







目录
1.Tensorflow实现
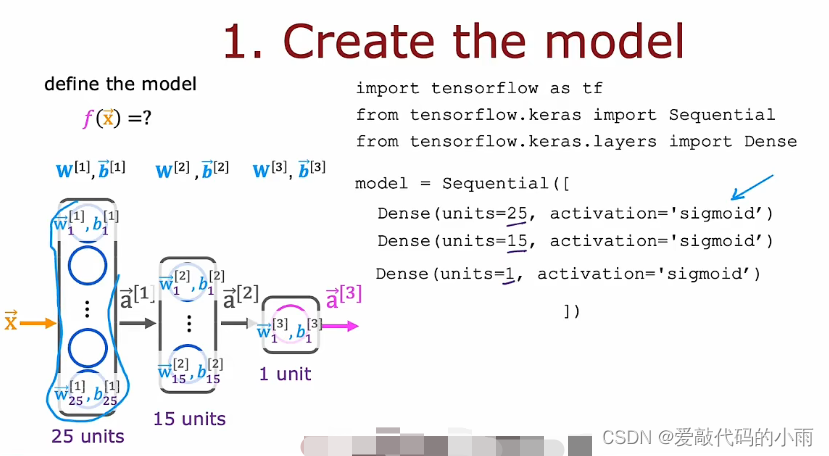
继续手写数字识别的运行示例,将此图像识别为0或1。这里我们使用的是如下神经网络架构。上周我们有一个输入x,即图像;第一层有25个神经元,第二层有15个神经元,输出层有一个神经元,如下所示:
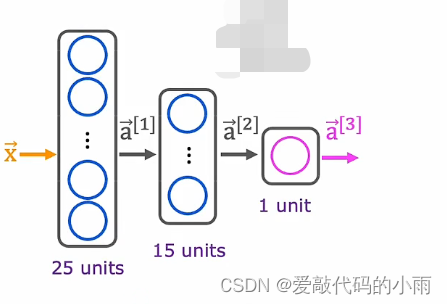
如果给你一个包含图像x的训练样本集,像标记为y的证明一样, 你将如何训练这个新网络的参数?下面是在tensorflow中用于训练此网络的代码:(第一部分和上周一样,用Sequential函数将三个层串起来;第二部分是让tensorflow编译模型并告诉tensorflow模型最关键的编译模式是指定你要使用的最后一个函数是什么(这里是loss),在这种情况下,我们将使用稀疏分类交叉熵这个名称(BinaryCrossentropy),第三步指定了最后一个函数fit告诉tensorflow使用最后一个来拟合你在步骤①中指定的模型 ②到数据集X Y)如下所示:

我们必须决定运行多少步来创建以及运行多长时间来创建。epochs是一个技术术语,表示你可能想要运行多少步来创建descent。
注:上图第一步是告诉tensorflow如何计算推理;第二步是用的函数;第三步是训练模型。
2.模型训练细节
在查看神经网络训练的细节之前,来回想一下之前是如何训练逻辑回归模型的:
建立逻辑回归模型的第一步是你会指定如何在给定输入特征x和参数w和b的情况下计算输出。也就是指定逻辑回归的输入输出函数。这取决于输入x和模型的参数。上周我们说逻辑回归模型是预测x的f等于g,应用于w·x+b的sigmoid函数。
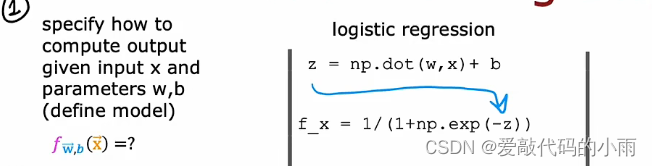
第二步是训练识字回归模型,指定损失函数和成本函数:
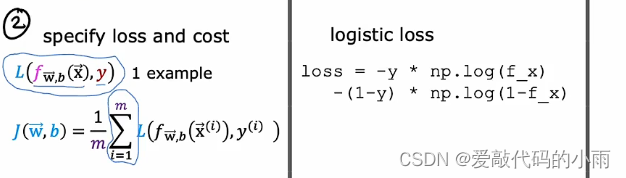
第三步也是最后一步是使用算法,最小化我们训练逻辑回归的成本函数。特别是梯度下降以最小化成本函数J(w,b)将其最小化,为参数w和b的函数。我们使用梯度下降最小化作为参数函数的成本函数J。
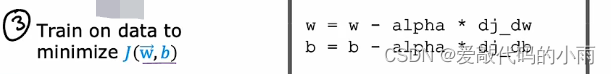
现在让我们来看以上三步如何映射到训练神经网络的:
第一步是计算给定输入x的输出和用这个熟悉的代码片段完成的参数w和b,上周指定的神经网络,这实际上足以指定向前传播所需的计算或推理。
第二步时编译模型并告诉它你想使用什么损失函数的代码。二元交叉熵损失函数,一旦你指定这个损失取平均值,整个训练集还为你提供神经网络的成本函数。
第三步是调用函数以尽量减少成本 神经网络参数的函数。

现在更详细地了解这三个步骤训练神经网络的上下文 ,以下代码指定了整个架构。
数字分类问题是一个二元分类问题,目前最常见,我们要使用的损失函数是这个实际上与我们使用的损失函数相同,但在Tensorflow的术语中,这种损失函数陈为二元交叉熵,语法是使用这个损失函数来编译神经网络。

在指定了单个训练示例的损失后,TensorFlow知道你想要最小化的成本是平均值,取所有训练样例的平均值,所有训练示例的损失。优化这个成本函数将导致神经网络适合你的二进制分类数据。
如果你想解决回归问题而不是分类问题,你可以告诉TensorFlow使用不同的损失函数来编译你的模型。
如果你使用梯度下降来训练神经网络的参数,那么你是重复的对每一层l和每个单元j,根据wlj减去学习率更新wlj。
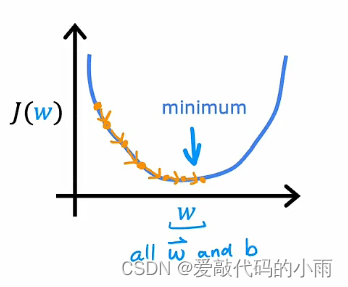
事实上,神经网络训练的标准是使用一种反向传播的算法来计算这些偏导数项。tensorflow在名为fit的函数中实现了反向传播,所以我们需要做的就是调用model.fit , x ,y 作为你的训练集,并告诉它这样做100次迭代或100个epoch

直接使用库,今天使用TensorFlow或PyTorch之类的库
3.Sigmoid激活函数的替代方案
到目前为止,我们一直在隐藏层和输出层的所有节点中使用sigmoid激活函数。我们之所以这样做是因为我们通过逻辑回归和创建许多逻辑回归单元并将它们串在一起。 但如果你使用其它激活函数,你的神经网络会变得更加强大。
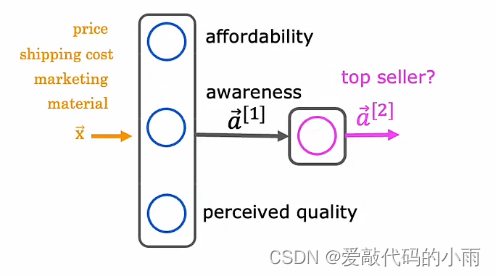
回想上周的需求预测示例,其中给定价格,运输成本,市场,材料,你尝试预测某些东西是否非常实惠,如果有良好的认知度和高感知质量,并以此为基础尝试预测它是畅销产品。但这假设意识可能是二元的,人们要么知道,要么不知道。
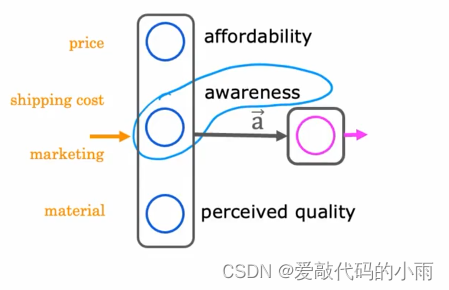
但潜在买家对你所售的T恤的了解可能不是二元的,它们可能有点了解,有点熟悉,非常熟悉或者可能已经完全熟悉了。因此,与其将意识建模为一个很小的数字0,1,不如尝试估计意识的概率,并不是建模意识只是一个介于0和1之间的数字。也许意识应该是如何非负数,因为意识的任何非负值都可以从0到非常大的数字。
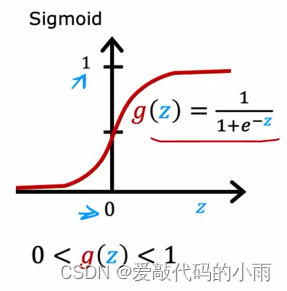
因此之前我们使用下图这个方程来计算第二个隐藏单元意识的激活。其中g是sigmoid函数,介于0和1之间。
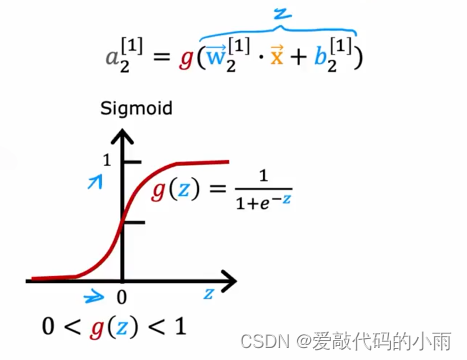
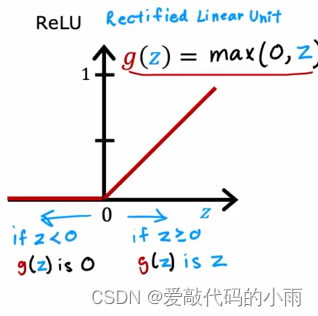
如果你想允许这个预测值a2潜在地采用更大的正值,我们可以换成不同的激活函数。事实证明,神经网络中一个非常常见的激活函数选择就是下图这个函数
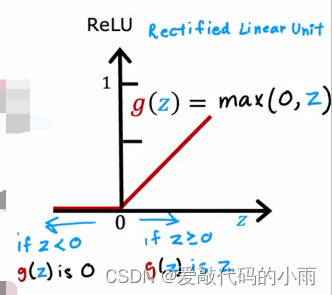
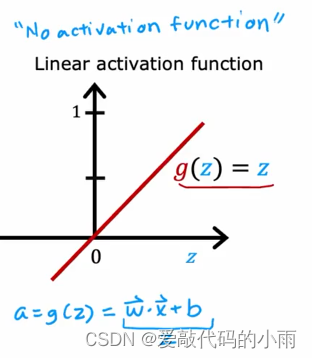
以下是最常用的激活函数:
4.如何选择激活函数
激活函数的选择取决于目标标签或真实标签是什么。
你可以选择不同的激活函数,神经网络中的不同神经元,在考虑激活函数的选择时,事实证明,通常输出层的激活函数将有一个相当自然的选择取决于什么目标输出。
具体来说,
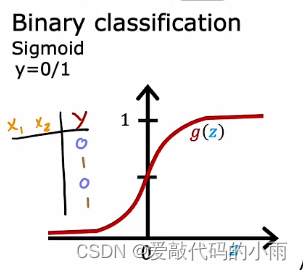
①如果你正在处理y为0或1的分类问题,所以是一个二分类问题,然后sigmoid函数是最自然的选择, 因为神经网络学会了预测等于1的概率,就像我们对逻辑回归所做的那样。所以二分类问题选择下图所示函数:
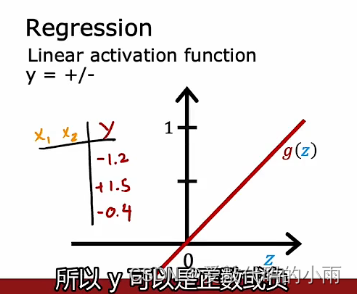
②如果你正在解决回归问题,那么你可能会选择不同的激活函数。例如,如果你试图预测明天的股票价格与今天的股价相比变化,它可能上升或下降,所以在这种情况下,y可以是一个积极或消极的,这种情况下,一般使用下图所示线性激活函数:(因为你的神经网络的输出可以取正值或负值,所以y可以是正数或负数)
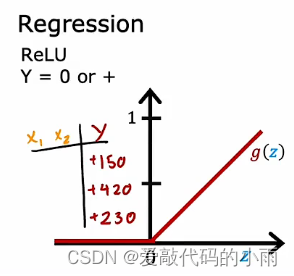
③如果y只能取非负值,例如,你要预测房子的价格,那永远不会是负数,所以最自然的选择是ReLU激活函数,因为正如下图所示,仅此激活函数取非负值。
在选择用于输出层的激活函数时,通常取决于你要预测的标签y是什么。
以上是对于输出层来说,下面来看隐藏层:
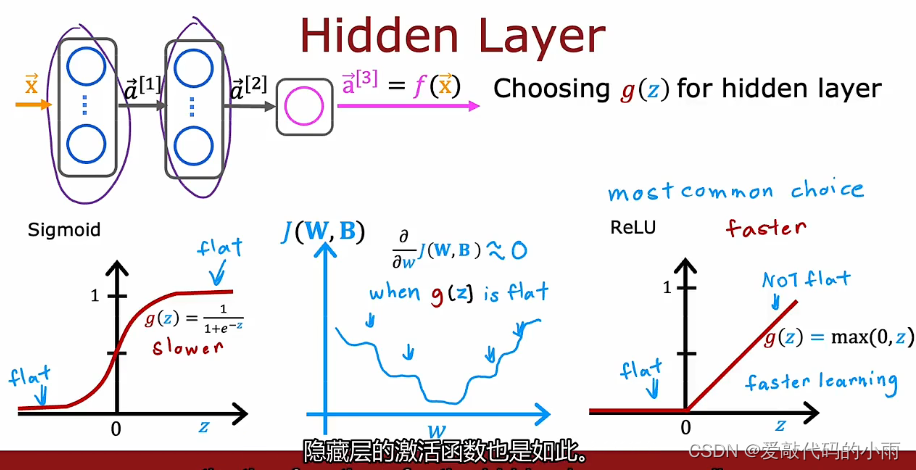
事实证明,ReLU激活函数是迄今为止神经网络中最常见的选择。
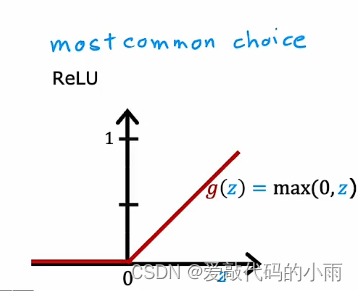
尽管我们最初使用sigmoid激活函数描述了神经网络,事实上,现在几乎都是使用ReLU激活函数,原因如下:
1.ReLU的计算速度更快一些,因为只需要计算0,z;而sigmoid函数需要取幂,然后取逆等等,所以它的效率有点低。
2.ReLU仅在图形的一部分中变平;sigmoid函数在两个方向变平。如果你使用梯度下降来训练神经网络,那当你有一个很胖的函数时,梯度下降真的很慢。
总结:

5.为什么模型需要激活函数
回想一下下图这个需求预测示例。
如果我们使用线性激活函数会发生什么?事实证明,这个大型神经网络将变得与线性回归没有什么不同。所以这会破坏使用神经网络的全部目的,因为它会无法拟合比线性回归模型更复杂的东西。
让我们用下边这个更简单的神经网络的例子来说明这一点:
输入x只是一个数字,我们有一个带有参数w1和b1的隐藏单元 输出a1
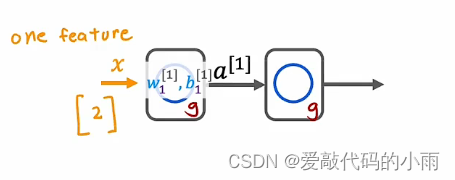
然后第二层是输出层,它也只有一个带有参数w2和b2的输出单元,然后输出a2,也只是一个数字,是一个标量。即x的神经网络f的输出。

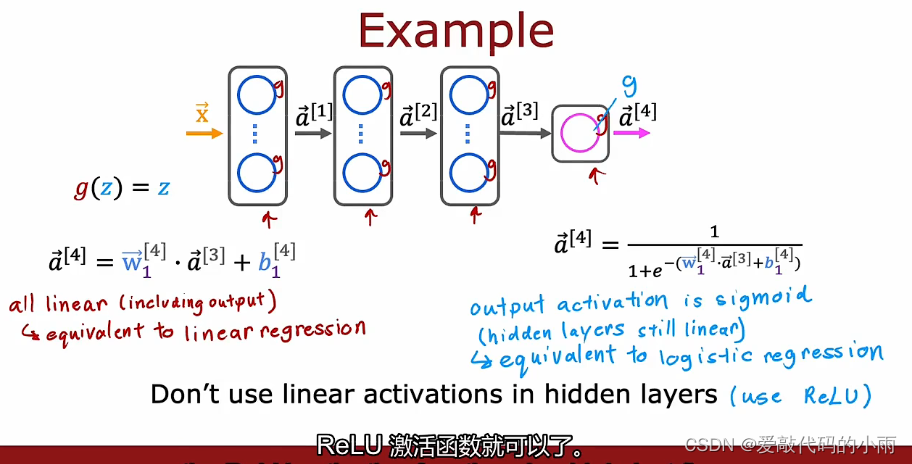
如果你有一个神经网络像下边那个多次,并说你要使用线性激活函数,所有隐藏层还使用线性激活函数,对于输出层 结果证明这个模型将计算完全等价于线性回归的输出。
6.多分类问题
你可以有两个以上可能的输出标签,而不仅仅是0或1。
对于目前我们看到的手写数字分类问题,我们只是试图区分手写数字0和1.但是,如果你尝试阅读信封中的协议或邮政编码,那么实际上你可能想要识别10个可能的数字。或者你想分类患者有几种可能的疾病,这也是一个多分类问题,或者我们常做的一件事是视觉缺陷检查,工厂里的零件制造商,制药公司生产的药丸的图片并试图弄清楚它是否有划痕效应或变色缺陷或芯片缺陷。
所以一个多分类问题依然是一个分类问题,因为y你可以只取少量离散类别不是任何数字,但现在y可以取两个以上的可能值。

因此,之前购买分类时,你可能已经拥有像下面这样具有特征x1和x2的数据集。
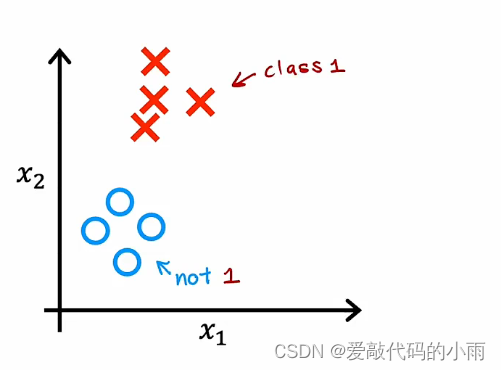
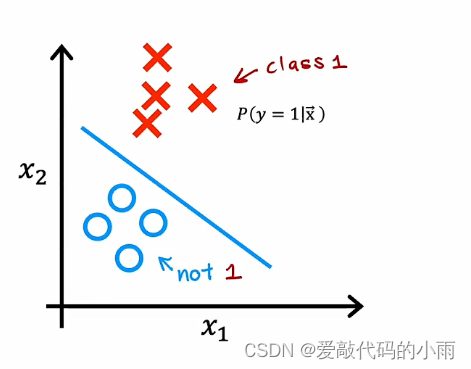
在这种情况下,给定特征x,逻辑回归将拟合模型来故居y为1的概率,y为0或1。
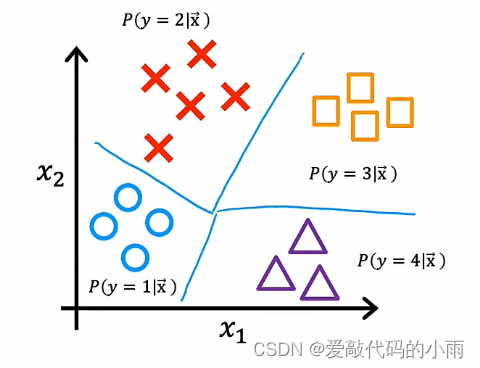
如果是多分类问题,你将看到下面这样的数据集:我们有四个类,其中O代表一个类,X代表一个类,三角代表第三类,矩形代表第四类。现在要估计y对于1的概率是多少,或者y等于2的概率是多少,或者y等于3的概率是多少,或者y等于4的概率是多少?
7.softmax回归算法
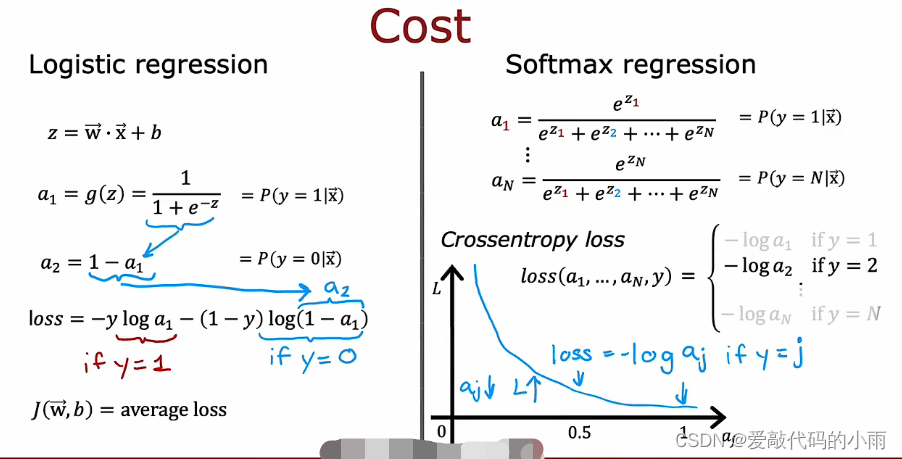
softmax回归算法是逻辑回归的推广,这是多分类上下文的二进制分类算法。
回想一下,当y可以取两个可能的输出值时,逻辑回归适用,输出0或1,计算这个输出的方式是z=wx+b,然后计算a=g(z),它是一个应用于z的sigmoid函数。(a1是y=1的概率若为0.71,那么y=0的概率a2为0.29)

现在推广到softmax回归:(例如当y可以取四个可能的输出时,因此y可以取1234)

现在softmax回归的一般情况的公式,在一般情况下,y可以取n个可能的值,所以y可以是123…n,在这种情况下softmax回归将计算zj ,最后计算aj,aj最后被解释为模型对y的估计

下面是如何指定softmax回归的成本函数
8.神经网络的softmax输出
为了构建一个可以进行多分类的神经网络,我们将采用softmax回归模型,本质上将其放入神经网络的输出层。
以前,我们只用两个子句进行手写数字识别时,我们使用下图架构的新神经网络。
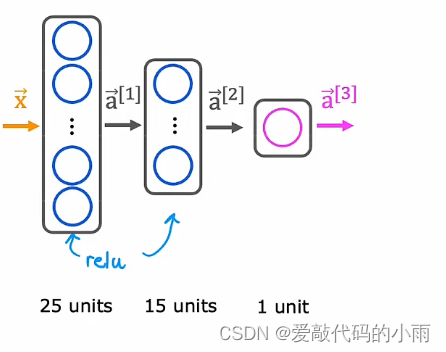
如果你选择想用10个类别进行手写数字分类,所有数字从0到9,那么我们将更改这个神经网络有10个这样的输出单元。这个新的输出层将是一个softmax输出层,所以有时我们会说这个神经网络有一个softmax输出,或者这个上层是一个softmax层。
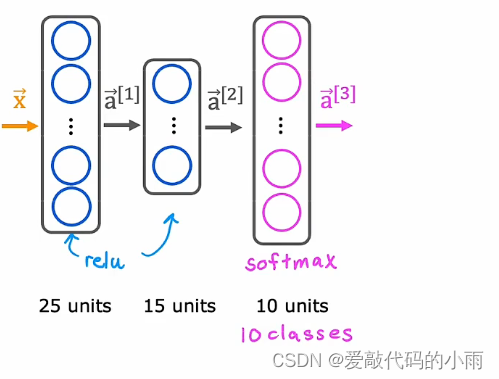
在这个神经网络中,向前传播的工作方式是给定输入x,a1和a2的计算方式与以前完全相同,我们现在计算这个输出层的激活,即a3。
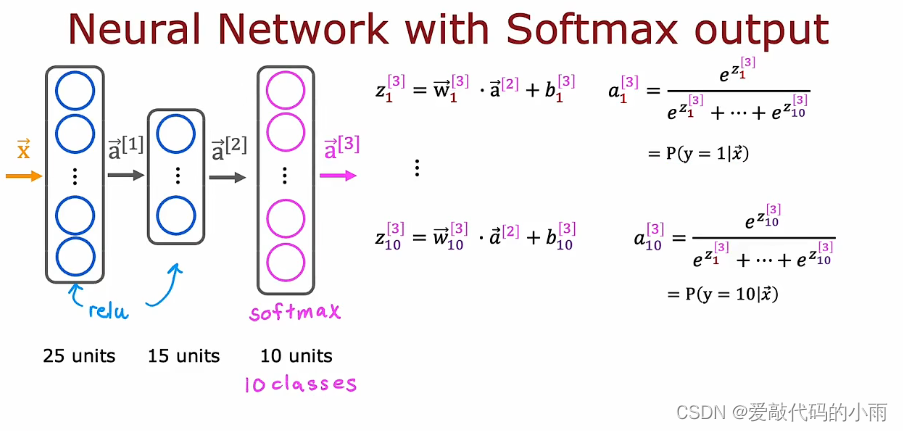
softmax层有时也称为softmax激活函数,如果你想计算a1到a10,则说明不同,它是z1一直到z10的函数,这与之前其他激活函数不同。

下面是如何在tensorflow中实现:

9.多个输出的分类
多标签分类问题,每个图像的关联位置可以是多个标签。
例如:如果你正在建造一辆自动驾驶汽车或一个驾驶员辅助系统,然后给出你车前的照片,问是否有汽车或至少有一辆车或者有一辆公交车或者有行人吗?如下所示,

这是多标签分类问题,因为与单个输入相关联,图像x是三个不同的标签,对应于图像中是否有汽车,公交车或行人,在这种情况下,y的目标实际上是三个数字的向量。这与多类分类,比如手写数字分类那里y只是一个数字不同,即使那个数字可以取10个不同的可能值。
那么你如何建立一个神经网络进行多标签分类?
一种解决方法是 将其视为三个完全独立的机器学习问题。你可以建立一个神经网络来决定有没有汽车,第二个检测公交车,第三个检测行人。分别如下图所示:
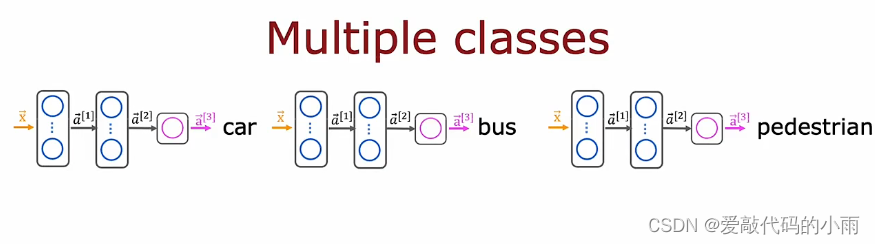
另一种解决方法是 训练单个神经网络同时检测所有三个汽车,公交车和行人,如果你的神经网络架构看起来像下图所示:
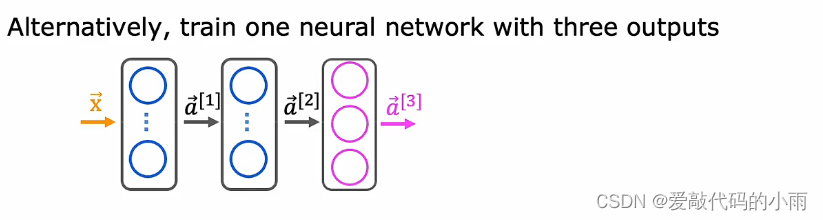
输入x,第一个隐藏层提供a1,第二个隐藏层提供a2,最后是输出层,在这种情况下,我们将有三个输出神经元,我们将输出a3,a3是三个数字的向量。
所以我们要解决三个二分类问题,所以有汽车吗?有公交车吗?有行人吗?你可以为输出层中的这三个节点中的每一个使用sigmoid激活函数,所以在这种情况下,a3是下面这个向量,对应于是否学习图像中有没有汽车,公交车,行人。
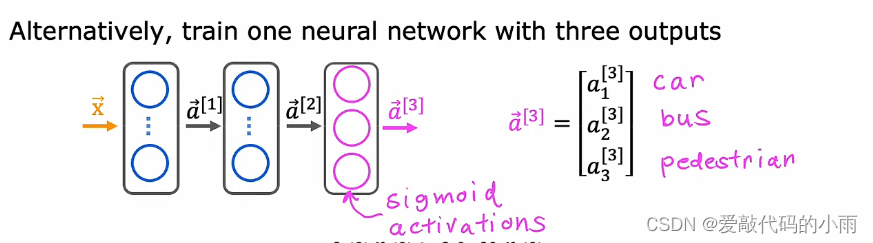
注意: 多类分类和多标签分类有时会互相混淆。
10.高级优化方法
梯度下降是一种广泛应用于机器学习的优化算法,并且是许多算法的基础,如线性回归和逻辑回归和神经网络的早期实现。现在有一些其他的优化算法用于最小化成本函数,甚至比梯度下降更好。
下图是一步梯度下降的表达式,参数wj更新wj,减去学习率α这个偏导数项

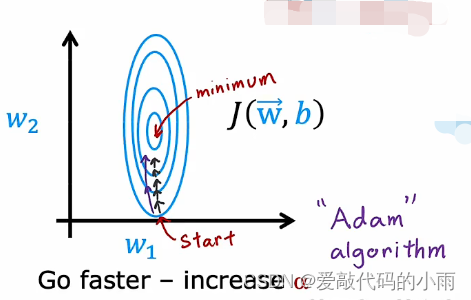
在此示例中,我们使用包含这些省略号的等高线图绘制了成本函数J,这个成本函数的最小值在这个省略号的中心。假设我们开始的位置在右下角位置,学习率很小时,如下所示:
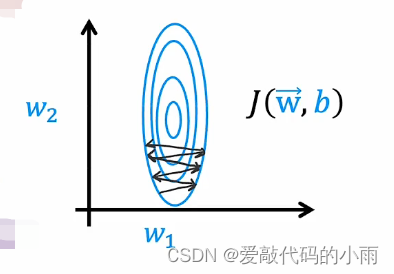
我们再使用相同的成本函数,从左下角开始并且有一个比较大的学习率α,梯度下降如下图所示,来回振荡:
Adam算法可以自动调整学习率,Adam代表自适应矩估计。Adam算法并没有使用单一的全局学习率α,它对模型的,每个参数使用不同的学习率。
如果你有参数w1到w10,就像b一样,那么它实践上有11个学习率参数α1到α10,对于参数b,我们称其为α11.
在代码中,下图是实现它的方法:

(模型和以前完全一样,编译方式,该模型和我们之前的模型非常相似,除了我们现在添加compile函数的一个额外参数,即我们指定你想要的优化器,使用的是tf.keras.optimizers.Adam优化器). Adam优化算法确实需要一些默认的初始学习率α,在上面那个例子中我们将初始学习率设置为10的-3次方。

你在使用Adan算法时,值得尝试一些值,这个默认的全局学习率,尝试一些较大的值和一些较小的值,看看什么可以为你提供最快的学习性能。
这与上一节课中学习的原始梯度下降算法相比,Adam算法可以自动调整学习率,更健壮,使你选择学习率更确切。
11.其他的网络层类型
目前你使用的所有网络层都是密集层类型,其中,层中的每个神经元都得到它输入上一层的所有激活,事实证明,仅使用密集层类型,你实际上可以构建一些非常强大的学习算法。
首先回顾一下我们一直在使用神经元激活的密集层,比如第二个隐藏层是来自前一层的每个激活值的函数,但事实证明,对于某些应用程序,设计神经网络的人可能会选择使用不同类型的层。你可能在某些工作中看到的另一种层类型称为卷积层。下面用例子来说明卷积层:
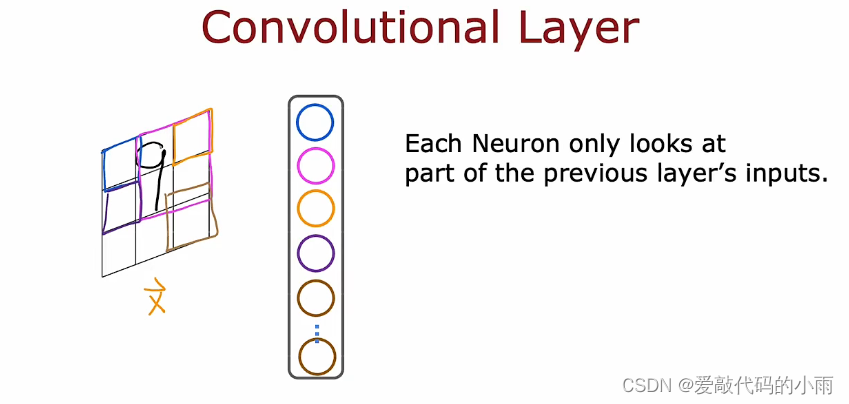
左边显示的是输入x,这是一个手写的数字9,我们要做的是构建一个隐藏层,它将计算不同的激活作为输入图像x的函数,这是我们可以为第一个隐藏单元做的事情。我们用蓝色绘制,并不是说这个神经元可以查看这张图像中的所有像素,这个神经元只能看到一个小矩形区域中的像素;第二个神经元只会查看有限区域中的像素(对于粉红色),后边神经元以此类推,直到最后一个神经元,它可能只看图像的那个区域。
我们为什么不让每个神经元查看所有像素而只查看部分像素呢?原因如下:①它加速了计算速度,②使用这种称为卷积层的神经网络可以需要更少的训练数据并且不太容易过度拟合。
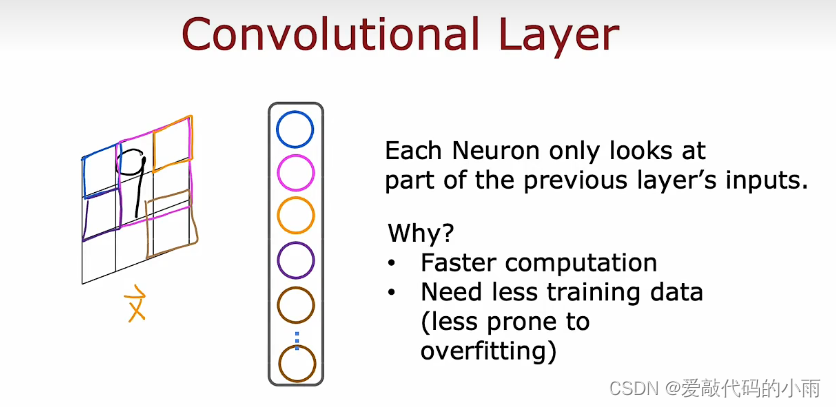
当我们谈论使用学习算法的实用技巧时,这是每个神经元只关注的层类型,输入图像的一个区域称为卷积层。下面更详细地说明一个卷积层,如果你在神经网络中有多个卷积层,有时这被称为卷积神经网络。
如下图所示,为了说明卷积神经网络的卷积层,我们将不使用二维图像输入,我们使用一维输入和激励示例。我们使用的时EKG信号或心电图的分类,因此,如果你将两个电极放在胸前,你将记录下与你的心跳相对于的电压,在某些地方,只有一个数字列表,对应于不同时间点的表面高度,因此,你可能会说100个数字对应于该曲线在100个不同时间点的高度。所以我们这里有100个输入x1 x2一直到x100,当我构造第一个隐藏层而不是让第一个隐藏单元输入所有100个数字时,让第一个隐藏单元只看x1到x20,所以这相当于只看这个EKG信号的一个小窗口,此处以不同颜色显示第二个隐藏层,只看x11到x30,只看这个EKG信号中的不同窗口,第三个隐藏查看另一个窗口x21到x40,依此类推,如下所示:
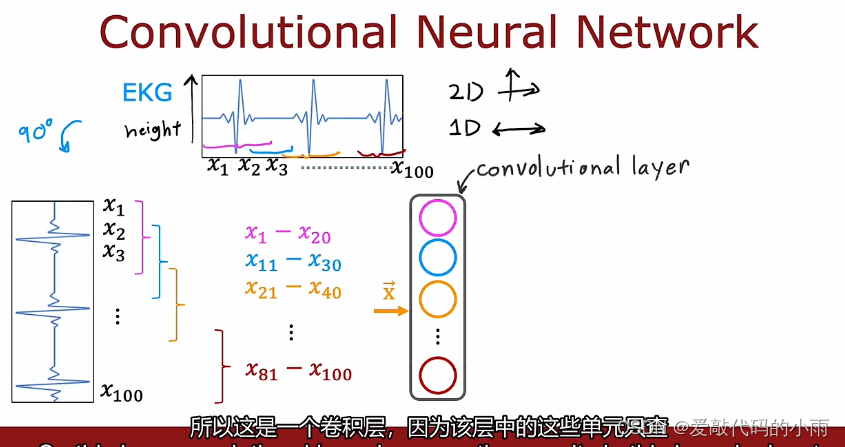
所以这是一个卷积层,因为该层中的这些单元只查看输入的有限窗口 ,现在这层神经网络有九个单元,下一层也可以是一个卷积层。在第二个隐藏层中,构建第一个单元,不要查看前一层的所有九个激活,而是看看前一层的5个激活a1到a5,然后第二个单位在第二个隐藏的地方a3到a7,第三个在a5到a9,最后这些激活a[2]获取sigmoid单元的输入,该单元确实查看 a[2]的所有这三个值以进行二进制分类。
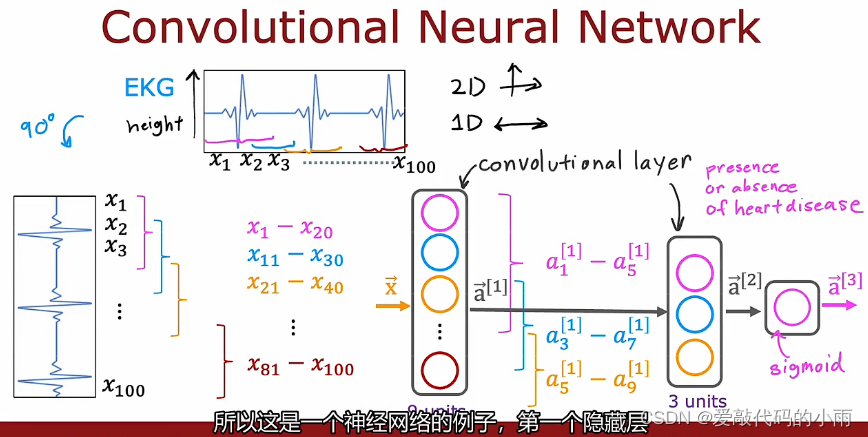
所以这是一个神经网络的例子,第一个隐藏层是一个卷积层,第二个隐藏层也是一个卷积层,然后输出层是一个sigmoid层。
对于卷积层,你可以有许多架构选择,例如,单个神经元应该查看的输入窗口有多大以及层应该有多少个神经元,通过有效地选择这些架构参数,你可以构建更有效的新版本神经网络。比如某些应用程序的密集层。
写在最后:
事实上,如果你听说过最新的前沿模型,比如transformer、LATM(长短期记忆网络)或者attention(注意力模型)。即使在今天,有许多的神经网络研究都是讲研究人员尝试创建新类型的神经网络把不同类型的层连接在一起,作为搭建模块,从而形成更复杂、更强大的神经网络。















 2000
2000











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









