







目录
一.图像检索相关介绍:
1.起因:
我们为什么要图像检索与识别?
在图像特征提取后进行比对
,如果采用暴力匹配法:
250,000 张图像
~ 310
亿个图像对 :
– 每个图相对
2
秒 匹配
500
台并行计算机需要
1
年才能完成计算 ;
• 1,000,000 张图像~5000亿个图像对 :
– 500
台并行计算机需要
15
年才能完成计算。
而
对于大场景数据集(如城市场景)
,
只有少
于
0.1% 的图像对具有匹配关系,
我们的解决方案
是
利用图像整体特征实现匹配
/
检索,
而非局部特征点。
2.参数介绍:
对于图像检索
我们首先了解一下:
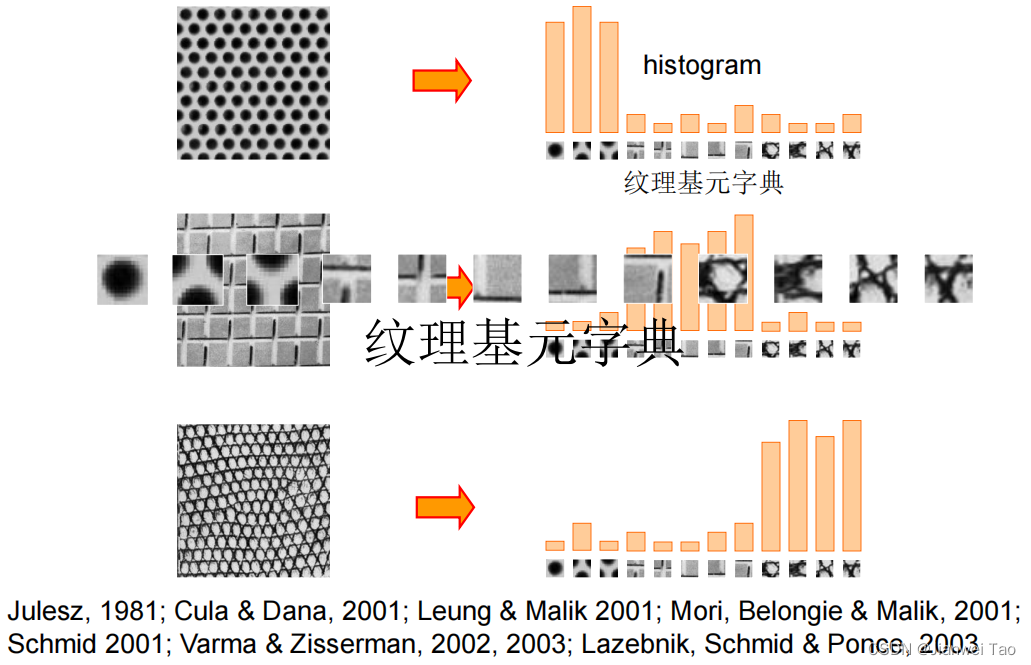
图像纹理:
纹理是指图像中的重复模式,或纹理基元组成的结构

词序无关的文本表述:
根据文本中的词频分布,构造文本描述子;
研表究明,汉字序顺并不定一影阅响读。比如当你看完这句话后,才发这现里的字全是都乱的。

图像分类:
对于图像我们可以将它分类成很多小组成;

图像特征词典:
Bag of features ( BOF)一种适用于图像和视频检索的算法。BOF借鉴了文本分类的思路(也就是BOW),从图像抽象出很多具有代表性的「关键词」,形成一个字典,再统计每张图片中出现的「关键词」数量,得到图片的特征向量。
基础流程:
1. 特征提取;

2. 学习 “视觉词典(visual vocabulary)” ;
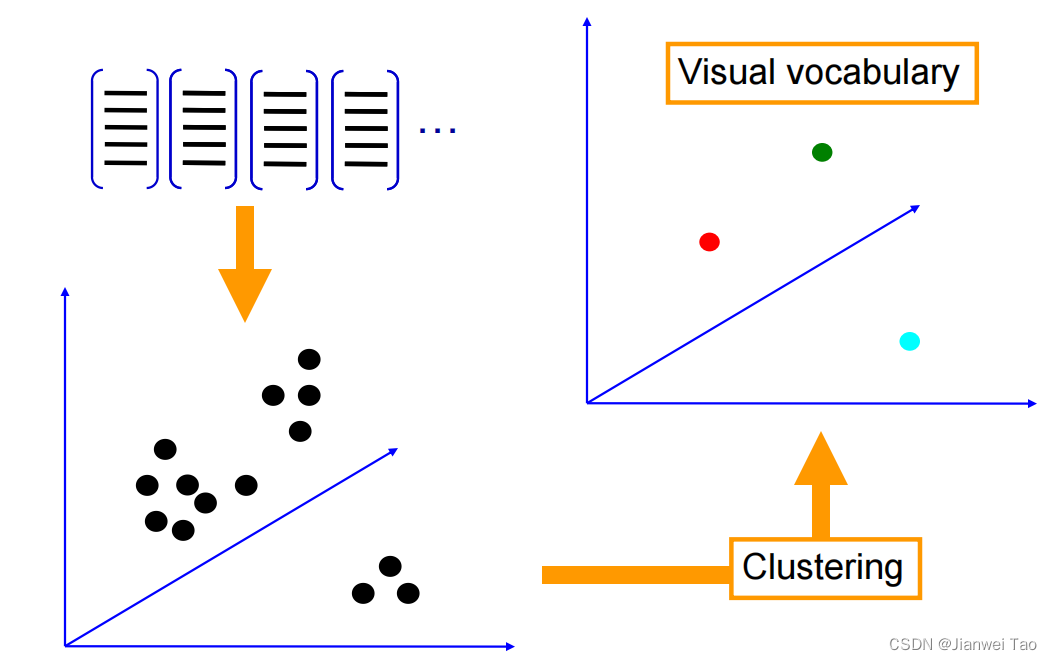
3. 针对输入特征集,根据视觉词典进行量化;
对于输入特征,量化的过程是将该特征映射到距离其最接近的 codevector ,并实现 计数 ,码本 = 视觉词典 ,Codevector = 视觉单词 。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3615
3615











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









