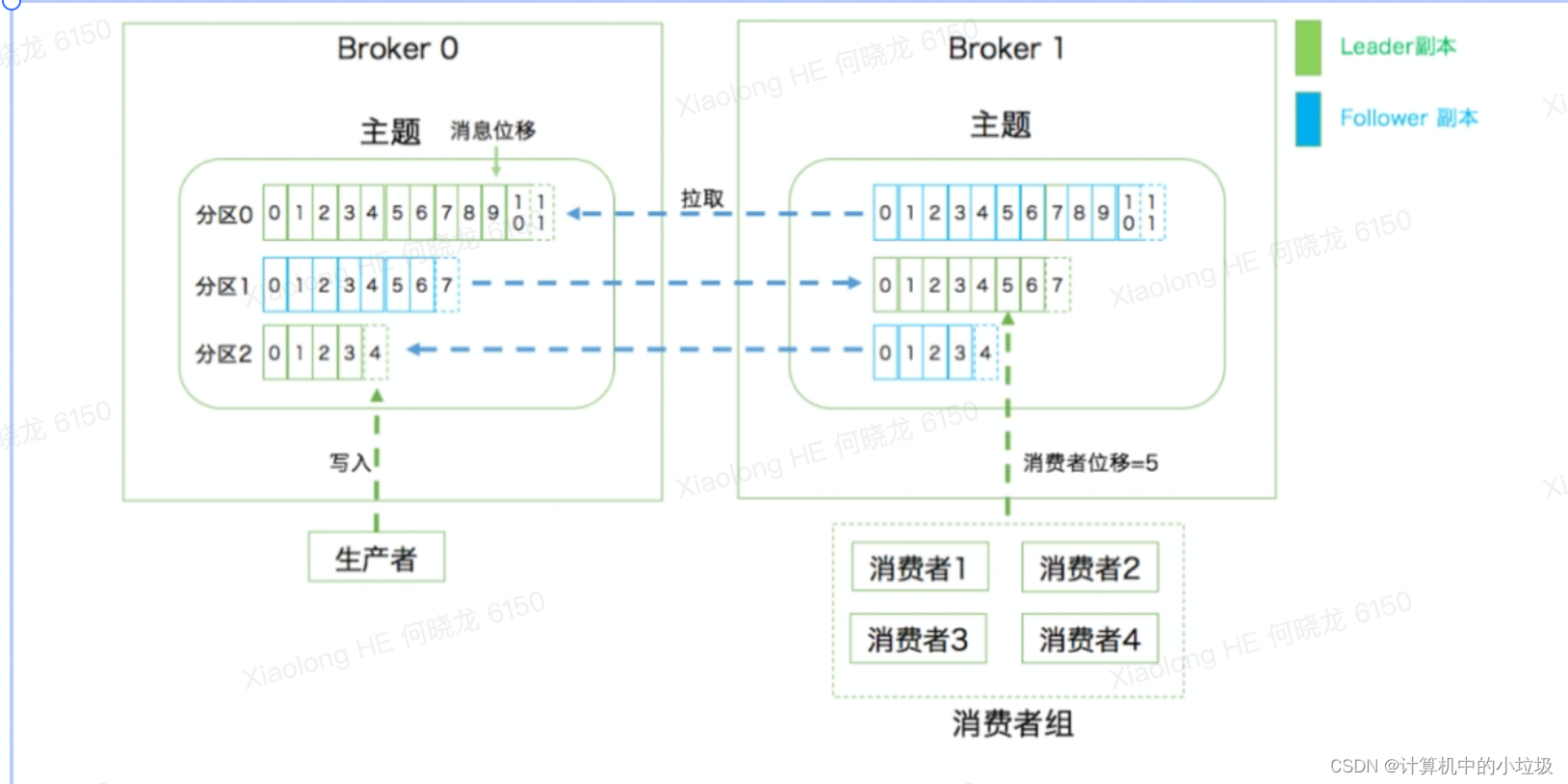
1,关于kafka的相关名词介绍
消息: Record。Kafka是消息引擎嘛,这里的消息就是指Kafka处理的主要对象。
主题: Topic。主题是承载消息的逻辑容器,在实际使用中多用来区分具体的业务。
分区: Partition。一个有序不变的消息序列。每个主题下可以有多个分区。
消息位移: Offset。表示分区中每条消息的位置信息,是一个单调递增且不变的值。
副本: Replica。Kafka中同一条消息能够被拷贝到多个地方以提供数据冗余,这些地方就是所谓的副本。副本还分为领导者副本和追随者副本,各自有不同的角色划分。副本是在分区层级下的,即每个分区可配置多个副本实现高可用。
生产者: Producer。向主题发布新消息的应用程序。
消费者: Consumer。从主题订阅新消息的应用程序。
消费者位移: ConsumerOffset。表征消费者消费进度,每个消费者都有自己的消费者位移。
消费者组: ConsumerGroup。多个消费者实例共同组成的一个组,同时消费多个分区以实现高吞吐。
重平衡: Rebalance。消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance是Kafka消费者端实现高可用的重要手段。 ----了解模式
1.1 容易弄混的名词
Broker是kafka服务端(是一个进程),消费者和生产者都是客户端(通常是一段程序);
Topic 是第一层 topic可以分到多个Broker上,可以拆分为多个分区,每个分区可以有多个副本
分区是第二层,每个分区的N个副本,只有一个主副本提供服务,其他的N-1只是数据冗余
第三层就是消息
1.2提出问题
Q:为什么kafka的追随者副本不像mysql的副本对外提供服务,而只是数据冗余作用
A:因为,数据分到不同的分区上,已经实现了负载均衡的作用。而如果追随者副本提供服务的话,就需要考虑数据一致性,等一系列问题,如果要解决这些问题就会降低效率。
2,分区的作用已经分区的机制
2.1分区的作用
kafka在有多个topic情况下还把每个topic拆分成若干个分区,分区的作用就是用来负载均衡。
不同的分区能够被放置到不同节点的机器 上,而数据的读写操作也都是针对分区这个粒度而进行的, 这样每个节点的机器都能独立地执行各自分区的读写请求处 理。
当我们想要增加吞吐量,怎么分区就行
2.2分区机制
1,kafka自带分区
轮询策略 (默认) :
轮询策略是 Kafka Java 生产者 API 默认提供的分区策略。如果你未指定 partitioner.class参数,那么你的生产者程序会按照轮 询的方式在主题的所有分区间均匀地“码放”消息。
随机策略:
本质上看随机策略也是力求将数据均匀地打散到各个分区, 但从实际表现来看,它要逊于轮询策略,所以如果追求数据 的均匀分布,还是使用轮询策略比较好
按消息键策略:
最近需求,就是用group id 作为key发送到消息中
2,自定义分区
自定义分区策略,你需要显式地配置生产者端的参数 partitioner.class。
你需要显式地配置生产者端的参数:(就在生产者配置)
props.put(“partitioner.class”,“kafka.producer.UserPartitioner”);
做法就是创建一个类,去实现org.apache.kafka.clients.producer.Partitioner接口 ,这个接口中只定义了两个方法
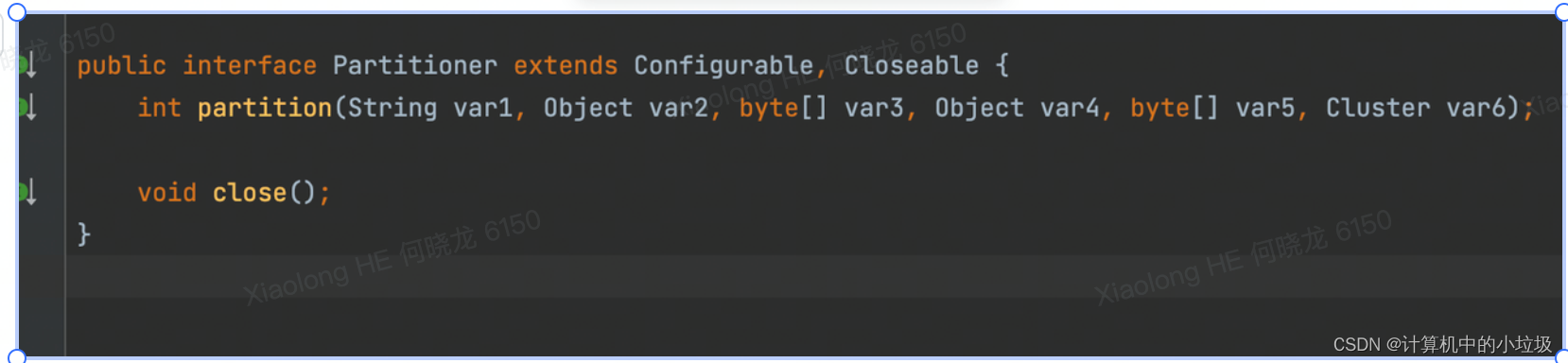
/**
* @description:根据用户id分区 相同用户id的数据肯定在一个分区 保证有序性
*/
public class UserPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
UserDomain userDomain = JSON.parseObject(value.toString(),UserDomain.class);
Integer keyObj = userDomain.getId();
List<PartitionInfo> partitionInfoList = cluster.availablePartitionsForTopic(topic);
int partitionCount = partitionInfoList.size();
System.out.println("keyObj=" + keyObj + " partition="+keyObj % partitionCount);
return keyObj % partitionCount;
}
}
2.3提出问题
Q:在kafka消息发送重试的时候,是否会再次执行一次分区策略?比如一开始选择到5号分区,但是5号分区有问题导致 重试,重试的时候可以重试发送到别的分区上吗?
A: 不会的。消息重试只是简单地将消息重新发送到 之前的分区
3,kafka消息压缩
3.1kafka的消息层次
Kafka 的消息层次都分为两层:消息集合(message set)以及消息 (message)。一个消息集合中包含若干条日志项(record item),而日志项才是真正封 装消息的地方。Kafka 底层的消息日志由一系列消息集合日志项组成 。
Kafka 通常不会直接 操作具体的一条条消息,它总是在消息集合这个层面上进行写入操作。
3.2 哪些地方压缩
生产者:
在生产者配置中可以配置压缩的类型 compression.type 参数即表示启用指定类型的压缩算法
props.put(“compression.type”, “gzip”);
Broker:
Broker一定会对生产方压缩的消息进行一个解压操作,目的就是为了消息各种验证
但是一般不会对消息内容进行修改重新压缩,只有特殊情况
(1)版本不同
消息格式转换,----会使kafka丧失零拷贝
(2 ) Broker 端指定了和 Producer 端不同的压缩算法
比如broker 指定了zip,producer指定了snappy-------broker默认是使用producer端的压缩算法
3.3压缩算法对比
支持的算法有GZIP、Snappy 和 LZ4 ,zstd;
一个压缩算法的优劣,有两个重要的指标:一个指标是压缩比,原先占 100 份空 间的东西经压缩之后变成了占 20 份空间,那么压缩比就是 5,显然压缩比越高越好;另一 个指标就是压缩 / 解压缩吞吐量,比如每秒能压缩或解压缩多少 MB 的数据。同样地,吞 吐量也是越高越好。
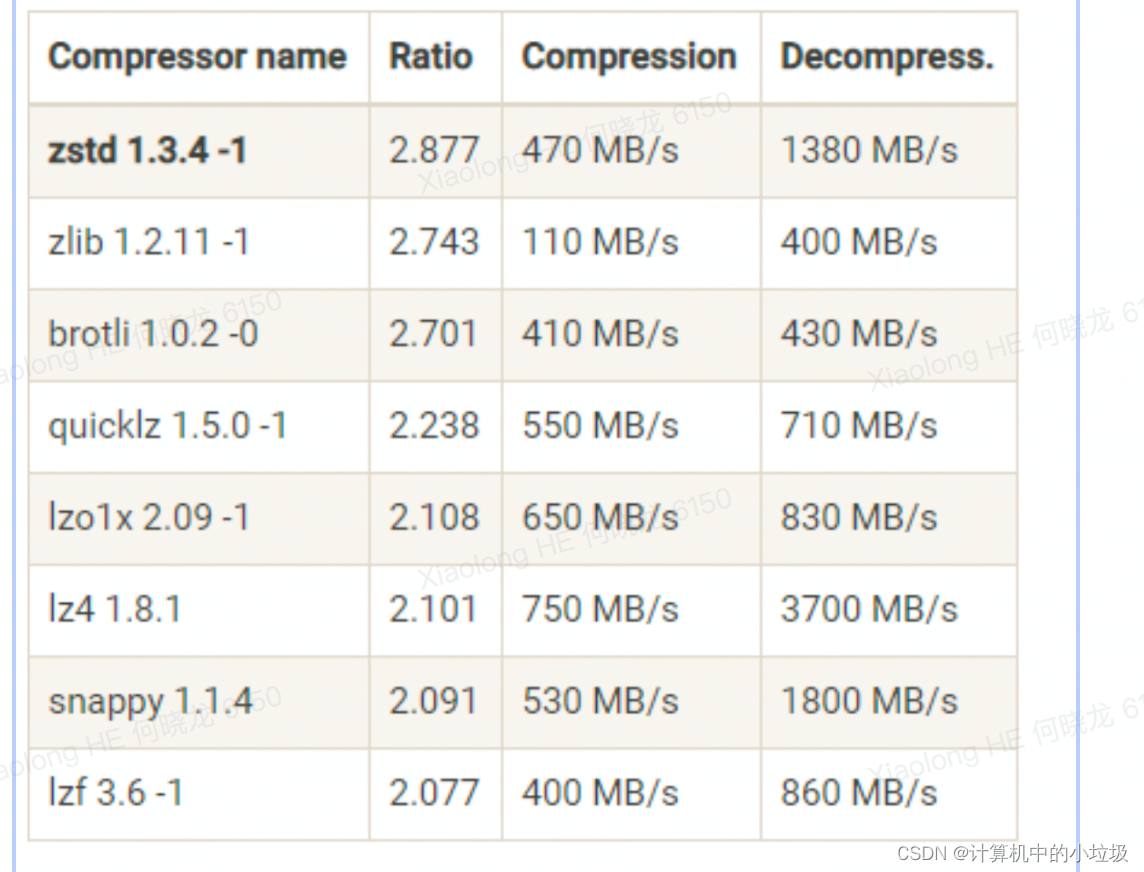
在吞吐量方面:LZ4 > Snappy > zstd 和 GZIP;而在压缩比方面,zstd > LZ4 > GZIP > Snappy。具体到物理资源,使用 Snappy 算法占用的网络带宽最多,zstd 最少,这是合理的,毕竟 zstd 就是要提供超高的压缩比
3.4提出问题
Q:可不可以把这种消息校验移到 Producer 端来做,Broker 直接读取校验结果即可,这样就可以避免在 Broker 端执行解压 缩操作。
A:本就是保证可靠性的,是不可以在发送方来验证
4,kafka持久化的配置
4.1消息会在哪丢失
kafka只对已提交的消息保持持久化
(1)生产者
(2)消费者
4.2如何配置
- 不要使用 producer.send(msg),而要使用 producer.send(msg, callback)。记住,一 定要使用带有回调通知的 send 方法。
- 设置 acks = all。acks 是 Producer 的一个参数,代表了你对“已提交”消息的定义。 如果设置成 all,则表明所有副本 Broker 都要接收到消息,该消息才算是“已提交”。 这是最高等级的“已提交”定义。
- 设置 retries 为一个较大的值。这里的 retries 同样是 Producer 的参数,对应前面提到 的 Producer 自动重试。当出现网络的瞬时抖动时,消息发送可能会失败,此时配置了 retries > 0 的 Producer 能够自动重试消息发送,避免消息丢失。
- 设置 unclean.leader.election.enable = false。这是 Broker 端的参数,它控制的是哪些 Broker 有资格竞选分区的 Leader。如果一个 Broker 落后原先的 Leader 太多,那么 它一旦成为新的 Leader,必然会造成消息的丢失。故一般都要将该参数设置成 false即不允许这种情况的发生。
- 设置 replication.factor >= 3。这也是 Broker 端的参数。其实这里想表述的是,最好将 消息多保存几份,毕竟目前防止消息丢失的主要机制就是冗余。
- 设置 min.insync.replicas > 1。这依然是 Broker 端参数,控制的是消息至少要被写入 到多少个副本才算是“已提交”。设置成大于 1 可以提升消息持久性。在实际环境中千万不要使用默认值 1。
- 确保 replication.factor > min.insync.replicas。如果两者相等,那么只要有一个副本挂 机,整个分区就无法正常工作了。我们不仅要改善消息的持久性,防止数据丢失,还要在不降低可用性的基础上完成。推荐设置成 replication.factor = min.insync.replicas + 1
- 确保消息消费完成再提交。Consumer 端有个参数 enable.auto.commit,最好把它设 false,手动提交
4.3提出问题
Q: 增加主题分区后,在某段“不凑巧”的时间间隔后,Producer 先于 Consumer 感知到新增加的分区,Consumer 设置的是“从最新位移处”开始读取消息,因此在 Consumer 感知到新分区前,Producer 发送的这些消息就全部“丢失”了,或者说 Consumer 无法读取到这些消息。严格来说这是 Kafka 设计上的一个小缺陷,你有什么解决的办法吗?
A:程序停止再增加分区,如果不能停止那就找个通知机制了 ,牺牲高可用
5,kafka采用的什么连接(TCP or HTTP)
Apache Kafka 的所有通信都是基于 TCP 的,而不是基于 HTTP 或其他协议。无论是生产者、消费者,还是 Broker 之间的通信都是如此。
5.1 使用tcp的原因
(1)TCP拥有一些高级功能,如多路复用请求和同时轮询多个连接的能力。
TCP的多路复用请求会在一条物理连接上创建若干个虚拟连接,每个虚拟连接负责流转各自对应的数据流。严格讲:TCP并不能多路复用,只是提供可靠的消息交付语义保证,如自动重传丢失的报文。
(2)很多编程语言的HTTP库功能相对的比较简陋。
5.2什么时候创建tcp连接
java使用kafka通常有以下几步
第 1 步:构造生产者对象所需的参数对象。
第 2 步:利用第 1 步的参数对象,创建 KafkaProducer 对 象实例。
第 3 步:使用 KafkaProducer 的 send 方法发送消息。
第 4 步:调用 KafkaProducer 的 close 方法关闭生产者并 释放各种系统资源。
(个人认为) 第二步 第三步都有可能
首先,生产者应用在创建 KafkaProducer 实例时是会建立 与 Broker 的 TCP 连接的。其实这种表述也不是很准确,应 该这样说:在创建 KafkaProducer 实例时,生产者应用会 在后台创建并启动一个名为 Sender 的线程,该 Sender 线 程开始运行时首先会创建与 Broker 的连接。
Q:在调用send方法的时候,才会在设置topic,之前的时候怎么判断和那个broker连接
A:bootstrap.servers 里面配置的都会建立一个tcp连接,里面配置了1000个就和1000个进行tcp连接
其次:TCP 连接还可能在两个地方被创建:一个是在更 新元数据后,另一个是在消息发送时
5.2 总结
- KafkaProducer 实例创建时启动 Sender 线程,从而创 建与 bootstrap.servers 中所有 Broker 的 TCP 连接。
- KafkaProducer 实例首次更新元数据信息之后,还会再 次创建与集群中所有 Broker 的 TCP 连接。
- 如果 Producer 端发送消息到某台 Broker 时发现没有与 该 Broker 的 TCP 连接,那么也会立即创建连接。
- 如果设置 Producer 端 connections.max.idle.ms 参数 大于 0,则步骤 1 中创建的 TCP 连接会被自动关闭;如
果设置该参数 =-1,那么步骤 1 中创建的 TCP 连接将无 法被关闭,从而成为“僵尸”连接。
6,kafka的幂等,和事物
6.1kafka的消息交付可靠性保障
是指 Kafka 对 Producer 和 Consumer 要处理的消息提供什么样的承诺。常见的承诺有
最多一次(at most once):消息可能会丢失,但绝不会 被重复发送。
至少一次(at least once):消息不会丢失,但有可能被 重复发送。 (默认提供)
精确一次(exactly once):消息不会丢失,也不会被重 复发送。
Kafka使用幂等,和事物两种机制来保证精确一次
幂等性 Producer
在 Kafka 中,Producer 默认不是幂等性的,但我们可以创 建幂等性 Producer。它其实是 0.11.0.0 版本引入的新功 能。在此之前,Kafka 向分区发送数据时,可能会出现同一 条消息被发送了多次,导致消息重复的情况。
设置幂等代码
props.put(“enable.idempotence”, ture),或
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CO NFIG, true)
底层具体的原理很 简单,就是经典的用空间去换时间的优化思路,即在 Broker 端多保存一些字段。当 Producer 发送了具有相同 字段值的消息后,Broker 能够自动知晓这些消息已经重复 了,于是可以在后台默默地把它们“丢弃”掉
幂等的不足
首先,它只能保证单分区上的幂等性,即一个幂等性 Producer 能够保证某个主题的一个分区上不出现重复消 息,它无法实现多个分区的幂等性。其次,它只能实现单会 话上的幂等性,不能实现跨会话的幂等性。这里的会话,你 可以理解为 Producer 进程的一次运行。当你重启了 Producer 进程之后,这种幂等性保证就丧失了。
解决这种不足就是使用事物
事务型 Producer 能够保证将消息原子性地写入到多个分区 中。这批消息要么全部写入成功,要么全部失败。另外,事 务型 Producer 也不惧进程的重启。Producer 重启回来 后,Kafka 依然保证它们发送消息的精确一次处理
设置事物
和幂等性 Producer 一样,开启 enable.idempotence = true。
设置 Producer 端参数 transctional. id。最好为其设置一 个有意义的名字。

7,消费者组
7.1 消费者组是什么
Consumer Group 是 Kafka 提供的可扩展且 具有容错性的消费者机制。既然是一个组,那么组内必然可 以有多个消费者或消费者实例(Consumer Instance),它 们共享一个公共的 ID,这个 ID 被称为 Group ID。组内的 所有消费者协调在一起来消费订阅主题(Subscribed Topics)的所有分区(Partition)。当然,每个分区只能由 同一个消费者组内的一个 Consumer 实例来消费。
- Consumer Group 下可以有一个或多个 Consumer 实 例。这里的实例可以是一个单独的进程,也可以是同一进 程下的线程。在实际场景中,使用进程更为常见一些。
- Group ID 是一个字符串,在一个 Kafka 集群中,它标识 唯一的一个 Consumer Group。
- Consumer Group 下所有实例订阅的主题的单个分区, 只能分配给组内的某个 Consumer 实例消费。这个分区 当然也可以被其他的 Group 消费。
7.2 一个组下,该有多少个consumer
理想情况下, Consumer 实例的数量应该等于该 Group 订阅主题的分区 总数。
一般来说,设置的个数,和分区相对应,可以小分区个数。不建议大于分区个数,这样会使得多的consumer空余,资源浪费
7.3 消费位移
消费者组中的消费者,都对应着自己消费的分区,那么就需要记录下消费到哪里了,这就是位移(offset)
看上去该 Offset 就是一个数值而已,其实对于 Consumer Group 而言,它是一组 KV 对,Key 是分区,V 对应 Consumer 消费该分区的最新位移。
老版本:
老版本的 Consumer Group 把位移保存在 ZooKeeper 中。Apache ZooKeeper 是一个分布式的协调服务框架, Kafka 重度依赖它实现各种各样的协调管理。将位移保存在
ZooKeeper 外部系统的做法,最显而易见的好处就是减少 了 Kafka Broker 端的状态保存开销 。
BUT
ZooKeeper 这类元 框架其实并不适合进行频繁的写更新,而 Consumer Group 的位移更新却是一个非常频繁的操作。这种大吞吐 量的写操作会极大地拖慢 ZooKeeper 集群的性能,因此 Kafka 社区渐渐有了这样的共识:将 Consumer 位移保存 在 ZooKeeper 中是不合适的做法。
新版本:
Kafka 社区重新 设计了 Consumer Group 的位移管理方式,采用了将位移 保存在 Kafka 内部主题的方法。这个内部主题就是让人既爱 又恨的 _consumer_offsets。
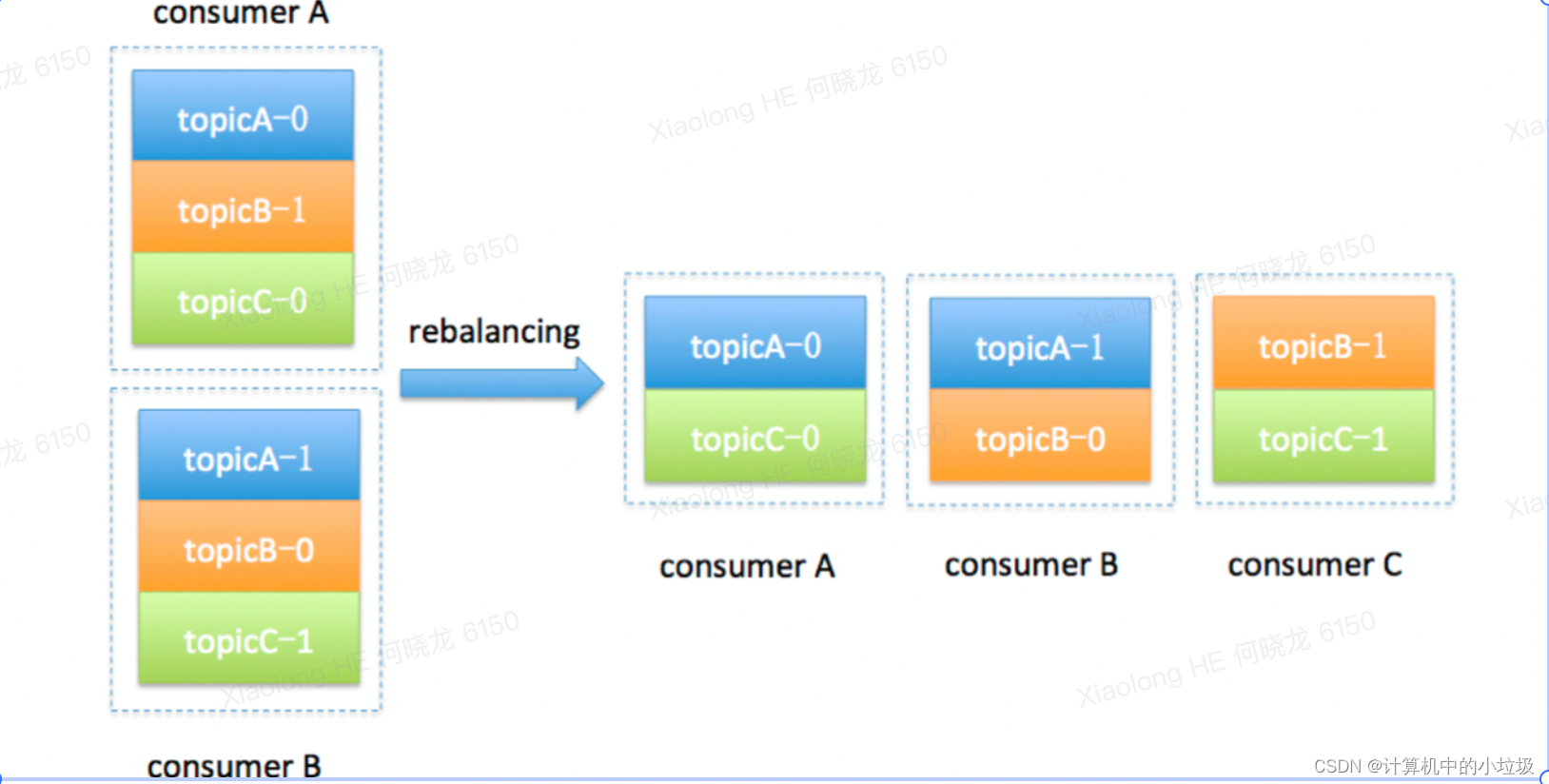
7.4 Rebalance
Rebalance 本质上是一种协议,规定了一个 Consumer Group 下的所有 Consumer 如何达成一致,来分配订阅 Topic 的每个分区。
Rebalance 的触发条件有 3 个。
- 组成员数发生变更。比如有新的 Consumer 实例加入组 或者离开组,抑或是有 Consumer 实例崩溃被“踢 出”组。
- 订阅主题数发生变更。Consumer Group 可以使用正则 表达式的方式订阅主题,比如 consumer.subscribe(Pattern.compile(“t.*c”)) 就表 明该 Group 订阅所有以字母 t 开头、字母 c 结尾的主 题。在 Consumer Group 的运行过程中,你新创建了一 个满足这样条件的主题,那么该 Group 就会发生 Rebalance。
- 订阅主题的分区数发生变更。Kafka 当前只能允许增加一 个主题的分区数。当分区数增加时,就会触发订阅该主题 的所有 Group 开启 Rebalance
缺点:Rebalance 速度太慢,所有分区都跌参加,就像JVM中的STW全部停止
8,kafka的位移主题
kakfa专门处理位移的一个主题 __consumer_offsets。(普通主题)
在不使用zk来存储位移后,现在把位移放到了kafka的内部。
8.1 原理:
新版本 Consumer 的位移管理机制其实也很简单,就是将 Consumer 的位移数据作为一 条条普通的 Kafka 消息,提交到 __consumer_offsets 中。可以这么说, __consumer_offsets 的主要作用是保存 Kafka 消费者的位移信息
虽说位移主题是一个普通的 Kafka 主题,但它的消息格式却是 Kafka 自己定义的,用户不 能修改,也就是说你不能随意地向这个主题写消息,因为一旦你写入的消息不满足 Kafka 规定的格式,那么 Kafka 内部无法成功解析,就会造成 Broker 的崩溃。事实上,Kafka Consumer 有 API 帮你提交位移,也就是向位移主题写消息。
8.2位移的主题格式
Q:位移主题如何发送位移消息的呢?如何去识别属于某个消费者的位移呢?
A:对于所谓的消息格式,你可以简单地理 解为是一个 KV 对。Key 和 Value 分别表示消息的键值和消息体,在 Kafka 中它们就是字 节数组而已。 位移主题的 Key 中应该保存 3 部分内容:<Group ID,主题名,分区号 >。
位移的主题格式不及上一种,还有两种
- 用于保存 Consumer Group 信息的消息。
- 用于删除 Group 过期位移甚至是删除 Group 的消息。
第 1 种格式非常神秘,以至于你几乎无法在搜索引擎中搜到它的身影。不过,你只需要记 住它是用来注册 Consumer Group 的就可以了。
第 2 种格式相对更加有名一些。它有个专属的名字:tombstone 消息,即墓碑消息,也称 delete mark。下次你在 Google 或百度中见到这些词,不用感到惊讶,它们指的是一个东 西。这些消息只出现在源码中而不暴露给你。它的主要特点是它的消息体是 null,即空消 息体。
8.3 位移主题如何被创建的
当 Kafka 集群中的第一个 Consumer 程序启动时,Kafka 会自动创建位移主题。(可以手动创建,在Kafka启动之前)我们说过, 位移主题就是普通的 Kafka 主题,那么它自然也有对应的分区数。但如果是 Kafka 自动创 建的,分区数是怎么设置的呢?这就要看 Broker 端参数 offsets.topic.num.partitions 的 取值了。它的默认值是 50,因此 Kafka 会自动创建一个 50 分区的位移主题。如果你曾经 惊讶于 Kafka 日志路径下冒出很多 __consumer_offsets-xxx 这样的目录,那么现在应该 明白了吧,这就是 Kafka 自动帮你创建的位移主题啊。
你可能会问,除了分区数,副本数或备份因子是怎么控制的呢?答案也很简单,这就是 Broker 端另一个参数 offsets.topic.replication.factor 要做的事情了。它的默认值是 3。
总结一下,如果位移主题是 Kafka 自动创建的,那么该主题的分区数是 50,副本数是 3。
8.4 位移如何提交
Consumer 提交位移的方式有两种:自动提交位移和手动提交位移。
Consumer 端有个参数叫 enable.auto.commit,如果值是 true,则 Consumer 在后台默 默
地为你定期提交位移,提交间隔由一个专属的参数 auto.commit.interval.ms 来控制。
自动提交位移有一个显著的优点,就是省事,你不用操心位移提交的事情,就能保证消息消 费不会丢失。
但这一点同时也是缺点。因为它太省事了,以至于丧失了很大的灵活性和可控 性,
你完全没法把控 Consumer 端的位移管理。
手动提交位移,即设置 enable.auto.commit = false。 一旦设置了 false,作为 Consumer
应用开发的你就要承担起位移提交的责任。Kafka Consumer API 为你提供了位移提交的方法,
如 consumer.commitSync 等。当调用这些 方法时,Kafka 会向位移主题写入相应的消息。
如果你选择的是自动提交位移,那么就可能存在一个问题:只要 Consumer 一直启动着,
它就会无限期地向位移主题写入消息。
自动提交位移可能会无限制的提交位移数据
8.5删除过期位移数据
Kafka 使用Compact 策略来删除位移主题中的过期消息,避免该主题无限 期膨胀。那么应该如何定义 Compact 策略中的过期呢?对于同一个 Key 的两条消息 M1 和 M2,如果 M1 的发送时间早于 M2,那么 M1 就是过期消息。Compact 的过程就是扫 描日志的所有消息,剔除那些过期的消息,然后把剩下的消息整理在一起。 (有点像redis 重写aof)
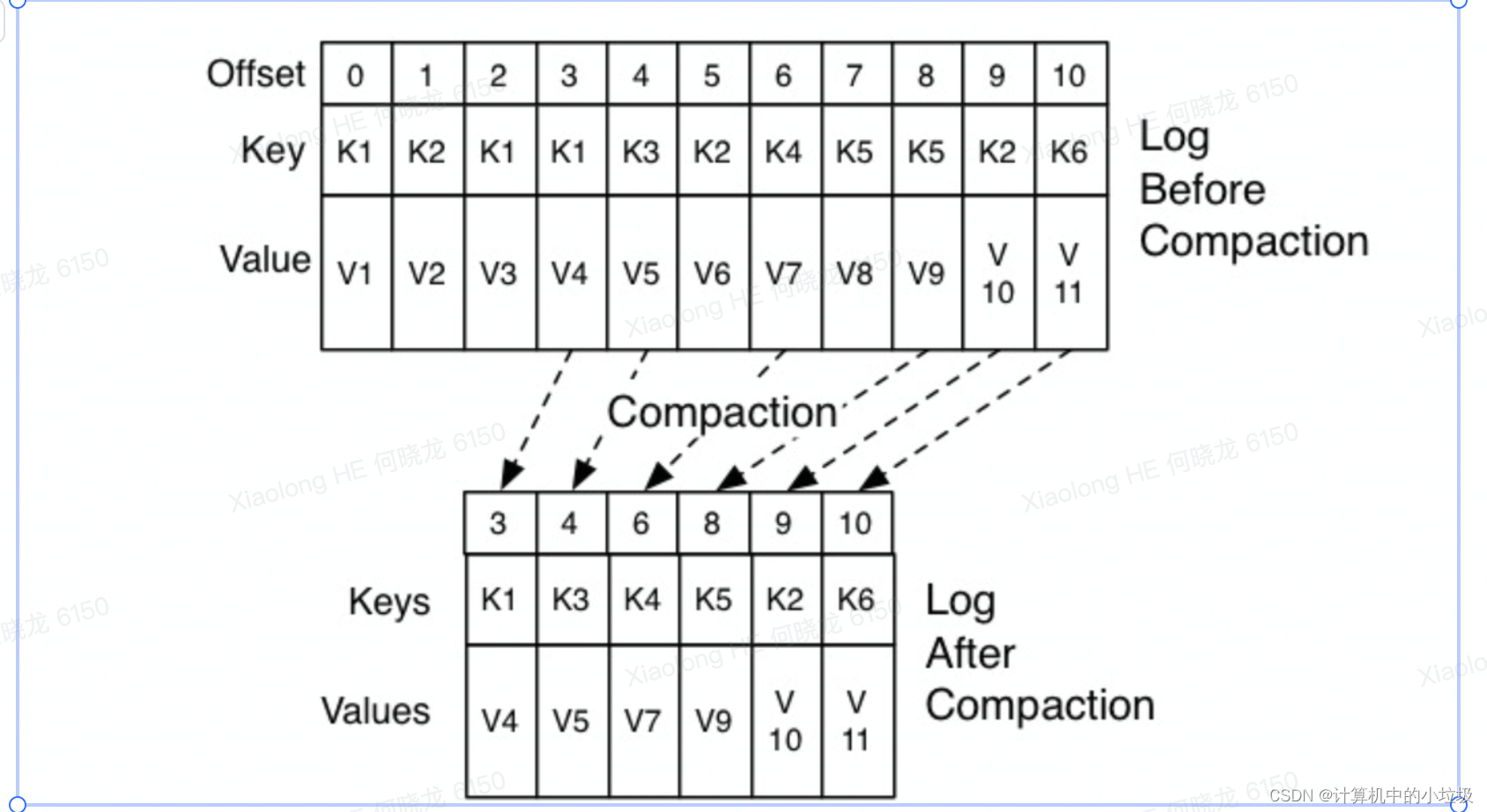
9,rebalance能避免吗
9.1协调者:
所谓协调者,在 Kafka 中 对应的术语是 Coordinator,它专门为 Consumer Group 服务,负责为 Group 执行 Rebalance 以及提供位移管理和组成员管理等。
具体来讲,Consumer 端应用程序在提交位移时,其实是向 Coordinator 所在的 Broker 提交位移。同样地,当 Consumer 应用启动时,也是向 Coordinator 所在的 Broker 发送 各种请求,然后由 Coordinator 负责执行消费者组的注册、成员管理记录等元数据管理操 作。
所有 Broker 在启动时,都会创建和开启相应的 Coordinator 组件。也就是说,所有 Broker 都有各自的 Coordinator 组件。那么,Consumer Group 如何确定为它服务的 Coordinator 在哪台 Broker 上呢?是 Kafka 内部位移主题 __consumer_offsets 身上。
目前,Kafka 为某个 Consumer Group 确定 Coordinator 所在的 Broker 的算法有 2 个 步骤。
第 1 步:确定由位移主题的哪个分区来保存该 Group 数据: partitionId=Math.abs(groupId.hashCode() % offsetsTopicPartitionCount)。
第 2 步:找出该分区 Leader 副本所在的 Broker,该 Broker 即为对应的 Coordinator。
9.2 rebalance 的缺点
- Rebalance 影响 Consumer 端 TPS。这个之前也反复提到了,这里就不再具体讲了。总 之就是,在 Rebalance 期间,Consumer 会停下手头的事情,什么也干不了。
- Rebalance 很慢。如果你的 Group 下成员很多,就一定会有这样的痛点。还记得我曾经 举过的那个国外用户的例子吧?他的 Group 下有几百个 Consumer 实例,Rebalance 一次要几个小时。在那种场景下,Consumer Group 的 Rebalance 已经完全失控了。
- Rebalance 效率不高。当前 Kafka 的设计机制决定了每次 Rebalance 时,Group 下的 所有成员都要参与进来,而且通常不会考虑局部性原理,但局部性原理对提升系统性能 是特别重要的。
9.3 哪些不需要rebalance
第一类非必要 Rebalance 是因为未能及时发送心跳,导致 Consumer 被“踢出”Group 而引发的。因此,你需要仔细地设置session.timeout.ms 和 heartbeat.interval.ms的 值。我在这里给出一些推荐数值,你可以“无脑”地应用在你的生产环境中。
设置 session.timeout.ms = 6s。 设置 heartbeat.interval.ms = 2s。
要保证 Consumer 实例在被判定为“dead”之前,能够发送至少 3 轮的心跳请求,即 session.timeout.ms >= 3 * heartbeat.interval.ms。
第二类非必要 Rebalance 是 Consumer 消费时间过长导致的。我之前有一个客户,在他 们的场景中,Consumer 消费数据时需要将消息处理之后写入到 MongoDB。显然,这是 一个很重的消费逻辑。MongoDB 的一丁点不稳定都会导致 Consumer 程序消费时长的增 加。此时,max.poll.interval.ms参数值的设置显得尤为关键。如果要避免非预期的 Rebalance,你最好将该参数值设置得大一点,比你的下游最大处理时间稍长一点。就拿 MongoDB 这个例子来说,如果写 MongoDB 的最长时间是 7 分钟,那么你可以将该参数 设置为 8 分钟左右。
总之,你要为你的业务处理逻辑留下充足的时间。这样,Consumer 就不会因为处理这些 消息的时间太长而引发 Rebalance 了。















 599
599











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









