







文章目录
正则表达式在线测试工具:
http://regex101.com
如图:
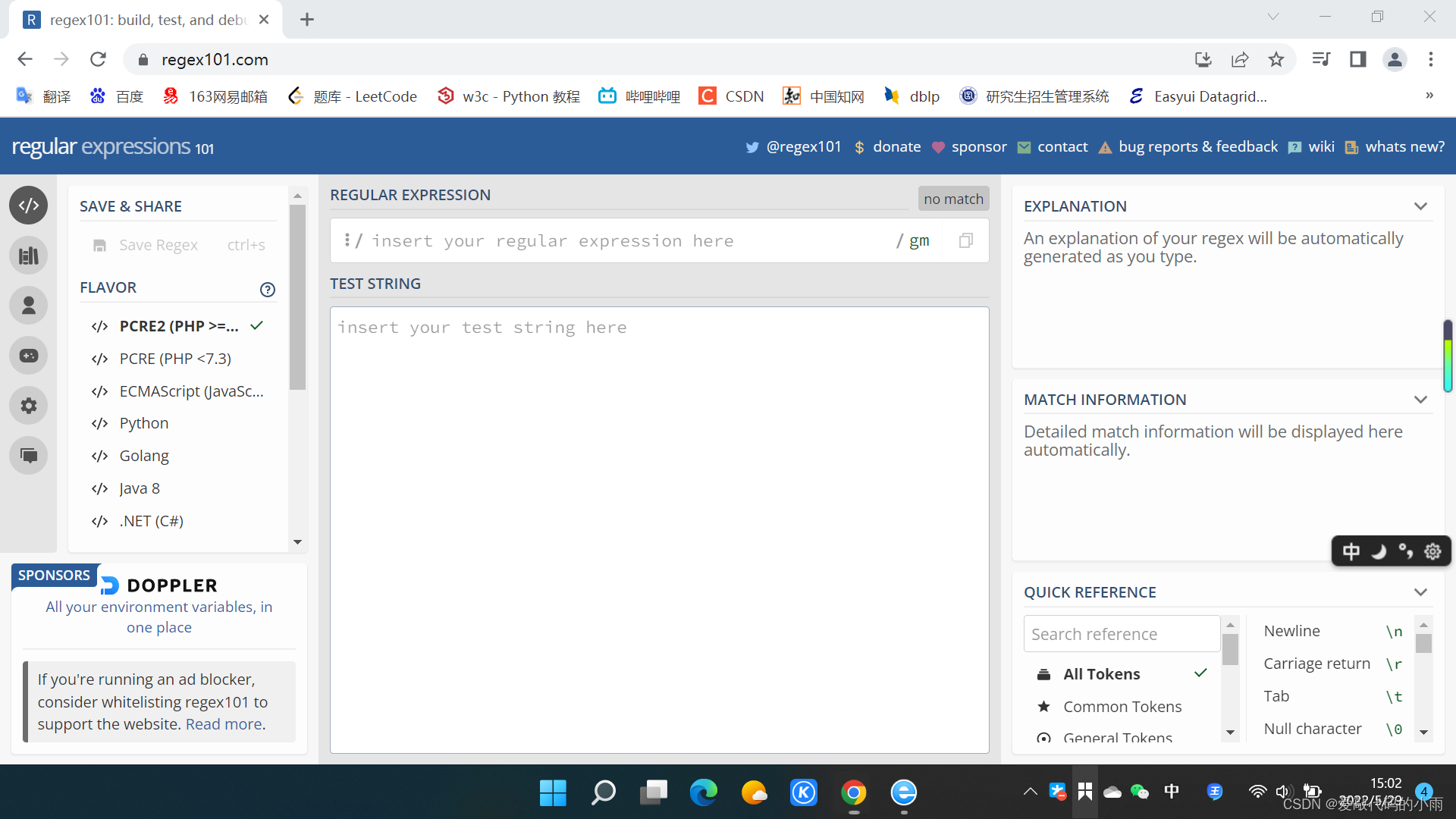
下面是要测试的文本,上面是正则表达式,左边可以选择正则表达式在不同语言下的变体,右边是帮助信息和参考文档。
正则表达式中最基础的用法:
限定符:
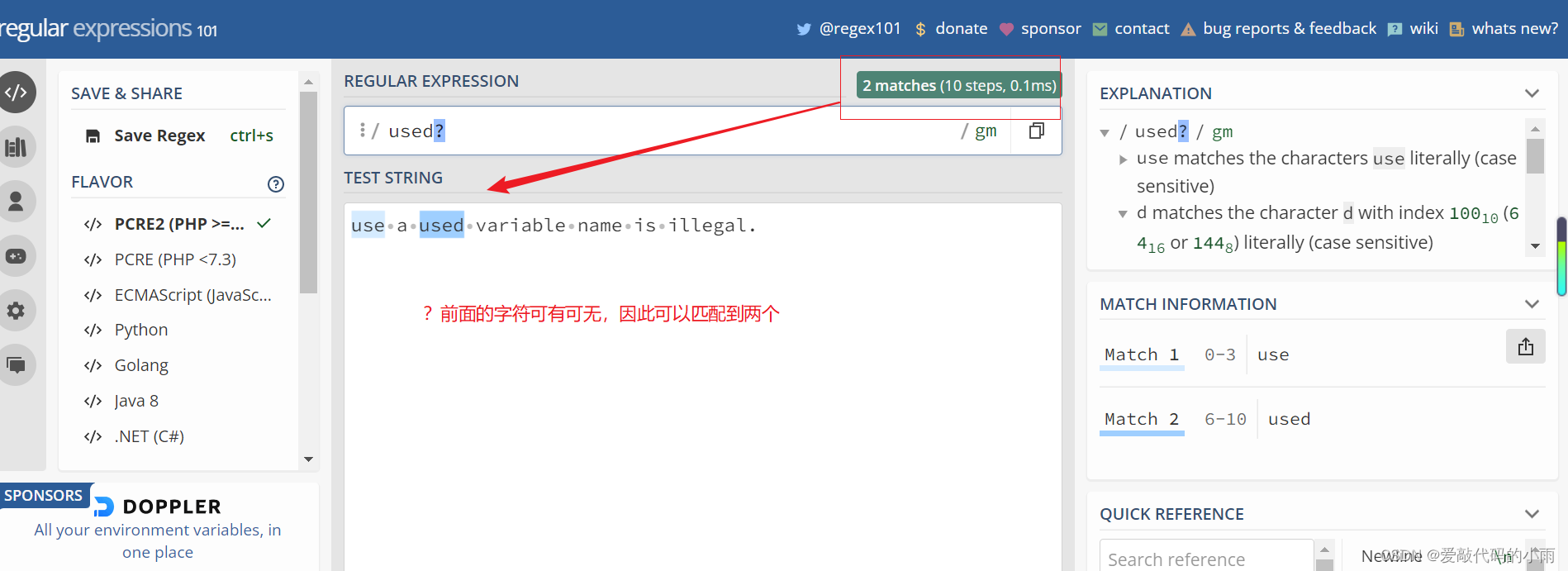
1*. ? 它前面的字符需要出现0次或者1次(也就是?前面的字符可有可无)。例如:
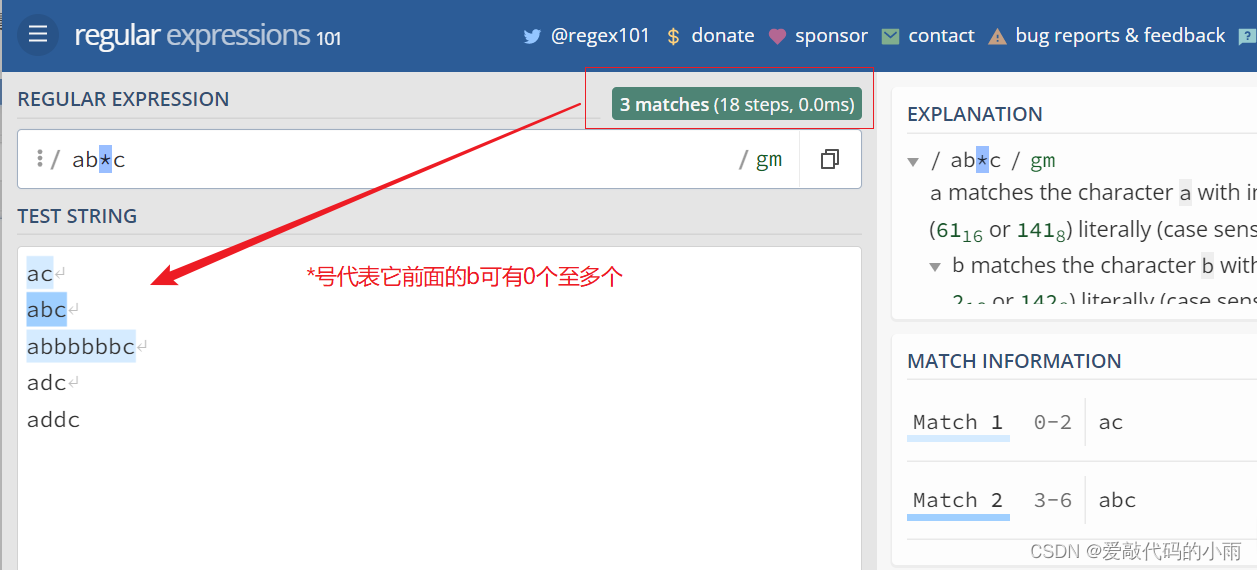
2*. * 它会去匹配0个或多个字符。例如:
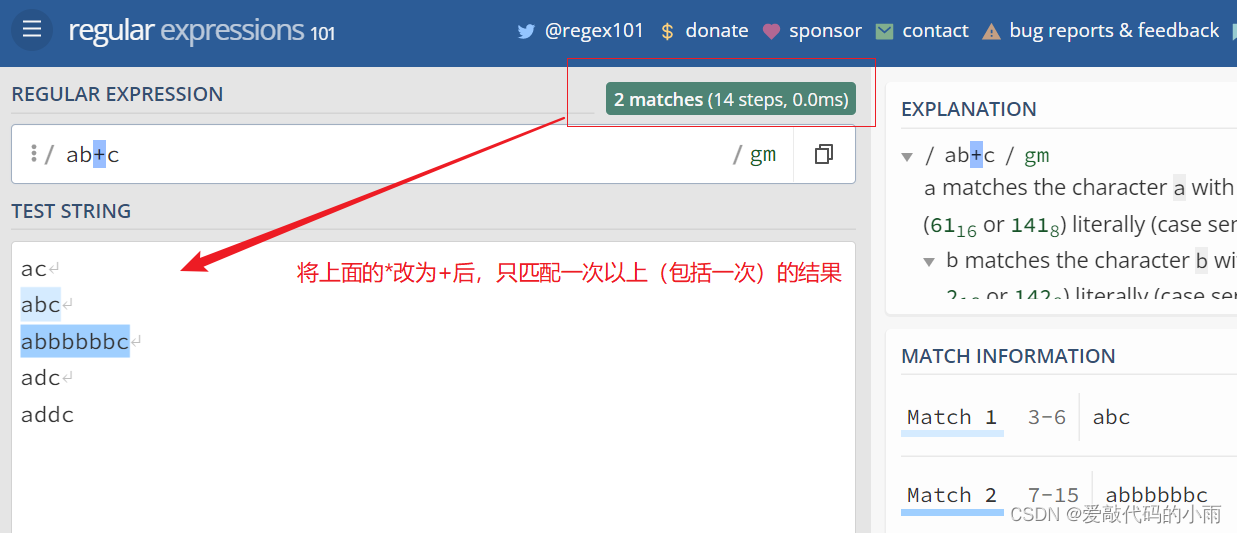
3*. + 它会匹配出现一次以上的字符。例如:
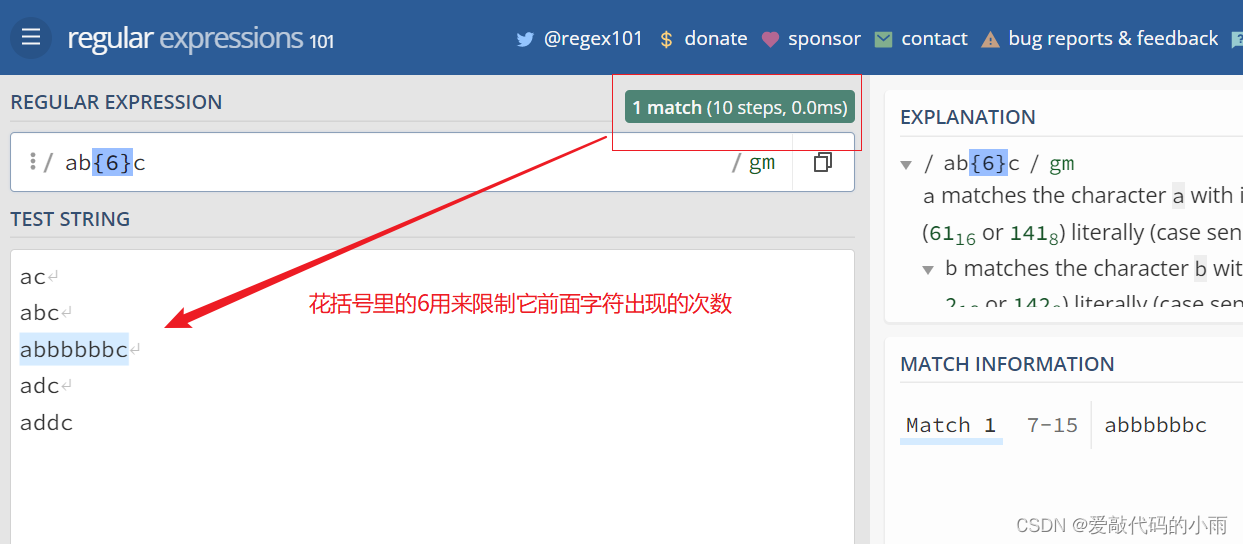
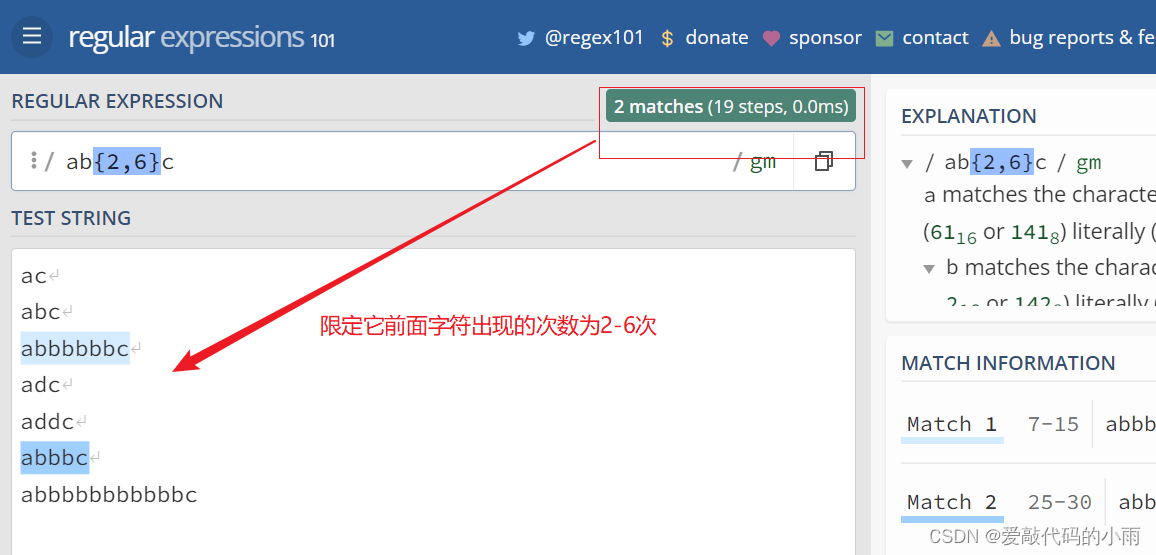
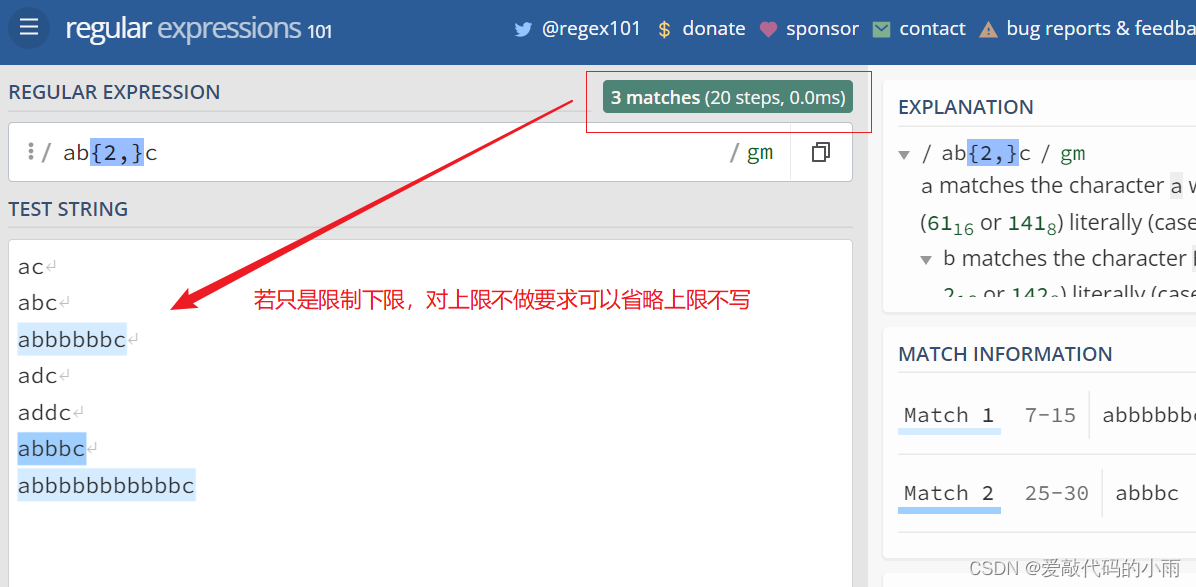
4*. 若想更精确匹配,限定匹配的次数,可以使用{ … }来限定。可以限定出现的次数,也可以限定出现次数的范围。例如:
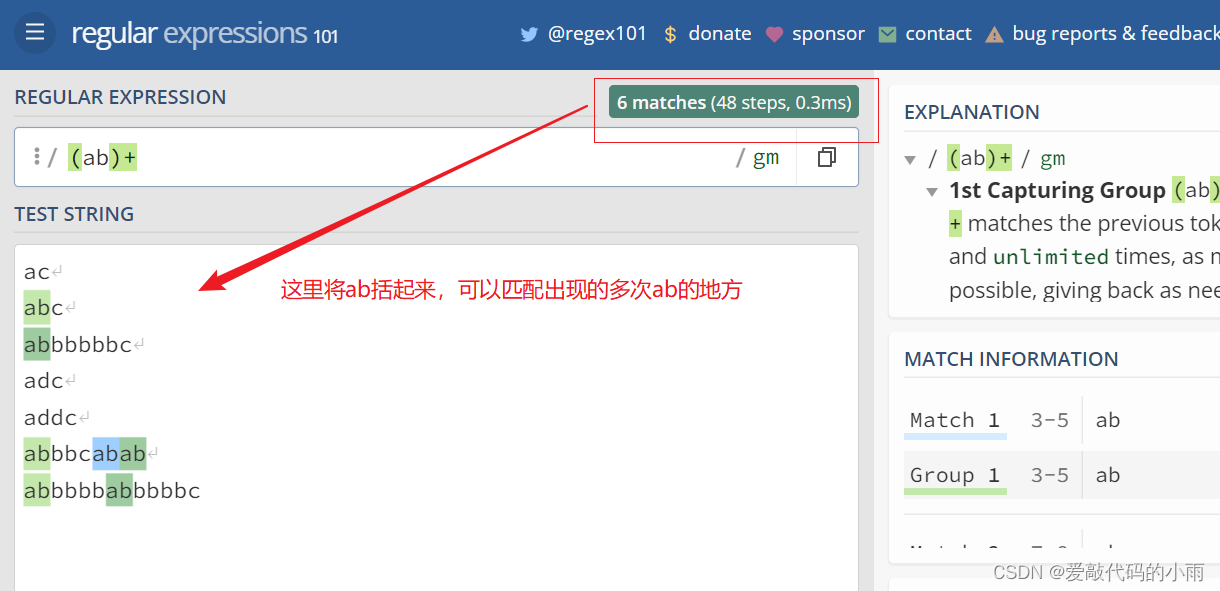
前面是对一个字符的限定,若希望对多个字符进行限定,可加括号,将希望匹配的字符括起来。例如:
正则表达式中的 “ 或 ”运算符:
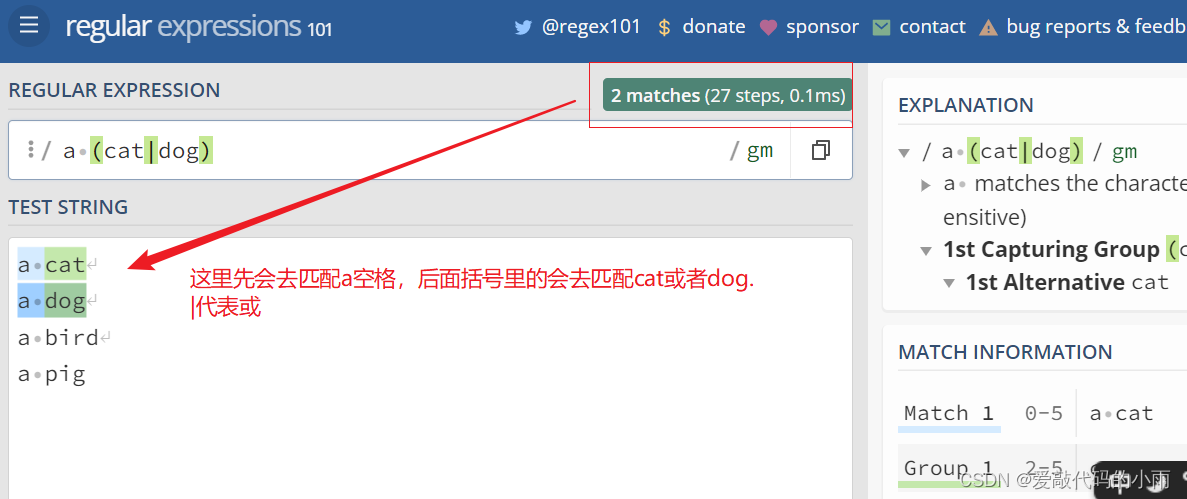
注意:或运算中或是必不可少的
字符类:
比如想匹配由字母abc这几个字母构成的单词,我们可以写成[ abc ]+ ,方括号中的内容代表我们想要去匹配的字符只能取自他们。
另外我们可以在方括号里指定字符的范围,比如[a-z]代表所有的小写英文字符,[a-zA-Z] 代表所有的大写英文字符,[a-zA-Z0-9] 代表所有的英文字符和数字。
如果在方括号的前面我们写一个尖号(脱字符^),则代表要求匹配除了尖号后面列出的【以外】的字符.比如[ ^ 0-9]+ 代表所有的非数字字符(包括换行符)。
元字符:
预先定义好的一系列常用字符类型:比如数字、空白符、单词开头、结尾等他们被称作元字符。
正则表达式中的大多数元字符都是以反斜杠开头。
\d代表数字字符等同于之前写的[0-9]+ ,
\w代表“单词”字符(英文、数字及下划线)也就是所有的英文字符 ,
\s代表空白符(包括Tab和换行符)
\D代表非数字字符
\W代表非单词字符
\S代表非空白字符
.代表任意字符,但不包括换行符
^匹配行首,例如 ^a 只会去匹配行首的a
$匹配行尾,例如 a $ 只会去匹配行尾的a
高级概念:
贪婪与懒惰匹配:
<.+> 默认贪婪匹配“任意字符”
<.+?> 懒惰匹配“任意字符”
之前说的* + {} 在匹配字符串时都是尽可能多的字符,可在+后面加一个问号,它会将正则表达式中默认的贪婪匹配切换为懒惰匹配。
下面是举例说明:
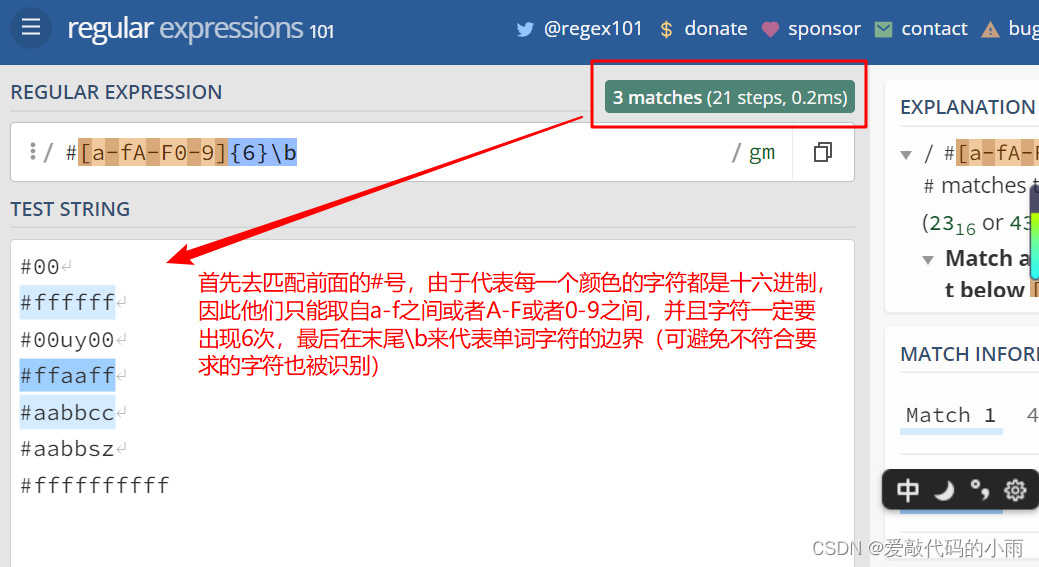
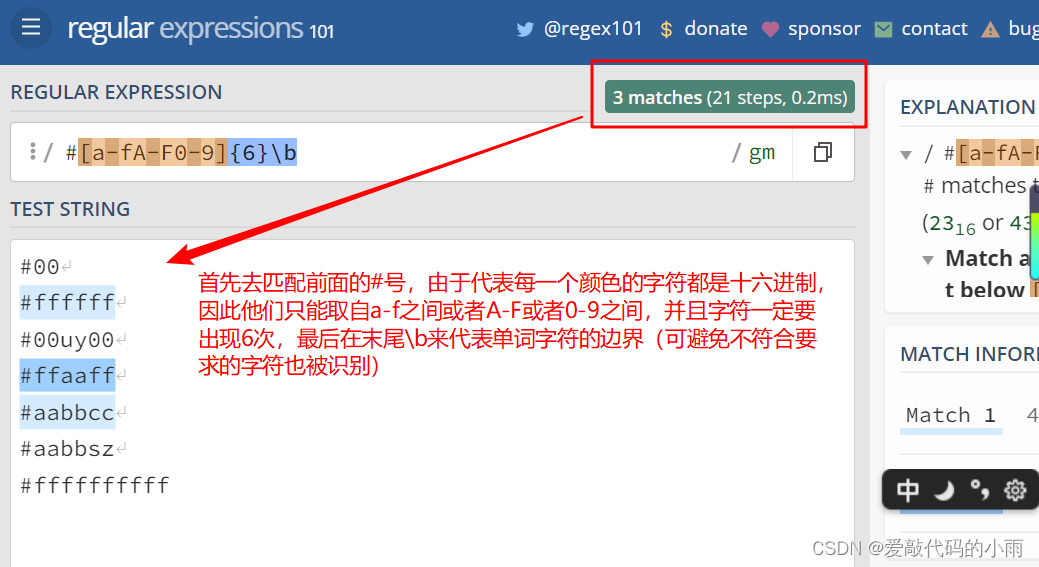
例1:RGB的匹配
例2:IP地址的匹配














 616
616











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









