







经典目标检测算法总结笔记
1 项目结构
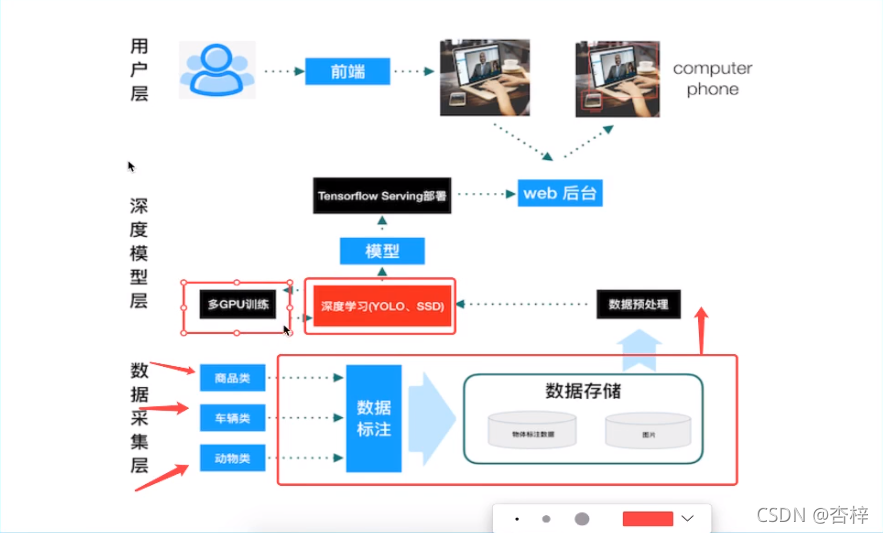
数据采集层:数据收集标注
深度模型层:YOLO、SSD,模型导出,Serving部署
用户层:前端交互,(web后台)对接部署的模型
2 目标检测算法分类
two-stage: 两步走,先区域推荐,后目标分类
代表:R-CNN、SPP-net、Fast R-CNN、Faster R-CNN
one-stage:端到端,一个网络一步到位,输入图片,输出类别和位置
代表:YOLO、SSD
3 目标检测任务
3.1 目标分类
卷积激活池化——类别概率——交叉熵损失
3.2 目标定位
经过FC后,输出四个预测位置,对比真实标注——均方误差损失计算
3.3 位置坐标
x y w h ——xmin(左上角) ymin xmax ymax

3.4 Bounding box
ground-truth bounding box: 图片中真实标记的值
predicted bounding box:预测的时候标记的值
4 R-CNN
多目标检测问题不能以固定个数输出物体的位置值,因为不知道图中有几个物体
4.1 目标检测的overfeat模型
4.1.1滑动窗口
暴力方法:检测转化为分类,首先定义K个大小窗口,每个窗口滑动提取M个,总共K*M图片来分类,物体?背景?
计算消耗大
4.2 R-CNN方法
在CVPR 2014中,20个类别的物体检测
4.2.1 候选区域方法
4.2.1.1 SS选择性搜索
相近像素合并,提取候选框,长宽不定
4.2.1.2 NMS非极大抑制
目的:筛选候选区域,目标是一个物体只保留一个最好的框,来抑制冗余的框
有N个ground truth 则经过概率筛选得到N个准确的候选框
迭代过程
1对2000个区域以0.5的概率筛选,得到5个
2剩余的候选框,对每个候选框找到自己对应的GT
3如下图,先找到概率最大的框B,算出来与B的IOU>0.5的框,删除掉,即删除DE

4 最终结果:每一个ground truth都有一个候选框
4.2.1.3 修正候选区域
A1A2…为候选框,G是目标GT
Ai和G做回归训练,得到四个参数Wx Wy Ww Wh
4.2.1.4 步骤(Alexnet为例)
1对一张图片,找出默认的2000个候选区域(SS)
2对2000个候选区域做大小变换,输入Alexnet中,得到特征向量2000*4096
3经过20个类别的SVM,对2000的候选区域做判断,得到【2000,20】得分
每一个特征向量进入SVM二分类得到2000个得分,一共20个二分类
4对【2000,20】做NMS(极大抑制),修正得到结果好的框,计算IOU
5修正候选框,做bbox回归微调, 使得候选框标注更准确
4.2.2 R-CNN输出
一张图片预测一个X候选框,由X*W=Y_locate得到真正的输出位置
4.2.3 效果
在VOC2007数据集上的map达到66%
4.2.5 缺点
训练时间长
模型多:微调网络+训练SVM+训练bbox
处理速度慢
5 目标检测评估指标
5.1 IOU交并比
位置的考量
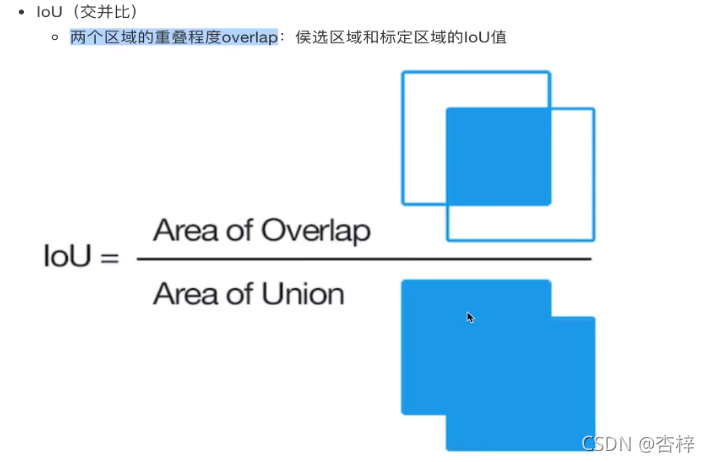
通常correct:类别正确且IOU>0.5
5.2 map平均精确率
分类准确率的考量
训练样本的标记,每个GT有最高的IOU anchor 标记为正样本,其余的anchor和任何GT的IOU>0.7为正样本,IOU<0.3为负样本
define:多个分类任务的AP的平均值
mAP=所有类别的AP之和/类别的总个数
AP:PR曲线下的面积(AUC)
step:
1、对N个类其中一个类别,比如猫,所有候选框输出是猫类别的概率进行排序,得到一个候选框列表
(R-CNN中就是SVM的输出分数)
2、根据候选框列表计算AUC
3、最终得到N个类别,N个AP相加/N
6 SPP-Net
6.1 R-CNN慢在何处
卷积运算耗时间
6.2 SPP-Net的几点改进

6.3 映射
(x’,y’)表示特征图上坐标点,原图(x,y)
左上角的点 x’=[x/S]+1
右下角的点 x’=[x/S]-1
S = 卷积层步长之乘积
6.4 SPP(spatial pyramid pooling)
空间金字塔池化
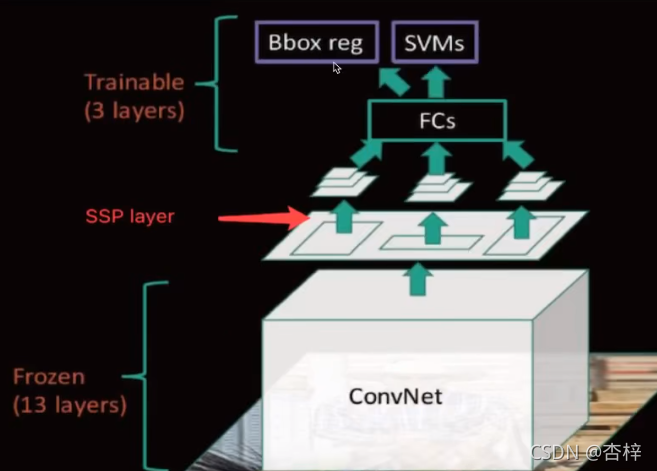
候选区域的特征图转换成固定大小的特征向量
spp layer 会把每一个候选区域分成 1×1 2×2 4×4三张子图
6.5 优缺点
优点:通过候选区域和feature map映射,配合SPP使用,达到CNN层共享计算
缺点:训练慢,特征需要写入磁盘(SVM)
分阶段训练:选取候选区域→训练CNN→训练SVM→训练Bbox回归器→SPPNet反向传播效率低
7 Fast R-CNN
7.1 Fast R-CNN的几点改进
1 提出一个Rol pooling层
2 分类使用softmax计算:K个类别加上“背景”类
3 与SPPNet相同的地方:
首先 b 整个图片输入到基础卷积网络,得到整张图的feature map
将SS得到的结果Rol(region proposal)映射到feature map中
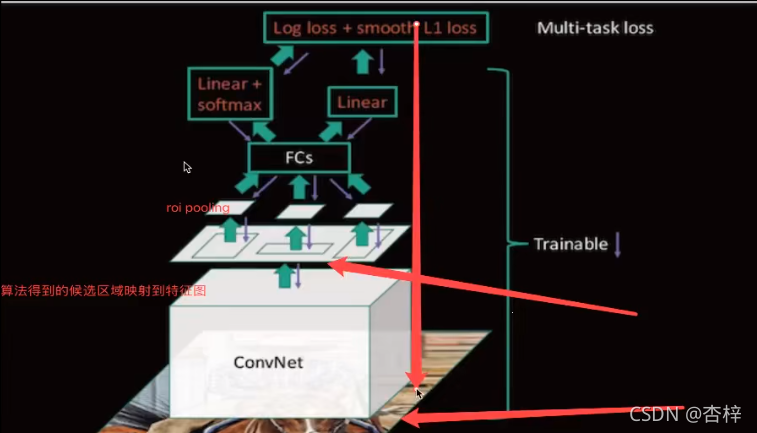
7.2 RoI pooling
为减少计算时间并且得出固定长度的向量,使用一种4×4的空间盒子(不再用金字塔型)
7.3 step

训练比较统一:废弃了 SVM 和 SPPNet ,采用Roi pooling + softmax
7.4 多任务损失 Multi-task loss
分类loss N+1(类别数+背景)个 softmax 输出————使用交叉熵损失
回归loss 4×N 个输出 regressor使用平均绝对误差MAE,即L1损失
fin-tuning训练
在微调时,调整 CNN+Roi pooling + softmax
调整 bbox regressor 回归当中的参数
7.5 总结
缺点:SS提取,没有实现端到端
8 Faster R-CNN
8.1 Faster R-CNN的改进
SS步骤融合到网络当中

区域生成网络(RPN)+ Fast R-CNN 即 RPN代替了SS
8.2 RPN实现
1 图片输入基础CNN (conv + relu + pooling),提取得到feature map
2 softmax 判断 anchors 属于 foreground or background
3 利用bbox修正anchors获得精确的候选区域
4 得到默认300个候选区域给ROI pooling
8.3 RPN原理
用n×n的大小窗口去扫描特征图(默认3*3)得到K个候选窗口
每个特征图中像素对应的9个窗口大小:三种尺度{128,256,512} 三种长宽比{1:1,1:2,2:1}
3*3=9不同大小的候选框
窗口输出【N,256】→分类:判断是否是背景
回归位置:N个候选框与自己对应目标值GT做回归,修正位置
得到更好的候选区域给ROI pooling
8.4 Faster-RCNN训练
8.4.1 RPN 训练
样本准备:正负anchors样本比例 1:3
分类:二分类,softmax,logistic regression
候选框的调整:均方误差修正
8.4.2 Fast R-CNN 部分的训练
预测类别训练:softmax
预测位置训练:均方误差损失
8.4.3 优点
提出RPN网络
端到端网络模型
8.4.4 缺点
训练参数过大
9 YOLO
You only look once
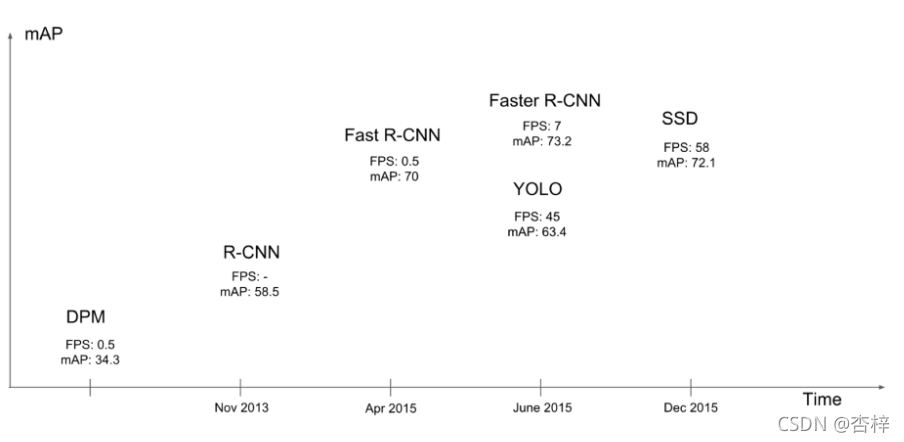
9.1 网络速度和精度比较
9.2 YOLO结构
GoogleNet + 4个卷积+2个全连接层 一个网络搞定一切
网络输出大小:7×7×30

9.3 流程
1 原始图片resize为448x448,图片输出成了一个7×7×30的结构
2 默认7×7个单元格
3 每个单元格预测两个bbox框
4 进行NMS筛选,筛选概率以及IoU
9.4 单元格
7 * 7=49个像素值,理解成49个单元格,每个单元格可以代表原图的一个方块。单元格需要做的两件事:
- 1.每个单元格负责预测一个物体类别,并且直接预测物体的概率值
- 2.每个单元格预测两个(默认)bbox位置,两个bbox置信度(confidence) 7 7 2=98个bbox
- 30=(4+1+4+1+20), 4个坐标信息xmin ymin xmax ymax,1个置信度(confidence)代表一个bbox的结果, 20代表 20类的预测概率结果
9.5 网络输出筛选
一个网格会预测两个Bbox,在训练时我们只有一个Bbox专门负责(一个Object 一个Bbox)
20个类别概率代表这个网格当中的一个bbox
- 通过置信度大小比较
每个bounding box都对应一个confidence score
-
如果grid cell里面没有object,confidence就是0
-
如果有,则confidence score等于预测的box和ground truth的IOU乘积
-
如何判断一个grid cell里面有没有包含object呢?
如果一个object的ground truth的中心点坐标在一个grid cell里面,那么这个grid cell就被认为包含这个object,即这个object的预测就由该grid cell负责,每个grid cell都预测20个概率,表示在一个grid cell包含object的条件下,该object属于某一个类别的概率
-
grid cell中的哪一个bounding box负责预测呢?
就是如果有好几个bbox都包括了物体中心点,我们选择IOU最大的
YOLO框,概率值都直接由网络输出 7 x 7 x 30(认为给30个值赋了具体的定义)
9.6 训练
- 预测框对应的目标值标记

- 三部分损失 bbox损失+confidence损失+classfication损失
9.7 缺点
- 准确率会打折扣
- YOLO对相互靠的很近的物体(挨在一起且中点都落在同一个格子上的情况),还有很小的群体检测效果不好,这是因为一个网格中只预测了两个框
10 SSD
Single Shot MultiBox Detector
- SSD结合了YOLO中的回归思想和Faster-RCNN中的Anchor机制
- 不同尺度的特征特征图上采用卷积核来预测一系列Default Bounding Boxes的类别、坐标偏移
- 不同尺度feature map所有特征点上使用PriorBox层(Detector&classifier)
10.1 Detector & classifier
- 1.PriorBox层:生成default boxes,默认候选框
- 候选框生成结果之后
- 做微调,利用4个variance做回归调整候选框
- 2.Conv3 x 3:生成localization, 4个位置偏移
- 3.Conv3 x 3:confidence,21个类别置信度(要区分出背景)
10.2 训练
-
训练
- 1、样本标记:8732个候选框default boxes,得到正负样本
- 正: 付=1:3
- Softmax Loss(Faster R-CNN是log loss),位置回归则是采用 Smooth L1 loss (与Faster R-CNN一样)
10.3 test流程
- 输入->输出->nms->输出














 3978
3978











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









