






目录
1 大数据概述
定义
- 狭义大数据:对海量数据进行处理的软件体系。
- 广义大数据:数字化、信息化时代的基础支撑。
5个特征
- Volume 体积
- Variety 种类
- Value 价值
- Velocity 速度
- Veracity 质量
大数据核心工作
- 数据存储:妥善保存海量待处理数据
- 数据计算:完成海量数据的价值挖掘
- 数据传输:协助各个环节的数据传输
2 大数据软件生态
大数据软件生态就是围绕大数据三大核心工作体系。
数据存储
- Apache Hadoop - HDFS:Apache Hadoop框架体系内的组件HDFS是大数据体系中使用最为广泛的分布式存储技术。
- Apache HBase:是大数据体系内使用非常广泛的NoSQL KV型数据库技术,是基于HDFS之上构建的。
- Apache KUDU:是大数据体系中使用较多的分布式存储引擎。
- 云平台存储组件:各大云平台厂商也有相应的大数据存储组件,如阿里云的OSS、UCloud的US3、AWS的S3、金山云的KS3等。
数据计算
- Apache Hadoop - MapReduce:该组件是最早一代的大数据分布式计算引擎。
- Apache Hive:是一款以SQL为首要开发语言的分布式计算框架,底层使用了Hadoop MapReduce技术,现在仍活跃在一线。
- Apache Spark:目前最火热的分布式内存计算引擎。
- Apache Flink:分布式内存计算引擎,适用于**实时计算(流计算)**领域,占据了国内大多数市场。
数据传输
- Apache Kafka:分布式消息系统,可以完成海量数据传输工作。
- Apache Pulsar:分布式消息系统。
- Apache Flume:流式数据采集工具,可以从非常多的数据源中完成数据采集传输任务。
- Apache Sqoop:ETL工具,可以协助大数据体系和关系型数据库之间的数据传输。
3 Hadoop
Hadoop是开源的技术框架,提供分布式存储、计算、资源调度的解决方案。
3.1 Hadoop组成
- HDFS组件:是Hadoop内的分布式存储组件,可以构建分布式文件系统用于数据存储。
- MapReduce组件:是Hadoop内分布式计算组件。提供分布式接口供用户开发分布式计算程序。
- YARN组件:是Hadoop内分布式资源调度组件,可供用户整体调度大规模集群的资源使用。
3.2 Hadoop HDFS 分布式文件系统
分布式调度架构模式
- 大数据体系中,分布式调度主要有两类架构模式: 去中心化模式和中心化模式。
- 去中心化模式:没有明确的中心,众多服务器之间基于特定规则进行同步协调。
- 中心化模式:大多数大数据框架一般都是符合中心化模式的。以一个中心节点(服务器) 为中心来统一调度多个节点(其他服务器),避免混乱。这也被称为一主多从(主从模式),Hadoop框架就是一个典型的主从模式。
定义
- 全称:Hadoop Distributed File System
- Hadoop技术栈内提供的分布式数据存储解决方案
- 可以在多台服务器上构建存储集群,存储海量数据
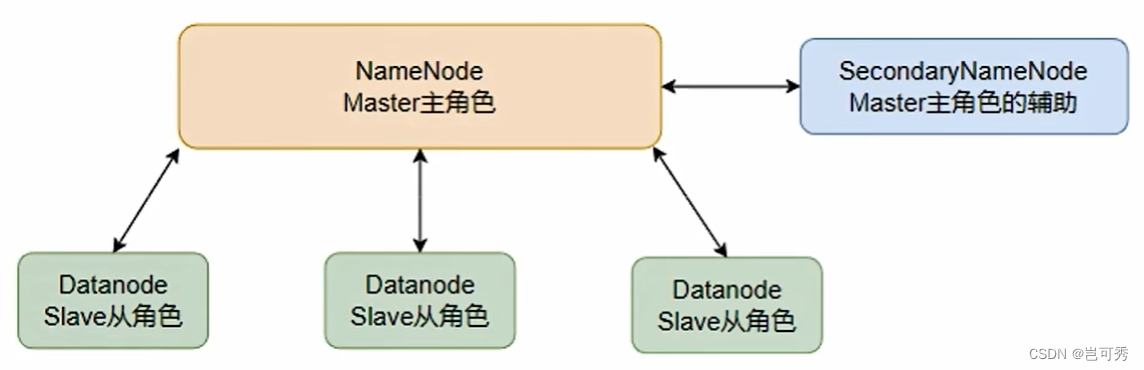
HDFS基础架构(主从模式)
- 主角色 NameNode:
- HDFS系统的主角色,是一个独立的进程
- 负责管理HDFS整个文件系统
- 负责管理DataNode
- 从角色 DataNode:
- HDFS系统的从角色,是一个独立进程
- 主要负责数据存储,即存入数据和取出数据
- 主角色辅助角色 SecondaryNameNode:
- NameNode的辅助,是一个独立进程
- 主要帮助NameNode完成元数据整理工作(打杂)
HDFS集群环境部署
- VMware虚拟机部署 https://www.bilibili.com/video/BV1WY4y197g7?p=22&vd_source=88202f7ef1a1571cd21e59c47d626387
- 云服务器部署 https://www.bilibili.com/video/BV1WY4y197g7?p=25
HDFS的Shell操作
(1)进程启停管理
- 一键启停脚本
- $HADOOP_HOME/sbin/start-dfs.sh,一键启动HDFS集群
- $HADOOP_HOME/sbin/stop-dfs.sh,一键关闭HDFS集群
- 单进程启停:单独控制进程的启停
- $HADOOP_HOME/sbin/hadoop-daemon.sh,单独控制所在机器的进程的启停。
hadoop-daemon.sh (start|status|stop) (namenode|secondarynamenode|datanode) - $HADOOP_HOME/bin/hdfs,单独控制所在机器的进程的启停。
hdfs --daemon (start|status|stop) (namenode|secondarynamenode|datanode)
- $HADOOP_HOME/sbin/hadoop-daemon.sh,单独控制所在机器的进程的启停。
(2)文件系统操作命令
- 文件系统基本信息:HDFS作为分布式存储的文件系统,有其对数据的路径表达方式。
HDFS同Linux系统一样,均是以/作为根目录的组织形式,区分方式如下,但是一般可以省略:Linux: file:/// file:///usr/local/hello.txt HDFS:hdfs://namenode:port/ hdfs://node1:8020/usr/local/hello.txt - 2套文件系统操作命令(用法完全一样)
- hadoop命令(老版本)
hadoop fs [generic options] - hdfs命令(新版本)
hdfs dfs [generic options]
- hadoop命令(老版本)
-
创建文件夹
hadoop fs -mkdir [-p] <path> ... hdfs dfs -mkdir [-p] <path> ...- path为待创建目录
-
查看指定目录下内容
hadoop fs -ls [-h] [-R] [<path> ...] hdfs dfs -ls [-h] [-R] [<path> ...]- path指定目录路径
- -h 人性化显示文件size
- -R 递归查看指定目录及其子目录
-
上传文件到HDFS指定目录下
hadoop fs -put [-f] [-p] <localsrc> ... <dst> hdfs dfs -put [-f] [-p] <localsrc> ... <dst>- -f 覆盖目标文件(已存在下)
- -p 保留访问和修改时间,所有权和权限
- localsrc 本地文件系统(客户端所在机器)
- dst 目标文件系统(HDFS)
-
查看HDFS文件内容
hadoop fs -cat <src> ... hdfs dfs -cat <src> ... # 读取大文件可以使用管道符配合more hadoop fs -cat <src> | more hdfs dfs -cat <src> | more -
下载HDFS文件到本地文件系统
hadoop fs -get [-f] [-p] <src> ... <localdst> hdfs dfs -get [-f] [-p] <src> ... <localdst>- -f 覆盖目标文件(已存在下)
- -p 保留访问和修改时间,所有权和权限
-
拷贝HDFS文件
hadoop fs -cp [-f] <src> ... <dst> hdfs dfs -get [-f] <src> ... <dst>- -f 覆盖目标文件(已存在下)
-
追加数据到HDFS文件
hadoop fs -appendToFile <localsrc> ... <dst> hdfs dfs -appendToFile <localsrc> ... <dst>- 将所有给定本地文件的内容追加到给定的dst文件中
- 如果dst文件不存在,将创建该文件
- 如果为-,则输入为从标准输入中读取。
-
HDFS数据移动操作
hdoop fs -mv <src> ... <dst> hdfs dfs -mv <src> ... <dst>- 移动文件到指定文件夹下
- 可以使用该命令移动数据,重命名文件的名称
-
HDFS数据删除
hadoop fs -rm -r [-skipTrash] URI [URI ...] hdfs dfs -rm -r [-skipTrash] URI [URI ...]- 删除指定路径的文件或文件夹
- -skipTrash 跳过回收站,直接删除
-
HDFS 权限
- HDFS中也是有权限控制的,其控制逻辑和Linux文件系统完全一致
- 但是Superuser(超级用户)不同:Linux的超级用户是root;而HDFS文件系统的超级用户是启动namenode的用户(即hadoop用户)
# 修改所属用户和组 hadoop fs -chown [-R] root:root /xxx.txt hdfs dfs -chown [-R] root:root /xxx.txt # 修改权限 hadoop fs -chmod [-R] 777 /xxx.txt hdfs dfs -chmod [-R] 777 /xxx.txt
(3)HDFS客户端 - Jetbrains产品插件
在Jetbrains产品中,均可以安装插件 Big Data Tools 来帮助我们方便地操作HDFS。
(4)HDFS客户端 - NFS
使用NFS网关功能将HDFS挂载到本地系统。
HDFS的存储原理
(1)存储原理
- 数据存入HDFS是分布式存储,即每个服务器节点,负责数据的一部分的一部分。
- 数据在HDFS上是划分为一个个Block块进行存储的。
- 在HDFS上,数据Block块可以有多个副本,提高数据安全性。
(2)fsck命令
- HDFS副本块数量配置:在每一台服务器中的hdfs-site.xml文件中修改,默认是3,一般情况下是不需要主动配置的。
- 除了配置文件,还可以在上传文件的时候临时修改以多少个副本存储。
hadoop fs -D dfs.replication=2 -put test.txt /tmp/ - 对于已经存在的HDFS文件,需要通过setrep命令来修改副本数量。
hadoop fs -setrep [-R] 2 path # -R表示递归,对子目录也生效 - fsck(file system check)命令检查文件的副本数
hdfs fsck path [-files [-blocks [-locations]]]
(3)NameNode元数据
- NameNode是基于一批edits和fsimage文件的配合完成整个文件系统的管理和维护
- edits文件:是一个流水账文件,记录了hdfs中每一次操作,以及本次操作影响的文件其对应的block
- fsimage文件:将全部edits文件合并得到一个fsimage文件
- NameNode基于edits和fsimage的配合,完成对整个系统文件的管理,即元数据管理维护:
- 每次对HDFS的操作均被edits文件记录
- edits达到大小上限后开启新的edits记录
- 定期进行edits合并操作:
- 如果当前没有fsimage文件,将全部edits合并成第一个fsimage
- 如果当前已存在fsimage文件,将全部edits和已存在的fsimage进行合并,形成新的fsimage
- 重复123流程
- 元数据合并控制参数:
- 对于元数据的合并是基于以下两个条件达到一个就执行:
- dfs.namenode.checkpoint.period,默认3600s即1小时
- dfs.namenode.checkpoint.txns,默认1000000,即100w次事务
- 检查是否达到条件,默认60s检查一次,基于:
- dfs.namenode.checkpoint.check.period,默认60s来决定
- 对于元数据的合并是基于以下两个条件达到一个就执行:
- SecondaryNameNode的作用:合并元数据,通过http从NameNode拉取数据(edits和fsimage)然后合并完成提供给NameNode使用。
(4)HDFS数据的读写流程
- 数据写入流程
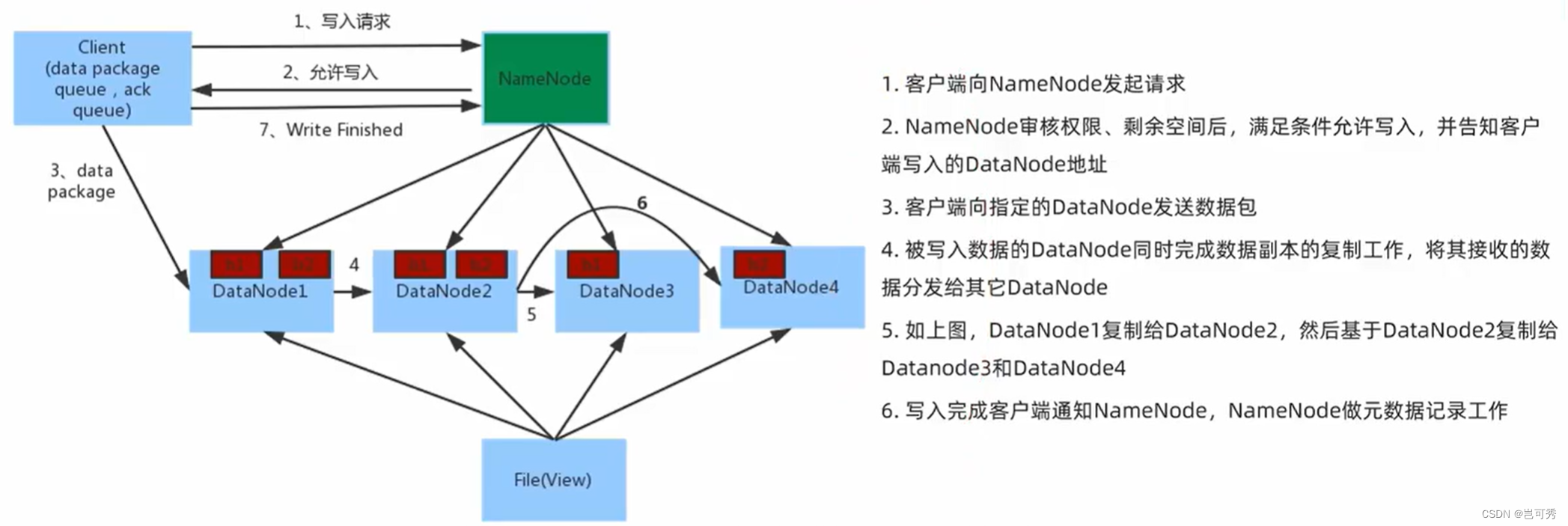
- NameNode不负责数据写入,只负责元数据记录和权限审批
- 客户端直接向一台DataNode写数据,这个DataNode一般是离客户端**最近(网络距离)**的那一个
- 数据块副本的复制工作,由DataNode之间自行完成(PipeLine)
- 数据读取流程
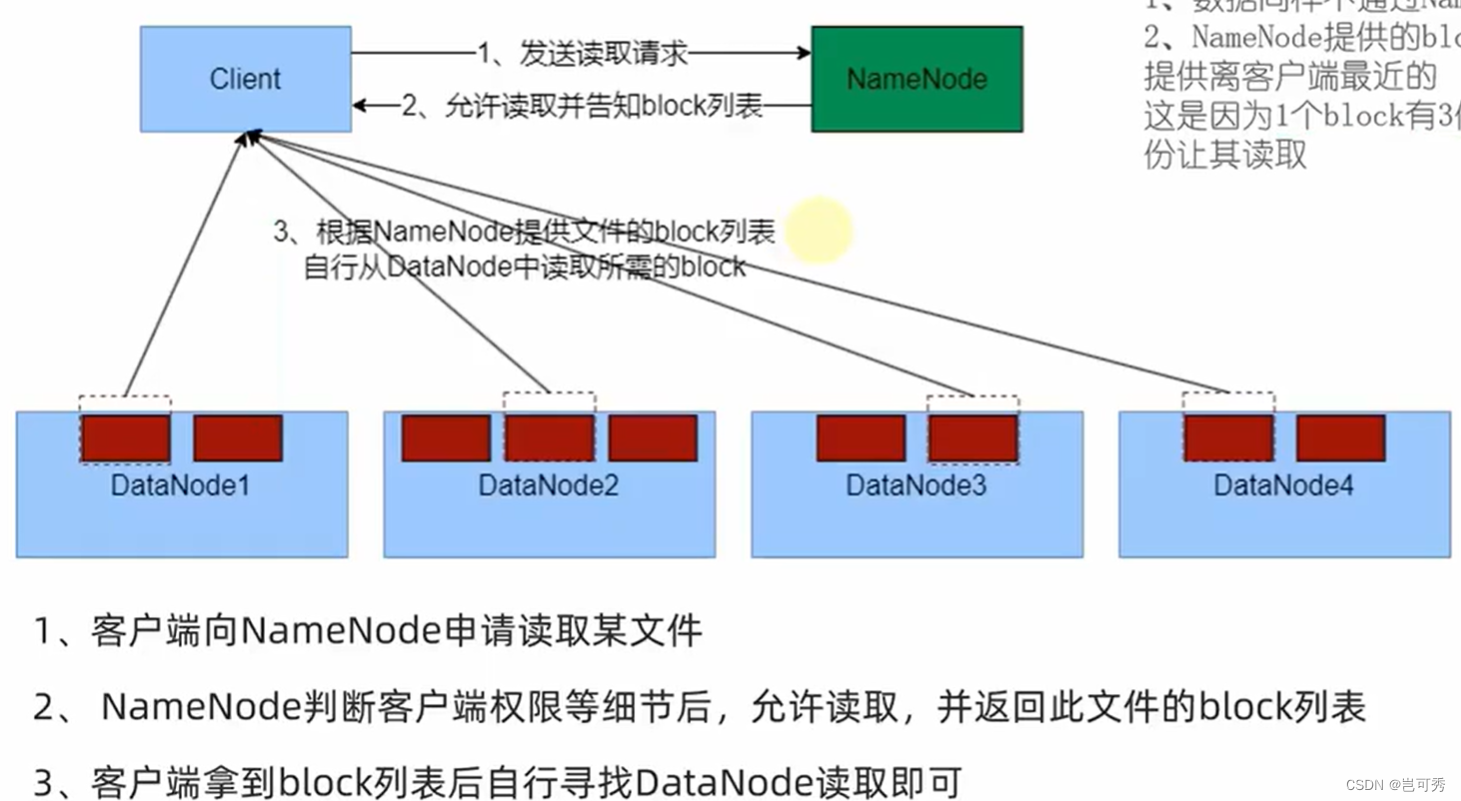
- 数据同样不是通过NameNode提供
- NameNode提供block列表,会基于网络距离计算尽量提供离客户最近的
3.3 MapReduce分布式计算和YARN分布式资源调度
分布式计算概述
- 计算和分布式计算
- 计算:对数据进行处理,使用统计分析等手段得到结果
- 分布式计算:多台服务器协同工作,共同完成一个计算任务
- 分布式计算模式
- 分散->汇总模式(MapReduce):
- 将数据分片,多台服务器各自负责一部分数据处理
- 然后将各自的结果进行汇总处理
- 最终得到想要的计算结果
- 中心调度->步骤执行模式(Spark、Flink)
- 由一个节点作为中心调度管理者
- 将任务划分为几个具体步骤
- 管理者安排每个机器执行任务
- 最终得到结果数据
- 分散->汇总模式(MapReduce):
MapReduce概述
- 什么是MapReduce
- MapReduce是Hadoop内提供的分布式计算的组件
- MapReduce是以分散->汇总模式来执行分布式任务的
- MapReduce的主要编程接口(功能):
- map接口:主要提供分散功能,由服务器分布式处理数据
- reduce接口:主要提供汇总功能,进行数据汇总统计得到结果
- MapReduce运行机制
- 将要执行的需求分解为多个Map Task和Reduce Task
- 将Map Task和Reduce Task分配到对应的服务器去执行
YARN概述
- 什么是MapReduce
- YARN是Hadoop内提供的分布式资源调度的组件
- YARN用于做集群资源(CPU、内存)的调度
- 为什么需要资源调度:将资源统一管控可以提高资源利用率
- 程序如何在YARN内运行:
- 程序向YARN申请所需资源
- YARN为程序分配所需资源供程序使用
- MapReduce和YARN的关系:
- YARN用来调度资源给MapReduce分配和管理运行资源
- 因此一般来说,MapReduce需要YARN才能执行
YARN架构
核心架构
- 主从架构:
- 主(Master)ResourceManager:整个集群的资源调度者
- 从(Slave)NodeManager:单个服务器的资源调度者,即创建容器、由容器提供资源供程序使用
- YARN容器
- 容器(Container)是YARN的NodeManager在所属服务器上分配资源的手段
- 创建一个资源容器,由NodeManager占用这部分资源
- 然后应用程序运行在NodeManager创建的这个容器内
- 应用程序无法突破容器的资源限制
辅助架构
- YARN还可以搭配两个辅助角色使得YARN集群运行更加稳定
- 代理服务器(ProxyServer):Web Application Proxy Web应用程序代理
- 是YARN的一部分,默认将作为资源管理器(RM)的一部分运行,但可以配置为在独立模式下运行。使用代理的原因是为了减少通过YARN进行基于网络攻击的可能。
- YARN在运行时会对外提供一个web UI站点供用户在浏览器查看YARN的运行信息,那就可能会有安全性问题,代理服务器最大的功能就是保障web UI的访问是安全的。
- 历史服务器(JobHistoryServer):应用程序历史信息记录服务
- 提供web UI站点供用户在浏览器上查看程序日志
- 可以保留历史数据随时查看历史运行程序信息
- 代理服务器(ProxyServer):Web Application Proxy Web应用程序代理
MapReduce & YARN部署

MapReduce & YARN初体验
4 Apache Hive
4.1 Hive概述
- Apache Hive是一款分布式SQL计算的工具,主要功能是:
- 将SQL语句翻译成MapReduce程序运行
- 即写的是SQL,跑的是MapReduce
- 使用Hive的好处:
- 操作接口采用类SQL语法,不需要使用Python/Java,快速开发
- 底层执行MapReduce,完成分布式海量数据的SQL处理
4.2 Hive基础架构
- 基于MR程序的分布式SQL执行引擎需要两大功能组件:元数据存储和SQL解析器。
- Hive包含以下三个组件:
- 元数据管理:Metastore服务,通常存储在关系型数据库中。Hive中的元数据包括表名、表的列和分区及其属性、表属性(是否为外部表)、表的数据所在目录等。
- Driver驱动程序,包括语法解析器、计划编译器、优化器、执行器:完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。
- 用户接口:包括CLI(shell命令行)、JDBC/ODBC(数据库连接的API)、WebGUI(浏览器)。
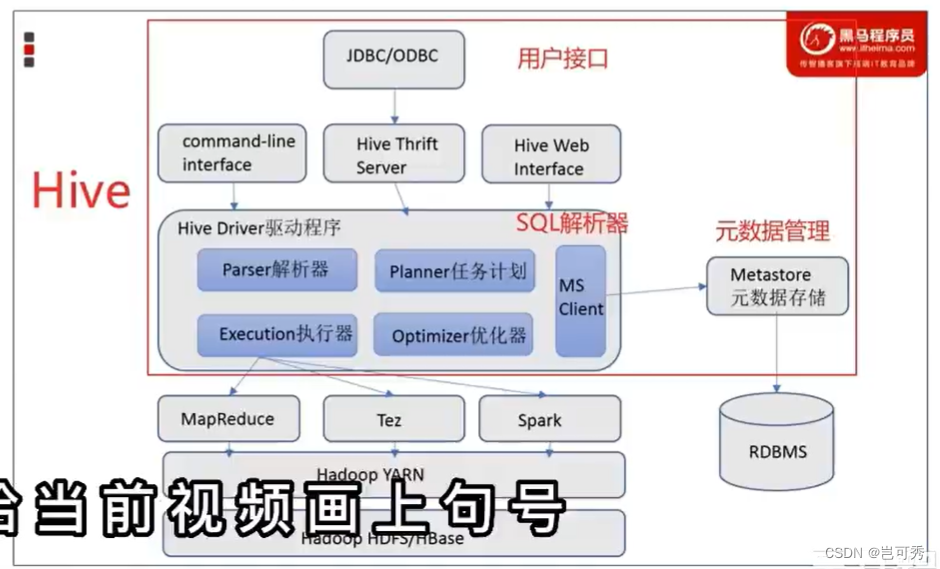
Hive部署
Hive初体验
- Hive中可以使用类SQL语法完成基本库、表的插入、查询等操作
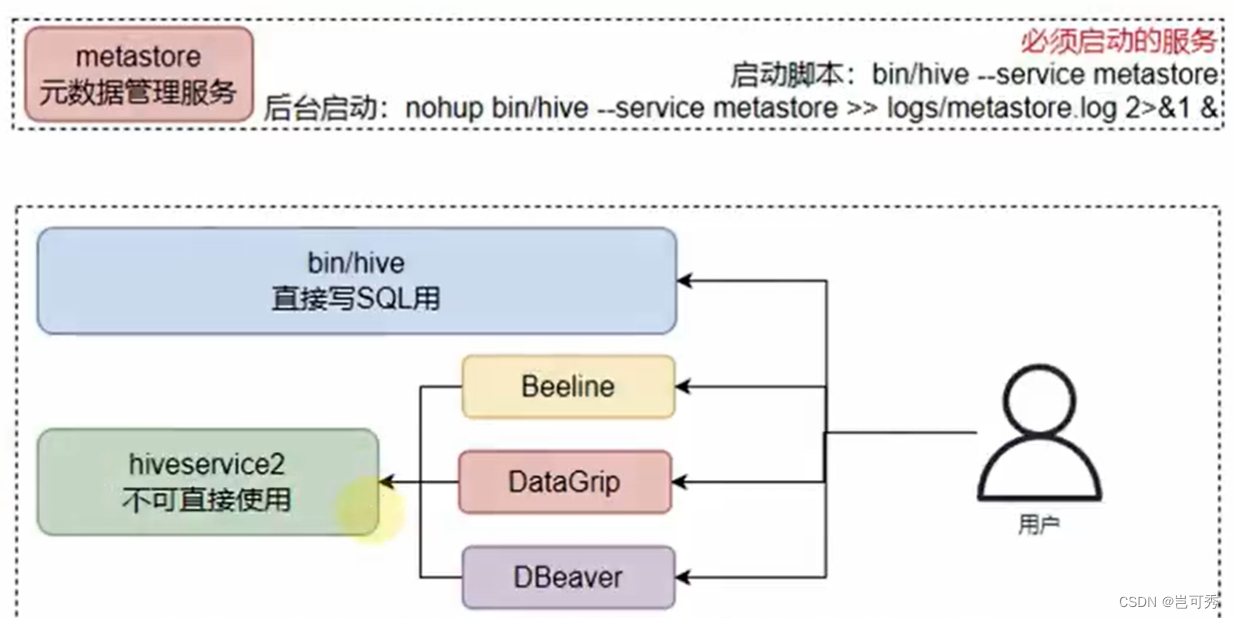
- 首先确保启动了Metastore服务
- 执行bin/hive文件,进入到Hive Shell环境中来执行SQL语句
- 创建表:
create table test(id int, name string, gender string); - 插入数据:
insert into test values(1,'王力宏','男'), (2,'周杰伦','男'), (3,'林俊杰','女'),; - 查询数据:
select gender count(*) as cnt from test group by gender;
- 通过YARN WEB UI界面(http://node1:8088)可以看到,Hive是将SQL翻译成MapReduce程序运行在YARN
- 在Hive中创建的库和表的数据存储在HDFS中,默认存放在hdfs://node1:8020/user/hive/warehouse
Hive客户端
- Hive客户端体系
- 执行:bin/hive,这是Hive提供的Shell环境,可以直接写SQL执行
- 启动HiveServer2,bin/hive --service hiveserver2,这是Hive的Thrift服务,对外提供接口(默认10000端口),可供其他客户端连接,如bin/beenline(内置),DataDrip(第三方)、DBeaver(第三方)














 1093
1093











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









