






相关知识
在文本聚类时,可以以文档中词为中心,抽取一篇文档中比较有代表性的词项作为文档的特征项,把文档中出现相同的词聚为一类。 一个文档的关键词是这样的词:其在本文档内出现频率较高,而在其他文档的出现频率较低,具体可以通过TF-IDF技术抽取文档中的关键字。 为了完成本关任务,你需要掌握:1.如何计算词频(TF);2.如何计算逆文档频率(IDF);3.如何计算TF-IDF。
词频(TF)的计算
词频(TF)**指的是某一个给定的词语在该文件中出现的次数**。这个数字通常会被正规化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否)

逆文档频率(IDF)的计算
逆文档频率(IDF)是一个词语普遍重要性的度量,它的主要思想是如果包含给定词语的文档越少,那么IDF的值就会越大,则说明该词具有很好的类别区分能力。
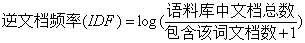
注:此处分母+1是为了避免当所有文档都不包含该词时,分母为0的情况。
TF-IDF的计算
TF-IDF随着词在文档中出现的次数成正比增加,但同时会随着该词在语料库中出现的频率成反比下降。某一特定文档内的高词语频率,以及该词语在整个文档集合中的低文档频率,可以产生出高权重的TF-IDF。因此,**TF-IDF倾向于过滤掉常见的词语,保留重要的词语**。
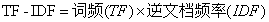
编程要求
本次编程的任务是: 根据提示,在右侧编辑器补充代码,实现计算TF-IDF的计算。 初始数据集如下所示:
my dog not has flea problems helpmaybe not my take him to dogmaybe my dalmation is so cute I love himmaybe not stop posting stupid worthless garbagemy licks ate my steak how to stop himquit buying worthless dog food
共有四处TF-IDF计算的关键代码需要补全,分别是: 1.每个词的词频计算:通过循环并根据上文给出的词频(TF)计算公式计算出每个词的词频(TF)word_tf[i],其中某个词在文档中的出现次数为doc_frequency[i],文档总词数为sum(doc_frequency.values());
2.总文档数的计算:总文档数doc_num可由list_words的长度len()求得;
3.每个词的逆文档频率计算:通过循环和if判断计算出每个词所对应的包含该词的文档数word_doc[i],再根据上文给出的公式计算出每个词的逆文档频率(IDF)word_idf[i],其中对数函数为math.log();
4.每个词的TF-IDF计算:将之前求得的词频(TF)值与其对应的逆文档频率(IDF)值相乘计算出每个词的T
from collections import defaultdict
import math
import operator
def loadDataSet():
lines_set = open('tf-idf.txt').readlines()
dataset = []
for line in lines_set:
data = line.strip().split()
dataset.append(data)
return dataset
"""
函数说明:特征选择TF-IDF算法
Parameters:
list_words:词列表
Returns:
dict_feature_select:特征选择词字典
"""
def feature_select(list_words):
# 总词频统计
count=0
doc_frequency = defaultdict(int) #字典
for word_list in list_words:
for i in word_list:
doc_frequency[i] += 1 #每个词出现的个数
count+=1
# 计算每个词的TF值
word_tf = {} # 存储每个词的tf值
#请补充代码,计算每个词的TF值
#********** Begin **********#
for i in doc_frequency:
word_tf[i]=doc_frequency[i]/sum(doc_frequency.values())
#********** End **********#
# 计算每个词的IDF值
#请补充代码,计算总文档数
#********** Begin **********#
doc_num=len(list_words)
#********** End **********#
word_idf = {} # 存储每个词的idf值
word_doc = defaultdict(int) # 存储包含该词的文档数
#请补充代码,计算每个词的IDF值
#********** Begin **********#
for i in doc_frequency:
for j in list_words:
if i in j:
word_doc[i]+=1
for i in doc_frequency:
word_idf[i]=math.log(doc_num/(word_doc[i]+1))
#********** End **********#
# 计算每个词的TF*IDF的值
word_tf_idf = {}
#请补充代码,计算每个词的TF-IDF值
#********** Begin **********#
for i in doc_frequency:
word_tf_idf[i]=word_tf[i]*word_idf[i]
#********** End **********#
# 对字典按值由大到小排序
dict_feature_select = sorted(word_tf_idf.items(), key=operator.itemgetter(1), reverse=True)
return dict_feature_select
if __name__== '__main__':
data_list = loadDataSet() # 加载数据
features = feature_select(data_list) # 所有词的TF-IDF值
print(features)
F-IDF值并通过循环存入word_tf_idf[i]。















 6486
6486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









