






环境问题:
一:conda创建环境无效
首先登录多用户的远程服务器
然后发现该远程服务器已经创建好了conda
然后直接使用该conda在pycharm中创建环境,
结果发现,该环境里面没有编译器(完全使用不了)
这是因为在用户环境里面没有python.exe的路径
解决办法:
1.可以通过设置里,搜索“环境变量”,点击编辑账户的环境变量。

2. 增加一条python.exe的路径,我用了conda里面的python执行程序。

3.然后再次去pycharm里面创建环境就可以了。
然后如果还不行,就直接卸载conda,然后重装conda,再按照上面的步骤执行。
注意:
这个问题的解决需要弄清楚那个用户环境变量/管理员环境变量/系统环境变量
原文链接:https://blog.csdn.net/weixin_43354152/article/details/128726687
所谓环境变量,可以简单理解为就是给操作系统定义的一些路径和名称。比如使用最常使用的就是名为Path的环境变量,该环境变量就指示了可执行文件的存放目录。
在cmd命令行中,在不指定路径的情况下执行某个命令,系统不一定知道这个命令对应的可执行文件在哪,如果在可执行文件所在的目录放到Path环境变量中,就能够确保找到对应的可执行文件
windows系统中环境变量分为两类:系统变量和用户变量。
由于windows系统可以创建多个账户,用户环境变量就是只对当前的账户有效,可以看到用户环境变量的全称是xxx的用户变量,表示这只是针对某个账户的变量;而系统变量就是对多有的账户都是有效的。
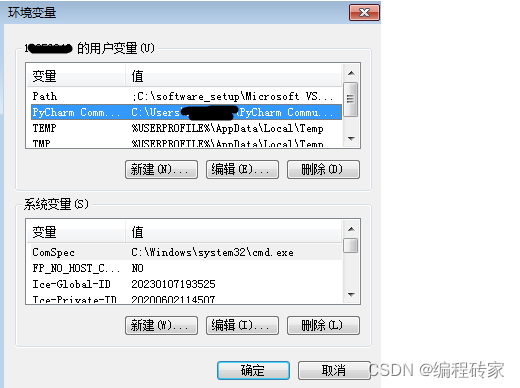
系统变量与用户变量的联系与区别如下:
1.系统变量与用户变量可以存在重名,比如系统变量与用户变量都可以一个名为Path的变量
2.如果系统变量与用户变量重名,优先使用系统变量
3.系统变量与用户变量的变量名都不区分大小写,即path与PATH是一样的
4.系统变量对所有的用户有效,用户变量只当前的用户有效。
5.Path变量告诉系统可执行文件存放的路径
如果没有特殊说明的话,都设置为系统变量吧,因为系统变量对当前用户肯定也是有效的。
二 安装gpu版本的tensorflow
1.首先需要安装cuda和cudnn,随便找个安装文档进行安装就可。
主要版本匹配问题(记录一下:cuda:12.1;cudnn:8.9.1)
因为nvidia的升级基本上都是是CUDA12了,在我发表文章的时候如果去官网下载CUDA包默认安装CUDA版本就是12了.
2.使用GPU报错Library cublas64_11.dll is not found 。
最后是去CUDA的安装路径下的bin目录你会看到新版本的cublas64_12.dll复制一个,名字改成cublas64_11.dll,然后一切顺利。
三 ImportError: cannot import name 'dtensor' from 'tensorflow.compat.v2.experimental' (C:\Users\lgh\.conda\envs\tensorflow2\lib\site-packages\tensorflow\_api\v2\compat\v2\experimental\__init__.py)
这是因为tensorflow的版本与keras版本不兼容的原因。
我的tensorflow_gpu为2.6.0,但是我看了keras的版本为2.10.0
尝试将keras卸载后,安装了2.6.0版本的keras,就可以运行了
四 NVIDIA显卡驱动+CUDA+CUDNN+Tensorflow+Keras之间的关系(含各版本对应关系表)

driver决定了CUDA的版本
CUDA决定了cuDNN的版本
CUDA决定了tensorflow-gpu的版本
tensorflow-gpu决定了python的版本
与此同时,tensorflow-gpu和Keras也存在对应关系
五 Could not locate zlibwapi.dll. Please make sure it is in your library path
六 l =tf.trainable_variables()
AttributeError: module 'tensorflow' has no attribute 'trainable_variables'
修改为
l =tf.compat.v1.trainable_variables()
七 np.object was a deprecated alias for the builtin object. To avoid this error in existing code, use object by itself. Doing this will not modify any behavior and is safe
这是因为numpy与tensoflow的版本不匹配
解决办法:修改numpy的版本,一般是降低版本(注意:在改变numpy的版本的时候会连带的影响其他依赖包的版本修改,所以要将涉及到的所有包都安装到适当的版本)
八 UserWarning: loaded more than 1 DLL from .libs:
表明在加载 numpy 库时,从 .libs 目录下加载了多个 DLL 文件。
解决办法:删掉一个就可以了
九 进入tensorboard的步骤
C:\Users\lgh>conda info --envs
C:\Users\lgh>activate tensorflow2
(tensorflow2) C:\Users\lgh>pip install tensorboard==2.6.0
(tensorflow2) C:\Users\lgh>tensorboard --logdir=D:\lgh\project\Autopilot-TensorFlow-master\Autopilot-TensorFlow-master\logs
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all
TensorBoard 2.6.0 at http://localhost:6006/ (Press CTRL+C to quit)
十 TypeError: unhashable type: 'dict'
十一 matplot.plot的用法
十二 db的换算
(1条消息) db分贝计算公式_db公式_cabbage2008的博客-CSDN博客
十三 ValueError: No such layer: normalization_noise_1.
K.set_value(autoencoder.get_layer('normalization_noise_1').snr_db, snr)
解决办法:
1.观察模型中的噪声层是否被正常调用了(在pycharm的右上角有个黄色警告标志,点击查看是否有NormalizationNoise' object is not callable。如果有,则表明该层没有调用。
2.安装tf_nightly版本
1)确保你已经正确安装了
pip工具。你可以在终端中运行pip --version来检查 pip 版本。2)确保你的 Python 版本与
tf-nightly兼容。tf-nightly可能需要较新的 Python 版本。建议使用 Python 3.7 或更高版本。pip install tf-nightly
参考:值错误:没有这样的层 - 提取张量流 keras 层的输出 - 堆栈溢出 (stackoverflow.com)
十四 安装GPU版本的pytorch老是失败的原因
主要是CUDA本身是12.1版本,但是pytorch的官网上的版本对应的只有cuda11.8的版本,这样该怎么解决?
不要在这里复制代码: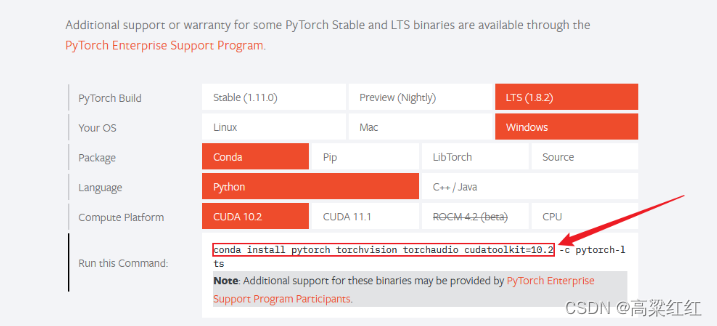
需要进入Previous versions of PyTorch

然后安装最新版本的,即可正常运行
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









