






1. 集合框架概述
1.1 集合使用场景
1.2 集合与数组的区别
数组的特点:
-
数组一旦初始化,其长度就是确定的
-
数组中的多个元素是依次紧密排列的,有序的,可重复的
-
数组一旦初始化完成,其元素类型就是确定的,不是此类型的元素,就不能加到数组中,安全
int[ ] arr = new int[ ];
arr[0] = 1;
arr[1] = “AA”;//编译报错
-
元素的类型既可以是基本数据类型,也可以是引用数据类型
Object [ ] arr1 = new Object[10];
arr1[0] = new String( );
arr1[1] = new Date( );
数组的弊端:
- 数组初始化之后,长度不可变,不便于扩展
- 数组中存储的数据特点的单一性。不适合无序的、不可重复的场景
- 数组中可用的方法、属性很少,具体需求需要自己组织代码逻辑
- 针对数组中的元素删除、插入操作,性能较差
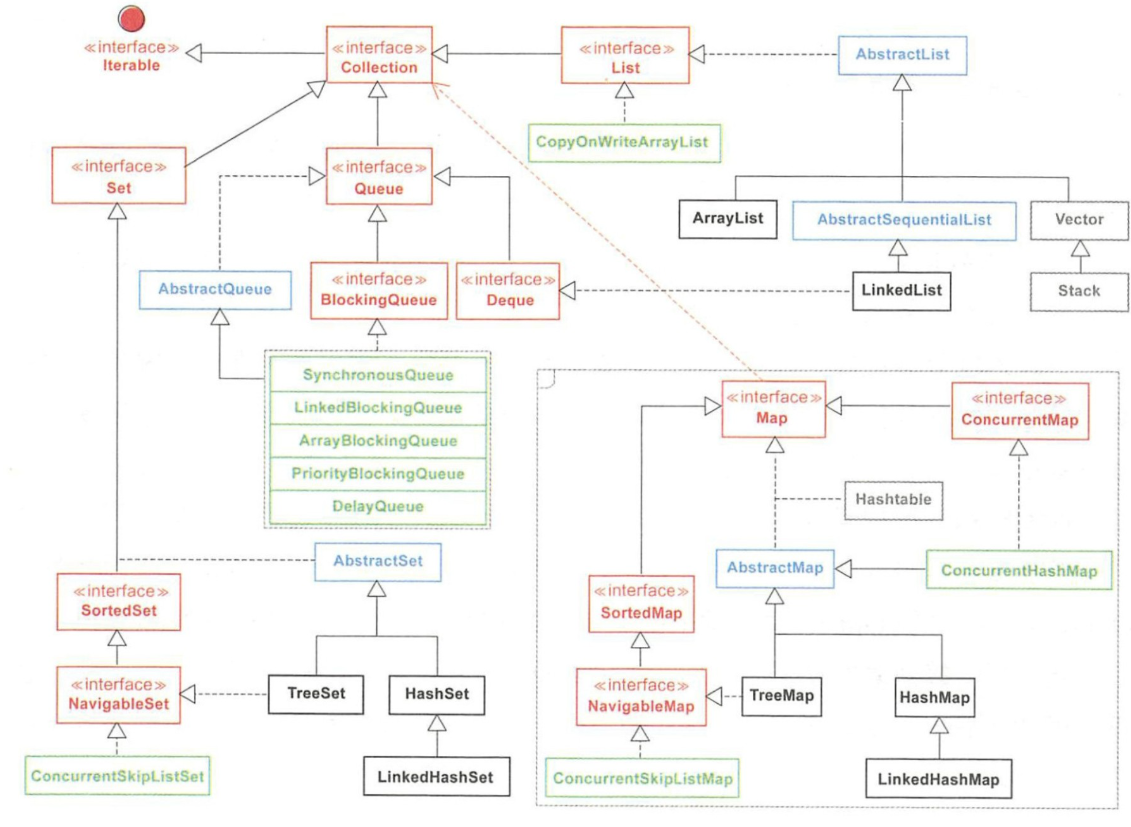
1.3 Java集合框架体系(java.util包下)
java.util.Collection:存储一个一个的数据
-
子接口List:存储有序的、可重复的数据(看做动态数组)
ArrayList、LinkedList、Vector
-
子接口Set:存储无序的、不可重复的数据 eg:订单(类似于高中的集合)
HashSet、LinkedHashSet、TreeSet
java.util.Map:存储一对一对的数据(key-value键值对类型的数据,类似于函数的映射)
- HashMap、LinkedHashMap、TreeMap、Hashtable、Properties
集合类关系图
2. Collection接口
2.1 简介
- Collection 接口是 List、 Set 和 Queue 接口的父接口,该接口里定义的方法既可用于操作 Set 集合,也可用于操作 List 和 Queue 集合。
- JDK不提供此接口的任何直接实现,而是提供更具体的子接口(如: Set和List)实现。
- 在 Java5 之前, Java 集合会丢失容器中所有对象的数据类型,把所有对象都当成 Object 类型处理; 从 JDK 5.0 增加了泛型以后, Java 集合可以记住容器中对象的数据类型。
2.1 接口方法

Test
package learn.k_collection;
import org.junit.Test;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
import java.util.List;
public class Collect {
@Test
public void test1() {
Collection c1 = new ArrayList();
//添加元素
c1.add("hello");
c1.add("world");
c1.add("tom");
c1.add("jarray");
c1.add(123); //自动装箱int->Integer
c1.add(456);
//添加自定义对象
c1.add(new User("马云", 45));
c1.add(new User("马化腾", 35));
//删除对象
c1.remove("tom");
// c1.clear(); //清空
System.out.println("isEmpty = " + c1.isEmpty());
String s1 = new String("hello");
User user=new User();
user.s="hello";
System.out.println("contains = " + c1.contains(s1)); //true,比较内容
System.out.println("contains = " + c1.contains("hello"));
System.out.println("contains = " + c1.contains(user.s));
System.out.println();
System.out.println(c1);
}
@Test
public void test2() {
Collection c1 = new ArrayList();
//添加元素
c1.add("hello");
c1.add("world");
c1.add("tom");
c1.add("jarray");
c1.add(123); //自动装箱int->Integer
c1.add(456);
//添加自定义对象
c1.add(new User("马云", 45));
c1.add(new User("马化腾", 35));
//添加自定义对象
User u1 = new User("马云", 45);
User u2 = new User("马云", 45);
User u3 = new User("马云", 45);
c1.add(u1);
c1.add(u2);
c1.add(new User("马化腾", 35));
System.out.println(c1.size());
System.out.println("contains马云 = " + c1.contains(u3)); //调用equals,比较内容,返回true
// Iterator it = c1.iterator();
//
// Object obj = it.next();
// System.out.println(obj);
//
// obj = it.next();
// System.out.println(obj);
/* //iterator循环集合
Iterator it = c1.iterator();
while (it.hasNext()) {
Object obj = it.next();
System.out.println(obj);
}*/
}
@Test
public void test3() {
Collection c1 = new ArrayList();
//添加元素
c1.add("hello");
c1.add("world");
c1.add("tom");
c1.add("jarray");
c1.add(123); //自动装箱int->Integer
c1.add(456);
//添加自定义对象
c1.add(new User("马云", 45));
c1.add(new User("马化腾", 35));
//collection没有get方法,不能用c2.fori
for (Object obj : c1) {
System.out.println(obj);
}
//idea的模板 ctrl + j显示所有的模板
//iter:增强for循环的模板
List c2 = new ArrayList();
c2.add("a");
c2.add("b");
c2.add(1);
c2.add(3);
c2.add(2);
//iter
for (Object o : c2) {
System.out.println(o);
}
//itar
// FIXME: 2023/8/7 这里有个错误,回头改
// TODO: 2023/8/7 这里有个bug,回头改
for (int i = 0; i < c2.size(); i++) {
System.out.println(c2.get(i));
}
}
}
package learn.k_collection;
public class User {
private String name;
private int age;
public String s;
public User() {
}
public User(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public boolean equals(Object o) {
System.out.println("User equals()....");
// return super.equals(o);
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
if (age != user.age) return false;
return name != null ? name.equals(user.name) : user.name == name;
}
}
sgg:
package sgg.collection.a_collection;
import org.junit.Test;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collection;
public class CollectionTest {
@Test
public void Test() {
Collection coll = new ArrayList();
//add()
coll.add("AA");
coll.add(123);//集合存引用数据类型,int自动装箱int->Integer
coll.add(128);
coll.add("我是天才");
coll.add(new Object());
coll.add(new Person("Tom", 12));
//output:[AA, 123, 128, 我是天才, java.lang.Object@ba8a1dc, Person{name='Tom', age=12}]
System.out.println(coll);
//addAll()
Collection coll1 = new ArrayList();
coll1.add("bb");
//coll1.add(coll);
//output:[bb, [AA, 123, 128, 我是天才, java.lang.Object@ba8a1dc, Person{name='Tom', age=12}]]
coll1.addAll(coll);
//output:[bb, AA, 123, 128, 我是天才, java.lang.Object@ba8a1dc, Person{name='Tom', age=12}]
System.out.println(coll1);
//output:6
System.out.println(coll.size());
//isEmpty
//output:false
System.out.println(coll.isEmpty());
}
@Test
public void test2() {
Collection coll = new ArrayList();
coll.add("AA");
coll.add(123);//集合存引用数据类型,int自动装箱int->Integer
coll.add(128);
coll.add("我是天才");
Person p1 = new Person("Tom", 12);
coll.add(new Person("Tom", 12));
//contains()
//遍历集合中的每个元素,并逐个使用equals方法来比较目标元素和集合中的元素是否相等
System.out.println(coll.contains("AA"));//true 比较内容 调用String中重写的equals方法
System.out.println(coll.contains(128));//true 比较内容 调用Integer中重写的equals方法
System.out.println(coll.contains(p1));//自定义的类中并没有重写equals方法,调用Object中的equals比较地址,结果为false;
// 在Person中重写后比较内容,结果为true
System.out.println(coll.contains(new Person("Tom", 12)));
//containsAll() 是不是真子集
Collection coll1 = new ArrayList();
coll1.add("AA");
coll1.add(128);
//output:true
System.out.println(coll.containsAll(coll1));
coll1.add(8888);
//output:false
System.out.println(coll.containsAll(coll1));
//boolean equals(Object obj) 判断当前集合与obj是否相等
}
@Test
public void test3() {
Collection coll = new ArrayList();
coll.add("AA");
coll.add("AA");
Person p1 = new Person("Tom", 12);
coll.add(128);
coll.add(new String("我是天才"));
/*coll.clear();//不是直接把size改为0,而是逐个删除,避免内存泄露
System.out.println(coll);//[]
System.out.println(coll.size());//0,并不是空指针*/
//remove()
coll.remove(new Person("Tom", 12));
coll.remove("AA");//只删除一个,找到第一个并删除,然后停止
/*
* person中重写的equals方法
person中重写的equals方法
person中重写的equals方法
person中重写的equals方法
[AA, 128, 我是天才]
* */
System.out.println(coll);
//removeAll() 从当前集合中删除所有与coll集合中相同的元素(取差集)
//retainAll() 从当前集合中删除两个集合中不同的元素,使得当前集合仅保留相同元素(取交集)
}
@Test
public void test4() {
Collection coll = new ArrayList();
coll.add("AA");
coll.add("AA");
Person p1 = new Person("Tom", 12);
coll.add(p1);
coll.add(128);
coll.add(new String("我是天才"));
//集合-->数组
//toArray()
Object[] arr=coll.toArray();
//[AA, AA, Person{name='Tom', age=12}, 128, 我是天才]
System.out.println(Arrays.toString(arr));
}
@Test
public void test5(){
//把数组转成集合
String[] arr = new String[]{"AA","BB","CC"};
//Collection list=Arrays.asList(arr);
List list=Arrays.asList(arr);
//[AA, BB, CC]
System.out.println(list);
}
}
package sgg.collection.a_collection;
import java.util.Objects;
public class Person {
String name;
int age;
public Person() {
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public boolean equals(Object o) {
System.out.println("person中重写的equals方法");
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return age == person.age && Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
注意
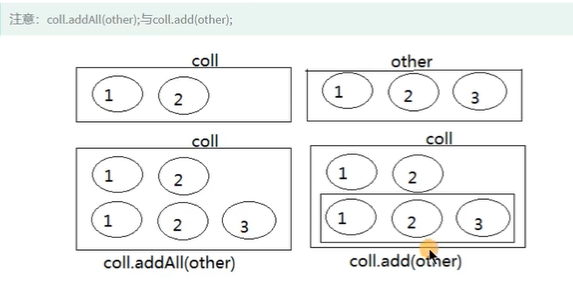
- addAll与add
- remove与contains都调用了equals

2.3 集合与数组的相互转化
- 集合转成数组
@Test
public void test4() {
Collection coll = new ArrayList();
coll.add("AA");
coll.add("AA");
Person p1 = new Person("Tom", 12);
coll.add(p1);
coll.add(128);
coll.add(new String("我是天才"));
//集合-->数组
//toArray()
Object[] arr=coll.toArray();
//[AA, AA, Person{name='Tom', age=12}, 128, 我是天才]
System.out.println(Arrays.toString(arr));
}
- 数组转成集合
@Test
public void test5(){
//把数组转成集合
String[] arr = new String[]{"AA","BB","CC"};
//Collection list=Arrays.asList(arr);
List list=Arrays.asList(arr);
//[AA, BB, CC]
System.out.println(list);
}
List list=Arrays.asList(1,2,3);
@Test
public void test6(){
//数组-->集合:调用Arrays的静态方法asList(Object ... objs)
//asList参数只能是对象
//所以Integer相当于放了三个对象,自动装箱之后的元素
Integer[] arr = new Integer[]{1,2,3};
//Collection list=Arrays.asList(arr);
List list=Arrays.asList(arr);
System.out.println(list);//[1,2,3]
System.out.println(list.size());//3
//int为基本数据类型,把int类型的一维数组看做一整个对象
int[] arr1 = new int[]{1,2,3};
//Collection list=Arrays.asList(arr);
List list1=Arrays.asList(arr1);
System.out.println(list1);//[[I@ba8a1dc]
System.out.println(list1.size());//1
}
2.4 遍历集合的四种方法
不同的遍历方法的示例代码:使用迭代器、for-each循环、索引以及某些语言中的forEach()方法。
- 使用迭代器:
import java.util.ArrayList;
import java.util.Iterator;
public class Main {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("Apple");
list.add("Banana");
list.add("Orange");
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String element = iterator.next();
System.out.println(element);
}
}
}
- 使用for-each循环:
import java.util.ArrayList;
public class Main {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("Apple");
list.add("Banana");
list.add("Orange");
for (String element : list) {
System.out.println(element);
}
}
}
- 使用索引:
import java.util.ArrayList;
public class Main {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("Apple");
list.add("Banana");
list.add("Orange");
for (int i = 0; i < list.size(); i++) {
String element = list.get(i);
System.out.println(element);
}
}
}
- 使用forEach()方法(某些编程语言可能提供这个方法):
import java.util.ArrayList;
public class Main {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("Apple");
list.add("Banana");
list.add("Orange");
list.forEach(element -> {
System.out.println(element);
});
}
}
2.5 判断元素是否存在于集合中的三种方法
当需要判断一个元素是否存在于集合中时,可以使用以下几种方式进行比较:
- 使用contains()方法:
import java.util.ArrayList;
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>(Arrays.asList("Apple", "Banana", "Orange"));
String element = "Apple";
boolean containsElement = list.contains(element);
if (containsElement) {
System.out.println(element + " is present in the list.");
} else {
System.out.println(element + " is not present in the list.");
}
}
}
- 使用indexOf()方法:
import java.util.ArrayList;
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>(Arrays.asList("Apple", "Banana", "Orange"));
String element = "Apple";
int index = list.indexOf(element);
if (index != -1) {
System.out.println(element + " is present in the list.");
} else {
System.out.println(element + " is not present in the list.");
}
}
}
- 使用循环遍历集合并逐个比较元素:
import java.util.ArrayList;
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>(Arrays.asList("Apple", "Banana", "Orange"));
String element = "Apple";
boolean containsElement = false;
for (String str : list) {
if (str.equals(element)) {
containsElement = true;
break;
}
}
if (containsElement) {
System.out.println(element + " is present in the list.");
} else {
System.out.println(element + " is not present in the list.");
}
}
}
3. Iterator迭代器接口
简介
- Iterator对象称为迭代器(设计模式的一种),主要用于遍历 Collection 集合中的元素。
- GOF给迭代器模式的定义为:提供一种方法访问一个容器(container)对象中各个元素,而又不需暴露该对象的内部细节。 迭代器模式,就是为容器而生。 类似于“公交车上的售票员”、“火车上的乘务员”、 “空姐” 。
- Collection接口继承了java.lang.Iterable接口,该接口有一个iterator()方法,那么所有实现了Collection接口的集合类都有一个iterator()方法,用以返回一个实现了Iterator接口的对象。
- Iterator 仅用于遍历集合, Iterator 本身并不提供承装对象的能力。如果需要创建Iterator 对象,则必须有一个被迭代的集合。
- 集合对象每次调用iterator()方法都得到一个全新的迭代器对象,默认游标都在集合的第一个元素之前。


案例
@Test
public void test2() {
Collection c1 = new ArrayList();
//添加元素
c1.add("hello");
c1.add("world");
c1.add("tom");
c1.add("jarray");
c1.add(123); //自动装箱int->Integer
c1.add(456);
//添加自定义对象
c1.add(new User("马云", 45));
c1.add(new User("马化腾", 35));
//添加自定义对象
User u1 = new User("马云", 45);
User u2 = new User("马云", 45);
User u3 = new User("马云", 45);
c1.add(u1);
c1.add(u2);
c1.add(new User("马化腾", 35));
System.out.println(c1.size());
System.out.println("contains马云 = " + c1.contains(u3)); //调用equals,比较内容,返回true
// Iterator it = c1.iterator();
//
// Object obj = it.next();
// System.out.println(obj);
//
// obj = it.next();
// System.out.println(obj);
//iterator循环集合
Iterator it = c1.iterator();
while (it.hasNext()) {
Object obj = it.next();
System.out.println(obj);
}
}
11
User equals()....
User equals()....
User equals()....
User equals()....
User equals()....
User equals()....
User equals()....
contains马云 = true
hello
world
tom
jarray
123
456
User{name='马云', age=45}
User{name='马化腾', age=35}
User{name='马云', age=45}
User{name='马云', age=45}
User{name='马化腾', age=35}
@Test
public void test3() {
Collection c1 = new ArrayList();
//添加元素
c1.add("hello");
c1.add("world");
c1.add("tom");
c1.add("jarray");
c1.add(123); //自动装箱int->Integer
c1.add(456);
//添加自定义对象
c1.add(new User("马云", 45));
c1.add(new User("马化腾", 35));
for (Object obj : c1) {
System.out.println(obj);
}
//idea的模板 ctrl + j显示所有的模板
//iter:增强for循环的模板
List c2 = new ArrayList();
c2.add("a");
c2.add("b");
c2.add(1);
c2.add(3);
c2.add(2);
//iter
/**
* 增强for循环,底层是Iterator循环
*/
for (Object o : c2) {
System.out.println(o);
}
System.out.println("-----");
//itar
// FIXME: 2023/8/7 这里有个错误,回头改
// TODO: 2023/8/7 这里有个bug,回头改
for (int i = 0; i < c2.size(); i++) {
System.out.println(c2.get(i));
}
System.out.println("--------");
Iterator iterator= c2.iterator();
for (int i=0;i<c2.size();i++){
System.out.println(iterator.next());
}
}
hello
world
tom
jarray
123
456
User{name='马云', age=45}
User{name='马化腾', age=35}
a
b
1
3
2
-----
a
b
1
3
2
--------
a
b
1
3
2

增强for循环

使用增强for循环修改数组内元素是错误的。增强for循环是将集合或数组中的元素依次赋值给临时变量。注意:循环体中对临时变量的修改不会导致原集合中内容修改。
因为:
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
没有用泛型的迭代器使用
@Test
public void test2() {
Collection c1 = new ArrayList();
//添加元素
c1.add("hello");
c1.add("world");
c1.add("tom");
c1.add("jarray");
c1.add(123); //自动装箱int->Integer
c1.add(456);
//添加自定义对象
c1.add(new User("马云", 45));
c1.add(new User("马化腾", 35));
//添加自定义对象
User u1 = new User("马云", 45);
User u2 = new User("马云", 45);
User u3 = new User("马云", 45);
c1.add(u1);
c1.add(u2);
c1.add(new User("马化腾", 35));
System.out.println(c1.size());
System.out.println("contains马云 = " + c1.contains(u3)); //调用equals,比较内容,返回true
//iterator循环集合
//方式1
Iterator it = c1.iterator();
while (it.hasNext()) {//检查迭代器是否还有下一个元素
Object obj = it.next();//未指定泛型,类型不统一,全部转换为Object,然后it.next()获取下一个元素
/*
在使用it.next()之前,一定要先调用it.hasNext()来确保迭代器还有下一个元素可供获取。否则,如果没有更多元素可供遍历,再调用it.next()会抛出NoSuchElementException异常
*/
/*可以在循环中加入判断条件实现指定删除元素的操作
if ("tom".equals(obj)) {
it.remove();
}
*/
System.out.println(obj);
}
//方式2
//混合使用了迭代器和索引的方式,使用size()来确定循环次数
Iterator iterator= c2.iterator();
for (int i=0;i<c2.size();i++){
System.out.println(iterator.next());
}
}
用了泛型的迭代器使用
@Test
public void test2() {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
//迭代器循环
Iterator<Integer> it = list.iterator();//指定泛型
while (it.hasNext()) {
Integer i = it.next();//指定泛型,保证类型一致,不用强制类型转换
System.out.println(i);
}
}
注意
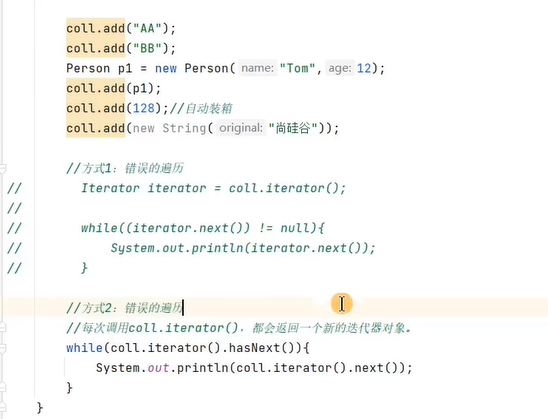
/*
错误:每次循环都新建一个迭代器对象,而不是重复使用一个迭代器。
这样会导致每个迭代器从集合起始位置开始遍历,而不是接着上一个
迭代器离开的位置进行遍历,从而一直读取并输出集合的第一个元素
while (list.iterator().hasNext()){
System.out.println(list.iterator().next());
}*/
/*
* 为了解决这个问题,应该首先获取迭代器对象,并将其存储在一个
* 变量中,然后在循环中重复使用迭代器对象,保证按照集合的顺序
* 逐个遍历并打印
* Iterator it = list.iterator();
while (it.hasNext()){
System.out.println(it.next());
}
* */
4. List接口
- 简介
- 鉴于java中数组用来存储数据的局限性,通常用list替代数组
- List集合类中元素有序、且可重复,集合中的每个元素都有其对应的顺序索引
- List容器中的元素都对应一个整数型的序号记载其容器中的位置,可以根据序号存取容器中的元素。
- JDK API中List接口的实现类常用的有:ArrayList、LinkedList 和 Vector
- List接口方法
List除了从Collection集合继承的方法外,List集合里添加了一些根据索引来操作集合元素的方法
- void add(int index,Object ele): 在index位置插入ele元素
- **boolean addAll(int index, Collection eles)😗*从index位置开始将eles中的所有元素添加进来
- Object get(int index):获取指定index位置的元素
- **int indexOf(Object obj)😗*返回obj在集合中首次出现的位置
- **int lastIndexOf(Object obj)😗*返回obj在当前集合中末次出现的位置
- **Object remove(int index)😗*移除指定index位置的元素,并返回此元素
- **Object set(int index, Object ele)😗*设置指定index位置的元素为ele
- **List subList(int fromIndex, int toIndex)😗*返回从from Index到to Index位置的子集合
@Test
public void test1() {
List list = new ArrayList();
list.add("aaa");
list.add("bbb");
list.add("aaa");
list.add("aaa");
list.add(0, 111);
list.add(0, 222);
list.add(0, 333);
System.out.println(list);
//get(从0开始数)
System.out.println(list.get(3));
//indexOf(从0开始数)
System.out.println(list.indexOf("aaa"));
System.out.println(list.lastIndexOf("aaa"));
//remove
list.remove(0);
list.remove("aaa");//移除第一个之后就不执行了
System.out.println(list);
System.out.println(list.subList(0, 3));
}
[333, 222, 111, aaa, bbb, aaa, aaa]
aaa
3
6
[222, 111, bbb, aaa, aaa]
[222, 111, bbb]
sgg:
4.1 ArrayList
ArrayList是容量可以改变的非线程安全集合。内部实现使用数组进行存储,集合扩容时会创建更大的数组空间,把原有数据复制到新数组中。ArrayList支持对元素的快速随机访问,但是插入与删除时的速度通常很慢,因为这个过程有可能要移动其他元素 遍历快,删插慢
超过10之后每次扩容1.5倍
-
ArrayList是List接口的典型实现类、主要实现类
-
本质上,ArrayList是对象引用的一个变长数组

-
ArrayList的JDK1.8之前与之后的实现区别
- JDK1.7:ArrayList像饿汉式,直接创建一个初始容量为10的数组
- JDK1.8:ArrayList像懒汉式,一开始创建一个长度为0的数组,当添加第一个元素时在创建一个初始容量为10的数组
-
Arrays.asList()方法返回List集合,既不是ArrayList实例也不是Vector实例。(数组转集合,见2.3)
-
Arrays.asList()返回值是一个固定长度的List集合
案例
/**
* 1. 有序:插入顺序
* 2. 允许重复
* 3. 底层是数组,默认大小10,每次扩容1.5倍
* - jdk1.7:默认大小10
* - jdk1.8 默认大小0,第一次使用时初始化成10
* 4:添加和删除,性能差,随机遍历性能好
*/
@Test
public void test2() {
List list = new ArrayList();
list.add("ccc");
list.add("ccc");
list.add("bbb");
list.add("aaa");
User u1 = new User("马云", 45);
User u2 = new User("马化腾", 38);
list.add(u1);
list.add(u1);
list.add(u2);
//方式1
for (Object o : list) {
System.out.println(o);
}
System.out.println("-------------");
//方式2
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
System.out.println("-------------");
//方式3 itco
for (Iterator iterator = list.iterator(); iterator.hasNext(); ) {
Object obj = iterator.next();
System.out.println(obj);
}
}
ccc
ccc
bbb
aaa
User{name='马云', age=45}
User{name='马云', age=45}
User{name='马化腾', age=38}
-------------
ccc
ccc
bbb
aaa
User{name='马云', age=45}
User{name='马云', age=45}
User{name='马化腾', age=38}
-------------
ccc
ccc
bbb
aaa
User{name='马云', age=45}
User{name='马云', age=45}
User{name='马化腾', age=38}
4.2 LinkedList
LinkedList 的本质是双向链表。与 Array List 相比 , **LinkedList 的插入和删 除速度更快,但是随机访问速度很慢。**测试表明,对于 IO 万条的数据,与 ArrayList 相比,随机提取元素时存在数百倍的差距。除继承 AbstractList 抽象类外, LinkedList 还实现了另一个接口 Deque ,即 double-ended queue。这个接口同时具有队列和枝的性质。LinkedList 包含 3 个重要的成员 size 、first、 last 。 size 是双向链表中节点的个数。first 和 last 分别指向第一个和最后一个节点的引用。 LinkedList 的优点在于可以将零散的内存单元通过附加引用的方式关联起来,形成按链路顺序序查找的线性结构,内存利用率较高。
新增方法:
- void addFirst(Object obj)
- void addLast(Object obj)
- Object getFirst()
- Object getLast()
- Object removeFirst()
- Object removeLast()
LinkedList: 双向链表, 内部没有声明数组,而是定义了Node类型的first和last,用于记录首末元素。同时,定义内部类Node,作为LinkedList中保存数据的基本结构。 Node除了保存数据,还定义了两个变量:
- prev变量记录前一个元素的位置
- next变量记录下一个元素的位置
案例
/**
* 1. 底层原理:基于双向链表实现
* 2. 插入和删除快,遍历性能差
* 3. 可以直接操作头和尾
* 4. 有序(插入顺序),容许重复
*/
@Test
public void test3() {
LinkedList list = new LinkedList();
list.add("ccc");
list.add("ccc");
list.add("bbb");
list.add("aaa");
User u1 = new User("马云", 45);
User u2 = new User("马化腾", 38);
list.add(u1);
list.add(u1);
list.add(u2);
list.addFirst("1111");
list.addLast("2222");
System.out.println(list.getLast());
System.out.println("-------");
//方式1
for (Object o : list) {
System.out.println(o);
}
}
2222
-------
1111
ccc
ccc
bbb
aaa
User{name='马云', age=45}
User{name='马云', age=45}
User{name='马化腾', age=38}
2222
问题1:调试时F7不能进入源码
问题2:调试不能看到集合中的成员变量

问题3:调试时,不能查看静态和常量
问题4:为什么使用集合要指定initialCapacity,如果不确定容量可以指定集合的初始容量
List list = new ArrayList();
#比如List集合存储一页查询的结果数据(20行数据)
List list = new ArrayList(20);
4.3 Vector
-
Vector 是一个古老的集合, JDK1.0就有了。大多数操作与ArrayList相同,区别之处在于Vector是线程安全的。
-
在各种list中,最好把ArrayList作为缺省选择。当插入、删除频繁时,使用LinkedList; Vector总是比ArrayList慢,所以尽量避免使用。
-
新增方法:
-
- void addElement(Object obj)
- void insertElementAt(Object obj,int index)
- void setElementAt(Object obj,int index)
- void removeElement(Object obj)
- void removeAllElements()
面试题:请问ArrayList/LinkedList/Vector的异同? 谈谈你的理解? ArrayList底层是什么?扩容机制? Vector和ArrayList的最大区别?
- ArrayList和LinkedList二者线程不安全,相对线程安全的Vector,执行效率高。此外, ArrayList是实现了基于动态数组的数据结构, LinkedList基于链表的数据结构。对于随机访问get和set, ArrayList觉得优于LinkedList,因为LinkedList要移动指针。对于新增和删除操作add(特指插入)和remove, LinkedList比较占优势,因为ArrayList要移动数据。
- ArrayList和Vector的区别Vector和ArrayList几乎是完全相同的,唯一的区别在于Vector是同步类(synchronized),属于强同步类。因此开销就比ArrayList要大,访问要慢。正常情况下,大多数的Java程序员使用ArrayList而不是Vector,因为同步完全可以由程序员自己来控制。 Vector每次扩容请求其大小的2倍空间,而ArrayList是1.5倍。 Vector还有一个子类Stack。
5. Set接口
Set 是不允许出现重复元素的集合类型。 Set 体系最常用的是 Hash Set 、 TreeSet和 LinkedHashSet 三个集合类。 HashSet 从源码分析是使用 HashMap 来实现的,只是Value 固定为一个静态对象,使用 Key 保证集合元素的唯 性,但它不保证集合元素的顺序。 TreeSet 也是如此,从源码分析是使用 TreeMap 来实现的,底层为树结构,在添加新元素到集合中时,按照某种比较规则将其插入合适的位置 ,保证插入后的集合仍然是有序的。 LinkedHashSet 继承自 HashSet , 具有 HashSet 的优点,内部使用链表维护了元素插入顺序。
5.1 HashSet
- 简介
-
HashSet 是 Set 接口的典型实现,大多数时候使用 Set 集合时都使用这个实现类。
-
HashSet 按 Hash 算法来存储集合中的元素,因此具有很好的存取、查找、删除性能。
-
HashSet 具有以下特点:
-
- 不能保证元素的排列顺序
- HashSet 不是线程安全的
- 集合元素可以是 null
案例 基本使用
/**
* HashSet基本使用
* 1. 无序
* 2. 没有重复
*/
@Test
public void test1() {
//按输入顺序
List list = new ArrayList();
list.add("ccc");
list.add("ccc");
list.add("bbb");
list.add("aaa");
list.add("aaa");
list.add("eee");
list.add("fff");
list.add("ggg");
list.add("hhh");
list.add("mmm");
System.out.println(list);
System.out.println("--------------");
//不保证顺序,不允许重复
Set set = new HashSet();
set.add("ccc");
set.add("ccc");
set.add("bbb");
set.add("aaa");
set.add("aaa");
set.add("aaa");
set.add("eee");
set.add("fff");
set.add("ggg");
set.add("hhh");
set.add("mmm");
System.out.println(set);
}
[ccc, ccc, bbb, aaa, aaa, eee, fff, ggg, hhh, mmm]
--------------
[aaa, ccc, bbb, eee, ggg, fff, hhh, mmm]
@Test
public void test2() {
Set set = new HashSet();
set.add("ccc");
set.add("ccc");
set.add("bbb");
set.add("aaa");
set.add("aaa");
set.add("aaa");
set.add("eee");
set.add("fff");
set.add("ggg");
set.add("hhh");
set.add("mmm");
System.out.println(set);
//方式1 增强for循环
for (Object o : set) {
System.out.println(o);
}
System.out.println("----------");
//方式2 Iterator
Iterator it = set.iterator();
while (it.hasNext()) {
Object obj = it.next();
System.out.println(obj);
}
}
[aaa, ccc, bbb, eee, ggg, fff, hhh, mmm]
aaa
ccc
bbb
eee
ggg
fff
hhh
mmm
----------
aaa
ccc
bbb
eee
ggg
fff
hhh
mmm
- 原理
- HashSet底层是HashMap实现的,只要用key,value存储一个静态的new Object

-
HashSet 集合判断两个元素相等的标准: 两个对象通过 hashCode() 方法比较相等,并且两个对象的 equals() 方法返回值也相等。
-
对于存放在Set容器中的对象, 对应的类一定要重写equals()和hashCode(Objectobj)方法,以实现对象相等规则。即: “相等的对象必须具有相等的散列码” 。
-
向HashSet中添加元素的过程:
-
- 当向 HashSet 集合中存入一个元素时, HashSet 会调用该对象的 hashCode() 方法来得到该对象的 hashCode 值, 然后根据 hashCode 值, 通过某种散列函数决定该对象在 HashSet 底层数组中的存储位置。 (这个散列函数会与底层数组的长度相计算得到在数组中的下标, 并且这种散列函数计算还尽可能保证能均匀存储元素, 越是散列分布,该散列函数设计的越好)
- 如果两个元素的hashCode()值相等, 会再继续调用equals方法, 如果equals方法结果为true, 添加失败; 如果为false, 那么会保存该元素, 但是该数组的位置已经有元素了,那么会通过链表的方式继续链接。
- 如果两个元素的 equals() 方法返回 true,但它们的 hashCode() 返回值不相等, hashSet 将会把它们存储在不同的位置,但依然可以添加成功。

//下面不同的字符串就有相同的hashCode
System.out.println("ABCDEa123abc".hashCode()); // 165374702
System.out.println("ABCDFB123abc".hashCode()); // 165374702
HashSet底层也是HashMap, 初始容量为16, 当如果使用率超过0.75, (16*0.75=12)就会扩大容量为原来的2倍。 (16扩容为32, 依次为64,128…等)
- 重写hashCode和equals原则
(1) hashCode
- 在程序运行时,同一个对象多次调用 hashCode() 方法应该返回相同的值。
- 当两个对象的 equals() 方法比较返回 true 时,这两个对象的 hashCode()方法的返回值也应相等。
- 对象中用作 equals() 方法比较的 Field,都应该用来计算 hashCode 值。
(2) equals
- 当一个类有自己特有的“逻辑相等”概念,当改写equals()的时候,总是要改写hashCode(),根据一个类的equals方法(改写后),两个截然不同的实例有可能在逻辑上是相等的,但是, 根据Object.hashCode()方法,它们仅仅是两个对象。
- 因此,违反了**“相等的对象必须具有相等的散列码”。**
- 结论:复写equals方法的时候一般都需要同时复写hashCode方法。 通常参与计算hashCode的对象的属性也应该参与到equals()中进行计算。
案例实现:
User.java
public class User {
private String name;
private int age;
public User() {
}
public User(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public boolean equals(Object o) {
System.out.println("User equals()....");
// return super.equals(o);
if (this == o) return true; //内存地址相同返回true
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
if (age != user.age) return false;
return name != null ? name.equals(user.name) : user.name == name;
}
/**
* * 注:**为什么hashCode中,用31这个数子?
* *
* * - 选择系数的时候要选择尽量大的系数。因为如果计算出来的hash地址越大,所谓的“冲突”就越少,查找起来效率也会提高。(减少冲突)
* * - 并且31只占用5bits,相乘造成数据溢出的概率较小。
* * - 31可以 由i*31== (i<<5)-1来表示,现在很多虚拟机里面都有做相关优化。 (提高算法效率)
* * - 31是一个素数,素数作用就是如果我用一个数字来乘以这个素数,那么最终出来的结果只能被素数本身和被乘数还有1来整除! (减少冲突)
* @return
*/
@Override
public int hashCode() { //return name.hashCode() + age;
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
}
测试代码
/**
* HashSet存入数据的过程
* 1. 得到对象的hashCode,hashCode%16,决定落到那个槽位(默认16个槽位)Entry[16]
* 2. 再次添加对象,如果对象的hashCode和第一次添加的相同,执行equals
* 3. 如果equals返回true,hashCode相同,equals相同,添加失败
* 4. 如果eques返回false,hashCode相同,形成一个链表
*/
@Test
public void test4() {
Set set = new HashSet();
User u1 = new User("马云", 45);
User u2 = new User("马云", 45);
User u3 = new User("马化腾", 40);
User u4 = new User("马化腾", 40);
User u5 = new User("奥巴马", 50);
User u6 = new User("马云", 45);
set.add(u1);
set.add(u2);
set.add(u3);
set.add(u4);
set.add(u5);
set.add(u6);
for (Object o : set) {
System.out.println(o);
}
}
User equals()....
User equals()....
User equals()....
User{name='奥巴马', age=50}
User{name='马云', age=45}
User{name='马化腾', age=40}
5.2 LinkedHashSet
- LinkedHashSet 是 HashSet 的子类
- LinkedHashSet 根据元素的 hashCode 值来决定元素的存储位置,但它同时使用双向链表维护元素的次序,这使得元素看起来是以插入顺序保存的。
- LinkedHashSet插入性能略低于 HashSet, 但在迭代访问 Set 里的全部元素时有很好的性能。
- LinkedHashSet 不允许集合元素重复。
- LinkedHashSet 底层结构
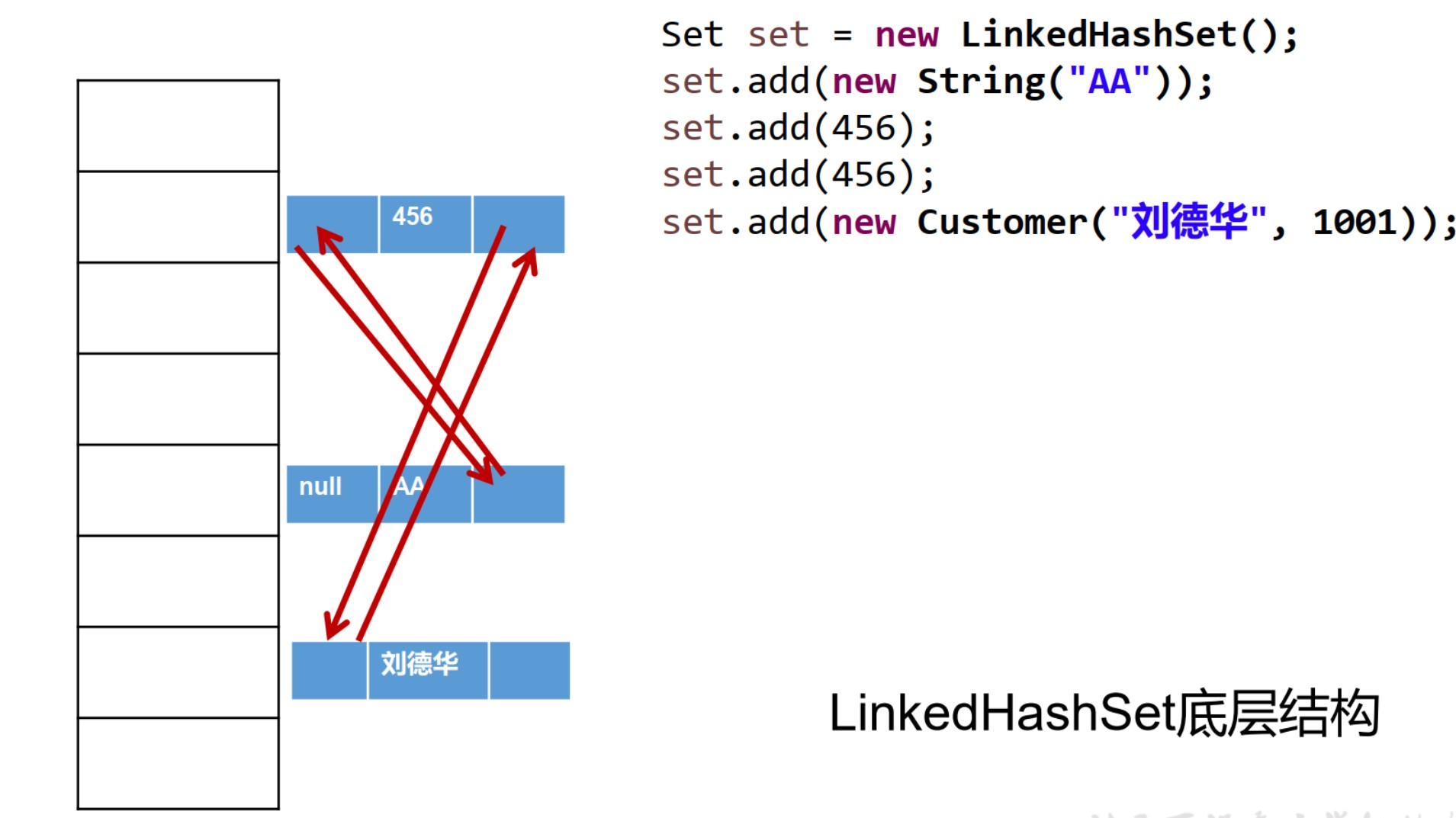
案例
public class LinkedHashSetDemo1 {
/**
* LinkedHashSet特点
* - 不能重复
* - 有序(跟插入顺序有关)
* - 双向链表
* @param args
*/
public static void main(String[] args) {
LinkedHashSet set = new LinkedHashSet();
set.add("zzz");
set.add("zzz");
set.add("zzz");
set.add("yyy");
set.add("yyy");
set.add("xxx");
set.add("xxx");
set.add("fff");
set.add("eee");
set.add("www");
set.add("111");
set.add("222");
set.add("333");
set.add("666");
set.add("555");
set.add("444");
for (Object o : set) {
System.out.println(o);
}
}
}
zzz
yyy
xxx
fff
eee
www
111
222
333
666
555
444
sgg:
- 是HashSet的子类:在现有数组+单向链表+红黑树结构的基础上,又添加了一组双向链表,用于记录添加元素的先后顺序,可以按照添加元素的顺序进行遍历,便于频繁的查询
5.3 TreeSet
- 简介:
-
TreeSet 是 SortedSet 接口的实现类, TreeSet 可以确保集合元素处于排序状态。
-
TreeSet的特点
-
- 有序(内容有序)
- 不能有重复
-
新增的方法如下: (了解)
-
- Comparator comparator():返回定制排序器
- Object first():返回此集合中当前的第一个(最低)元素。
- Object last():返回此集合中当前的最后一个(最高)元素。
- Object lower(Object e):返回此集合中的最大元素严格小于给定元素,如果没有这样的元素,则 null 。
- Object higher(Object e)
- SortedSet subSet(fromElement, toElement)
- SortedSet headSet(toElement)
- SortedSet tailSet(fromElement)
案例:
public class TreeSetDemo1 {
/**
* TreeSet的特点
* - 有序(通过内容排序),通过排序器Comparable进行排序
* - 不能重复
*/
@Test
public void test1() {
TreeSet set = new TreeSet();
set.add("zzz");
set.add("zzz");
set.add("zzz");
set.add("yyy");
set.add("yyy");
set.add("xxx");
set.add("xxx");
set.add("fff");
set.add("eee");
set.add("www");
set.add("111");
set.add("222");
set.add("333");
set.add("666");
set.add("555");
set.add("444");
//得到第一个
System.out.println(set.first());
//得到最后一个
System.out.println(set.last());
System.out.println("------------");
for (Object o : set) {
System.out.println(o);
}
}
}
111
zzz
------------
111
222
333
444
555
666
eee
fff
www
xxx
yyy
zzz
- TreeSet 两种排序方法: 自然排序和定制排序。默认情况下, TreeSet 采用自然排序。
- TreeSet底层使用红黑树结构存储数据,特点:有序,查询速度比List快
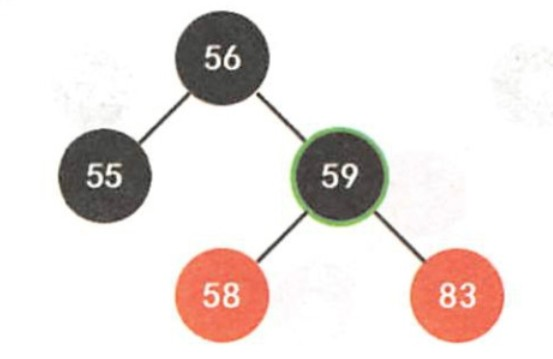
自然排序:
-
自然排序: TreeSet 会调用集合元素的 compareTo(Object obj) 方法来比较元素之间的大小关系,然后将集合元素按升序(默认情况)排列
-
如果试图把一个对象添加到 TreeSet 时,则该对象的类必须实现 Comparable接口。
-
实现 Comparable 的类必须实现 compareTo(Object obj) 方法,两个对象即通过compareTo(Object obj) 方法的返回值来比较大小。
-
Comparable 的典型实现:
-
- BigDecimal、 BigInteger 以及所有的数值型对应的包装类:按它们对应的数值大小进行比较
- Character:按字符的 unicode值来进行比较
- Boolean: true 对应的包装类实例大于 false 对应的包装类实例
- String:按字符串中字符的 unicode 值进行比较
- Date、 Time:后边的时间、日期比前面的时间、日期大
-
向TreeSet 中添加元素时,只有第一个元素无须比较compareTo()方法,后面添加的所有元素都会调用compareTo()方法进行比较。
-
因为只有相同类的两个实例才会比较大小,所以向 TreeSet 中添加的应该是同一个类的对象。
-
对于 TreeSet 集合而言,它判断两个对象是否相等的唯一标准是:两个对象通过 compareTo(Object obj) 方法比较返回值。
-
当需要把一个对象放入 TreeSet 中,重写该对象对应的 equals() 方法时,应保证该方法与 compareTo(Object obj) 方法有一致的结果:如果两个对象通过equals() 方法比较返回 true,则通过 compareTo(Object obj) 方法比较应返回 0。否则,让人难以理解。
-
0:相等,添加失败
-
-1:小,放到左子树
-
1:大,放到右子树
案例:
public class User implements Comparable {
private String name;
private int age;
public User() {
}
public User(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
//按照姓名从大到小排列,年龄从小到大排列
@Override
public int compareTo(Object o) {
if(o instanceof User){
User user = (User)o;
// return -this.name.compareTo(user.name);
// int compare = -this.name.compareTo(user.name);
int compare = this.name.compareTo(user.name);
if(compare != 0){
return compare;
}else{
return Integer.compare(this.age,user.age);
}
}else{
throw new RuntimeException("输入的类型不匹配");
}
}
}
public class TreeSetDemo1 {
@Test
public void test1() {
System.out.println("cc".compareTo("ccc"));
// System.out.println(Integer.compare(3, 2));
}
public static void main(String[] args) {
User u1 = new User("aaa", 35);
User u2 = new User("bbb", 36);
User u3 = new User("ccc", 83);
User u4 = new User("ccc", 30);
User u5 = new User("ccc", 74);
User u6 = new User("eee", 39);
User u7 = new User("fff", 40);
User u8 = new User("ggg", 40);
User u9 = new User("ggg", 40);
TreeSet set = new TreeSet();
set.add(u1);
set.add(u2);
set.add(u3);
set.add(u4);
set.add(u5);
set.add(u6);
set.add(u7);
set.add(u8);
set.add(u9);
for (Object o : set) {
System.out.println(o);
}
}
}
hashmap原理
树化,链化
添加/修改的过程:
将(key1,value1)添加到当前的map方法中
首先,需要调用key1所在类的hashCode()方法,计算key1对应的哈希值1,此哈希值1经过某种算法(hash() )之后,得到哈希值2
哈希值2再经过(indexFor() )之后,就确定了(key1,value1)在数组table中的索引位置
定制排序是指在排序过程中可以自定义比较元素的方式。Java 提供了多种方式来实现定制排序。
- 使用 Comparable 接口: 可以通过让待排序的类实现
Comparable接口,并实现其中的compareTo()方法来定义对象之间的比较规则。然后在排序时,可以直接使用Arrays.sort()或Collections.sort()方法进行排序。
示例代码:
java复制代码public class Person implements Comparable<Person> {
private String name;
private int age;
// 构造方法、getter、setter 省略
@Override
public int compareTo(Person other) {
// 自定义比较规则,按年龄升序排序
return this.age - other.age;
}
}
// 使用示例
Person[] people = new Person[3];
people[0] = new Person("Alice", 25);
people[1] = new Person("Bob", 30);
people[2] = new Person("Charlie", 20);
Arrays.sort(people);
- 使用 Comparator 接口: 如果无法修改待排序类的源代码,或者需要多种不同的比较则,可以通过实现
Comparator接口来定义比较器。比较器可以在排序时作为参数传递给Arrays.sort()或Collections.sort()方法。
示例代码:
java复制代码public class PersonComparator implements Comparator<Person> {
@Override
public int compare(Person p1, Person p2) {
// 自定义比较规则,按姓名长度升序排序
return p1.getName().length() - p2.getName().length();
}
}
// 使用示例
Person[] people = new Person[3];
people[0] = new Person("Alice", 25);
people[1] = new Person("Bob", 30);
people[2] = new Person("Charlie", 20);
Arrays.sort(people, new PersonComparator());
通过实现 Comparable 接口或实现 Comparator 接口,可以灵活地定义自定义的排序规则。根据具体需求选择合适的方式来实现定制排序。
题:
//其中Person类中重写了hashCode()和equal()方法

1. 集合框架概述
1.1 生活中的容器

1.2 数组的特点与弊端
- 一方面,面向对象语言对事物的体现都是以对象的形式,为了方便对多个对象的操作,就要对对象进行存储。
- 另一方面,使用数组存储对象方面具有
一些弊端,而Java 集合就像一种容器,可以动态地把多个对象的引用放入容器中。 - 数组在内存存储方面的
特点:- 数组初始化以后,长度就确定了。
- 数组中的添加的元素是依次紧密排列的,有序的,可以重复的。
- 数组声明的类型,就决定了进行元素初始化时的类型。不是此类型的变量,就不能添加。
- 可以存储基本数据类型值,也可以存储引用数据类型的变量
- 数组在存储数据方面的
弊端:- 数组初始化以后,长度就不可变了,不便于扩展
- 数组中提供的属性和方法少,不便于进行添加、删除、插入、获取元素个数等操作,且效率不高。
- 数组存储数据的特点单一,只能存储有序的、可以重复的数据
- Java 集合框架中的类可以用于存储多个
对象,还可用于保存具有映射关系的关联数组。
1.3 Java集合框架体系
Java 集合可分为 Collection 和 Map 两大体系:
-
Collection接口:用于存储一个一个的数据,也称
单列数据集合。- List子接口:用来存储有序的、可以重复的数据(主要用来替换数组,"动态"数组)
- 实现类:ArrayList(主要实现类)、LinkedList、Vector
- List子接口:用来存储有序的、可以重复的数据(主要用来替换数组,"动态"数组)
-
Set子接口:用来存储无序的、不可重复的数据(类似于高中讲的"集合")
- 实现类:HashSet(主要实现类)、LinkedHashSet、TreeSet
-
Map接口:用于存储具有映射关系“key-value对”的集合,即一对一对的数据,也称
双列数据集合。(类似于高中的函数、映射。(x1,y1),(x2,y2) —> y = f(x) )- HashMap(主要实现类)、LinkedHashMap、TreeMap、Hashtable、Properties
-
JDK提供的集合API位于java.util包内
-
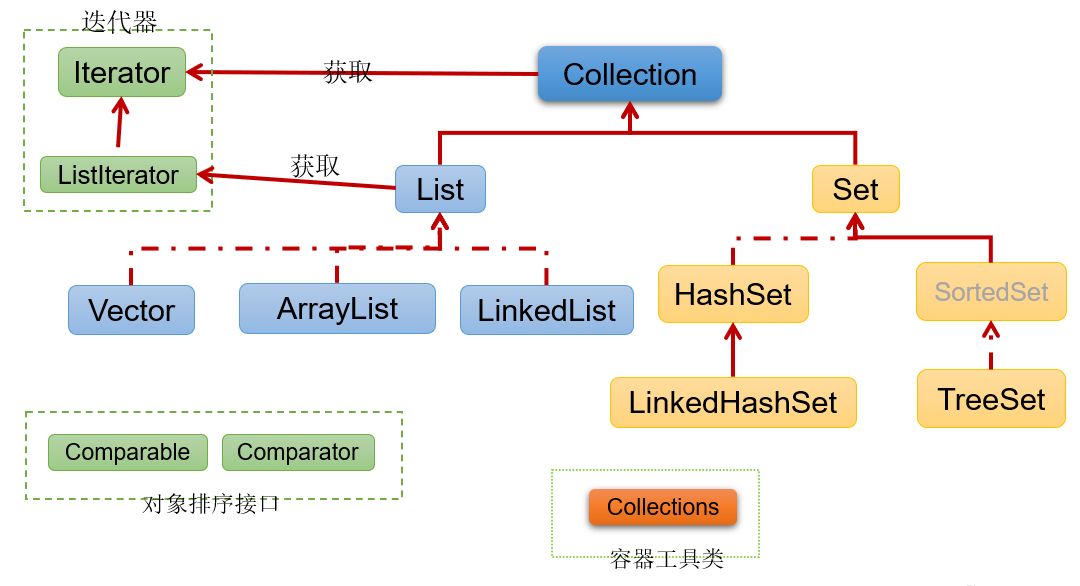
图示:集合框架全图

- 简图1:Collection接口继承树
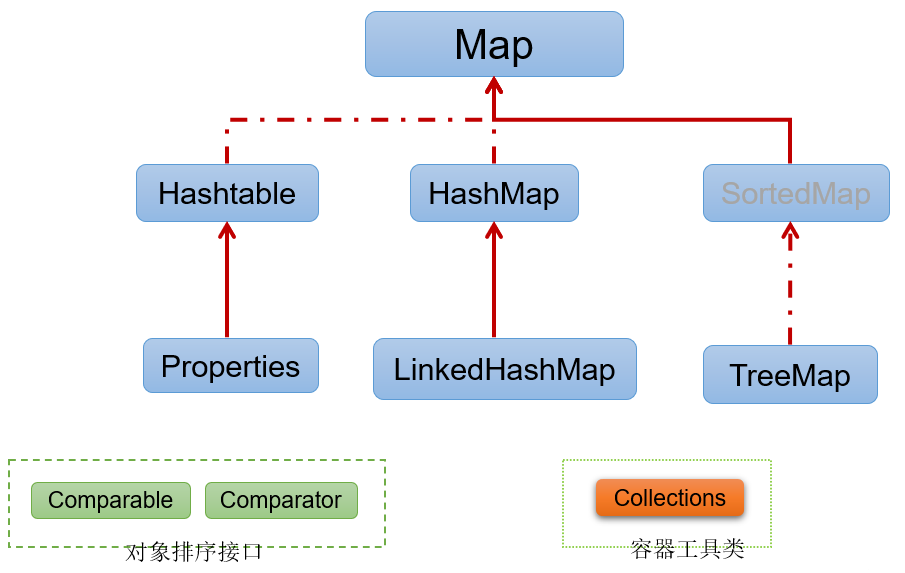
- 简图2:Map接口继承树
1.4 集合的使用场景

2. Collection接口及方法
- JDK不提供此接口的任何直接实现,而是提供更具体的子接口(如:Set和List)去实现。
- Collection 接口是 List和Set接口的父接口,该接口里定义的方法既可用于操作 Set 集合,也可用于操作 List 集合。方法如下:
2.1 添加
(1)add(E obj):添加元素对象到当前集合中
(2)addAll(Collection other):添加other集合中的所有元素对象到当前集合中,即this = this ∪ other
注意:add和addAll的区别
package com.atguigu.collection;
import org.junit.Test;
import java.util.ArrayList;
import java.util.Collection;
public class TestCollectionAdd {
@Test
public void testAdd(){
//ArrayList是Collection的子接口List的实现类之一。
Collection coll = new ArrayList();
coll.add("小李广");
coll.add("扫地僧");
coll.add("石破天");
System.out.println(coll);
}
@Test
public void testAddAll(){
Collection c1 = new ArrayList();
c1.add(1);
c1.add(2);
System.out.println("c1集合元素的个数:" + c1.size());//2
System.out.println("c1 = " + c1);
Collection c2 = new ArrayList();
c2.add(1);
c2.add(2);
System.out.println("c2集合元素的个数:" + c2.size());//2
System.out.println("c2 = " + c2);
Collection other = new ArrayList();
other.add(1);
other.add(2);
other.add(3);
System.out.println("other集合元素的个数:" + other.size());//3
System.out.println("other = " + other);
System.out.println();
c1.addAll(other);
System.out.println("c1集合元素的个数:" + c1.size());//5
System.out.println("c1.addAll(other) = " + c1);
c2.add(other);
System.out.println("c2集合元素的个数:" + c2.size());//3
System.out.println("c2.add(other) = " + c2);
}
}
注意:coll.addAll(other);与coll.add(other);

2.2 判断
(3)int size():获取当前集合中实际存储的元素个数
(4)boolean isEmpty():判断当前集合是否为空集合
(5)boolean contains(Object obj):判断当前集合中是否存在一个与obj对象equals返回true的元素
(6)boolean containsAll(Collection coll):判断coll集合中的元素是否在当前集合中都存在。即coll集合是否是当前集合的“子集”
(7)boolean equals(Object obj):判断当前集合与obj是否相等
package com.atguigu.collection;
import org.junit.Test;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collection;
public class TestCollectionContains {
@Test
public void test01() {
Collection coll = new ArrayList();
System.out.println("coll在添加元素之前,isEmpty = " + coll.isEmpty());
coll.add("小李广");
coll.add("扫地僧");
coll.add("石破天");
coll.add("佛地魔");
System.out.println("coll的元素个数" + coll.size());
System.out.println("coll在添加元素之后,isEmpty = " + coll.isEmpty());
}
@Test
public void test02() {
Collection coll = new ArrayList();
coll.add("小李广");
coll.add("扫地僧");
coll.add("石破天");
coll.add("佛地魔");
System.out.println("coll = " + coll);
System.out.println("coll是否包含“小李广” = " + coll.contains("小李广"));
System.out.println("coll是否包含“宋红康” = " + coll.contains("宋红康"));
Collection other = new ArrayList();
other.add("小李广");
other.add("扫地僧");
other.add("尚硅谷");
System.out.println("other = " + other);
System.out.println("coll.containsAll(other) = " + coll.containsAll(other));
}
@Test
public void test03(){
Collection c1 = new ArrayList();
c1.add(1);
c1.add(2);
System.out.println("c1集合元素的个数:" + c1.size());//2
System.out.println("c1 = " + c1);
Collection c2 = new ArrayList();
c2.add(1);
c2.add(2);
System.out.println("c2集合元素的个数:" + c2.size());//2
System.out.println("c2 = " + c2);
Collection other = new ArrayList();
other.add(1);
other.add(2);
other.add(3);
System.out.println("other集合元素的个数:" + other.size());//3
System.out.println("other = " + other);
System.out.println();
c1.addAll(other);
System.out.println("c1集合元素的个数:" + c1.size());//5
System.out.println("c1.addAll(other) = " + c1);
System.out.println("c1.contains(other) = " + c1.contains(other));
System.out.println("c1.containsAll(other) = " + c1.containsAll(other));
System.out.println();
c2.add(other);
System.out.println("c2集合元素的个数:" + c2.size());
System.out.println("c2.add(other) = " + c2);
System.out.println("c2.contains(other) = " + c2.contains(other));
System.out.println("c2.containsAll(other) = " + c2.containsAll(other));
}
}
2.3 删除
(8)void clear():清空集合元素
(9) boolean remove(Object obj) :从当前集合中删除第一个找到的与obj对象equals返回true的元素。
(10)boolean removeAll(Collection coll):从当前集合中删除所有与coll集合中相同的元素。即this = this - this ∩ coll
(11)boolean retainAll(Collection coll):从当前集合中删除两个集合中不同的元素,使得当前集合仅保留与coll集合中的元素相同的元素,即当前集合中仅保留两个集合的交集,即this = this ∩ coll;
注意几种删除方法的区别
package com.atguigu.collection;
import org.junit.Test;
import java.util.ArrayList;
import java.util.Collection;
import java.util.function.Predicate;
public class TestCollectionRemove {
@Test
public void test01(){
Collection coll = new ArrayList();
coll.add("小李广");
coll.add("扫地僧");
coll.add("石破天");
coll.add("佛地魔");
System.out.println("coll = " + coll);
coll.remove("小李广");
System.out.println("删除元素\"小李广\"之后coll = " + coll);
coll.clear();
System.out.println("coll清空之后,coll = " + coll);
}
@Test
public void test02() {
Collection coll = new ArrayList();
coll.add("小李广");
coll.add("扫地僧");
coll.add("石破天");
coll.add("佛地魔");
System.out.println("coll = " + coll);
Collection other = new ArrayList();
other.add("小李广");
other.add("扫地僧");
other.add("尚硅谷");
System.out.println("other = " + other);
coll.removeAll(other);
System.out.println("coll.removeAll(other)之后,coll = " + coll);
System.out.println("coll.removeAll(other)之后,other = " + other);
}
@Test
public void test03() {
Collection coll = new ArrayList();
coll.add("小李广");
coll.add("扫地僧");
coll.add("石破天");
coll.add("佛地魔");
System.out.println("coll = " + coll);
Collection other = new ArrayList();
other.add("小李广");
other.add("扫地僧");
other.add("尚硅谷");
System.out.println("other = " + other);
coll.retainAll(other);
System.out.println("coll.retainAll(other)之后,coll = " + coll);
System.out.println("coll.retainAll(other)之后,other = " + other);
}
}
2.4 其它
(12)Object[] toArray():返回包含当前集合中所有元素的数组
(13)hashCode():获取集合对象的哈希值
(14)iterator():返回迭代器对象,用于集合遍历
public class TestCollectionContains {
@Test
public void test01() {
Collection coll = new ArrayList();
coll.add("小李广");
coll.add("扫地僧");
coll.add("石破天");
coll.add("佛地魔");
//集合转换为数组:集合的toArray()方法
Object[] objects = coll.toArray();
System.out.println("用数组返回coll中所有元素:" + Arrays.toString(objects));
//对应的,数组转换为集合:调用Arrays的asList(Object ...objs)
Object[] arr1 = new Object[]{123,"AA","CC"};
Collection list = Arrays.asList(arr1);
System.out.println(list);
}
}
3. Iterator(迭代器)接口
3.1 Iterator接口
-
在程序开发中,经常需要遍历集合中的所有元素。针对这种需求,JDK专门提供了一个接口
java.util.Iterator。Iterator接口也是Java集合中的一员,但它与Collection、Map接口有所不同。- Collection接口与Map接口主要用于
存储元素 Iterator,被称为迭代器接口,本身并不提供存储对象的能力,主要用于遍历Collection中的元素
- Collection接口与Map接口主要用于
-
Collection接口继承了java.lang.Iterable接口,该接口有一个iterator()方法,那么所有实现了Collection接口的集合类都有一个iterator()方法,用以返回一个实现了Iterator接口的对象。
public Iterator iterator(): 获取集合对应的迭代器,用来遍历集合中的元素的。- 集合对象每次调用iterator()方法都得到一个全新的迭代器对象,默认游标都在集合的第一个元素之前。
-
Iterator接口的常用方法如下:
public E next():返回迭代的下一个元素。public boolean hasNext():如果仍有元素可以迭代,则返回 true。
-
注意:在调用it.next()方法之前必须要调用it.hasNext()进行检测。若不调用,且下一条记录无效,直接调用it.next()会抛出
NoSuchElementException异常。
举例:
package com.atguigu.iterator;
import org.junit.Test;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class TestIterator {
@Test
public void test01(){
Collection coll = new ArrayList();
coll.add("小李广");
coll.add("扫地僧");
coll.add("石破天");
Iterator iterator = coll.iterator();
System.out.println(iterator.next());
System.out.println(iterator.next());
System.out.println(iterator.next());
System.out.println(iterator.next()); //报NoSuchElementException异常
}
@Test
public void test02(){
Collection coll = new ArrayList();
coll.add("小李广");
coll.add("扫地僧");
coll.add("石破天");
Iterator iterator = coll.iterator();//获取迭代器对象
while(iterator.hasNext()) {//判断是否还有元素可迭代
System.out.println(iterator.next());//取出下一个元素
}
}
}
3.2 迭代器的执行原理
Iterator迭代器对象在遍历集合时,内部采用指针的方式来跟踪集合中的元素,接下来通过一个图例来演示Iterator对象迭代元素的过程:

使用Iterator迭代器删除元素:java.util.Iterator迭代器中有一个方法:void remove() ;
Iterator iter = coll.iterator();//回到起点
while(iter.hasNext()){
Object obj = iter.next();
if(obj.equals("Tom")){
iter.remove();
}
}
注意:
-
Iterator可以删除集合的元素,但是遍历过程中通过迭代器对象的remove方法,不是集合对象的remove方法。
-
如果还未调用next()或在上一次调用 next() 方法之后已经调用了 remove() 方法,再调用remove()都会报IllegalStateException。
-
Collection已经有remove(xx)方法了,为什么Iterator迭代器还要提供删除方法呢?因为迭代器的remove()可以按指定的条件进行删除。
例如:要删除以下集合元素中的偶数
package com.atguigu.iterator;
import org.junit.Test;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class TestIteratorRemove {
@Test
public void test01(){
Collection coll = new ArrayList();
coll.add(1);
coll.add(2);
coll.add(3);
coll.add(4);
coll.add(5);
coll.add(6);
Iterator iterator = coll.iterator();
while(iterator.hasNext()){
Integer element = (Integer) iterator.next();
if(element % 2 == 0){
iterator.remove();
}
}
System.out.println(coll);
}
}
在JDK8.0时,Collection接口有了removeIf 方法,即可以根据条件删除。(第18章中再讲)
package com.atguigu.collection;
import org.junit.Test;
import java.util.ArrayList;
import java.util.Collection;
import java.util.function.Predicate;
public class TestCollectionRemoveIf {
@Test
public void test01(){
Collection coll = new ArrayList();
coll.add("小李广");
coll.add("扫地僧");
coll.add("石破天");
coll.add("佛地魔");
System.out.println("coll = " + coll);
coll.removeIf(new Predicate() {
@Override
public boolean test(Object o) {
String str = (String) o;
return str.contains("地");
}
});
System.out.println("删除包含\"地\"字的元素之后coll = " + coll);
}
}
3.3 foreach循环
-
foreach循环(也称增强for循环)是 JDK5.0 中定义的一个高级for循环,专门用来
遍历数组和集合的。 -
foreach循环的语法格式:
for(元素的数据类型 局部变量 : Collection集合或数组){
//操作局部变量的输出操作
}
//这里局部变量就是一个临时变量,自己命名就可以
- 举例:
package com.atguigu.iterator;
import org.junit.Test;
import java.util.ArrayList;
import java.util.Collection;
public class TestForeach {
@Test
public void test01(){
Collection coll = new ArrayList();
coll.add("小李广");
coll.add("扫地僧");
coll.add("石破天");
//foreach循环其实就是使用Iterator迭代器来完成元素的遍历的。
for (Object o : coll) {
System.out.println(o);
}
}
@Test
public void test02(){
int[] nums = {1,2,3,4,5};
for (int num : nums) {
System.out.println(num);
}
System.out.println("-----------------");
String[] names = {"张三","李四","王五"};
for (String name : names) {
System.out.println(name);
}
}
}
- 对于集合的遍历,增强for的内部原理其实是个Iterator迭代器。如下图。

- 它用于遍历Collection和数组。通常只进行遍历元素,不要在遍历的过程中对集合元素进行增删操作。
- 练习:判断输出结果为何?
public class ForTest {
public static void main(String[] args) {
String[] str = new String[5];
for (String myStr : str) {
myStr = "atguigu";
System.out.println(myStr);
}
for (int i = 0; i < str.length; i++) {
System.out.println(str[i]);
}
}
}
4. Collection子接口1:List
4.1 List接口特点
-
鉴于Java中数组用来存储数据的局限性,我们通常使用
java.util.List替代数组 -
List集合类中
元素有序、且可重复,集合中的每个元素都有其对应的顺序索引。- 举例:List集合存储数据,就像银行门口客服,给每一个来办理业务的客户分配序号:第一个来的是“张三”,客服给他分配的是0;第二个来的是“李四”,客服给他分配的1;以此类推,最后一个序号应该是“总人数-1”。
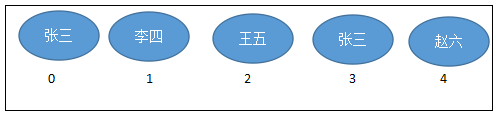
- JDK API中List接口的实现类常用的有:
ArrayList、LinkedList和Vector。
4.2 List接口方法
List除了从Collection集合继承的方法外,List 集合里添加了一些根据索引来操作集合元素的方法。
- 插入元素
void add(int index, Object ele):在index位置插入ele元素- boolean addAll(int index, Collection eles):从index位置开始将eles中的所有元素添加进来
- 获取元素
Object get(int index):获取指定index位置的元素- List subList(int fromIndex, int toIndex):返回从fromIndex到toIndex位置的子集合
- 获取元素索引
- int indexOf(Object obj):返回obj在集合中首次出现的位置
- int lastIndexOf(Object obj):返回obj在当前集合中末次出现的位置
- 删除和替换元素
-
Object remove(int index):移除指定index位置的元素,并返回此元素 -
Object set(int index, Object ele):设置指定index位置的元素为ele
-
举例:
package com.atguigu.list;
import java.util.ArrayList;
import java.util.List;
public class TestListMethod {
public static void main(String[] args) {
// 创建List集合对象
List<String> list = new ArrayList<String>();
// 往 尾部添加 指定元素
list.add("图图");
list.add("小美");
list.add("不高兴");
System.out.println(list);
// add(int index,String s) 往指定位置添加
list.add(1,"没头脑");
System.out.println(list);
// String remove(int index) 删除指定位置元素 返回被删除元素
// 删除索引位置为2的元素
System.out.println("删除索引位置为2的元素");
System.out.println(list.remove(2));
System.out.println(list);
// String set(int index,String s)
// 在指定位置 进行 元素替代(改)
// 修改指定位置元素
list.set(0, "三毛");
System.out.println(list);
// String get(int index) 获取指定位置元素
// 跟size() 方法一起用 来 遍历的
for(int i = 0;i<list.size();i++){
System.out.println(list.get(i));
}
//还可以使用增强for
for (String string : list) {
System.out.println(string);
}
}
}
注意:在JavaSE中List名称的类型有两个,一个是java.util.List集合接口,一个是java.awt.List图形界面的组件,别导错包了。
4.3 List接口主要实现类:ArrayList
-
ArrayList 是 List 接口的
主要实现类 -
本质上,ArrayList是对象引用的一个”变长”数组
-
Arrays.asList(…) 方法返回的 List 集合,既不是 ArrayList 实例,也不是 Vector 实例。 Arrays.asList(…) 返回值是一个固定长度的 List 集合
4.4 List的实现类之二:LinkedList
- 对于频繁的插入或删除元素的操作,建议使用LinkedList类,效率较高。这是由底层采用链表(双向链表)结构存储数据决定的。

- 特有方法:
- void addFirst(Object obj)
- void addLast(Object obj)
- Object getFirst()
- Object getLast()
- Object removeFirst()
- Object removeLast()
4.5 List的实现类之三:Vector
- Vector 是一个
古老的集合,JDK1.0就有了。大多数操作与ArrayList相同,区别之处在于Vector是线程安全的。 - 在各种List中,最好把
ArrayList作为默认选择。当插入、删除频繁时,使用LinkedList;Vector总是比ArrayList慢,所以尽量避免使用。 - 特有方法:
- void addElement(Object obj)
- void insertElementAt(Object obj,int index)
- void setElementAt(Object obj,int index)
- void removeElement(Object obj)
- void removeAllElements()
4.6 练习
面试题:
@Test
public void testListRemove() {
List list = new ArrayList();
list.add(1);
list.add(2);
list.add(3);
updateList(list);
System.out.println(list);//[1,2]
}
private static void updateList(List list) {
list.remove(2);
}
练习1:
- 定义学生类,属性为姓名、年龄,提供必要的getter、setter方法,构造器,toString(),equals()方法。
- 使用ArrayList集合,保存录入的多个学生对象。
- 循环录入的方式,1:继续录入,0:结束录入。
- 录入结束后,用foreach遍历集合。
-
代码实现,效果如图所示:

package com.atguigu.test01;
import java.util.ArrayList;
import java.util.Scanner;
public class StudentTest {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
ArrayList stuList = new ArrayList();
for (;;) {
System.out.println("选择(录入 1 ;结束 0)");
int x = scanner.nextInt();//根据x的值,判断是否需要继续循环
if (x == 1) {
System.out.println("姓名");
String name = scanner.next();
System.out.println("年龄");
int age = scanner.nextInt();
Student stu = new Student(age, name);
stuList.add(stu);
} else if (x == 0) {
break;
} else {
System.out.println("输入有误,请重新输入");
}
}
for (Object stu : stuList) {
System.out.println(stu);
}
}
}
public class Student {
private int age;
private String name;
public Student() {
}
public Student(int age, String name) {
super();
this.age = age;
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Student [age=" + age + ", name=" + name + "]";
}
}
练习2:
1、请定义方法public static int listTest(Collection list,String s)统计集合中指定元素出现的次数
2、创建集合,集合存放随机生成的30个小写字母
3、用listTest统计,a、b、c、x元素的出现次数
4、效果如下
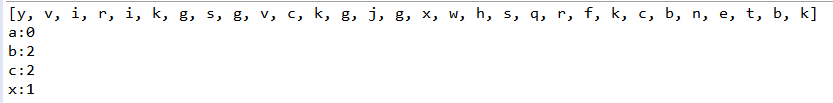
package com.atguigu.test02;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Random;
public class Test02 {
public static void main(String[] args) {
Collection list = new ArrayList();
Random rand = new Random();
for (int i = 0; i < 30; i++) {
list.add((char)(rand.nextInt(26)+97)+"");
}
System.out.println(list);
System.out.println("a:"+listTest(list, "a"));
System.out.println("b:"+listTest(list, "b"));
System.out.println("c:"+listTest(list, "c"));
System.out.println("x:"+listTest(list, "x"));
}
public static int listTest(Collection list, String string) {
int count = 0;
for (Object object : list) {
if(string.equals(object)){
count++;
}
}
return count;
}
}
练习3:KTV点歌系统
描述
分别使用ArrayList和LinkedList集合,编写一个**KTV点歌系统**的程序。在程序中:
- 指令1代表添加歌曲
- 指令2代表将所选歌曲置顶
- 指令3代表将所选歌曲提前一位
- 指令4代表退出该系统
要求根据用户输入的指令和歌曲名展现歌曲列表。例如输入指令1,输入歌曲名"爱你一万年",则输出“当前歌曲列表:[爱你一万年]”。
提示
-
为了指引用户操作,首先要将各个指令所表示的含义打印到控制台
System.out.println("-------------欢迎来到点歌系统------------"); System.out.println("1.添加歌曲至列表"); System.out.println("2.将歌曲置顶"); System.out.println("3.将歌曲前移一位"); System.out.println("4.退出"); -
程序中需要创建一个集合作为歌曲列表,并向其添加一部分歌曲
-
通过ArrayList或LinkedList集合定义的方法操作歌曲列表
代码
-
使用ArrayList集合模拟点歌系统的实现代码,如下所示:
/** * @author 尚硅谷-宋红康 * @create 20:26 */ public class KTVByArrayList { private static ArrayList musicList = new ArrayList();// 创建歌曲列表 private static Scanner sc = new Scanner(System.in); public static void main(String[] args) { addMusicList();// 添加一部分歌曲至歌曲列表 boolean flag = true; while (flag) { System.out.println("当前歌曲列表:" + musicList); System.out.println("-------------欢迎来到点歌系统------------"); System.out.println("1.添加歌曲至列表"); System.out.println("2.将歌曲置顶"); System.out.println("3.将歌曲前移一位"); System.out.println("4.退出"); System.out.print("请输入操作序号:"); int key = sc.nextInt();// //接收键盘输入的功能选项序号 // 执行序号对应的功能 switch (key) { case 1:// 添加歌曲至列表 addMusic(); break; case 2:// 将歌曲置顶 setTop(); break; case 3:// 将歌曲前移一位 setBefore(); break; case 4:// 退出 System.out.println("----------------退出---------------"); System.out.println("您已退出系统"); flag = false; break; default: System.out.println("----------------------------------"); System.out.println("功能选择有误,请输入正确的功能序号!"); break; } } } // 初始时添加歌曲名称 private static void addMusicList() { musicList.add("本草纲目"); musicList.add("你是我的眼"); musicList.add("老男孩"); musicList.add("白月光与朱砂痣"); musicList.add("不谓侠"); musicList.add("爱你"); } // 执行添加歌曲 private static void addMusic() { System.out.print("请输入要添加的歌曲名称:"); String musicName = sc.next();// 获取键盘输入内容 musicList.add(musicName);// 添加歌曲到列表的最后 System.out.println("已添加歌曲:" + musicName); } // 执行将歌曲置顶 private static void setTop() { System.out.print("请输入要置顶的歌曲名称:"); String musicName = sc.next();// 获取键盘输入内容 int musicIndex = musicList.indexOf(musicName);// 查找指定歌曲位置 if (musicIndex < 0) {// 判断输入歌曲是否存在 System.out.println("当前列表中没有输入的歌曲!"); }else if(musicIndex == 0){ System.out.println("当前歌曲默认已置顶!"); }else { musicList.remove(musicName);// 移除指定的歌曲 musicList.add(0, musicName);// 将指定的歌曲放到第一位 System.out.println("已将歌曲《" + musicName + "》置顶"); } } // 执行将歌曲置前一位 private static void setBefore() { System.out.print("请输入要置前的歌曲名称:"); String musicName = sc.next();// 获取键盘输入内容 int musicIndex = musicList.indexOf(musicName);// 查找指定歌曲位置 if (musicIndex < 0) {// 判断输入歌曲是否存在 System.out.println("当前列表中没有输入的歌曲!"); } else if (musicIndex == 0) {// 判断歌曲是否已在第一位 System.out.println("当前歌曲已在最顶部!"); } else { musicList.remove(musicName);// 移除指定的歌曲 musicList.add(musicIndex - 1, musicName);// 将指定的歌曲放到前一位 System.out.println("已将歌曲《" + musicName + "》置前一位"); } } }
5. Collection子接口2:Set
5.1 Set接口概述
- Set接口是Collection的子接口,Set接口相较于Collection接口没有提供额外的方法
- Set 集合不允许包含相同的元素,如果试把两个相同的元素加入同一个 Set 集合中,则添加操作失败。
- Set集合支持的遍历方式和Collection集合一样:foreach和Iterator。
- Set的常用实现类有:HashSet、TreeSet、LinkedHashSet。
5.2 Set主要实现类:HashSet
5.2.1 HashSet概述
-
HashSet 是 Set 接口的主要实现类,大多数时候使用 Set 集合时都使用这个实现类。
-
HashSet 按 Hash 算法来存储集合中的元素,因此具有很好的存储、查找、删除性能。
-
HashSet 具有以下
特点:- 不能保证元素的排列顺序
- HashSet 不是线程安全的
- 集合元素可以是 null
-
HashSet 集合
判断两个元素相等的标准:两个对象通过hashCode()方法得到的哈希值相等,并且两个对象的equals()方法返回值为true。 -
对于存放在Set容器中的对象,对应的类一定要重写hashCode()和equals(Object obj)方法,以实现对象相等规则。即:“相等的对象必须具有相等的散列码”。
-
HashSet集合中元素的无序性,不等同于随机性。这里的无序性与元素的添加位置有关。具体来说:我们在添加每一个元素到数组中时,具体的存储位置是由元素的hashCode()调用后返回的hash值决定的。导致在数组中每个元素不是依次紧密存放的,表现出一定的无序性。
5.2.2 HashSet中添加元素的过程:
-
第1步:当向 HashSet 集合中存入一个元素时,HashSet 会调用该对象的 hashCode() 方法得到该对象的 hashCode值,然后根据 hashCode值,通过某个散列函数决定该对象在 HashSet 底层数组中的存储位置。
-
第2步:如果要在数组中存储的位置上没有元素,则直接添加成功。
-
第3步:如果要在数组中存储的位置上有元素,则继续比较:
- 如果两个元素的hashCode值不相等,则添加成功;
- 如果两个元素的hashCode()值相等,则会继续调用equals()方法:
- 如果equals()方法结果为false,则添加成功。
- 如果equals()方法结果为true,则添加失败。
第2步添加成功,元素会保存在底层数组中。
第3步两种添加成功的操作,由于该底层数组的位置已经有元素了,则会通过
链表的方式继续链接,存储。
举例:
package com.atguigu.set;
import java.util.Objects;
public class MyDate {
private int year;
private int month;
private int day;
public MyDate(int year, int month, int day) {
this.year = year;
this.month = month;
this.day = day;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
MyDate myDate = (MyDate) o;
return year == myDate.year &&
month == myDate.month &&
day == myDate.day;
}
@Override
public int hashCode() {
return Objects.hash(year, month, day);
}
@Override
public String toString() {
return "MyDate{" +
"year=" + year +
", month=" + month +
", day=" + day +
'}';
}
}
package com.atguigu.set;
import org.junit.Test;
import java.util.HashSet;
public class TestHashSet {
@Test
public void test01(){
HashSet set = new HashSet();
set.add("张三");
set.add("张三");
set.add("李四");
set.add("王五");
set.add("王五");
set.add("赵六");
System.out.println("set = " + set);//不允许重复,无序
}
@Test
public void test02(){
HashSet set = new HashSet();
set.add(new MyDate(2021,1,1));
set.add(new MyDate(2021,1,1));
set.add(new MyDate(2022,2,4));
set.add(new MyDate(2022,2,4));
System.out.println("set = " + set);//不允许重复,无序
}
}
5.2.3 重写 hashCode() 方法的基本原则
- 在程序运行时,同一个对象多次调用 hashCode() 方法应该返回相同的值。
- 当两个对象的 equals() 方法比较返回 true 时,这两个对象的 hashCode() 方法的返回值也应相等。
- 对象中用作 equals() 方法比较的 Field,都应该用来计算 hashCode 值。
注意:如果两个元素的 equals() 方法返回 true,但它们的 hashCode() 返回值不相等,hashSet 将会把它们存储在不同的位置,但依然可以添加成功。
5.2.4 重写equals()方法的基本原则
-
重写equals方法的时候一般都需要同时复写hashCode方法。通常参与计算hashCode的对象的属性也应该参与到equals()中进行计算。
-
推荐:开发中直接调用Eclipse/IDEA里的快捷键自动重写equals()和hashCode()方法即可。
- 为什么用Eclipse/IDEA复写hashCode方法,有31这个数字?
首先,选择系数的时候要选择尽量大的系数。因为如果计算出来的hash地址越大,所谓的“冲突”就越少,查找起来效率也会提高。(减少冲突) 其次,31只占用5bits,相乘造成数据溢出的概率较小。 再次,31可以 由i*31== (i<<5)-1来表示,现在很多虚拟机里面都有做相关优化。(提高算法效率) 最后,31是一个素数,素数作用就是如果我用一个数字来乘以这个素数,那么最终出来的结果只能被素数本身和被乘数还有1来整除!(减少冲突)
5.2.5 练习
**练习1:**在List内去除重复数字值,要求尽量简单
public static List duplicateList(List list) {
HashSet set = new HashSet();
set.addAll(list);
return new ArrayList(set);
}
public static void main(String[] args) {
List list = new ArrayList();
list.add(new Integer(1));
list.add(new Integer(2));
list.add(new Integer(2));
list.add(new Integer(4));
list.add(new Integer(4));
List list2 = duplicateList(list);
for (Object integer : list2) {
System.out.println(integer);
}
}
**练习2:**获取随机数
编写一个程序,获取10个1至20的随机数,要求随机数不能重复。并把最终的随机数输出到控制台。
/**
*
* @Description
* @author 尚硅谷-宋红康
* @date 2022年5月7日上午12:43:01
*
*/
public class RandomValueTest {
public static void main(String[] args) {
HashSet hs = new HashSet(); // 创建集合对象
Random r = new Random();
while (hs.size() < 10) {
int num = r.nextInt(20) + 1; // 生成1到20的随机数
hs.add(num);
}
for (Integer integer : hs) { // 遍历集合
System.out.println(integer); // 打印每一个元素
}
}
}
**练习3:**去重
使用Scanner从键盘读取一行输入,去掉其中重复字符,打印出不同的那些字符。比如:aaaabbbcccddd
/**
*
* @Description
* @author 尚硅谷-宋红康
* @date 2022年5月7日上午12:44:01
*
*/
public class DistinctTest {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in); // 创建键盘录入对象
System.out.println("请输入一行字符串:");
String line = sc.nextLine(); // 将键盘录入的字符串存储在line中
char[] arr = line.toCharArray(); // 将字符串转换成字符数组
HashSet hs = new HashSet(); // 创建HashSet集合对象
for (Object c : arr) { // 遍历字符数组
hs.add(c); // 将字符数组中的字符添加到集合中
}
for (Object ch : hs) { // 遍历集合
System.out.print(ch);
}
}
}
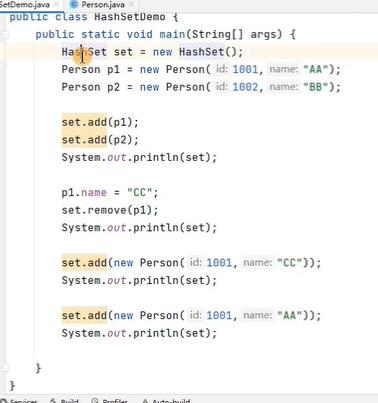
**练习4:**面试题
HashSet set = new HashSet();
Person p1 = new Person(1001,"AA");
Person p2 = new Person(1002,"BB");
set.add(p1);
set.add(p2);
p1.name = "CC";
set.remove(p1);
System.out.println(set);
set.add(new Person(1001,"CC"));
System.out.println(set);
set.add(new Person(1001,"AA"));
System.out.println(set);
//其中Person类中重写了hashCode()和equal()方法
5.3 Set实现类之二:LinkedHashSet
-
LinkedHashSet 是 HashSet 的子类,不允许集合元素重复。
-
LinkedHashSet 根据元素的 hashCode 值来决定元素的存储位置,但它同时使用
双向链表维护元素的次序,这使得元素看起来是以添加顺序保存的。 -
LinkedHashSet
插入性能略低于 HashSet,但在迭代访问Set 里的全部元素时有很好的性能。

举例:
package com.atguigu.set;
import org.junit.Test;
import java.util.LinkedHashSet;
public class TestLinkedHashSet {
@Test
public void test01(){
LinkedHashSet set = new LinkedHashSet();
set.add("张三");
set.add("张三");
set.add("李四");
set.add("王五");
set.add("王五");
set.add("赵六");
System.out.println("set = " + set);//不允许重复,体现添加顺序
}
}
5.4 Set实现类之三:TreeSet
5.4.1 TreeSet概述
- TreeSet 是 SortedSet 接口的实现类,TreeSet 可以按照添加的元素的指定的属性的大小顺序进行遍历。
- TreeSet底层使用
红黑树结构存储数据 - 新增的方法如下: (了解)
- Comparator comparator()
- Object first()
- Object last()
- Object lower(Object e)
- Object higher(Object e)
- SortedSet subSet(fromElement, toElement)
- SortedSet headSet(toElement)
- SortedSet tailSet(fromElement)
- TreeSet特点:不允许重复、实现排序(自然排序或定制排序)
- TreeSet 两种排序方法:
自然排序和定制排序。默认情况下,TreeSet 采用自然排序。自然排序:TreeSet 会调用集合元素的 compareTo(Object obj) 方法来比较元素之间的大小关系,然后将集合元素按升序(默认情况)排列。- 如果试图把一个对象添加到 TreeSet 时,则该对象的类必须实现 Comparable 接口。
- 实现 Comparable 的类必须实现 compareTo(Object obj) 方法,两个对象即通过 compareTo(Object obj) 方法的返回值来比较大小。
定制排序:如果元素所属的类没有实现Comparable接口,或不希望按照升序(默认情况)的方式排列元素或希望按照其它属性大小进行排序,则考虑使用定制排序。定制排序,通过Comparator接口来实现。需要重写compare(T o1,T o2)方法。- 利用int compare(T o1,T o2)方法,比较o1和o2的大小:如果方法返回正整数,则表示o1大于o2;如果返回0,表示相等;返回负整数,表示o1小于o2。
- 要实现定制排序,需要将实现Comparator接口的实例作为形参传递给TreeSet的构造器。
- 因为只有相同类的两个实例才会比较大小,所以向 TreeSet 中添加的应该是
同一个类的对象。 - 对于 TreeSet 集合而言,它判断
两个对象是否相等的唯一标准是:两个对象通过compareTo(Object obj) 或compare(Object o1,Object o2)方法比较返回值。返回值为0,则认为两个对象相等。
5.4.2 举例
举例1:
package com.atguigu.set;
import org.junit.Test;
import java.util.Iterator;
import java.util.TreeSet;
/**
* @author 尚硅谷-宋红康
* @create 14:22
*/
public class TreeSetTest {
/*
* 自然排序:针对String类的对象
* */
@Test
public void test1(){
TreeSet set = new TreeSet();
set.add("MM");
set.add("CC");
set.add("AA");
set.add("DD");
set.add("ZZ");
//set.add(123); //报ClassCastException的异常
Iterator iterator = set.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
/*
* 自然排序:针对User类的对象
* */
@Test
public void test2(){
TreeSet set = new TreeSet();
set.add(new User("Tom",12));
set.add(new User("Rose",23));
set.add(new User("Jerry",2));
set.add(new User("Eric",18));
set.add(new User("Tommy",44));
set.add(new User("Jim",23));
set.add(new User("Maria",18));
//set.add("Tom");
Iterator iterator = set.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
System.out.println(set.contains(new User("Jack", 23))); //true
}
}
其中,User类定义如下:
/**
* @author 尚硅谷-宋红康
* @create 14:22
*/
public class User implements Comparable{
String name;
int age;
public User() {
}
public User(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
/*
举例:按照age从小到大的顺序排列,如果age相同,则按照name从大到小的顺序排列
* */
public int compareTo(Object o) {
if(this == o){
return 0;
}
if(o instanceof User){
User user = (User)o;
int value = this.age - user.age;
if(value != 0){
return value;
}
return -this.name.compareTo(user.name);
}
throw new RuntimeException("输入的类型不匹配");
}
/*
public int compareTo(Object o) {
// 判断是否为同一对象,如果是则返回0,表示相等
if (this == o) {
return 0;
}
// 判断o是否是User类型的实例
if (o instanceof User) {
// 强制类型转换为User对象
User user = (User) o;
// 比较年龄
int value = this.age - user.age;
// 如果年龄不等于0,则直接返回年龄差值
if (value != 0) {
return value;
}
// 年龄相等时,比较姓名
// 返回姓名的字典序差值的负数,以实现按姓名降序排序
return -this.name.compareTo(user.name);
}
// 如果o不是User类型的实例,抛出异常
throw new RuntimeException("输入的类型不匹配");
}
*/
}
举例2:
/*
* 定制排序
* */
@Test
public void test3(){
//按照User的姓名的从小到大的顺序排列
Comparator comparator = new Comparator() {
@Override
public int compare(Object o1, Object o2) {
if(o1 instanceof User && o2 instanceof User){
User u1 = (User)o1;
User u2 = (User)o2;
return u1.name.compareTo(u2.name);
}
throw new RuntimeException("输入的类型不匹配");
}
};
TreeSet set = new TreeSet(comparator);
set.add(new User("Tom",12));
set.add(new User("Rose",23));
set.add(new User("Jerry",2));
set.add(new User("Eric",18));
set.add(new User("Tommy",44));
set.add(new User("Jim",23));
set.add(new User("Maria",18));
//set.add(new User("Maria",28));
Iterator iterator = set.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
5.4.3 练习
**练习1:**在一个List集合中存储了多个无大小顺序并且有重复的字符串,定义一个方法,让其有序(从小到大排序),并且不能去除重复元素。
提示:考查ArrayList、TreeSet
/**
*
* @Description
* @author 尚硅谷-宋红康
* @date 2022年4月7日上午12:50:46
*
*/
public class SortTest {
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add("ccc");
list.add("ccc");
list.add("aaa");
list.add("aaa");
list.add("bbb");
list.add("ddd");
list.add("ddd");
sort(list);
System.out.println(list);
}
/*
* 对集合中的元素排序,并保留重复
*/
public static void sort(List list) {
TreeSet ts = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) { // 重写compare方法
String s1 = (String)o1;
String s2 = (String)o2;
int num = s1.compareTo(s2); // 比较内容
return num == 0 ? 1 : num; // 如果内容一样返回一个不为0的数字即可
}
});
ts.addAll(list); // 将list集合中的所有元素添加到ts中
list.clear(); // 清空list
list.addAll(ts); // 将ts中排序并保留重复的结果在添加到list中
}
}
**练习2:**TreeSet的自然排序和定制排序
-
定义一个Employee类。
该类包含:private成员变量name,age,birthday,其中 birthday 为 MyDate 类的对象;
并为每一个属性定义 getter, setter 方法;
并重写 toString 方法输出 name, age, birthday -
MyDate类包含:
private成员变量year,month,day;并为每一个属性定义 getter, setter 方法; -
创建该类的 5 个对象,并把这些对象放入 TreeSet 集合中(下一章:TreeSet 需使用泛型来定义)
-
分别按以下两种方式对集合中的元素进行排序,并遍历输出:
1). 使Employee 实现 Comparable 接口,并按 name 排序
2). 创建 TreeSet 时传入 Comparator对象,按生日日期的先后排序。
代码实现:
public class MyDate implements Comparable{
private int year;
private int month;
private int day;
public MyDate() {
}
public MyDate(int year, int month, int day) {
this.year = year;
this.month = month;
this.day = day;
}
public int getYear() {
return year;
}
public void setYear(int year) {
this.year = year;
}
public int getMonth() {
return month;
}
public void setMonth(int month) {
this.month = month;
}
public int getDay() {
return day;
}
public void setDay(int day) {
this.day = day;
}
@Override
public String toString() {
// return "MyDate{" +
// "year=" + year +
// ", month=" + month +
// ", day=" + day +
// '}';
return year + "年" + month + "月" + day + "日";
}
@Override
public int compareTo(Object o) {
if(this == o){
return 0;
}
if(o instanceof MyDate){
MyDate myDate = (MyDate) o;
int yearDistance = this.getYear() - myDate.getYear();
if(yearDistance != 0){
return yearDistance;
}
int monthDistance = this.getMonth() - myDate.getMonth();
if(monthDistance != 0){
return monthDistance;
}
return this.getDay() - myDate.getDay();
}
throw new RuntimeException("输入的类型不匹配");
}
}
public class Employee implements Comparable{
private String name;
private int age;
private MyDate birthday;
public Employee() {
}
public Employee(String name, int age, MyDate birthday) {
this.name = name;
this.age = age;
this.birthday = birthday;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public MyDate getBirthday() {
return birthday;
}
public void setBirthday(MyDate birthday) {
this.birthday = birthday;
}
@Override
public String toString() {
return "Employee{" +
"name='" + name + '\'' +
", age='" + age + '\'' +
", birthday=" + birthday +
'}';
}
@Override
public int compareTo(Object o) {
if(o == this){
return 0;
}
if(o instanceof Employee){
Employee emp = (Employee) o;
return this.name.compareTo(emp.name);
}
throw new RuntimeException("传入的类型不匹配");
}
}
public class EmployeeTest {
/*
自然排序:
创建该类的 5 个对象,并把这些对象放入 TreeSet 集合中
* 需求1:使Employee 实现 Comparable 接口,并按 name 排序
* */
@Test
public void test1(){
TreeSet set = new TreeSet();
Employee e1 = new Employee("Tom",23,new MyDate(1999,7,9));
Employee e2 = new Employee("Rose",43,new MyDate(1999,7,19));
Employee e3 = new Employee("Jack",54,new MyDate(1998,12,21));
Employee e4 = new Employee("Jerry",12,new MyDate(2002,4,21));
Employee e5 = new Employee("Tony",22,new MyDate(2001,9,12));
set.add(e1);
set.add(e2);
set.add(e3);
set.add(e4);
set.add(e5);
//遍历
Iterator iterator = set.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
/*
* 定制排序:
* 创建 TreeSet 时传入 Comparator对象,按生日日期的先后排序。
* */
@Test
public void test2(){
Comparator comparator = new Comparator() {
@Override
public int compare(Object o1, Object o2) {
if(o1 instanceof Employee && o2 instanceof Employee){
Employee e1 = (Employee) o1;
Employee e2 = (Employee) o2;
//对比两个employee的生日的大小
MyDate birth1 = e1.getBirthday();
MyDate birth2 = e2.getBirthday();
//方式1:
// int yearDistance = birth1.getYear() - birth2.getYear();
// if(yearDistance != 0){
// return yearDistance;
// }
// int monthDistance = birth1.getMonth() - birth2.getMonth();
// if(monthDistance != 0){
// return monthDistance;
// }
//
// return birth1.getDay() - birth2.getDay();
//方式2:
return birth1.compareTo(birth2);
}
throw new RuntimeException("输入的类型不匹配");
}
};
TreeSet set = new TreeSet(comparator);
Employee e1 = new Employee("Tom",23,new MyDate(1999,7,9));
Employee e2 = new Employee("Rose",43,new MyDate(1999,7,19));
Employee e3 = new Employee("Jack",54,new MyDate(1998,12,21));
Employee e4 = new Employee("Jerry",12,new MyDate(2002,4,21));
Employee e5 = new Employee("Tony",22,new MyDate(2001,9,12));
set.add(e1);
set.add(e2);
set.add(e3);
set.add(e4);
set.add(e5);
//遍历
Iterator iterator = set.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
}
6. Map接口
现实生活与开发中,我们常会看到这样的一类集合:用户ID与账户信息、学生姓名与考试成绩、IP地址与主机名等,这种一一对应的关系,就称作映射。Java提供了专门的集合框架用来存储这种映射关系的对象,即java.util.Map接口。
6.1 Map接口概述
-
Map与Collection并列存在。用于保存具有
映射关系的数据:key-valueCollection集合称为单列集合,元素是孤立存在的(理解为单身)。Map集合称为双列集合,元素是成对存在的(理解为夫妻)。
-
Map 中的 key 和 value 都可以是任何引用类型的数据。但常用String类作为Map的“键”。
-
Map接口的常用实现类:
HashMap、LinkedHashMap、TreeMap和``Properties。其中,HashMap是 Map 接口使用频率最高`的实现类。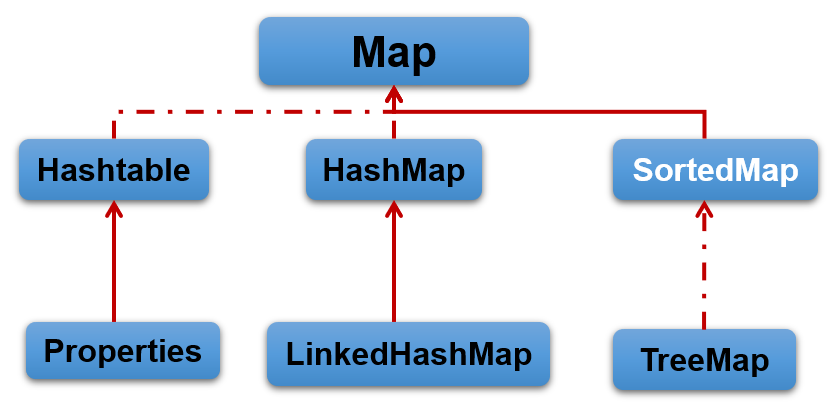
6.2 Map中key-value特点
这里主要以HashMap为例说明。HashMap中存储的key、value的特点如下:
-
Map 中的
key用Set来存放,不允许重复,即同一个 Map 对象所对应的类,须重写hashCode()和equals()方法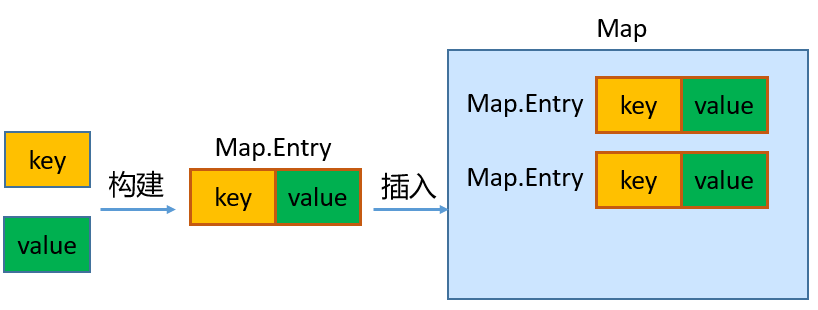
-
key 和 value 之间存在单向一对一关系,即通过指定的 key 总能找到唯一的、确定的 value,不同key对应的
value可以重复。value所在的类要重写equals()方法。 -
key和value构成一个entry。所有的entry彼此之间是
无序的、不可重复的。
6.2 Map接口的常用方法
- 添加、修改操作:
- Object put(Object key,Object value):将指定key-value添加到(或修改)当前map对象中
- void putAll(Map m):将m中的所有key-value对存放到当前map中
- 删除操作:
- Object remove(Object key):移除指定key的key-value对,并返回value
- void clear():清空当前map中的所有数据
- 元素查询的操作:
- Object get(Object key):获取指定key对应的value
- boolean containsKey(Object key):是否包含指定的key
- boolean containsValue(Object value):是否包含指定的value
- int size():返回map中key-value对的个数
- boolean isEmpty():判断当前map是否为空
- boolean equals(Object obj):判断当前map和参数对象obj是否相等
- 元视图操作的方法:
- Set keySet():返回所有key构成的Set集合
- Collection values():返回所有value构成的Collection集合
- Set entrySet():返回所有key-value对构成的Set集合
举例:
package com.atguigu.map;
import java.util.HashMap;
public class TestMapMethod {
public static void main(String[] args) {
//创建 map对象
HashMap map = new HashMap();
//添加元素到集合
map.put("黄晓明", "杨颖");
map.put("李晨", "李小璐");
map.put("李晨", "范冰冰");
map.put("邓超", "孙俪");
System.out.println(map);
//删除指定的key-value
System.out.println(map.remove("黄晓明"));
System.out.println(map);
//查询指定key对应的value
System.out.println(map.get("邓超"));
System.out.println(map.get("黄晓明"));
}
}
举例:
public static void main(String[] args) {
HashMap map = new HashMap();
map.put("许仙", "白娘子");
map.put("董永", "七仙女");
map.put("牛郎", "织女");
map.put("许仙", "小青");
System.out.println("所有的key:");
Set keySet = map.keySet();
for (Object key : keySet) {
System.out.println(key);
}
System.out.println("所有的value:");
Collection values = map.values();
for (Object value : values) {
System.out.println(value);
}
System.out.println("所有的映射关系:");
Set entrySet = map.entrySet();
for (Object mapping : entrySet) {
//System.out.println(entry);
Map.Entry entry = (Map.Entry) mapping;
System.out.println(entry.getKey() + "->" + entry.getValue());
}
}
6.3 Map的主要实现类:HashMap
6.3.1 HashMap概述
- HashMap是 Map 接口
使用频率最高的实现类。 - HashMap是线程不安全的。允许添加 null 键和 null 值。
- 存储数据采用的哈希表结构,底层使用
一维数组+单向链表+红黑树进行key-value数据的存储。与HashSet一样,元素的存取顺序不能保证一致。 - HashMap
判断两个key相等的标准是:两个 key 的hashCode值相等,通过 equals() 方法返回 true。 - HashMap
判断两个value相等的标准是:两个 value 通过 equals() 方法返回 true。
6.3.2 扩容
6.3.3 练习
**练习1:**添加你喜欢的歌手以及你喜欢他唱过的歌曲
例如:

//方式1
/**
* @author 尚硅谷-宋红康
* @create 9:03
*/
public class SingerTest1 {
public static void main(String[] args) {
//创建一个HashMap用于保存歌手和其歌曲集
HashMap singers = new HashMap();
//声明一组key,value
String singer1 = "周杰伦";
ArrayList songs1 = new ArrayList();
songs1.add("双节棍");
songs1.add("本草纲目");
songs1.add("夜曲");
songs1.add("稻香");
//添加到map中
singers.put(singer1,songs1);
//声明一组key,value
String singer2 = "陈奕迅";
List songs2 = Arrays.asList("浮夸", "十年", "红玫瑰", "好久不见", "孤勇者");
//添加到map中
singers.put(singer2,songs2);
//遍历map
Set entrySet = singers.entrySet();
for(Object obj : entrySet){
Map.Entry entry = (Map.Entry)obj;
String singer = (String) entry.getKey();
List songs = (List) entry.getValue();
System.out.println("歌手:" + singer);
System.out.println("歌曲有:" + songs);
}
}
}
//方式2:改为HashSet实现
public class SingerTest2 {
@Test
public void test1() {
Singer singer1 = new Singer("周杰伦");
Singer singer2 = new Singer("陈奕迅");
Song song1 = new Song("双节棍");
Song song2 = new Song("本草纲目");
Song song3 = new Song("夜曲");
Song song4 = new Song("浮夸");
Song song5 = new Song("十年");
Song song6 = new Song("孤勇者");
HashSet h1 = new HashSet();// 放歌手一的歌曲
h1.add(song1);
h1.add(song2);
h1.add(song3);
HashSet h2 = new HashSet();// 放歌手二的歌曲
h2.add(song4);
h2.add(song5);
h2.add(song6);
HashMap hashMap = new HashMap();// 放歌手和他对应的歌曲
hashMap.put(singer1, h1);
hashMap.put(singer2, h2);
for (Object obj : hashMap.keySet()) {
System.out.println(obj + "=" + hashMap.get(obj));
}
}
}
//歌曲
public class Song implements Comparable{
private String songName;//歌名
public Song() {
super();
}
public Song(String songName) {
super();
this.songName = songName;
}
public String getSongName() {
return songName;
}
public void setSongName(String songName) {
this.songName = songName;
}
@Override
public String toString() {
return "《" + songName + "》";
}
@Override
public int compareTo(Object o) {
if(o == this){
return 0;
}
if(o instanceof Song){
Song song = (Song)o;
return songName.compareTo(song.getSongName());
}
return 0;
}
}
//歌手
public class Singer implements Comparable{
private String name;
private Song song;
public Singer() {
super();
}
public Singer(String name) {
super();
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Song getSong() {
return song;
}
public void setSong(Song song) {
this.song = song;
}
@Override
public String toString() {
return name;
}
@Override
public int compareTo(Object o) {
if(o == this){
return 0;
}
if(o instanceof Singer){
Singer singer = (Singer)o;
return name.compareTo(singer.getName());
}
return 0;
}
}
练习2:二级联动
将省份和城市的名称保存在集合中,当用户选择省份以后,二级联动,显示对应省份的地级市供用户选择。
效果演示:

/**
*
* @Description
* @author 尚硅谷-宋红康 Email:shkstart@126.com
* @version
* @date 2021年5月7日上午12:26:59
*
*/
class CityMap{
public static Map model = new HashMap();
static {
model.put("北京", new String[] {"北京"});
model.put("上海", new String[] {"上海"});
model.put("天津", new String[] {"天津"});
model.put("重庆", new String[] {"重庆"});
model.put("黑龙江", new String[] {"哈尔滨","齐齐哈尔","牡丹江","大庆","伊春","双鸭山","绥化"});
model.put("吉林", new String[] {"长春","延边","吉林","白山","白城","四平","松原"});
model.put("河北", new String[] {"石家庄","张家口","邯郸","邢台","唐山","保定","秦皇岛"});
}
}
public class ProvinceTest {
public static void main(String[] args) {
Set keySet = CityMap.model.keySet();
for(Object s : keySet) {
System.out.print(s + "\t");
}
System.out.println();
System.out.println("请选择你所在的省份:");
Scanner scan = new Scanner(System.in);
String province = scan.next();
String[] citys = (String[])CityMap.model.get(province);
for(String city : citys) {
System.out.print(city + "\t");
}
System.out.println();
System.out.println("请选择你所在的城市:");
String city = scan.next();
System.out.println("信息登记完毕");
}
}
练习3:WordCount统计
需求:统计字符串中每个字符出现的次数
String str = “aaaabbbcccccccccc”;
提示:
char[] arr = str.toCharArray(); //将字符串转换成字符数组
HashMap hm = new HashMap(); //创建双列集合存储键和值,键放字符,值放次数
/**
*
* @author 尚硅谷-宋红康
* @date 2022年5月7日上午12:26:59
*
*/
public class WordCountTest {
public static void main(String[] args) {
String str = "aaaabbbcccccccccc";
char[] arr = str.toCharArray(); // 将字符串转换成字符数组
HashMap map = new HashMap(); // 创建双列集合存储键和值
for (char c : arr) { // 遍历字符数组
if (!map.containsKey(c)) { // 如果不包含这个键
map.put(c, 1); // 就将键和值为1添加
} else { // 如果包含这个键
map.put(c, (int)map.get(c) + 1); // 就将键和值再加1添加进来
}
}
for (Object key : map.keySet()) { // 遍历双列集合
System.out.println(key + "=" + map.get(key));
}
}
}
6.4 Map实现类之二:LinkedHashMap
- LinkedHashMap 是 HashMap 的子类
- 存储数据采用的哈希表结构+链表结构,在HashMap存储结构的基础上,使用了一对
双向链表来记录添加元素的先后顺序,可以保证遍历元素时,与添加的顺序一致。 - 通过哈希表结构可以保证键的唯一、不重复,需要键所在类重写hashCode()方法、equals()方法。
public class TestLinkedHashMap {
public static void main(String[] args) {
LinkedHashMap map = new LinkedHashMap();
map.put("王五", 13000.0);
map.put("张三", 10000.0);
//key相同,新的value会覆盖原来的value
//因为String重写了hashCode和equals方法
map.put("张三", 12000.0);
map.put("李四", 14000.0);
//HashMap支持key和value为null值
String name = null;
Double salary = null;
map.put(name, salary);
Set entrySet = map.entrySet();
for (Object obj : entrySet) {
Map.Entry entry = (Map.Entry)obj;
System.out.println(entry);
}
}
}
6.5 Map实现类之三:TreeMap
- TreeMap存储 key-value 对时,需要根据 key-value 对进行排序。TreeMap 可以保证所有的 key-value 对处于
有序状态。 - TreeSet底层使用
红黑树结构存储数据 - TreeMap 的 Key 的排序:
自然排序:TreeMap 的所有的 Key 必须实现 Comparable 接口,而且所有的 Key 应该是同一个类的对象,否则将会抛出 ClasssCastException定制排序:创建 TreeMap 时,构造器传入一个 Comparator 对象,该对象负责对 TreeMap 中的所有 key 进行排序。此时不需要 Map 的 Key 实现 Comparable 接口
- TreeMap判断
两个key相等的标准:两个key通过compareTo()方法或者compare()方法返回0。
/**
* @author 尚硅谷-宋红康
* @create 1:23
*/
public class TestTreeMap {
/*
* 自然排序举例
* */
@Test
public void test1(){
TreeMap map = new TreeMap();
map.put("CC",45);
map.put("MM",78);
map.put("DD",56);
map.put("GG",89);
map.put("JJ",99);
Set entrySet = map.entrySet();
for(Object entry : entrySet){
System.out.println(entry);
}
}
/*
* 定制排序
*
* */
@Test
public void test2(){
//按照User的姓名的从小到大的顺序排列
TreeMap map = new TreeMap(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
if(o1 instanceof User && o2 instanceof User){
User u1 = (User)o1;
User u2 = (User)o2;
return u1.name.compareTo(u2.name);
}
throw new RuntimeException("输入的类型不匹配");
}
});
map.put(new User("Tom",12),67);
map.put(new User("Rose",23),"87");
map.put(new User("Jerry",2),88);
map.put(new User("Eric",18),45);
map.put(new User("Tommy",44),77);
map.put(new User("Jim",23),88);
map.put(new User("Maria",18),34);
Set entrySet = map.entrySet();
for(Object entry : entrySet){
System.out.println(entry);
}
}
}
class User implements Comparable{
String name;
int age;
public User(String name, int age) {
this.name = name;
this.age = age;
}
public User() {
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
/*
举例:按照age从小到大的顺序排列,如果age相同,则按照name从大到小的顺序排列
* */
@Override
public int compareTo(Object o) {
if(this == o){
return 0;
}
if(o instanceof User){
User user = (User)o;
int value = this.age - user.age;
if(value != 0){
return value;
}
return -this.name.compareTo(user.name);
}
throw new RuntimeException("输入的类型不匹配");
}
}
6.6 Map实现类之四:Hashtable
- Hashtable是Map接口的
古老实现类,JDK1.0就提供了。不同于HashMap,Hashtable是线程安全的。 - Hashtable实现原理和HashMap相同,功能相同。底层都使用哈希表结构(数组+单向链表),查询速度快。
- 与HashMap一样,Hashtable 也不能保证其中 Key-Value 对的顺序
- Hashtable判断两个key相等、两个value相等的标准,与HashMap一致。
- 与HashMap不同,Hashtable 不允许使用 null 作为 key 或 value。
面试题:Hashtable和HashMap的区别
HashMap:底层是一个哈希表(jdk7:数组+链表;jdk8:数组+链表+红黑树),是一个线程不安全的集合,执行效率高
Hashtable:底层也是一个哈希表(数组+链表),是一个线程安全的集合,执行效率低
HashMap集合:可以存储null的键、null的值
Hashtable集合,不能存储null的键、null的值
Hashtable和Vector集合一样,在jdk1.2版本之后被更先进的集合(HashMap,ArrayList)取代了。所以HashMap是Map的主要实现类,Hashtable是Map的古老实现类。
Hashtable的子类Properties(配置文件)依然活跃在历史舞台
Properties集合是一个唯一和IO流相结合的集合
6.7 Map实现类之五:Properties
-
Properties 类是 Hashtable 的子类,该对象用于处理属性文件
-
由于属性文件里的 key、value 都是字符串类型,所以 Properties 中要求 key 和 value 都是字符串类型
-
存取数据时,建议使用setProperty(String key,String value)方法和getProperty(String key)方法
@Test
public void test01() {
Properties properties = System.getProperties();
String fileEncoding = properties.getProperty("file.encoding");//当前源文件字符编码
System.out.println("fileEncoding = " + fileEncoding);
}
@Test
public void test02() {
Properties properties = new Properties();
properties.setProperty("user","songhk");
properties.setProperty("password","123456");
System.out.println(properties);
}
@Test
public void test03() throws IOException {
Properties pros = new Properties();
pros.load(new FileInputStream("jdbc.properties"));
String user = pros.getProperty("user");
System.out.println(user);
}
7. Collections工具类
参考操作数组的工具类:Arrays,Collections 是一个操作 Set、List 和 Map 等集合的工具类。
7.1 常用方法
Collections 中提供了一系列静态的方法对集合元素进行排序、查询和修改等操作,还提供了对集合对象设置不可变、对集合对象实现同步控制等方法(均为static方法):
排序操作:
- reverse(List):反转 List 中元素的顺序
- shuffle(List):对 List 集合元素进行随机排序
- sort(List):根据元素的自然顺序对指定 List 集合元素按升序排序
- sort(List,Comparator):根据指定的 Comparator 产生的顺序对 List 集合元素进行排序
- swap(List,int, int):将指定 list 集合中的 i 处元素和 j 处元素进行交换
查找
- Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素
- Object max(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最大元素
- Object min(Collection):根据元素的自然顺序,返回给定集合中的最小元素
- Object min(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最小元素
- int binarySearch(List list,T key)在List集合中查找某个元素的下标,但是List的元素必须是T或T的子类对象,而且必须是可比较大小的,即支持自然排序的。而且集合也事先必须是有序的,否则结果不确定。
- int binarySearch(List list,T key,Comparator c)在List集合中查找某个元素的下标,但是List的元素必须是T或T的子类对象,而且集合也事先必须是按照c比较器规则进行排序过的,否则结果不确定。
- int frequency(Collection c,Object o):返回指定集合中指定元素的出现次数
复制、替换
- void copy(List dest,List src):将src中的内容复制到dest中
- boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换 List 对象的所有旧值
- 提供了多个unmodifiableXxx()方法,该方法返回指定 Xxx的不可修改的视图。
添加
- boolean addAll(Collection c,T… elements)将所有指定元素添加到指定 collection 中。
同步
- Collections 类中提供了多个 synchronizedXxx() 方法,该方法可使将指定集合包装成线程同步的集合,从而可以解决多线程并发访问集合时的线程安全问题:
7.2 举例
package com.atguigu.collections;
import org.junit.Test;
import java.text.Collator;
import java.util.*;
public class TestCollections {
@Test
public void test01(){
/*
public static <T> boolean addAll(Collection<? super T> c,T... elements)
将所有指定元素添加到指定 collection 中。Collection的集合的元素类型必须>=T类型
*/
Collection<Object> coll = new ArrayList<>();
Collections.addAll(coll, "hello","java");
Collections.addAll(coll, 1,2,3,4);
Collection<String> coll2 = new ArrayList<>();
Collections.addAll(coll2, "hello","java");
//Collections.addAll(coll2, 1,2,3,4);//String和Integer之间没有父子类关系
}
@Test
public void test02(){
/*
* public static <T extends Object & Comparable<? super T>> T max(Collection<? extends T> coll)
* 在coll集合中找出最大的元素,集合中的对象必须是T或T的子类对象,而且支持自然排序
*
* public static <T> T max(Collection<? extends T> coll,Comparator<? super T> comp)
* 在coll集合中找出最大的元素,集合中的对象必须是T或T的子类对象,按照比较器comp找出最大者
*
*/
List<Man> list = new ArrayList<>();
list.add(new Man("张三",23));
list.add(new Man("李四",24));
list.add(new Man("王五",25));
/*
* Man max = Collections.max(list);//要求Man实现Comparable接口,或者父类实现
* System.out.println(max);
*/
Man max = Collections.max(list, new Comparator<Man>() {
@Override
public int compare(Man o1, Man o2) {
return o2.getAge()-o2.getAge();
}
});
System.out.println(max);
}
@Test
public void test03(){
/*
* public static void reverse(List<?> list)
* 反转指定列表List中元素的顺序。
*/
List<String> list = new ArrayList<>();
Collections.addAll(list,"hello","java","world");
System.out.println(list);
Collections.reverse(list);
System.out.println(list);
}
@Test
public void test04(){
/*
* public static void shuffle(List<?> list)
* List 集合元素进行随机排序,类似洗牌,打乱顺序
*/
List<String> list = new ArrayList<>();
Collections.addAll(list,"hello","java","world");
Collections.shuffle(list);
System.out.println(list);
}
@Test
public void test05() {
/*
* public static <T extends Comparable<? super T>> void sort(List<T> list)
* 根据元素的自然顺序对指定 List 集合元素按升序排序
*
* public static <T> void sort(List<T> list,Comparator<? super T> c)
* 根据指定的 Comparator 产生的顺序对 List 集合元素进行排序
*/
List<Man> list = new ArrayList<>();
list.add(new Man("张三",23));
list.add(new Man("李四",24));
list.add(new Man("王五",25));
Collections.sort(list);
System.out.println(list);
Collections.sort(list, new Comparator<Man>() {
@Override
public int compare(Man o1, Man o2) {
return Collator.getInstance(Locale.CHINA).compare(o1.getName(),o2.getName());
}
});
System.out.println(list);
}
@Test
public void test06(){
/*
* public static void swap(List<?> list,int i,int j)
* 将指定 list 集合中的 i 处元素和 j 处元素进行交换
*/
List<String> list = new ArrayList<>();
Collections.addAll(list,"hello","java","world");
Collections.swap(list,0,2);
System.out.println(list);
}
@Test
public void test07(){
/*
* public static int frequency(Collection<?> c,Object o)
* 返回指定集合中指定元素的出现次数
*/
List<String> list = new ArrayList<>();
Collections.addAll(list,"hello","java","world","hello","hello");
int count = Collections.frequency(list, "hello");
System.out.println("count = " + count);
}
@Test
public void test08(){
/*
* public static <T> void copy(List<? super T> dest,List<? extends T> src)
* 将src中的内容复制到dest中
*/
List<Integer> list = new ArrayList<>();
for(int i=1; i<=5; i++){//1-5
list.add(i);
}
List<Integer> list2 = new ArrayList<>();
for(int i=11; i<=13; i++){//11-13
list2.add(i);
}
Collections.copy(list, list2);
System.out.println(list);
List<Integer> list3 = new ArrayList<>();
for(int i=11; i<=20; i++){//11-20
list3.add(i);
}
//java.lang.IndexOutOfBoundsException: Source does not fit in dest
//Collections.copy(list, list3);
//System.out.println(list);
}
@Test
public void test09(){
/*
* public static <T> boolean replaceAll(List<T> list,T oldVal,T newVal)
* 使用新值替换 List 对象的所有旧值
*/
List<String> list = new ArrayList<>();
Collections.addAll(list,"hello","java","world","hello","hello");
Collections.replaceAll(list, "hello","song");
System.out.println(list);
}
}
7.3 练习
练习1:
请从键盘随机输入10个整数保存到List中,并按倒序、从大到小的顺序显示出来
**练习2:**模拟斗地主洗牌和发牌,牌没有排序
效果演示:

提示:
String[] num = {"A","2","3","4","5","6","7","8","9","10","J","Q","K"};
String[] color = {"方片","梅花","红桃","黑桃"};
ArrayList<String> poker = new ArrayList<>();
代码示例:
/**
*
* @author 尚硅谷-宋红康
* @date 2022年5月7日上午12:26:59
*
*/
public class PokerTest {
public static void main(String[] args) {
String[] num = {"A","2","3","4","5","6","7","8","9","10","J","Q","K"};
String[] color = {"方片","梅花","红桃","黑桃"};
ArrayList poker = new ArrayList();
//1. 生成54张扑克牌
for (String s1 : color) {
for (String s2 : num) {
poker.add(s1.concat(" " + s2));
}
}
poker.add("小王");
poker.add("大王");
//2. 洗牌
Collections.shuffle(poker);
//3. 发牌
ArrayList tomCards = new ArrayList();
ArrayList jerryCards = new ArrayList();
ArrayList meCards = new ArrayList();
ArrayList lastCards = new ArrayList();
for (int i = 0; i < poker.size(); i++) {
if(i >= poker.size() - 3){
lastCards.add(poker.get(i));
}else if(i % 3 == 0){
tomCards.add(poker.get(i));
}else if(i % 3 == 1){
jerryCards.add(poker.get(i));
}else {
meCards.add(poker.get(i));
}
}
//4. 看牌
System.out.println("Tom:\n" + tomCards);
System.out.println("Jerry:\n" + jerryCards);
System.out.println("me:\n" + meCards);
System.out.println("底牌:\n" + lastCards);
}
}
**练习3:**模拟斗地主洗牌和发牌并对牌进行排序的代码实现。

提示:考查HashMap、TreeSet、ArrayList、Collections
代码示例:
/**
* @author 尚硅谷-宋红康
* @create 0:23
*/
public class PokerTest1 {
public static void main(String[] args) {
String[] num = {"3", "4", "5", "6", "7", "8", "9", "10", "J", "Q", "K", "A", "2"};
String[] color = {"方片", "梅花", "红桃", "黑桃"};
HashMap map = new HashMap(); // 存储索引和扑克牌
ArrayList list = new ArrayList(); // 存储索引
int index = 0; // 索引的开始值
for (String s1 : num) {
for (String s2 : color) {
map.put(index, s2.concat(s1)); // 将索引和扑克牌添加到HashMap中
list.add(index); // 将索引添加到ArrayList集合中
index++;
}
}
map.put(index, "小王");
list.add(index);
index++;
map.put(index, "大王");
list.add(index);
// 洗牌
Collections.shuffle(list);
// 发牌
TreeSet Tom = new TreeSet();
TreeSet Jerry = new TreeSet();
TreeSet me = new TreeSet();
TreeSet lastCards = new TreeSet();
for (int i = 0; i < list.size(); i++) {
if (i >= list.size() - 3) {
lastCards.add(list.get(i)); // 将list集合中的索引添加到TreeSet集合中会自动排序
} else if (i % 3 == 0) {
Tom.add(list.get(i));
} else if (i % 3 == 1) {
Jerry.add(list.get(i));
} else {
me.add(list.get(i));
}
}
// 看牌
lookPoker("Tom", Tom, map);
lookPoker("Jerry", Jerry, map);
lookPoker("康师傅", me, map);
lookPoker("底牌", lastCards, map);
}
public static void lookPoker(String name, TreeSet ts, HashMap map) {
System.out.println(name + "的牌是:");
for (Object index : ts) {
System.out.print(map.get(index) + " ");
}
System.out.println();
}
}














 1229
1229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









