






一、关于模型微调的一些基础知识
1、模型微调(fine-tune)
微调(fine-tune)通过使用在大数据上得到的预训练好的模型来初始化自己的模型权重,从而提升精度。这就要求预训练模型质量要有保证。微调通常速度更快、精度更高。当然,自己训练好的模型也可以当做预训练模型,然后再在自己的数据集上进行训练,来使模型适用于自己的场景、自己的任务。
先引入迁移学习(Transfer Learning)的概念:
当我们训练好了一个模型之后,如果想应用到其他任务中,可以在这个模型的基础上进行训练,来作微调网络。这也是迁移学习的概念,可以节省训练的资源以及训练的时间。
迁移学习的一大应用场景就是模型微调,简单的来说就是把在别人训练好的基础上,换成自己的数据集继续训练,来调整参数。Pytorch中提供很多预训练模型,学习如何进行模型微调,可以大大提升自己任务的质量和速度。
假设我们要识别的图片类别是椅子,尽管ImageNet数据集中的大多数图像与椅子无关,但在ImageNet数据集上训练的模型可能会提取更通用的图像特征,这有助于识别边缘、纹理、形状和对象组合。 这些类似的特征对于识别椅子也可能同样有效。
负迁移问题:
负迁移(Negative Transfer)指的是,在源域上学习到的知识,对于目标域上的学习产生负面作用。
产生负迁移的原因主要有:
1、数据问题:源域和目标域压根不相似,谈何迁移?
2、方法问题:源域和目标域是相似的,但是,迁移学习方法不够好,没找到可迁移的成分。
负迁移给迁移学习的研究和应用带来了负面影响。在实际应用中,找到合理的相似性,并且选择或开发合理的迁移学习方法,能够避免负迁移现象。
2、为什么要微调
因为预训练模型用了大量数据做训练,已经具备了提取浅层基础特征和深层抽象特征的能力。
对于图片来说,我们CNN的前几层学习到的都是低级的特征,比如,点、线、面,这些低级的特征对于任何图片来说都是可以抽象出来的,所以我们将他作为通用数据,只微调这些低级特征组合起来的高级特征即可,例如,这些点、线、面,组成的是园还是椭圆,还是正方形,这些代表的含义是我们需要后面训练出来的。
如果我们自己的数据不够多,泛化性不够强,那么可能存在模型不收敛,准确率低,模型泛化能力差,过拟合等问题,所以这时就需要使用预训练模型来做微调了。注意的是,进行微调时,应该使用较小的学习率。因为预训练模型的权重相对于随机初始化的权重来说已经很不错了,所以不希望使用太大的学习率来破坏原本的权重。通常用于微调的初始学习率会比从头开始训练的学习率小10倍。
了解学习率: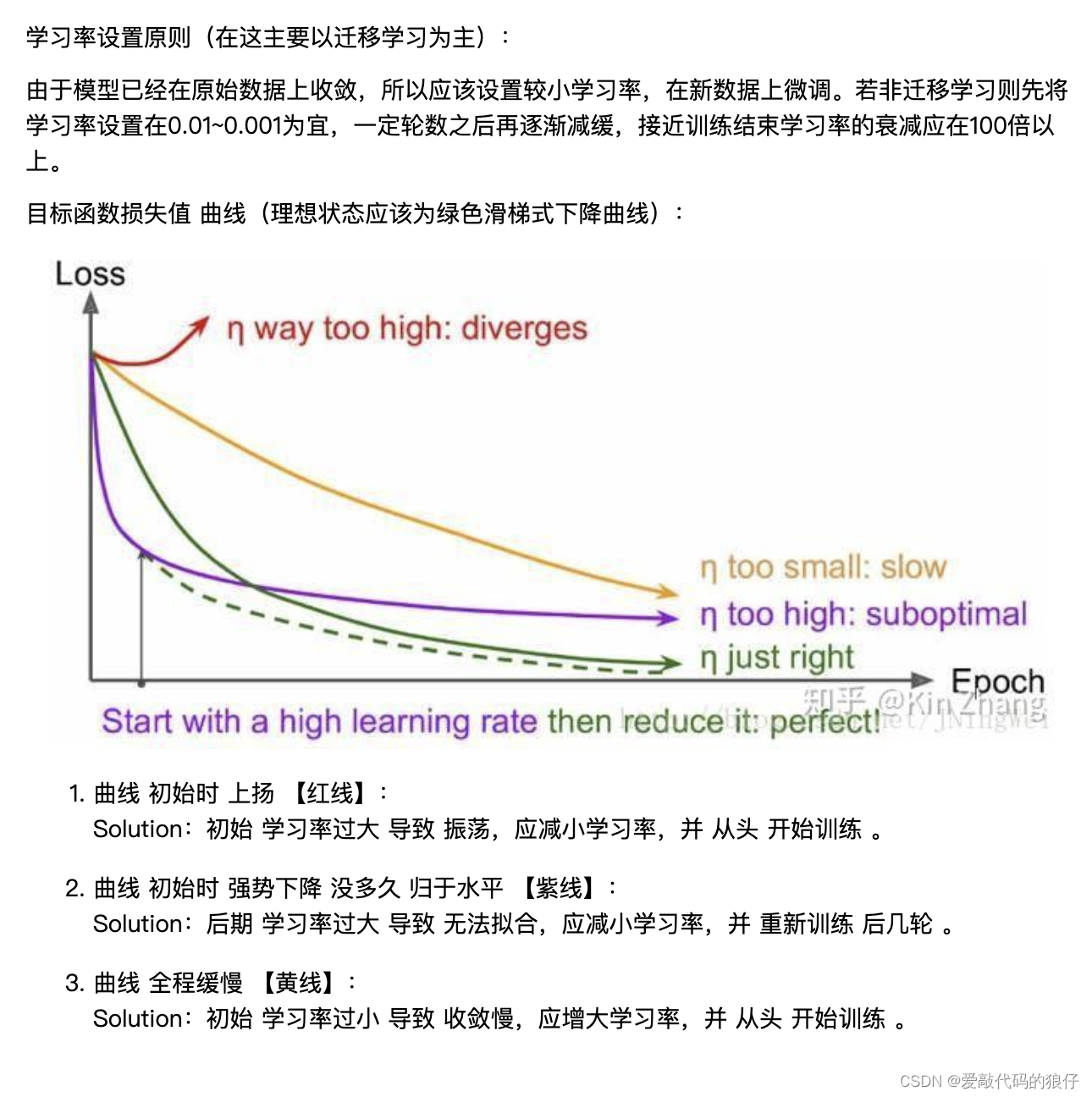
总结:对于不同的层可以设置不同的学习率,一般情况下建议,对于使用的原始数据做初始化的层设置的学习率要小于(一般可设置小于10倍)初始化的学习率,这样保证对于已经初始化的数据不会扭曲的过快,而使用初始化学习率的新层可以快速的收敛。
train/loss:训练级loss
eval/loss:验证级loss,这两者一般以图表的形式表达
过拟合

3、需要微调的情况
其中微调的方法又要根据自身数据集和预训练模型数据集的相似程度,以及自己数据集的大小来抉择。
不同情况下的微调:
数据少,数据类似程度高:可以只修改最后几层或者最后一层进行微调。
数据少,数据类似程度低:冻结预训练模型的前几层,训练剩余的层。因为数据集之间的相似度较低,所以根据自身的数据集对较高层进行重新训练会比较有效。
数据多,数据类似程度高:这是最理想的情况。使用预训练的权重来初始化模型,然后重新训练整个模型。这也是最简单的微调方式,因为不涉及修改、冻结模型的层。
数据多,数据类似程度低:微调的效果估计不好,可以考虑直接重新训练整个模型。如果你用的预训练模型的数据集是ImageNet,而你要做的是文字识别,那么预训练模型自然不会起到太大作用,因为它们的场景特征相差太大了。
注意:
如果自己的模型中有fc层,则新数据集的大小一定要与原始数据集相同,比如CNN中输入的图片大小一定要相同,才不会报错。
如果包含fc层但是数据集大小不同的话,可以在最后的fc层之前添加卷积或者pool层,使得最后的输出与fc层一致,但这样会导致准确度大幅下降,所以不建议这样做
4、 模型微调的流程
微调的步骤有很多,看你自身数据和计算资源的情况而定。虽然各有不同,但是总体的流程大同小异。
步骤示例1:
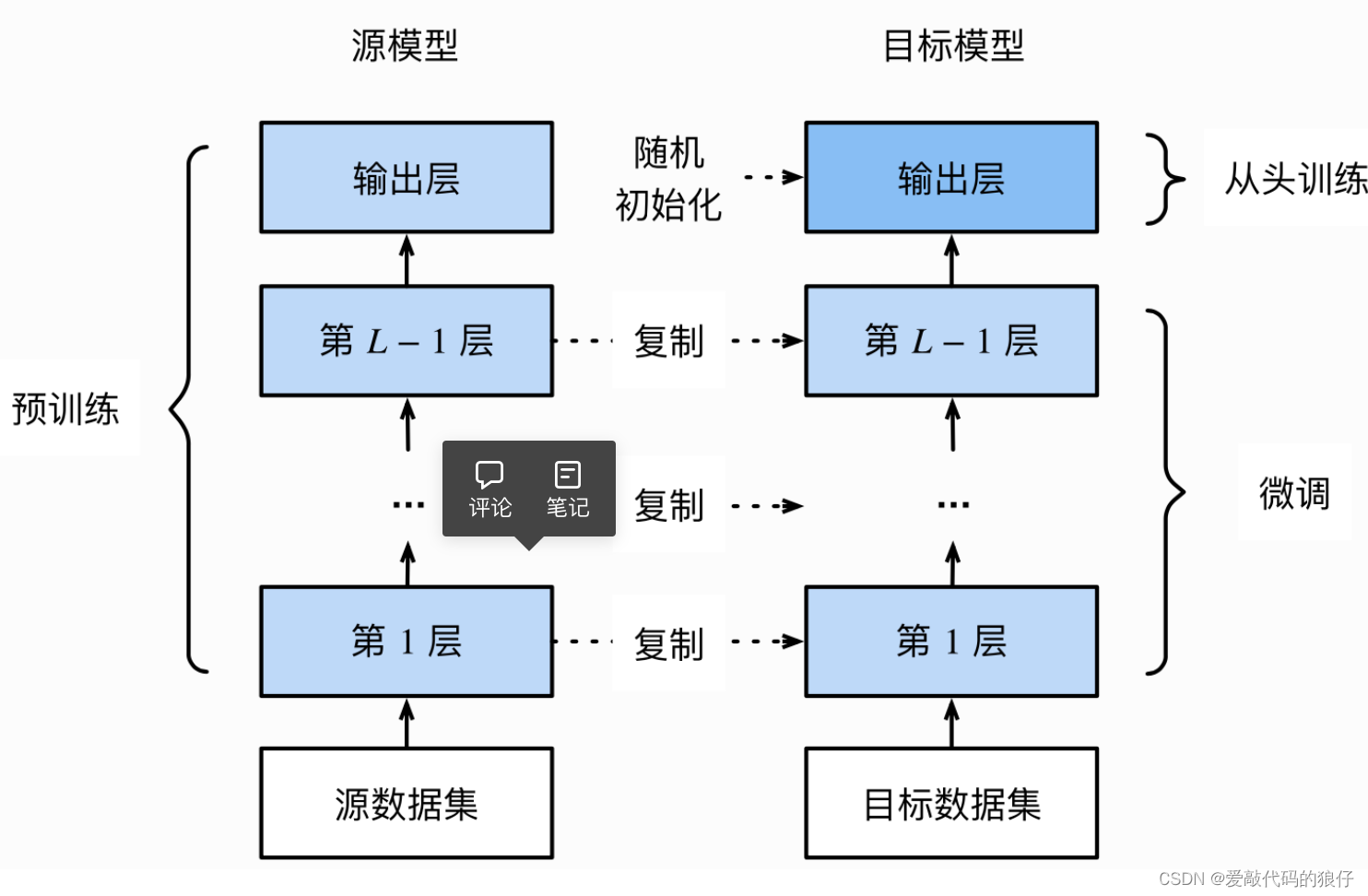
1、在源数据集(如ImageNet数据集)上预训练一个神经网络模型,即源模型。
2、创建一个新的神经网络模型,即目标模型。它复制了源模型上除了输出层外的所有模型设计及其参数。
我们假设这些模型参数包含了源数据集上学习到的知识,且这些知识同样适用于目标数据集。
我们还假设源模型的输出层跟源数据集的标签紧密相关,因此在目标模型中不予采用。
3、为目标模型添加一个输出大小为目标数据集类别个数的输出层,并随机初始化该层的模型参数。
4、在目标数据集(如椅子数据集)上训练目标模型。可以从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的。
步骤示例2:
在已经训练好的网络上进行修改;
冻结网络的原来那一部分;
训练新添加的部分;
解冻原来网络的部分层;
联合训练解冻的层和新添加的部分。
5、参数冻结—指定训练模型的部分层
我们所提到的冻结模型、冻结部分层,其实归根结底都是对参数进行冻结。冻结训练可以加快训练速度。在这里,有两种方式:全程冻结与非全程冻结。
非全程冻结比全程冻结多了一个步骤:解冻,因此这里就讲解非全程冻结。看完非全程冻结之后,就明白全程冻结是如何进行的了。
非全程冻结训练分为两个阶段,分别是冻结阶段和解冻阶段。当处于冻结阶段时,被冻结的参数就不会被更新,在这个阶段,可以看做是全程冻结;而处于解冻阶段时,就和普通的训练一样了,所有参数都会被更新。
当进行冻结训练时,占用的显存较小,因为仅对部分网络进行微调。如果计算资源不够,也可以通过冻结训练的方式来减少训练时资源的占用。
因为一般需要保留Features Extractor的结构和参数,提出了两种训练方法:
固定预训练的参数:requires_grad = False 或者 lr = 0,即不更新参数;
将Features Extractor部分设置很小的学习率,这里用到参数组(params_group)的概念,分组设置优化器的参数。
5.1、参数冻结的方式
我们经常提到的模型,就是一个可遍历的字典。既然是字典,又是可遍历的,那么就有两种方式进行索引:一是通过数字,二是通过名字。
其实使用冻结很简单,没有太高深的魔法,只用设置模型的参数requires_grad为False就可以了。
5.1.1、冻结方式1
在默认情况下,参数的属性.requires_grad = True,如果我们从头开始训练或微调不需要注意这里。但如果我们正在提取特征并且只想为新初始化的层计算梯度,其他参数不进行改变。那我们就需要通过设置requires_grad = False来冻结部分层。在PyTorch官方中提供了这样一个例程。
def set_parameter_requires_grad(model, feature_extracting):
if feature_extracting:
for param in model.parameters():
param.requires_grad = False
在下面我们使用resnet18为例的将1000类改为4类,但是仅改变最后一层的模型参数,不改变特征提取的模型参数;
注意我们先冻结模型参数的梯度;
再对模型输出部分的全连接层进行修改,这样修改后的全连接层的参数就是可计算梯度的。
在训练过程中,model仍会进行梯度回传,但是参数更新则只会发生在fc层。通过设定参数的requires_grad属性,我们完成了指定训练模型的特定层的目标,这对实现模型微调非常重要。
import torchvision.models as models
# 冻结参数的梯度
feature_extract = True
model = models.resnet18(pretrained=True)
set_parameter_requires_grad(model, feature_extract)
# 修改模型, 输出通道4, 此时,fc层就被随机初始化了,但是其他层依然保存着预训练得到的参数。
model.fc = nn.Linear(in_features=512, out_features=4, bias=True)
我们直接拿torchvision.models.resnet50 模型微调,首先冻结预训练模型中的所有参数,然后替换掉最后两层的网络(替换2层池化层,还有fc层改为dropout,正则,线性,激活等部分),最后返回模型:
8 更改池化层
class AdaptiveConcatPool2d(nn.Module):
def __init__(self, size=None):
super().__init__()
size = size or (1, 1) # 池化层的卷积核大小,默认值为(1,1)
self.pool_one = nn.AdaptiveAvgPool2d(size) # 池化层1
self.pool_two = nn.AdaptiveAvgPool2d(size) # 池化层2
def forward(self, x):
return torch.cat([self.pool_one(x), self.pool_two(x), 1]) # 连接两个池化层
# 7 迁移学习:拿到一个成熟的模型,进行模型微调
```javascript
def get_model():
model_pre = models.resnet50(pretrained=True) # 获取预训练模型
# 冻结预训练模型中所有的参数
for param in model_pre.parameters():
param.requires_grad = False
# 微调模型:替换ResNet最后的两层网络,返回一个新的模型
model_pre.avgpool = AdaptiveConcatPool2d() # 池化层替换
model_pre.fc = nn.Sequential(
nn.Flatten(), # 所有维度拉平
nn.BatchNorm1d(4096), # 256 x 6 x 6 ——> 4096
nn.Dropout(0.5), # 丢掉一些神经元
nn.Linear(4096, 512), # 线性层的处理
nn.ReLU(), # 激活层
nn.BatchNorm1d(512), # 正则化处理
nn.Linear(512,2),
nn.LogSoftmax(dim=1), # 损失函数
)
return
5.1.2、冻结方式2
因为ImageNet有1000个类别,所以提供的ImageNet预训练模型也是1000分类。如果我需要训练一个10分类模型,理论上来说只需要修改最后一层的全连接层即可。
如果前面的参数不冻结就表示所有特征提取的层会使用预训练模型的参数来进行参数初始化,而最后一层的参数还是保持某种初始化的方式来进行初始化。
在模型中,每一层的参数前面都有前缀,比如conv1、conv2、fc3、backbone等等,我们可以通过这个前缀来进行判断,也就是通过名字来判断,如:if “backbone” in param.name,最终选择需要冻结与不需要冻结的层。最后需要将训练的参数传入优化器进行配置。
if freeze_layers:
for name, param in model.named_parameters():
# 除最后的全连接层外,其他权重全部冻结
if "fc" not in name:
param.requires_grad_(False)
pg = [p for p in model.parameters() if p.requires_grad]
optimizer = optim.SGD(pg, lr=0.01, momentum=0.9, weight_decay=4E-5)
或者判断该参数位于模型的哪些模块层中,如param in model.backbone.parameters(),然后对于该模块层的全部参数进行批量设置,将requires_grad置为False。
if Freeze_Train:
for param in model.backbone.parameters():
param.requires_grad = False
5.1.3、冻结方式3
通过数字来遍历模型中的层的参数,冻结所指定的若干个参数, 这种方式用的少
count = 0
for layer in model.children():
count = count + 1
if count < 10:
for param in layer.parameters():
param.requires_grad = False
# 然后将需要训练的参数传入优化器,也就是过滤掉被冻结的参数。
optimizer = torch.optim.Adam(filter(lambda p: p.requires_grad, model.parameters()), lr=LR)
5.2、修改模型参数
前面说道,冻结模型就是冻结参数,那么这里的修改模型参数更多的是修改模型参数的名称。
值得一提的是,由于训练方式(单卡、多卡训练)、模型定义的方式不同,参数的名称也会有所区别,但是此时模型的结构是一样的,依旧可以加载预训练模型。不过却无法直接载入预训练模型的参数,因为名称不同,会出现KeyError的错误,所以载入前可能需要修改参数的名称。
比如说,使用多卡训练时,保存的时候每个参数前面多会多出’module.'这几个字符,那么当使用单卡载入时,可能就会报错了。
 通过以下方式,就可以使用’conv1’来替代’module.conv1’这个key的方式来将更新后的key和原来的value相匹配,再载入自己定义的模型中。
通过以下方式,就可以使用’conv1’来替代’module.conv1’这个key的方式来将更新后的key和原来的value相匹配,再载入自己定义的模型中。
model_dict = pretrained_model.state_dict()
pretrained_dict={k: v for k, v in pretrained_dict.items() if k[7:] in model_dict}
model_dict.update(pretrained_dict)
5.3、修改模型结构
import torch.nn as nn
import torch
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.features=nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2), # 使用卷积层,输入为3,输出为64,核大小为11,步长为4
nn.ReLU(inplace=True), # 使用激活函数
nn.MaxPool2d(kernel_size=3, stride=2), # 使用最大池化,这里的大小为3,步长为2
nn.Conv2d(64, 192, kernel_size=5, padding=2), # 使用卷积层,输入为64,输出为192,核大小为5,步长为2
nn.ReLU(inplace=True),# 使用激活函数
nn.MaxPool2d(kernel_size=3, stride=2), # 使用最大池化,这里的大小为3,步长为2
nn.Conv2d(192, 384, kernel_size=3, padding=1), # 使用卷积层,输入为192,输出为384,核大小为3,步长为1
nn.ReLU(inplace=True),# 使用激活函数
nn.Conv2d(384, 256, kernel_size=3, padding=1),# 使用卷积层,输入为384,输出为256,核大小为3,步长为1
nn.ReLU(inplace=True),# 使用激活函数
nn.Conv2d(256, 256, kernel_size=3, padding=1),# 使用卷积层,输入为256,输出为256,核大小为3,步长为1
nn.ReLU(inplace=True),# 使用激活函数
nn.MaxPool2d(kernel_size=3, stride=2), # 使用最大池化,这里的大小为3,步长为2
)
self.avgpool=nn.AdaptiveAvgPool2d((6, 6))
self.classifier=nn.Sequential(
nn.Dropout(),# 使用Dropout来减缓过拟合
nn.Linear(256 * 6 * 6, 4096), # 全连接,输出为4096
nn.ReLU(inplace=True),# 使用激活函数
nn.Dropout(),# 使用Dropout来减缓过拟合
nn.Linear(4096, 4096), # 维度不变,因为后面引入了激活函数,从而引入非线性
nn.ReLU(inplace=True), # 使用激活函数
nn.Linear(4096, 1000), #ImageNet默认为1000个类别,所以这里进行1000个类别分类
)
def forward(self, x):
x=self.features(x)
x=self.avgpool(x)
x=torch.flatten(x, 1)
x=self.classifier(x)
return x
def alexnet(num_classes, device, pretrained_weights=""):
net=AlexNet() # 定义AlexNet
if pretrained_weights: # 判断预训练模型路径是否为空,如果不为空则加载
net.load_state_dict(torch.load(pretrained_weights,map_location=device))
num_fc=net.classifier[6].in_features # 获取输入到全连接层的输入维度信息
net.classifier[6]=torch.nn.Linear(in_features=num_fc, out_features=num_classes) # 根据数据集的类别数来指定最后输出的out_features数目
return net
在上述代码中,是先将权重载入全部网络结构中。此时,模型的最后一层大小并不是预想的,因此需要获取输入到最后一层全连接层之前的维度大小,然后根据数据集的类别数来指定最后输出的out_features数目,以此代替原来的全连接层。
也可以先定义好具有指定全连接大小的网络结构,然后除了最后一层全连接层之外,全部层都载入预训练模型;也可以先将权重载入全部网络结构中,然后删掉最后一层全连接层,最后再加入一层指定大小的全连接层。
详情参考:https://blog.csdn.net/ytusdc/article/details/128522887
大模型应用技术分类底座:
1,提示词工程
2,知识库
3,AI Agent
4,微调
二、模型微调的数据准备
1,模型准备
2,模型加载
from *** import ******
·冻结参数
·输出层调整(fp16/fp32精度),输出层一般需要更高的精度,原有的权重不需要改变,这样在计算loss的时候会使loss更加合理。
一些准备步骤在引入函数的时候可能就已经处理过了
eg:baichuan-7B
 模型定义变化:
模型定义变化:
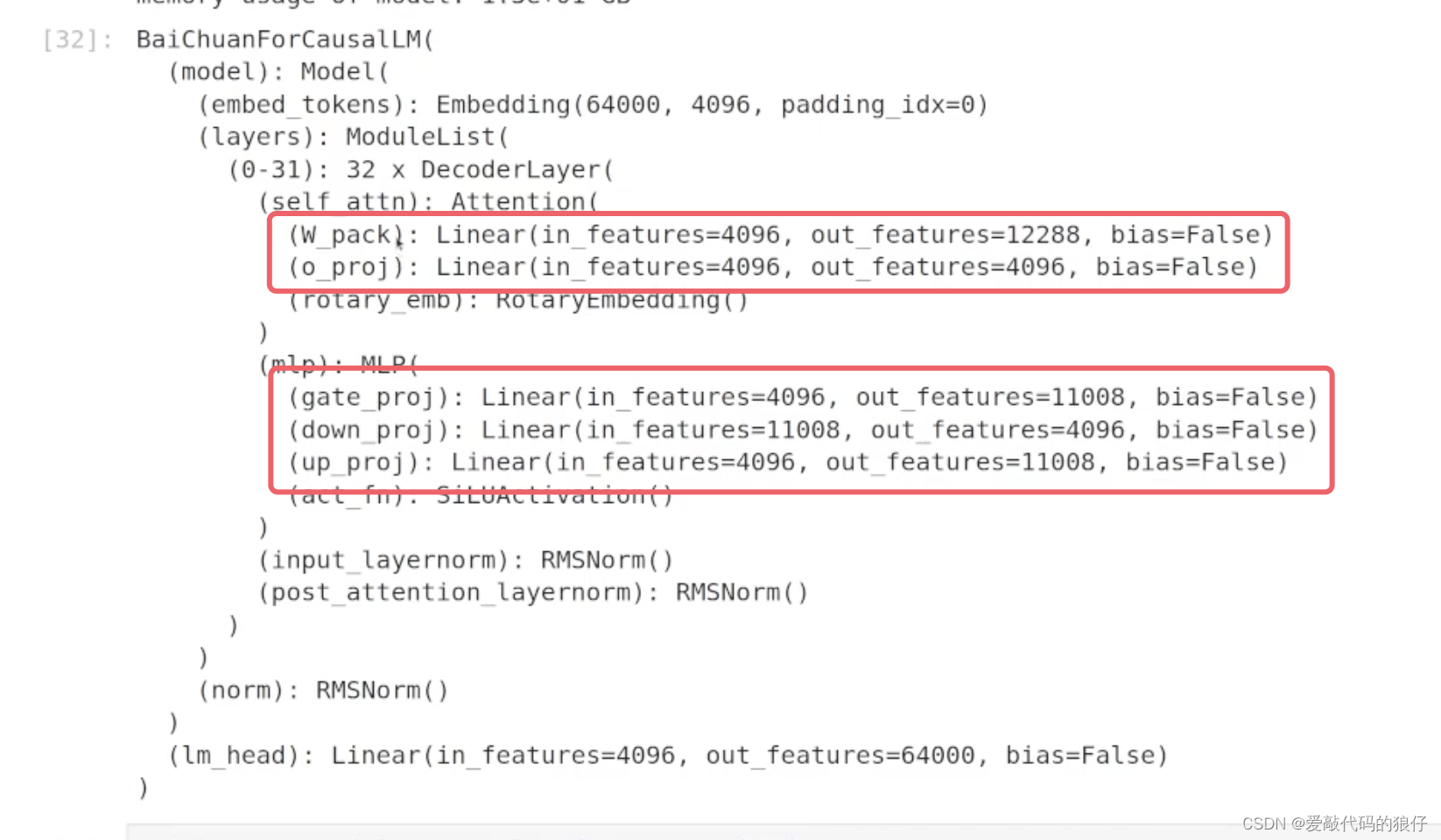
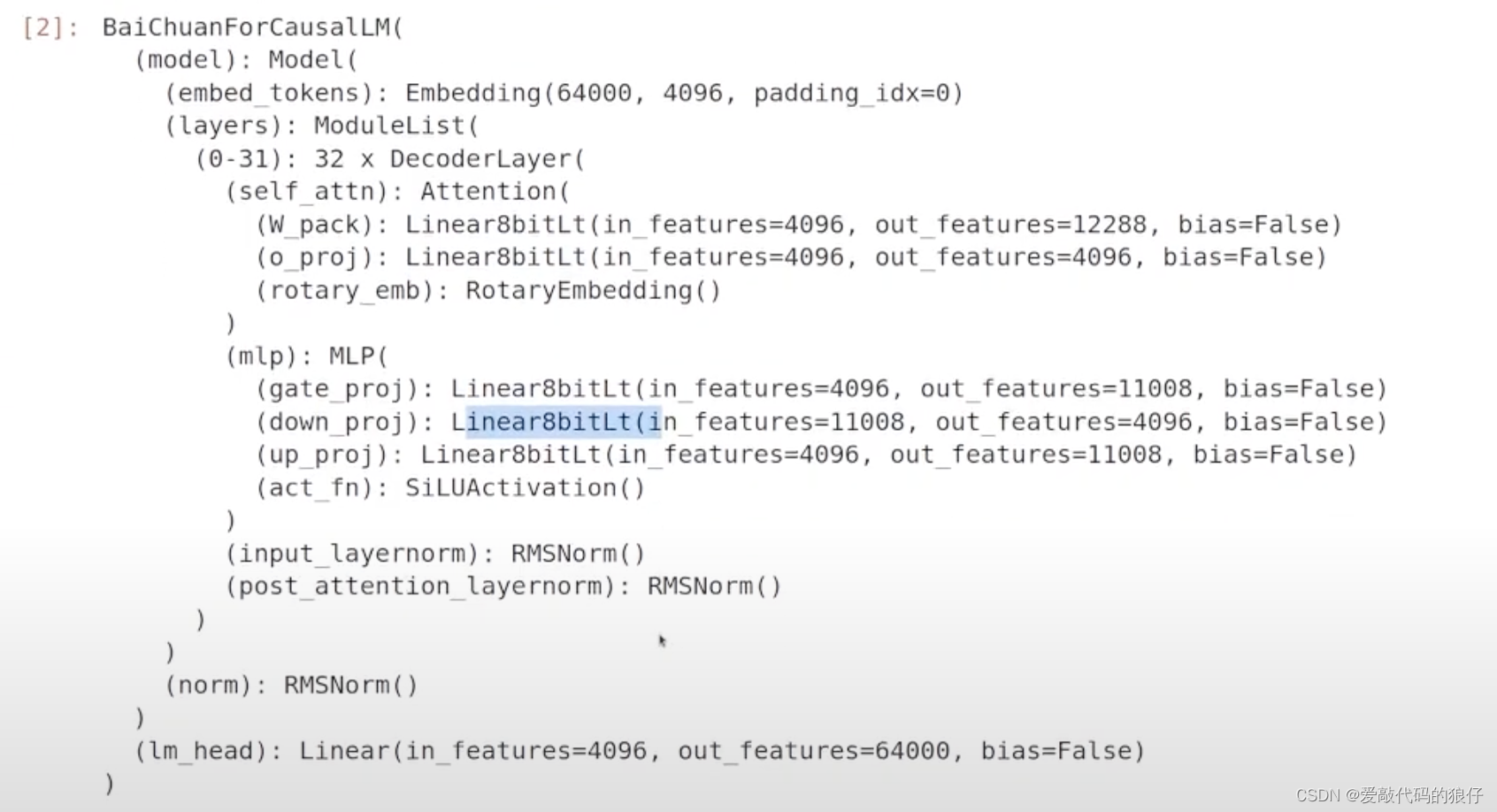
训练的时候模型会计算损失函数,一般采用CrossEntropyLoss
另外语言模型的loss是根据上一个输入去预测下一个输出,所以labels和input_ids会差一位,因此在Transformers中的forward中已经定义了,如下代码

另外一些参数的介绍,学习率,GPU实际使用的数量 * batch_size
显存较小可以调低对应的batch_size,调高累计梯度
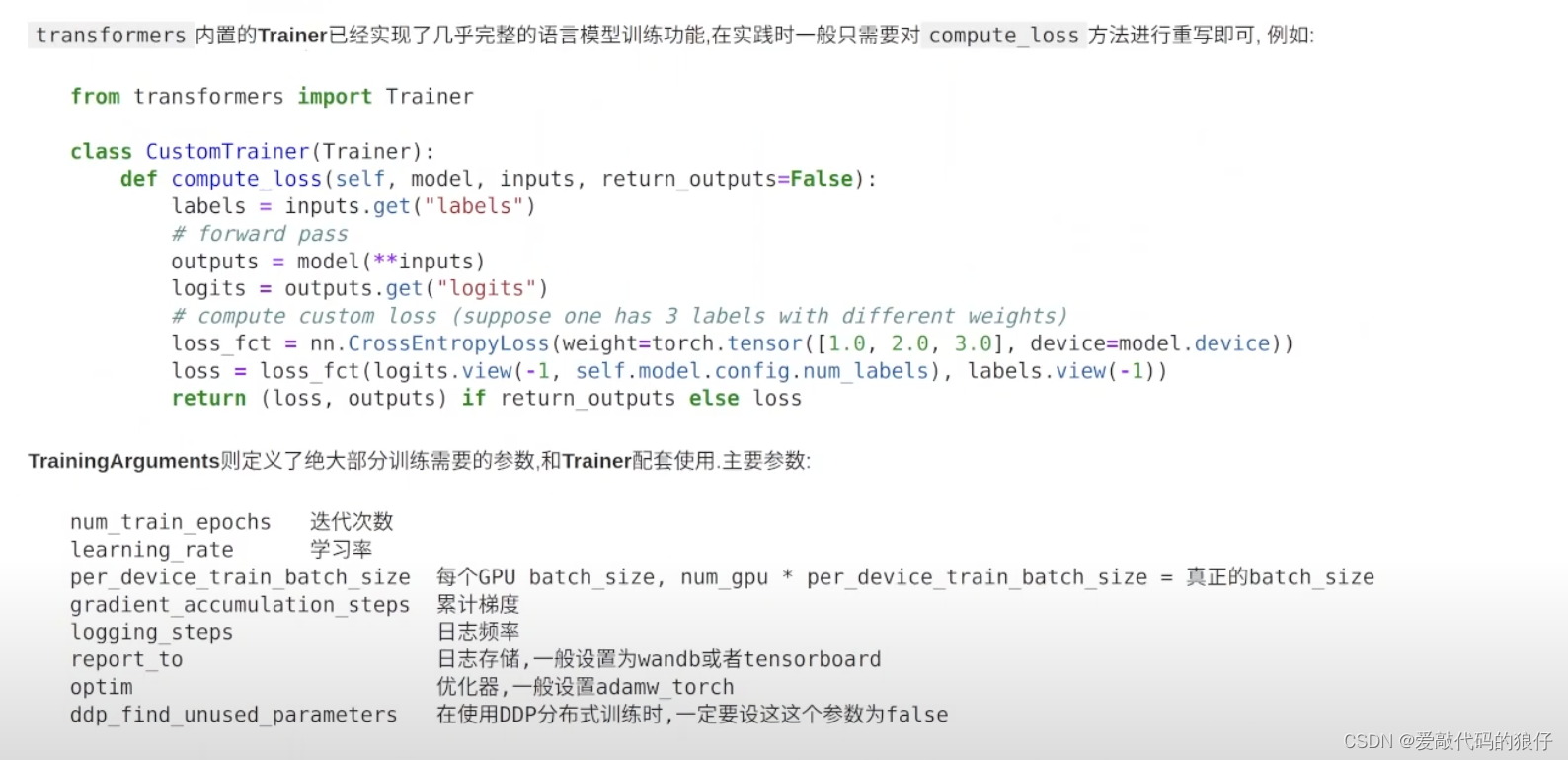
三、模型微调的实际操作(训练)
1,准备数据集,一般如果没有专有数据集的话一般用GPT处理数据(蒸馏数据),然后预处理数据,最后进行数据微调。gpt-llm-trainer集成了这三步
数据蒸馏:数据集蒸馏旨在构造一个合成数据集,其数据规模远小于原始数据集,但却能使在其上面训练的模型达到和原始数据集相似的精度。论文链接: Dataset Distillation by Matching Training Trajectories















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









