






前几天帮助室友搞定bug的时候,出现了一个Scanner读取中文乱码的问题。
问题描述如下:使用Scanner读取从windows的cmd窗口中的中文的时候出现乱码。
问题代码如下:
import java.util.Scanner;
public class Test{
public static void main(String[] args){
Scanner sc = new Scanner(System.in);
String line = sc.next();
System.out.println(line);
System.out.println("销售经理");
}
}问题截图:
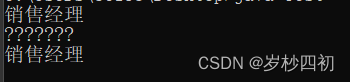
分析原因:这个乍一看就是个编码解码字符集不一致导致的乱码问题嘛。
但是,仔细想想,这到底是个怎样的过程呢?而且这个问题不是一定会发生的,比如在我室友的电脑上就会乱码,但是到我自己的电脑上就不乱码了。所以这里面一定有古怪!
经过我多方走访资料,发现,主要问题是出在windows的cmd窗口的编码字符集和jvm本身默认的解码字符集不一致导致的乱码。
大家想想,Scanner(System.in)是从控制台读取字节流的,那么将中文字符转换为字节流是谁来完成的呢?当然是由你输入的控制台来完成的啦。
所以我们就需要搞清楚cmd窗口的编码集和jvm本身的解码集(其实编码和解码都是一个字符集,这里只是为了更清楚的描述这个过程)。
我们可以使用这样一组过程来查看cmd窗口字符集:
查看当前windows字符集
开始--》运行---》cmd----》
键入:chcp
活动的代码页:936
在命令提示符的“菜单”上,右击-----》属性----》当前代码页 936(ANSI/OEM -简体中文GBK)。
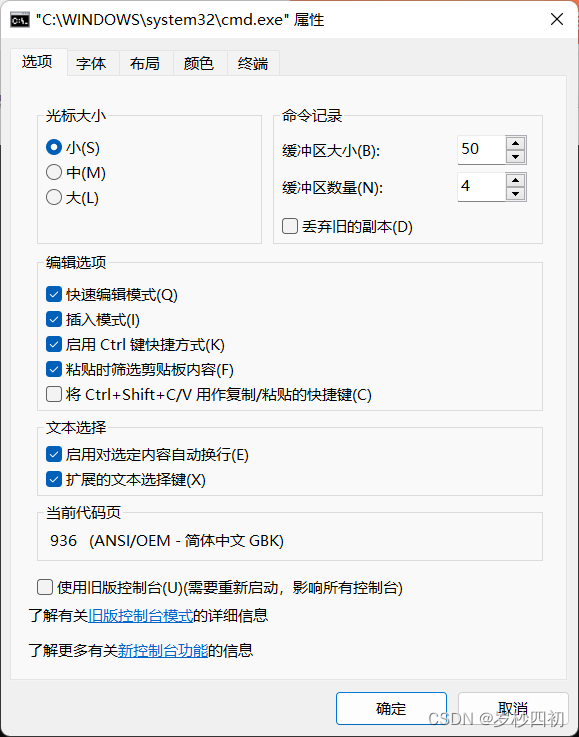
然后可以通过这样一组过程来查看jvm的字符集:
可以使用System.out.println(Charset.defaultCharset());来查看jvm默认的字符集。
这里我是放到idea上测了,不过效果是一样的,都是控制台编码,scanner解码。测试代码如下:
import java.util.Scanner;
import java.lang.Exception;
import java.nio.charset.Charset;
public class Test{
public static void main(String[] args){
//第一种方法测试
Scanner sc1 = new Scanner(System.in, "GBK");//修改Scanner转换字节流到字符的解码集
String text1 = sc1.next();
System.out.println(text1);
//第二种方法测试,结合上面代码的结果可以看出,确实是由控制台编码-》字节流-》Scanner读入字节流-》Scanner解码成字符串
Scanner sc = new Scanner(System.in);
try {
String next = sc.next();
System.out.println(next);
String line = new String(next.getBytes("utf-8"), "GBK");
System.out.println(line);
} catch (Exception e) {
e.printStackTrace();
}
}
}
第二种方法在我室友电脑上测试的时候发现依旧乱码,一开始我以为我思路错了,但是我不是很能接受,最后我终于在一个博主的文章中找到了答案。
java中的编码转换(以utf8和gbk为例)_请叫我徐先生的博客-CSDN博客_java中文编码转换方法
用GBK编码成的字节流,只能通过GBK解码回来,不能通过一次utf-8编码解码转换回来。
以本文为例:cmd窗口将“销售经理”用GBK编码成字节流,然后Scanner读取字节流,如果jvm是utf-8字符集,那么Scanner将默认使用utf-8解码,这时候sc.next()得到的数据就是乱码的。那我一开始的想法就是使用String.getBytes("utf-8")方法将这个字符串在转换为字节数组,再用GBK的字符集解码得到正确字符。
可惜理想很丰满,现实很骨感。因为utf-8是三个字节去存储一个中文字符的,而GBK是以两个字节去存储中文字符的,那么“销售经理”一开始就被cmd窗口使用GBK转换成了8个字节长度的字节流了,那么Scanner又使用utf-8解码,那么它三个字节三个字节的转换,那么就肯定不会得到四个中文字符,那么无论它是得到两个中文字符还是三个中文字符(因为我没有仔细去找如果使用utf-8读取字节不够三个会怎么样),最后转换成字节再用GBK编码肯定是无法得到原来的字符的。
总结:
其实乱码的根本原因就是编码与解码的时候采用的字符集不一致导致的,所以出现这种问题,最根本的解决办法就是搞清楚这个过程是怎样编码和解码的,找到关键的两个过程对应的平台,查看他们的字符集,再对症下药!
用啥编码就用啥解码,就肯定没问题了。
这里记录一些我在寻找答案的过程中一个知识点:
unicode是一种字符编码,让每个字符和一个数字对应起来,仅此而已,至于这个数字如何存储它就不管了。
utf8就是定义了如何具体存储这个编码数字的一种方法。(当然,计算机有多种存储方式,还有utf-16,utf-32等存储格式)















 2219
2219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









