










一,前期准备 需要用到python 的编译工具 pycharm 下载链接:
Download PyCharm: Python IDE for Professional Developers by JetBrains
(此外需要下载jdk对环境进行配置,这里不做过多讲解请看该链接)
(28条消息) jkd的安装与配置_wangpaichengxu的博客-CSDN博客_jkd64位
二,数据爬取
1.向服务器发送请求
随便找一个电影的界面,输入F12,刷新一下找到chart这个文档
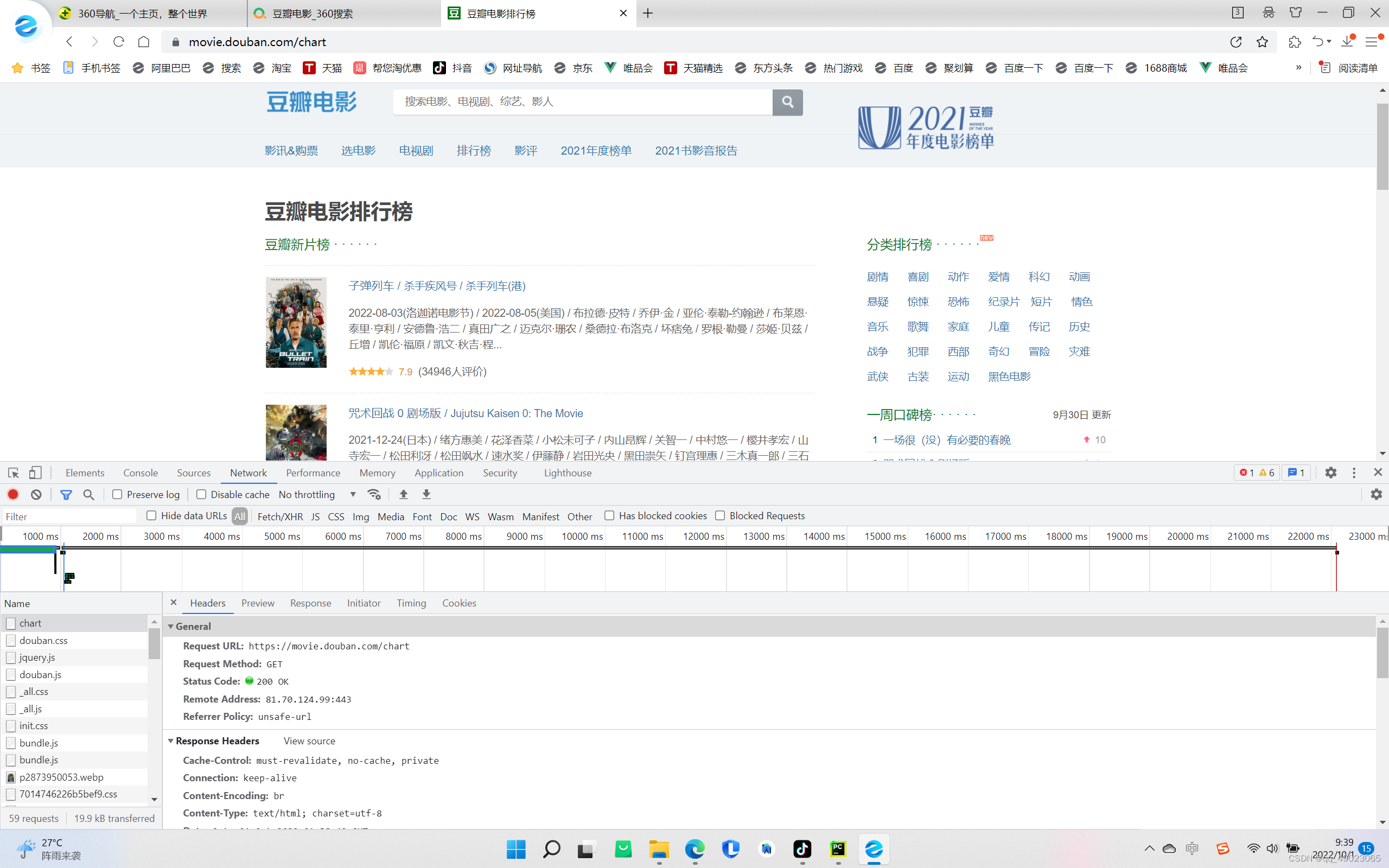
下载requests这个需求库 用win+R 进入终端 输入
pip install requests
下载后就可以使用这个库了 ,接着进行代码编写

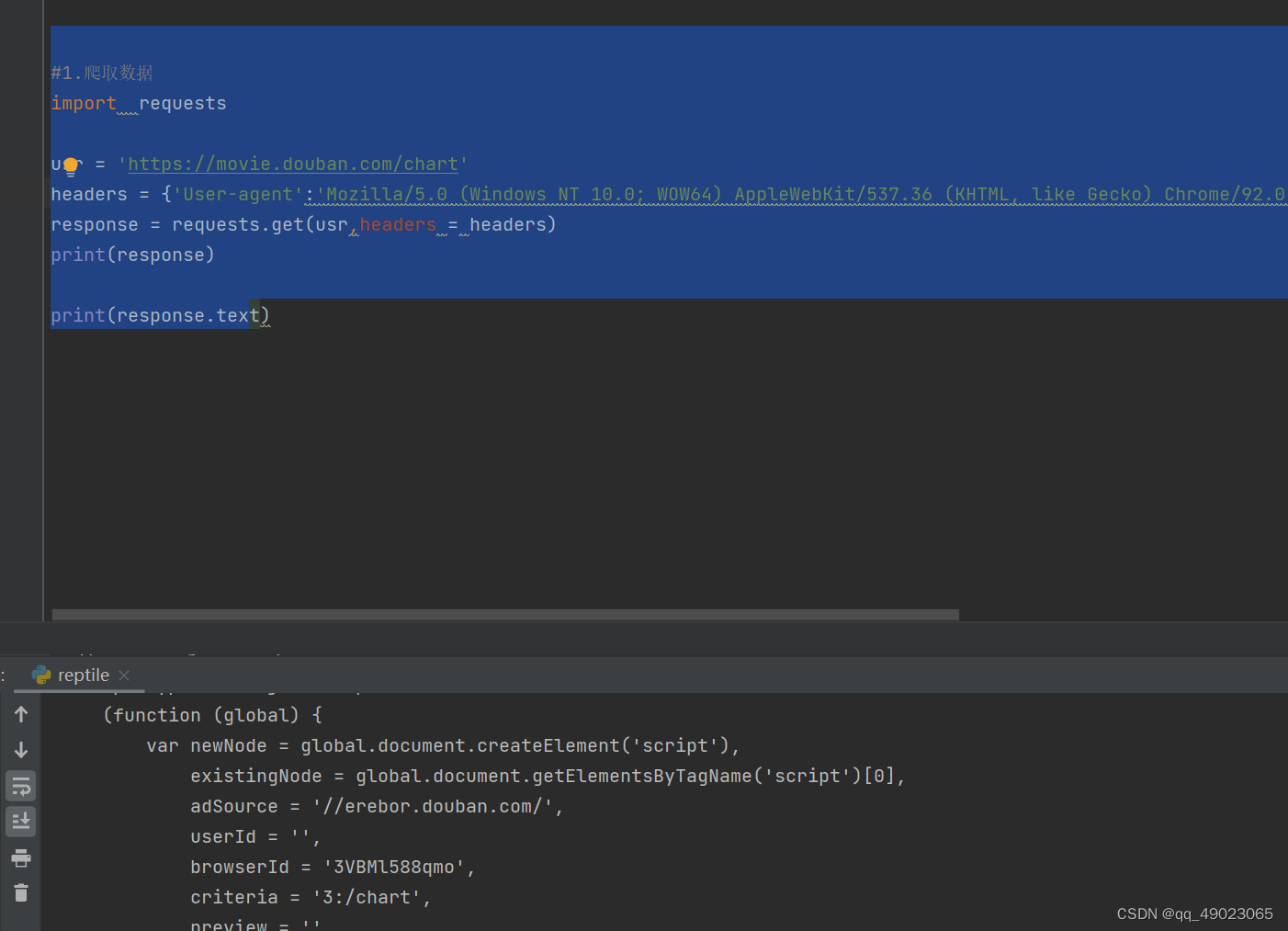
#1.爬取数据
import requests
usr = 'https://movie.douban.com/chart'
headers = {'User-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.0.3161 SLBChan/105'}
response = requests.get(usr,headers = headers)
print(response)
接着运行代码,返回
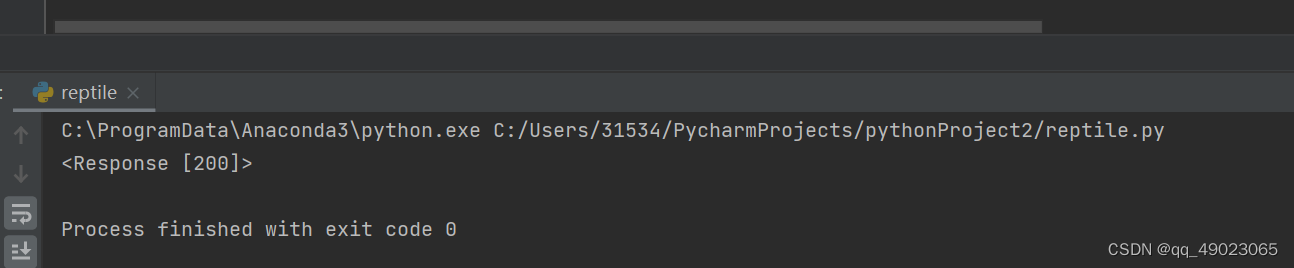
我们可以打印一下代码,可以发现和网页上的源代码一致
三,数据解析
需要掌握正则表达式,不会的可以参考(当然还有很多方面,这里是最简单的正则表达式)
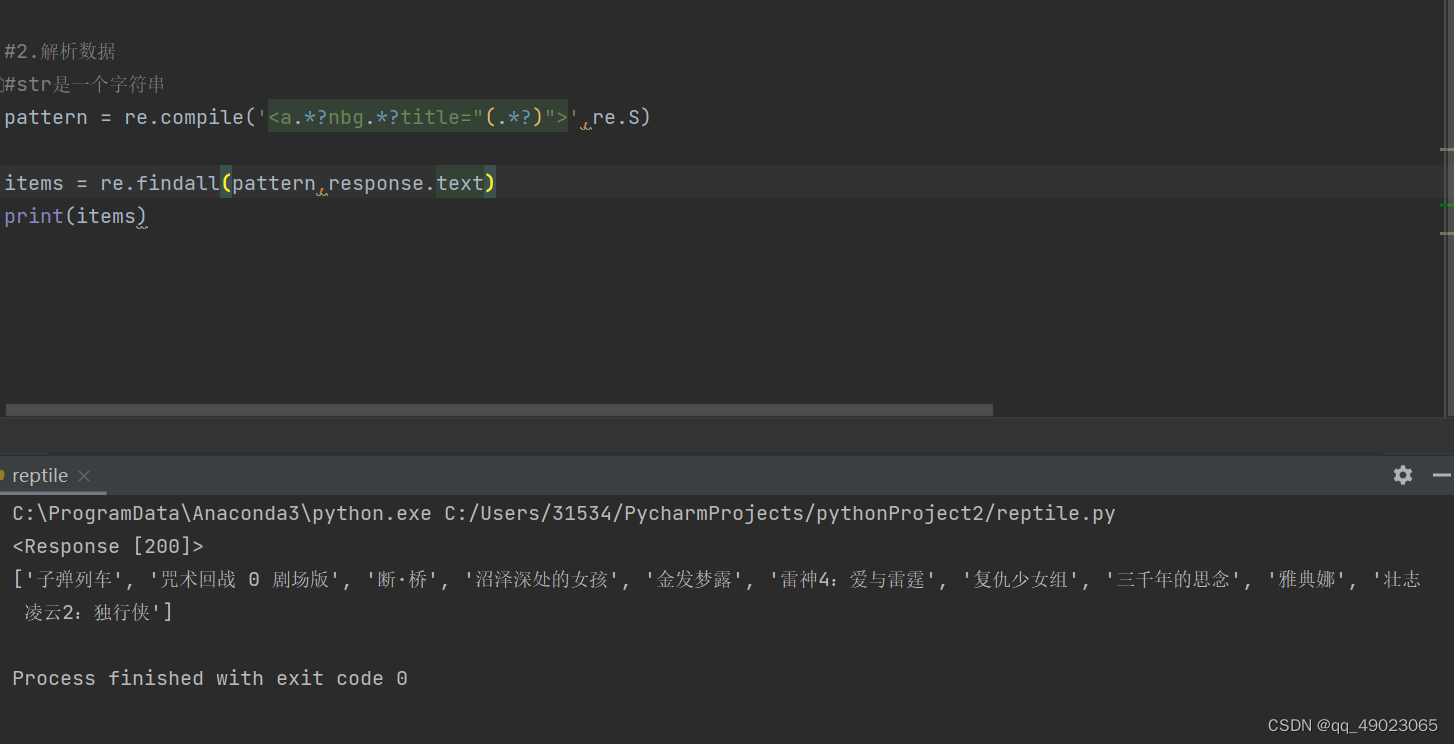
#2.解析数据
pattern = re.compile('<a.*?nbg.*?title="(.*?)">',re.S)
items = re.findall(pattern,respond_text)
print(items)
四,数据存储
这里我把数据存储在txt中
#数据存储
with open('douban.txt','w',encoding='utf-8') as f:
for items in items:
f.write(items+'\n')

完整的代码:
#1.爬取数据
import requests
import re
usr = 'https://movie.douban.com/chart'
headers = {'User-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.0.3161 SLBChan/105'}
response = requests.get(usr,headers = headers)
print(response)
#print(response.text)
#2.解析数据
pattern = re.compile('<a.*?nbg.*?title="(.*?)">',re.S)
items = re.findall(pattern,response.text)
print(items)
#数据存储
with open('douban.txt','w',encoding='utf-8') as f:
for items in items:
f.write(items+'\n')















 1507
1507











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









