






代码在pycharm项目ASRT种
1. huafen_txt.py
按比例划分数据集为train,test,dev
# train/val/test = 8/1/1
# encoding: utf-8
import os
import random
def ran_split(full_list, shuffle=False, ratio1=0.8, ratio2=0.1):
sublists = []
n_total = len(full_list)
offset1 = int(n_total * ratio1)
offset2 = int(n_total * ratio2) + offset1
if n_total == 0 or offset1 < 1:
return [], full_list
if shuffle:
random.shuffle(full_list) # 打乱排序
sublist_1 = full_list[:offset1]
sublist_2 = full_list[offset1:offset2]
sublist_3 = full_list[offset2:]
sublists.append(sublist_1)
sublists.append(sublist_2)
sublists.append(sublist_3)
return sublists # sublists=[sublist_1,sublist_2,sublist_3]
def read_file(filepath):
file_list = []
with open(filepath, 'r') as fr:
data = fr.readlines()
data = ''.join(data).strip('\n').splitlines()
# ''.join() list转为str
# s.strip(rm) 删除s中开头结尾处的rm字符
# .splitlines() 将字符串返回列表
file_list = data
return file_list
def write_file(dst1, txt):
fo = open(dst1, 'w')
for item in txt:
fo.write(str(item) + '\n')
if __name__ == "__main__":
root_path = r'F:\all_date\WHU'
from_txt = 'file.txt'
txts = ['train.txt', 'test.txt', 'val.txt']
from_path = os.path.join(root_path, from_txt)
txt_list = read_file(from_path)
sublists = ran_split(txt_list, shuffle=True, ratio1=0.8, ratio2=0.1)
# 注:生成的sublist数量与txts数量相同
for txt_name, i in zip(txts, range(len(txts))):
to_path = os.path.join(root_path, txt_name)
write_file(to_path, sublists[i])2.批量修改后缀名
import os
# 这是你需要修改文件的路径地址
filePath = r"E:\SpeechData\ChessSpeech\Download\trainlisttxt"
def update(filePath):
# listdir:返回指定的文件夹包含的文件或文件夹的名字的列表
files = os.listdir(filePath)
for file in files:
fileName = filePath + os.sep + file
path1 = filePath
# 运用递归;isdir:判断某一路径是否为目录
if os.path.isdir(fileName):
update(fileName)
continue
else:
if file.endswith('.wav.trn'):
test = file.replace(".wav.trn", ".txt")
print("修改前:" + path1 + os.sep + file)
print("修改后:" + path1 + os.sep + test)
os.renames(path1 + os.sep + file, path1 + os.sep + test)
if __name__ == '__main__':
update(filePath)
3.划分数据
按照对应的的标签文件,把data文件夹中对应的文件分别复制到train,test,dev文件夹中
# -*- coding:utf-8 -*-
import shutil
import os
oldpath = 'E:\SpeechData\ChessSpeech\Download\data' # 原数据路径
newpath = 'E:\SpeechData\ChessSpeech\Download\dev' # 移动到新文件夹的路径
file_path = 'random_8500.txt' # txt中指定移动文件的文件信息
#从文件中获取要拷贝的文件的信息
def get_filename_from_txt(file):
filename_lists = []
with open(file,'r',encoding='utf-8') as f:
lists = f.readlines()
for list in lists:
filename_lists.append(str(list).strip('\n')+'.wav') /.wav.trn
return filename_lists
#拷贝文件到新的文件夹中
def mycopy(srcpath,dstpath,filename):
if not os.path.exists(srcpath):
print("srcpath not exist!")
if not os.path.exists(dstpath):
print("dstpath not exist!")
for root,dirs,files in os.walk(srcpath,True):
if filename in files:
# 如果存在就拷贝
shutil.copy(os.path.join(root,filename),dstpath)
else:
# 不存在的话将文件信息打印出来
print(filename)
if __name__ == "__main__":
#执行获取文件信息的程序
filename_lists = get_filename_from_txt(file_path)
#根据获取的信息进行遍历输出
for filename in filename_lists:
mycopy(oldpath,newpath,filename)
txt中是对应的名字(不含后缀,后缀在代码中写如.wav .trn)
4.获取所有txt文件的文件名
# P02 批量读取文件名(不带后缀)
import os
file_path = "E:\\SpeechData\\ChessSpeech\\Download\\批量操作获取trn内容\\trainlisttxt\\"
path_list = os.listdir(file_path) # os.listdir(file)会历遍文件夹内的文件并返回一个列表
print(path_list)
path_name = [] # 把文件列表写入save.txt中
def saveList(pathName):
for file_name in pathName:
with open("train_txt_name.txt", "a") as f:
f.write(file_name.split(".")[0] + "\n")
def dirList(path_list):
for i in range(0, len(path_list)):
path = os.path.join(file_path, path_list[i])
if os.path.isdir(path):
saveList(os.listdir(path))
dirList(path_list)
saveList(path_list)
5.批量修改文件名(具体看我的收藏-数据)
import os #导入模块
filename = 'E:\\SpeechData\\ChessSpeech\\Download\\新建文件夹' #文件地址
list_path = os.listdir(filename) #读取文件夹里面的名字
for index in list_path: #list_path返回的是一个列表 通过for循环遍历提取元素
name = index.split('.')[0] #split字符串分割的方法 , 分割之后是返回的列表 索引取第一个元素[0]
kid = index.split('.')[-1] #[-1] 取最后一个
path = filename + '\\' + index
new_path = filename + '\\' + name + 'white.wav.trn' + '.'
os.rename(path, new_path) #重新命名
print('修改完成')type *.txt >>E:\SpeechData\ChessSpeech\Download\data_3\devtrn\merge.txt
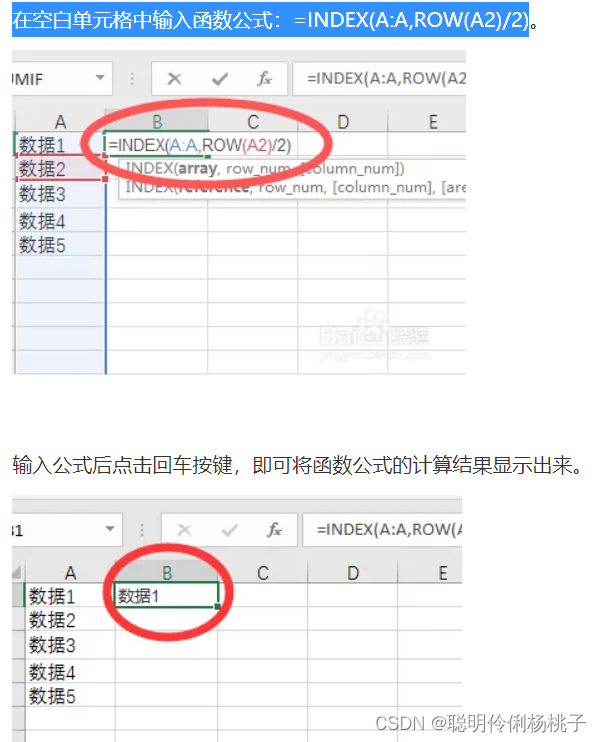
6.excel每一行复制成2行
在空白单元格中输入函数公式:=INDEX(A:A,ROW(A2)/2)
7.ASRT utils audio_modify.py
批量修改音频文件(采样率、格式、通道数等)
python audio_modify.py --audio_dir="E:\SpeechData\ChessSpeech\Download\qyt_data\mp3" --out_dir="E:\SpeechData\ChessSpeech\Download\qyt_data\wav" --audio_postfixes=.mp3 --sample_rate=16000 --channels=2 --format=wav















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









