







接下来的一些时间会分享一些爬虫相关的代码和知识
有人会问爬虫怎么舔女神?
我只能说浅了 看完伟大的Technical Licking Dog 的文章你将会对舔狗的认知得到一个升华!
目录
正文
import requests
name = input("输入你要查询的名字:")
url = f'https://cn.bing.com/search?q={name}'
dic = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.12151 SLBChan/33"
}#找user-agent f12
resp = requests.get(url,headers=dic)
print(resp.text)上面这串代码就是爬虫 是不是觉得很简单 可以去打一下的确很简单 但是我还是想说浅了
有没有想过它的运行方式?
爬虫的运行原理:

对服务器发起请求:
其中会携带你的数据 服务器就会对这些数据(headers、cookie、referer等等),类似于你过安检检查你是否安全不是非法的
-
返回响应:
其中可能携带数据或者网页信息等等
-
其实以上说到的基本原理别看我只画了一个请求和一个返回,其实是有可能是请求多次,返回多组数据的
-
实战一下豆瓣TOP250
看到一个网站
不要先打开开发者工具!!!
不要先打开开发者工具!!!
不要先打开开发者工具!!!
(想知道为什么请关注我的后续文章会有细致的讲解哈哈)
-
先别急看看源代码嘛(ctrl+u)
源代码 ≠ 开发者工具(element或元素)
-
当我们看到这串源代码的时候 就会发现我们需要的信息都出现在了源代码里面 我们只要请求然后筛选出我们需要的数据就行了(包浆 否则说我违规)

-
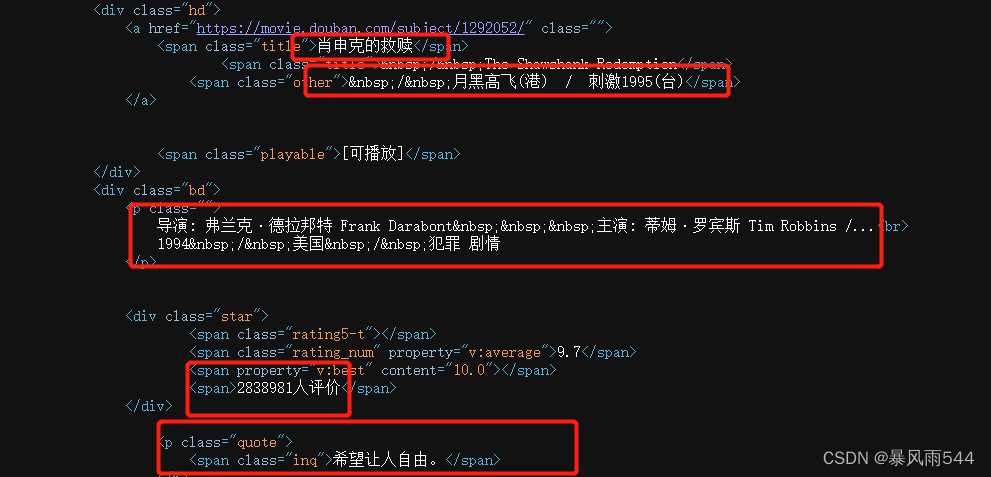
然后你就会写这么一串代码去发送请求 但是你会发现居然报错了 这就是反爬机制
-
所谓的反爬机制我们也无法就是说精确的找到一种办法去解决 只能就是试
这个时候就打开你的开发者工具F12 或 Fn+F12 ---> 找到网络(network)
如果发现里面是空的没有文件 ctrl + R 刷新一下
-

随便点开一个文件找到里面的user-agent 复制粘贴
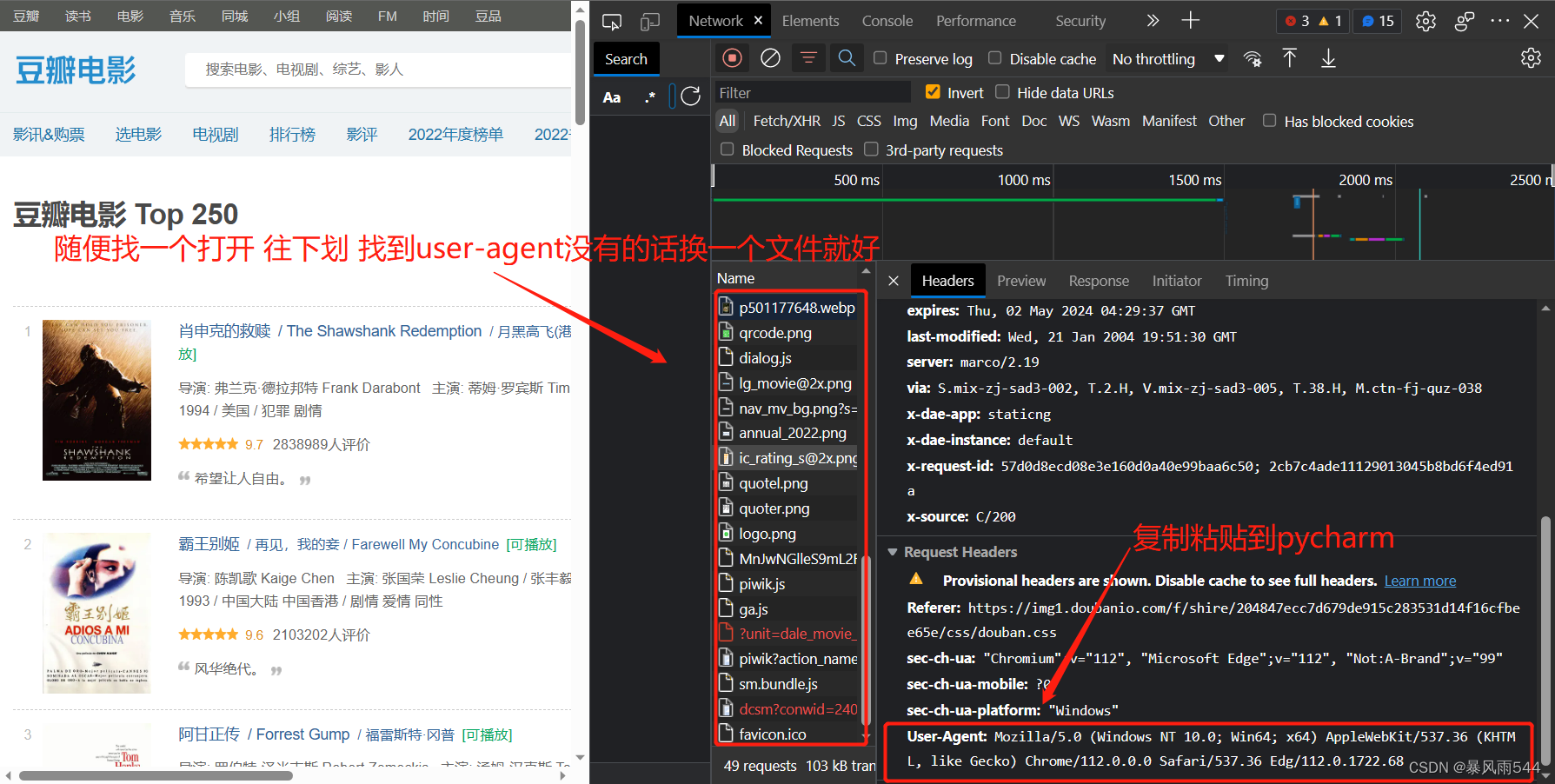
-

ok 这样我们就获取到了源代码
-
用正则清理一下提取出我们需要的数据
(除了re(正则)、xpath,美味的汤(忘了怎么拼了好像是beautifulsoup))
但是正则可以说是最快的
re.S :让正则去匹配的时候能够换行
obj.finditer :匹配出来的数据是一个迭代器 因为后面要写入exel里面比较方便就这么用了,当然也可以直接用findall 试试吧 不会可以私信问我
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)'
r'</span>.*?<p class="">.*?<br>(?P<year>.*?) .*?<span '
r'class="rating_num" property="v:average">(?P<score>.*?)</span>.*?'
r'<span>(?P<said>.*?)</span>',re.S)
datas = obj.finditer(resp)
for data in datas:
result = []
dic = data.groupdict()
dic['year'] = dic['year'].strip()
for value in dic.values():
result.append(value)
print(result)正则简单讲解:
如果要真的去学习正则表达式可以去网上找一下 但是作者不喜欢记太多东西 所以偷坤取巧发现了.*? 这个好东西
如何理解.*?:
.* 在正则里面表示任何东西都能匹配上(贪婪匹配)

-
.?在正则里表示谁都看不上(惰性匹配)

-
他两一结合就变成了 .*?

-
实现翻页
当我们爬出源代码的时候会发现我们top250只有top25
ok 我们滑倒最下面点击第二页 会看到网址显示
![]()
第三页
![]()
第四页
![]()
我们发现了一个规律就是每次翻页start= 后面的数字会增加25!!!!crazy!!!
那我们是不是有可能就是去访问这些网址然后筛选出我们需要的数据就ok了 我们只要请求十次就能实现我们的目标了
那我们只要循环十次然后每次加25就行了
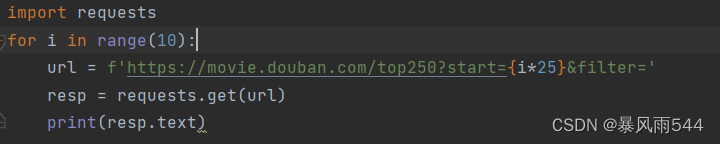
完整代码
最后把数据存储到表内 并简单做个可视化
import re
import requests
import openpyxl
import matplotlib.pyplot as plt
wb = openpyxl.Workbook()
sheet = wb.create_sheet('电影数据')
year = []
val = []
for i in range(10):
url = f"https://movie.douban.com/top250?start={i*25}"
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.62',
'Cookie':'ll="118286"; bid=h6vgP6FRIHw; _ga=GA1.2.38607179.1655792431; Hm_lvt_16a14f3002af32bf3a75dfe352478639=1655891953; viewed="1007305"; gr_user_id=34f6c8b0-7330-46aa-8df1-e07526f78957; __gads=ID=297653f28df76163-226ffe4538d50098:T=1658134586:RT=1658134586:S=ALNI_MZZVJWb95pMCooIcRP02XMA3vzraQ; ap_v=0,6.0; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1658423336%2C%22https%3A%2F%2Fcn.bing.com%2F%22%5D; _pk_ses.100001.4cf6=*; __utma=30149280.38607179.1655792431.1658140565.1658423338.8; __utmb=30149280.0.10.1658423338; __utmc=30149280; __utmz=30149280.1658423338.8.3.utmcsr=cn.bing.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utma=223695111.1864728931.1655792440.1656089200.1658423338.4; __utmb=223695111.0.10.1658423338; __utmc=223695111; __utmz=223695111.1658423338.4.3.utmcsr=cn.bing.com|utmccn=(referral)|utmcmd=referral|utmcct=/; _vwo_uuid_v2=D99D5C5BC1DF7395DA51F575DECBE1A29|7be6d65793d9cbb7a499ebc09a24b531; _pk_id.100001.4cf6=3a78da035377a38e.1655792440.4.1658423373.1656089237.; __gpi=UID=000007d49fb12f4b:T=1658134586:RT=1658423373:S=ALNI_MYN_rWPIi9BpB9FzZHFuFaCu3mKVQ',
'Host':'movie.douban.com'
}
resp = requests.get(url,headers=header).text
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)'
r'</span>.*?<p class="">.*?<br>(?P<year>.*?) .*?<span '
r'class="rating_num" property="v:average">(?P<score>.*?)</span>.*?'
r'<span>(?P<said>.*?)</span>',re.S)
datas = obj.finditer(resp)
for data in datas:
result = []
dic = data.groupdict()
dic['year'] = dic['year'].strip()
for value in dic.values():
result.append(value)
print(result)
sheet.append(result)#写入Exel表
year.append(result[1])#提取信息
val.append(result[2])#为了可视化
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False##中文显示问题
plt.bar(year,val)#柱状图
plt.show()#显示出可视化结果
wb.save('hhhhhhhhhhhhhhhh好找.xlsx',)#保存
因为篇幅有限有些东西无法尽善尽美 如果有什么不懂的地方可以评论区或私信问我!















 567
567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











