






 本文详细介绍了LSTM(长短期记忆)的工作原理,包括为何使用、解决RNN的梯度问题、基本架构(记忆细胞、遗忘门、输入门、输出门)以及参数如何提升理解能力。LSTM通过分离权重来处理长期和短期记忆,有效地解决了梯度消失和爆炸问题。
本文详细介绍了LSTM(长短期记忆)的工作原理,包括为何使用、解决RNN的梯度问题、基本架构(记忆细胞、遗忘门、输入门、输出门)以及参数如何提升理解能力。LSTM通过分离权重来处理长期和短期记忆,有效地解决了梯度消失和爆炸问题。
LSTM(Long short-term memory) 长短期记忆 全解手册
为什么使用LSTM,它解决什么问题?
时间回到1997年,这个时候的RNN面临的问题就是容易发生梯度消失和梯度爆炸。
具体RNN梯度消失和梯度爆炸的原因可以看这篇博客: Recurrent Neural Networks Tutorial, Part 3 – Backpropagation Through Time and Vanishing Gradients
简言之,就是在反向传播计算梯度的过程中,加上激活函数后向量函数相对于向量的导数结果如下:
S
j
=
t
a
n
h
(
W
x
X
j
+
W
s
S
j
−
1
+
b
1
)
S_j=tanh(W_xX_j+W_sS_{j-1}+b_1)
Sj=tanh(WxXj+WsSj−1+b1)
∏
j
=
k
+
1
t
∂
S
j
∂
S
j
−
1
=
∏
j
=
k
+
1
t
t
a
n
h
′
W
s
\prod_{j=k+1}^{t}\frac{\partial S_j}{\partial S_{j-1}}=\prod_{j=k+1}^{t}tanh'W_s
j=k+1∏t∂Sj−1∂Sj=j=k+1∏ttanh′Ws
在绝大部分训练过程中
t
a
n
h
tanh
tanh的导数是小于等于1的。
如果
W
s
Ws
Ws也是一个大于0小于1的值,
t
t
t很大整体会趋向于0。
如果
W
s
Ws
Ws很大,随着t的变大整体会趋向于无穷。
这就是RNN中梯度消失和爆炸的原因。
LSTM的基本架构
1997年,Sepp Hochreiter等人提出LSTM的原论文:Long short-term memory
(如果你对原论文十分感兴趣可以去看看,继续看下面的内容理解更快。)
LSTM的基本计算单元——记忆细胞
- RNN由输入层(输入 X t X_t Xt )、隐藏层和输出层(输出 Y t Y_t Yt)构成。
- LSTM由输入层(输入 X t X_t Xt )、记忆细胞( M e m o r y C e l l Memory Cell MemoryCell) 和输出层(输出 Y t Y_t Yt)构成。
LSTM和RNN一样是循环神经网络,也需要遍历所有时间步,不断循环嵌套。
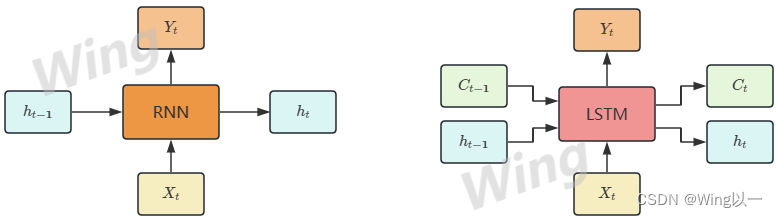
记忆细胞是LSTM的基本计算单元,其中设置了两个关键变量:
- 细胞状态 C C C:负责长期记忆
- 隐藏状态 h h h:负责短期记忆,尤其是当前时间步的信息
这两个变量都随着时间步进行迭代。如上图所示,在迭代开始时,LSTM会同时初始化 h 0 h_0 h0和 C 0 C_0 C0;在任意时间步t上,记忆细胞会同时接受到来自上一个时间步的长期记忆 C t − 1 C_{t-1} Ct−1、短期信息 h t − 1 h_{t-1} ht−1以及当前时间步上输入的新信息 X t X_t Xt三个变量,结合三者进行运算后,记忆细胞会输出当前时间步上的长期记忆 C t C_{t} Ct和短期信息 h t h_{t} ht,并将它们传递到下一个时间步上。同时,在每个时间步上, h t h_t ht还会被传向当前时间步的输出层,用于计算当前时间步的预测值 y ^ t \hat{y}_t y^t 。
记忆细胞内部的处理流程

在记忆细胞内部,如果我们横向切割来看,分为上面传递长期记忆的C和下面传递短期记忆的h。如果纵向切割来看,可以如图所示分为遗忘门、输入门、输出门。
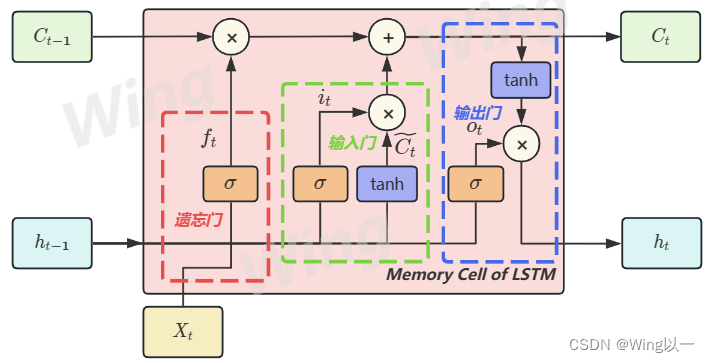
RNN使用同一套权重
LSTM将权重分割为历史信息、当前时间步信息、当前时间步最有效信息三类权重,分别对应:
- 输入门:解读新信息含义、判断有效性,并对新信息进行筛选纳入
- 遗忘门:判断长期信息是否有效,并对长期信息进行保护和筛选
- 输出门:判断对于当前时间步的预测最有效的信息,并将该信息输出
遗忘门
遗忘门是决定要留下多少长期信息C的关键计算单元,其数学本质是令一个时间步传入的
C
t
−
1
C_{t-1}
Ct−1乘以一个[0,1]之间的权重
f
t
f_t
ft,以此筛选掉部分旧信息。
在这个计算过程中,假设遗忘门赋予
C
t
−
1
C_{t-1}
Ct−1的权重为0.6,那就是说遗忘门决定了要保留60%的历史信息,遗忘40%的历史信息,这40%的信息空间就可以留给全新的信息来使用。
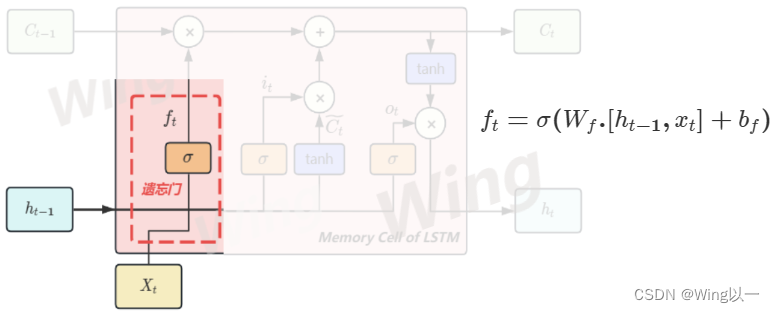
这个权重应该如何计算呢?
想要解决保留多少历史信息的问题,就需要综合考量上个时间步传来的信息
h
t
−
1
h_{t-1}
ht−1和当前信息
x
t
x_t
xt。上面的权重
W
f
W_f
Wf可以细化看作
W
f
x
W_{fx}
Wfx和
W
f
h
W_{fh}
Wfh,即如下公式:
f
t
=
σ
(
W
f
h
.
h
t
−
1
+
W
f
x
x
t
+
b
f
)
f_t=\sigma(W_{fh}.h_{t-1}+W_{fx}x_t+b_f)
ft=σ(Wfh.ht−1+Wfxxt+bf)
遗忘门会使用当前时间步的信息
x
t
x_t
xt与上一个时间步的短时信息
h
t
−
1
h_{t-1}
ht−1分别乘以对应的权重后,加上偏置项
b
f
b_f
bf来计算。套上
σ
\sigma
σ即sigmoid函数后,就会使得包含了“上一步”和“这一步”信息的整体,归一化到 [0,1] 之间 。
参数
w
f
w_f
wf会受到损失函数和算法整体表现的影响,不断调节遗忘门中计算出的权重f的大小,因此遗忘门能够结合上下文信息、损失函数传来的梯度信息、以及历史信息共同计算出全新的、被留下的长期记忆
C
t
C_t
Ct。
输入门
输入门是决定要吸纳多少新信息来融入长期记忆C的计算单元,其数学本质是为当前时间步传入的所有信息赋予一个[0,1]之间的权重,以筛选掉部分新信息,将剩余的新信息融入长期记忆C。
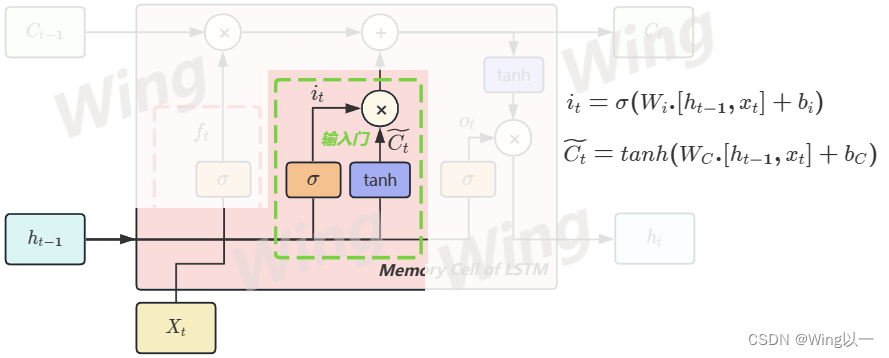
- 输入总信息
C
t
~
\tilde{C_t}
Ct~
首先要计算出当前时间步总共吸收了多少全新的信息 C ~ t \tilde{C}_t C~t,这个计算全新信息的方式就与RNN中计算 h t h_t ht的方式高度相似,因此也会包含用于影响新信息传递的参数 W C W_C WC和RNN中常见的tanh函数。 C t ~ = t a n h ( W C h . h t − 1 + W C x x t + b C ) \tilde{C_t}=tanh(W_{Ch}.h_{t-1}+W_{Cx}x_t+b_C) Ct~=tanh(WCh.ht−1+WCxxt+bC) - 然后,我们要依据上下文信息(依然是 X t X_t Xt和 h t − 1 h_{t-1} ht−1)以及参数 W i W_i Wi来生成筛选新信息的权重 i t i_t it。
- 最后我们将二者相乘,并加入到长期记忆 C C C当中。
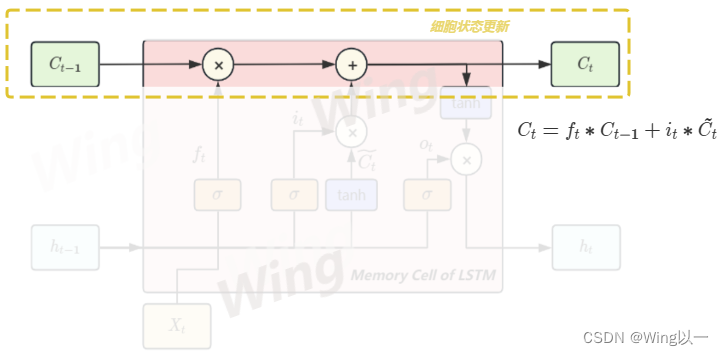
细胞状态更新
当遗忘门决定了哪些信息要被遗忘,输入门决定了哪些信息要被加入到长期记忆后,就可以更新用于控制长期记忆的细胞状态了。
如下图所示,上一个时间步的长期记忆将乘以遗忘门的权重,再加上新信息
C
~
t
\tilde{C}_t
C~t乘以新信息筛选的权重
i
t
i_t
it,同时考虑放弃过去的信息、容纳新信息,以此来构成传递给下一个时间步的长期信息
C
t
C_t
Ct,至此长期记忆
C
C
C完成了一次迭代。
输出门
输出门是从全新的长期信息
C
t
C_t
Ct中筛选出最适合当前时间步的短期信息
h
t
h_t
ht的计算单元,其数学本质是对已经计算好的长期信息
C
t
C_t
Ct赋予一个[0,1]之间的权重,以此筛选出对当前时间步最有效的信息用于当前时间步的预测。
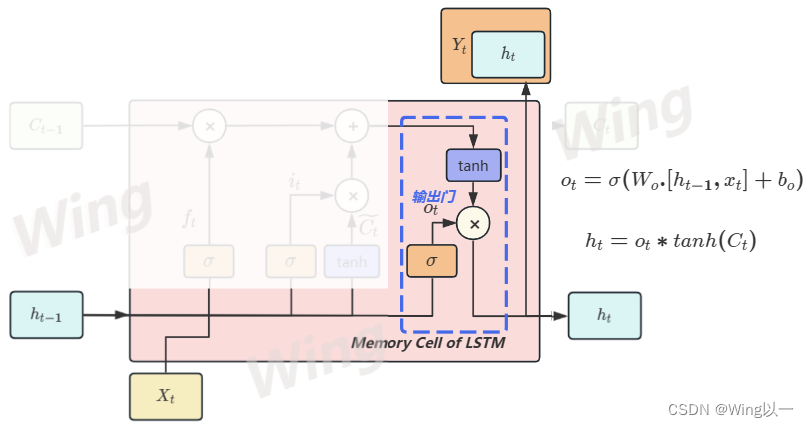
它判断多少信息对于当前时间步有用,同样需要两步:
- 借助上下文信息和参数
W
o
W_o
Wo来求解出权重
o
t
o_t
ot
o t = σ ( W o h . h t − 1 + W o x x t + b o ) o_t=\sigma(W_{oh}.h_{t-1}+W_{ox}x_t+b_o) ot=σ(Woh.ht−1+Woxxt+bo) - 长期信息
C
t
C_t
Ct进行tanh标准化处理后,乘以
o
t
o_t
ot,用于求解
h
t
h_t
ht
h t = o t ∗ t a n h ( C t ) h_t=o_t*tanh(C_t) ht=ot∗tanh(Ct)
输出门为什么有两个输出路径?
输出门中计算出的 h t h_t ht需要完成两项不同的职责任务:
1、进入整个LSTM的输出层 Y t Y_t Yt,负责生成预测标签 y ^ \hat y y^。来辅助计算损失函数。 在这个过程中,如果把 h t h_t ht计算 Y t Y_t Yt的权重调为0就相当于不输出当前步信息。
2、作为当前时间步上最有效的短期信息,进入下一个记忆细胞,来辅助下一个细胞状态的更新。
LSTM 分解参数来提升理解能力
在 RNN 中,每输入一步,每一层各自都共享参数 U,V,W。其反映着 RNN 中的每一步都在做相同的事,只是输入不同,因此大大地降低了网络中需要学习的参数,但也带来了其语义理解能力较差的问题。
RNN的迭代过程: h t = W h h . h t − 1 + W h x x t h_t=W_{hh}.h_{t-1}+W_{hx}x_t ht=Whh.ht−1+Whxxt
我们回顾一下上面LSTM的记忆细胞里迭代过程涉及的公式:
遗忘门中的保留比例:
f
t
=
σ
(
W
f
h
.
h
t
−
1
+
W
f
x
x
t
+
b
f
)
f_t=\sigma(W_{fh}.h_{t-1}+W_{fx}x_t+b_f)
ft=σ(Wfh.ht−1+Wfxxt+bf)
输入门中的纳入比例:
i
t
=
σ
(
W
i
h
.
h
t
−
1
+
W
i
x
x
t
+
b
i
)
i_t=\sigma(W_{ih}.h_{t-1}+W_{ix}x_t+b_i)
it=σ(Wih.ht−1+Wixxt+bi)
输入门中的输入总信息:
C
t
~
=
t
a
n
h
(
W
C
h
.
h
t
−
1
+
W
C
x
x
t
+
b
C
)
\tilde{C_t}=tanh(W_{Ch}.h_{t-1}+W_{Cx}x_t+b_C)
Ct~=tanh(WCh.ht−1+WCxxt+bC)
更新长期记忆:
C
t
=
f
t
∗
C
t
−
1
+
i
t
∗
C
t
~
C_t=f_t*C_{t-1}+i_t*\tilde{C_t}
Ct=ft∗Ct−1+it∗Ct~
输出门中的保留比例:
o
t
=
σ
(
W
o
h
.
h
t
−
1
+
W
o
x
x
t
+
b
o
)
o_t=\sigma(W_{oh}.h_{t-1}+W_{ox}x_t+b_o)
ot=σ(Woh.ht−1+Woxxt+bo)
输出门中的输出结果:
h
t
=
o
t
∗
t
a
n
h
(
C
t
)
h_t=o_t*tanh(C_t)
ht=ot∗tanh(Ct)
对比可以看出LSTM在迭代过程中可以调节的权重参数
W
W
W非常多,可以选择放大
W
i
x
W_{ix}
Wix或者
W
C
x
W_{Cx}
WCx来更多的存储新内容,也可以减小
W
f
x
W_{fx}
Wfx或者
W
f
h
W_{fh}
Wfh等来减少历史信息的保留。
具体如何选择,会由损失函数、当前时间点的信息
x
t
x_t
xt,以及上一个时间步上的短时记忆
h
t
−
1
h_{t-1}
ht−1共同决定,LSTM通常不会同时调节所有权重。


















 1590
1590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











