







A Simple Framework for Contrastive Learning of Visual Representations
2020年,已开源 SimCLR
参考文章点击这里
参考文章
主要思想:
1、对比学习是什么?
对比学习就是让机器去学会区分相似和不相似的事物。
相似与不相似图像的定义:假设送入网络的一批图像有2个AB,对一个图像A进行数据增强方式得到A1,A2,对B进行数据增强得到B1,B2。则A1A2之间是相似的,B1B2之间是相似的,我们把它就叫做正样本;A1B1,A1B2以及A2B1,A2B2之间是不同的,我们将它定义为负样本。
其中使用到的一些具体的数据增强方式:**随机裁剪和恢复,随机颜色失真,随机高斯模糊。**后续实验发现单个的数据增强方式效果并不是很好,而且随机裁剪与颜色失真结合的效果最好。
2、怎么做?
主要结构:

这篇文章主要是针对于图像分类任务。对数据集中的一幅图像x,进行数据增强操作,得到两张增强图像xi,xj。然后经过f(.)得到图像的向量形式hi,再送入“投影仪”g(.)得到输出zi,zj将特征映射到适合做对比损失的空间上。将这两幅图像之间做一个对比度损失。
公式表示流程为: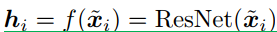
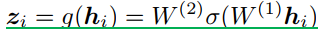
xi是数据增强后的图像,送入f(.)(使用的是Resnet50)得到hi,g(.)使用的是MLP(两层)得到输出zi(σ is a ReLU 非线性)。
所以*对比度损失其实就是实现相同的一个原图像的不同数据增强版本之间的一致性最大化。对两张图像AB则对比损失表示为:
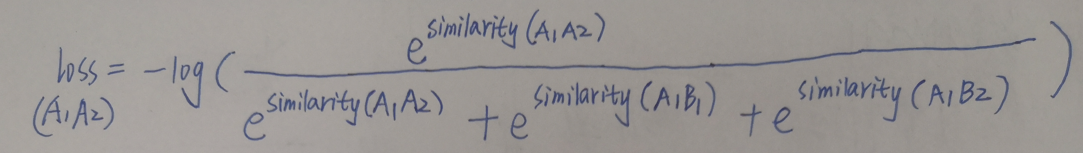
相似度计算:余弦相似度

然后我们计算A2的,与A1同理,是位置互换后的:

通用形式:当一匹图像有N张时,增强图像有2N个。则对其中的一幅图像来说,其中的2(N-1)个是它的负样本,有着相同原图像的两种增强方式得到的图像之间是正样本。我们计算大小为N = 2的批次中所有对上的损耗并取平均值:
3、注意:
一旦在对比学习任务上对SimCLR模型进行了训练,就可以将其用于转移学习。**就不使用后半部分的“投影头”,直接使用来自编码器的表示代替从投影头获得的表示。**直接用于下游任务。
附论文伪代码:

额外学习:三元组损失
主要思想:输入三张图像,分别是原图像、正样本以及负样本。我们希望模型可以学习到正样本与原图之间的距离越小越好, 原图与负样本之间的距离越大越好,这个损失就叫做三元组损失。可以用如下公式来表示:
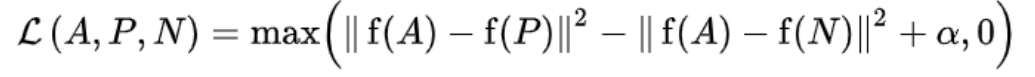
使用欧式距离衡量两者之间的距离大小,参数a是在比较时将正样本与负样本分开设置的阈值。
三元组损失参考链接点这
三月份最后一天今日打卡!
明天也要继续加油呀~!!!















 788
788











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









