






1.首先可以问大家一个问题:Java中的char类型是占用几个字节?
ok,占用两个字节。那接着请问大家知道为什么吗?
寻根溯源,这其实是一个历史原因,因为早期计算机发展的时候是只有美国在用,对于字符如何转换成计算机可以识别的二进制数据的字符编码标准也是美国指定的,也就是我们熟知的Ascii码。但是随着计算机的普及化,大量国家都纷纷开始指定自己的编码标准,比如咱们中国的GBK,西欧的ISO8859-1;
如果任由各个国家这么发展下去,那么计算机世界将会充斥着大量的方言和俗语,极大的阻碍了计算机之间的交流。最经典的就是臭名昭著的乱码问题。
所以就有了Unicode,简称万国码,其实就是一个统一的标准,这个很好理解。
不过在1991年发布的Unicode1.0认为两个字节的代码宽度足以对世界上各种语言的所有字符进行编码, 并有足够的空间留给未来的扩展。碰巧1991年,java也在设计的萌芽期,当时Java就采用了16位的Unicode字符集,而char类型的本意是用来表示一个字符,所以它自然也就设计成了2个字节。
但是由于时代的发展,经过一段时间, 不可避免的事情发生了。Unicode 字符超过了 65536 个,其
主要原因是增加了大量的汉语、 日语和韩语中的表意文字。那么,16 位的 char 类型已经不能满足描述所有 Unicode 字符的需要了。
2.好了,上面讲清楚了为啥char占用两个字节,那么现在我们来解决一下这个char类型不能表示所有Unicode字符的问题?
首先我们来介绍两个概念:
- 码点。码点( code point) 是指与一个编码表中的某个字符对应的代码值。很好理解吧
- 代码单元,简称码元。Unicode 的码点可以分成 17 个代码级别。第一个代码级别称为基本的多语言级别, 码点从 U+0000 到 U+FFFF, 其中包括经典的 Unicode 代码;其余的 16个级别码点从 U+10000 到 U+10FFFF , 其中包括一些辅助字符。而在UTF-16编码中,在基本的多语言级别中,每个字符用 16 位表示,通常被称为代码单元( code unit); 而辅助字符采用一对连续的代码单元进行编码。
好的,我知道很长,不好理解对吧。简单来说,代码单元就是英语里的字母,码点就是英语单词。
ok,知道这两个概念之后,我们可以发现其实java里的char类型,其实表示就是一个代码单元。它已经不是曾经的它,而我们也不是曾经的我们了。
而且具体来说,在 Java 中,char 类型描述了 UTF-16 编码中的一个代码单元。通过两个连续代码单元就可以解决上面我们提出的问题了。
这里插播一下:知道这个码元的概念对我们实际敲代码有什么帮助呢?
一段感人肺腑的发言
确实,我得承认,帮助不大,但是为什么人们要去攀登珠穆朗玛峰呢?因为它就在那里啊!追求知识的过程本身不也是一种幸福吗?
而且帮助还是有的,比如我得告诉你String类的length 方法将返回采用 UTF-16 编码表示的给定字符串所需要的代码单元数量。例如:String greeting = "Hello"; int n = greeting.length。; // is 5 .要想得到实际的长度,即码点数量,可以调用:
int cpCount = greeting.codePointCount(0, greeting.lengthQ);调用 s.charAt(n) 将返回位置 n 的代码单元,n 介于 0 ~ s.length()-l 之间。例如:
char first = greeting.charAtO); // first is 'H' char last = greeting.charAt(4); // last is ’o’要想得到第 i 个码点,应该使用下列语句
int index = greeting.offsetByCodePoints(0, i); int cp = greeting.codePointAt(index);而且更恐怖的是对于下面这个字符串:
⑪ is the set of octonions使用 UTF-16 编码表示字符⑪(U+1D546) 需要两个代码单元。调用
char ch = sentence.charAt(1)
返回的不是一个空格,而是⑪的第二个代码单元。为了避免这个问题,《Java核心技术卷Ⅰ》强烈建议我们不要使用 char 类型。这太底层了。
3.不过!好好好,这么玩是吧?不理解了,为啥又说是UTF-16编码的代码单元了,这个UTF-16又是什么鬼?和大名鼎鼎的UTF-8又是什么关系?
OK,刚刚我们一直讲的Unicode编码标准,其实它只是制定了每一个字符对应的二进制数据,但是,它没有给出如何存储这些二进制数据的解决方案。
就比如前面提到, Unicode 字符集的编码范围是 0x0000 - 0x10FFFF,因此需要 1 到 3 个字节来表示
那么,对于三个字节的 Unicode字符,计算机怎么知道它表示的是一个字符而不是三个字符呢 ?
如果所有字符都用三个字节表示,那么对于那些一个字节就能表示的字符来说,有两个字节是无意义的,对于存储来说,这是极大的浪费,假如 , 一个普通的文本, 大部分字符都只需一个字节就能表示,现在如果需要三个字节才能表示,文本的大小会大出三倍左右。
于是解决方案出现了,也就是Unicode的对应实现:那就是UTF。
"UTF" 是 "Unicode Transformation Format" 的缩写,意思是"Unicode 转换格式",后面的数字表明至少使用多少个比特位来存储字符, 同时也是表示该实现方案的码元是多少位的。比如:UTF-8 最少需要8个比特位也就是一个字节来存储,同时表示UTF-8的码元就是一个字节的;对应的, UTF-16 和 UTF-32 分别需要最少 2 个字节 和 4 个字节来存储。(具体的编码规则我就不介绍了,感兴趣的可以自行百度)
而Java虚拟机也就是使用的UTF-16 Big Endian的编码方案来实现编码的。
4.真是母猪戴胸罩,一套又一套啊!哪里又跑出来个Big Endian哦,造孽啊!好吧,做人做到底,送佛送到西,咱们继续往下挖。
这里需要介绍一个字节序的概念:
最小编码单元是多字节才会有字节序的问题存在,UTF-8 最小编码单元是一字节,所以 它是没有字节序的问题,UTF-16 最小编码单元是 2 个字节,在解析一个 UTF-16 字符之前,需要读入两个字节去解析,因此需要知道每个编码单元的字节序。
比如:前面提到过,"中" 字的 Unicode 码是 4E2D, "ⵎ" 字符的 Unicode 码是 2D4E, 当我们收到一个 UTF-16 字节流 4E2D 时,计算机如何识别它表示的是字符 "中" 还是 字符 "ⵎ" 呢 ?
这里可能很多人想当然的认为直接把4E2D的二进制和2D4E的二进制根本不一样啊,怎么会不能识别呢?
呐呐呐,没有将心比心了吧?计算机能有你这么聪明吗?计算机得先把数据存到内存里再进行后续操作吧?
那么这个内存读写的过程中,多字节就牵扯到一个存储的问题。
- 大端模式:低位字节排放在内存中的高位地址,高位字节排放在内存中的低位地址。
- 小端模式:低位字节排放在内存中的低位地址,高位字节排放在内存中的高位地址。
以0x4E2D为例来说明大端和小端,具体参见下图:
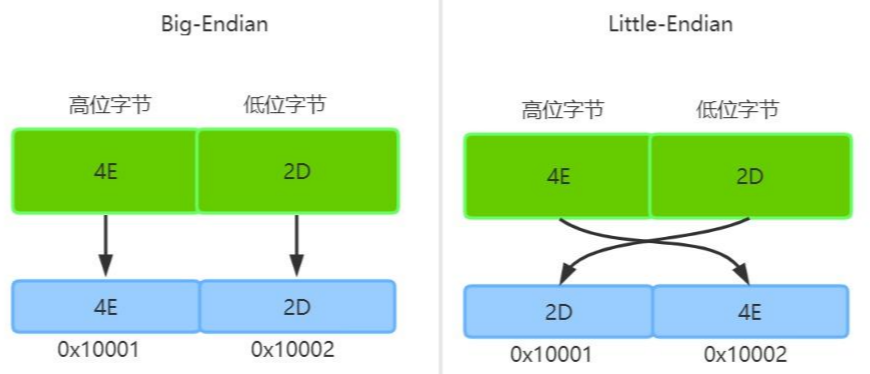
首先需要声明的是,这里内存读取顺序是从低地址到高地址,于是由于存储的字节序不同,计算机读取的字节结果就是4E2D(大端序)或者2D4E(小端序)。
所以,对于多字节的编码单元,需要有一个标记显式的告诉计算机,按照什么样的顺序解析字符,也就是字节序。(至于为什么计算机不都采用大端序这种人类易懂存储方式呢?这个似乎是小端序性能更高的缘故吧,和底层cpu硬件有关,不过现在差距已经不大了,有兴趣自行百度)
又来了,那么这个标记叫什么呢?
没错,这个标记就叫BOM,是不是之前在文本编辑器里见过这个东西,但是又不知道是啥?
BOM 是 byte-order mark 的缩写,是 "字节序标记" 的意思, 它常被用来当做标识文件是以 UTF-8、UTF-16 或 UTF-32 编码的标记。
在 Unicode 编码中有一个叫做 "零宽度非换行空格" 的字符 ( ZERO WIDTH NO-BREAK SPACE ), 用字符 FEFF来表示。通常是以这个字符来做BOM标记的。
因为在读取文件是按照低地址到高地址的顺序,所以如果读取到0xFEFF则说明该文件是采用大端模式来储存的;如果读取到0xFFFE则说明文件是采用小端模式来存储的。
UTF-8 没有字节序问题,上述字符只是用来标识它是 UTF-8 文件,而不是用来说明字节顺序的。"零宽度非换行空格" 字符 的 UTF-8 编码是 EF BB BF, 所以如果接收到以 EF BB BF 开头的字节流,就知道这是UTF-8 文件。
5.ok,最后再提三点吧
- Java文件的编码可能有多种多样,但 Java编译器会自动将这些编码按照Java文件的编码格式正确读取后产生class文件 , 这里的class文件编码是Unicode编码(具体说是UTF-16be编码)。
因此,在Java代码中定义一个字符串:
String s="汉字";
不管在编译前java文件使用何种编码,在编译后成class后,他们都是一样的----Unicode编码表示。JVM里面的任何字符串资源都是Unicode,就是说,任何String类型的数据都是Unicode编码。 - JVM加载class文件读取时候使用Unicode编码方式正确读取class文件,那么原来定义的String s="汉字";在内存中的表现形式是Unicode编码。
- MySQL 中的 "utf8" 实际上不是真正的 UTF-8, "utf8" 只支持每个字符最多 3 个字节, 对于超过 3 个字节的字符就会出错, 而真正的 UTF-8 至少要支持 4 个字节
MySQL 中的 "utf8mb4" 才是真正的 UTF-8
如有错误,欢迎斧正!
参考文章:
Unicode的前世今生 - 掘金
Unicode、UTF-8、UTF-16 终于懂了 - 知乎
在Java语言中,下列关于字符集编码(Character s_阿里巴巴笔试题_牛客网
理解字节序 - 阮一峰的网络日志
JAVA与Unicode(吐血整理)_java unicode-CSDN博客
《Java核心技术卷Ⅰ》














 2083
2083











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









