







本篇文章主要跟着代码随想录的刷题网站来学习的,Carl哥写的算法是真的详细、简单、又系统,解决了我长久以来学习算法吃力的困境,希望大家多多支持他
1.双指针
1.1字符串中第二大的数字
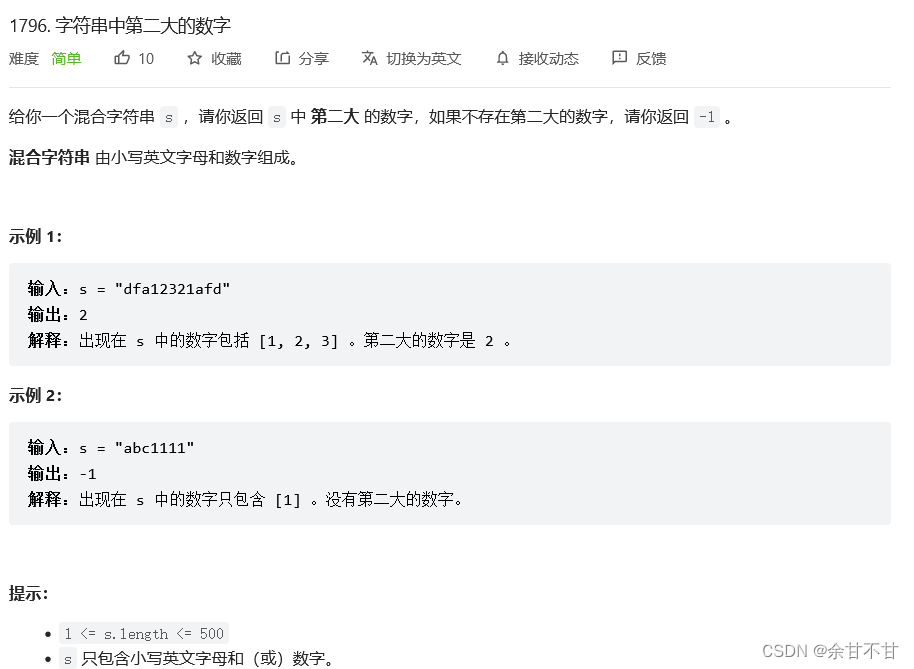
- 思路
暂不写
- 代码
class Solution {
public int secondHighest(String s) {
// 顾名思义,first 是用来记录第一个的,second 是用来记录第二个的
int first = -1, second = -1;
for (char c : s.toCharArray()) {
// 如果 c 是一个数字,那么就进行检查处理
if (Character.isDigit(c)) {
// 首先字符转换成数字
int num = c - '0';
// 如果 first 还没有赋值呢,那么就直接赋值
if (first == -1) first = num;
// first 已经带值,而且 num 比 first 还大,那么就更新它们
else if (num > first) {
second = first;
first = num;
} else if (num < first && num > second)
// 如果介于两者中间,那么就只更新第二个值
second = num;
}
}
return second;
}
}
1.2 删除链表的倒数第N个节点
- 题目
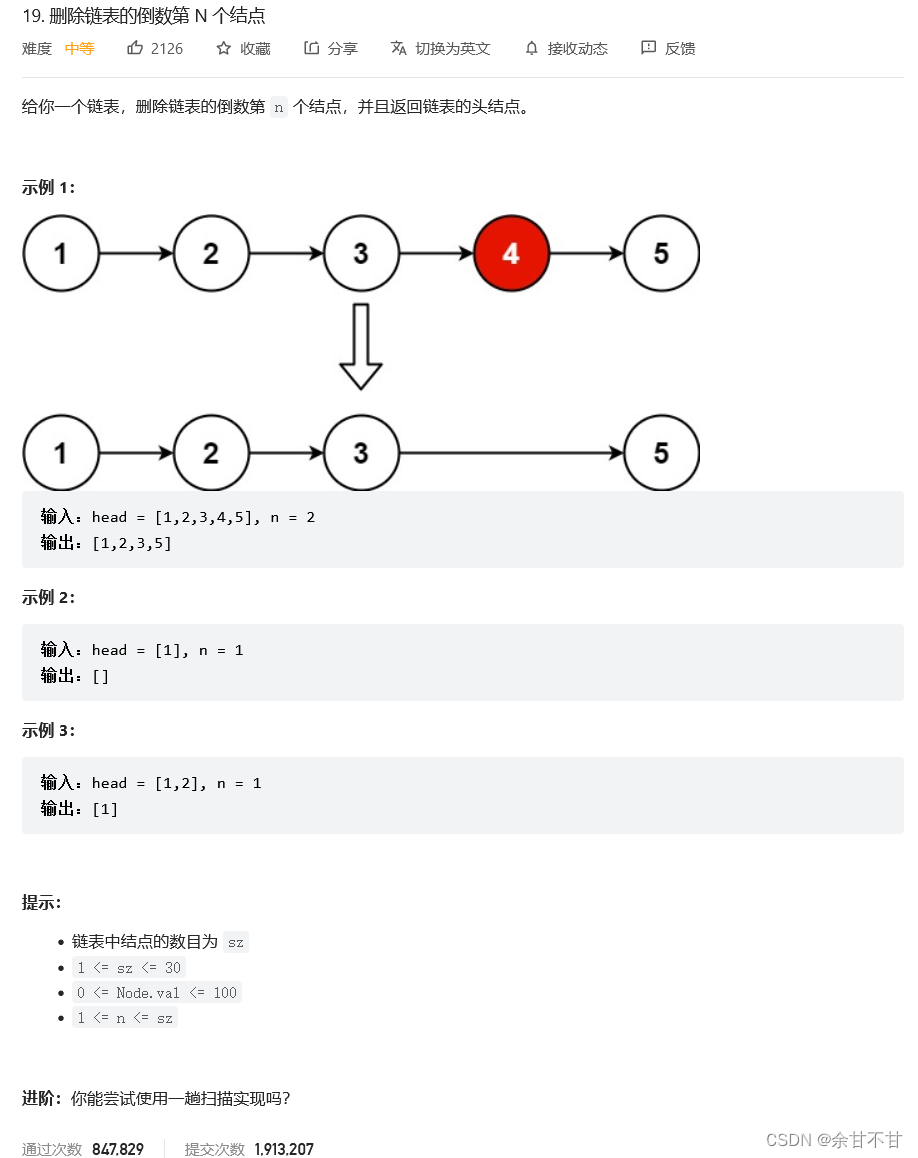
- 思路
详解请看链表
2.递归
其实我们既然可以用递归来解决二叉树的遍历问题,那么反过来我们其实用树的结构去形象理解递归过程
2.1题目描述

/*
// Definition for a Node.
class Node {
public int val;
public List<Node> children;
public Node() {}
public Node(int _val) {
val = _val;
}
public Node(int _val, List<Node> _children) {
val = _val;
children = _children;
}
};
*/
class Solution {
public List<Integer> preorder(Node root) {
List<Integer> res = new ArrayList<>();
helper(root, res);
return res;
}
public void helper(Node root, List<Integer> res) {
if (root == null) {
return;
}
res.add(root.val);
for (Node ch : root.children) {
helper(ch, res);
}
}
}
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/n-ary-tree-preorder-traversal/solution/n-cha-shu-de-qian-xu-bian-li-by-leetcode-bg99/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

自我理解:所谓递归就是先沿着1->3->5这条路走到底,但走一条很长的路总得一直带点什么东西才能找到回去的路,此题中的list就是一直带着的东西.
3.字典树
3.1 基础概念


3.2字典树的实现
- 题目

- 实现思路

- 代码:
class Trie {
private Trie[] children;
private boolean isEnd;
public Trie() {
children = new Trie[26];
isEnd = false;
}
public void insert(String word) {
Trie node = this;
for (int i = 0; i < word.length(); i++) {
char ch = word.charAt(i);
int index = ch - 'a';
if (node.children[index] == null) {
node.children[index] = new Trie();
}
node = node.children[index];
}
node.isEnd = true;
}
public boolean search(String word) {
Trie node = searchPrefix(word);
return node != null && node.isEnd;
}
public boolean startsWith(String prefix) {
return searchPrefix(prefix) != null;
}
private Trie searchPrefix(String prefix) {
Trie node = this;
for (int i = 0; i < prefix.length(); i++) {
char ch = prefix.charAt(i);
int index = ch - 'a';
if (node.children[index] == null) {
return null;
}
node = node.children[index];
}
return node;
}
}
3.3字典树search()函数的升级
- 力扣地址
- 题目

- 代码
class Solution {
public String longestWord(String[] words) {
Trie node=new Trie();
for(int i=0;i<words.length;i++){
node.insert(words[i]);
}
String s="";
for(int i=0;i<words.length;i++){
if(node.search(words[i])){
if(words[i].length()>s.length()){
s=words[i];
}
if(words[i].length()==s.length()&&words[i].compareTo(s)<0){
s=words[i];
}
}
}
return s;
}
class Trie{
Trie[] children;
boolean isEnd;
public Trie(){
children=new Trie[26];
isEnd=false;
}
public void insert(String words){
Trie node=this;
for(int i=0;i<words.length();i++){
char ch=words.charAt(i);
int index=ch-'a';
if(node.children[index]==null){
node.children[index]=new Trie();
}
node = node.children[index];
}
node.isEnd=true;
}
public boolean search(String words){
Trie node=this;
for(int i=0;i<words.length();i++){
char ch=words.charAt(i);
int index=ch-'a';
if(node.children[index]==null||!node.children[index].isEnd){
return false;
}
node=node.children[index];
}
return node!=null&&node.isEnd;
}
}
}

该代码再字典树的基础上是如何判断words词典中其他单词逐步添加一个字符组成的呢?
作者的思路是极其神奇的,他只加了一句话就实现了相加的过程

4.DFS和BFS
DFS
- 迷宫问题
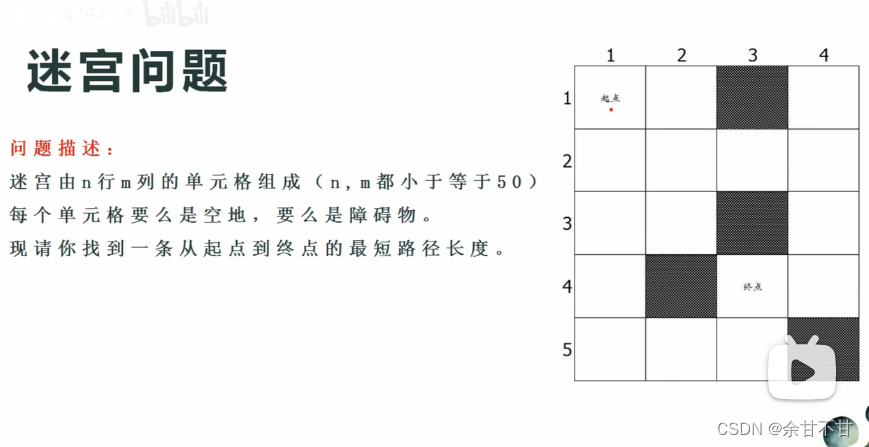
package August;
import java.util.Scanner;
public class test {
static int p; //先申明再到下面输入
static int q;
static int min = Integer.MAX_VALUE;
static int[][] map = new int[100][100];
static boolean[][] visit = new boolean[100][100];
static int[] dx = {0, 1, 0, -1};
static int[] dy = {1, 0, -1, 0};
/*
5 4
1 1 2 1
1 1 1 1
1 1 2 1
1 2 1 1
1 1 1 2
1 1 4 3
*/
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt();
int m = scanner.nextInt();
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
map[i][j] = scanner.nextInt();
}
}
int startx = scanner.nextInt();
int starty = scanner.nextInt();
p = scanner.nextInt();
q = scanner.nextInt();
dfs(startx, starty, 0);
System.out.println(min);
scanner.close();
}
public static void dfs(int x, int y, int step) {
if (x == p && y == q) {
if (step < min) min = step;
return; }
// 深度优先搜索
for (int i = 0; i < 4; i++) {
int tx = x + dx[i];
int ty = y + dy[i];
if (map[tx][ty]==1 && visit[tx][ty]==false){
visit[tx][ty]=true;
dfs(tx, ty, step + 1);
visit[tx][ty]=false;
}
}
return;
}
}
BFS
1
1
5.时间复杂度详解
5.1基本概念
- T(n)的定义

但随着数据量的增大,算出T(n)十分麻烦,所以我们使用T(n)的简化值即时间复杂度O(n)来代替它,T(n)与O(n)之间的转化

如果运行语句存在分支,还是以运行时间最长的分支为判断依据,如下图为O(n*2)

5.1对数时间复杂度是如何计算出来的

考虑到时间复杂度的简化,我们T(n)只计算printf()的执行语句,

log下面的也算是常数,所以时间复杂度即为logn
6.回溯
6.1 一般用来解决的问题

6.2 组合问题模板
- 题目
 - 力扣地址
- 力扣地址
我们知道,回溯问题都可以画成一个树形结构图,此题的树形结构图为

-
回溯三部曲

-
代码
class Solution {
public List<List<Integer>> combine(int n, int k) {
Deque<Integer> path=new ArrayDeque<>();
List<List<Integer>> lists=new ArrayList<>();
backTracing(n,k,1,path,lists);
return lists;
}
public void backTracing(int n,int k,int starIndex,Deque<Integer> path,List<List<Integer>> lists){
if(path.size()==k){//确定终止条件
lists.add(new ArrayList<>(path));
return;
}
//单层递归逻辑
for(int i=starIndex;i<=n;i++){//对节点的每一个孩子节点进行遍历
//加入元素
path.addLast(i);
//递归调用
backTracing(n,k,i+1,path, lists);
//回溯
path.removeLast();
}
}
}
6.3组合问题的剪枝
我们继续以6.2的组合问题为模板

别看只是一个小小的改动,但如果树的高度很深的话,就是一个极大的优化了,两次提交时间效率的对比

树的简易画法


for (int i = startIndex; i <= n - (k - path.size()) + 1; i++) // i为本次搜索的起始位置
6.3.2 组合问题2(解决集合有重复元素,但还不能有重复的组合。)

class Solution {
public List<List<Integer>> combinationSum2(int[] candidates, int target) {
Arrays.sort(candidates);//为了将重复的数字都放到一起,所以先进行排序
boolean[] flag=new boolean[candidates.length]; //加标志数组,用来辅助判断同层节点是否已经遍历
Deque<Integer> path=new ArrayDeque<>();
List<List<Integer>> result=new ArrayList<>();
backTracking(candidates,0,0,target,path,result,flag);
return result;
}
public static void backTracking(int[] candidates, int startIndex,int sum,int target, Deque<Integer> path, List<List<Integer>> result,boolean[] flag){
if(sum==target){
result.add(new ArrayList<>(path));
return;
}
for(int i=startIndex;i<candidates.length&&sum+candidates[i]<=target;i++){
if(i>0&&candidates[i]==candidates[i-1]&&!flag[i-1]){//出现重复节点,同层的第一个节点已经被访问过,所以直接跳过
continue;
}
path.addLast(candidates[i]);
flag[i]=true;
backTracking(candidates,i+1,sum+candidates[i],target,path,result,flag);
flag[i]=false;
path.removeLast();
}
}
}
6.4分割回文串
- 题目

- 抽象的树形结构
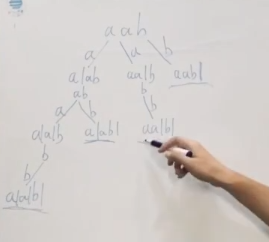

很明显在分割的过程中,跟我们组合问题中选取元素的思路是及其相似的,所以我们考虑到了回溯,那怎么在代码中展示分隔符这一表示呢,其实分隔符的位置就是我们在单层遍历中的startIndex
- 代码
class Solution {
public List<List<String>> partition(String s) {
Deque<String> path=new ArrayDeque<>();
List<List<String>> result=new ArrayList<>();
backTracking(s,0,path,result);
return result;
}
public void backTracking(String s, int startIndex, Deque<String> path, List<List<String>> result){
if(startIndex==s.length()){//分隔符到达末尾就结束
result.add(new ArrayList<>(path));
return;
}
for(int i=startIndex;i<s.length();i++){
if(isPalindrome(s,startIndex,i)){
path.addLast(s.substring(startIndex,i+1));//选取分割区间
}else {
continue;//一定要写else,不然就会报错
}
backTracking(s,i+1,path,result);
path.removeLast();
}
return;
}
public boolean isPalindrome(String s,int startIndex,int endIndex){//判断字符串的某个子集是否为回文串
for(int i=startIndex,j=endIndex;i<j;i++,j--){
if(s.charAt(i)!=s.charAt(j)){
return false;
}
}
return true;
}
}
6.5复原IP地址(分割回文串加强版)
-
题目

-
代码
此题的难点有很多,在分割回文串时,我们的终止条件是startIndex到达末尾,因为在叶子节点中分隔符是必然会达到末尾的,但在此题中显示是行不通的,本题明确要求只会分成4段,所以不能用切割线切到最后作为终止条件,而是分割的段数作为终止条件。pointNum表示逗点数量,pointNum为3说明字符串分成了4段了,然后验证一下第四段是否合法,如果合法就加入到结果集里
class Solution {
List<String> result=new ArrayList<>();
public List<String> restoreIpAddresses(String s) {
backTracking(s,0,0);
return result;
}
public void backTracking(String s,int startIndex,int pointNum){
if(pointNum==3){
if(effectiveNum(s,startIndex,s.length()-1)){
result.add(s);
// System.out.println("result:"+result);
}
return;
}
for(int i=startIndex;i<s.length();i++){
if(effectiveNum(s,startIndex,i)){
s=s.substring(0,i+1)+"."+s.substring(i+1);
// System.out.println("s:"+s);
// System.out.println("i+2=:"+(i+2));
backTracking(s,i+2,pointNum+1);
s=s.substring(0,i+1)+s.substring(i+2);
}else {
continue;
}
}
}
public boolean effectiveNum(String s,int startIndex,int endIndex){
if(startIndex>endIndex){//以s:10.10.23.为例,此时i==7,进入下一个backTracking()i,startIndex=i+2=9去了,可此时s数组下表最大却只有8,这样就会越界
return false;
}
if (s.charAt(startIndex) == '0' && startIndex != endIndex) { // 0开头的数字不合法
return false;
}
for(int i=startIndex;i<=endIndex;i++){
if(s.charAt(i)<'0'||s.charAt(i)>'9'){
return false;
}
}
int num=0;
for(int i=startIndex;i<=endIndex;i++){
num=num*10+(s.charAt(i)-'0');
}
if(num>255||num<0){ //一定要加入num<0的判断,因为如果数字字符串太长,转化为整数时会溢出,就会借助符号位变为负数
return false;
}
return true;
}
}
6.6 子集问题

- 构造树图

从构造的树图中可以很明显看出,此题不同于组合问题是取叶子节点,而是取所有的节点
- 代码
class Solution {
Deque<Integer> path=new ArrayDeque<>();//一定要new,不然会报空指针异常
List<List<Integer>> result=new ArrayList<>();
public List<List<Integer>> subsets(int[] nums) {
backTracking(nums,0);
return result;
}
public void backTracking(int[ ] arr,int startIndex){
result.add(new ArrayList<>(path));//取路径上的所有节点
if(startIndex==arr.length){ //其实这也是下面for循环的结束条件,可以不用写1
return;
}
for(int i=startIndex;i<arr.length;i++){
path.addLast(arr[i]);
backTracking(arr,i+1);
path.removeLast();
}
return;
}
}
6.7递增子序列(子集问题不用排序的树层查重,单层递归逻辑的加强)
- 题目

- 力扣地址
- 构造的树图

- 代码
class Solution {
Deque<Integer> path=new ArrayDeque<>();
List<List<Integer>> result=new ArrayList<>();
public List<List<Integer>> findSubsequences(int[] nums) {
backTracking(nums,0);
return result;
}
public void backTracking(int[] nums,int startIndex){
if(path.size()>=2){ //对应题目中至少有两个元素,即树的高度>=2结束(从0开始算)
result.add(new ArrayList<>(path));
// System.out.println("result:"+result);
}
if(startIndex==nums.length){ //可以不用写
return;
}
boolean[] flag=new boolean[201];// 这里使用数组来进行去重操作,题目说数值范围[-100, 100]
for(int i=startIndex;i<nums.length;i++){
if((!path.isEmpty()&&i>0&&nums[i]<path.getLast())||flag[nums[i]+100]){
//path.isEmpty()必须放在前面,不然path为空时path.getLast()会导致程序异常结束
//判断加入的元素是否为升序以及树层查重
continue;
}
else {
path.addLast(nums[i]);
// System.out.println("path:"+path);
flag[nums[i]+100]=true;
}
backTracking(nums,i+1);
path.removeLast();
}
}
}
6.8全排列
-
题目

-
树形结构图
自己在画树形结构图中,虽然自己能想到用一个boolean数组来表示是否使用,但在画图中却无法灵性的把这个flag数组加上画图,这是值得学习的一个地方

- 代码
class Solution {
Deque<Integer> path=new ArrayDeque<>();
List<List<Integer>> result=new ArrayList<>();
public List<List<Integer>> permute(int[] nums) {
boolean[] flag=new boolean[nums.length];
backTracking(nums,flag);
return result;
}
public void backTracking(int[] nums,boolean[] flag){
if(path.size()==nums.length){
result.add(new ArrayList<>(path));
// System.out.println("result:"+result);
return;
}
for(int i=0;i<nums.length;i++){
if(!flag[i]){
path.addLast(nums[i]);
// System.out.println("path:"+path);
flag[i]=true;
}else {
continue;
}
backTracking(nums,flag);
flag[i]=false;
path.removeLast();
}
return;
}
}
代码美观度优化
class Solution {
Deque<Integer> path=new ArrayDeque<>();
List<List<Integer>> result=new ArrayList<>();
public List<List<Integer>> permute(int[] nums) {
boolean[] flag=new boolean[nums.length];
backTracking(nums,flag);
return result;
}
public void backTracking(int[] nums,boolean[] flag){
if(path.size()==nums.length){
result.add(new ArrayList<>(path));
// System.out.println("result:"+result);
return;
}
for(int i=0;i<nums.length;i++){
if(flag[i]){
continue;
}
path.addLast(nums[i]);
flag[i]=true;
backTracking(nums,flag);
flag[i]=false;
path.removeLast();
}
return;
}
}
6.9N皇后问题(其实是回溯的二维问题)
- 题目

刚开始遇到这种二维的问题,虽然知道要用到回溯,但难点之一就是终止条件如何确定,其实我们加入对某点是否合法的判断后,回溯的终止条件就是这一次递归能进入到最后一行。
此题还有一个难点就是如何把二维的字符数组转化为List,作者是给出了一个函数,但自己通过巧妙的运行StringBuilder也达到了此效果,值得鼓励.
然后就是对位置合法的判断了
public static boolean isValid(int n,int row,int col,char[][] arr){
//有同列的无效
for(int i=0;i<row;i++){
if(arr[i][col]=='Q'){
return false;
}
}
//45度角无效
for(int i=row-1,j=col-1;i>=0&&j>=0;i--,j--){//起初自己很困惑如果在第一行判断45度角的点岂不是直接报错,因为0-1已经超出数组的索引范围了,但通过测试,如果i<0,首先就会进入i>=0的判断,不满足,连函数体都不会进入,所以并不会报错
if(arr[i][j]=='Q'){
return false;
}
}
//135度角无效
for(int i=row-1,j=col+1;i>=0&&j<n;i--,j++){//与判断45度角类似
if(arr[i][j]=='Q'){
return false;
}
}
return true;
}
-
树状图

-
全部代码
class Solution {
List<List<String>> result=new ArrayList<>();
public List<List<String>> solveNQueens(int n) {
char[][] arr=new char[n][n];
for(int i=0;i<n;i++){
for(int j=0;j<n;j++){
arr[i][j]='.';
}
}
backTracking(n,0,arr);
return result;
}
public static boolean isValid(int n,int row,int col,char[][] arr){
//有同列的无效
for(int i=0;i<row;i++){
if(arr[i][col]=='Q'){
return false;
}
}
//45度角无效
for(int i=row-1,j=col-1;i>=0&&j>=0;i--,j--){//起初自己很困惑如果在第一行判断45度角的点岂不是直接报错,因为0-1已经超出数组的索引范围了,但通过测试,如果i<0,首先就会进入i>=0的判断,不满足,连函数体都不会进入,所以并不会报错
if(arr[i][j]=='Q'){
return false;
}
}
//135度角无效
for(int i=row-1,j=col+1;i>=0&&j<n;i--,j++){//与判断45度角类似
if(arr[i][j]=='Q'){
return false;
}
}
return true;
}
public void backTracking(int n,int row,char[][] arr){
if(row==n){
result.add(toListString(arr));
// System.out.println("result:"+result);
return;
}
for(int col=0;col<n;col++){
if(!isValid(n,row,col,arr)){
continue;
}
arr[row][col]='Q';
backTracking(n,row+1,arr);
arr[row][col]='.';
}
}
public List<String> toListString(char[][] arr){
List<String> result=new ArrayList<>();
StringBuilder s1=new StringBuilder();
for(char[] c:arr){
s1=new StringBuilder();
for(int i=0;i<c.length;i++){
s1.append(c[i]);
}
// System.out.println("s1:"+s1);
result.add(s1.toString());
}
return result;
}
}
7.二叉树
7.1二叉树节点的定义方式
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode() {}
TreeNode(int val) { this.val = val; }
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
}
7.1.1 用顺序数组初始化二叉树
- 代码
TreeNode
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode() {}
TreeNode(int val) { this.val = val; }
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
Test
public static void main(String[] args) {
int[] arr={0,1,2,3,4};
TreeNode root=new TreeNode();
List<Integer> result = new ArrayList<Integer>();
initial(arr,0,root);
preorder(root, result);
System.out.println(result);
}
//用数组初始化二叉树
public static void initial(int[] arr,int index,TreeNode root){
if(arr==null||arr.length==0)
{
System.out.println("数组为空,不可以按照二叉树的前序遍历");
}
root.val=arr[index];
// System.out.println("index:"+index);
if(2*index+1<arr.length){
root.left=new TreeNode();
initial(arr,2*index+1,root.left);
}
if(2*index+2<arr.length){
root.right=new TreeNode();
initial(arr,2*index+2,root.right);
}
}
//前序遍历用集合打印出二叉树
public static void preorder(TreeNode root, List<Integer> result) {
if (root == null) {
return;
}
result.add(root.val);
preorder(root.left, result);
preorder(root.right, result);
}
自己最初想的是用两个二参数arr和root去初始化,后面发现实现不了,看了别人的实现,发现需要再加一个index参数就能实现了
7.2二叉树前中后序的递归遍历
// 前序遍历·递归·LC144_二叉树的前序遍历
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> result = new ArrayList<Integer>();
preorder(root, result);
return result;
}
public void preorder(TreeNode root, List<Integer> result) {
if (root == null) {
return;
}
result.add(root.val);
preorder(root.left, result);
preorder(root.right, result);
}
}
// 中序遍历·递归·LC94_二叉树的中序遍历
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
inorder(root, res);
return res;
}
void inorder(TreeNode root, List<Integer> list) {
if (root == null) {
return;
}
inorder(root.left, list);
list.add(root.val); // 注意这一句
inorder(root.right, list);
}
}
// 后序遍历·递归·LC145_二叉树的后序遍历
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
postorder(root, res);
return res;
}
void postorder(TreeNode root, List<Integer> list) {
if (root == null) {
return;
}
postorder(root.left, list);
postorder(root.right, list);
list.add(root.val); // 注意这一句
}
}
7.3二叉树的迭代遍历
// 前序遍历顺序:中-左-右,入栈顺序:中-右-左
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> result = new ArrayList<>();
if (root == null){//一定要加,因为递归遍历中的终止条件,有root是否为空的判断
return result;
}
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while (!stack.isEmpty()){
TreeNode node = stack.pop();
result.add(node.val);
if (node.right != null){
stack.push(node.right);
}
if (node.left != null){
stack.push(node.left);
}
}
return result;
}
}
// 中序遍历顺序: 左-中-右 入栈顺序: 左-右
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> result = new ArrayList<>();
if (root == null){
return result;
}
Stack<TreeNode> stack = new Stack<>();
TreeNode cur = root;
while (cur != null || !stack.isEmpty()){
if (cur != null){
stack.push(cur);
cur = cur.left;
}else{
cur = stack.pop();
result.add(cur.val);
cur = cur.right;
}
}
return result;
}
}
// 后序遍历顺序 左-右-中 入栈顺序:中-左-右 出栈顺序:中-右-左, 最后翻转结果
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> result = new ArrayList<>();
if (root == null){
return result;
}
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while (!stack.isEmpty()){
TreeNode node = stack.pop();
result.add(node.val);
if (node.left != null){
stack.push(node.left);
}
if (node.right != null){
stack.push(node.right);
}
}
Collections.reverse(result);
return result;
}
}
7.4二叉树的层序遍历
-
思路
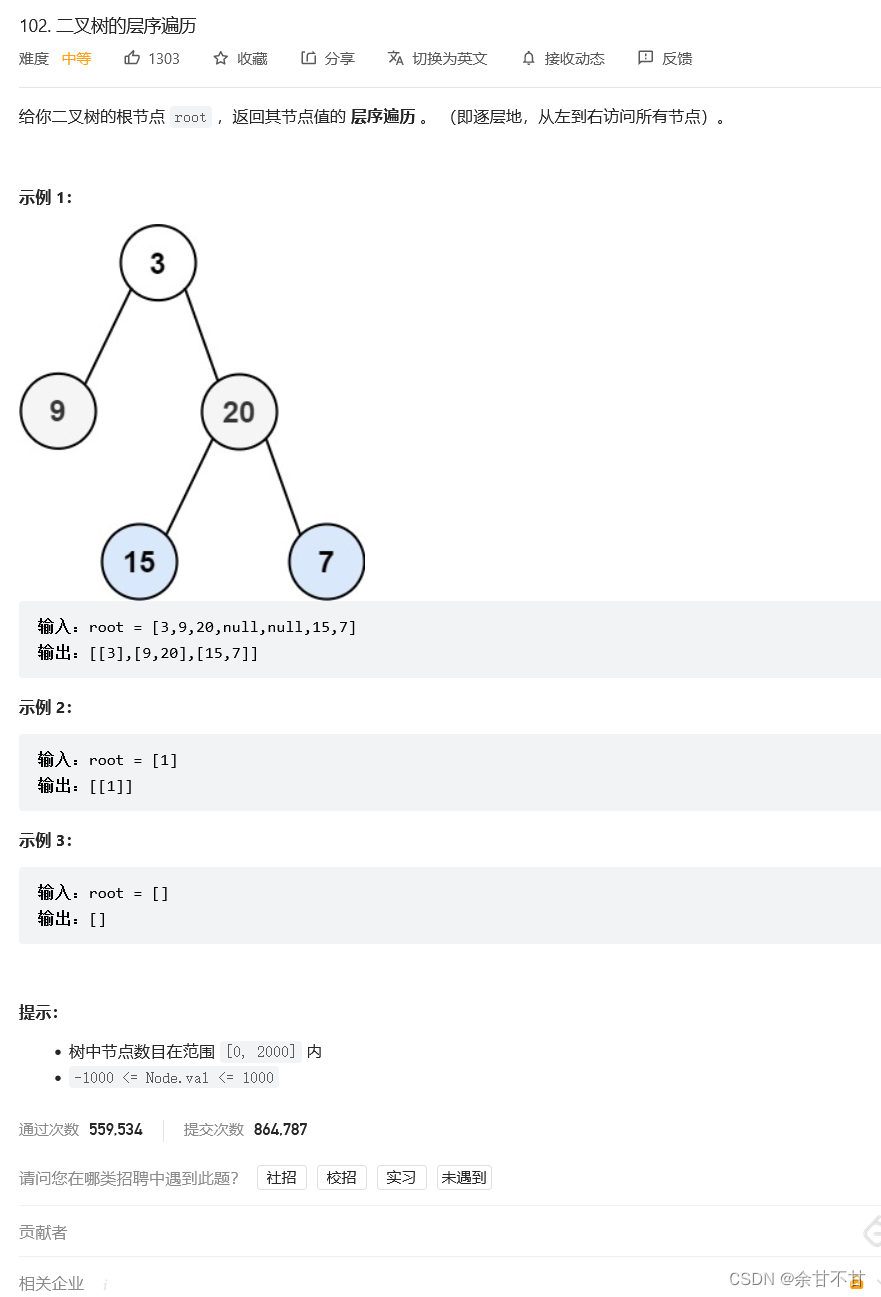
用队列实现,虽然我能存储每一层的节点,但自己在实现的过程中遇到了如何遍历每一层的节点的问题,后面在题解中才搞清楚需要再加一层while遍历每一次queue的长度
- 代码
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
Queue<TreeNode> queue=new LinkedList<>();
queue.offer(root);
List<List<Integer>> res=new ArrayList<>();
if(root==null){
return res;
}
while(!queue.isEmpty()){
int len=queue.size();
List<Integer> list=new ArrayList<>();
while(len>0){
TreeNode tem=queue.poll();
list.add(tem.val);
if(tem.left!=null) queue.offer(tem.left);
if(tem.right!=null) queue.offer(tem.right);
len--;
}
res.add(list);
}
return res;
}
}
7.5对称二叉树
-
思路
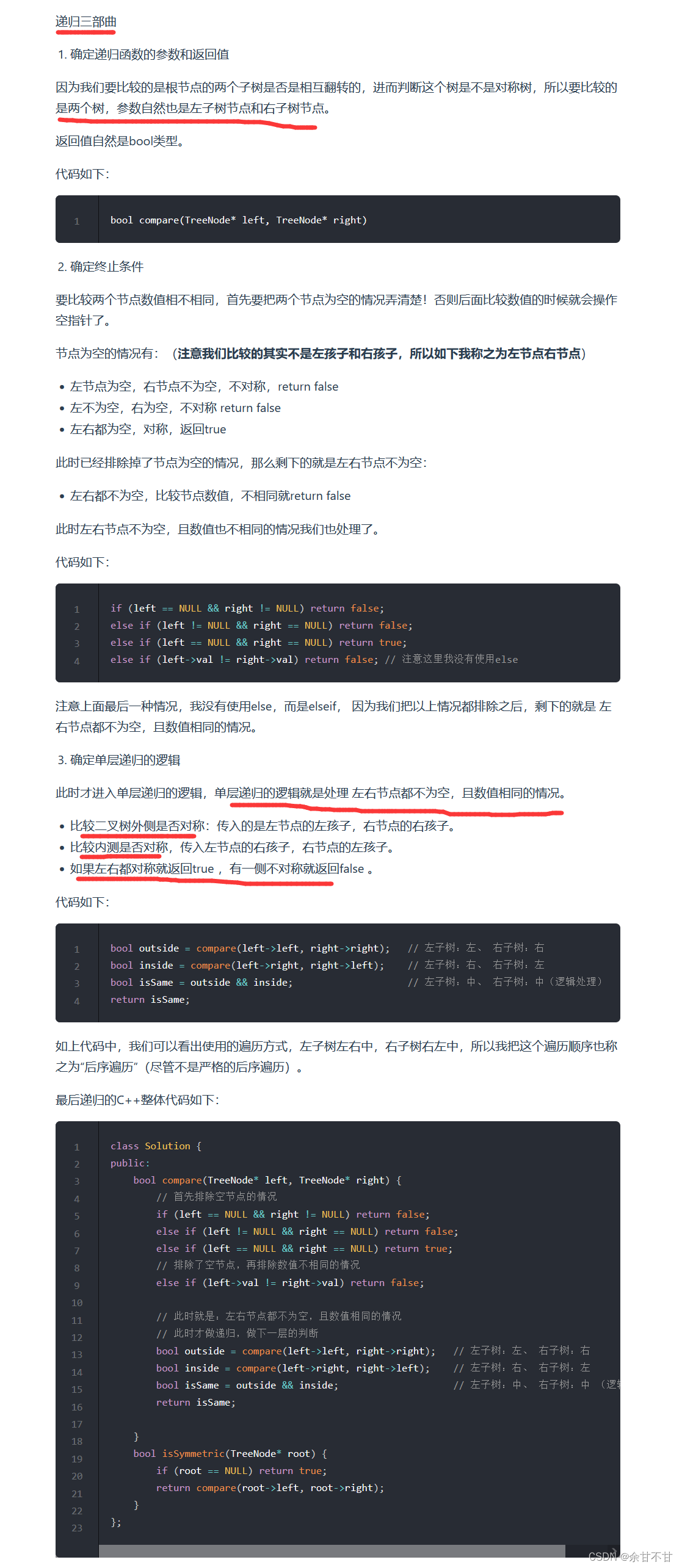
-
代码
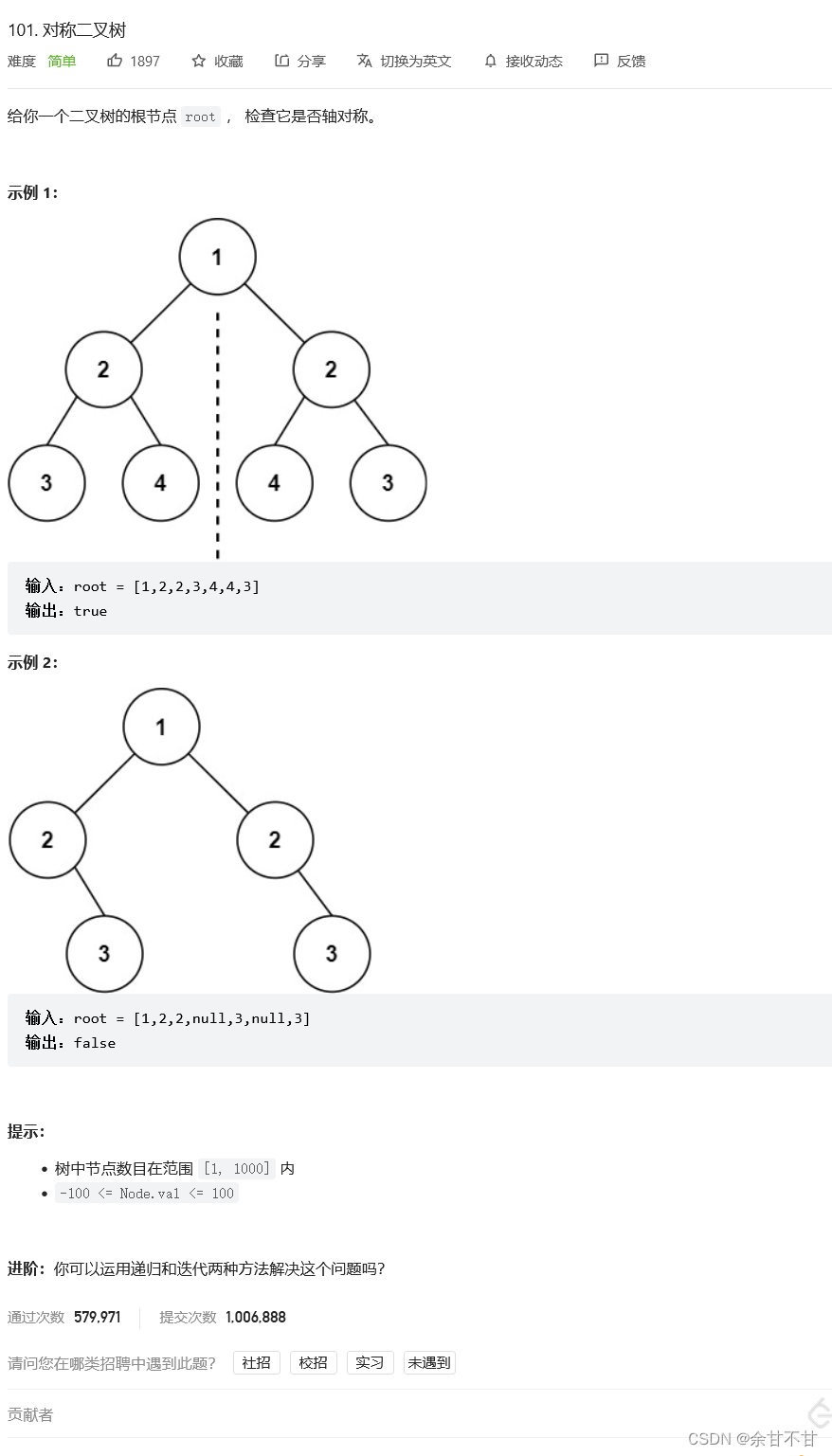
public boolean isSymmetric1(TreeNode root) {
return compare(root.left, root.right);
}
private boolean compare(TreeNode left, TreeNode right) {
if (left == null && right != null) {
return false;
}
else if (left != null && right == null) {
return false;
}
else if (left == null && right == null) {
return true;
}
else if (left.val != right.val) {
return false;
}
//如果两个节点的值相同了再进行下面的操作
// 比较外侧
boolean compareOutside = compare(left.left, right.right);
// 比较内侧
boolean compareInside = compare(left.right, right.left);
return compareOutside && compareInside;
}
7.6二叉树的最大深度
-
思路
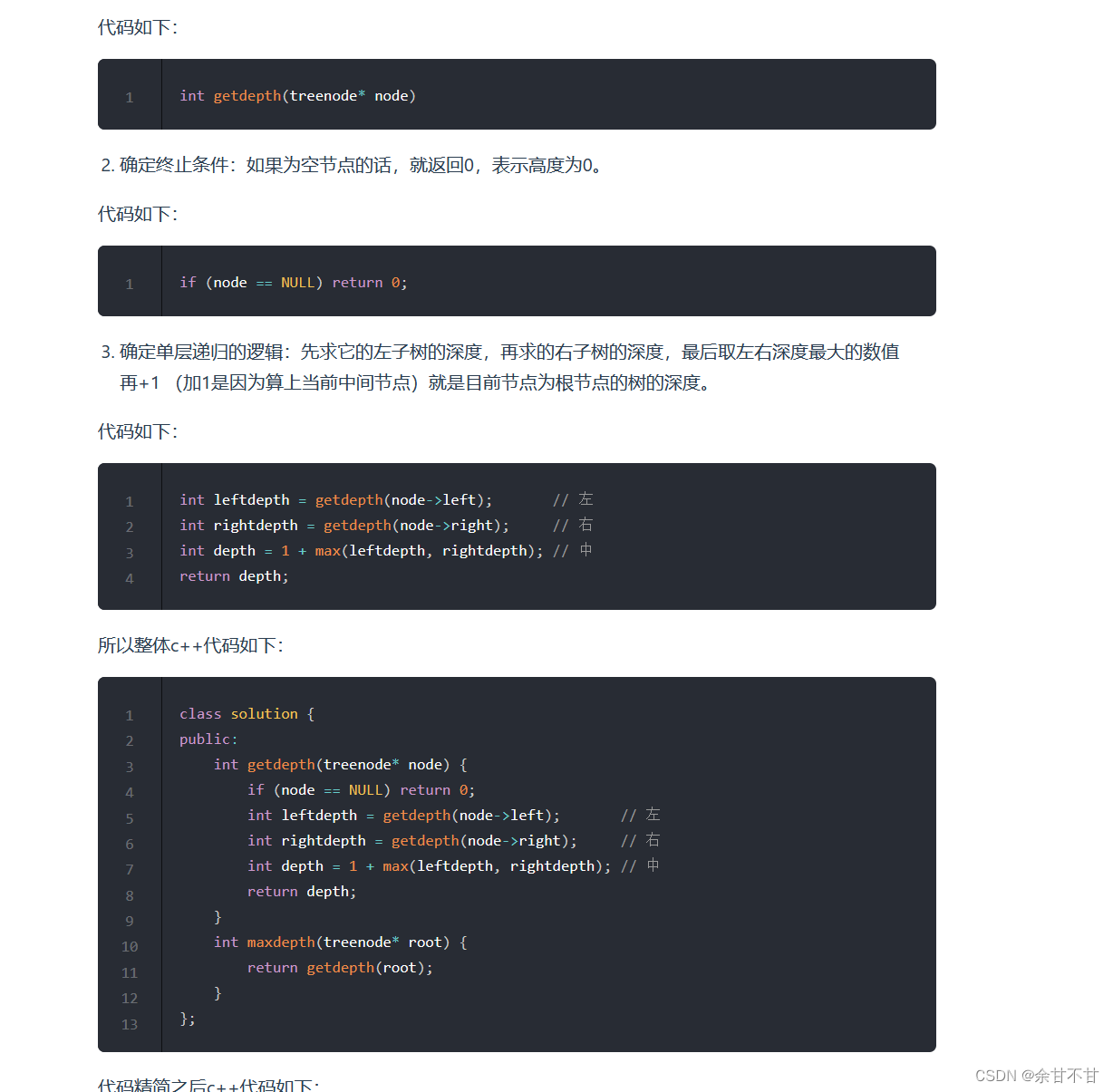
-
代码
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public int maxDepth(TreeNode root) {
return getDepth(root);
}
int getDepth(TreeNode root){
if(root==null) return 0;
int leftDepth=getDepth(root.left);
int rightDepth=getDepth(root.right);
int depth=1+Math.max(leftDepth,rightDepth);
return depth;
}
}
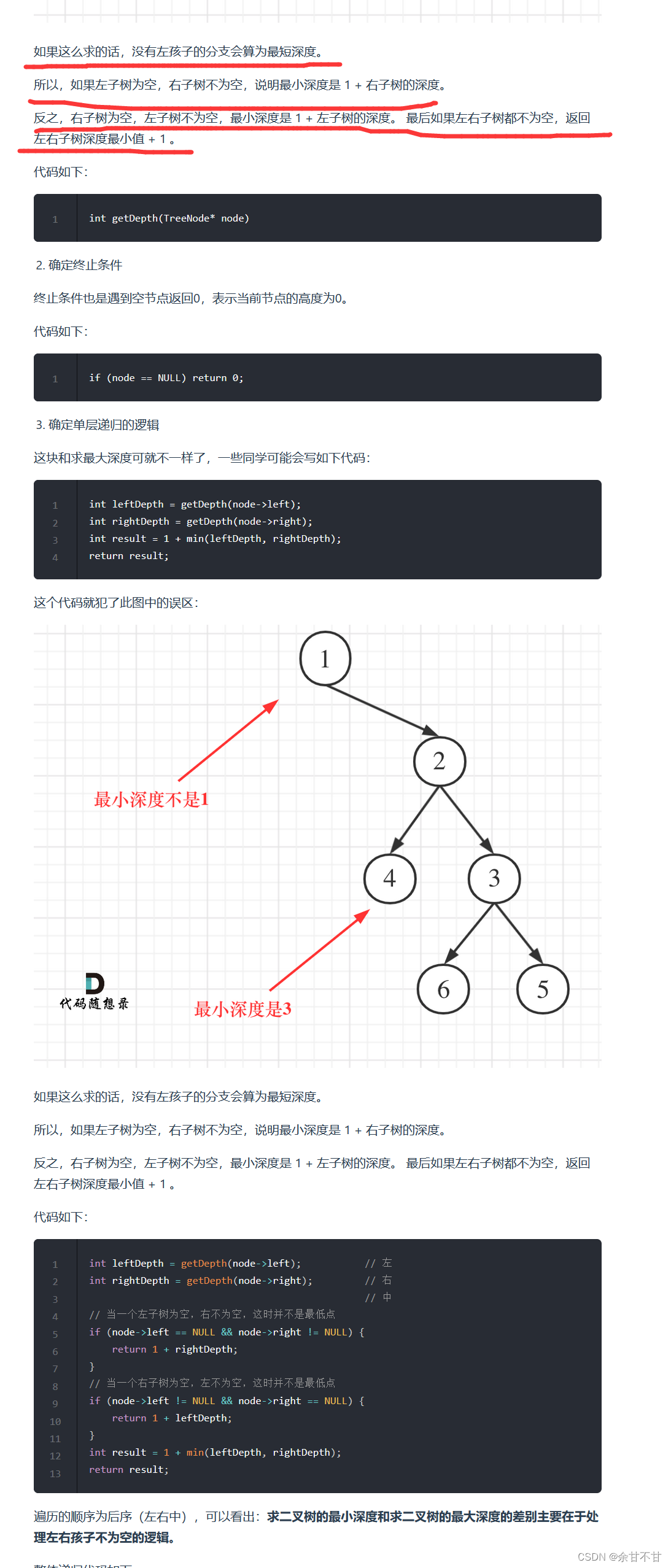
7.7二叉树的最小深度
-
思路
-
代码
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public int minDepth(TreeNode root) {
if(root==null) return 0;
int leftDepth=minDepth(root.left);
int rightDepth=minDepth(root.right);
if(root.left==null&&root.right!=null) return 1+rightDepth;
if(root.right==null&&root.left!=null) return 1+leftDepth;
int depth=1+Math.min(leftDepth,rightDepth);
return depth;
}
}
7.8完全二叉树的节点个数
-
思路
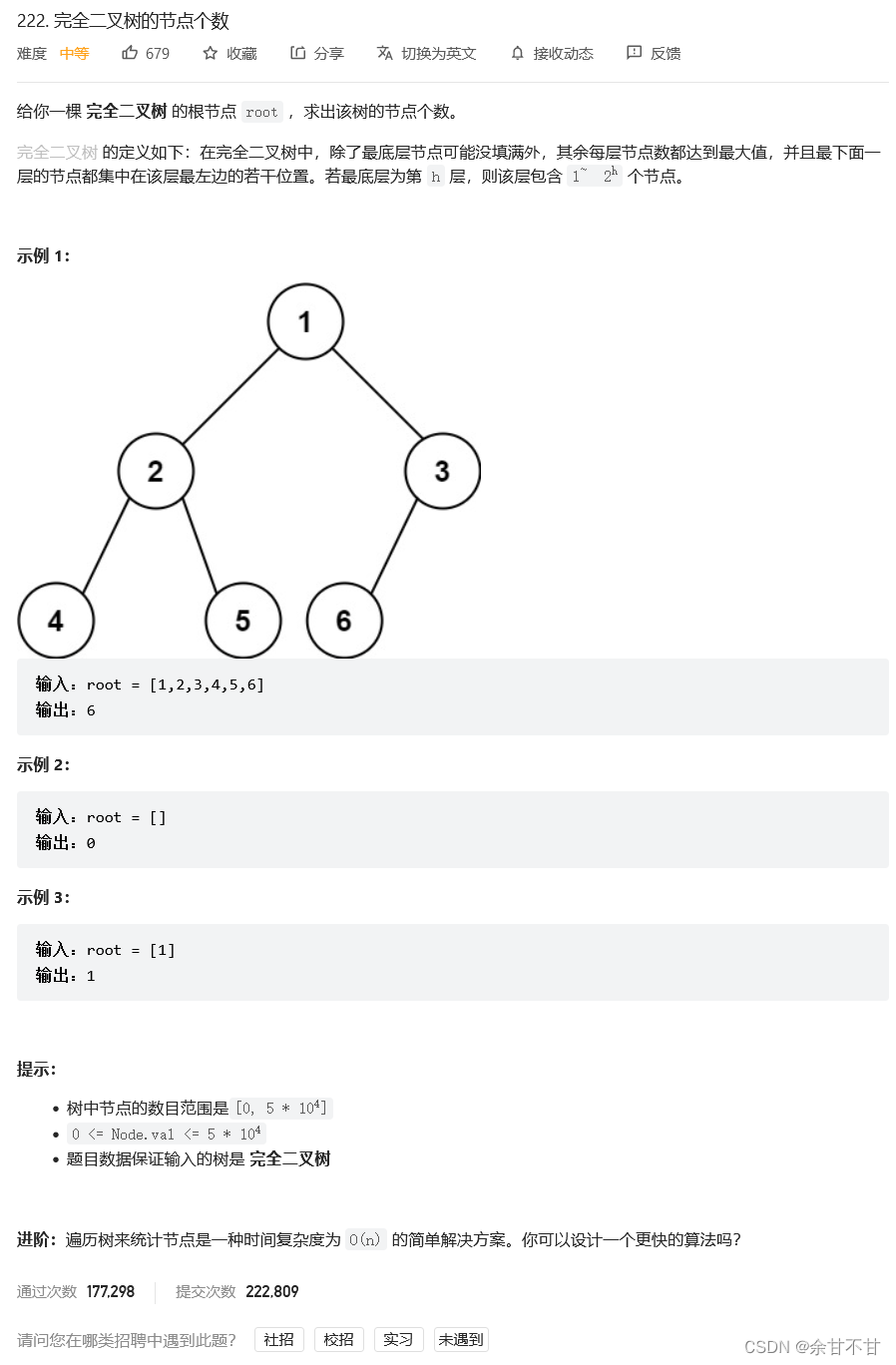
由于受到7.7求二叉树的最小深度的影响,自己的终止条件设置了四个,起初还因为四个沾沾自喜,虽然结果是对上了,但一看作者的题解,自己明显多虑了,其实只要一个终止条件就行了
- 代码
自己
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public int countNodes(TreeNode root) {
if(root==null) return 0;
if(root!=null&&root.left==null&&root.right==null) return 1;
if(root.left==null&&root.right!=null) return 1+countNodes(root.right);
if(root.right==null&&root.left!=null) return 1+countNodes(root.left);
return 1+countNodes(root.left)+countNodes(root.right);
}
}
作者
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public int countNodes(TreeNode root) {
if(root==null) return 0;
return 1+countNodes(root.left)+countNodes(root.right);
}
}
7.9平衡二叉树
-
思路
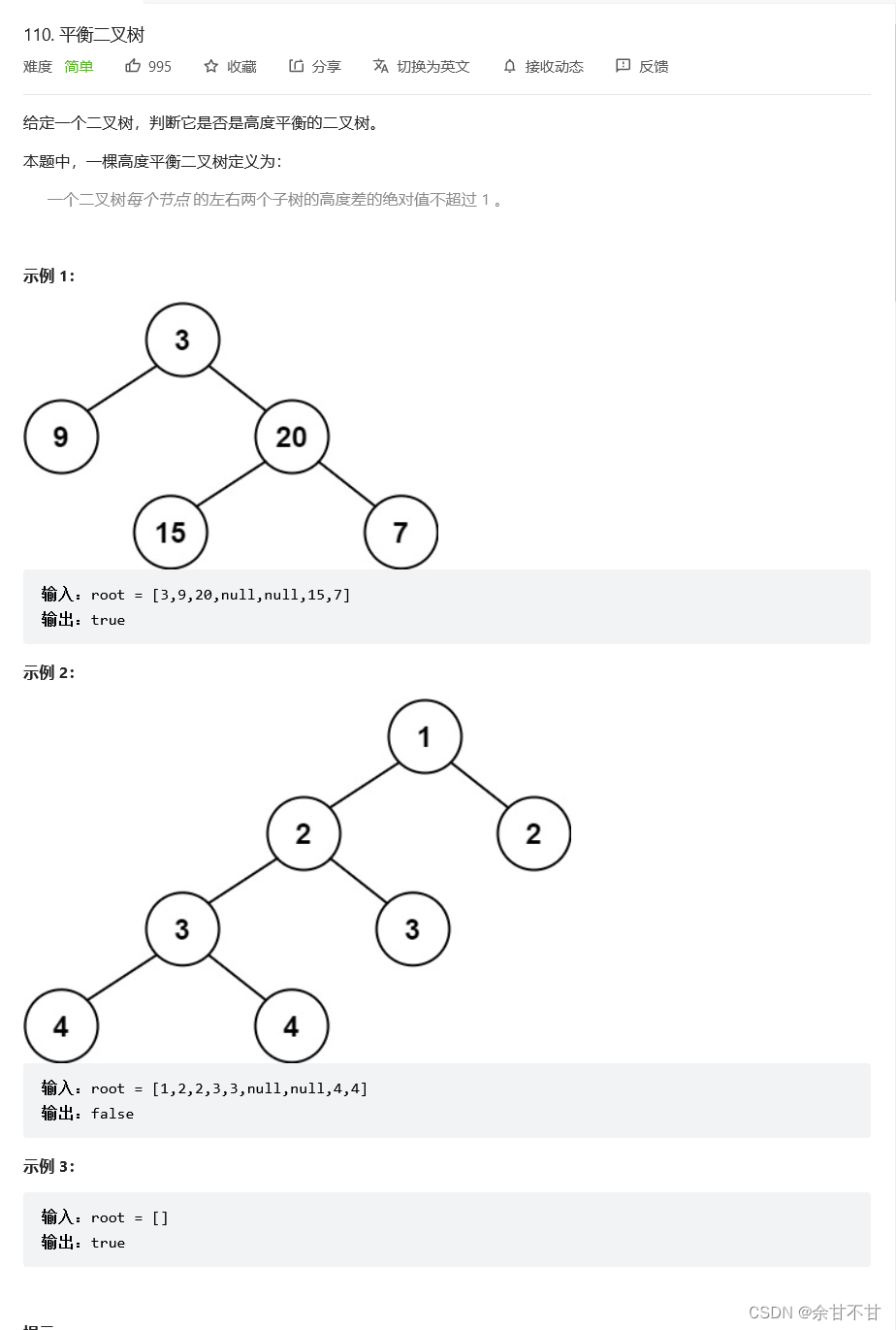
自己最初写的还有四个用例过不了,且用例太长,无法看出错误在哪,不过从作者的解法来看,加深了自己对递归的理解,二叉树的递归是一个从小往下的求解
- 代码·
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public boolean isBalanced(TreeNode root) {
return isBalanced_(root)==-1?false:true;
}
public int isBalanced_(TreeNode root){
if(root==null) return 0;
int leftDepth=isBalanced_(root.left);
if(leftDepth==-1) return -1; //一个从小往上推的过程
int rightDepth=isBalanced_(root.right);
if(rightDepth==-1) return -1;
if(Math.abs(rightDepth-leftDepth)>1){
return -1;
}
return 1+Math.max(leftDepth,rightDepth);
}
}
7.10二叉树的所有路径
-
思路
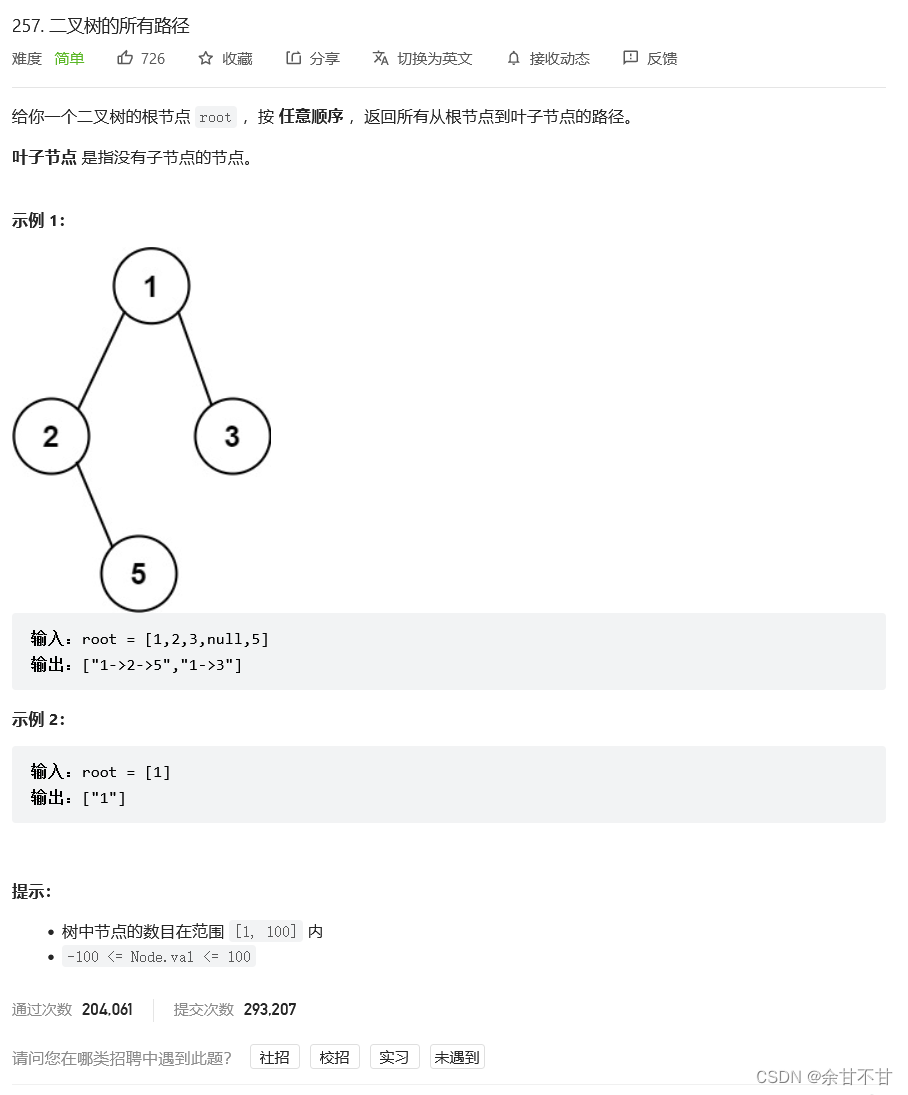
自己也想到了回溯和前序遍历联合解题,但是自己是直接在路径字符串加入"->"符号,这在回溯中可为难死自己了,左子树回溯时是退两个字符串,那算法左子树再算右子树回溯时改退几个字符串呢?哎,但作者用一个整数数组直接只用来记录,到叶子节点再加入”->"符号就完美解决了这个问题
class Solution {
/**
* 递归法
*/
public List<String> binaryTreePaths(TreeNode root) {
List<String> res = new ArrayList<>();
if (root == null) {
return res;
}
List<Integer> paths = new ArrayList<>();
traversal(root, paths, res);
return res;
}
private void traversal(TreeNode root, List<Integer> paths, List<String> res) {
paths.add(root.val);
// 叶子结点
if (root.left == null && root.right == null) {
// 输出
StringBuilder sb = new StringBuilder();
for (int i = 0; i < paths.size() - 1; i++) {
sb.append(paths.get(i)).append("->");
}
sb.append(paths.get(paths.size() - 1));
res.add(sb.toString());
return;
}
if (root.left != null) {
traversal(root.left, paths, res);
paths.remove(paths.size() - 1);// 回溯
}
if (root.right != null) {
traversal(root.right, paths, res);
paths.remove(paths.size() - 1);// 回溯
}
}
}
7.11左叶子之和
-
思路
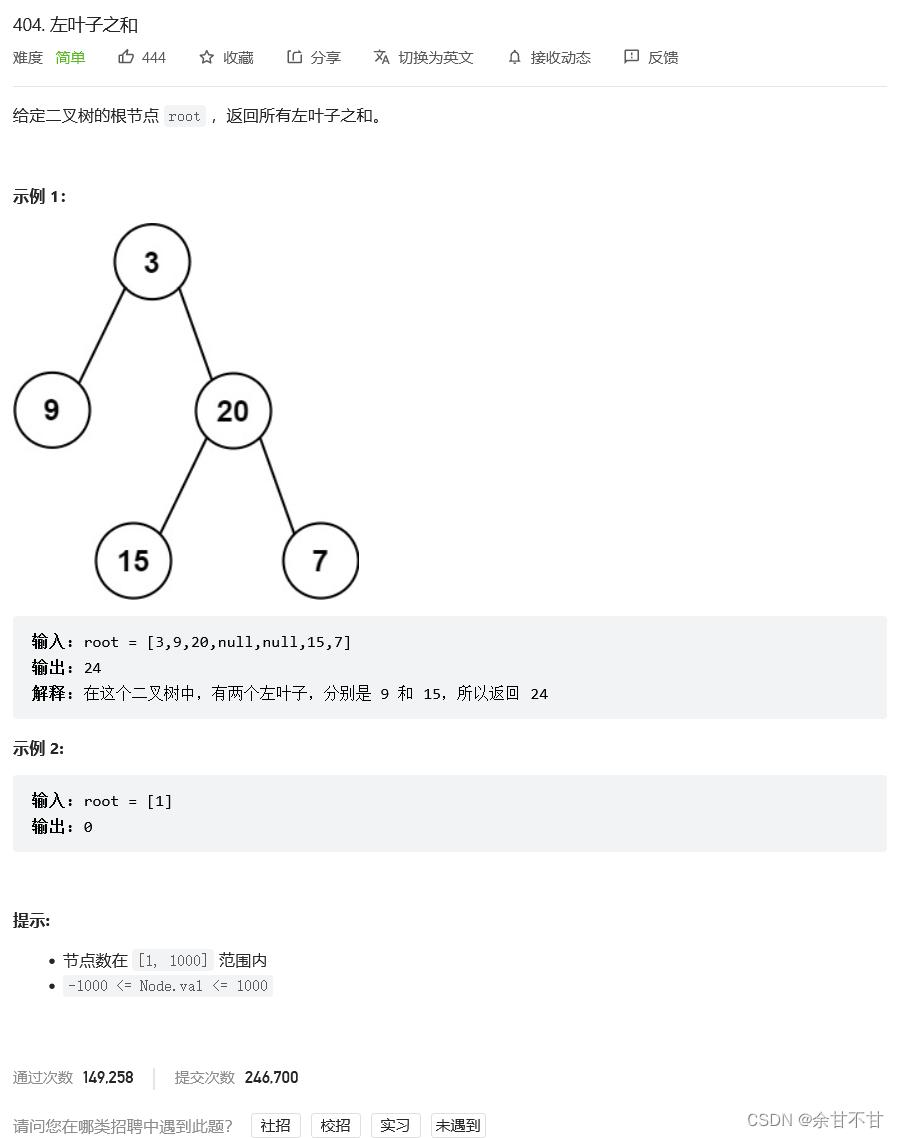
自己跟作者想的一模一样,但经过长时间的推导,还是觉得总结下来以便回顾

- 代码
作者用的是后序遍历,但自己更习惯于用前序遍历思考
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public int sumOfLeftLeaves(TreeNode root) {
List<Integer> list=new ArrayList<>();
preooder(root,list);
int sum=0;
for(int s:list) sum+=s;
return sum;
}
public void preooder(TreeNode root,List<Integer> list){
if(root==null) return;
if(root.left!=null&&root.left.left==null&&root.left.right==null){
list.add(root.left.val);
}
preooder(root.left,list);
preooder(root.right,list);
}
}
7.12路径总和
-
思路
我想的是用res每一条从根节点到叶子节点的路径都记录起来,思路是十分正确的,当我用
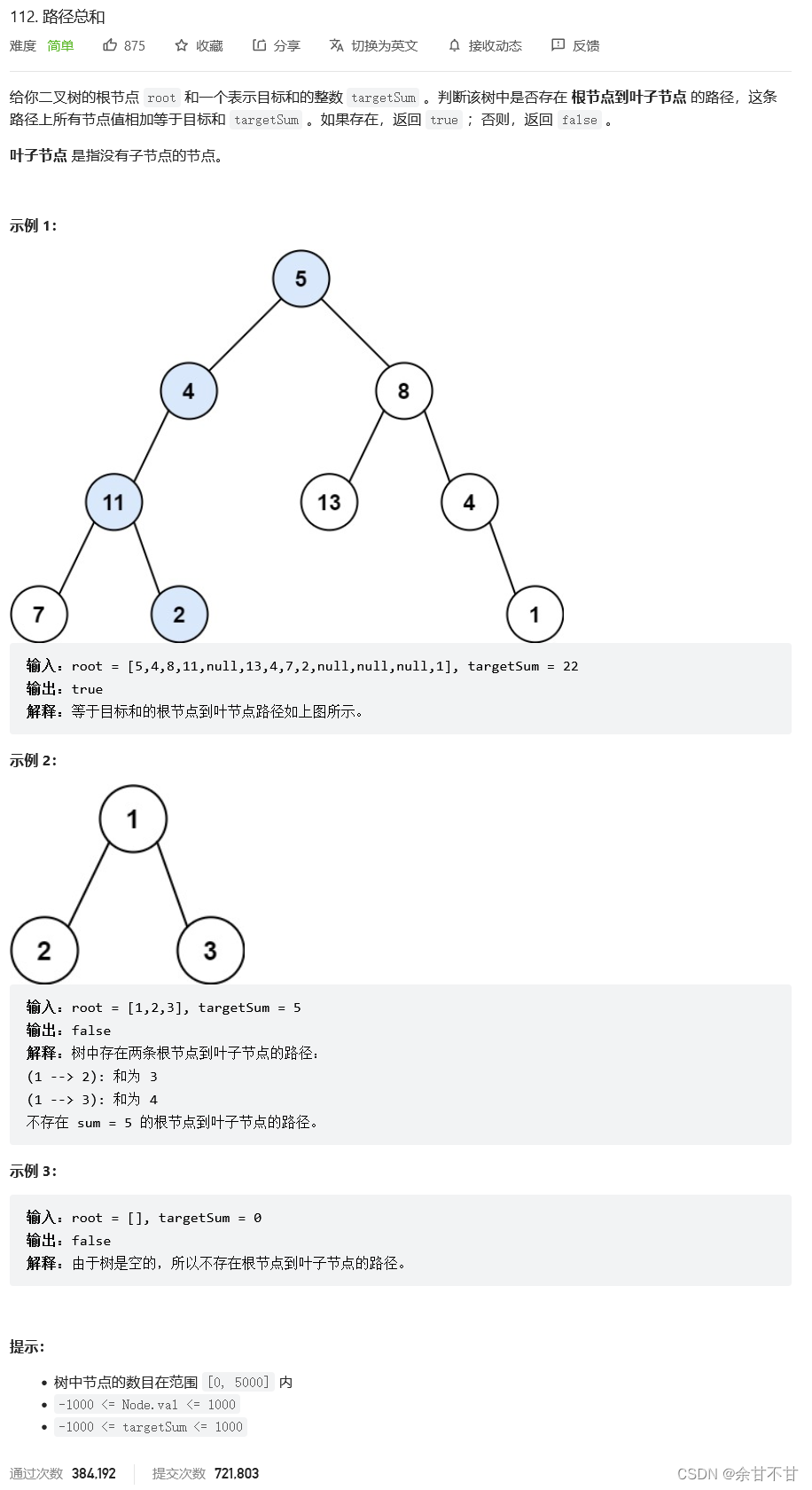
if(root!=null&&root.left==null&&root.right==null){
path.add(root.val);
System.out.println("pathres:"+path);
// res.add(new ArrayList<>(path));
res.add(path);
System.out.println("res:"+res);
return;
}
结果出现了戏剧性的一慕
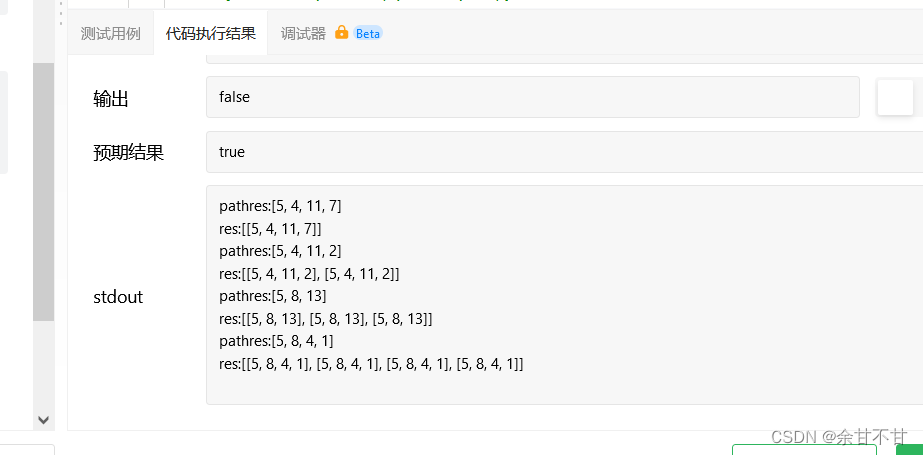
res的值出现了奇怪的重合,然后我就联想到了以前的回溯模板和引用传递,
修改成以下代码
res.add(new ArrayList<>(path));
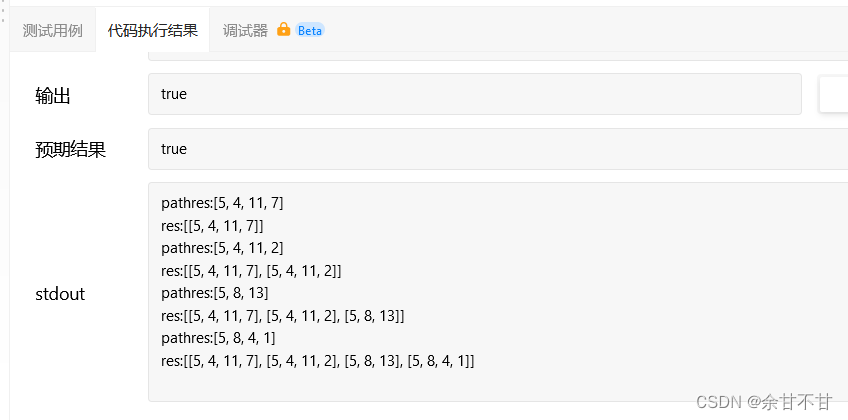
神奇的结果出现了,原来**new ArrayList<>(path)**的作用是防止java的引用传递覆盖掉原来的结果,以前一直以为是把deque转化为list
- 代码
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public boolean hasPathSum(TreeNode root, int targetSum) {
List<Integer> path=new ArrayList<>();
List<List<Integer>> res=new ArrayList<>();
collectPath(root,path,res);
//System.out.println("res:"+res);
for(List<Integer> s:res){
int sum=0;
for(int i=0;i<s.size();i++){
sum+=s.get(i);
}
if(sum==targetSum){
return true;
}
}
return false;
}
public void collectPath(TreeNode root, List<Integer> path, List<List<Integer>> res){
if(root!=null&&root.left==null&&root.right==null){
path.add(root.val);
System.out.println("pathres:"+path);
res.add(new ArrayList<>(path));
System.out.println("res:"+res);
return;
}
if(root==null) return;
path.add(root.val);
// System.out.println("path:"+path);
collectPath(root.left,path,res);
if(root.left!=null) path.remove(path.size()-1);
// System.out.println("removepath1:"+path);
collectPath(root.right,path,res);
if(root.right!=null) path.remove(path.size()-1);
//System.out.println("removepath2:"+path);
}
}
7.13最大二叉树
-
思路
不知不觉又碰到这种破递归的题目了,自己做的时候还是很害怕的,自己最直观的感受是,每次找到数组的最大值maxValue和最大值的下标 maxValueIndex,然后再根据maxValueIndex分割成左边的数组和右边的数组,思路和作者的简直一摸一样,但自己很明显就卡到了终止条件,终止条件该怎么写呢?通过自己的模拟,终于摸索出了递归的终止条件的寻找方式。
首先我们肯定的是每次找到数组的最大值maxValue和最大值的下标 maxValueIndex,然后再根据maxValueIndex分割成左边的数组和右边的数组,既然是这样的递归的,然后递归又可以用二叉树来形象的解释,我们先画出一颗二叉树来模拟下分割的过程,我们以nums = [3,2,1,6,0,5]为例
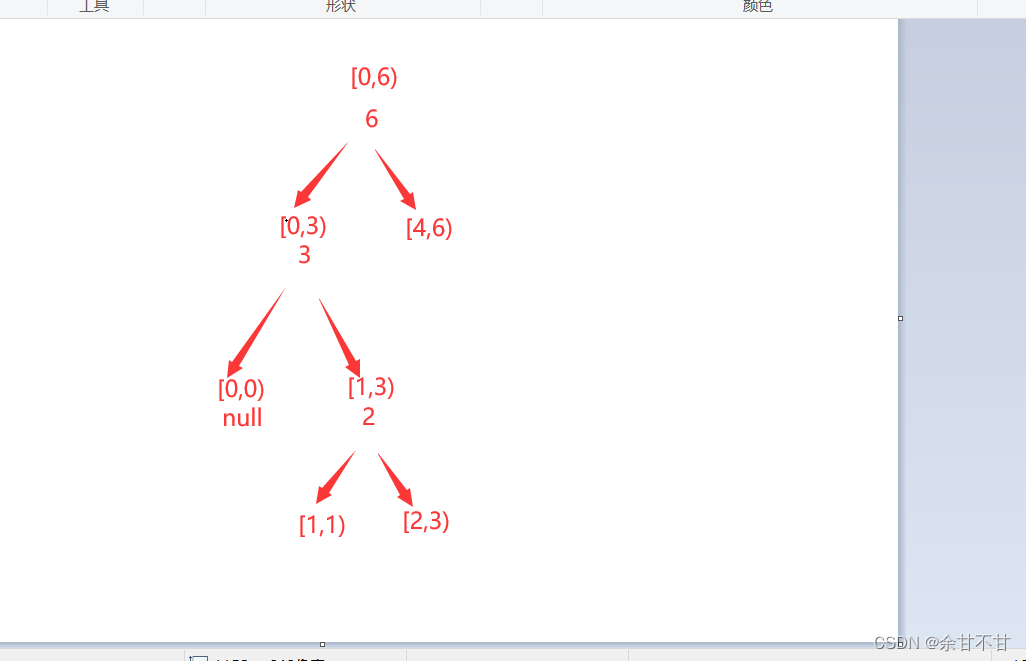
这时候我们会很容易发现,递归到最后,rightIndex-leftIndex无非就两种情况,而这两者情况的返回结果我们也很容易得出
if(rightIndex-leftIndex==0) return null;
if(rightIndex-leftIndex==1) return new TreeNode(nums[leftIndex]);
到这里我们终于解决了困扰了自己很久的如何自己寻找递归终止条件
- 代码
class Solution {
public TreeNode constructMaximumBinaryTree(int[] nums) {
return constructMaximumBinaryTree1(nums, 0, nums.length);
}
public TreeNode constructMaximumBinaryTree1(int[] nums, int leftIndex, int rightIndex) {
if (rightIndex - leftIndex < 1) {// 没有元素了
return null;
}
if (rightIndex - leftIndex == 1) {// 只有一个元素
return new TreeNode(nums[leftIndex]);
}
int maxIndex = leftIndex;// 最大值所在位置
int maxVal = nums[maxIndex];// 最大值
for (int i = leftIndex + 1; i < rightIndex; i++) {
if (nums[i] > maxVal){
maxVal = nums[i];
maxIndex = i;
}
}
TreeNode root = new TreeNode(maxVal);
// 根据maxIndex划分左右子树
root.left = constructMaximumBinaryTree1(nums, leftIndex, maxIndex);
root.right = constructMaximumBinaryTree1(nums, maxIndex + 1, rightIndex);
return root;
}
}
7.14合并二叉树
-
思路

自己最初想的是把所有空节点替换为值为0的节点,后面构造了一个多小时,发现自己实现不了,哈哈哈,无奈看题解,作者对一端为空另一端不为空的执行语句太精妙了,自己最初的判断条件和思路
if(root1==null&&root2==null) return null;
TreeNode root=new TreeNode();
if(root1==null&&root2!=null){
root.val=0+root2.val;
}
if(root1!=null&&root2==null){
root.val=root1.val+0;
}
if(root1!=null&&root2!=null){
root.val=root1.val+root2.val;
}
root.left=mergeTrees(root1.left,root2.left);
System.out.println("root.left_val:"+root.left);
root.right=mergeTrees(root1.right,root2.right);
return root;
这个还会在root1!=null,root1.left!=null,root1.left.leftnull和root2!=null,root2.leftnull,root1.left.left==null的条件下报错
- 代码
class Solution {
public TreeNode mergeTrees(TreeNode root1, TreeNode root2) {
if(root1==null) return root2;
if(root2==null) return root1;
TreeNode newRoot=new TreeNode(root1.val+root2.val);
newRoot.left=mergeTrees(root1.left,root2.left);
newRoot.right=mergeTrees(root1.right,root2.right);
return newRoot;
}
}
7.15验证二叉搜索树
-
思路
- 思路一
要知道中序遍历下,输出的二叉搜索树节点的数值是有序序列。
有了这个特性,验证二叉搜索树,就相当于变成了判断一个序列是不是递增的了。- 思路二
递归实现是否递增
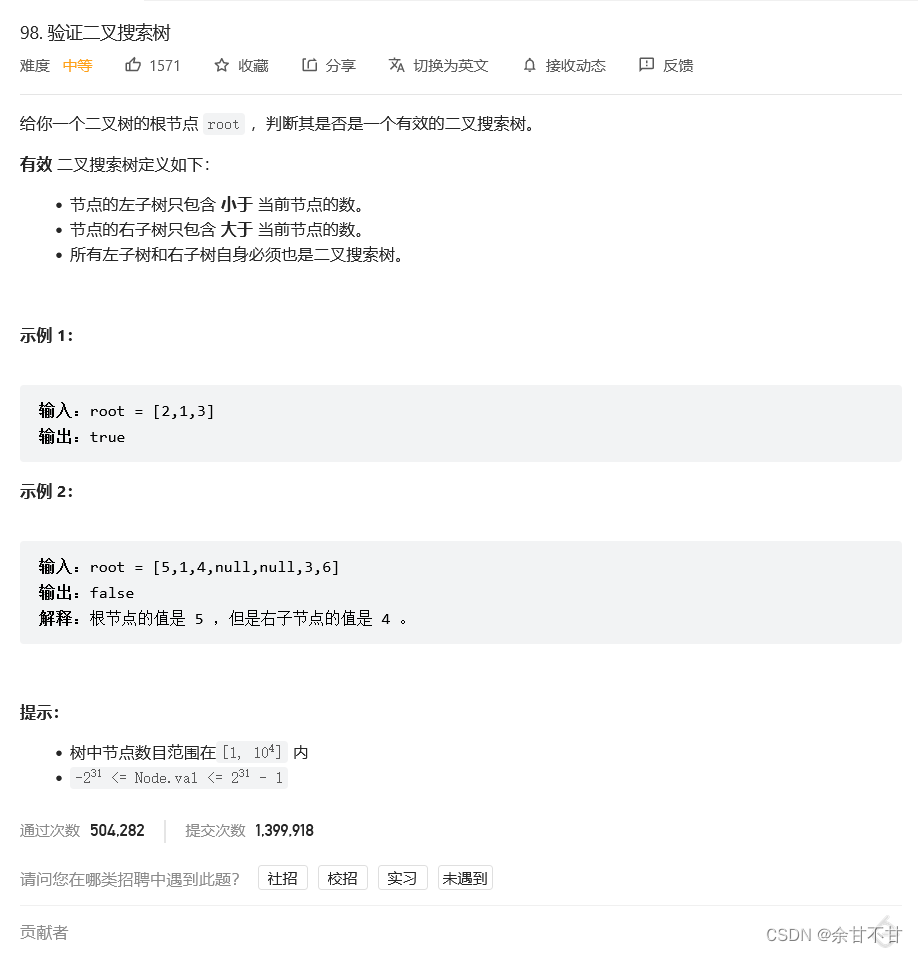
class Solution {
public:
long long maxVal = LONG_MIN; // 因为后台测试数据中有int最小值
bool isValidBST(TreeNode* root) {
if (root == NULL) return true;
bool left = isValidBST(root->left);
// 中序遍历,验证遍历的元素是不是从小到大
if (maxVal < root->val) maxVal = root->val;
else return false;
bool right = isValidBST(root->right);
return left && right;
}
};
其实本质还是求个递增数组
- 代码
class Solution {
public boolean isValidBST(TreeNode root) {
List<Integer> list=new ArrayList<>();
inorder(root,list);
// System.out.println("list:"+list);
for(int i=0;i<list.size()-1;i++){
if(list.get(i)>=list.get(i+1)) return false;
}
return true;
}
public void inorder(TreeNode root,List<Integer> list){
if(root==null) return;
inorder(root.left,list);
list.add(root.val);
inorder(root.right,list);
}
}
7.16二叉树的最近公共祖先
-
思路
很明显这是一个自底向上找的过程,也就是一个回溯的过程,而二叉树的后序遍历就是一个很完美的回溯过程
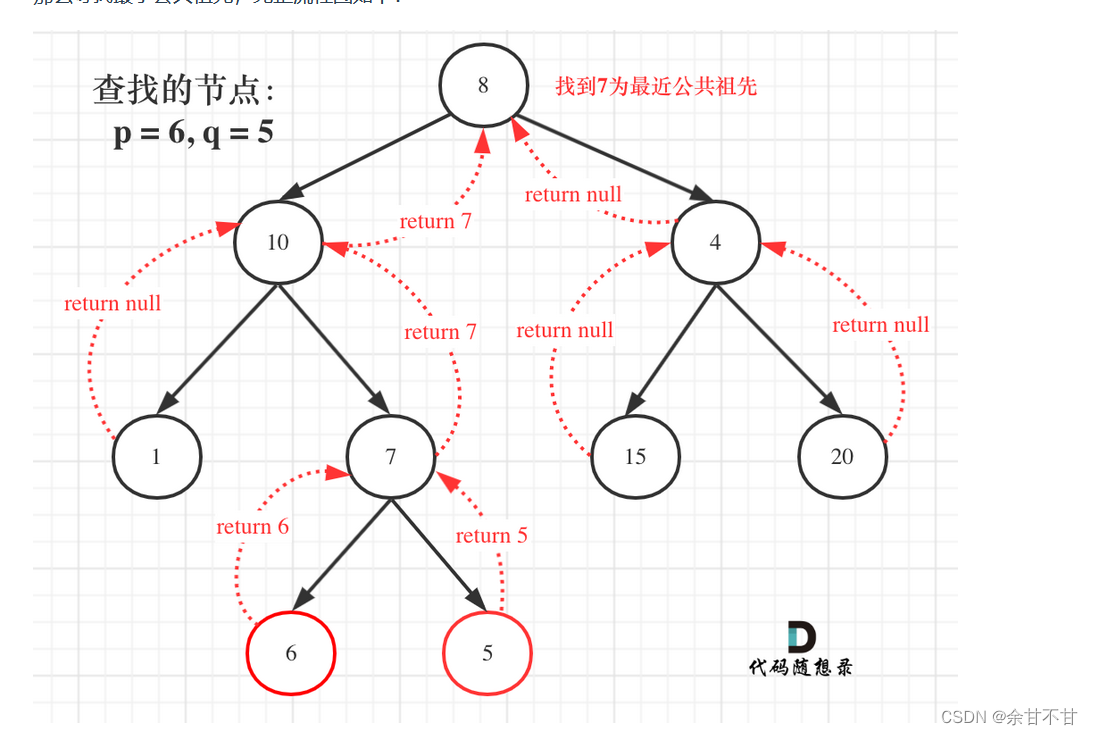
-
代码

class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if(root==p||root==q||root==null) return root;
TreeNode left=lowestCommonAncestor(root.left,p,q);
TreeNode right=lowestCommonAncestor(root.right,p,q);
if(right!=null&&left!=null) return root;
else if(right!=null&&left==null) return right;
else if(right==null&&left!=null) return left;
else return null;
}
}
7.17二叉搜索树的插入操作
-
思路
自己解决:
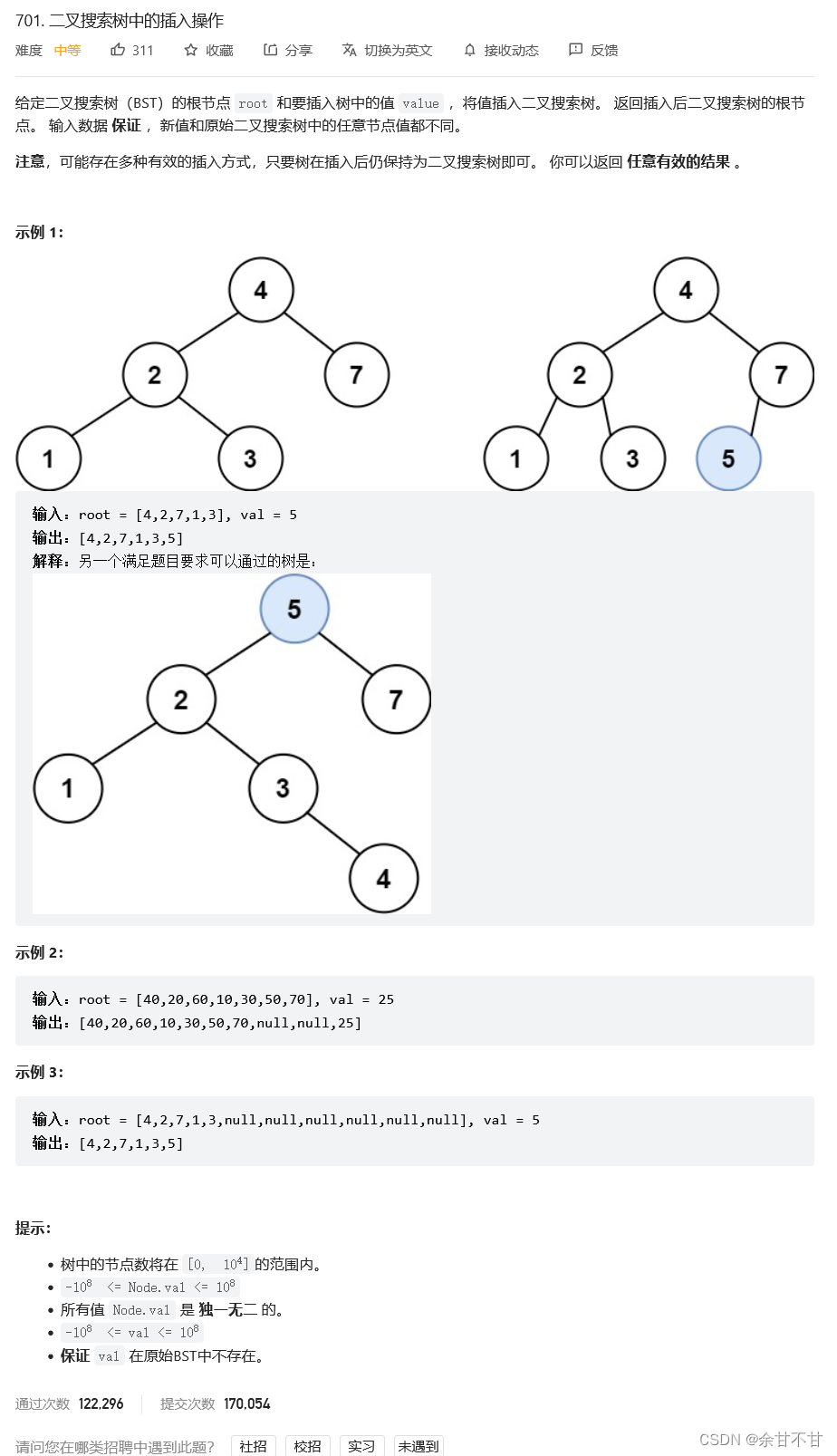
if(val<root.val){
insertIntoBST(root.left,val);
}
if(val>root.val){
insertIntoBST(root.right,val);
}
至于终止条件即返回结果,通过7.16最近公共祖先的了解,加强了对递归返回结果的理解
- 代码
class Solution {
public TreeNode insertIntoBST(TreeNode root, int val) {
if(root==null){ //空树特判
TreeNode createRoot=new TreeNode(val);
return createRoot;
}
if(root.left==null&&val<root.val){
root.left=new TreeNode(val);
return root;
}
if(root.right==null&&val>root.val){
root.right=new TreeNode(val);
return root;
}
if(val<root.val){
insertIntoBST(root.left,val);
}
if(val>root.val){
insertIntoBST(root.right,val);
}
return root;
}
}
7.18二叉树的删除操作
- 题目
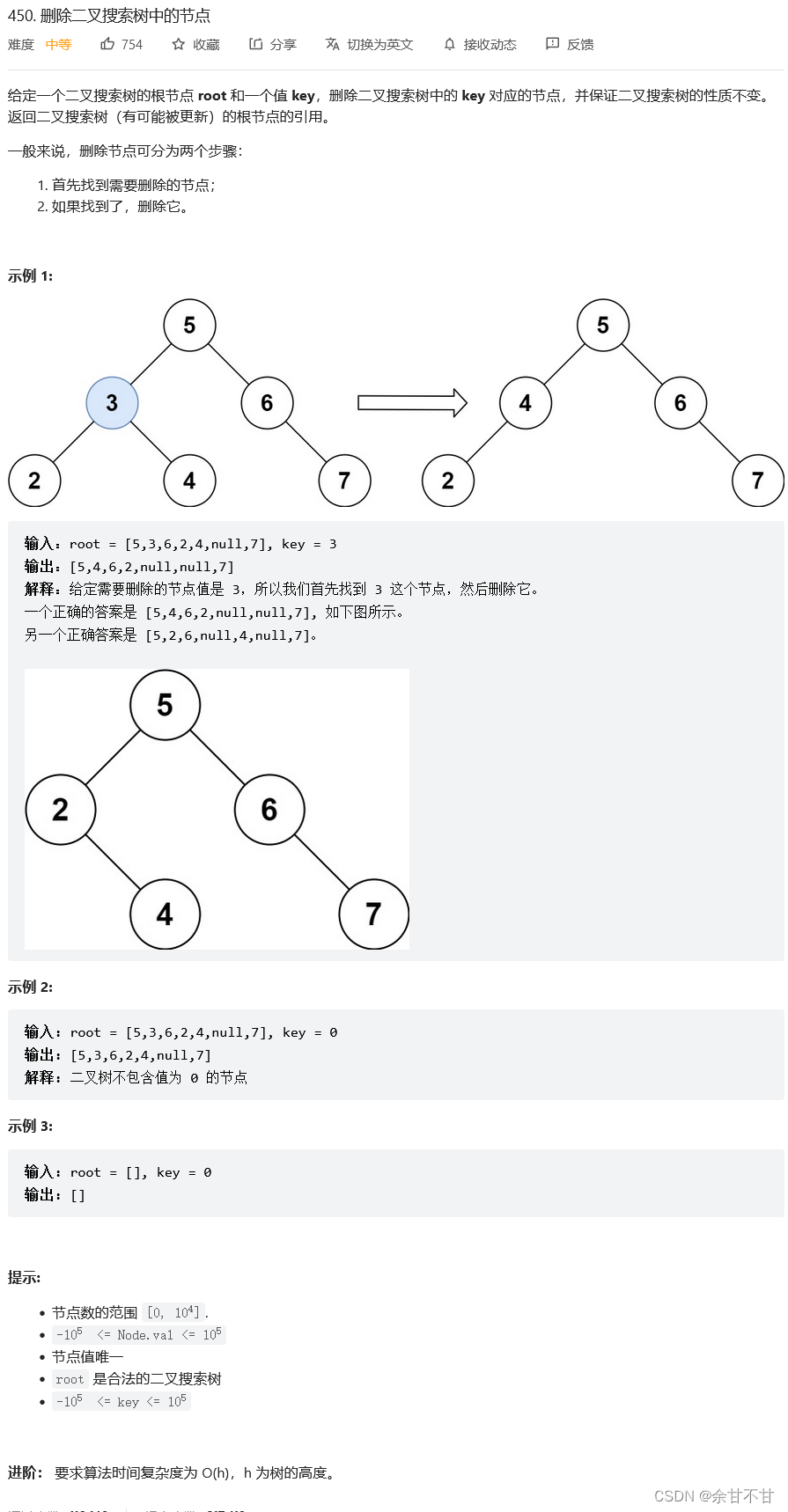
- 思路
刚开始自己想的太复杂了,但是到最后也只过了72个用例,其实这种回溯的题,自己老是容易被题目的画图过程带偏从而想的太复杂,其实我们回到一个最基本的可能插入单位,无非就下面五种情况
第一种找不到给定值情况,返回null,这是其余四种
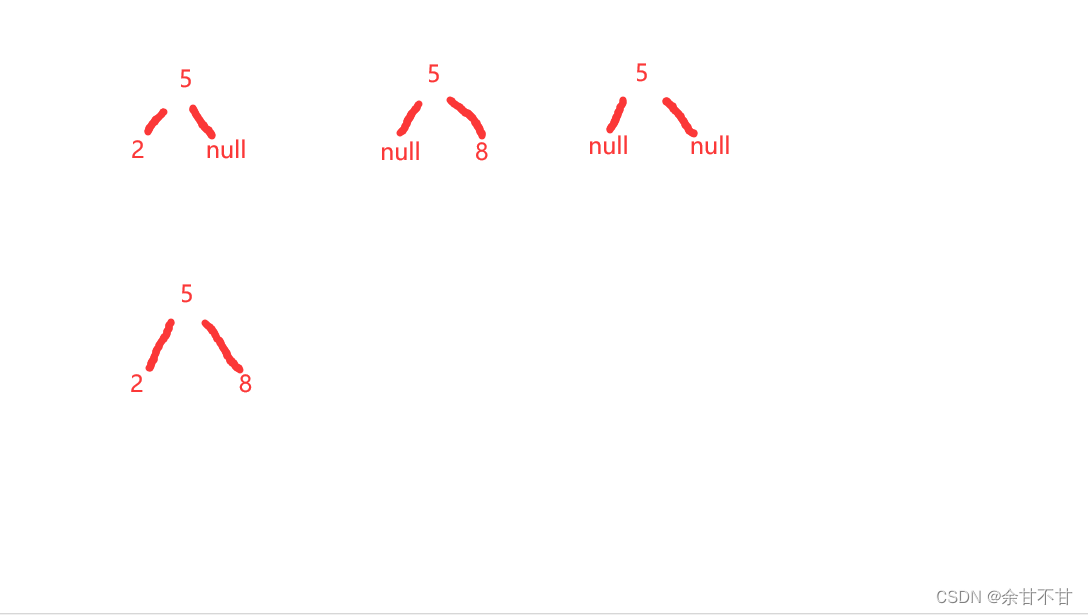
最难的就是第五种的操作,作者给出了一个很巧妙的思路

- 代码
class Solution {
public TreeNode deleteNode(TreeNode root, int key) {
if(root==null) return null; // 第一种情况:没找到删除的节点,遍历到空节点直接返回了
if(root.val==key){
if(root.left==null&&root.right==null) return null;//第二种情况:左右孩子都为空(叶子节点),直接删除节点, 返回NULL为根节点
if(root.left!=null&&root.right==null) return root.left;//第四种情况
if(root.left==null&&root.right!=null) return root.right;//第三种情况:其左孩子为空,右孩子不为空,删除节点,右孩子补位 ,返回右孩子为根节点
if(root.left!=null&&root.right!=null){ //第五种情况
TreeNode tem1=root.right;
while(tem1.left!=null){
tem1=tem1.left;
}
TreeNode tem2=root.left;
tem1.left=tem2;
return root.right;
}
}
if(key<root.val){
root.left=deleteNode(root.left,key);
}
if(key>root.val){
root.right=deleteNode(root.right,key);
}
return root;
}
}
7.19修剪二叉搜索树
-
思路
思路一(自己):我寻思这不是多次的删除操作吗;所以我用暴力删除删除达到了修建,没想到竟然也成功了,哈哈哈
class Solution {
public TreeNode trimBST(TreeNode root, int low, int high) {
TreeNode root_=trimBST_(root,low,high);
int i=1;
while(i<1000){
root_=trimBST_(root_,low,high);
i++;
}
return root_;
}
public TreeNode trimBST_(TreeNode root, int low, int high) {
if(root==null) return null;
if(root.val<low||root.val>high){
if(root.left==null&&root.right==null) return null;
if(root.left==null&&root.right!=null) return root.right;
if(root.left!=null&&root.right==null) return root.left;
if(root.left!=null&&root.right!=null){
TreeNode tem1=root.right;
while(tem1.left!=null){
tem1=tem1.left;
}
TreeNode tem2=root.left;
tem1.left=tem2;
return root.right;
}
}
root.left=trimBST_(root.left,low,high);
root.right=trimBST_(root.right,low,high);
return root;
}
}
思路二:
class Solution {
public TreeNode trimBST(TreeNode root, int low, int high) {
if(root==null) return null;
if(root.val<low) return trimBST(root.right,low,high); //如果root.val<low,那么root.lefr.val肯定也小于low,直接就可以全部删除掉了
if(root.val>high) return trimBST(root.left,low,high);//与上面的情况同理
root.left=trimBST(root.left,low,high);
root.right=trimBST(root.right,low,high);
return root;
}
}
- 代码
class Solution {
public TreeNode trimBST(TreeNode root, int low, int high) {
if(root==null) return null;
if(root.val<low) return trimBST(root.right,low,high);
if(root.val>high) return trimBST(root.left,low,high);
root.left=trimBST(root.left,low,high);
root.right=trimBST(root.right,low,high);
return root;
}
}
7.20将有序数组转化为二叉搜索树
-
思路
-
代码

class Solution {
public TreeNode sortedArrayToBST(int[] nums) {
return sortedArrayToBST_(nums,0,nums.length-1);
}
public TreeNode sortedArrayToBST_(int[] nums,int left,int right){
if(left>right) return null;
int mid=left+((right-left)/2);
TreeNode root=new TreeNode(nums[mid]);
root.left=sortedArrayToBST_(nums,left,mid-1);
root.right=sortedArrayToBST_(nums,mid+1,right);
return root;
}
}
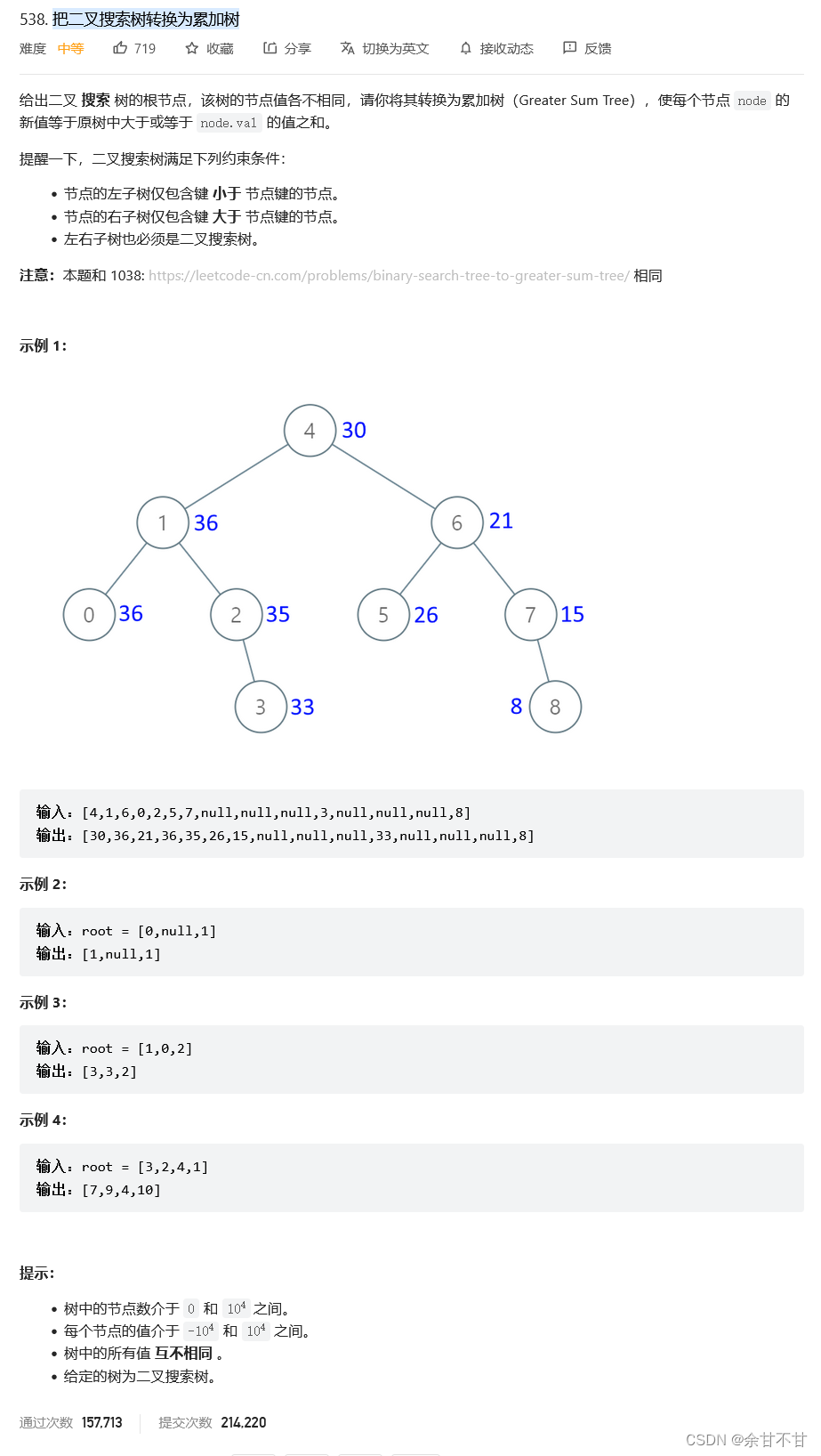
7.21把二叉搜索树转换为累加树
-
思路
自:既然这是一颗二叉搜索树,那么使用中序遍历该树得到的就是一个有序数组呀,然后我们只要再遍历这个有序数组,判断谁>=该节点的值再累加就行了 -
代码
class Solution {
public TreeNode convertBST(TreeNode root) {
List<Integer> list=new ArrayList<>();
collectVal(root,list);
// System.out.println("list:"+list);
fun(root,list);
return root;
}
public void collectVal(TreeNode root,List<Integer> list){
if(root==null) return ;
collectVal(root.left,list);
list.add(root.val);
collectVal(root.right,list);
}
public void fun(TreeNode root,List<Integer> list){
if(root==null) return ;
int val=root.val;
int sum=0;
for(int i=0;i<list.size();i++){
if(list.get(i)>=val){
sum+=list.get(i);
}
}
root.val=sum;
fun(root.left,list);
fun(root.right,list);
}
}
7.贪心
7.1理论基础
贪心的本质是选择每一阶段的局部最优,从而达到全局最优。
贪心算法一般分为如下四步:
- 将问题分解为若干个子问题
- 找出适合的贪心策略
- 求解每一个子问题的最优解
- 将局部最优解堆叠成全局最优解
不好意思了,贪心没有套路,说白了就是常识性推导加上举反例。一般题目中要求什么最xxx可以考虑到贪心
7.2分发饼干
-
题目

主要学习用一个index来控制小孩胃口数组的遍历,遍历小孩胃口并没有再起一个for循环,而是采用自增的方式,这也是常用的技巧。
class Solution {
public int findContentChildren(int[] s1, int[] s2) {
List<Integer> arr=new ArrayList<>();
Arrays.sort(s1);
Arrays.sort(s2);
for(int i=0;i<s1.length;i++){
arr.add(s1[i]);
}
int count=0;
for(int i=0;i<s2.length;i++){
for(int j=0;j<arr.size();j++){
if(s2[i]>=arr.get(j)){
count++;
arr.remove(j);
break;
}
}
}
return count;
}
}
- 优化后的代码
class Solution {
// 思路1:优先考虑饼干,小饼干先喂饱小胃口
public int findContentChildren(int[] g, int[] s) {
Arrays.sort(g);
Arrays.sort(s);
int start = 0;
int count = 0;
for (int i = 0; i < s.length && start < g.length; i++) {
if (s[i] >= g[start]) {
start++;
count++;
}
}
return count;
}
}
- 时间效率对比

7.3摆动序列
-
题目

-
解题思路

-
代码
class Solution {
public int wiggleMaxLength(int[] nums) {
if (nums.length <= 1) {
return nums.length;
}
//当前差值
int curDiff = 0;
//上一个差值
int preDiff = 0;
int count = 1;
for (int i = 1; i < nums.length; i++) {
//得到当前差值
curDiff = nums[i] - nums[i - 1];
//如果当前差值和上一个差值为一正一负
//等于0的情况表示初始时的preDiff
if ((curDiff > 0 && preDiff <= 0) || (curDiff < 0 && preDiff >= 0)) {
count++;
preDiff = curDiff;
}
}
return count;
}
}
7.4最大子数组和
-
题目
题目地址

-
思路

-
代码
class Solution {
public int maxSubArray(int[] nums) {
if (nums.length == 1){
return nums[0];
}
int sum = Integer.MIN_VALUE;
int count = 0;
for (int i = 0; i < nums.length; i++){
count += nums[i];
sum = Math.max(sum, count); // 取区间累计的最大值(相当于不断确定最大子序终止位置)
if (count <= 0){
count = 0; // 相当于重置最大子序起始位置,因为遇到负数一定是拉低总和
}
}
return sum;
}
}
7.5买卖股票的最佳时机2
-
思路

-
代码

// 贪心思路
class Solution {
public int maxProfit(int[] prices) {
int result = 0;
for (int i = 1; i < prices.length; i++) {
result += Math.max(prices[i] - prices[i - 1], 0);
}
return result;
}
}
7.6跳跃游戏
-题目

- 思路
最开始自己想的是回溯,看了下测试数据范围,感觉会超时,一写果然超时了,但自己能联想到回溯并解决了70个用例,是个很大的进步,还是记录一下
class Solution {
Deque<Integer> path=new ArrayDeque<>();
List<List<Integer>> result=new ArrayList<>();
public boolean canJump(int[] nums) {
int step=nums.length-1;
backTracking(nums,0,step,0);
if(!result.isEmpty()){
return true;
}
return false;
}
public void backTracking(int[]nums,int index,int step,int totalStep){
if(index>step){
return ;
}
if(totalStep==step){
result.add(new ArrayList<>(path));
// System.out.println(result);
}
for(int i=1;i<=nums[index];i++){
if(totalStep+i>step){
continue;
}
path.add(i);
backTracking(nums,index+i,step,totalStep+i);
path.removeLast();
}
}
}

- 代码
class Solution {
public boolean canJump(int[] nums) {
if (nums.length == 1) {
return true;
}
//覆盖范围, 初始覆盖范围应该是0,因为下面的迭代是从下标0开始的
int coverRange = 0;
//在覆盖范围内更新最大的覆盖范围
for (int i = 0; i <= coverRange; i++) {
coverRange = Math.max(coverRange, i + nums[i]);
if (coverRange >= nums.length - 1) {
return true;
}
}
return false;
}
}
7.7加油站
-
思路
本题的关键是,题目已给出**如果存在解,则 保证 它是 唯一 的。**那么

-
代码

// 解法2
class Solution {
public int canCompleteCircuit(int[] gas, int[] cost) {
int curSum = 0;
int totalSum = 0;
int index = 0;
for (int i = 0; i < gas.length; i++) {
curSum += gas[i] - cost[i];
totalSum += gas[i] - cost[i];
if (curSum < 0) {
index = (i + 1) % gas.length ;
curSum = 0;
}
}
if (totalSum < 0) return -1;
return index;
}
}
7.8分发糖果

-
思路

-
代码
class Solution {
/**
分两个阶段
1、起点下标1 从左往右,只要 右边 比 左边 大,右边的糖果=左边 + 1
2、起点下标 ratings.length - 2 从右往左, 只要左边 比 右边 大,此时 左边的糖果应该 取本身的糖果数(符合比它左边大) 和 右边糖果数 + 1 二者的最大值,这样才符合 它比它左边的大,也比它右边大
*/
public int candy(int[] ratings) {
int[] candyVec = new int[ratings.length];
candyVec[0] = 1;
for (int i = 1; i < ratings.length; i++) {
if (ratings[i] > ratings[i - 1]) {
candyVec[i] = candyVec[i - 1] + 1;
} else {
candyVec[i] = 1;
}
}
for (int i = ratings.length - 2; i >= 0; i--) {
if (ratings[i] > ratings[i + 1]) {
candyVec[i] = Math.max(candyVec[i], candyVec[i + 1] + 1);
}
}
int ans = 0;
for (int s : candyVec) {
ans += s;
}
return ans;
}
}
7.9根据身高重建队列

-
思路

-
代码
class Solution {
public int[][] reconstructQueue(int[][] people) {
// 身高从大到小排(身高相同k小的站前面)
Arrays.sort(people, (a, b) -> {
if (a[0] == b[0]) return a[1] - b[1];
return b[0] - a[0];
});
LinkedList<int[]> que = new LinkedList<>();
for (int[] p : people) {
que.add(p[1],p); //网上队列似乎没有插入方法,但在idea中已经存在,可能是新特性
}
// for(int[] p2:que){
// System.out.println("["+p2[0]+","+p2[1]+"]");
// }
return que.toArray(new int[people.length][]);
}
}
7.10用最少数量的箭引爆气球
-
思路

-代码
主要学习更新最小右边界的模拟过程

class Solution {
public int findMinArrowShots(int[][] points) {
if (points.length == 0) return 0;
Arrays.sort(points, (o1, o2) -> Integer.compare(o1[0], o2[0]));//有一个用例为{{-2147483646,-2147483645},{2147483646,2147483647}};不用这个方法这个用例无法实现排序
int count = 1;
for (int i = 1; i < points.length; i++) {
if (points[i][0] > points[i - 1][1]) {//如果讨论区间的包含,情况就太多了,所以这里采用了巧妙的反向论证
count++;
} else {
points[i][1] = Math.min(points[i][1],points[i - 1][1]);//最小右边界的更新
}
}
return count;
}
}
7.11划分字母区间
-
思路

-
代码

class Solution {
public List<Integer> partitionLabels(String s) {
List<Integer> result=new ArrayList<>();
int left=0;
int ritht=0;
int[] hash=new int[27];
for(int i=0;i<s.length();i++){
hash[s.charAt(i)-'a']=i;
}
for(int i=0;i<s.length();i++){
ritht=Math.max(ritht,hash[s.charAt(i)-'a']);
if(i==ritht){
result.add(ritht-left+1);
left=ritht+1;
}
}
return result;
}
}
7.12单调递增的数字
-
思路
首先自己最先想到的是暴力,把数字变成字符串然后遍历比较,毫无疑问超时了


作者的思路似乎是正确的,但是只按照这个思路解题,会在下面的用例上出现错误

所以我们还应该记录下最先出现的9的位置,然后后面的数字全改为9(因为我9后面只能为9了)这样就能实现递增了。
- 代码·
class Solution {
public int monotoneIncreasingDigits(int n) {
String s1=n+"";
char[] s=s1.toCharArray();
int flag=Integer.MAX_VALUE;//记录最后一个9出现的位置
for(int i=s.length-1;i>=1;i--){
if(s[i-1]>s[i]){
int tem=s[i-1]-'1';
s[i-1]=(char)(tem+48);//数字和它的ASSIC码之间相差48
s[i]='9';
flag=i;
}
else if(s[i-1]=='0'){
s[i]='9'; //对101这样的数字进行判断
}
}
StringBuilder result=new StringBuilder();
for(int i=flag;i<s.length;i++){
s[i]='9';
}
for(int i=0;i<s.length;i++){
result.append(s[i]);
}
return Integer.parseInt(result.toString());
}
}
7.13买卖股票的最佳时机含手续费
-
思路

-
代码

class Solution {
public int maxProfit(int[] prices, int fee) {
int result = 0;
int minPrice = prices[0]; // 记录最低价格
for (int i = 1; i < prices.length; i++) {
// 情况二:相当于买入
if (prices[i] < minPrice) minPrice = prices[i];
// 情况三:保持原有状态(因为此时买则不便宜,卖则亏本)
if (prices[i] >= minPrice && prices[i] <= minPrice + fee) {
continue;
}
// 计算利润,可能有多次计算利润,最后一次计算利润才是真正意义的卖出
if (prices[i] > minPrice + fee) {
result += prices[i] - minPrice - fee;
minPrice = prices[i] - fee; // 情况一,这一步很关键
}
}
return result;
}
}
- 关于情况一minPrice=prices[i]-fee的理解

8动态规划
9.二分查找
-
思路
思路一:由于自己是先做二叉树再来思考这个问题,自己刚刚模拟时,发现它的搜索过程很像二叉搜索树,按照二叉树的解答形式,我首先想到的是回溯+二分,但是使用回溯时,返回结果倒是给了我一个很大的麻烦,所以只好在参数中加入了一个list,我们以案例一为例子,模拟过程如下
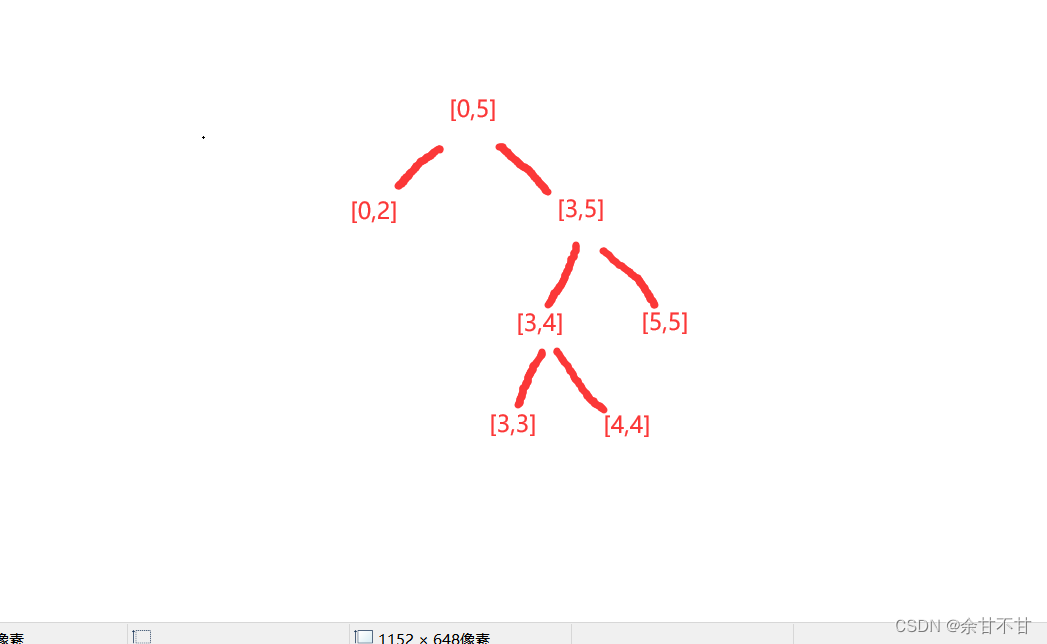
但当我们看二分查找的模板时,发现它的判断过程跟我们还是有很大差别的

- 代码
思路一:
class Solution {
public int search(int[] nums, int target) {
List<Integer> list=new ArrayList<>();
search_(nums,target,0,nums.length-1,list);
if(list.isEmpty()) return -1;
return list.get(0);
}
public static void search_(int[] nums,int target,int left,int right,List<Integer> list){
//System.out.println("left:"+left+" "+"right:"+right);
if(left==right) {
if(nums[left]==target){
list.add(left);
return;
}
else return;
}
int mid=left+(right-left)/2;
// System.out.println("mid:"+mid);
if(target<=nums[mid]){
search_(nums,target,left,mid,list);
}else{
search_(nums,target,mid+1,right,list);
}
}
}
- 思路二
class Solution {
public int search(int[] nums, int target) {
int left=0;
int right=nums.length-1;
while(left<=right){ //为什么会有=号,最极端的例子数组只有一个元素时,不加=号,循环都进不去
int mid=left+((right-left)/2);
if(nums[mid]>target) right=mid-1;
else if(nums[mid]<target) left=mid+1;
else return mid;
}
return -1;
}
}
10.链表
10.1 理论基础
链表的代码定义
class ListNode {
int val;
ListNode next;
ListNode() {};
ListNode(int val) { this.val=val; }
ListNode(int val, ListNode next) { this.val = val; this.next = next; }
}
10.2 移除链表元素
-
思路
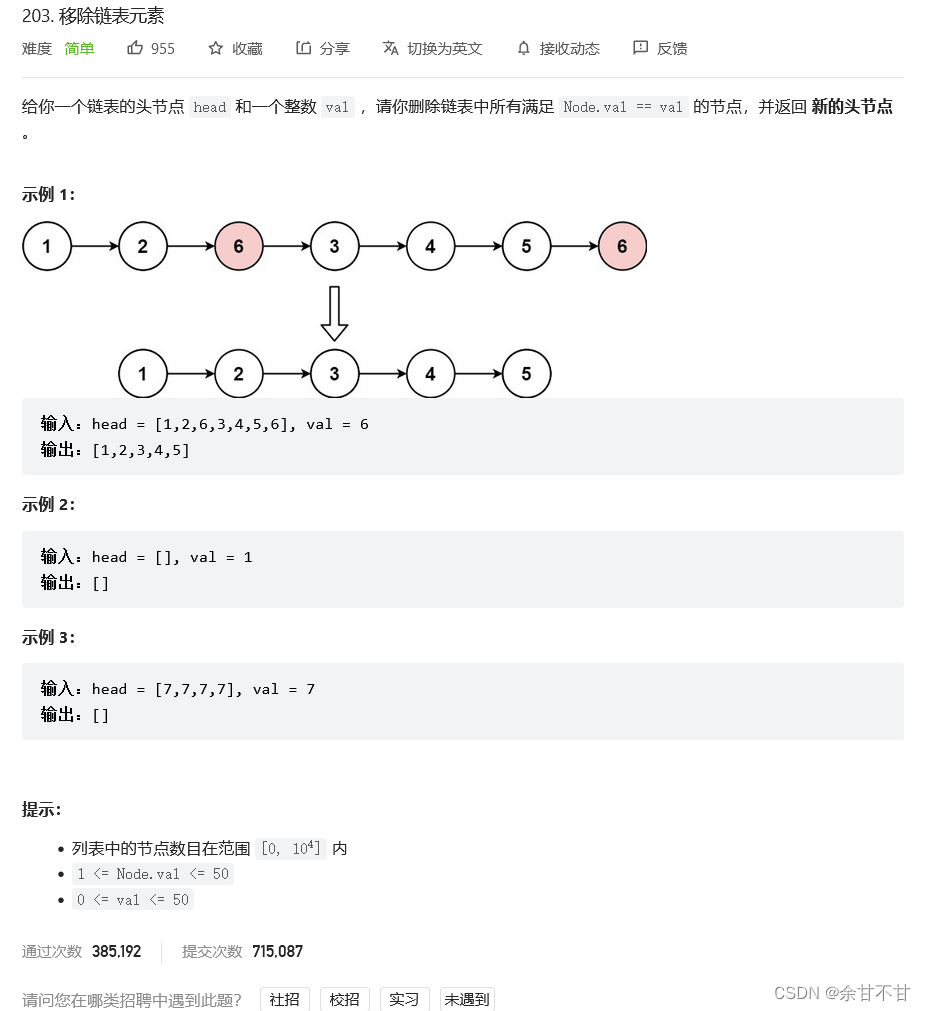
自己最开始并没有想到设置一个虚的头节点,所以在删除头部元素时,需要单独提出一个判断逻辑,但作者巧妙的设置一个虚头节点就把判断逻辑统一了
- 代码
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode removeElements(ListNode head, int val) {
ListNode virtual = new ListNode(-1,head);
ListNode pre = virtual;
ListNode cur = head;
while (cur != null) {
if (cur.val == val) {
pre.next = cur.next;
} else {
pre = cur;
}
cur = cur.next;
}
return virtual.next;
}
}
10.3 翻转链表
-
思路
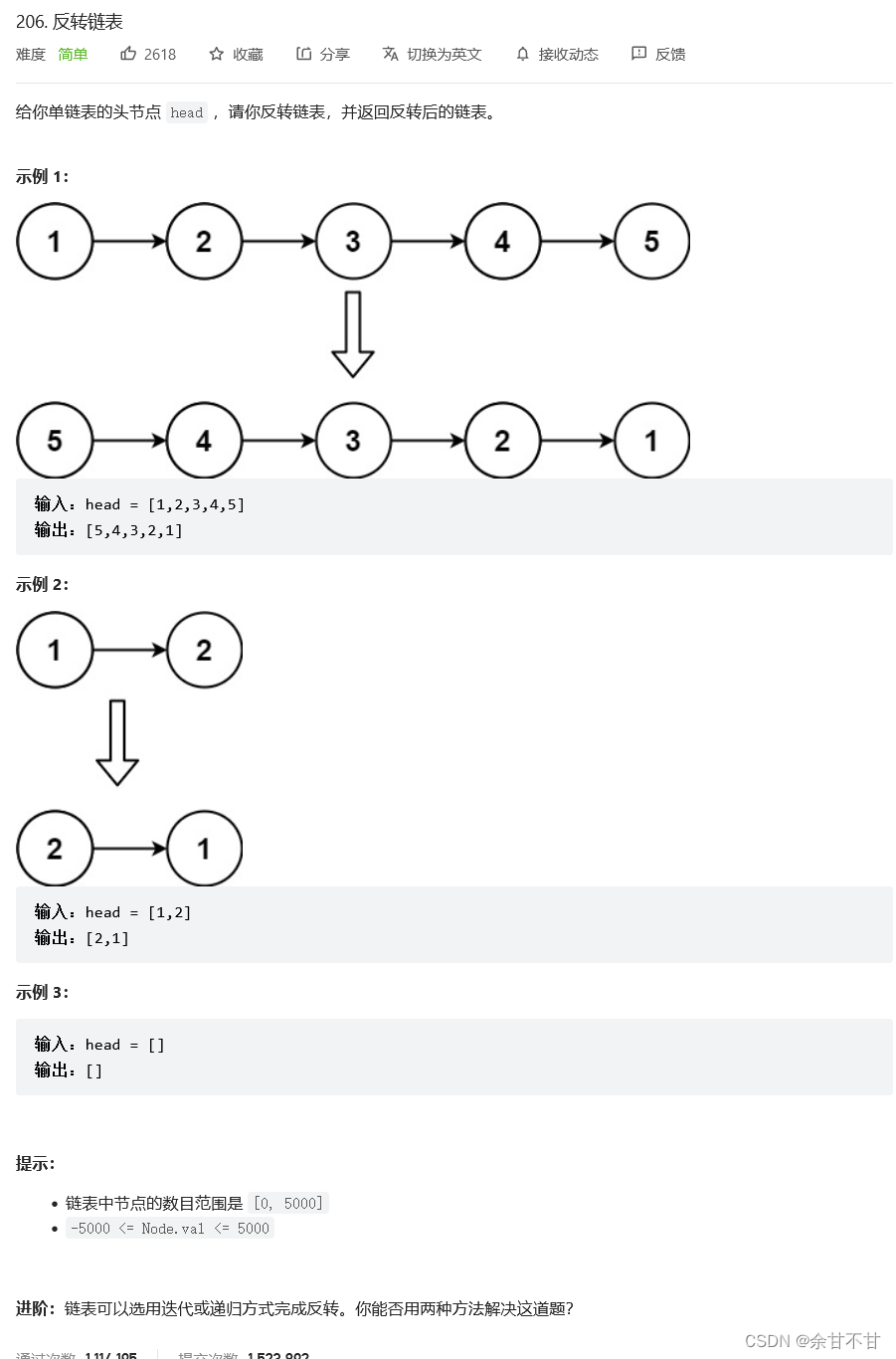
自己最初想的是再新建一个链表,然后每次取给链表的最后一个
但是后面神奇的发现,只要遍历一次给定的链表,然后翻转指针就行了
- 代码
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode reverseList(ListNode head) {
ListNode pre = null;
ListNode cur = head;
while (cur != null) {
ListNode tem=cur.next;
cur.next = pre;
pre = cur;
cur =tem;
}
return pre;
}
}
10.4两两交换链表中的节点
-
题目
在这里插入图片描述 -
思路
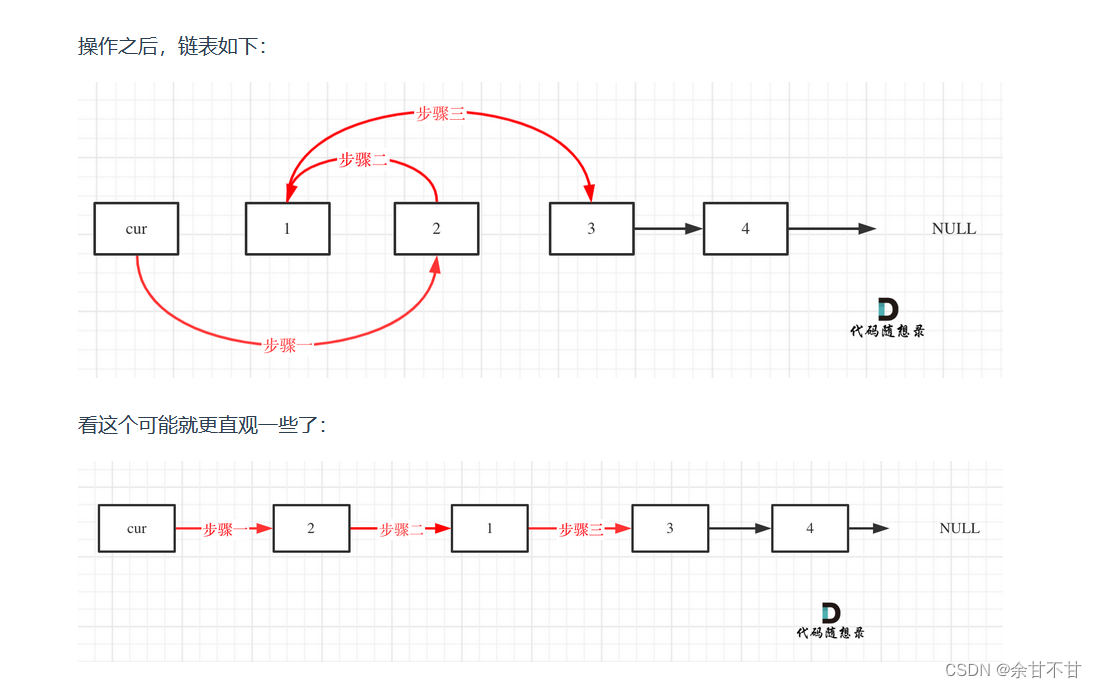
-
代码
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode swapPairs(ListNode head) {
ListNode virtualHead = new ListNode(0);
virtualHead.next = head;
ListNode cur = virtualHead;
while (cur.next != null && cur.next.next != null) {
ListNode tem = cur.next; //记录临时节点
ListNode tem1=cur.next.next.next; //记录临时节点
cur.next = cur.next.next; //第一步
cur.next.next = tem; // 第二步
cur.next.next.next = tem1; //第三步
cur = cur.next.next; //改变当前节点
}
return virtualHead.next;
}
}
10.5 删除链表中的第N个节点
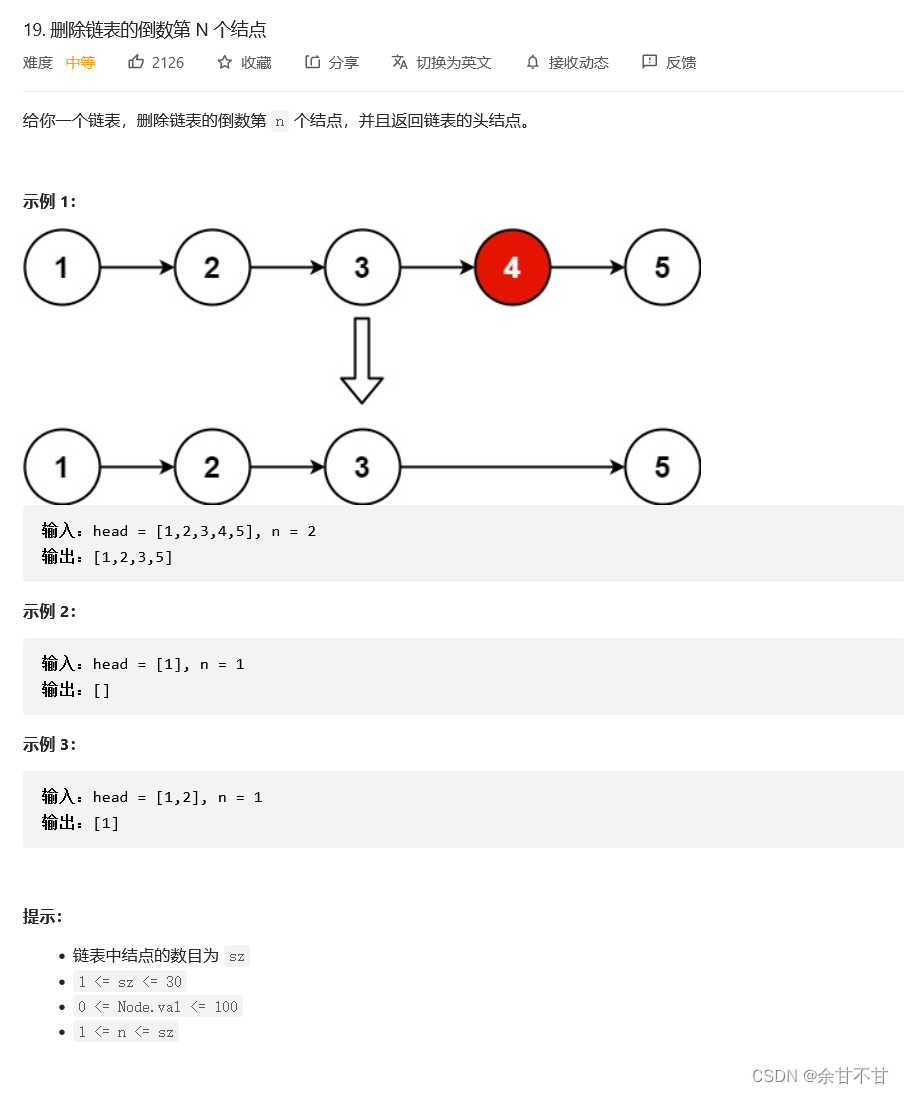
- 思路
我最初想的是用一个hashmap存储链表和它的下标,在通过计算得出倒数第n个链表的下标,然后获取到该链表的值val_,再通过遍历链表删除val == val_的链表,但是再实现过程中会发现,多次的遍历让head一直在移动,我们需要通过virtualHead反复获得最初的head,而且在删除过程中你会发现,你删除的是所有val == val_的链表,所有此思路不通
此思路代码
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode removeNthFromEnd(ListNode head, int n) {
ListNode virtualHead=new ListNode(0,head);
ListNode cur=head;
ListNode pre=virtualHead;
Integer m=1;
HashMap<Integer,ListNode> hashMap = new HashMap<Integer,ListNode>();
ListNode head_=virtualHead.next;
while (head_ != null) {
hashMap.put(m,head_);
head_ = head_.next;
m++;
}
// System.out.println("m:"+m);
Integer tem = m-n;
// System.out.println("tem:"+tem);
// System.out.println("val_:"+hashMap.get(tem).val);
int val_=hashMap.get(tem).val;
ListNode cur_2=virtualHead.next;
while (cur_2 != null){
if(cur_2.val == val_) {
pre.next = cur_2.next;
} else {
pre = cur_2;
}
cur_2 = cur_2.next;
}
return virtualHead.next;
}
}
解答错误
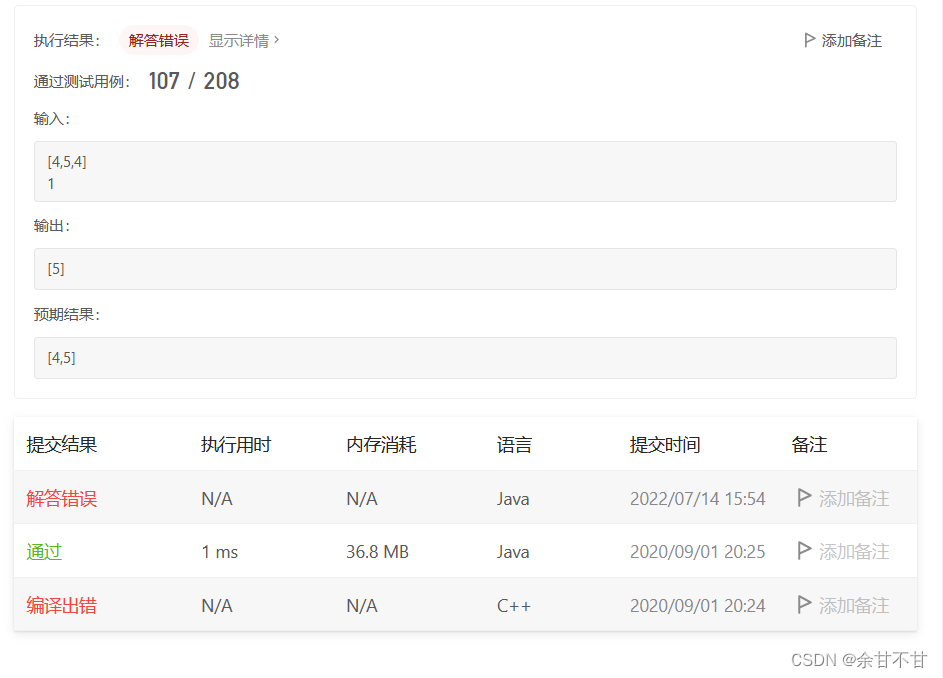
作者思路:通过双指针删除倒数第n个链表,因为在同时移动的过程中fast-slow == n+1;所以当fast到达末尾时,slow刚好就能达到我们想要删除聊表的前一个位置
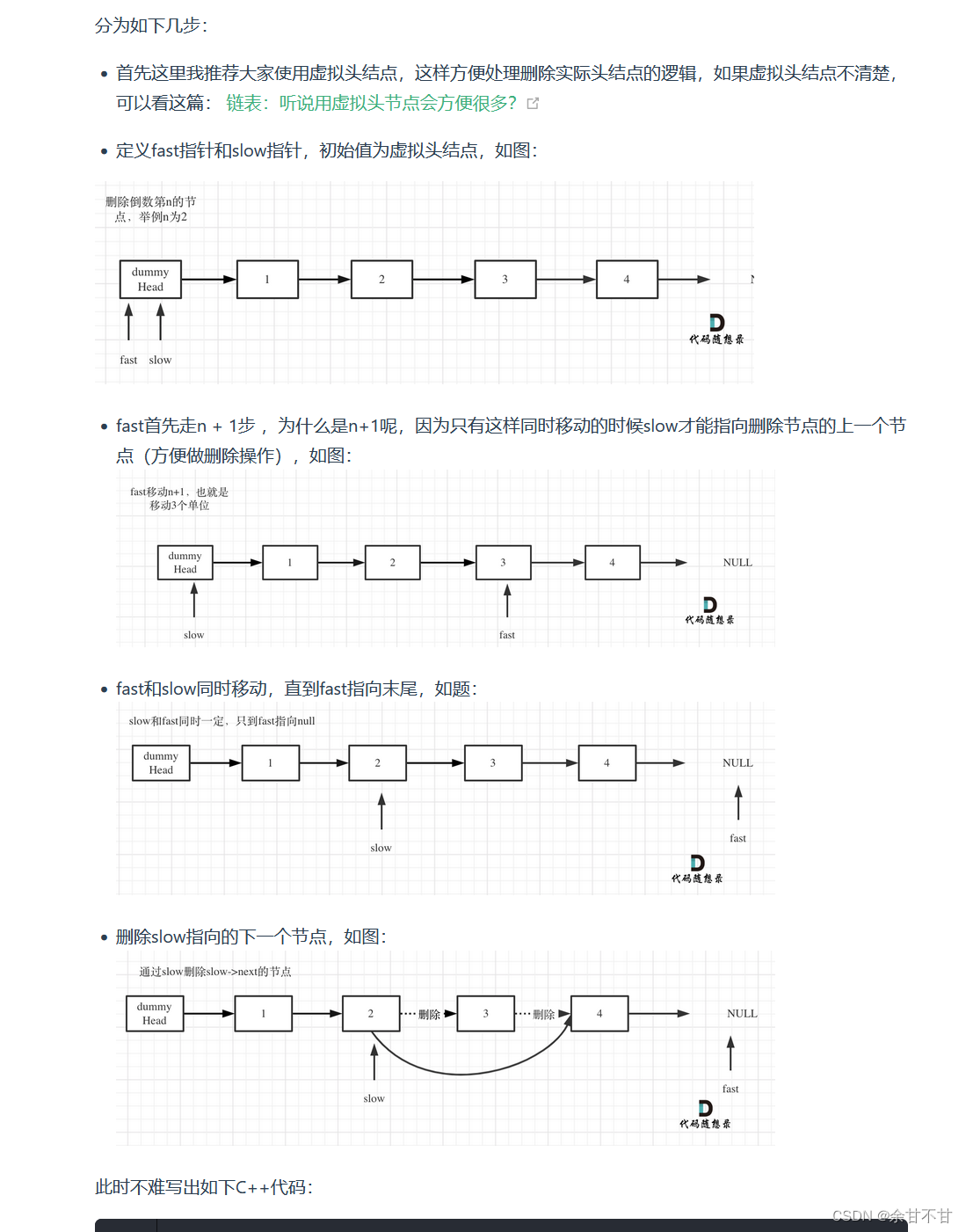
- 代码
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode removeNthFromEnd(ListNode head, int n) {
ListNode dummy = new ListNode(-1,head);
ListNode fast = dummy;
ListNode slow = dummy;
while (n >= 0) {
fast = fast.next;
n--;
}
while (fast != null) {
slow = slow.next;
fast = fast.next;
}
slow.next = slow.next.next;
return dummy.next;
}
}
10.6 链表相交

- 思路
在题解中看到一个超级浪漫和巧妙的思路,我们把ListNodeA分为a和两部分,ListNodeB分为c和b两部分,当我们以a->b->c和以c->b>a这两种同的路径走时,其实我们走的是相同的距离,所以最终会以curA == curB == 3结束
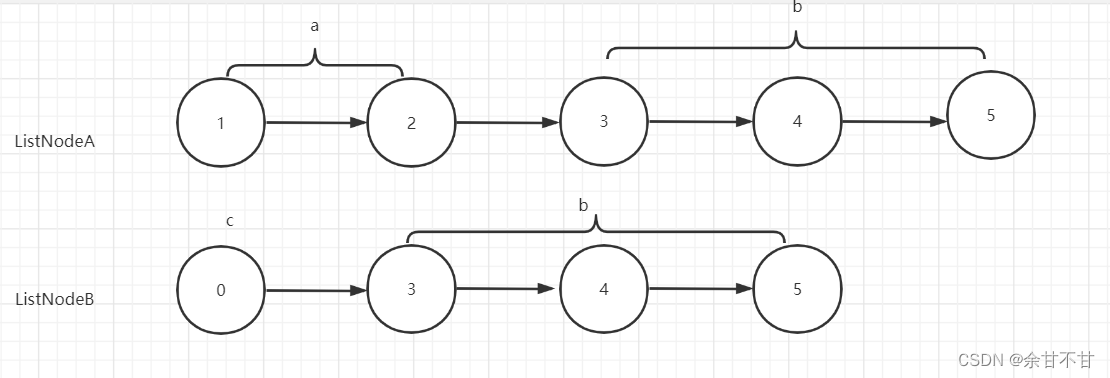
- 代码
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
ListNode curA = headA;
ListNode curB = headB;
// 要么相遇即节点相等,要么都为空即无缘无分,最终都能跳出感情的死循环。
while(curA != curB){
// 两人以相同的速度(一次一步)沿着各自的路径走,当走完各自的路时,再“跳”至对方的路上。(起点平齐速度相同,终点即为相遇点)
curA = (curA == null? headB:curA.next);
curB = (curB == null? headA:curB.next);
}
return curA;
}
}
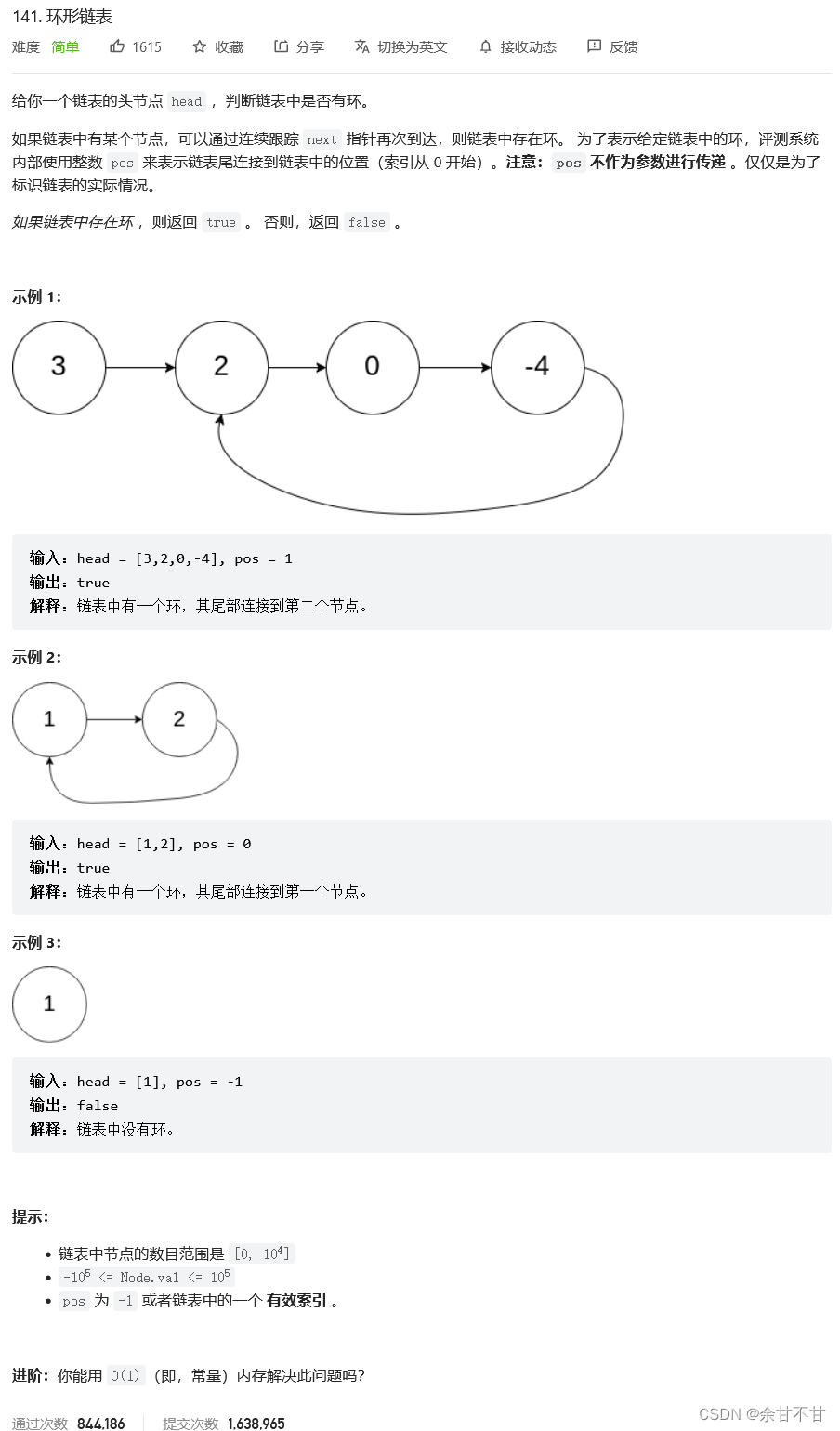
10.7.1 环形链表
-
代码
/**
* Definition for singly-linked list.
* class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
public boolean hasCycle(ListNode head) {
ListNode fast = head;
ListNode slow = head;
while(fast != null && fast.next!=null){ //如果不为环形链表,肯定会跳出该循环,如果为环形链表,快慢指针一定会相遇
fast = fast.next.next;
slow = slow.next;
if(fast == slow) return true;
}
return false;
}
}
10.7环形链表II
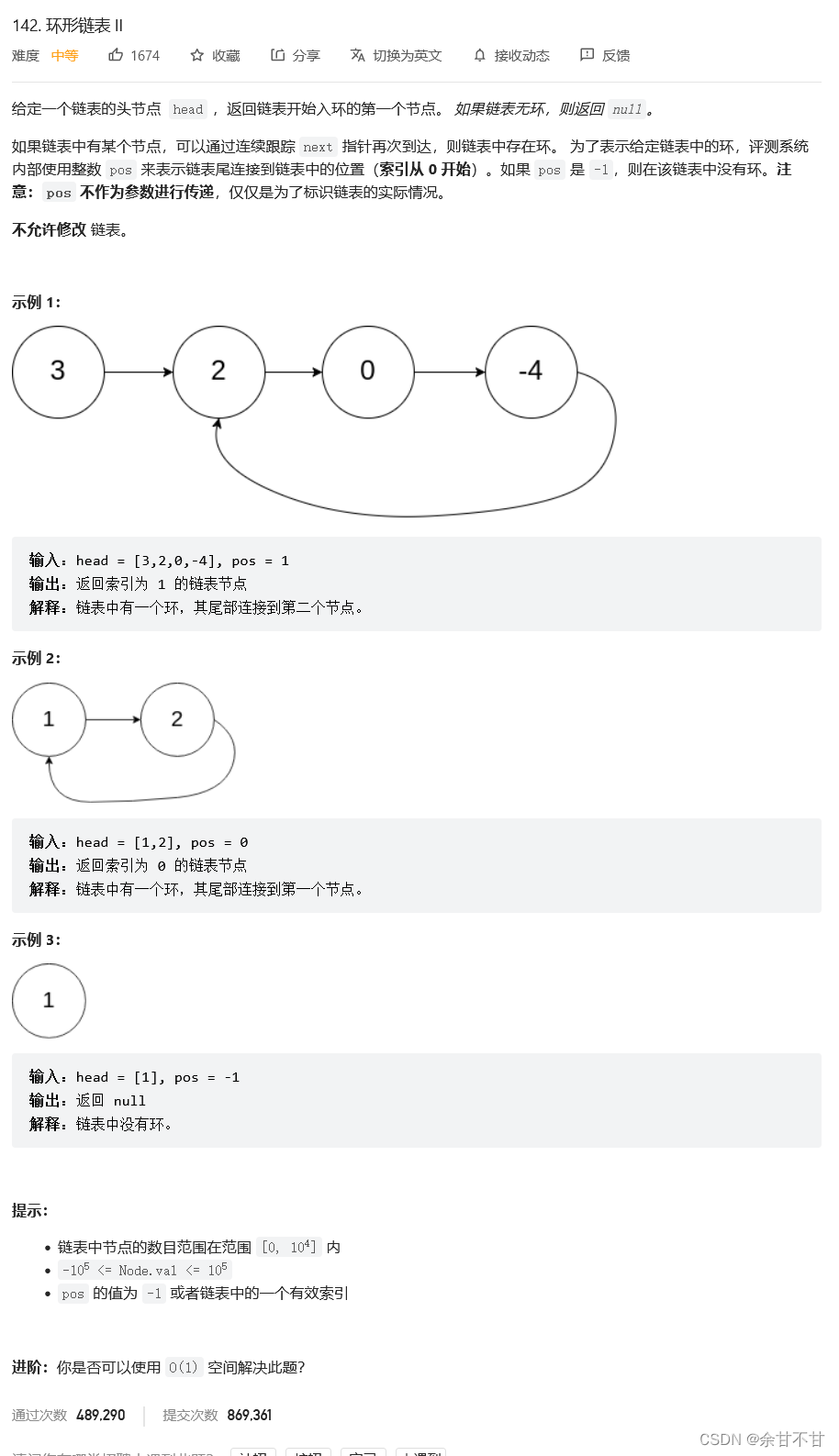
- 思路
看完解题思路我只能说一句卧槽
- 代码
/**
* Definition for singly-linked list.
* class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
public ListNode detectCycle(ListNode head) {
ListNode fast = head;
ListNode slow = head;
while (fast != null && fast.next != null) {
fast = fast.next.next;
slow = slow.next;
if (fast == slow) {
ListNode index1 = fast;
ListNode index2 = head;
while (index1 != index2) {
index1 = index1.next;
index2 = index2.next;
}
return index1;
}
}
return null;
}
}
11 滑动数组
无重复字符的最长子串
- 思路

- 代码
class Solution {
public int lengthOfLongestSubstring(String s) {
int n = s.length(), ans = 0;
Map<Character, Integer> map = new HashMap<>();
for (int end = 0, start = 0; end < n; end++) {
char alpha = s.charAt(end);
if (map.containsKey(alpha)) {
start = Math.max(map.get(alpha), start);
}
ans = Math.max(ans, end - start + 1);
map.put(s.charAt(end), end + 1);
}
return ans;
}
}
12.栈和队列
有效的括号
- 题目
- 解题思路

- 代码
自己的代码,当然代码还可以简化成作者那样的,但思路并不是特别容易懂
思路
通过模拟发现无非就“(()”左边多了括号,“(}”括号不匹配,“())”右边多了括号这三种情况
Stack<Character> stack = new Stack<>();
for(int i = 0; i < s.length(); i++){
if(s.charAt(i) == '(') stack.add(')');
else if(s.charAt(i) == '{') stack.add('}');
else if(s.charAt(i) == '[') stack.add(']');
else if(stack.isEmpty()) return false; // 解决“())”右边多了括号这种情况
else { //解决“(}”括号不匹配
Character tem = stack.peek();
if(tem != s.charAt(i)) return false;
stack.pop();
}
}
return stack.isEmpty(); //“(()”左边多了括号
class Solution {
public boolean isValid(String s) {
Stack<Character> stack = new Stack<>();
for(int i = 0;i < s.length();i++){
if(s.charAt(i) == '(') stack.push(')');
else if(s.charAt(i) == '{') stack.push('}');
else if(s.charAt(i) == '[') stack.push(']');
// 第三种情况:遍历字符串匹配的过程中,栈已经为空了,没有匹配的字符了,说明右括号没有找到对应的左括号 return false
// 第二种情况:遍历字符串匹配的过程中,发现栈里没有我们要匹配的字符。所以return false
else if(stack.isEmpty() || (stack.peek() != s.charAt(i)) ) return false;
else stack.pop();
}
// 第一种情况:此时我们已经遍历完了字符串,但是栈不为空,说明有相应的左括号没有右括号来匹配,所以return false,否则就return true
return stack.isEmpty();
}
}
排序算法
快速排序
地址
时间复杂度:这里可以说大部分情况下可以做到O(nlogn),极端情况下才会退化O(n^2)
public static void main(String[] args) {
int[] arr={6,1,2,7,9,3,4,5,10,8};
quickSort(arr,0,arr.length-1);
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i]+" ");
}
}
public static void quickSort(int[] arr,int start,int end){
int i,j,temp;
if (start >= end) { //二分法确定递归终止条件
return ;
}
i = start;
j = end;
temp = arr[start];
while (i != j) { //每一轮的交换终止条件为俩个哨兵相遇
while (arr[j] >= temp && i<j) j--;
while (arr[i] <= temp && i<j) i++; //加上"="号是为了防止碰到[5,5,5,5]这种数组i,j无法移动
int tem1 = arr[i];
arr[i] = arr[j];
arr[j] = tem1;
}
arr[start] = arr[i];
arr[i] = temp ;
quickSort(arr,start,i-1);
quickSort(arr,i+1,end);
return ;
}
冒泡排序
public static void main(String[] args) {
int[] arr={2,3,1,5,8};
int[] res = bubbleSort(arr);
for (int i = 0; i < res.length; i++) {
System.out.print(res[i]+" ");
}
}
public static int[] bubbleSort(int[] arr){
if(arr.length <= 1) {
return arr;
}
for (int i = 0; i < arr.length; i++) {
boolean issorted = true;
for(int j = 0; j < arr.length-1-i; j++) { //j < arr.length-1-i而不是j <= arr.length-1-i说明第一次比较时,j最多到达数组的倒数第二个位置
int tem = arr[j];
if(arr[j] > arr[j+1]) {
arr[j] = arr[j+1];
arr[j+1] = tem;
issorted = false;
}
}
if(issorted) break;;
}
return arr;
}















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









