







前言
保研后大四在企业进行短期实习,一方面利用公司上下班制度强迫自己不偷懒,早睡早起,一方面希望通过公司实习学点东西
实习的目的
- 丰富自己的简历 ,便于研究生毕业后找大厂工作
- 通过项目开发提高自己的代码能力
- 了解企业内的工作氛围,为日后研究生毕业决定进入社会的时候提高方向
- 了解企业的企业结构,人员结构
任务
这是在公司实习mentor给我布置的任务
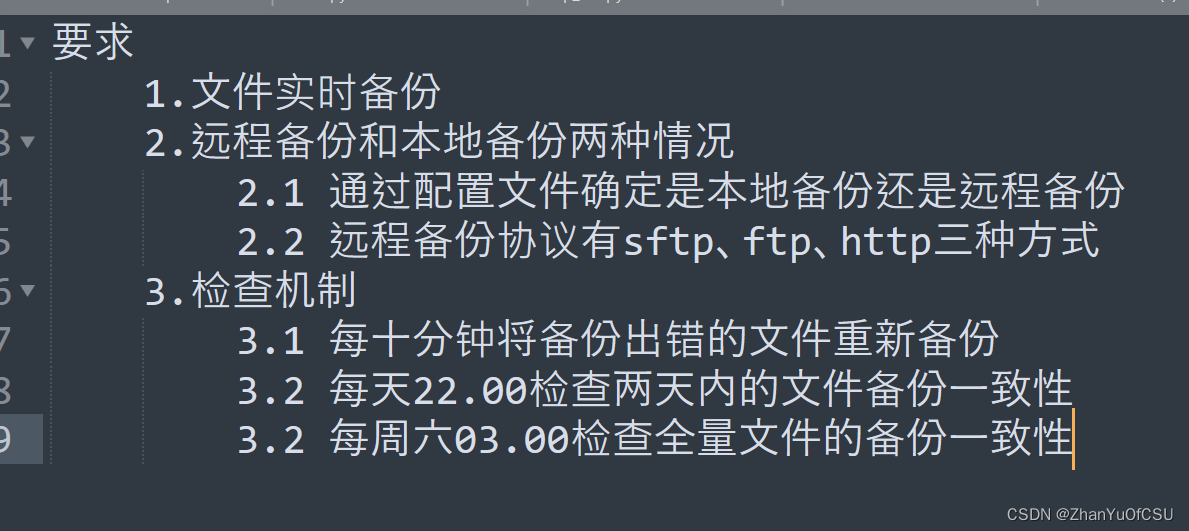
这个东西对我来说是完全陌生的,我将其分散拆解成了如下几个步骤完成
- 本地小文件的备份
- 本地大文件的备份
- 实现实时功能
- 实现远程备份
分解任务
在进行实验前我还大致知道需要用到io的知识,我就不写在这了,过程中又不懂的地方在临时去学吧
1. 本地小文件的备份
本地小文件的备份我参考了《Python备份文件,复制文件的操作》博客1,和博客2《Python 备份文件,以及备份大文件》
过程
我遇到的第一个问题是博客2中的这句代码
ori_file_name = r'E:\PYTHON\mayday.mp3'
我的问题是是字符串前的那个r的作用是什么
查阅资料后得知作用是告诉解释器所有字符按照原本的样子进行解释(即忽略转义字符串的转义功能)
path = '12\24'
print(path)
path = r'12\24'
print(path)
结果如下所示

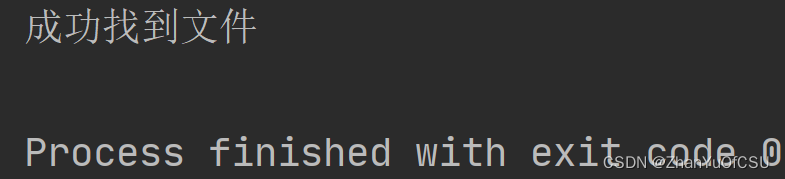
然后我遇到的问题是如何找到我的文件(文件路径应该怎么写),由于我的test.txt文件不在项目的同级目录下,故使用了绝对路径
r’D:\我\我的\研究生学习\研0\实习\备份\test.txt’
file_path = r'D:\我\我的\研究生学习\研0\实习\备份\test.txt'
if os.path.isfile(file_path):
print('成功找到文件')
结果如下所示,成功找到文件
接下来就是备份的逻辑,备份其实很简单,就是复制,复制的步骤可以分为如下几步
- 生成新文件文件名
我们这里就简单的在旧文件名后添加_copy作为新文件的文件名吧
比如说旧文件的文件名为test.txt,那么新文件的文件名为test_copy.txt
windows下文件名很容易获取,符号.前面的就是文件名,符号.后面的就是文件类型
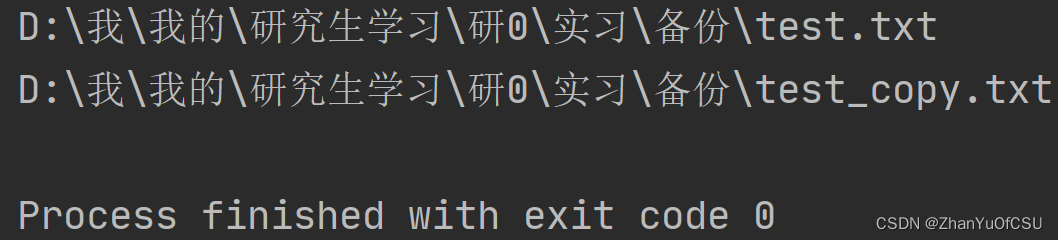
# 生成新文件名
dot_index = file_path.rfind('.')
new_file_path = file_path[:dot_index] + '_copy' + file_path[dot_index:]
print(file_path)
print(new_file_path)
结果如下
2. 打开源文件,读取文件信息
不管三七二十一,先以二进制的形式读进来,
with open(file_path, 'rb') as old_file:
old_file_content = old_file.read()
old_file_content = old_file_content.decode('utf-8')
print(old_file_content)
这里有一些需要注意的地方
1. 最好使用with open的方式使用open,因为open文件后需要记得close文件,不然在文件不需要的时候,也会在后台占用计算机资源,程序运行结束或者是异常终止的情况下,也会占用系统资源
2. open()函数在’r’的情况下返回的是字符串str,而在’b’的情况下返回的是bytes
在python中,数据转成2进制后不是直接以010101的形式表示的,而是用一种叫bytes(字节)的类型来表示的,使用.decode(‘utf-8’)方法后可以将二进制bytes类型编码为utf-8编码格式
3. 在记事本中可以看到test.txt编码格式为utf-8,故将2进制编码编码为utf-8,若使用了.decode(‘gbk’)方法会出现乱码现象
结果如下所示
由图可知我们已经正确获得了正确的二进制数据
3. 创建新文件并写入数据
# 创建新文件并写入数据
with open(new_file_path,'wb') as new_file:
new_file.write(old_file_content)
结果如下所示

实验过程中我提出了这样几个问题
1. open一个不存在的文件时是会创建一个新文件吗:是的
2. 如果要open的这个文件已经存在了,read方法是覆盖重写,还是续写在后面呢:是覆盖重写
3. 我open了这个新文件,以二进制的形式将数据写入新文件,但是只有在新文件和旧文件编码格式相同的情况下才是正确的,那我如何判断新文件编码格式呢?
4. 不是文本文件能这样复制吗?
针对上述1,2问题,学习了相应的io知识
1. 使用open时如果不提供mode参数,使用默认的只读方式打开。但是如果文件不存在则程序会报错
2. 使用’w’写入模式,或者’w+'读写模式,文件不存在会创建文件,但是如果文件存在会将其覆盖
3. 'a’追加写模式,和’a+'追加读写模式。这是我需要的。文件存在,则打开该文件;文件不存在,则新建一个空白文件。
完整代码
# backup1为简单的复制小文件的版本
import os
file_path = r'D:\我\我的\研究生学习\研0\实习\备份\test.txt'
if os.path.isfile(file_path):
# 生成新文件名
dot_index = file_path.rfind('.')
new_file_path = file_path[:dot_index] + '_copy' + file_path[dot_index:]
# 打开原文件,读取文件信息
with open(file_path, 'rb') as old_file:
old_file_content = old_file.read()
# old_file_content = old_file_content.decode('utf-8')
# print(old_file_content)
# 创建新文件并写入数据
# open一个不存在的文件时是会创建一个新文件吗:是的
# 如果要open的这个文件已经存在了,read方法是覆盖重写,还是续写在后面呢:是覆盖重写
with open(new_file_path,'wb') as new_file:
new_file.write(old_file_content)
# 我open了这个新文件,以二进制的形式将数据写入新文件,但是只有在新文件和旧文件编码格式相同的情况下才是正确的
# 不是文本文件能这样复制吗
2.本地大文件的备份
本地小文件的备份存在很大的问题,这个代码满足一般文件的copy,但是,如果遇到大文件,在读取文件信息的时候内存会扛不住
解决这个问题的思路很简单,不要一次将老文件所有数据一次读取即可,一次读取一行的数据,写入后再读取下一行,问题即可解决
我遇到的第一个问题是如何判断已经读取到了最后一行,跳出循环















 3798
3798











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









