






(一)邮箱地址和网址提取
构建正则表达式
re模块常见相关函数
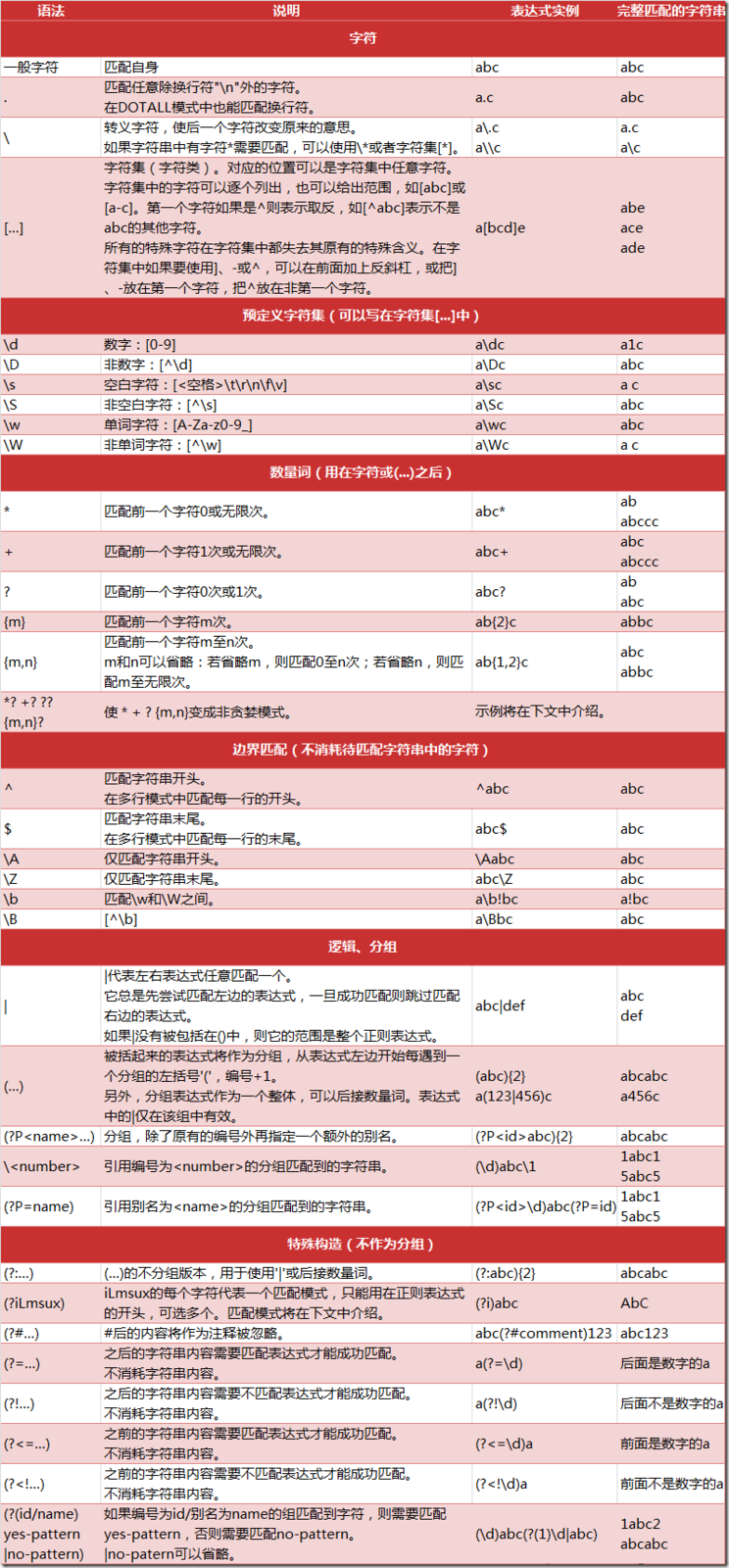
re.search()在一个字符串中搜索正则表达式的第一个位置,返回match对象
re.match()从一个字符串的开始位置起匹配正则表达式,返回match对象
re.findall()搜索字符串,以列表类型返回全部能匹配的子串
re.split()将一个字符串按照正则表达式匹配结果进行分割,返回列表类型
re.finditer()搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象
re.sub()在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串
举例说明:
邮箱地址提取:
输入:
请使用我的邮箱:nlp@nudt.com,发邮件给:educoder@edu.net
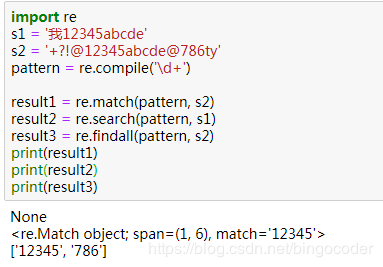
import re
string =input()
email=re.findall(r"[a-z0-9\.\-+_]+@[a-z0-9\.\-+_]+\.[a-z]+", string)
print("提取邮箱地址如下:")
for i in range(len(email)):
print(email[i])输出结果:
提取邮箱地址如下: nlp@nudt.com educoder@edu.net
网址提取:
输入:
please click https://www.educoder.net
import re
string =input()
urls=re.findall(r"(http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*,]|(?:%[0-9a-fA-F][0-9a-fA-F]))+)|([a-zA-Z]+.\w+\.+[a-zA-Z0-9\/_]+)",string)
print("提取网址如下:")
urls=list(sum(urls,()))
for i in range(len(urls)):
print(urls[i])输出结果:
提取网址如下: https://www.educoder.net
(二)密码提取
输入:
密码是:NUDT_NLP2021
import re
string =input()
print("提取密码是")
p=re.compile('[a-z]|[A-Z]|_|\d')
t=re.findall(p,string)
if t:
for i in t:
print(i,end="")输出结果:
提取密码是 NUDT_NLP2021















 5571
5571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









