






Python基础
第一章
1、python 中的输出函数
print() 函数
我里面有一个你可以直接使用的函数叫做 print() 函数,可以展示在 IDLE 或标准的控制台显示
print(520) #向计算机发出指令打印520,把代码编译成计算机能听懂的语言,做出相应的执行,在控制台上输出结果
print() 函数可以输出的函数:
1、可以输出数字
print(520)
2、可以输出字符串
print("helloworld")
3、可以输出含有运算符的表达式
print(4+8)
print() 函数可以将内容输出到目的地
1、显示器
2、文件
fp=open('D:/text.txt','a+') #设置变量及变量路径,若无则添加新变量,a+ ==》以读写方式打开
print('helloworld',file=fp) #在fp中输出helloworld
fp.close() #关闭变量
注意:1.所指定的盘必须存在 2.使用 file=fp
print() 函数的输出形式
1、换行
2、不换行
注意:若想进行不换行输出(输出内容在一行当中)
print('hello','world','python')
2、转义字符
转义字符是反斜杠+想要实现的转义功能首字母
当字符串中包含反斜杠、单引号和双引号等有特殊用途的字符时,必须使用反斜杠对这些字符进行转义(转换一个含义)
反斜杠: \\
单引号: \'
双引号: \"
当字符串中包含换行,回车,水平制表符或退格等无法直接表示的特殊字符时,也可以直接使用转义字符
换行: \n # print('hello\nworld')
回车: \r # print('hello\rworld')
水平制表符: \t # print('hello\tworld')
退格: \b # print('hello\bworld') # \b退一个格
纵向制表符: \v
八进制: \oyy
十六进制: \xyy
在输出双斜杠时
print('http:\\\\www.baidu.com')
print('老师说:\'大家好\'')
不希望字符串中的转义字符起作用,就使用原字符,就是在字符串之前加上r或R
print(r'hello\nworld')
注意事项,最后一个字符不能是反斜杠
print(r'hello\nworld\') =====>>> 报错
print(r'hello\nworld\\') ====>>> 可以
第二章
1、二进制与字符编码

二进制(0,1) =》 ASCII ==》GB2312 ==》GBK ==》GB18030 ==》Unicode 几乎包含了全世界的字符 ==》 UTF-8
==》 其他国家的字符编码 ==》 Unicode 几乎包含了全世界的字符 ==》 UTF-8
2、python 中的标识符和保留字
保留字:
有一些单词被赋予了特定的意义,这些单词不能用于对任何对象起名字
import keyword
print(keyword.kwlist)
如下:
'False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield'
标识符:
变量,函数,类,模块和其他对象起的名字。
规则:
- 字母、数字、下划线
- 不能以数字开头
- 不能是我的保留字
- 严格区分大小写
注:若以下划线开头的标识符是具有特殊意义的且不能是 python 的特殊字符
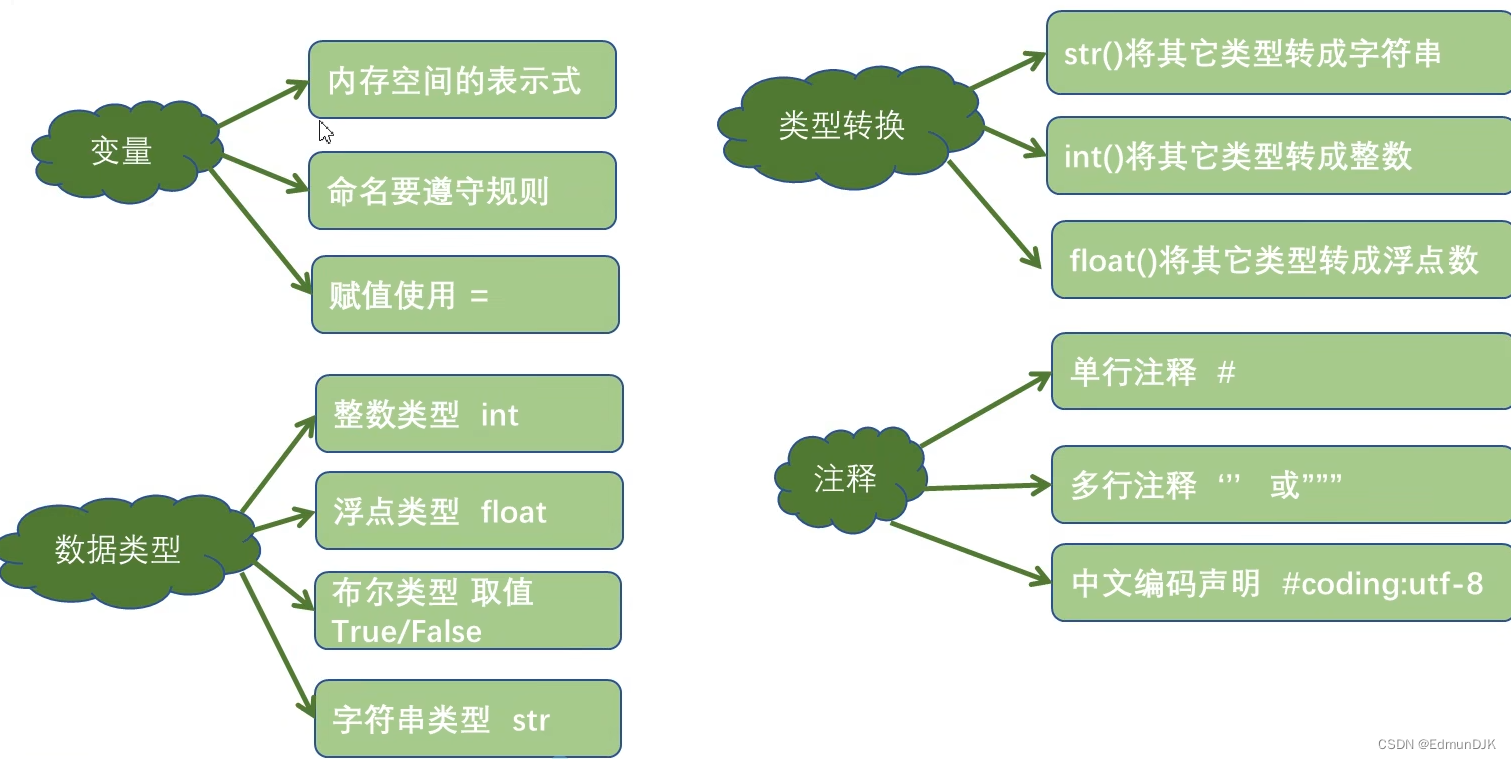
3、变量的定义与使用
变量是内存中一个带标签的盒子
name = 'xxx' #将需要的数据放进去
变量名 赋值运算符 值
变量由三部分组成:
标识:表示对象所存储的内存地址,使用内置函数 id(obj)来获取
类型:表示的是对象的数据类型,使用内置函数 type(obj)来获取
值:表示对象所存储的具体数据,使用print(obj)可以将值进行打印输出
name='xxx'
print(name)
print('标识',id(name))
print('类型',type(name))
print('值',name)
输出为
xxx
标识 2816505906672
类型 <class 'str'>
值 xxx
当变量多次赋值后,变量名会指向新的空间
输入
name='0.0'
name='111'
print(name)
输出
111
4、数据类型
4.1、可变数据类型
list
set
dictonary
4.2、不可变数据类型
string
tuple
number
常用的数据类型:
整数类型: int # 98 11 23
英文为 integer 简写为 int 可以表示正数,负数和零
整数的不同进制表示方式
十进制 ==》 默认的进制
二进制 ==》以 0b 开头
八进制 ==》以 0o 开头
十六进制 ==》以 0x 开头

浮点数类型: float # 1.5113
浮点数由整数部分和小数部分组成
浮点数存储不精确
使用浮点数进行计算时,可能会出现小数位数不确定的情况

from decimal import Decimal
print(Decimal('1.1')+Decimal('2.2'))
输出为
3.3
布尔类型: bool boolean # True False
用来表示真或假的值
True 表示真 False 表示假
布尔值可以转化为整数
True ==》 1
False ==》 0
print(True+1) #2
print(False+1) #1
字符串类型: str # 'helloword'
4.3、字符串类型
1、字符串又被称为不可变的字符序列
2、可以使用单引号‘’双引号”“三引号“‘ ”’或“““ ”””来定义
3、单引号和双引号定义的字符串必须在一行
4、三引号定义的字符串可以分布在连续的多行
str1='helloworld'
str2="helloworld"
str3="""helloworld"""
str4='''helloworld'''
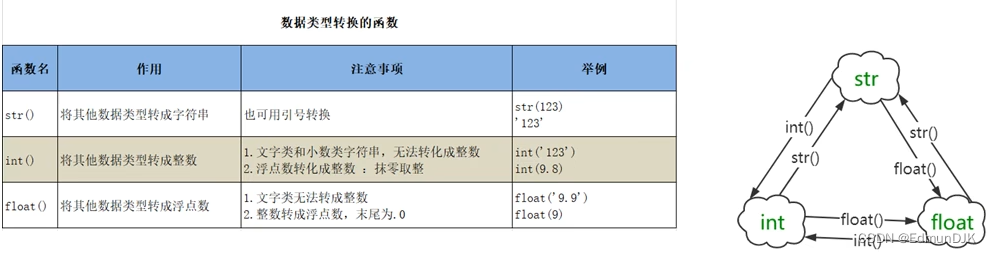
4.4、数据类型转换
可以将不同数据类型的数据拼接到一块
`
name='nihao'
ZYM=10
print(type(name),type(ZYM))
print(name+'ya'+str(ZYM)) #当将str类型与int类型进行连接时报错,解决方案,类型转换
PS:
将str转成int类型,字符串为数字串
float转成int类型,截取整数部分,舍掉小数部分
将str转成int类型,报错,因为字符串为小数串
将str转成int类型,字符串必须为数字串(整数)
6、python 中的注释
注释:
1、在代码中对代码的功能进行术后名的标注性文字,可以提高代码的可读性
2、注释的内容会被 python 解释器忽略
3、通常包括三种类型的注释:
(1)单行注释==》以"#"开头,直到换行结束
(2)多行注释==》并没有单独的多行注释标记,将一对三引号之间的代码成为多行注释
(3)中文编码声明注释==》在文件开头加上中文声明注释,用以指定源码文件的编码格式
#coding:gbk #使用gbk编码模式
第三章
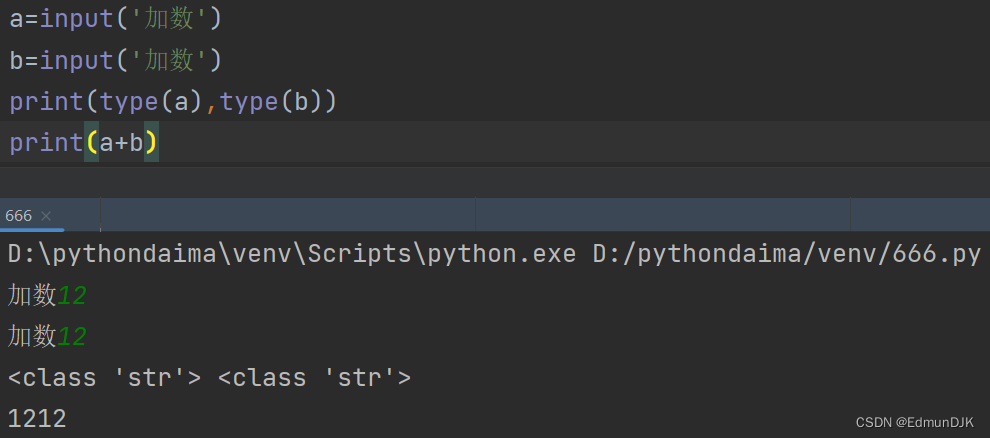
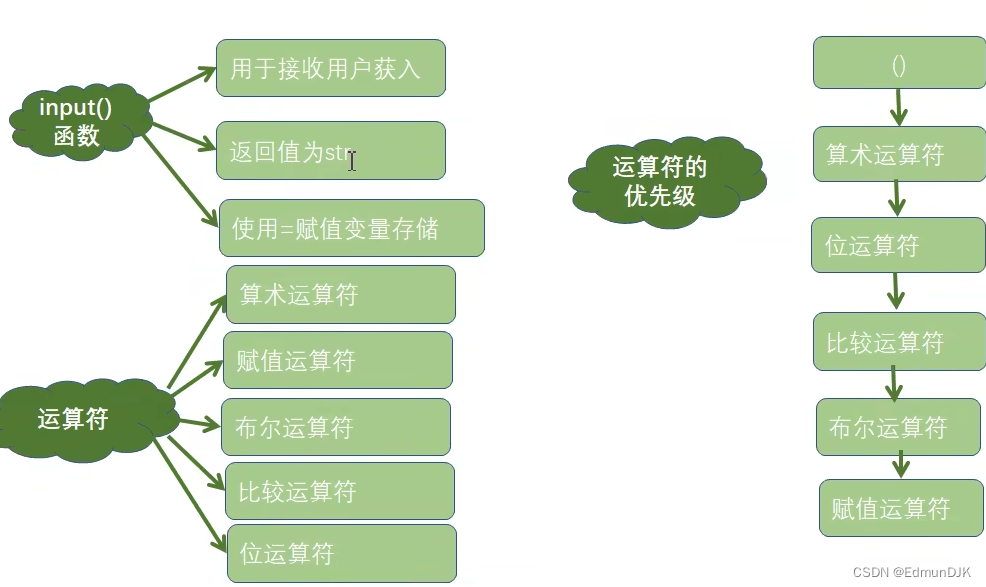
1、python的输入函数input()
input函数
作用:接收来自用户的输入
返回值类型:输入值的类型为str
值的存储:使用=对输入的值进行存储
present = input('helloworld')
变量 赋值运算符(将输入函数的结果赋值给present) input()函数是一个输入函数,需要输入回答
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qIQ0Qa9B-1658146261353)(…/…/AppData/Roaming/Typora/typora-user-images/image-20220526201119892.png)]
两个数均为 str ,需要进行数据类型转换
将转化后的结果存储到 a 中
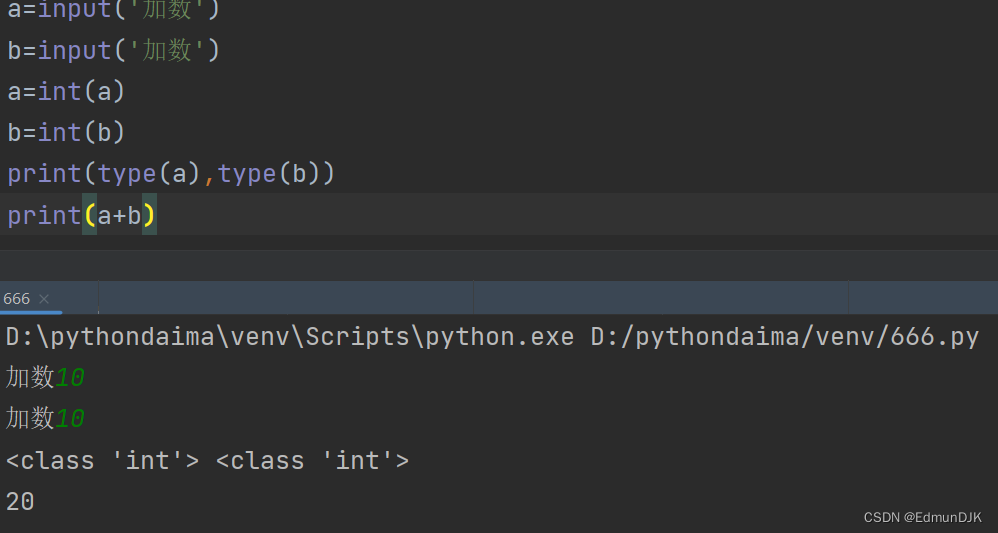
或者
a=int(input('加数'))
b=int(input('加数'))
print(type(a),type(b))
print(a+b)
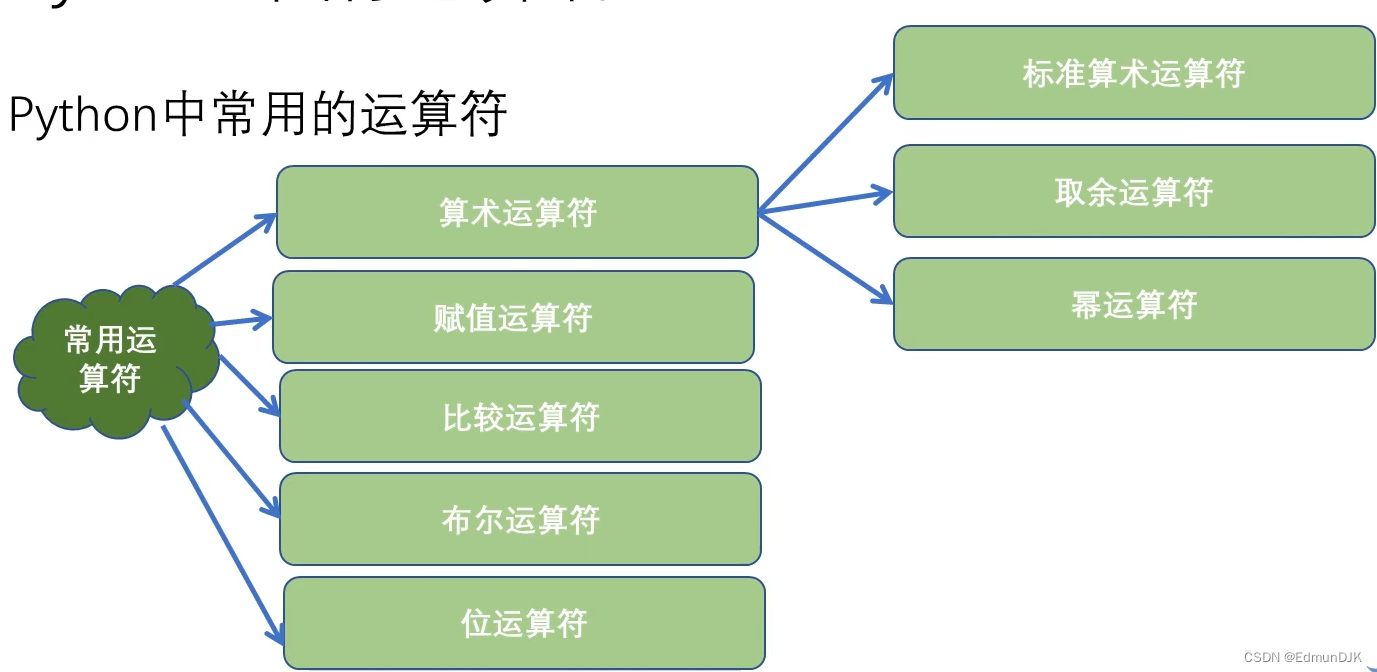
2.1、算术运算符
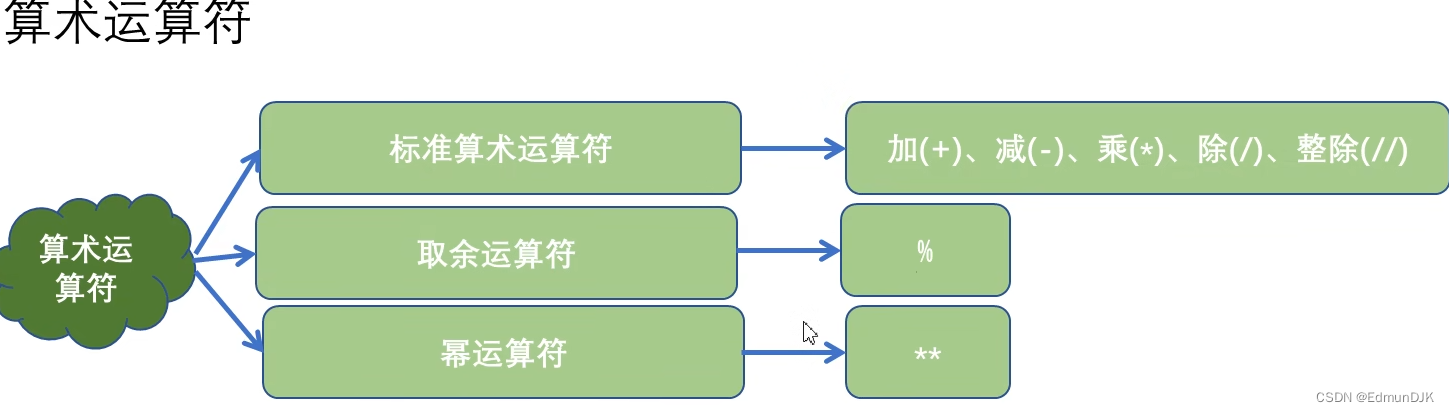
print(1+1) #加法运算 2
print(1-1) #减法运算 0
print(2*4) #乘法运算 8
print(1/2) #除法运算 0.5
print(11/2) #除法运算 5.5
print(11//2) #整除运算 5
print(11%2) #取余运算 1
print(2**3) #2的3次方 8
print(9//-4) #一正一负整除,向下取整 -3
print(9%-4) #余数=被除数-除数*商 9-(-4)*(-3)
2.2、赋值运算符
运算顺序从右到左
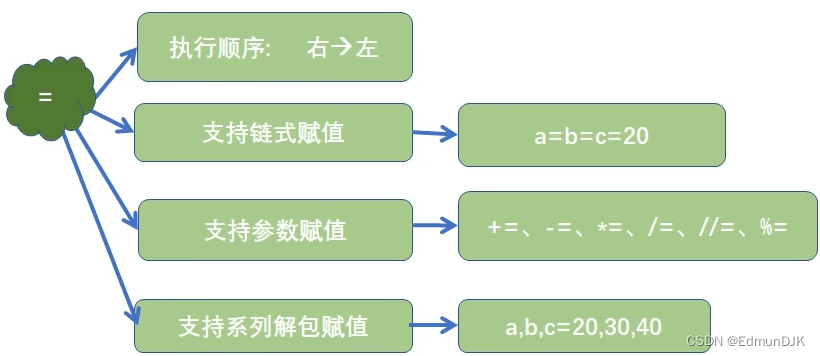
解包赋值:
a,b,c=10,20,30
print(a,b,c) #
交换变量值
a,b=10,20
print('交换之前',a,b)
a,b=b,a
print('交换之后',a,b)
2.3、比较运算符
对变量或表达式的结果进行大小、真假比较
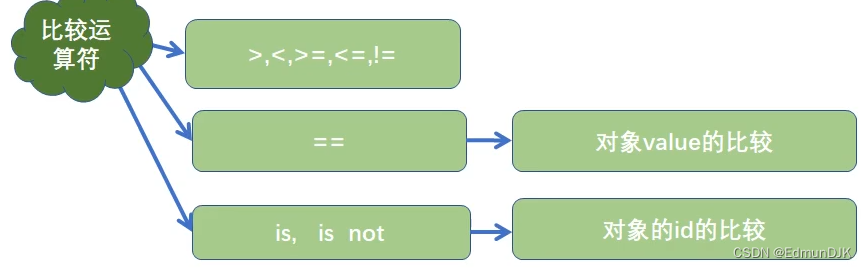
比较运算符的结果为 bool 类型
a,b=10,20
print('a>b吗?',a>b) # False
一个 = 称为赋值运算符, == 称为比较运算符(== 比较的是值)
一个变量由三部分组成
比较对象的标识使用 is
a=10
b=10
print(a==b) # True 说明,a与b的value相等
print(a is b) # True 说明,a与b的id标识相等
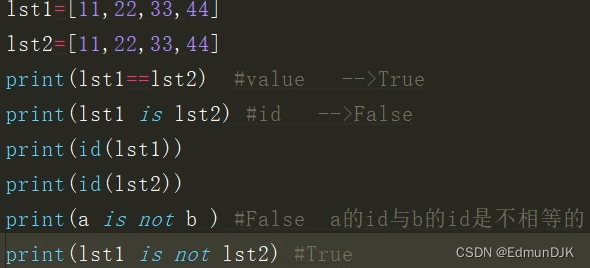
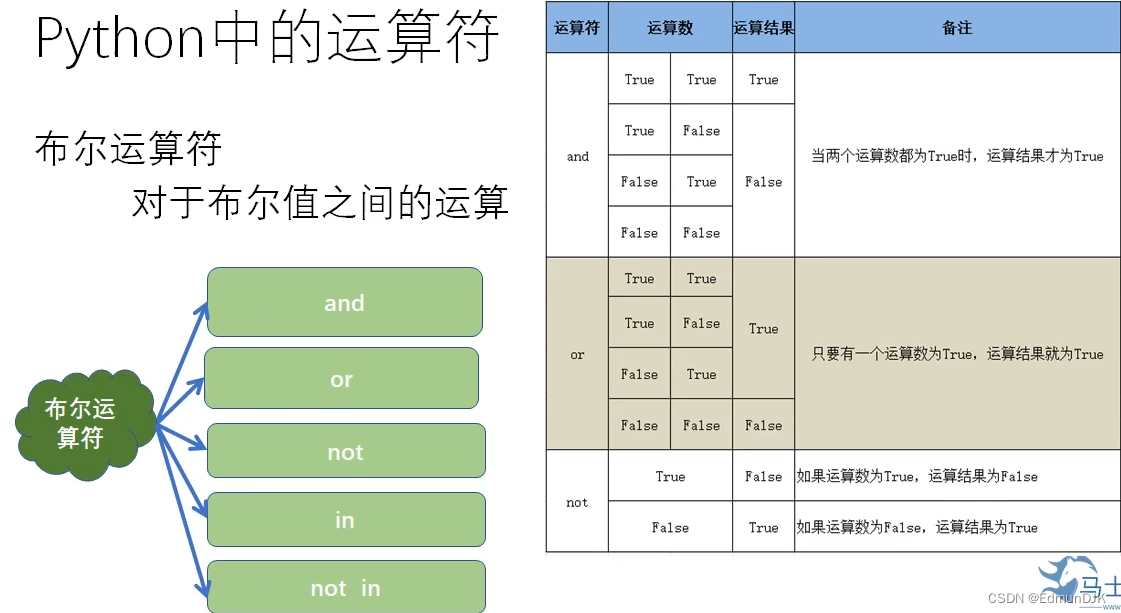
2.4、布尔运算符
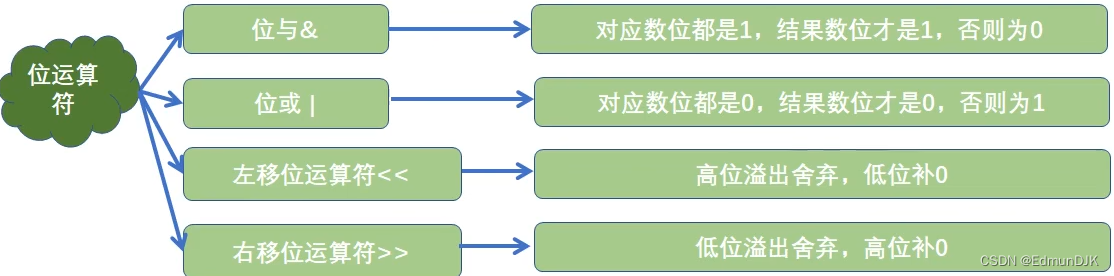
2.5、位运算符
将数据转成二进制进行计算
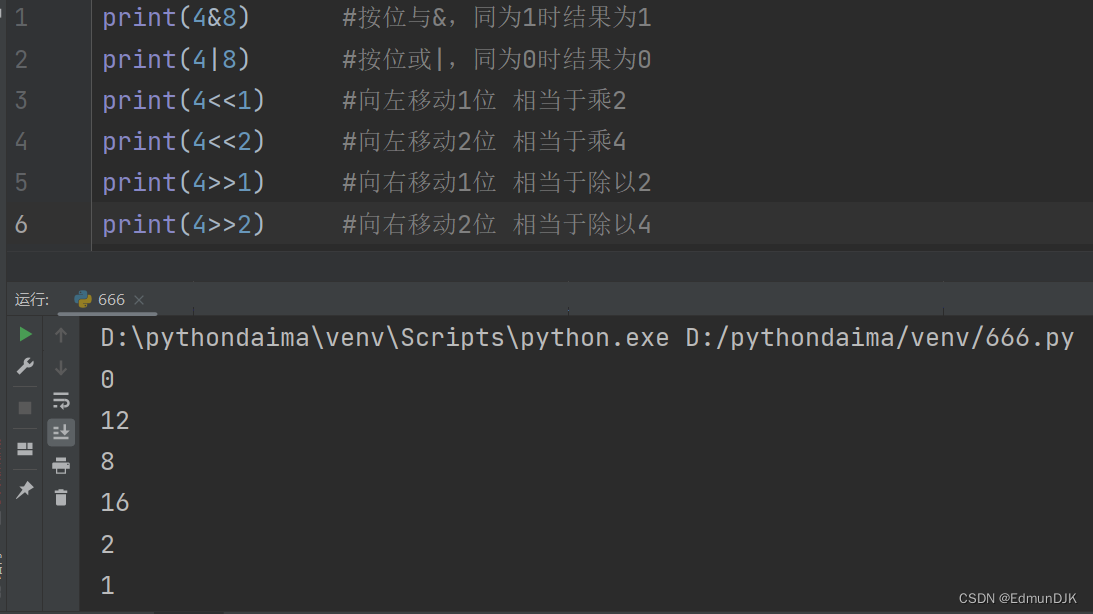
3、运算符的优先级
算术运算 位运算 比较运算符 布尔运算 赋值
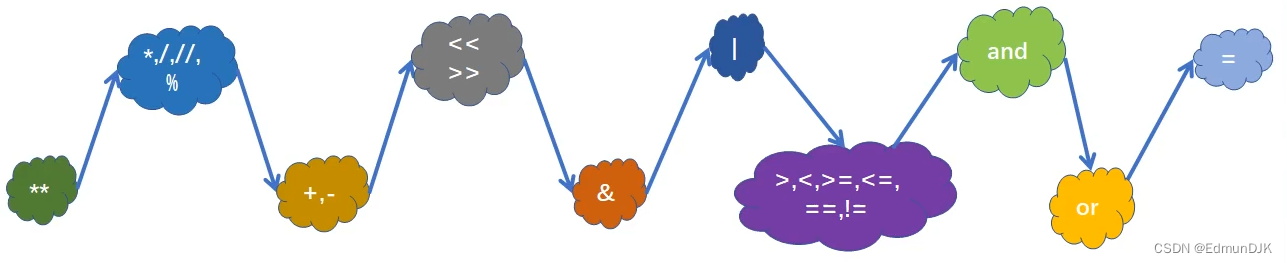
幂运算 乘除取余 加减 左右移 按位与& 按位或| 比较 True False =
第四章
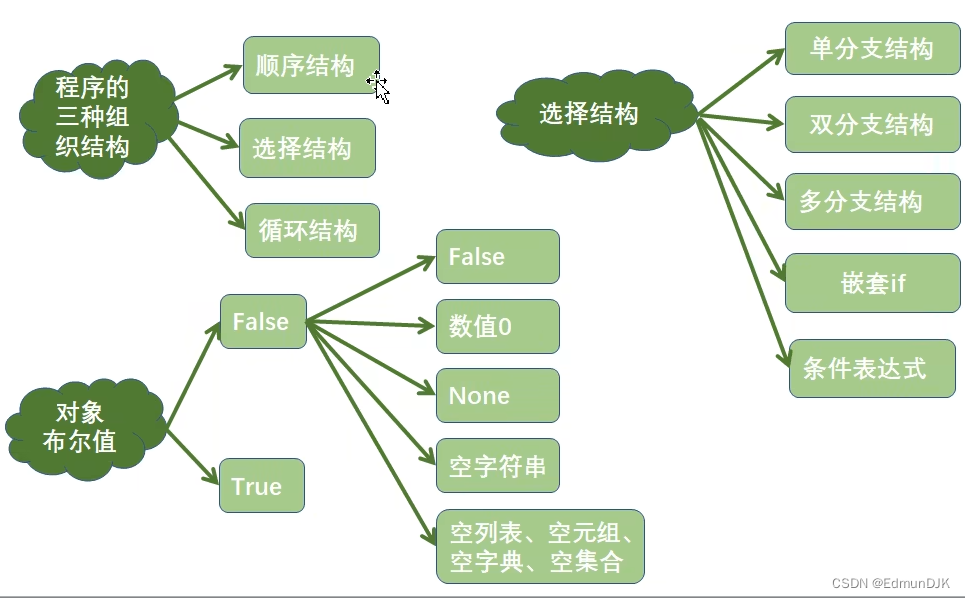
1、程序的组织结构
2、顺序结构
程序从上到下顺序地执行代码,中间没有任何的判断和跳转,直到程序结束
3、对象的布尔值
python 一切皆对象,所有对象都有一个布尔值
获取对象的布尔值
使用内置函数 bool()
以下对象的布尔值为 False
False 、数值0 、None 、空字符串 、空列表 、空元组 、空字典 、空集合
print(bool(False)) #Fasle
print(bool(0)) #Fasle
print(bool(0.0)) #Fasle
print(bool(None)) #Fasle
print(bool('')) #Fasle
print(bool("")) #Fasle
print(bool([])) #空列表Fasle
print(bool(list())) #空列表Fasle
print(bool(())) #空元组Fasle
print(bool(tuple())) #空元组Fasle
print(bool({})) #空字典Fasle
print(bool(dict())) #空字典False
print(bool(set())) #空集合False
4、分支结构
4.1、选择结构
程序根据判断条件的布尔值选择性的执行部分代码
4.2、单分支结构
中文语义:如果…就…
语法结构:
if 条件表达式:
条件执行体
4.3、双分支结构
中文语义:如果…不满足…就…
语法结构:
if 条件表达式:
条件执行体1
else:
条件执行体2
4.4、多分支结构
语法结构:
if 条件表达式1:
条件执行体1
elif 条件表达式2:
条件执行体2
elif 条件表达式3:
条件执行体N
[else:]
条件执行体N+1
判断可用 10<=score<=100: ====== score>=10 and score<=100
4.5、嵌套 if
语法结构:
if 条件表达式1:
if 内层条件表达式:
内存条件执行体1
else:
内存条件执行体2
else:
条件执行体
4.6、条件表达式
条件表达式是 if…else的简写
语法结构:
x if 判断条件 else y
运算规则:
如果判断条件的布尔值为 True ,条件表达式的返回值为 x ,否则条件表达式的返回值为 False
num_a=input('第一个整数')
num_b=input('第二个整数')
print(str(num_a)+'大于等于'+str(num_b) if num_a>=num_b else str(num_a)+'小于'+str(num_b))
4.7、pass语句
语句什么都不做,只是一个占位符,用在语法需要语句的地方
可以和 if 语句的条件执行体、for-in语句的循环体、定义函数时的函数体一起使用
第五章
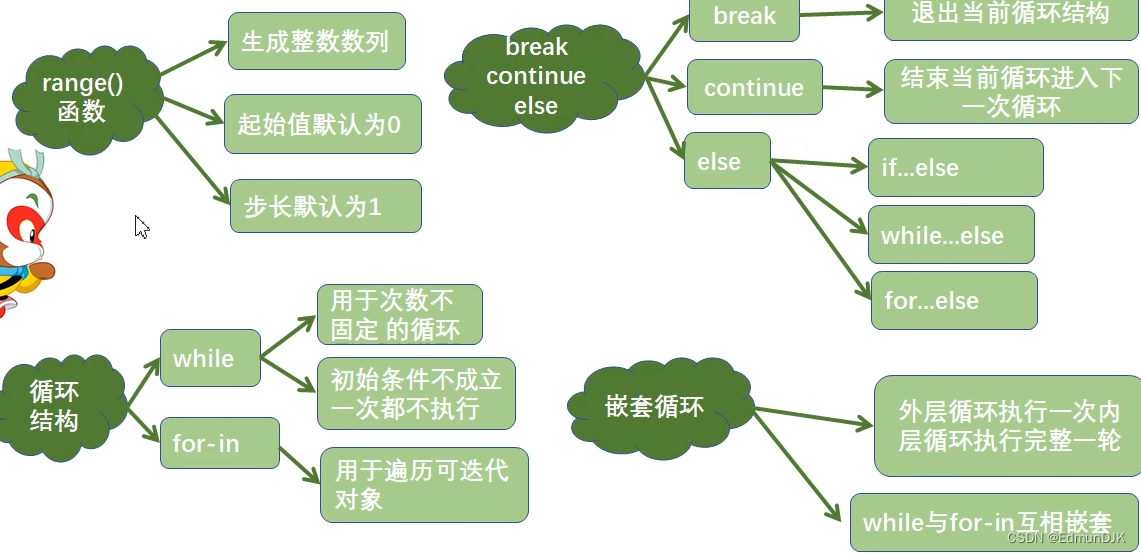
1、内置函数 range()
用于生成一个整数序列
创建 range 对象的三种方式

返回值是一个迭代器对象
range 类型的优点:
不管 range 对象标识的整数序列有多长,所有 range 对象占用的内存空间都是相同的,因为仅仅需要存储start,stop 和 step,只有当用到 range 对象时, 才回去计算序列中的相关元素
in 与 not in 判断整数序列中是否存在(不存在)指定的整数
'''第一种创建方式,只有一个参数(小括号只给一个数)'''
r=range(10) #[0,1,2,3,4,5,6,7,8,9],默认从0开始,默认相差1,称为步长
print(r) #range(0,10)
print(list(r)) #用于查看 range 对象中的整数序列 ==》 list表示列表
'''第二种创建方式,给了两个参数(小括号中给了两个数)'''
r=range(1,10) #指定起始值,从1开始,到10结束(不包括10),默认步长为1
print(list(r)) #[1,2,3,4,5,6,7,8,9]
'''第三种创建方式,给了三个参数(小括号中给了三个数)'''
r=range(1,10,2) #指定起始值,到10结束,步长为2
print(list(r)) #[1,3,5,7,9]
'''判断指定的整数 在序列中是否存在 in,not in'''
print(10 in r) # False
print(9 in r) # True
print(10 not in r) # True
2、While 循环
反复做同一件事情,称为循环
2.1、循环的分类
while、for-in
2.2、语法结构:
while 条件表达式
条件执行体(循环体)
2.3、选择结构的 if 与循环结构 while 的区别:
if 是判断一次,条件为 True 执行一行
whlie 是判断 N+1 次,条件为 True 执行 N 次
2.4、whlie循环的执行流程
四部循环法:
初始化变量
条件判断
条件执行体(循环体)
改变变量
总结:初始化变量与条件判断的变量与改变的变量为同一个
whlie循环的执行流程
求前几数之和
sum=0
#初始化变量为0
a=0
#条件判断
while a<5:
#条件执行体(循环体)
sum+=a
#改变变量
a+=1
print('和为',sum)
3、for-in 循环
3.1、for-in 循环
in 表达从(字符串、序列等)中依次取值,又称为遍历
for-in 遍历的对象必须是可迭代对象
3.2、for-in 的语法结构
for 自定义的变量 in 可迭代对象
循环体
3.3、for-in 的执行图
循环体内不需要访问自定义变量,可以将自定义变量替代为下划线
for item in 'Python': #第一次取出来的是p,将p赋值给item,将item的值输出
print(item)
#range()产生一个整数序列 是可迭代对象
for i in range(10):
print(i)
#如果在循环体中 不需要用到自定义变量 可将自定义变量写为"_"
for _ in range(5):
print('helloworld')
#使用for-in循环,计算1-100偶数和
sum=0
for item in range(1,101):
if item %2==0:
sum+=item
print('1-100偶数和为',sum)
#使用for-in循环,计算1-100偶数和
sum=0
for item in range(1,101,2):
sum+=item
print('1-100偶数和为',sum)
#求水仙花数
for item in range(100,1000):
bai=item//100
shi=item//10-bai*10
ge=item-bai*100-shi*10
if bai**3+shi**3+ge**3==item:
print(item)
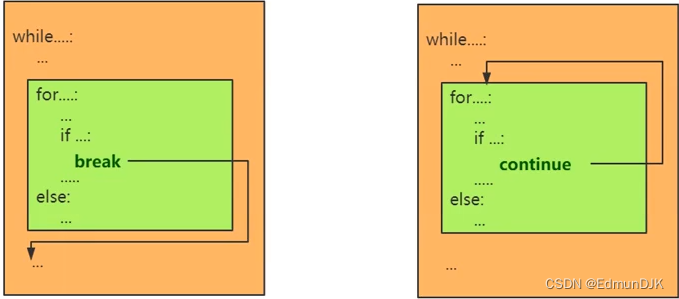
4、break、continue 与 else 语句
4.1、流程控制语句 break
用于结束循环结构,通常与分支结构 if 一起使用

#从键盘输入密码,最多错误3次
# 解法一
for pwd in range(3):
pwd=input('请输入密码:')
if pwd=='8888':
print('密码正确')
break
else:
print('密码不正确,请重新输入')
# 解法二
a=0
while a<3:
pwd=input('请输入密码:')
if pwd=='8888':
print('密码正确')
break
else:
print('密码错误')
a+=1
4.2、流程控制语句 continue
用于结束当前循环,进入下一次循环,通常与分支结构中的 if 一起使用
求1-50中5的倍数
for item in range(1,51):
if item%5!=0:
continue
print(item)
或
for item in range(1,51):
if item%5!=0:
continue
else:
print(item)
4.3、else 语句
与 else 语句配合使用的三种情况
#解法一
for pwd in range(3):
pwd=input('请输入密码:')
if pwd=='8888':
print('密码正确')
break
else:
print('密码不正确')
else:
print('对不起,三次输入均错误')
#解法二
a=0
while a<3:
pwd=input('请输入密码:')
if pwd=='8888':
print('密码正确')
break
else:
print('密码不正确')
a+=1
else:
print('对不起,三次输入均错误')
4.4、pass 空语句
保持程序结构的完整性
示例:
for letter in 'Python':
if letter == 'h':
pass
print '这是 pass 块'
print '当前字母 :', letter
print "Good bye!"
输出:
当前字母 : P
当前字母 : y
当前字母 : t
这是 pass 块
当前字母 : h
当前字母 : o
当前字母 : n
Good bye!
5、嵌套循环
循环结构中又嵌套了另外的完整的循环结构,其中内层循环作为外层循环的循环体执行

#九九乘法表
for i in range(1,10): #行数
for j in range(1,i+1): #列数
print(i,'*',j,'=',i*j,end='\t')
print()
#判断素数:
i = 2
while (i<100):
j = 2
while (j<=(i/j)):
if not(i%j):
break
j = j + 1
if (j>(i/j)):
print (i,'是素数')
i = i + 1
print("Done!")
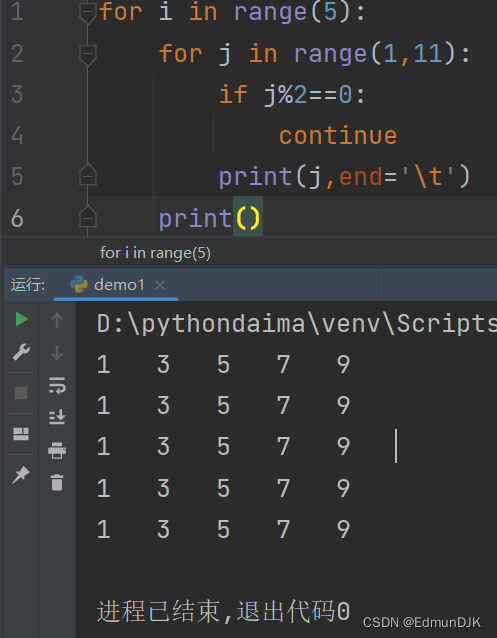
6、二重循环中的 break 和 continue
二重循环中的 break 和 continue 用于控制本层循环
for i in range(5): #代表外层要执行5次
for j in range(1,11):
if j%2==0:
break #可以换为 continue
print(j)

for i in range(5):
for j in range(1,11):
if j%2==0:
continue
print(j,end='\t')
print()
第六章
列表是什么?为什么需要列表?
1、变量可以存储一个元素,而列表是一个"大容器"可以存储 N 多个元素,程序可以方便的对这些数据进行整体操作
2、列表相当于其他语言中的数组
3、列表示意图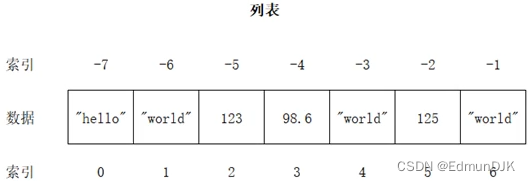
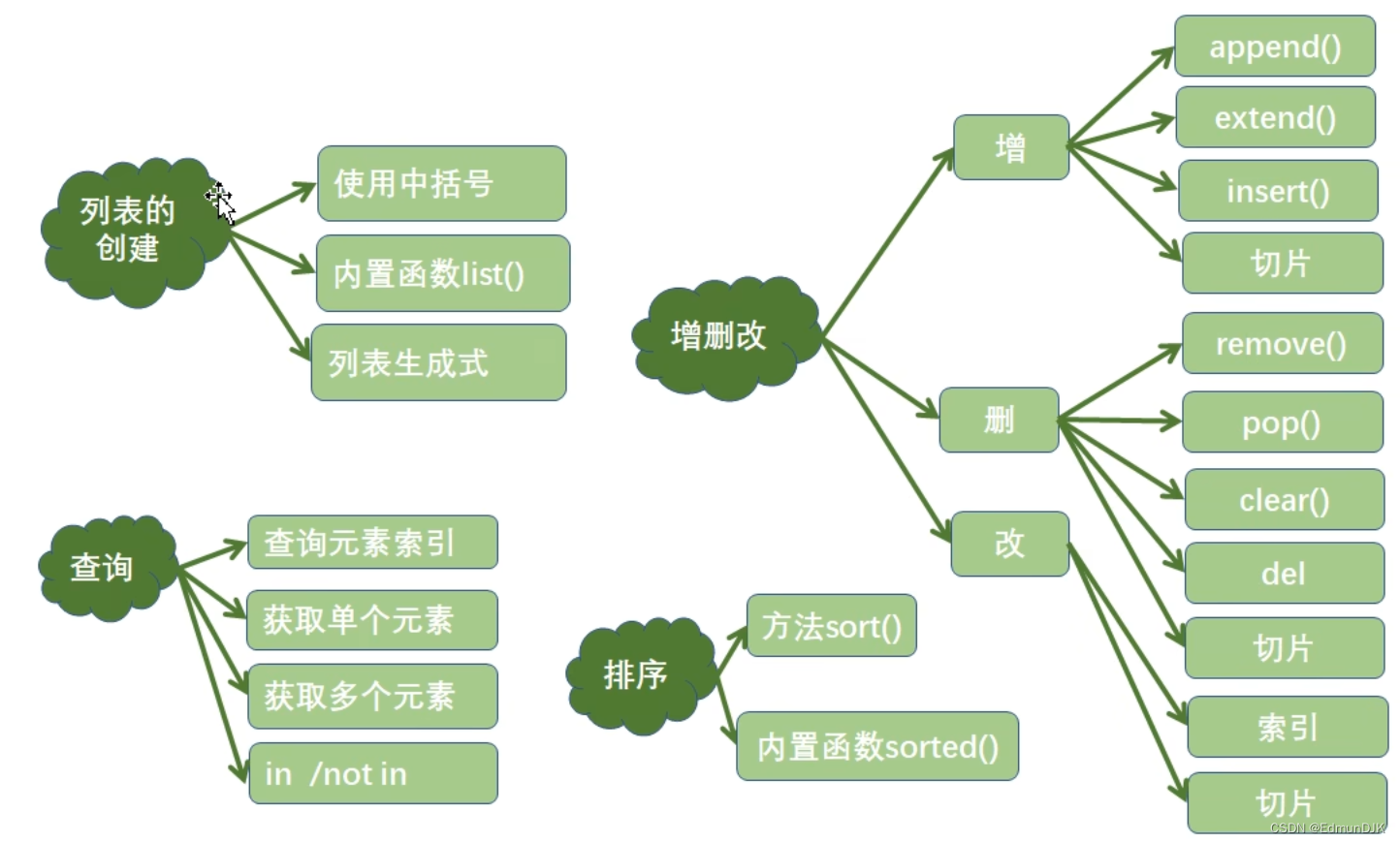
1、列表的创建
列表需要使用中括号 [ ] ,元素之间使用英文的逗号进行分隔
lst = ['hello','world']
列表对象名 赋值号 中括号 逗号
列表的创建方式:
1、使用中括号
2、调用内置函数list()
#创建列表的第一种方式 使用[]
lst=['hello','world',98]
#创建列表的第二种方式,使用内置函数list()
lst2=list(['hello','world',98])
列表的特点:
列表元素按顺序有序排列
索引映射唯一一个数据
列表可以存储重复数据
任意数据类型混存
根据需要动态分配和回收内存
2、列表的查询操作
获取列表中指定元素的索引:
index() :
如查列表中存在N个相同元素,只返回相同元素中的第一个元素的索引
如果查询的元素在列表中不存在,则会抛出ValueError
可以在指定的start和stop之间进行查找
获取列表中的单个元素:
获取单个元素:
正向索引从0到N-1 举例:lst[0]
逆向索引从-N到-1 举例:lst[-N]
指定索引不存在,抛出IndexError
lst=['hello','world',98,'hello']
print(lst.index('hello')) #如果列表中有相同元素只返回列表中相同元素的第一个元素索引
print(lst.index(98,1,3)) # 2
lst=['hello','world',52,'hello','world',74]
#获取索引为2的元素
print(lst[2]) #52
#获取索引为-3的元素
print(lst[-3]) #hello
#获取索引为10的元素
print(lst[10]) #报错
列表元素的查询操作
获取列表中的多个元素
语法格式:
列表名[start:stop:step]
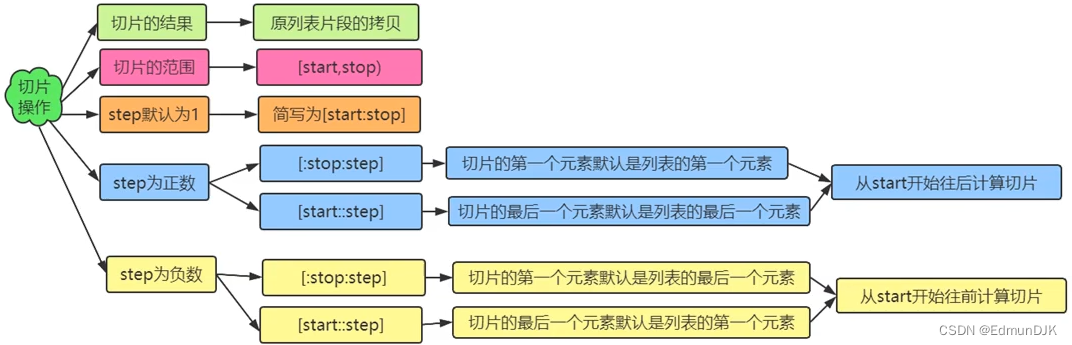

判断指定元素在列表中是否存在:
元素 in 列表名
元素 not in 列表名
列表元素的遍历:
for 迭代变量 in 列表名
>操作<
lst=[10,20,30,'hello','python']
print(10 in lst) #True
print(20 not in lst) #False
3、列表元素的增、删、改操作
增操作:
append() #在列表的末尾添加一个元素
extend() #在列表的末尾至少添加一个元素
insert() #在列表的任意位置添加一个元素
切片 #在列表的任意位置添加至少一个元素
append() 函数用法:
lst=[10,20,30]
print('添加元素之前',lst,id(lst)) #添加元素之前 [10, 20, 30] 2274584023744
lst.append(100)
print('添加元素之后',lst,id(lst)) #添加元素之后 [10, 20, 30, 100] 2274584023744
与extend() 函数区别:
lst=[10,20,30]
print('添加元素之前',lst,id(lst))
lst.append(100)
print('添加元素之后',lst,id(lst))
lst2=['hello','world']
lst.append(lst2) #将lst2作为一个元素添加到列表末尾
lst.extend(lst2) #在列表的末尾至少添加一个元素
lst.insert(2,80) #在任意位置上添加一个元素
print(lst)
lst3=[True,False,'hi']
lst[1:]=lst3 #在任意位置添加N多个元素
print(lst) #[10, True, False, 'hi']
删操作:
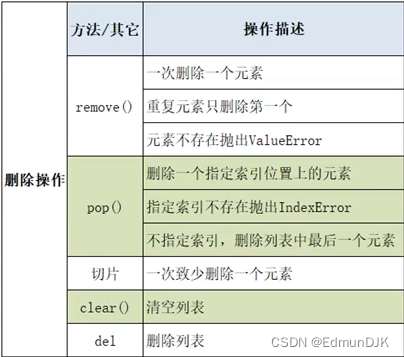
lst=[10,20,30,40,30]
lst.remove(30) #从列表中移除一个元素,如果有重复元素只移第一个元素
print(lst) #[10, 20, 40, 30]
#pop()根据索引移除元素
lst.pop(1) #移除索引为1的数,后面超出则报错
print(lst)
lst.pop() #不写默认删除最后一个元素
print(lst)
lst=[10,20,30,40,30]
#切片
new_list=lst[1:3]
print('原列表',lst) #原列表 [10, 20, 30, 40, 30]
print('切片后列表',new_list) #切片后列表 [20, 30]
#不产生新的列表对象,而是删除原列表中的内容
lst[1:3]=[]
print(lst) #[10, 40, 30]
#清除列表中的所有元素
lst.clear()
print(lst) #[]
#del语句将列表对象删除
del lst #此时输出lst会发生报错
修改操作
为指定索引的元素赋予一个新值
为指定的切片赋予一个新值
lst=[10,20,30,40,30]
#一次修改一个值
lst[2]=100 #将列表中索引为2的元素修改为100
print(lst) #[10, 20, 100, 40, 30]
lst[1:3]=[300,400,500,600] #将1-3的索引元素替换
print(lst) #[10, 300, 400, 500, 600, 40, 30]
4、列表元素的排序
常见的两种方式:
调用 sort() 方法,列表中的所有元素默认按照从小到大的顺序进行排序,可以指定 reverse=True ,进行降序排序
lst=[80,40,70,50,10,30]
print('排列前',lst) #排列前 [80, 40, 70, 50, 10, 30]
lst.sort()
print('排列后',lst) #升序排序排列后 [10, 30, 40, 50, 70, 80]
#通过指定关键字参数,将列表中的元素进行降序排序
lst.sort(reverse=True) #False为升序排序
print(lst) #[80, 70, 50, 40, 30, 10]
调用内置函数 sorted() ,可以指定 reverse=True ,进行降序排序,原列表不发生改变
lst=[80,40,70,50,10,30]
print('原列表',lst)
new_lst=sorted(lst)
print(new_lst) #[10, 30, 40, 50, 70, 80]
#指定关键字参数,实现列表元素的降序排序
nnews_lst=sorted(lst,reverse=True) #降序排序
print(nnews_lst) #[80, 70, 50, 40, 30, 10]
PS:sort() 函数是对原列表进行排序,sorted() 函数是创建新的列表进行排序
5、列表推导式
列表生成式(生成列表的公式)
语法结构:
[ i*i for i in range(1,10) ]
表示列表元素的表达式 自定义变量 可迭代对象
注意,表示列表元素的表达式中通常包含自定义变量
lst=[i for i in range(1,11)]
print(lst) #[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
#若只想要类表中的元素为2,4,6,8,10
lst2=[i*2 for i in range(1,6)]
print(lst2) #[2, 4, 6, 8, 10]
6、列表函数
cmp() #cmp(x,y) 函数用于比较2个对象,如果x<y返回-1,如果x==y返回0,如果x>y返回 1
len #列表元素个数
max #返回列表元素最大值
list(seq) #将元组转化为列表
min #返回列表元素最小值
operator
operator.lt(a, b) # a < b
operator.le(a, b) # a <= b
operator.eq(a, b) # a == b
operator.ne(a, b) # a != b
operator.ge(a, b) # a > b
operator.gt(a, b) # a >= b
第七章
1、什么是字典
字典:Python 内置的数据结构之一,与列表一样是一个可变序列
以键值对的方式存储数据,字典是一个无序的序列(以双成对)
放在字典中的键必须是不可变序列
scores = { '张三': 100 , '李四': 98 , '王五' : 45 }
字典名 花括号 逗号 键 冒号 值
字典示意图: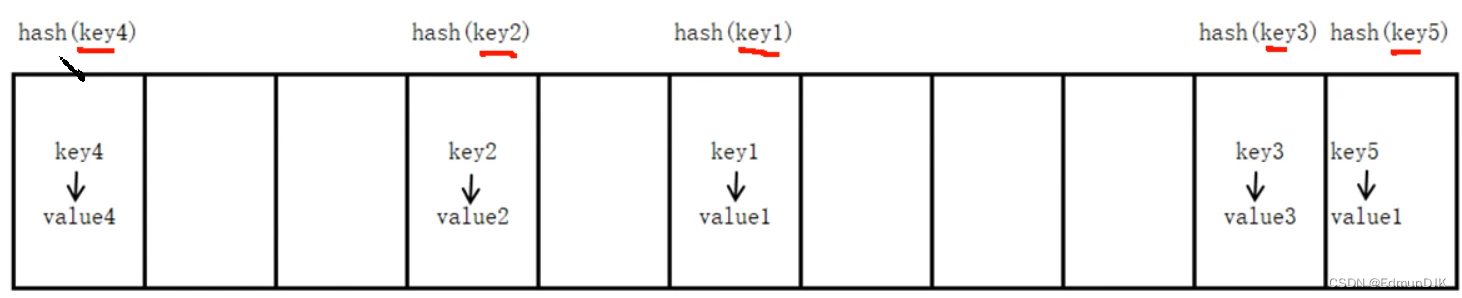
2、字典实现原理:
与查字典相似,Python 中的字典是根据 key 查找 value 所在的位置
3、字典的创建
最常用的方式:使用花括号
scores = { '张三' : 100 , '李四' : 98 , '王五' : 45 }
使用内置函数 dict() :
dict ( name = 'jack' , age = 20 )
4、字典的常用操作
4.1、字典中的元素获取
[] scores['hello']
get()方法 scores.get('hello')
[] 取值与使用 get() 取值的区别:
[] 如果字典中不存在指定的 key ,抛出 keyError 异常
get() 方法取值,如果字典中不存在指定的 key ,并不会抛出 KeyError 而是返回 None ,可以通过参数设置默认的 value ,以便指定的 key 不存在时返回
#获取字典的元素
scores={'a':100,'b':98,'c':45}
#第一种方式,使用[]
print(scores['a']) #100
print(scores['d']) #报错
#第二种方式,使用get()方法
print(scores.get('b')) #98
print(scores.get('d')) #None
print(scores.get('e',99)) #查找是元素不存在给默认值
4.2、key 的判断:
in 指定的key在字典中存在返回True 'a' in scores
not in 指定的key在字典中不存在返回True 'b' not in scores
scores={'a':100,'b':98,'c':45}
print('a' in scores) #True
print('b' not in scores) #False
4.3、字典元素额删除:
del scores ['c']
scores.clear() #全部删除
4.4、字典元素的新增:
scores ['a']=90
4.5、获取字典视图的三个方法:
keys() #获取字典中所有 key
values() #获取字典中所有 value
items() #获取字典中所有 key、value 对
# keys
scores={'a':100,'b':98,'c':45}
keys=scores.keys()
print(keys) #dict_keys(['a', 'b', 'c'])
print(type(keys)) #<class 'dict_keys'>
print(list(keys)) #['a', 'b', 'c'] 将所有的 key 组成的视图转成列表
# values
values=scores.value()
print(values) # dict_values([100, 98, 45])
print(type(values))
# items
items=scores.items()
print(items) # dict_items([('a', 100), ('b', 98), ('c', 45)])
print(list(items)) #[('a', 100), ('b', 98), ('c', 45)] 转换之后的列表元素是由元组组成
4.6、字典元素的遍历
for item in scores:
# 元素 字典
scores={'a':100,'b':98,'c':45}
for item in scores:
print(item,scores[item],scores.get(item))
5、字典的特点
1、字典中的所有元素都是一个 key-value 对, key 不允许重复,value 可以重复
d={'name':'a','name':'b'} #输出 b
d={'name':'a','nikename':'a'} #输出 'name':'a','nikename':'a'
2、字典中的元素都是无序的
3、字典中的 key 必须是不可变对象
4、字典也可以根据需要动态的伸缩
5、字典会浪费较大的内存,是一种使用空间换时间的数据结构
6、字典推导式
字典生成式:
items=['Fruits','Books','Others']
prices=[96,97,85]
d={ items:prices for items , prices in zip(items,prices)}
print(d) #{'Fruits': 96, 'Books': 97, 'Others': 85}
d={ items.upper():prices for items , prices in zip(items,prices)}
print(d) #{'FRUITS': 96, 'BOOKS': 97, 'OTHERS': 85}
内置函数 zip()
用于将可迭代的对象作为参数,将对象中对应的元素打包成一个元组,然后返回有这些元组组成的列表
第八章
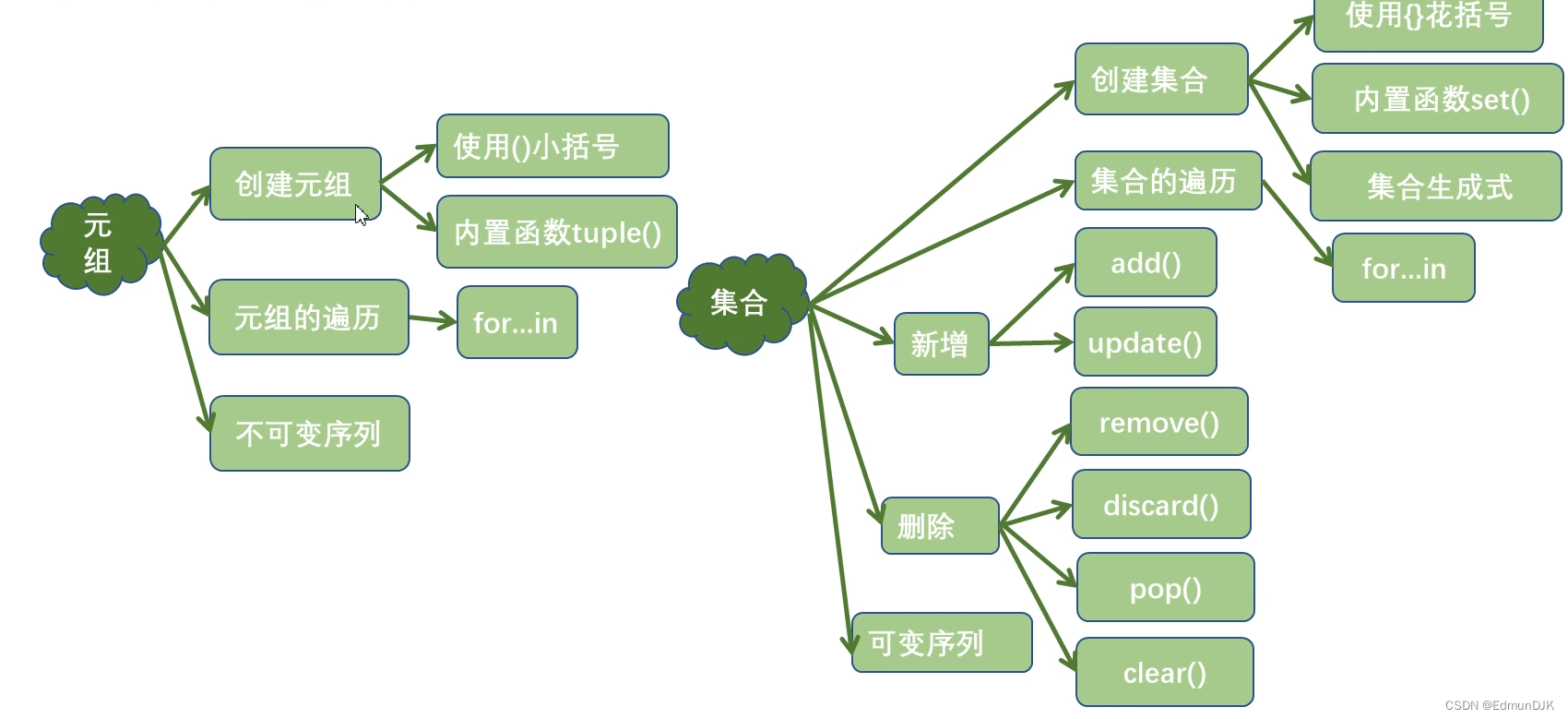
1、什么是元组
元组:Python 内置的数据结构之一,是一个不可变序列
不可变序列与可变序列:
不变可变序:字符串、元组(没有增删改的操作)
可变序列:列表、字典(可以对序列进行增删改操作,对象地址不发生更改)
t = ( 'python' , 'hello' ,90 )
小括号 逗号
2、元组的创建方式
直接小括号:
t = ('python','hello',90)
使用内置函数tuple()
t=tuple(('python','hello',90))
只包含一个元组的元素需要使用逗号和小括号(否则type不再是tuple类型)
t=(10, )
2.1、元组的组合
tup1=()
tup2=()
tup3=tup1+tup2
print tup3
2.2、元组的删除
tup=()
del tup
#### 2.3、索引 截取
a = ('hello','Hello','hellO')
a[2] #读取第二个元素
a[1:] #截取元素
a[-2] #反向读数 读取第二个元素
2.4、内置函数
cmp(tup1,tup2) #比较两个元素
len(tup) #计算元组个数
max(tup) #获取元组中元素的最大值
min(tup) #获取元组中元素的最小值
tuple(seq) #将列表转换为元组
空元组的创建方式:
t = ()
t1 = tuple()
空列表的创建方式:
lst = []
lst1 = list()
空字典的创建方式:
d = {}
d2 = dict()
PS:尽量将元组设计成不可变序列,在多任务环境下,同时操作对象是不需要加锁,所以,在程序中尽量使用不可变序列
(加锁:多客户操作时将重要数据安全化,不能进行增删改)
元组中存储的是对象的引用:
1、如果元组中对象本身是不可变对象,则不能在引用其他对象
2、如果元组中的对象是可变对象,则可变对象的引用不允许改变,但数据可以改变
举例:
t = ( 10 , [20,30] , 9 )
print(t)
print(type(t))
print(t[0],type(t[0]),id(t[0])) # 10,int,2836809581072
print(t[1],type(t[1]),id(t[1])) # [20,30],list,2836810956480
print(t[2],type(t[2]),id(t[2])) # 9,int,2836809581040
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SOtw8WRK-1658234404774)(…/…/AppData/Roaming/Typora/typora-user-images/image-20220612194922802.png)]

3、元组的遍历
元组是可迭代对象,所以可以使用 for…in 进行遍历
t = tuple(('python','hello',90))
for item in t:
print(item)
4、什么是集合
集合:
python语言提供的内置数据结构
与列表、字典一样都属于可变类型的序列
集合石没有 value 的字典
5、集合的创建方式
1、直接{} #集合中的元素不允许重复
s = {'hello','world',90}
2、使用内置函数set()
s = set(range(6))
print(s)
print(set([3,4,53,56]))
print(set((3,4,43,435)))
print(set({124,3,4,4,5}))
print(set())
3、定义空集合
s = set()
6、集合的增、删、改、查操作
集合元素的判断操作
in 或 not in
s = {10,20,30,40,50}
print(10 in s) #true
print(100 in s) #false
print(10 not in s) #false
集合元素的新增操作
调用 add() 方法,一次添中一个元素
调用 update() 方法至少添中一个元素
s = {10,20,30,40,50}
s.add(60) #单个添加
print(s) # {50, 20, 40, 10, 60, 30}
s.update({80,90,100})#多个添加
print(s) # {100, 40, 10, 80, 50, 20, 90, 60, 30}
s.update([100,99,8])
s.update((78,64,56))
print(s) # {64, 99, 100, 40, 8, 10, 78, 80, 50, 20, 56, 90, 60, 30}
集合元素的删除操作
调用 remove() 方法,一次删除一个指定元素,如果指定的元素不存在则报错
调用 discard()方法,一次删除一个指定元素,如果指定的元素不存在不抛出异常
调用 pop() 方法,一次只删除一个任意元素
调用 clear() 方法,清空集合
s = {64, 99, 100, 40, 8, 10, 78, 80, 50, 20, 56, 90, 60, 30}
s.remove(500) #报错
print(s)
s.discard(500) #正常
s.pop() #随机删除
print(s)
s.clear() #清空
print(s)
集合之间的关系
两个集合是否相等:
可以使用运算符 == 或 != 进行判断
s = {10,20,30,40}
s1 = {30,40,10,20}
print(s==s1) # true
一个集合是否是另一个集合的子集:
可以调用方法 issubset 进行判断
B是A的子集
s1={10,20,30,40}
s2={10,20}
print(s2.issubset(s1)) # true
一个集合是否是另一个集合的超集:
可以调用方法 issuperset 进行判断
A是B的超集
s1={10,20,30,40}
s2={10,20}
print(s1.issuperset(s2)) # true
两个集合是否没有交集:
可以调用方法 isdisjoint 进行判断
s1={10,20,30,40}
s2={10,20}
print(s1.isdisjoint(s2)) # false 有交集为false
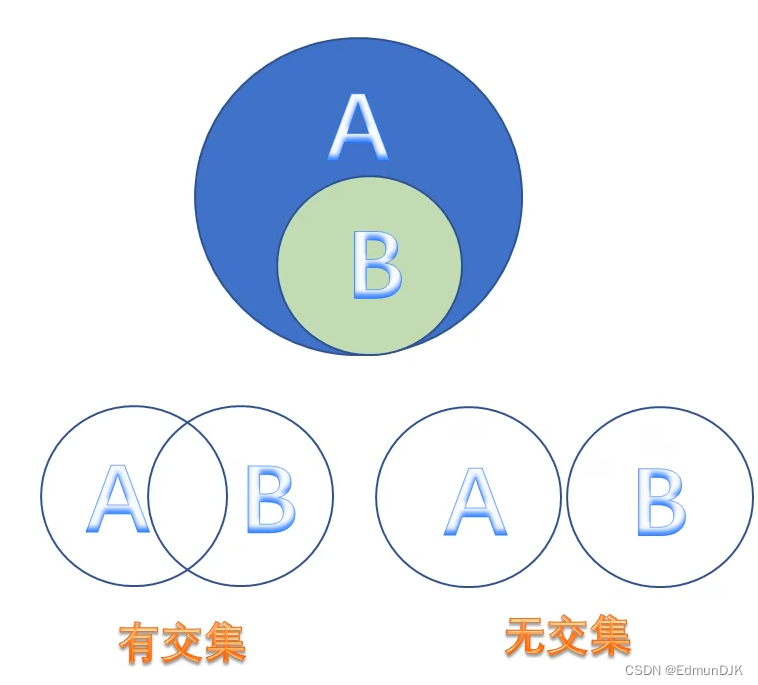
集合的数学操作

1、交集
s1={1,2,3,4}
s2={2,3,4,5}
print(s1.intersection(s2)) # {4,2,3}
print(s1 & s2) # intersection()与 & 等价,交集操作
2、并集
s1={1,2,3,4}
s2={2,3,4,5}
print(s1.union(s2)) # {4,1,5,2,3}
print(s1 | s2) # union 与 | 等价,并集操作
3、差集
s1={1,2,3,4}
s2={2,3,4,5}
print(s1.difference(s2)) # {1}
print(s1-s2) # difference 与 - 等价,差集操作
4、对称差集
s1={1,2,3,4}
s2={2,3,4,5}
print(s1.symmetric_difference(s2)) # {1,5}
print(s1 ^ s2) # symmetric_difference 与 ^ 等价,对称差集操作
7、集合生成式
用于生成集合的公式
{ i*i for i in range(1,10) }
表示集合元素的表达式 自定义变量 可迭代对象
将 {} 修改为 [] 就是列表生成式
没有元组生成式
1、列表生成式
lst=[ i*i for i in range(10)]
print(lst) # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
2、集合生成式
s={ i*i for i in range(10)}
print(s) # {0, 1, 64, 4, 36, 9, 16, 49, 81, 25}
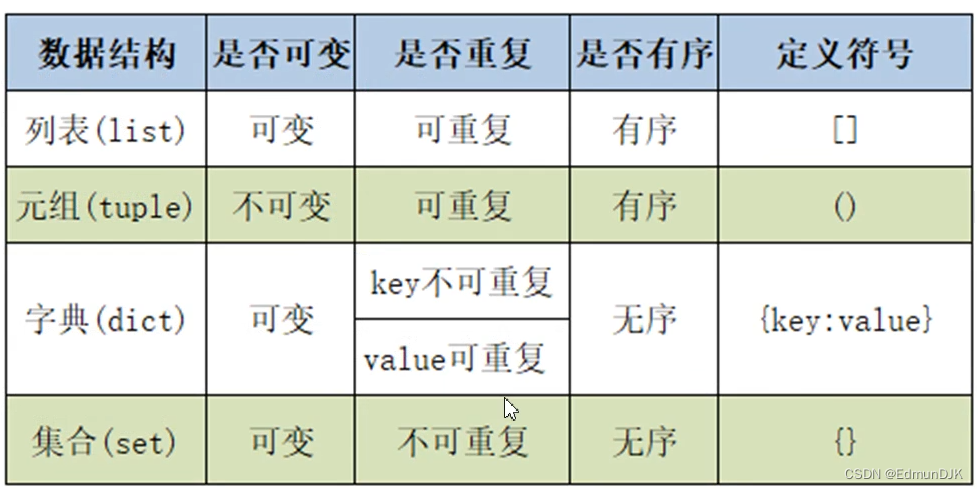
列表、字典、元组、集合总结
第九章
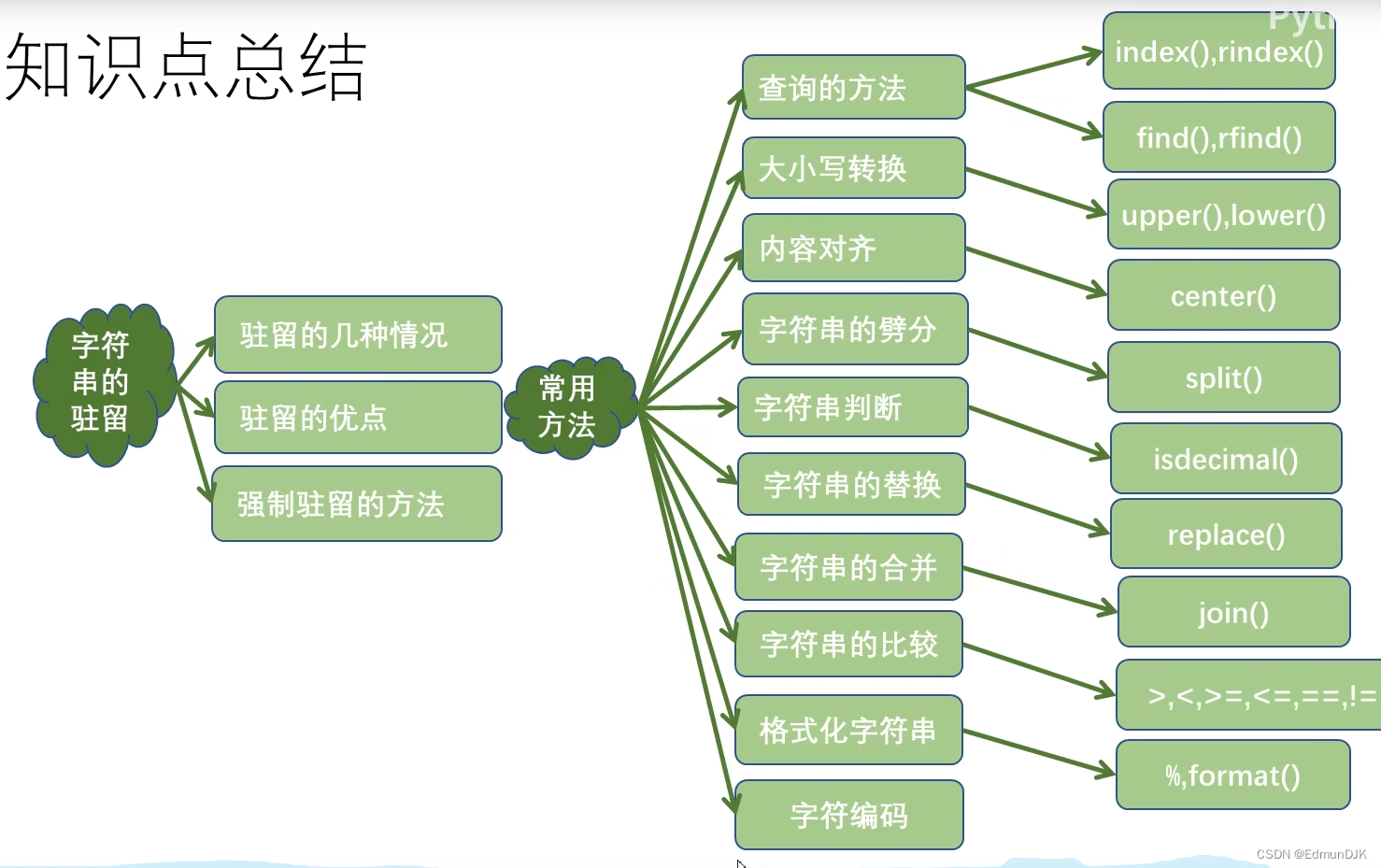
1、字符串的驻留机制
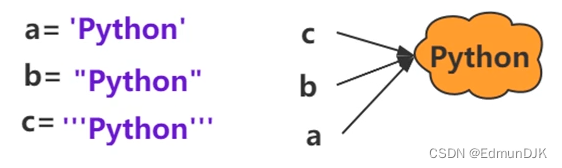
字符串:在 python 中字符串是基本数据结构,是一个不可变的字符序列
字符串驻留机制:仅保存一份相同且不可变字符串的方法,不同的值被存放在字符串的驻留池中,python 的驻留机制对相同的字符串只保留一份拷贝,后续创建相同字符串时,不会开辟新空间,而是把该字符的地址赋给新创建的变量
驻留机制的几种情况(交互模式):
1、字符串的长度为0或1时
2、符合标识符的字符串
3、字符串值只在编译时进行驻留,而非运行时
4、[ -5 , 256 ]之间的整数数字
PS:(sys 中的 intern 方法强制2个字符串指向同一个对象,PyCharm 对字符串进行了优化处理)
字符串驻留机制的优缺点:
1、当需要值相同的字符串时,可以直接从字符串池里拿来用,避免频繁的创建和销毁,提升效率和节约内存,因此拼接字符串和修改字符串是会比较影响性能的。
2、在需要进行字符串拼接时建议使用 str 类型的 join 方法,而非 + ,因为 join() 方法是先计算出所有字符中的长度,然后再拷贝,只 new 一次对象,效率要比 “+” 效率高
2、字符串的常用操作
2.1、字符串运算符
+ 字符串连接 >>>a + b 'HelloPython'
* 重复输出字符串 >>>a * 2 'HelloHello'
[] 通过索引获取字符串中字符 >>>a[1] 'e'
[:] 截取字符串中的一部分 >>>a[1:4] 'ell'
in 成员运算符 >>>"H" in a True
not in 成员运算符 >>>"M" not in a True
r/R 原始字符串 所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母"r"(可以大小写)以外。 >>>print r'\n' \n
>>> print R'\n' \n
2.2、格式化字符串
%s #字符串
%d #整数
%f #浮点数
%x #十六进制
%e #科学计数法
%c #格式化字符串及其ASCII码
%u #无符号整型
2.3、字符串的查询操作方法
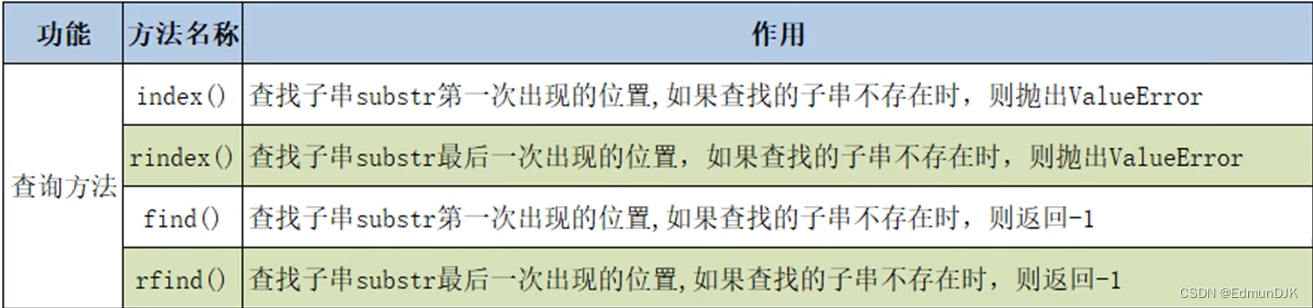
s='hello,hello'
print(s.index('lo')) # 3
print(s.find('lo')) # 3 建议使用find
print(s.rindex('lo')) # 9
print(s.rfind('lo')) # 9 建议使用rfind
2.4、字符串的大小写转换操作的方法
1、upper() #把字符串中所有字符都转成大写字母
s='hello,World'
a=s.upper()
print(a) # HELLO,WORLD
print(s) # hello,World
2、lower() #把字符串中所有字符都转成小写字母
print(s.lower()) # hello,world
3、swapcase() #把字符串中所有大写字母转换成小写字母,把所有小写字母都转成大写字母
print(s.swapcase) # HELLO,wORLD
4、capitalize() #把第一个字符转换为大写,把其余字符转成小写
print(s.capitalize()) # Hello,world
5、title() #把每个单词的第一个字符转换为大写,把每个单词的剩余字符转换为小写
print(s.title()) # Hello,World
title() #开头大写
upper() #全部字符大写
lower() #全部字符小写
rstrip() #去除末尾的空白
lstrip() #去除开头的空白
strip() #去除开头和末尾的空白
2.5、字符串内容对其操作的方法

1、center(居中对齐)
s='hello,World'
print(s.center(20,'*')) # ****hello,World*****
2、ljust(左对齐)
print(s.ljust(20,'*')) # hello,World*********
3、rjust(右对齐)
print(s.rjust(20,'*')) # *********hello,World
4、zfill(右对齐使用0进行填充)
print(s.zfill(20)) # 000000000hello,World
print('-8999'.zfill(8)) # -0008999
PS:不写填充符,默认为空格!!!
2.6、字符串的劈分操作的方法
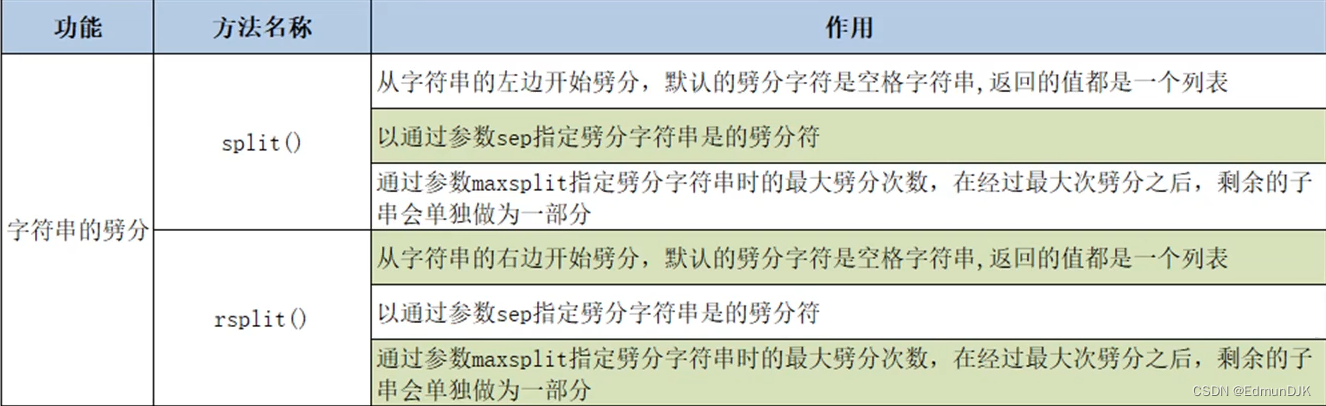
1、split (从左开始劈分)
s='hello world Python'
lst=s.split()
print(lst) # ['hello', 'world', 'Python']
s1='hello|world|Python'
print(s1.split()) # ['hello|world|Python']
print(s1.split(sep='|')) # ['hello', 'world', 'Python']
print(s1.split(sep='|',maxsplit=1)) # ['hello', 'world|Python']
2、rsplit (从右开始劈分)
s='hello world Python'
lst=s.rsplit()
print(lst) # ['hello', 'world', 'Python']
s1='hello|world|Python'
print(s1.rsplit()) # ['hello|world|Python']
print(s1.rsplit(sep='|')) # ['hello', 'world', 'Python']
print(s1.rsplit(sep='|',maxsplit=1)) # ['hello|world', 'Python']
2.7、判断字符串操作的方法
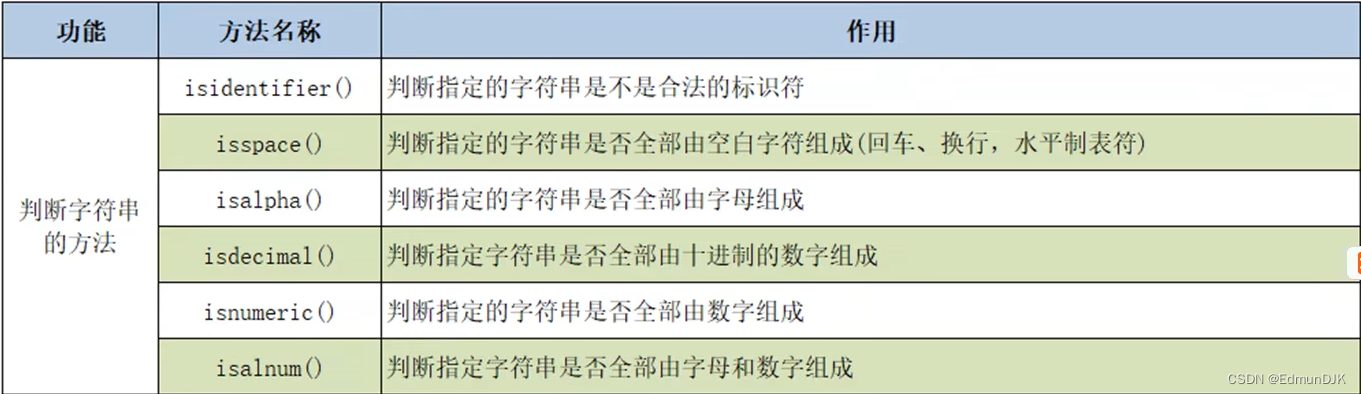
1、isidentifier
s='hello,world,Python'
print(s.isidentifier()) # False
print('hello'.isidentifier()) # True
print('你好_'.isidentifier()) # True
2、isspace
print('\t'.isspace()) # True
3、isalpha
print('abc'.isalpha()) # True
print('张'.isalpha()) # True
print('张1'.isalpha()) # False
4、isdecimal
print('123'.isdecimal()) # True
print('123四'.isdecimal()) # False
5、isnumeric
print('123四'.isnumeric()) # True
6、isalnum
print('abc123'.isalnum()) # True
print('abc张三'.isalnum()) # True
print('abc!'.isalnum()) #False
2.8、字符串操作的其他方法

1、replace
s='hello,world'
s1='hello,world,world,world'
print(s.replace('world','python')) # hello,python
print(s1.replace('world','python',2)) # hello,python,python,world
2、join
lst=['hello','world','python']
print('|'.join(lst)) # hello|world|python
print(''.join(lst)) # helloworldpython
t=('hello','world','python')
print(''.join(t)) # helloworldpython
3、字符串的比较
字符串的比较操作:
运算符: > >= < <= == !=
比较规则:
比较两个字符串中的第一个字符,如果相等则继续比较下一个字符,依次比较下去,直到两个字符串中的字符不相等时,其比较结果就是两个字符串的比较结果,两个字符串中的所有后续字符将不再被比较
比较原理:
两个字符进行比较时,比较的是其 ordinal value(原始值),调用内置函数 ord 可以得到指定字符的 ordinal value。与内置函数 ord 对应的是内置函数chr,调用内置函数chr时指定 ordinal value 可以得到其对应的字符
print('ap'>'a') # True
print('a'>'b') # False
print(ord('a'),ord('b')) # 97 98
PS:== 与 is 的区别: == 比较的是 value,is 比较的是 id 是否相等
4、字符串的切片操作
字符串是不可变类型:1、不具备增删改等操作 2、切片操作将产生新的对象
s='hello,world'
s1=s[:5] #由于没有指定起始位置,所以从零开始切
s2=s[6:] #由于没有指定结束位置,所以切到字符串的最后一个元素
print(s1) # hello
print(s2) # world
'''切片'''
变量名=切片对象[start:end:step]
print(s[1:5:1]) # ello 从1开始截到5(不包含5),步长为1
print(s[::2]) # hlowrd 默认为0开始,默认字符串最后一个元素结束,步长为2,两个元素之间的索引间隔为2
print(s[::-1]) # dlrow,olleh 默认从字符串的最后一个与元素开始,到字符串的第一个元素结束,步长为负数
print(s[-6::1]) # ,world 从索引为-6开始,到字符串的最后一个元素结束,步长为1
5、格式化字符串
格式化字符:按一定格式输出的字符
%作占位符:
name='xxx'
age=18
print('我是%s,今年%d岁'%(name,age)) # 我是xxx,今年18岁

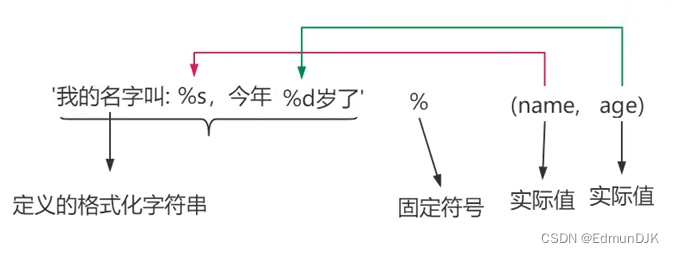
{} 作占位符:
name='xxx'
age=18
print('我叫{0},今年{1}岁'.format(name,age)) # 我叫xxx,今年18岁

f-string 作占位符:
name='xxx'
age=18
print(f'我叫{name},今年{age}岁') # 我叫xxx,今年18岁
print('%10d' % 99) #' 99' 10表示的是宽度
print('%.3f'%3.1415926) #'3.142'.3表示的是小数点后三位
#同时表示宽度和精度
print('%10.3f'% 3.1415926) #' 3.142' 一共总宽度为10,保留小数点后3位
print('{0:.3}'.format(3.1415926)) #3.14 .3表示的是一共是3位数字
print('{0:.3f}'.format(3.1415926)) #3.142 .3f表示的是保留3位小数
print('{0:10.3f}'.format(3.1415926))#' 3.142'同时设置宽度和精度,一共是10位,3位小数
6、字符串的编码转换
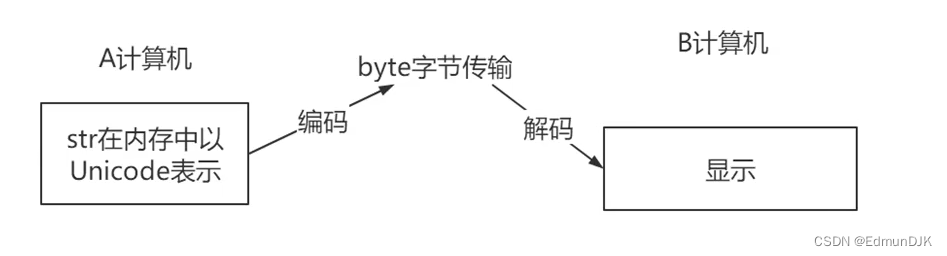
编码与解码的方式:
编码:将字符串转换为二进制数据(bytes)
解码:将bytes类型的数据转换成字符串类型
s='你好'
'''编码'''
print(s.encode(encoding='GBK')) # b'\xc4\xe3\xba\xc3' 在GBK编码格式中一个中文占两个字节
print(s.encode(encoding='UTF-8')) # b'\xe4\xbd\xa0\xe5\xa5\xbd' 在UTF-8编码格式中,一个中文占3个字节
'''解码'''
#byte代表就是一个二进制数据(字节类型的数据)
byte=s.encode(encoding='GBK')
print(byte.decode(encoding='GBK'))
 ## 第十章
## 第十章
1、函数的创建和调动
2、函数的参数传递
3、函数的返回值
4、函数的参数定义
5、变量的作用域
6、递归函数
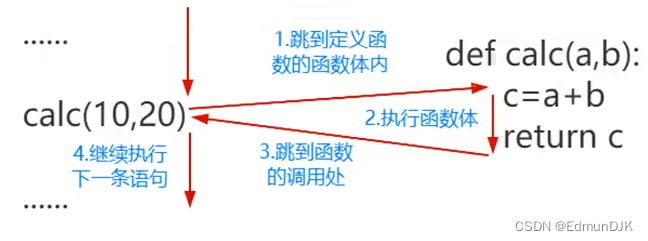
1、函数的创建和调用
函数:执行特定任务和完成特定功能的一段代码
函数的功能:1、复用代码 2、隐藏实现细节 3、提高可维护性 4、提高可读性便于调试
函数的创建:
def 函数名([输入参数])
函数体
[return xxx]
1、函数的创建
def calc(a,b)
c=a+b
return c
2、函数的调用
result=calc(10,20)
print(result)
2、函数的参数传递
函数的调用的参数传递:
1、'位置实参:根据形参对应的位置进行实参传递'
calc ( 10 , 20 )
def calc ( a , b ): # 10对应a,20对应b
------------------------------------------------------------------------
def calc(a,b): # a,b称为形式参数,简称形参,形参的位置是在函数的定义处
c=a+b
return c
result=calc(10,20) # 10,20称为实际参数的值,简称实参,实参的位置是函数的调用处
print(result)
2、'关键词实参:根据形参名称进行实参传递'
calc ( b = 10 , a = 20 )
形参名称 实参值
def calc ( a , b ): # a,b传参
-------------------------------------------------------------------------
def calc(a,b):
c=a+b
return c
qwe=calc(b=10,a=20) ## a,b称为关键字参数
print(qwe)
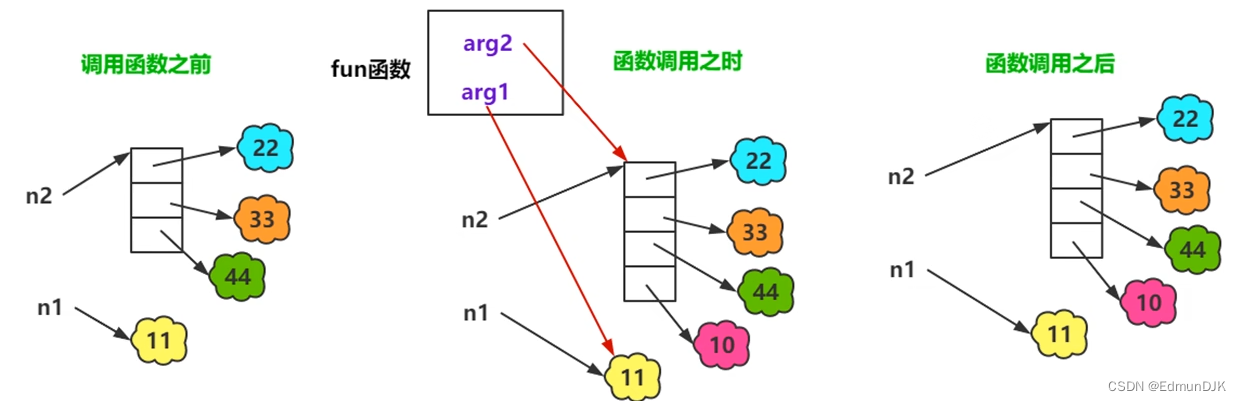
函数调用的参数传递内存分析图
def fun(arg1,arg2):
print('arg1',arg1) # arg1 11
print('arg2',arg2) # arg2 [22, 33, 44]
arg1=100
arg2.append(10)
print('arg1=',arg1) # arg1= 100
print('arg2=',arg2) # arg2= [22, 33, 44, 10]
n1=11
n2=[22,33,44]
print(n1) # 11
print(n2) # [22, 33, 44]
fun(n1,n2) # 将位置传参,arg1,arg2,是函数定义处的形参,n1,n2是函数调用处的实参,形参实参名称可以不一样
print(n1) # 11
print(n2) # [22, 33, 44, 10]
'''在函数调用过程中,进行参数的传递
如果是不可变对象,在函数体的修改不会影响实参的值 arg1的修改为100,不会影响到n1的值
如果是可变对象,在函数体的修改会影响到实参的值 arg2的修改,append(10),会影响到n2的值'''
 #### 3、函数的返回值
#### 3、函数的返回值
函数返回多个值时,结果为元组
def fun(num):
ji=[] #存奇数
ou=[] #存偶数
for i in num:
if i%2:
ji.append(i)
else:
ou.append(i)
return ji,ou
print(fun([12,57,85,64,21,46,95])) # ([57, 85, 21, 95], [12, 64, 46])
'''bool判定 0为False--偶数 非0为True--奇数
函数的返回值:
(1)如果函数没有返回值【函数执行完毕后,不需要给调用处提供数据】return可以不写
(2)函数的返回值如果是1个,直接返回类型
(3)函数的返回值如果是多个,返回的结果为元组'''
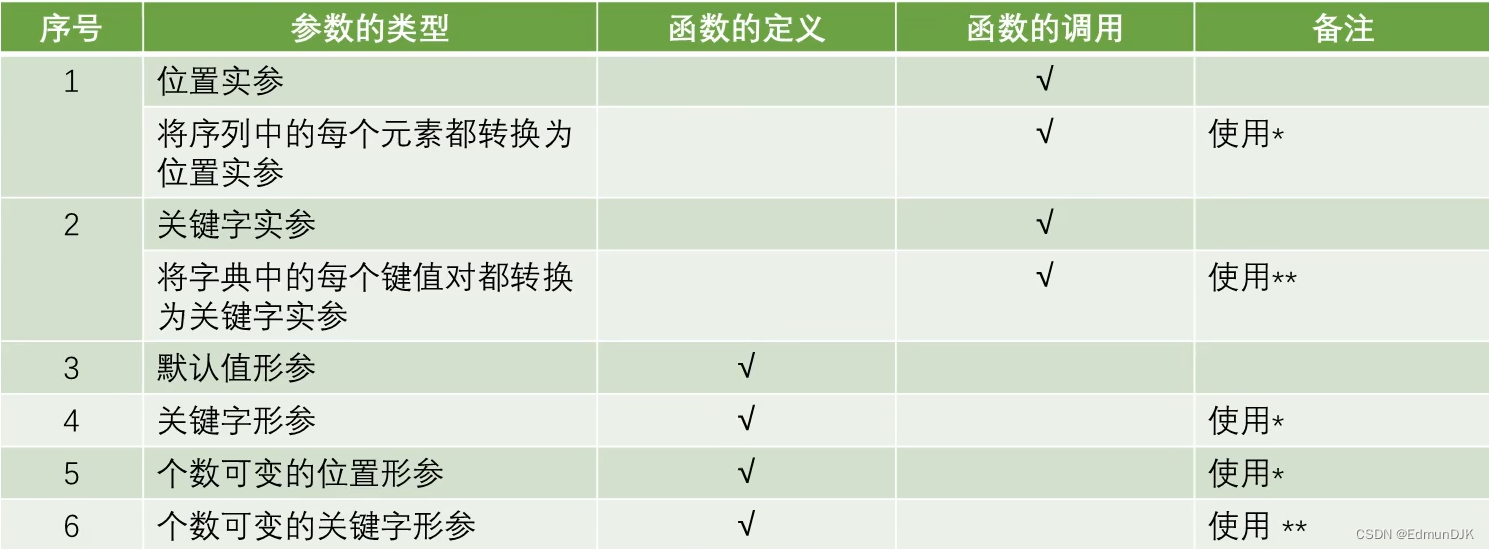
4、函数的参数定义
函数定义默认值参数:
函数定义时,给形参设置默认值,只有与默认值不符的时候才需要传递实参
def fun(a,b=10):
print(a,b)
fun(100) # 100 10 只传一个参数,b采用默认值
fun(20,30) # 20 30 30将默认值10替换
个数可变的位置参数:
定义参数时,可能无法事先确定传递的位置实参的个数,使用可变的位置参数
使用 * 定义个数可变的位置形参
结果为一个元组
def fun(*args): # 函数定义时可变的位置参数
print(args)
fun(10) # (10,)
fun(10,20,30) # (10, 20, 30)
个数可变的关键字形参:
定义函数时,无法事先确定传递的关键字实参的个数时,使用可变的关键字形参
使用 ** 定义个数可变的关键字形参
结果为一个字典
def fun(**args): #
print(args)
fun(a=10) # {'a': 10}
fun(a=10,b=20,c=30) # {'a': 10, 'b': 20, 'c': 30}
'''c,d只能采用关键字实参传递'''
def fun(a,b,*,c,d): #从*之后的参数,在函数调用时,只能采用关键字参数传递
print(a)
print(b)
print(c)
print(d)
fun(a=10,b=20,c=30,d=40) #关键字实参传递
fun(10,20,c=30,d=40) #前两个参数,采用的是位置实参传递,而c,d采用的是关键字实参传递
5、变量的作用域
程序代码能访问该变量的区域
根据变量的有效范围可分为:
1、局部变量:
在函数内定义使用的变量,只在函数内部有效,局部变量使用 global 声明,这个变量就会为全局变量
2、全局变量:
函数体外定义的变量,可作用于函数内外
def fun(a,b):
c=a+b
print(c) # c为局部变量,只在函数定义内部有效,在外调用报错
a='hello'
print(a)
def fun():
print(a) # a为全局变量,任意位置可用
def fun():
global a #使用global变为全局变量
a='hello'
print(a)
fun()
print(a) # hello
6、递归函数
递归函数:
一个函数的函数体内调用了该函数本身
递归的组成部分:
递归调用与递归终止条件
递归的调用过程:
每递归一次函数,都会在栈内存分配一个栈帧
每执行完一次函数,都会释放相应空间
递归的优缺点:
缺点:占用内存多,效率低下
优点:思路和代码简单
使用递归计算阶乘
def fun(n):
if n==1:
return 1
else:
return n*fun(n-1)
print(fun(6))
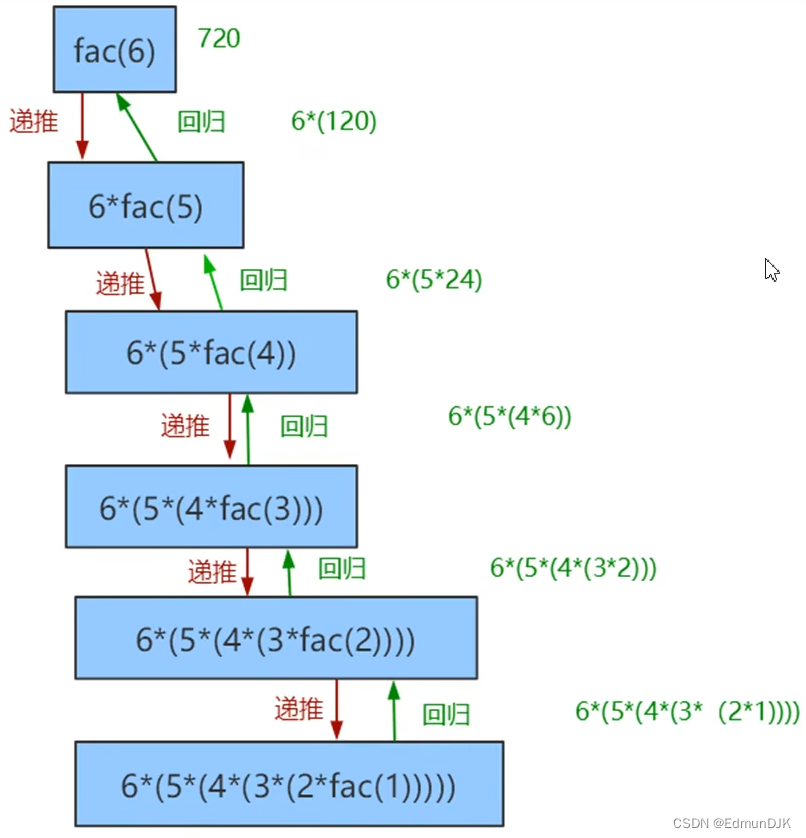
使用递归计算斐波那契数列:
def fun(n):
if n==1:
return 1
if n==2:
return 1
else:
return fun(n-1)+fun(n-2)
for i in range(1,20):
print(fun(i)) # 斐波那契数列枚举
7、数学函数
math #浮点数的数学运算函数
cmath #复数运算函数
abs #数字的绝对值 abs(-1)
fabs #数字的绝对值 math.fabs(1.9)--1
floor #向下取整 math.floor(1.9)-----1
ceil #向上取整 math.ceil(1.1)------2
pow # x**y 运算过的值
sqrt #返回了数字 a 的平方根
8、随机数函数
random() #随机生成一个实数
seed() #改变随机数生成器的种子
randrange() #按指定的基数递增的集合最终获取一个随机数
shuffle #降序列的所有元素随机排序
示例:
import random
print(random.random()) --随机小数
print(random.randint(0,10)) --随机生成整数
print(random.choice("EdmunDJK")) --随机选取字符串中的元素
print(random.sample("EdmunDJK",3)) --随机选取指定字符串元素
a=[0,1,2,3,4,5,6,7,8,9] print(random.shuffle(a)) --将序列的所有元素随机排序
9、数学常量
pi --圆周率
e --自然常数
示例:
'''猜数游戏'''
import random
a=0
i=random.randint(0,10)
while a<3:
try:
ans =int(input('请输入猜的数:'))
if(ans==i):
print("恭喜!")
break
if(ans<i):
print("less!")
a+=1
if(ans>i):
print("more!")
a+=1
except ValueError:
print("请输入标准格式!!!")
else:
print('对不起,你失败了,正确的数字为:',i)
7、文件
t #文本模式
b #二进制模式
r #只读
rb #以二进制模式打开一个文件用于只读
r+ #打开一个文件用于读写
w #打开一个文件只用于写入
w+ #打开一个文件用于读写
wb+ #以二进制模式打开一个文件用于读写
a #打开一个文件用于追加
a+ #打开一个文件用于读写
ab #以二进制模式打开一个文件用于追加
8、时间函数
time
calendar
8.1、time 库
import time
a=time.time()
print ("当前时间戳:",a)
time 模块的 strftime()方法
格式化日期
asctime()
import time
localtime=time.asctime(time.localtime(time.time()))
print("当前时间:",localtime) #输出为 当前时间: Tue Jul 19 10:21:26 2022
import time
print (time.strftime('%Y-%m-%d %H:%M:%S'))
8.2、canlendar 库
calendar.firstweekday() #返回当前每周起始日期的设置
calendar.isleap() #判断闰年
calendar.leapdays(y1,y2) #返回在Y1,Y2两年之间的闰年总数
import calendar
cal=calendar.month(2022,7)
print("输出本月日历:")
print (cal)
输出为:
输出本月日历:
July 2022
Mo Tu We Th Fr Sa Su
1 2 3
4 5 6 7 8 9 10
11 12 13 14 15 16 17
18 19 20 21 22 23 24
25 26 27 28 29 30 31
8.4、datetime
import datetime
date = datetime.date(2022,7,19)
print (date) #输出 2022-07-19
date1=datetime.date.today()
print(date) #输出当前日期
9、异常处理、断言
BaseException #所有异常的基类
Exception #常规错误的基类
StandardError #所有的内建标准异常的基类
ArithmeticError #所有数值计算错误的基类
FloatingPointError #浮点计算错误
IOError #输入/输出操作失败
OSError #操作系统错误
ValueError #传入无效的参数
TabError #Tab和空格混用
语法:
try:
<语句> #运行别的代码
except <名字>:
<语句> #如果在try部份引发了'name'异常
except <名字>,<数据>:
<语句> #如果引发了'name'异常,获得附加的数据
else:
<语句> #如果没有异常发生
10、类
class
Instance
base
subclasses
global
object
class Student(object):
pass
示例:
class Student(object):
def __init__(self,name,score):
self.name = name
self.score = score
def get_grade(self):
if self.score >=90:
return "A"
elif self.score >=60:
return "B"
else :
return "C"
x=input("请输入姓名:")
y=int(input("请输入你的成绩:"))
a=Student(x,y)
print(a.name,a.get_grade())
10.1、类变量
数据成员
局部变量
实例变量
方法重写
继承
实例化
方法
对象
__init__ 类的构造函数或初始化方法
self 类的实例 self.__class__ 指向类
内置类
__dict__ 类的属性
__name__ 类名
__bases__ 类的所有父类
__module__ 类定义所在的模板
析构函数
__del__ 对象销毁时调用
def __del__(self):
输入四个整数abcd 将四个数由小到大输出
11、正则表达式
11.1、re 模块
内置函数:
re.match()
re.search()
findall()
re.finditer()
re.sub()
re.compile()
re.split()
11.2、re.match() 函数
尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match() 就返回 none
语法:
re.match( pattern , string , flags=0 )
要匹配的字符串 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等
示例:
import re
print(re.match('www', 'www.runoob.com').span()) # 在起始位置匹配
print(re.match('com', 'www.runoob.com')) # 不在起始位置匹配 #输出为 (0, 3) None
11.3、re.search() 函数
扫描整个字符串并返回第一个成功的匹配
语法:
re.search(pattern, string, flags=0)
示例:
import re
print(re.search('www', 'www.runoob.com').span()) # 在起始位置匹配
print(re.search('com', 'www.runoob.com').span()) # 不在起始位置匹配
输出为:
<re.Match object; span=(0, 3), match='www'>
<re.Match object; span=(11, 14), match='com'>
加上 .span()后
(0, 3)
(11, 14)
11.4、re.sub() 函数
用于替换字符串中的匹配项
语法:
re.sub(pattern, repl, string, count=0, flags=0)
示例:
import re
phone = "2004-959-559 # 这是一个国外电话号码"
# 删除字符串中的 Python注释
num = re.sub(r'#.*$', "", phone)
print "电话号码是: ", num
# 删除非数字(-)的字符串
num = re.sub(r'\D', "", phone)
print "电话号码是 : ", num
输出为:
电话号码是: 2004-959-559
电话号码是 : 2004959559
11.5、re.compile 函数
用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用
语法:
re.compile(pattern[, flags])
re.I 忽略大小写
re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
re.M 多行模式
re.S 即为 . 并且包括换行符在内的任意字符(. 不包括换行符)
re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
re.X 为了增加可读性,忽略空格和 # 后面的注释
11.6、findall() 函数
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。
注意: match 和 search 是匹配一次 findall 匹配所有。
语法:
findall(string[, pos[, endpos]])
示例:
import re
pattern = re.compile(r'\d+') # 查找数字
result1 = pattern.findall('runoob 123 google 456')
result2 = pattern.findall('run88oob123google456', 0, 10)
print(result1)
print(result2)
输出为:
['123', '456']
['88', '12']
11.7、re.finditer() 函数
和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
re.finditer(pattern, string, flags=0)
示例:
import re
it = re.finditer(r"\d+","12a32bc43jf3")
for match in it:
print (match.group() )
输出为:
12
32
43
3
11.8、re.split() 函数
能够匹配的子串将字符串分割后返回列表
语法:
re.split(pattern, string[, maxsplit=0, flags=0])
12、正则表达式模式
^ #匹配字符串的开头
$ #匹配字符串的末尾。
. #匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。
re* #匹配0个或多个的表达式。
re+ #匹配1个或多个的表达式。
\w #匹配字母数字及下划线
\W #匹配非字母数字及下划线
\s #匹配任意空白字符,等价于 [ \t\n\r\f]。
\S #匹配任意非空字符
\d #匹配任意数字,等价于 [0-9].
\D #匹配任意非数字
\z #匹配字符串结束
\Z #匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。
\A #匹配字符串开始
第十一章
1、网络编程
套接字
socket
语法:
socket.socket([family[, type[, proto]]])
family: 套接字家族可以使 AF_UNIX 或者 AF_INET。
type: 套接字类型可以根据是面向连接的还是非连接分为 SOCK_STREAM 或 SOCK_DGRAM。
protocol: 一般不填默认为 0。
socket.socket(AF_INET,type)
type SOCK_STREAM
protocol
2、内建方法
'''客户端套接字'''
s.connect() #主动初始化TCP服务器连接,。一般address的格式为元组(hostname,port),如果连接出错,返回socket.error错误
'''服务器端套接字'''
s.listen() #开始TCP监听.backlog指定在拒绝连接前,操作系统可以挂起的最大连接数量.该值至少为1,大部分应用程序设为5就可以
s.accept() #被动接受TCP客户端连接,(阻塞式)等待连接的到来
s.bind() #绑定地址(host,port)到套接字, 在 AF_INET下,以元组(host,port)的形式表示地址
'''公共用途的套接字函数'''
s.close() #关闭套接字
s.recv() #接收 TCP 数据,数据以字符串形式返回,bufsize 指定要接收的最大数据量
s.send() #发送 TCP 数据,将 string 中的数据发送到连接的套接字
简单实例:
服务端:
使用 socket 模块的 socket 函数来创建一个 socket 对象。socket 对象可以通过调用其他函数来设置一个 socket 服务。
现在我们可以通过调用 bind(hostname, port) 函数来指定服务的 port(端口)。
接着,我们调用 socket 对象的 accept 方法。该方法等待客户端的连接,并返回 connection 对象,表示已连接到客户端。
'''服务端:'''
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 文件名:server.py
import socket # 导入 socket 模块
s = socket.socket() # 创建 socket 对象
host = socket.gethostname() # 获取本地主机名
port = 12345 # 设置端口
s.bind((host, port)) # 绑定端口
s.listen(5) # 等待客户端连接
while True:
c,addr = s.accept() # 建立客户端连接
print '连接地址:', addr
c.send('欢迎访问菜鸟教程!')
c.close() # 关闭连接
客户端:
简单的客户端实例连接到以上创建的服务。端口号为 12345。
socket.connect(hosname, port ) 方法打开一个 TCP 连接到主机为 hostname 端口为 port 的服务商。连接后我们就可以从服务端获取数据,记住,操作完成后需要关闭连接。
'''客户端:'''
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 文件名:client.py
import socket # 导入 socket 模块
s = socket.socket() # 创建 socket 对象
host = socket.gethostname() # 获取本地主机名
port = 12345 # 设置端口号
s.connect((host, port))
print s.recv(1024)
s.close()
练习
1、输入四个整数,将四个整数由小到大排列输出
a=int(input('请输入第一个整数:'))
b=int(input('请输入第二个整数:'))
c=int(input('请输入第三个整数:'))
d=int(input('请输入第四个整数:'))
lst=[a,b,c,d]
lst.sort()
print('又小到大为:',lst)
2、暂停一秒输出,并格式化当前时间
import time
print(time.strftime("%Y-%m-%d %H-%M-%S",time.localtime()))
time.sleep(1)
print(time.strftime("%Y-%m-%d %H-%M-%S",time.localtime()))
3、匹配 fox 字符串位置
the quick brown fox jumps over the lazy dog
s='the quick brown fox jumps over the lazy dog'
print(s.find('fox'))
import re
str = 'the quick brown fox jumps over the lazy dog'
pattern='fox'
r=re.search(pattern,str)
print(r.span())
4、查找所有的 1 (西安市第1中学1班)
s='陕西省西安市第1中学1班'
print(s.find('1'))
print(s.rfind('1'))
str='陕西省西安市第1中学1班'
pattern='1'
r=re.finditer(pattern,str)
for i in r:
print(i)
5、学生成绩查询系统
class Student(object):
def __init__(self,name,score):
self.name = name
self.score = score
def get_grade(self):
if self.score >=90:
return "A"
elif self.score >=60:
return "B"
else :
return "C"
f = open("C:/Users/九泽/Desktop/2.txt", "r",encoding=('utf8'))
lst=f.read().splitlines()
lst1=len(lst)
s=input('请输入你的姓名:')
i=0
for i in range(0,lst1):
if lst[i]==s:
x=Student(str(lst[i]),int(lst[i+1]))
print(x.name,x.get_grade())
break
else:
continue
f.close()
















 742
742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









