






python与Selenium3测试实战
HTML技术
HTML元素
1、块状元素
使用该元素的内容相对于其前后的内容另起一行,例如< p>是块状元素,浏览器会单独用一行显示该元素及其内容
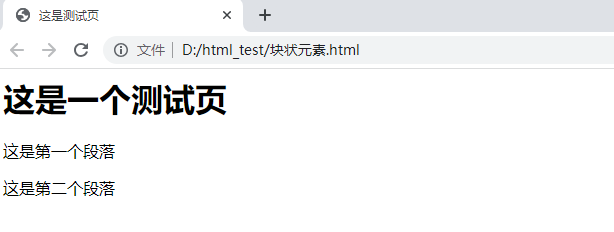
<html>
<head>
<title>这是测试页</title>
</head>
<body>
<h1>
这是一个测试页
</h1>
<p>这是第一个段落</p>
<p>这是第二个段落</p>
</body>
</html>
块状元素显示为矩形区域,常用的块状元素有div/dl/menu/dt/dd/ol/ul/h1-h6/p/form/hr/table/tr/td.块状元素可以自定义宽高,通常作为其他元素的容器,也可以实现内联元素和其他块状元素的包含操作
2、内联元素
行内元素/行间元素或者内嵌元素,内联元素在网页中的效果是该元素与其前后元素的内容在一行进行显示。例如:< b>元素和< input>元素都是内联元素,浏览器会将他们放在一行显示
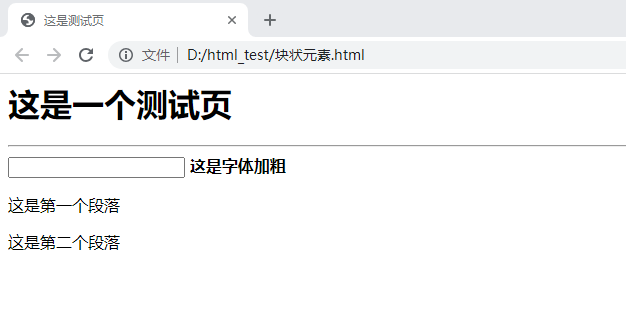
<html>
<head>
<title>这是测试页</title>
</head>
<body>
<h1>
这是一个测试页
</h1>
<hr>
<input type="text"></input>
<b>这是字体加粗</b>
<p>这是第一个段落</p>
<p>这是第二个段落</p>
</body>
</html>
内联元素就是以行内的形式逐个显示,他没有自己的形状,只能根据包含的内容来确定高和宽,最小内容单位呈矩形。常见的内联元素有a.br.select,u,sapn,i,em,strong,img,input,b等
3、可变元素
不知道是何种元素时,需要通过上下文关系来确定是块状元素还是内联元素,常见的可变元素有applet,button,script,object,map,del,ins等
HTML属性
属性是以键值对形式存在的,如name = "value"属性一般在HTML元素的开始标签中定义
1、定义标题的对齐方式
居中显示定义标题
<h1 align="center"></h1>
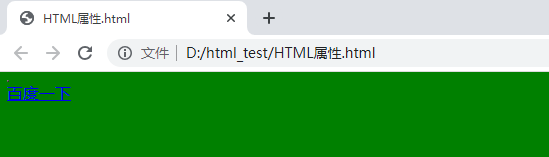
2、定义HTML文档主体背景颜色
<body bgcolor="green"></body>
3、定义表格边框
<table border="1"></table>
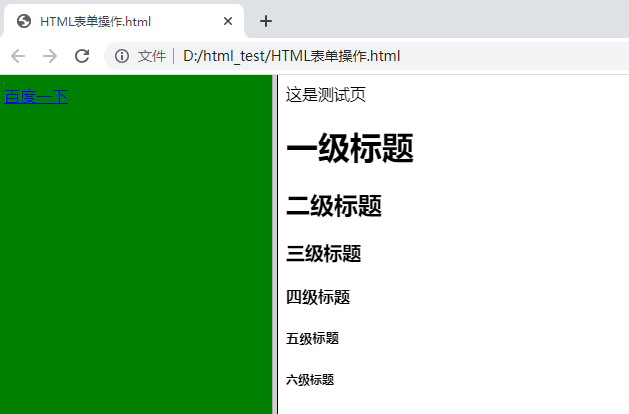
4、定义超链接
<a href="http://www.baidu.com">百度一下</a>
注意:
1、属性和属性值大于大小写不敏感
2、属性值应该始终在引号内,如果属性值本身包含双引号,那么外部就必须使用单引号,如name = ‘word “programing” hello’
HTML标题与段落
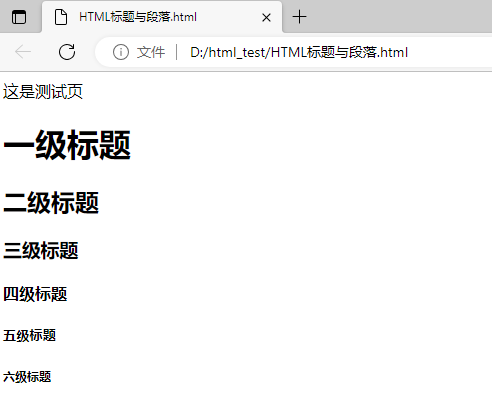
HTML六级标题
<html>
<head>这是测试页</head>
<body>
<h1>一级标题</h1>
<h2>二级标题</h2>
<h3>三级标题</h3>
<h4>四级标题</h4>
<h5>五级标题</h5>
<h6>六级标题</h6>
</body>
</html>
在HTML文档中可以通过< p>标签完成多个段落的分割操作< p>属于块状元素,使用空段落< p> < /p>完成一个空行的插入不好,应该使用</ br>标签进行换行
注释的语法格式:<! --注释文案 -->
HTML表单常用操作
HTML表单可以实现登录/注册等场景,使用< form>元素定义html表单,所有需要提交奥的数据都必须存储在< form>标签中
HTML表单中包含表单元素,其中最主要的有input,checkout,radio和select等
< input>元素是整个表单中最重要的元素,该元素有多个形态,主要由type属性决定,type常用属性值:text,password,radio,submit等
(1)type属性:text,password
<form>
用户名:<br>
<input type="text" name ="username" >
<br>
密码:<br>
<input type="password" name ="password"
</form>
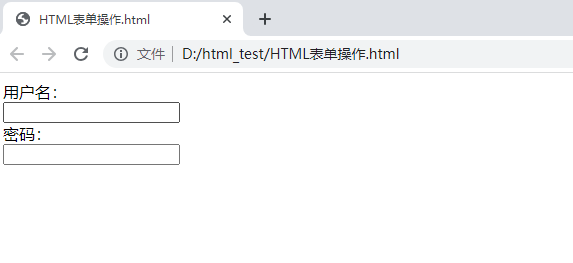
在实现登陆操作时,输入的密码一般是密文,不会以明文显示i,所以此处的type属性值是password
(2)type属性:radio
<form>
<input type="radio" name = "sex" value="male" checked>男
<br>
<input type="radio" name="sex" value="female" checked>女
</form>
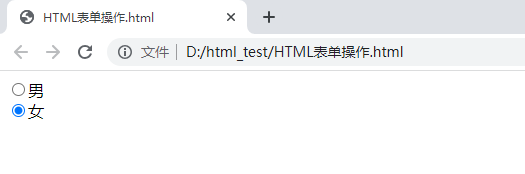
(3)type属性:submit
<form action="#">
用户名:<br>
<input type="text" name="username" value = "wood">
<br>
密码:<br>
<input type="password" name="password" value="123456">
<br><br>
<input type ="submit" value="登录">
</form>
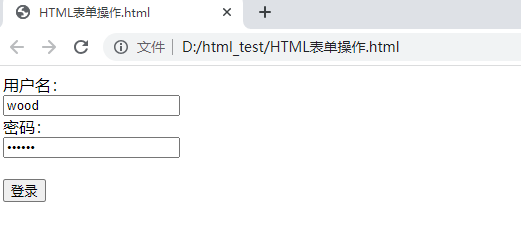
(4)action属性
<form action="/">
action属性表示在提交表单时执行的动作。通常表达会基于发送请求被提交到web服务器,然后由web服务器进行处理。如果此处省略了action属性,那么action会默认在当前页面执行动作
(5)method属性
<form action="/" method="get">或者<form action="/" method="post">
method属性表示在提交表单的时候所使用的http请求方法
HTML图像与布局
< img>标签用于定义HTML中的图片,因为< img>标签属于空标签,只包含属性,所有没有闭合标签的概念
如果要在页面显示图片,除了心意< img>标签外,还需要使用源属性src,源属性的值就是图像的url地址
定义图像的语法:<img src ="图像的所在路径 />
使用< div>元素实现HTML布局是最常用的方式,因为他能非常轻松的通过css进行对齐并定位
示例:通过三个div元素来创建多列布局
<html>
<head>
<title>
这是测试页
</title>
</head>
<body>
<h1>课程选择</h1>
<div>
<div id ="nav">
python<br>
java<br>
c<br>
</div>
<div id = "section">
<h1>木头编程</h1>
</div>
<p>
ceshi1
</p>
</div>
</body>
</html>

HTML框架
使用HTML框架的主要目的是使打开的一个浏览器选项卡不知有一个HTML文档,而是可疑包含多个,其中一个HTML文档就是一个框架,每个框架独立与其他框架
在HTML文档中,使用frame标签定义框架,还可以使用frameset标签将窗口分割为框架
示例:两列框架集,第一列浏览器窗口的30%,第二列窗口的70%
<frameset cols =30%,70%>
<frame src="HTML属性.html">
<frame src ="HTML标题与段落.html"
</frameset>
不能同时使用< body>< /body>标签与< frameset ></ frameset >标签,不过要添加包含一段文本的< noframes>标签,就必须将这段文字嵌套与< body>< /body>标签中
如果想要在网页中显示网页,可以通过iframe标签进行定义
语法:< iframe src ="隔离页面的位置“>< /iframe>
(1)设置iframe的宽度和高度
< iframe src=“https://www.baidu.com” width=“200” height=“200”> </ iframe>
使用width和height属性设置iframe的宽度和高度,属性值默认单位是像素,也可以是百分比设置
(2) 删除iframe边框
< iframe src=“iframe_1.html” frameborader = “0”>< /iframe>
frameborder属性规定是否显示iframe周围的边框,如果属性值设置为0,则表示移除边框的操作
(3)使用iframe作为链接目标
< iframe src =“iframe_1.html” name =“iframe_1”< /iframe>
< p>< a href=“http://www.baidu.com” target=“iframe_1”>百度一下< /a>< /p>
iframe可疑使用target属性实现链接目标的操作,但是target属性值必须是iframe的name属性值
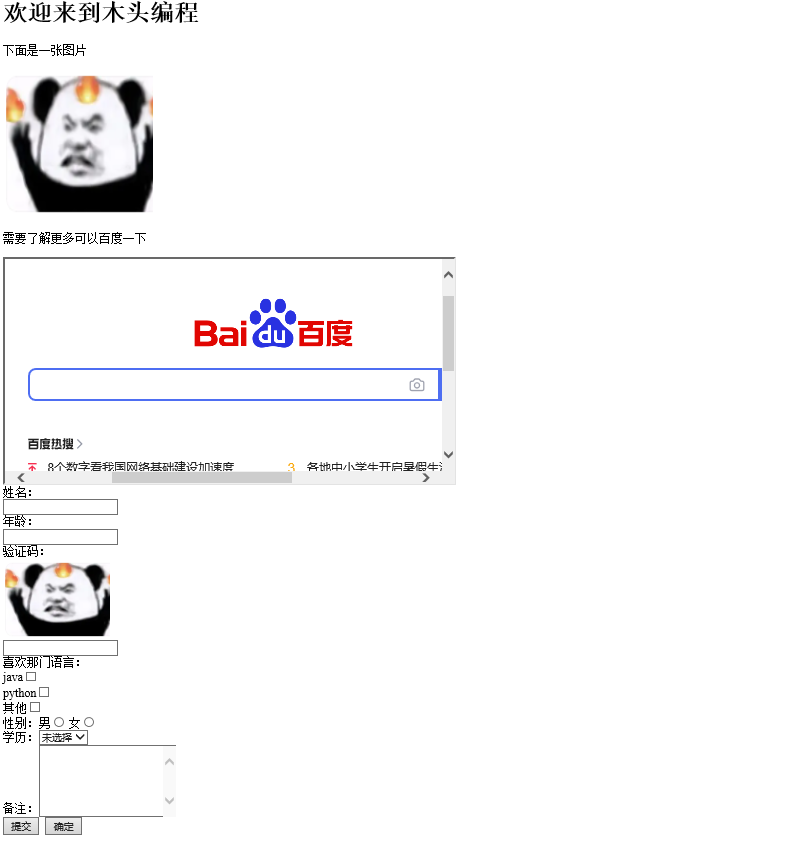
实战案例:一个静态的HTML页面
<html>
<head>
<title>综合所有要素的一个完整页面</title>
</head>
<body>
<!--这是标题-->
<div id ="header">
<h1>欢迎来到木头编程</h1>
</div>
<p>下面是一张图片</p>
<div id = "image">
<img src="D:\html_test\77a7258411f6473ab090e0f22b5e0ab1.png" height="200" width="200">
</div>
<!-- 嵌入iframe框架 -->
<p>需要了解更多可以百度一下</p>
<iframe src="http://www.baidu.com" name="iframe_1" width="600" height="300">
</iframe>
<!-- 下面做一个简单调查 -->
<form action="success" method="POST">
<!-- 输入框,密码框 -->
<div>
姓名:<br/><input type="text" /><br/>
年龄:<br/><input type="text" /><br/>
验证码:<br/><img src="D:\html_test\77a7258411f6473ab090e0f22b5e0ab1.png"/><br/>
<input type ="text" /><br/>
<div>
<!-- 复选框/单选框/下拉列表框 -->
<div>
喜欢那门语言:<br/>
java<input type="checkbox"/><br/>
python<input type="checkbox"/><br/>
其他<input type="checkbox"/><br/>
性别:男<input type="radio" name=" sex" />
女<input type="radio" name="sex"/><br/>
学历:<select>
<option>未选择</option>
<option>本科</option>
<option>大专</option>
</select><br/>
<!-- clos定义文本区域的宽度,而row定义文本区域的高度 -->
备注:<textarea clos="10" rows="6"></textarea><br/>
<!-- 按钮会触发事件,在web自动化中如果得到了元素定位却无法使用click方法,可以使用onclick执行 -->
<input type="submit" value ="提交" onclick="javascript:alert('确定提交?');"/> <input type="button" value="确定"/>
</div>
</div>
</form>
</div>
</body>
</html>
CSS技术
css层叠样式表,是一种计算机语言,主要用于表现HTML或者XML等文件样式。
css基础语法
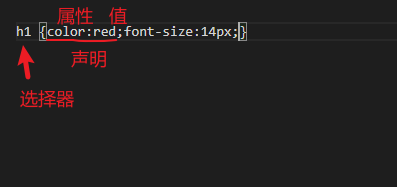
声明之间用逗号隔开,且所有的声明都必须用大括号括起来
1、值的不同定义和单位
p{color:#ff0000;}
p{color:rgb(255,0,0);}
p{color: rgb(100%,0%,0%);}
2、多重申明
如果声明不止一个,可以使用多个分号隔开多个申明
黄色居中段落
p{text-align: center;color:yellow;}
3、空格和大小写问题
css中是否包含空格对浏览器没有影响,对大小写不敏感,但是结合HTML时,class和id元素对大小写是敏感的
CSS高级语法
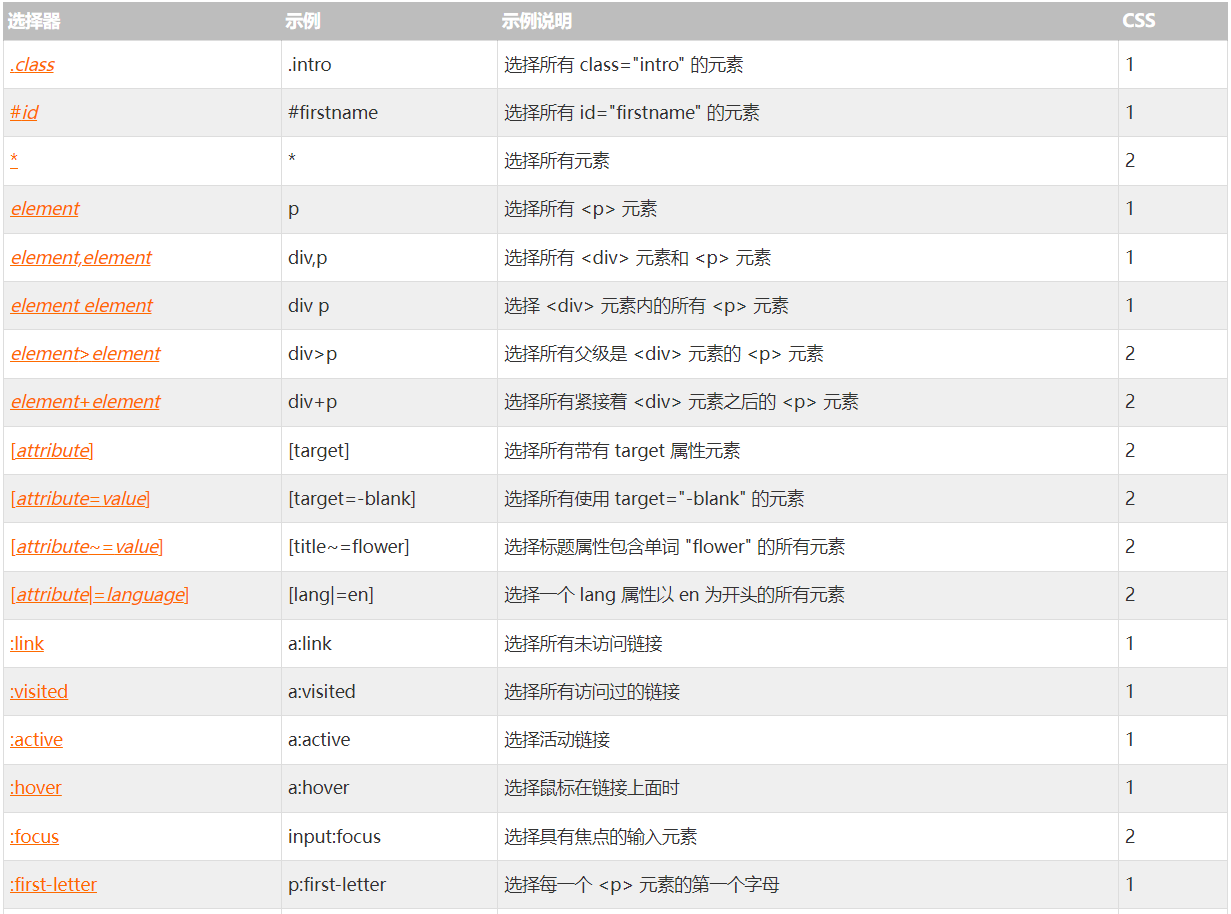
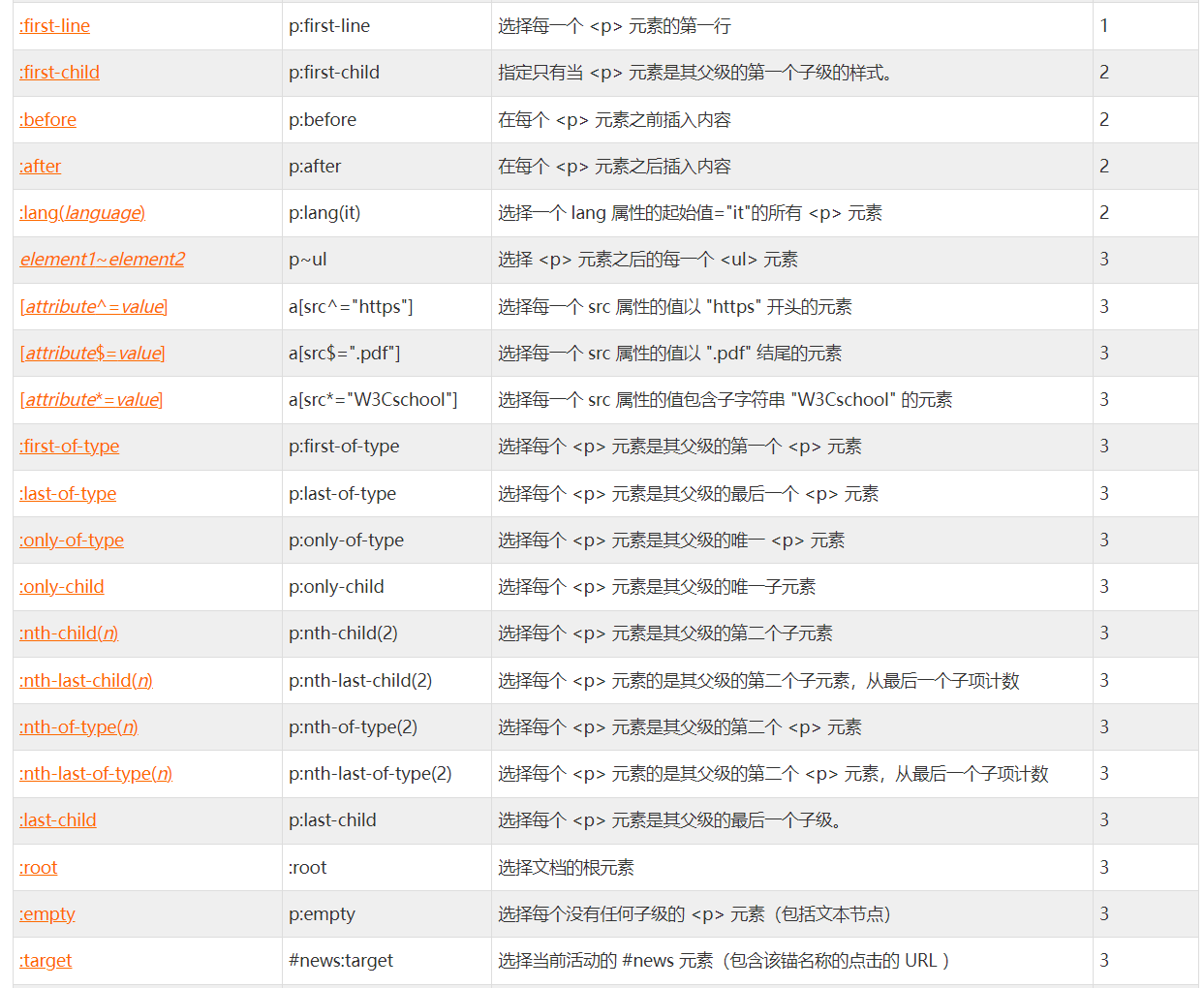
在css高级语法中,主要从一下几个方面进行考虑:选择的分组/选择器的继承继承及问题/CSS派生选择器/css后代选择器和css子元素选择器等
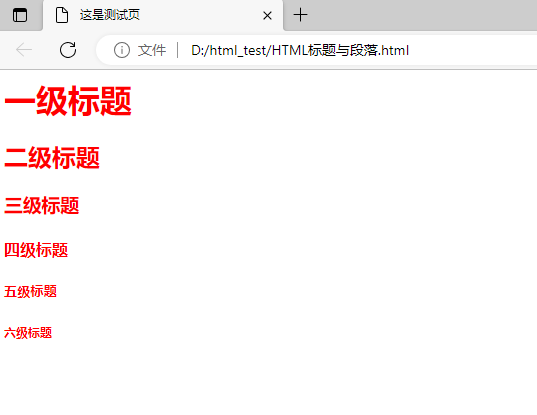
选择器的分组就是对选择器进行分组操作,被分组的选择器可以共享相同的声明,多组选择器之间使用逗号隔开即可
h1, h2, h3, h4, h5, h6 {
color: red;
}
<html>
<head>
<title>这是测试页</title>
<style>
h1, h2, h3, h4, h5, h6 {
color: red;
}
</style>
</head>
<body>
<h1>一级标题</h1>
<h2>二级标题</h2>
<h3>三级标题</h3>
<h4>四级标题</h4>
<h5>五级标题</h5>
<h6>六级标题</h6>
</body>
</html>
如果声明了父元素的样式,那么所有的子元素将使用和父元素一样的样式,考虑到浏览器的不同,为了让所有的浏览器都保持相同的样式,需要对其子元素进行声明
例如:声明父元素body的字体格式
body{
font-family: arial,sans-serif;
}
body元素使用的字体是arial,假设访问系统中存在这个字体,那么通过css继承,子元素都应该显示arial字体,子元素的子元素也是相同的
为了摆脱父元素的规则问题,可以单独针对子元素进行特殊规则的设定
p{
font-family: Times,"Times New Roman",serif;
}
有时需要根据上下文关系来定义其样式格式,此时可以通过派生学则其,一句元素的位置进行标记
例如:如果需要将列表中的strong元素的字体改为斜体,而不是通常的粗体字,就可以定义一个派生选择器
li strong{
font-style: italic;
font-weight: normal;
}
标记为< strong>元素的代码的上下文关系
<p><strong>我是粗体字,不在列表,规则不起作用</strong></p>
<ol><li><strong>斜体字,因为strong元素在li元素内</strong></li>
<li>正常字</li></ol>

在元素之间存在以下关系,如:父元素/子元素/祖先元素/后代元素/兄弟元素等,选中指定的元素作为后代元素,就是后代选择器
其语法是:祖先元素 后代元素{}
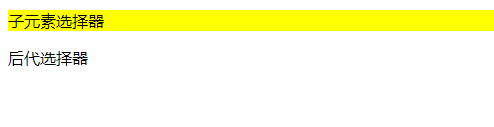
如果选中指定父元素作为指定元素,那么就是子元素选择器·
语法:父元素>子元素
例:声明一个后代选择器,元素为h1和em,其属性颜色值是红色,声明一个子元素选择器,元素是div和ul,其属性颜色也是红色
div>ul{color:red}
h1 em{color: red;}
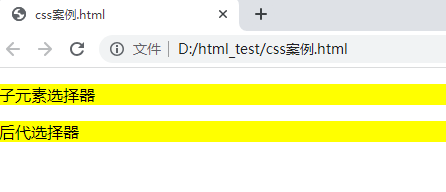
直接应用案例
后代选择器div.p效果
<!DOCTYPE html>
<html>
<head>
<style>
div p{
background-color: yellow;
}
</style>
</head>
<body>
<div>
<p>子元素选择器</p>
<span><p>后代选择器</p></span>
</div>
</body>
</html>
<!DOCTYPE html>
<html>
<head>
<style>
div>p {
background-color: yellow;
}
</style>
</head>
<body>
<div>
<p>子元素选择器</p>
<span><p>后代选择器</p></span>
</div>
</body>
</html>
实战案例:编写css样式并应用到HTML页面
链接:https://pan.baidu.com/s/1Q0hJV6uwDPJ1S8Jyqvyxpg
提取码:oajv
Selenium基础
基于web的ui自动化测试工具,支持跨平台,多语言
selenium家族
selenium框架组成:selenium IDE、seleniumRC、selenium WebDriver、selenium Grid
seleniumIDE是一个可以通过录制操作完成基本脚本构建的工具,拥有简单易用的界面,火狐浏览器的一个插件,可以录制用户的基本操作,生成测试脚本,可直接在浏览器回放,也可以转换成各种语言导出
selenium RC:使用编程语言创建复杂的测试,由client libraries和selenium server组成,client libraries主要通过编写测试脚本来控制selenium server库,而selenium server主要控制浏览器
selenium webdriver其实就是selenium RC的升级版,基于rc进行的再次封装
selenium grid 用于运行不同的及其,不同的浏览器进行并行测试,目的是加快测试用例的执行速度,从而减少测试运行的速度
安装selenium及selenium IDE
安装selenium
(1)直接在DOS窗口运行pip install selenium
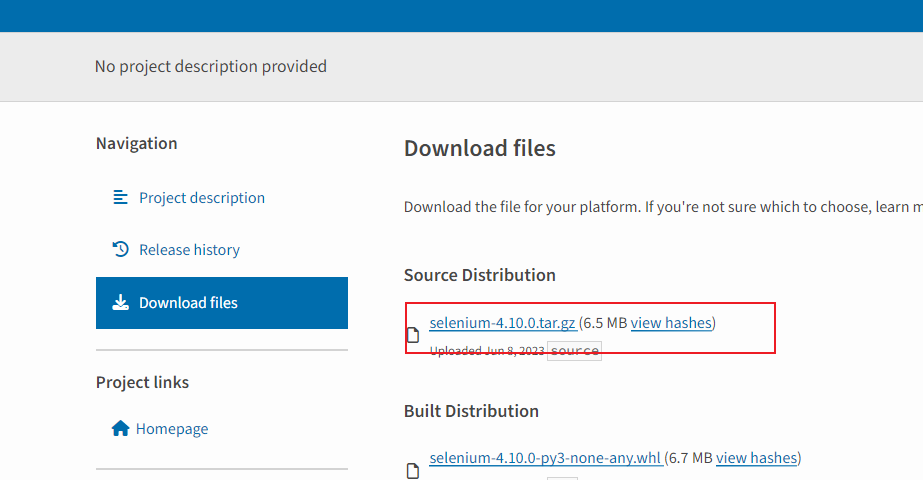
(2)下载源码安装,选择扩展名为gz的源码包进行下载
https://pypi.org/project/selenium/#files
下载后解压,在DOS环境下切换到setup.py文件所在的目录,运行python setup.py install 命令进行安装
(3)直接通过pycharm集成工具进行安装,打开pycharm,选择file,单击settings,进入页面,选择projectinterpreter,单击+搜索selenium,选中并单机installpackage即可
安装seleniuIDE
因为这个是一个插件,可以再火狐浏览器选择添加插件
在搜索到的结果中进行安装
浏览器驱动
需要使用那个浏览器完成自动化,就需要获取该浏览器官方提供的对应版本的驱动
各个主流浏览器的驱动程序下载和安装地址:
Chrome浏览器驱动(ChromeDriver):
下载地址:http://chromedriver.storage.googleapis.com/index.html
安装方法:将下载的 chromedriver 执行文件放在系统的 PATH 路径下,或者将其路径配置到 webdriver.Chrome() 的 executable_path 参数中。
Firefox浏览器驱动(geckodriver):
下载地址:https://github.com/mozilla/geckodriver/releases
安装方法:将下载的 geckodriver 执行文件放在系统的 PATH 路径下,或者将其路径配置到 webdriver.Firefox() 的 executable_path 参数中。
Edge浏览器驱动(Microsoft WebDriver):
下载地址:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
安装方法:将下载的 MicrosoftWebDriver 执行文件放在系统的 PATH 路径下,或者将其路径配置到 webdriver.Edge() 的 executable_path 参数中。
Safari浏览器驱动(SafariDriver):Safari驱动程序是Safari浏览器自带的驱动,不需要单独下载和安装。
仅支持macOS上的Safari浏览器。
注意要启用开发模式: Safari > Preferences > Advanced > Show Develop menu in menu bar。
在菜单栏中的Develop选项中,选择Allow Remote Automation。
Opera浏览器驱动(OperaDriver):
下载地址:https://github.com/operasoftware/operachromiumdriver/releases
安装方法:将下载的 operadriver 执行文件放在系统的 PATH 路径下,或者将其路径配置到 webdriver.Opera() 的 executable_path 参数中
selenium的第一个脚本
from selenium import webdriver
get_driver = webdriver.Chrome()
get_driver.get("https:www.baidu.com")
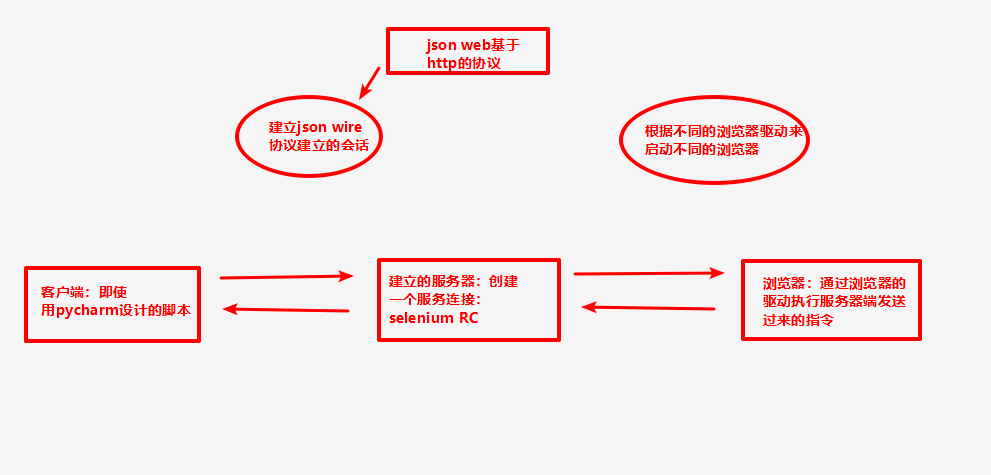
selenium运行原理
客户端(pycharm设计的脚本)发送请求,基于jsonwire格式的协议创建一个绑定特定端口的会话链接,相当于服务器
服务端又根据不同的浏览器驱动来启动不同的浏览器,浏览器不同的类型,不同的版本有不同的驱动,此时服务器会将客户端发过来的事件指令通过驱动在浏览器中完成,浏览器操作完成之后将这些结果返回服务端
selenium元素定位
浏览器查找元素的方法
在一个网页中快速找到id属性,可以使用浏览器提供的开发者工具来辅助查找。
以下是使用Chrome浏览器的步骤:
打开Chrome浏览器并访问您要查找id属性的网页。
右键点击要查找的元素,然后选择“检查”或“审查元素”选项。也可以使用快捷键Ctrl + Shift + I(Windows)或Cmd + Option + I(Mac)来打开开发者工具。
在开发者工具中,会显示一个类似于Inspector的窗口。光标会自动定位到对应的元素上。
在开发者工具上方的工具栏中,可以找到一个放大镜图标,通常被称为“选择元素”工具(Hover over the element)或是直接在元素标签的开头有一个选择(Inspect an element…)。点击它(或直接用快捷键Ctrl + Shift + C)来启用鼠标指向元素并高亮显示的模式。
鼠标指向您要查找id属性的元素上,该元素将被高亮显示,并且在开发者工具的代码视图中,将会显示该元素对应的 HTML 代码。
在代码视图中,定位到高亮显示的元素标签,查找其id属性即可。
使用此方法,您可以快速定位到网页中的元素并找到其id属性。请注意,不同的浏览器可能会略有差异,但基本原理是相似的。
id定位
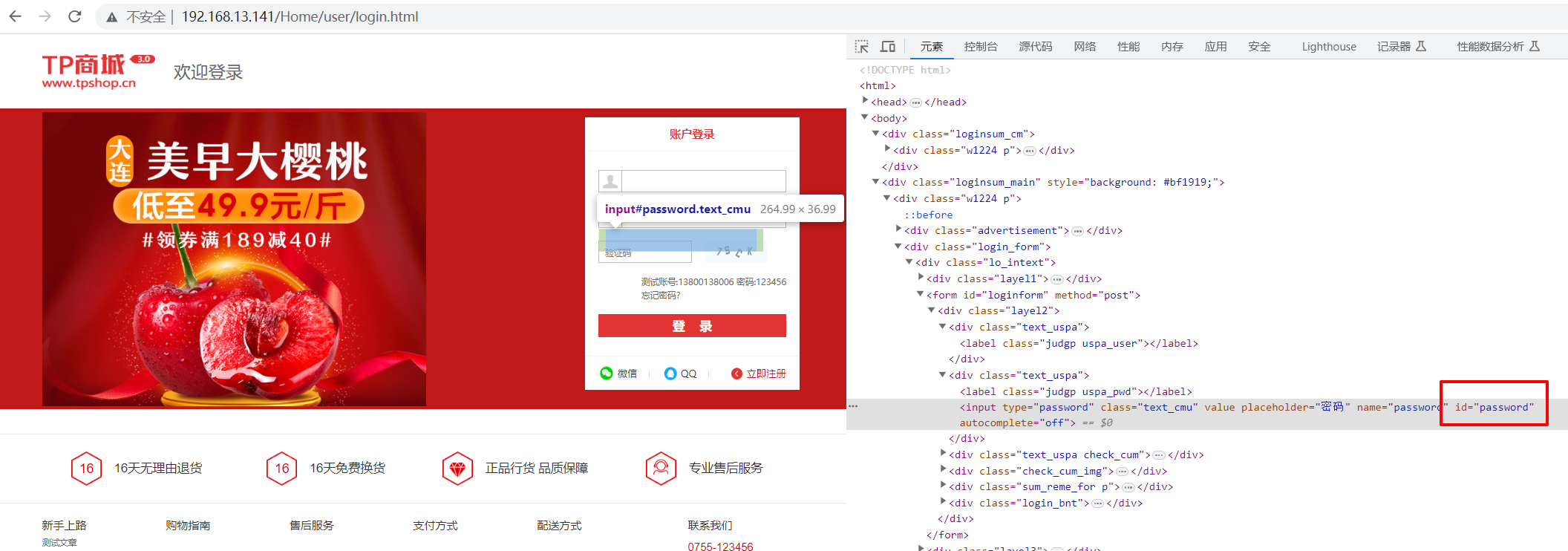
webdrive提供的id定位就是通过元素的id属性或通过firebug查找deidaoid的相关信息,id属性是HTML中唯一的,类似于元素的身份证号码,webderive的id定位方法就是通过元素的id属性来查找元素的,如:driver,find_element_by_id(“findwd”),找到标签为id、属性值为findpwd的元素
from selenium import webdriver
# 创建webdriver对象
driver = webdriver.Chrome()
# 打开网页
driver.get("http://192.168.13.141/Home/user/login.html")
# 使用id定位元素并进行操作
element = driver.find_element_by_id("password")
element.click()
# 关闭浏览器
driver.quit()
name定位
name定位方式将识别首个name属性等于定位值的页面元素,如果多个元素的name属性值相同,那么可以使用过滤器来进一步细化,默认的过滤器类型是value(也就是value属性)
driver.find_element_by_name(“username”)
from selenium import webdriver
# 创建webdriver对象
driver = webdriver.Chrome()
# 打开网页
driver.get("http://192.168.13.141/Home/user/login.html")
# 使用id定位元素并进行操作
element = driver.find_element_by_name("verify_code")
element.click()
# 关闭浏览器
driver.quit()

class_name定位
driver.find_element_by_class_name(“logindo”)
from selenium import webdriver
# 创建webdriver对象
driver = webdriver.Chrome()
# 打开网页
driver.get("http://192.168.13.141/Home/user/login.html")
# 使用id定位元素并进行操作
element = driver.find_element_by_class_name("login_bnt")
element.click()
# 关闭浏览器
driver.quit()

tag_name定位
通过标签的名称来定位元素的位置,这种定位方法比较困难,同一个页面中相同名称的标签往往比较多
driver.find_element_by_tag_name(“input”)
from selenium import webdriver
# 创建webdriver对象
driver = webdriver.Chrome()
# 打开网页
driver.get("http://192.168.13.141/Home/user/login.html")
# 使用id定位元素并进行操作
element = driver.find_element_by_tag_name("input")
element.click()
# 关闭浏览器
driver.quit()

link_text定位
link_text专门用来定位文本连接
driver.find_ellement_by_link_text(“忘记密码”)
使用a标签中链接的文字内容来定位页面上的具体元素,其中使用link_text定位页面的html的代码元素
from selenium import webdriver
# 创建webdriver对象
driver = webdriver.Chrome()
# 打开网页
driver.get("http://192.168.13.141/Home/user/login.html")
# 使用id定位元素并进行操作
element = driver.find_element_by_link_text("忘记密码?")
element.click()
# 关闭浏览器
driver.quit()

partial_link_text定位
partial_link_text是link_text的一种补充,有些文本链接较长时,可以提取文本链接的一部分进行定位,只要这一部分信息可以唯一标识出这个链接
element = driver.find_element_by_partial_link_text(“忘记”)
xpath定位
xpath定位方式由XML(可扩展标记语言,也是由一系列标签构成,主要实现数据交换)和path两部分构成,以xml格式的树状结构进行递归逐级定位
xpath定位两种方式:绝对路径定位、相对路径定位
绝对路径:从顶级符标签到当前标签的整个路径结构称为绝对路径。在使用绝对路径的时候,如果同级中存在多个相同标签,则通过索引进行具体选择,索引值从1开始,只要页面稍微发生变动整个定位就会失败。
相对路径:表示相对于当前标签而言的路径结构。常用的定位方式:
1、属性定位语法://标签名[@属性名=属性值]
标签名可以具体,也可以使用*(表示任意标签,定义的范围会比较广,可能会定义出多个对象)
属性值如果是字符串,需要使用引号
2、使用逻辑运算符可以实现多个属性定位,逻辑运算符有and/or/not,例如://input[@name=“username” and @pwd=“upasswd”],但是一般的组合属性不会超过2个,因为设定的属性越多,对脚本的依赖性就越高
3、嵌入函数完后xpath定位
(1)text函数定位语法://标签名[contains(@属性名,对应属性名的部分值)]
(2)contains函数定位语法://标签名[contains(@属性名,对应属性名的部分值)]
(3)start-with函数定位语法://标签名[start-with(@属性名,对应属性名的前面的部分值)]
(4)ends-with函数定位语法://标签名[end-with@(属性名,对应属性名的后面部分值)]
一般start-with end-with函数能完成的,contains函数也能完成
实例代码:
element = driver.find_element_by_xpath(“//button[text()=‘登录’].click”)
element = driver.find_element_by_xpath(“//button[contains(@class,‘login’)]”).click()
element = driver.find_element_by_xpath(“//button[start-with(text(),‘登’)]”.click())
css定位
CSS定位主要是通过选择器来完成的,这属于css的高级定位
css定位于xpath定位的使用时同等重要的,两者有很对类似的地方,但是无论是从性能还是语法上来说,css还是比较有优势的
css定位中选择器的常用语法
element = driver.find_element_by_css_selector(“div:nth-child(3) a”)
在上述代码中,div:nth-child(3) 表示选择 < div> 元素下的第三个子元素,然后 a 表示选择该子元素内的 < a> 元素。
可以将这个代码应用到您的 Selenium 脚本中,通过 driver.find_element_by_css_selector() 找到对应的元素。
这个选择器会选择下述 HTML 结构中的 < a> 元素:
<div> <!-- 第一个 div 元素 -->
<p>Paragraph</p>
<span>Span</span>
<a href="https://example.com">Link 1</a>
</div>
<div> <!-- 第二个 div 元素 -->
<p>Paragraph</p>
<span>Span</span>
<a href="https://example.com">Link 2</a>
</div>
<div> <!-- 第三个 div 元素 -->
<p>Paragraph</p>
<span>Span</span>
<a href="https://example.com">Link 3</a> <!-- 被选择的 <a> 元素 -->
</div>
elements复数定位
上述的8种基本定位方式,分别对应的复数形式
find_elements_by_id()
find_elements_by_name()
find_elements_by_class_name()
find_elements_by_tag_name()
find_elements_by_link_text()
find_elements_by_partial_link_text()
find_elements_by_xpath()
find_elements_by_css_selector()
通过复数定位的方法获取得到的返回值都是一组元素对象,其返回的是一个列表数据类型,可以通过索引取出想要的元素对象,然后通过该对象完成对应的操作
例:百度首页,有相同的class,定位视频
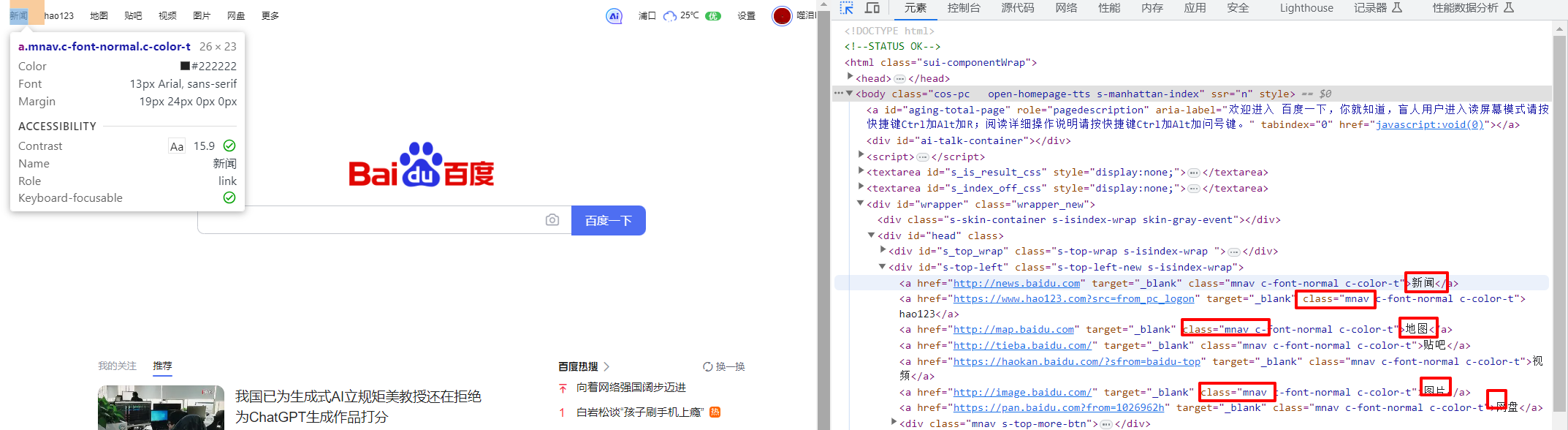
driver.find_elements_by_class_name(“mnav”)[6].click()
css的复数定位:
driver.find_elements(“css selector”,“.mnav”)[6].click()
可借助pop()函数,一般pop()或者pop(-1)表示获取元素中的最后一个,pop(2)表示第三个
driver.find_elements(“css selector”,“.mnav”).pop().click()
by定位
具体语法:
element =find_elementt(BY.ID,“kw")
element = driver.find_element(By.NAME, “element_name”)
element = driver.find_element(By.TAG_NAME, “tag_name”)
element = driver.find_element(By.CLASS_NAME, “class_name”)
element = driver.find_element(By.LINK_TEXT, “link_text”)
element = driver.find_element(By.PARTIAL_LINK_TEXT, “partial_link_text”)
element = driver.find_element(By.XPATH, “xpath_expression”)
element = driver.find_element(By.CSS_SELECTOR, “css_selector”)
实际上find_by_id方法就是对find_element(BY.ID,“id的属性值”)方法进行了二次封装,便于直接调用
注意在使用上述定位方式的时候需要导入by类
from selenium.webdriver.common.by import By
父子定位、二次定位
父子定位:如果当前标签或者子级标签不存在任何属性可以作为定位方式,则可以查找当前标签的父标签是否存在可以定位的属性,如果父级还没有,则继续向上一级查找,依次类推,知道找到可定位的标签
二次定位:可以先定位到可定位的以及标签获取对象,然后再通过该对象作为基准再次定位
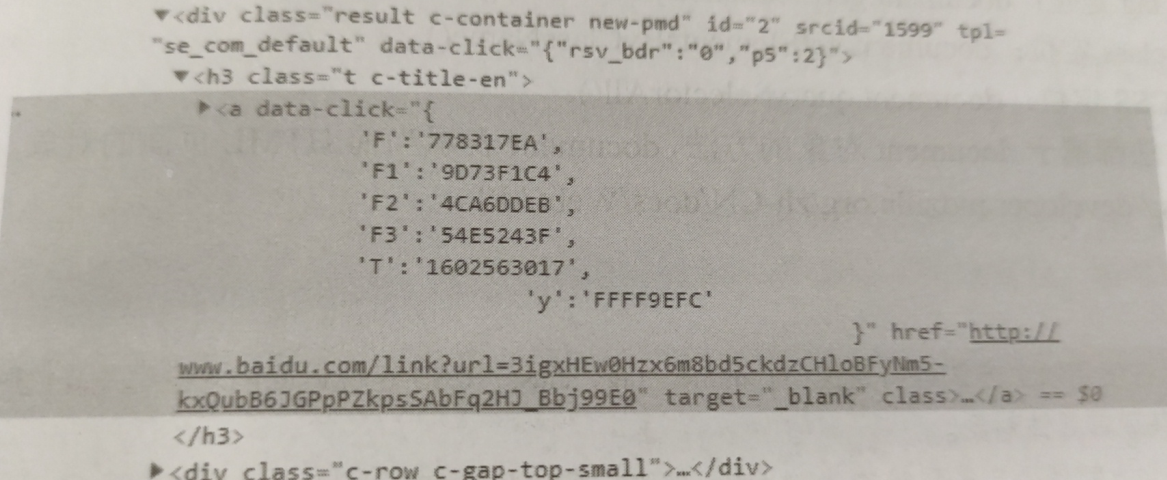
get_dril.find_element_by_xpath("//h3[contains(@class,'c-titile-en')]")'find_element_by_xpath("//a").click()
# 当前级中没有属性可以定位,则可以寻找上一级父标签进行定位,然后再接子标签,注意父标签属性是否与其他标签相同
# 多观察当前标签周围标签的属性
get_dril.find_element_by_xpath(//div[@id=2]/h3/a").click()
js定位
JS定位实际上是使用DOM树的定位方式(DOM树表示的是树形展示的层级结构)
document.getElementById(“su”)
以上代码和浏览器的console控制台的定位方式一致
Document.getElementById(“su”)
< input type=“submit” id=“su” value =“百度一下” class =”bg_s_btn">
常用的几种定位方式:
document.getElementById(“elementId”)
document.getElementsByClassName(“className”)
document.getElementsByTagName(“tagName”)
document.querySelector(“selector”)
document.querySelectorAll(“selector”)
document对象的方法,document表示当前HTML页面的对象,具体的api参考:https://developer.mozilla.org/zh-CN/docs/Web/API/
在使用以上方法时,name/tag/class/css定位返回的随想都是复数形式,所以需要通过索引来获取具体的对象
文本复制使用改的是该方法的value属性,如果是按钮则直接使用click()方法
如果已通过定位元素获取了对应的对象,但是该对象无法直接完成某些事件的操作,则可以通过该对象调用该标签中声明的操作事件的属性值(js骄脚本完成),然后使用execute_script执行即可
例:
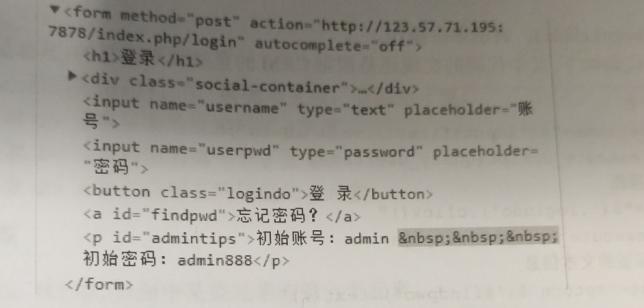
username_js="document.getElementsByName('username')[0].value='wood';"
username_js2="document.getElementsByTagName('input')[0].value='wood';"
button_js="document.getElementById(findpwd').click()"
button_js2="document.getElementsByClassName('logindo')[0].click()"
driver.excute+_script(username_js2)
driver.excute+_script(button_js2)
jQuery定位
常见的 jQuery定位方法有两种,一种是通过 jQuery选择器来完成元素的选择操作,可以直接获取一个或者一组元素,另外一种是它通过jQuery遍历来选择元素
jQuery语法实际是为了HTML元素的选择进行设置,不仅可以完成定位,还可以对元素完成一些操作
基础语法:
$(selector).action()
通过$进行定义,selector选择器主要用于获取具体的html元素,而action()用于实现对获取的元素的具体操作
常用操作:
$(selector).val(‘input_value’) :input_value表示要输入的文本
$(selector).val("):如果为空,则执行后是清空的意思
$(selector).click():表示单击操作
# 定位用户名
querry_username ="$('input:first').val('admin')"
get_dir.excute_script(query_username)
# 定位登录按钮
query_js="$('.logoindo).click()"
get_dir.excute_script(query_js)
# 获取对应标签的文本信息
query_text ="return $('#findpwd').text();"
print(get_dir.excute_script(query_text))
# 可以使用css样式中的表示方式,获取属性值href的值
get_script="""return $('div[id="3]>h3>a').attr("href")"""
print(get_dir.excute_script(get_script))
jQuery常用方法总结



隐藏元素如何操作
通过js脚本定位到该元素,获取对应的元素对象,然后通过removeAttribute和setAttribute两个方法完成属性的删除或者重新赋值操作,使得当前的属性属于显示状态,即可完成操作

selenium操作浏览器
浏览器前进操作
forward():在初始操作时,不存在前进操作,一般与back配合使用
back:后退操作(当前对象必须有上下文)
浏览器的最大化、最小化、全屏
窗口最大化操作
import time
from selenium import webdriver
get_driver = webdriver.Chrome()
# 打开网页
get_driver.get("http://www.baidu.com")
from selenium import webdriver
# 最大化浏览器窗口
get_driver.maximize_window()
time.sleep(2)
# 关闭浏览器
get_driver.quit()
get_driver.minimize_windows():实现窗口最小化操作
get_driver.fullscreen_window():实现窗口全屏操作
浏览器close和quit方法的区别
close表示关闭当前对象所处页面(操作页面)的窗口,quit表示关闭所有的页面窗口并关闭驱动器,如果只存在一个窗口,其效果是一样的
浏览器的相关属性获取
print(get_driver.current_url) # 获取当前对象的url地址
print(get_driver.current_window_handle) # 获取当前对象的句柄
print(get_driver.title) # 获取当前对象的标题
print(get_driver.window_handles) # 获取当前对象的所有句柄(选项卡)
浏览器句柄操作
驱动器对象.switch_to_window(句柄名):这种方法属于保留方法,不建议适应,句柄名可以通过先获取所有的句柄然后定义其索引的方式获取
浏览器中的alert框操作
需要使用switch_to.alert先切换到alert对象中,让后调用对应的方法执行,accept()方法表示确定;dissmiss()方法表示取消,也可以获取其文本内容,调用text属性即可
浏览器的滚动条操作
无法直接定位,需要使用js脚本完成操作
指定上下滚动的高度,此种浏览器滚动条可能会因为浏览器的类型不同。版本不同环境不同而失败

scrolllnto view 方法中默认值是true,表示滚动到的元素作为第一行进行显示;同样可以设置为false如果false值则表示指定元素,作为最后一行进行显示
webelement接口常用方法:

WebDriver API及对象识别技术
鼠标键盘模块
1、鼠标事件
api方法都封装在ActionChains类中
from selenium.webdriver.common.action_chains import ActionChains
常用的鼠标事件对应的api方法
context_click():右击
double_click():双击
drag_and_drop():拖动
move_to_element():鼠标悬停在一个元素上
click_and_hold():按下鼠标左键在一个元素上
具体实例:
(1)context_click():右击

(2)drag_and_drop():拖动

(3)move_to_element():鼠标悬停

2、键盘事件


键盘事件可以使用上/下建乘以随机产生的数来完成向上或者向下的选择,具体的实现代码如下
get_driver.find_element_by_name(“area”).send_keys.ARROW_DOWN*3)
多个iframe处理
frame标签右frameset/frame.iframe三种类型,其中frameset和其他普通标签没有区别,不会影响到定位,frame与iframe对selenium定位而言是一样的
1、如何切换frame
switch_to.frame(param)
param表示传入的参数,该参数可以是iframe元素的id/name/index等属性,还可以是该iframe所返回的selenium的webelement对象,假设有以下网页index.html

定位切换其中的iframe
from selenium import webdriver
get_driver.switch_to_frame(0) # 打开frame的索引来定位,第一个是0
get_driver.switch_to_frame("frame1") # 使用id的值来定位
get_driver.switch_to.frame("myframe") # 使用name值来定位
# 使用webdriverelement对象来定位
# get_driver.switch_to.frame(get_driver.find_element_by_id('frame1'))
一般情况下,如果iframe存在id和name属性,则使用这两个属性可以直接定位,但是有些场景前面段的frame框架中不一定存在这两个属性,就需要index和webelement来完成定位操作
(1) idex 的值是从0开始的,传入整型参数即表示使用 index 来进行定位,但是如果定位入的是 String 类型,则表示使用 id、name 来进行定位。
(2)WebElement 对象,即用 find element 系列方法所取得的对象,可以用 tag_name、XPath.父子定位等方式来定位 frame 对象。
< iframe src=“mywoodframe.html”/>
用x-path定位,传入webelement对象
get_driver.switch_to,frame (get driver.find element by xpath("//iframe (contains (@src,‘wood’) ) ") )
2、从frame中切回主文档
如果切换至 fame,则不能继续操作主文档的元素。如果需要操作主文档元素,则必须完成文档与 frame 的切换操作
self.get driver.switch to.default content()
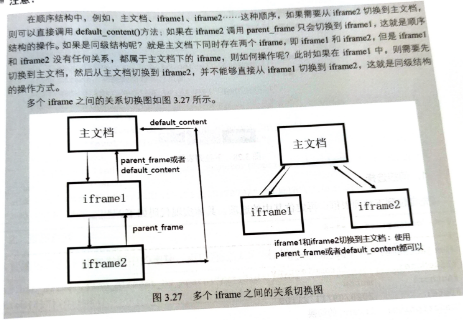
3、嵌套frame的操作
<htm1>
<iframe id="iframel">
<iframe id="iframe2" />
</iframe>
</html>
(1)先从主文档切换到 iframel,然后从 iframel 切换到 frame2,一层层切过去
self.get_driver.switch to.frame(“iframel”)
self.get driver.switch to.frame(“iframe2”)
(2)从 ifame2 再切换回 ifamel,这里 Selenium 提供了一个方法能够从子 iframe 切回父iframe,而不用先切回主文档再切回来
self.get_driver.switch_to.parent_frame()
有了parent_frame()相当于有了后退的方法,就可以切换不同的frame3
下拉列表框的多种实现方式
1、间接选择
下定位到下拉列表框,在定位到其中的选项
2、直接选择
直接定位到下拉列表框中的选项
from selenium import webdriver
# 启动浏览器驱动
driver = webdriver.Chrome()
# 导航到页面
driver.get("https://example.com")
# 直接定位到下拉列表框中的选项
option = driver.find_element_by_xpath("//select[@id='dropdown']/option[text()='Option 1']")
# 输出选项文本
print(option.text)
# 关闭浏览器驱动
driver.quit()
3、select模块
select_by_index():通过索引定位(从0开始)
select_by_value():通过value值定位
select_by_visible_text():通过选项的文本值定位
from selenium import webdriver
from selenium.webdriver.support.select import Select
# 启动浏览器驱动
driver = webdriver.Chrome()
# 导航到页面
driver.get("https://example.com")
# 定位下拉列表框元素
dropdown = driver.find_element_by_id("dropdown")
# 创建 Select 对象
select = Select(dropdown)
# 通过文本选择下拉列表框中的选项
select.select_by_visible_text("Option 1")
# 通过索引选择下拉列表框中的选项(索引从0开始)
select.select_by_index(2)
# 通过值选择下拉列表框中的选项
select.select_by_value("value2")
# 关闭浏览器驱动
driver.quit()
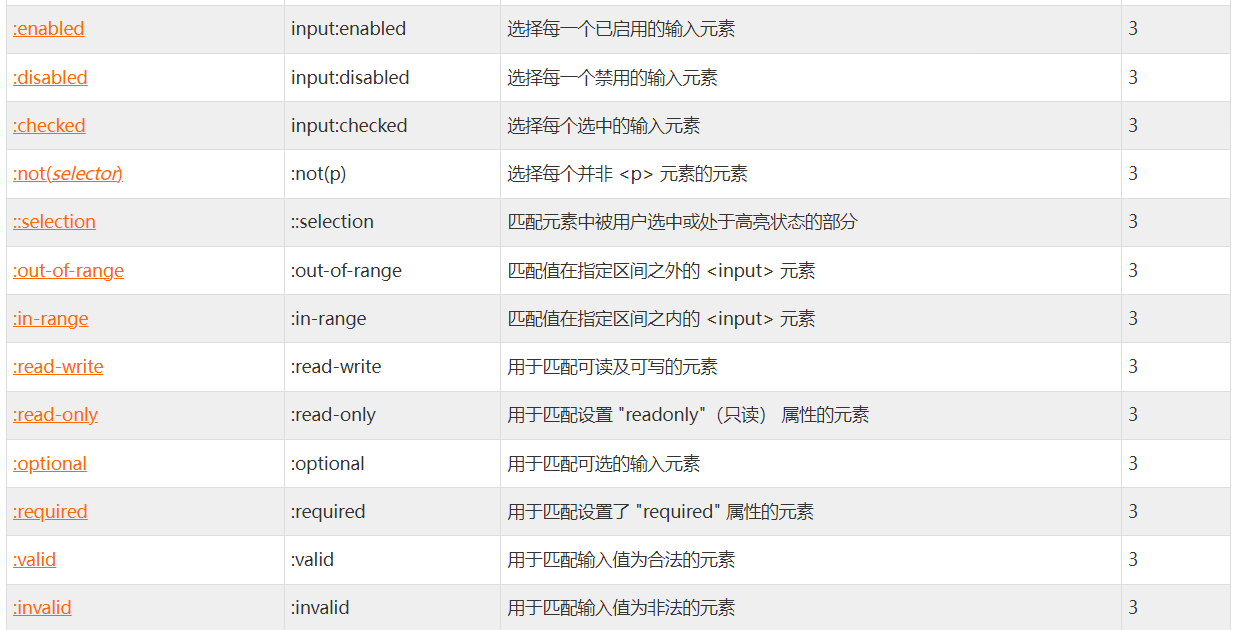
4、select模块提供了四种取消选中项的方法
deselect_all:取消了全部的已选择项
deselect_by_index:取消已选择中的索引项
deselect_by_value:取消已选择的value值
deselect_by_visible_text:取消已选中的文本值
三种元素的等待方式
1、强制等待
语法:time.sleep(x),表示等待x秒后,进行下一步操作,直接使用内置的time模块的sleep方法即可
如果存在多行,则需要每行设置休眠操作
2、隐式等待
语法:driver.implicitly_wait(x),等待x秒后,进行下一步操作,implicitly_wait(x)方法直接通过使用浏览器驱动对象进行调用
隐形等待对整个脚本的生命周期都起作用,所以只需要设置一次
3、显式等待
WebDriverWait表示显式等待,主要对单个元素设置一定的频率,使其按频率刷新当前页面并检测是否存在该元素可从ui包中导入,也可从wait包中导入
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support.ui import WebDriverWait
参数:
driver:传入当前驱动器对象
timeout:设定刷新页面的超时时间,即等待的最长时间
poll_frequency:传入页面刷新频率,默认0.5s
ignored exceptions:表示忽略异常。如果没有定义为默认值,若页面无法找到元素的异类型对象,则抛出NoSuchElementException 异常。
这个模块中共有两种方法:until与untilnot。
method:传入的对象只能是两种,一种是匿名函数另一种是预置条件对象expected conditiommessage:当执行 until或者 until not 方法出现超时时会抛出TimeoutException 异常,并message 信息传入异常。until 表示直到指定某元素出现或某些条件成立才继续执行,until则表示直到某元素消失或者指定的某些条件不成立才继续执行
可以引用selenium提供的expected_conditions
from selenium.webdriver.support import expected_conditions as Ec


(By.XPATH,“//*[@id=‘ul’]/a[8]”))).click()
文件上传与下载
1、文件上传
如果定位的上传的按钮是一个input标签则可以使用普通上传,将本地文件的路径作为一个值放在input标签中,通过from表单提交时将这个值提交给服务器,也就是此时输入框的标签必须是input
#将一个文件的绝对路径写入上传输入框
get_driver.find_element_by_name(‘file’).send_keys(‘需要上传的文件的路径’)
如果定位的上传功能未使用 imput 标签,则可以使用专门用于Windows 操作的自动化测试工具 AutoIT 编写代码完成操作。AutoIT是一款实现 WindowsGUI窗口的第三方扩展库,也是一款强大的脚本开发语言。通过 AutoT 编码可以将其转换成 exe 格式后使用Selenium中的os模块完成可执行文件的运行操作。
AutoIT 可以通过官网进行下载,官网地址:https://www.autoitscript.com/site/。
可以通过AutoIT Window Info 的组件完成元素的定位操作,然后使用 SciTE Script Editor 组件完成auto 上传文件的编码操作,编码完成后,需要通过Compile Script toexe 组件完成au3 后缀文件的转换操作,最后转换成以.exe 为后缀的文件。
AutoIT上传文件的具体代码如下
#聚焦一个Windows窗口
# 传入参数controlID的值对应ClassNameNN
ControlFoucs("打开","","Edit1")
#设置窗口等待时间
WinWait("打开","",5)
# 将文件路径写入指定的文本框
ContorlSelectText("打开","","Edit1",$CmdLine[1])
# 最后单击打开
ContralClick("打开","打开(&O)","Button1")
上述代码使用 SciTE Script Editor 组件编码后,保存为文件 upfile.au3。下面通过 CompileScript to.exe 组件进行转换,转换后的文件为 upfile.exe。最后使用 Selenium 中的os 模块完成文件的上传操作,具体代码如下
get_path = os.path.dirname (os .path.abspath( file ))+" imagepython.png"
get_driver.find_element_by_name('file').click() #单击上传文件按钮
os.system("upfile.exe %s"gget_path) #上传本地文件
SCmdLine[1]表示在执行 exe 文件时可以携带一个参数,表示将第一个参数值传入此处。所以可以使用该命令完成文件参数化操作,并不需要设定固定的值。在调用 Sclenium 的 os 模块时,只需要传入一个文件所在的具体路径参数,这样就更加灵活方便了
2、文件下载
(1)Firefox 文件下载。如果使用火狐浏览器进行文件下载,则需要对 FireFoxProfile0进行相关的设置操作。配置信息如下。
browser.download.foladerList: 该选项值如果设置为 0,则表示下载到浏览器的默认下载路径;如果设置为 2,则可以保存到指定的目录。
browser.download.manager.showWhenStarting: 表示是否显示开始,其值只有 True 和 False:其中 True 为显示开始,Flase 为不显示开始。
browser.download.dir: 主要用于指定下载文件的所在目录。
browser.helperApps.neverAsk.saveToDisk:表示对所给文件类型不再进行弹框询问
from selenium import webdriver
import os
#对火狐浏览器的下载参数进行设置
fp = webdriver.FirefoxProfile()#设置成 0代表下载到浏览器的默认下载路径,设置成 2 则可以保存到指定的目录
fp.set preference("browser.download.folderList",2)#True 为显示开始,Flase 为不显示开始
fp.set preference("browser.download.manager.showhenStarting",True)
<!--browser.download.dir 指定文件下载路径,os.getcwd()返回当前目录; 综合即指将文下载到脚本所在目录-->
fp.set preference("browser.download.dir",os.getcwd())
ip.set preference ("browser,helperApps.neverAsk.saveToDisk", "applaction/octet-stream")
#下载文件类型
dr = webdriver.Firefox(firefox profile = fp) #将设置参数传给浏览器
dr.get("https://pypi.org/project/selenium/#files")
dr. find element by xpath ("//* [@]/div[3) /table/tbody/tr[3]/td[1]/span/a[1]") .click()
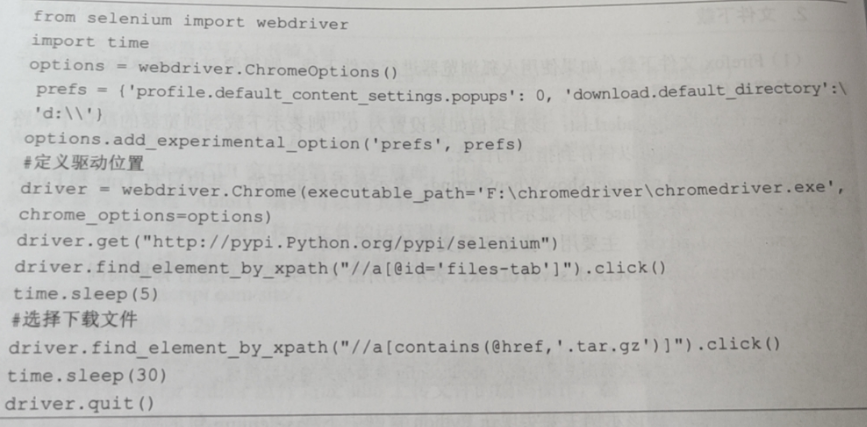
(2)Chrome 文件下载。同样的,如果使用谷歌浏览器完成下载,也需要完成相应的设置如指定下载目录、禁止弹窗等。download.default_directory’:C:/Users/Administrator/Desktop/test/,表示指定下载目录。
profile.default_content_settings,popups: 通常将该选项的值设置为0,表示禁止弹出窗口。
profile.default_content_setting_values.images: 通常将该选项的值设置为 2,表示禁止图片加载。
具体示例代码如下,同样是实现 selenium 包的下载操作。
验证码处理的多种实现方式
1、去掉验证码
去掉验证码操作是所有实现验证码处理方法中最简单的。对于开发人员而言,只需要将与验证码功能相关的代码进行注释即可。当然,此方法如果是在测试环境中还是可以实现的,但是针对生产环境,就不能够轻易地去掉了,因为这样会存在一定的风险。
2.设置万能码
在生产环境中如果去掉验证码,必然存在安全问题。为了能够解决在线系统的安全性问题可以不注释验证码功能,只需让开发人员在程序中声明一个万能验证码,该验证码只提供给自动化测试人员,用户是无法获取的。这样,程序就可以使用万能验证码通过验证,从而完成自动化操作。
3.只保留一个资源
如果是图片资源,实际就是在指定的文件夹资源库中随机抽取一张,只需要将服务器上的所有图片全部删除只留一张,相当于固定验证码。
4.光学字符识别
光学字符识别实际就是通过 Python-tesseract 模块来智能识别图片中的验证码。Python-tesseract表示光学字符识别 Tesseract OCR引擎对应的 Python 封装类,它能够读取任何常规的图片文件,如 JPG、GIF、PNG、TIFF 等。现如今由于验证码的形式繁多,所以光学字符识别率是非常低的。
5.打码平台识别
通过主流的打码平台完成,如斐斐、超人、图鉴等。
6.记录 cookie如果登录页面存在验证码,还可以在浏览器中添加登录成功时所携带的 cookie 来跳过登录,这是比较有意思的一种实现方式。例如,在第一次登录某网站时可以勾选“记住密码”的选项,当下次再访问这个网站时就自动处于登录状态了。这样其实也绕过了验证码问题,这个“记住码”其实就将密码记在了浏览器的 cookie 中。在 Selenium 中可以通过 add cookie0方法将用名、密码的登录信息写入浏览器的 cookie 中,当再次访问网站时服务器只需读取浏览器的
实现光学字符识别
引用第三方模块pytesseract,具体步骤:
pip install pytesseract
pip install Pillow
安装OCR识别库
https://github.com/UB-Mannheim/tesseract/wiki
安装时直接单击下一步,但是安装完成后必须将其根目录添加到path环境变量中
完成上述配置步骤操作后,就可以实现简单识别了。简单识别的一般思路就是通过图片降噪、图片切割,最后输出图像文本等。其中图片降噪的含义就是将图片中一些不需要的信息全部去除,如背景、干扰像素、干扰线等,只留下需要识别的文字,所以让图片变成二进制点阵最好。
如果验证码是彩色背景,其实是把每个像素都放在了一个五维的空间里,这五个维度分别是X、Y、R、G、B,其中X、Y 代表的就是这个像素的二维平面坐标,R、G、B 代表的就是这个像素所对应的颜色。
例如,处理以下验证码图片,如图 3.32 所示





















 2092
2092











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









