







目录
1、概念
在计算机科学中,trie,又称前缀树或字典树。与二叉查找树不同,值不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。
Trie 的典型应用是用于统计,它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较
2、时间复杂度
Trie只和字符串长度有关
O(n) n为查找单词长度

3、Trie节点结构
//节点
private class Node {
boolean isWord; //查询是否是单词
Map<Character, Node> next; //该节点下所有的字符对应的节点
Node() {
isWord = false;
next = new HashMap<>();
}
}
4、添加单词操作
/**
* 添加单词
*
* @param str
*/
public void addStr(String str) {
if (str == null && str.length() == 0) {
return;
}
Node cur = root;
for (int i = 0; i < str.length(); i++) {
char c = str.charAt(i);//取出每一个字符
//放进集合里
Map<Character, Node> chilren = cur.next;
if (!chilren.keySet().contains(c)) {
chilren.put(c, new Node());
}
cur = chilren.get(c);
}
//isWord 默认为false 如果是单词,size加1
if (!cur.isWord) {
cur.isWord = true;
this.size += 1;
}
}
-
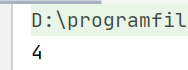
String[] strs = {"dog", "rabbit", "tree", "panda"}; Trie trie = new Trie(); Arrays.stream(strs).forEach(item -> trie.addStr(item)); System.out.println(trie.getSize()); ```
长度为4的数组
5、判断是否有指定的单词
/**
* 判断是否存在指定的单词
*
* @param word
* @return
*/
public boolean matchWord(String word) {
if (word == null || word.length() == 0) {
return false;
}
Node cur = root;
for (int i = 0; i < word.length(); i++) {
char c = word.charAt(i);
Map<Character, Node> children = cur.next;
if (!children.keySet().contains(c)) {
return false;
}
cur = children.get(c);
}
return cur.isWord;
}
- System.out.println(trie.matchWord(“pan”));

6、判断是否有以pre为前缀的单词
/**
* 判断是否存在以pre开始的单词
*
* @param pre
* @return
*/
public boolean matchStartPre(String pre) {
if (pre == null || pre.length() == 0) {
return false;
}
Node cur = root;
for (int i = 0; i < pre.length(); i++) {
char c = pre.charAt(i);
Map<Character, Node> children = cur.next;
if (!children.keySet().contains(c)) {
return false;
}
cur = children.get(c);
}
return true;
}
public boolean search(String express) {
if (express == null || express.length() == 0) {
return false;
}
return match(root, express, 0);
}
- System.out.println(trie.matchStartPre(“pan”));

7、模糊查询 .可以为任意数
/**
* 查询是否包含某个单词的前缀 .可以是任意单词
*
* @param node 当前节点
* @param express 表达式
* @param index 表达式中匹配自负的索引
* @return
*/
private boolean match(Node node, String express, int index) {
if (index == express.length()) {
return true;
}
char c = express.charAt(index);
if (c != '.') {
Map<Character, Node> children = node.next;
if (!children.keySet().contains(c)) {
return false;
}
return match(children.get(c), express, index + 1);
} else {
Map<Character, Node> children = node.next;
Set<Character> set = children.keySet();
for (Character chr : set
) {
if (match(children.get(chr), express, index + 1)) {
return true;
}
}
return false;
}
}
- System.out.println(trie.match(trie.root, “do.”, 0));

8、查询出以pre为前缀的单词
/**
* 查询出和表达式前缀匹配的单词
* @param express
* @return
*/
public List<String> matchstartexpressWords(String express){
List<String> list= new ArrayList<>();
if (express!=null&&express.length()!=0){
matchs(root,express,0,list);
}
return list;
}
/**
*
* @param node
* @param express
* @param index
* @param list
* @return
*/
private void matchs(Node node, String express, int index, List<String> list) {
//递归到底
if (express.length()==index){
//查找
findwords(node,list);
return ;
}
//递归操作
char c = express.charAt(index);
if (c != '.') {
Map<Character, Node> children = node.next;
if (!children.keySet().contains(c)) {
return;
}
matchs(children.get(c), express, index + 1,list);
} else {
Map<Character, Node> children = node.next;
Set<Character> set = children.keySet();
for (Character chr : set
) {
matchs(children.get(chr), express, index + 1,list);
}
}
}
//递归操作 获取单词
private void findwords(Node node, List<String> list) {
if (node.isWord){
list.add(node.val);
}
//递归到底
if (node.next.size()==0){
return;
}
Map<Character, Node> map =node.next;
Set<Character> keys =map.keySet();
for (Character key: keys
) {
findwords(map.get(key),list);
}
}
-
List<String> list =trie.matchstartexpressWords("pan"); list.stream().forEach(System.out::println);

9、删除单词
//删除单词
public void deleteWord(String word){
if (word==null&&word.length()==0){
throw new IllegalArgumentException("word is vaild");
}
Node cur =root;
Node multiNode =null; //单词分叉的节点
int mulitIndex =-1;//单词分叉的索引
for (int i = 0; i < word.length(); i++) {
char c= word.charAt(i);//取到每一个符号
Map<Character ,Node> children = cur.next;
if (!children.containsKey(c)){
return;
}else {
Node node =children.get(c);
if (node.next.size()>1||node.next.size()==1&&node.isWord){
multiNode=node;
mulitIndex=i;
}
cur=node;
}
}
//真正删除 分为三种形式
if (cur.isWord){ //判断是单词的话,进行下面的操作
//如果要删除的单词是不删除单词的前缀(pan是panda的前缀),则把节点设置为false
if (cur.next.size()>0){
cur.isWord=false;
//当单词分叉的节点为空,这说明这个单词整个删除
}else if (multiNode==null){
this.root.next.remove(word.charAt(0));
//两个单词要删除单词和不删除单词公用前缀(dog 和 door 公用do),则删除节点下一个元素
}else {
multiNode.next.remove(word.charAt(mulitIndex+1));
}
this.size+=1;
}
}
-
trie.deleteWord("pan"); System.out.println(trie.matchWord("pan")); System.out.println(trie.matchWord("panda")); System.out.println(trie.matchWord("pand"));

10、完整代码实现
package lesson7;
import java.util.*;
public class Trie {
public static void main(String[] args) {
String[] strs = {"dog", "rabbit", "tree", "panda","pan","pand"};
Trie trie = new Trie();
Arrays.stream(strs).forEach(item -> trie.addStr(item));
System.out.println(trie.getSize());
// System.out.println(trie.toString());
// System.out.println(trie.matchWord("pan"));
// System.out.println(trie.matchStartPre("pan"));
// System.out.println(trie.match(trie.root, "do.", 0));
List<String> list =trie.matchstartexpressWords("pan");
list.stream().forEach(System.out::println);
//删除
trie.deleteWord("pan");
System.out.println(trie.matchWord("pan"));
System.out.println(trie.matchWord("panda"));
System.out.println(trie.matchWord("pand"));
}
//节点
private class Node {
boolean isWord; //查询是否是单词
Map<Character, Node> next; //该节点下所有的字符对应的节点
String val; //保存该节点之前的所有字符组成的字符串
Node(String val) {
isWord = false;
next = new HashMap<>();
this.val=val;
}
public Node() {
this("");
}
}
private Node root;
private int size;
public Trie() {
this.root = new Node();
this.size = 0;
}
public int getSize() {
return this.size;
}
/**
* 添加单词
*
* @param str
*/
public void addStr(String str) {
if (str == null && str.length() == 0) {
return;
}
Node cur = root;
for (int i = 0; i < str.length(); i++) {
char c = str.charAt(i);//取出每一个字符
//放进集合里
Map<Character, Node> chilren = cur.next;
if (!chilren.keySet().contains(c)) {
chilren.put(c, new Node(cur.val+c));
}
cur = chilren.get(c);
}
//isWord 默认为false 如果是单词,size加1
if (!cur.isWord) {
cur.isWord = true;
this.size += 1;
}
}
/**
* 判断是否存在指定的单词
*
* @param word
* @return
*/
public boolean matchWord(String word) {
if (word == null || word.length() == 0) {
return false;
}
Node cur = root;
for (int i = 0; i < word.length(); i++) {
char c = word.charAt(i);
Map<Character, Node> children = cur.next;
if (!children.keySet().contains(c)) {
return false;
}
cur = children.get(c);
}
return cur.isWord;
}
/**
* 判断是否存在以pre开始的单词
*
* @param pre
* @return
*/
public boolean matchStartPre(String pre) {
if (pre == null || pre.length() == 0) {
return false;
}
Node cur = root;
for (int i = 0; i < pre.length(); i++) {
char c = pre.charAt(i);
Map<Character, Node> children = cur.next;
if (!children.keySet().contains(c)) {
return false;
}
cur = children.get(c);
}
return true;
}
/**
* 模糊匹配
* @param express
* @return
*/
public boolean search(String express) {
if (express == null || express.length() == 0) {
return false;
}
return match(root, express, 0);
}
/**
* 查询是否包含某个单词的前缀 .可以是任意单词 模糊匹配
*
* @param node 当前节点
* @param express 表达式
* @param index 表达式中匹配自负的索引
* @return
*/
private boolean match(Node node, String express, int index) {
//递归到底
if (index == express.length()) {
return node.isWord;
}
char c = express.charAt(index);
if (c != '.') {
Map<Character, Node> children = node.next;
if (!children.keySet().contains(c)) {
return false;
}
return match(children.get(c), express, index + 1);
} else {
Map<Character, Node> children = node.next;
Set<Character> set = children.keySet();
for (Character chr : set
) {
if (match(children.get(chr), express, index + 1)) {
return true;
}
}
return false;
}
}
/**
* 查询出和表达式前缀匹配的单词
* @param express
* @return
*/
public List<String> matchstartexpressWords(String express){
List<String> list= new ArrayList<>();
if (express!=null&&express.length()!=0){
matchs(root,express,0,list);
}
return list;
}
/**
*
* @param node
* @param express
* @param index
* @param list
* @return
*/
private void matchs(Node node, String express, int index, List<String> list) {
//递归到底
if (express.length()==index){
//查找
findwords(node,list);
return ;
}
//递归操作
char c = express.charAt(index);
if (c != '.') {
Map<Character, Node> children = node.next;
if (!children.keySet().contains(c)) {
return;
}
matchs(children.get(c), express, index + 1,list);
} else {
Map<Character, Node> children = node.next;
Set<Character> set = children.keySet();
for (Character chr : set
) {
matchs(children.get(chr), express, index + 1,list);
}
}
}
//递归操作 获取单词
private void findwords(Node node, List<String> list) {
if (node.isWord){
list.add(node.val);
}
//递归到底
if (node.next.size()==0){
return;
}
Map<Character, Node> map =node.next;
Set<Character> keys =map.keySet();
for (Character key: keys
) {
findwords(map.get(key),list);
}
}
//删除单词
public void deleteWord(String word){
if (word==null&&word.length()==0){
throw new IllegalArgumentException("word is vaild");
}
Node cur =root;
Node multiNode =null; //单词分叉的节点
int mulitIndex =-1;//单词分叉的索引
for (int i = 0; i < word.length(); i++) {
char c= word.charAt(i);//取到每一个符号
Map<Character ,Node> children = cur.next;
if (!children.containsKey(c)){
return;
}else {
Node node =children.get(c);
if (node.next.size()>1||node.next.size()==1&&node.isWord){
multiNode=node;
mulitIndex=i;
}
cur=node;
}
}
//真正删除 分为三种形式
if (cur.isWord){ //判断是单词的话,进行下面的操作
//如果要删除的单词是不删除单词的前缀(pan是panda的前缀),则把节点设置为false
if (cur.next.size()>0){
cur.isWord=false;
//当单词分叉的节点为空,这说明这个单词整个删除
}else if (multiNode==null){
this.root.next.remove(word.charAt(0));
//两个单词要删除单词和不删除单词公用前缀(dog 和 door 公用do),则删除节点下一个元素
}else {
multiNode.next.remove(word.charAt(mulitIndex+1));
}
this.size+=1;
}
}
}















 305
305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









