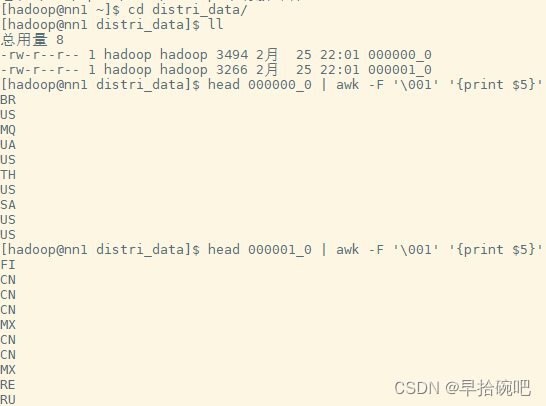
set mapred.reduce.tasks=2;insert overwrite local directory '/home/hadoop/distri_data'select*from user_install_status_limit distribute by country sort;-- 相同hashcode的国家名分到同一个reducer文件中.
cluster by
cluster by column= distribute by column + sort by column(必须是相同的column才能相等,否则distribute by和sort by 要各自指定列),
即:又分桶又进行内部排序.cluster by可以保证组内有序.
注意,都是针对column列,且采用默认ASC(升序),不能指定排序规则为asc或者desc.
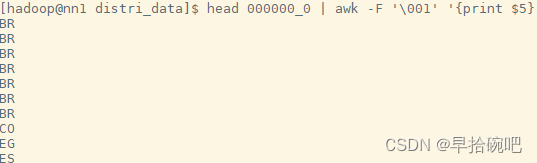
set mapred.reduce.tasks=2;insert overwrite local directory '/home/hadoop/cluster_data'select*from user_install_status_limit cluster by country;--等于insert overwrite local directory '/home/hadoop/cluster_data'select*from user_install_status_limit distribute by country sort by country;
实现降序
需要用distribute by and sort by 组合的方式,
在创建桶表的语法中clustered by桶内是否有序要根据sort by决定.
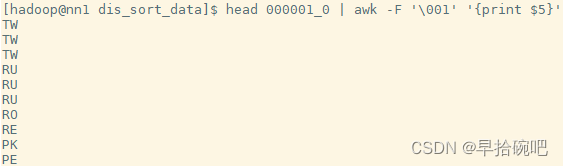
set mapred.reduce.tasks=2;insert overwrite local directory '/home/hadoop/dis_sort_data'select*from user_install_status_limit distribute by country sort by country desc;
























 876
876

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











