







目录
一、Lambda 表达式
1、Lambda 表达式的标准格式
- ( 形式参数 ) -> { 代码块 }
- 形式参数:如果有多个参数,参数之间用逗号隔开;如果没有参数,留空即可
- ->:由英文中画线和大于符号组成,固定写法。代表指向动作
- 代码块:是我们具体要做的事情,也就是以前我们写的方法体内容
2、Lambda 表达式的使用前提
使用前提:
- 有一个接口
- 接口中有且仅有一个抽象方法
3、Lambda 表达式的练习
练习一
- 定义一个接口(Eatable),里面定义一个抽象方法:void eat()
- 定义一个测试类(EatableDemo),在测试类中提供两个方法
- 一个方法是:useEatable(Eatable e)
- 一个方法是主方法,在主方法中调用 useEatable 方法
代码如下:
public interface Eatable {
void eat();
}public class EatableDemo {
public static void main(String[] args) {
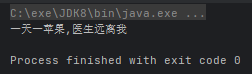
useEatable(() -> {
System.out.println("一天一苹果,医生远离我");
});
}
private static void useEatable(Eatable e) {
e.eat();
}
}运行结果:
练习二
- 定义一个接口(Flyable),里面定义一个抽象方法:void fly(String s)
- 定义一个测试类(FlyableDemo),在测试类中提供两个方法
- 一个方法是:useFlyable(Flyable f)
- 一个方法是主方法,在主方法中调用 useFlyable 方法
代码如下:
public interface Flyable {
void fly(String s);
}public class FlyableDemo {
public static void main(String[] args) {
useFlyable((String s) -> {
System.out.println(s);
});
}
public static void useFlyable(Flyable f) {
f.fly("风和日丽,晴空万里");
}
}运行结果:

练习三
- 定义一个接口(Add able),里面定义一个抽象方法:int add(int x, int y)
- 定义一个测试类(AddableDemo),在测试类中提供两个方法
- 一个方法是:useAddable(Addable a)
- 一个方法是主方法,在主方法中调用 useAddable 方法
代码如下:
public interface Addable {
int add(int x, int y);
}public class AddableDemo {
public static void main(String[] args) {
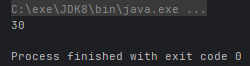
useAddable((int x, int y) -> {
return x + y;
});
}
public static void useAddable(Addable a) {
int sum = a.add(10, 20);
System.out.println(sum);
}
}运行结果:
4、Lambda 表达式的省略模式
省略规则:
- 参数类型可以省略。但是有多个参数的情况下,不能只省略一个
- 如果参数有且仅有一个,那么小括号可以省略
- 如果代码块的语句只有一条,那么可以省略大括号和分号,甚至是 return
5、Lambda 表达式的注意事项
注意事项:
- 使用 Lambda 必须要有接口,并且要求接口中有且仅有一个抽象方法
- 必须有上下文环境,才能推导出 Lambda 对应的接口
- 根据局部变量的赋值得知 Lambda 对应的接口:Runnable r = () -> System.out.println("Lambda表达式“);
- 根据调用方法的参数得知 Lambda 对应的接口:new Thread(() -> System.out.println("Lambda表达式")).start();
6、Lambda 表达式与匿名内部类的区别
所需类型不同
- 匿名内部类:可以是接口,也可以是抽象类,还可以是具体类
- Lambda 表达式:只能是接口
使用限制不同
- 如果接口中有且仅有一个抽象方法,可以使用 Lambda 表达式,也可以使用匿名内部类
- 如果接口中多于一个抽象方法,只能使用匿名内部类,而不能使用 Lambda 表达式
实现原理不同
- 匿名内部类:编译之后,产生一个单独的 .class 字节码文件
- Lambda 表达式:编译之后,没有一个单独的 .class 字节码文件。对应的字节码会在运行的时候动态生成
二、方法引用
1、方法引用符
方法引用符
- :: 该符号为引用运算符,而它所在的表达式被称为方法引用
推导与省略
- 如果使用 Lambda,那么根据 "可推导就是可省略" 的原则,无需指定参数类型,也无需指定重载形式,他们都将被自动推导
- 如果使用方法引用,也是同样可以根据上下文进行推导
- 方法引用是 Lambda 的孪生兄弟
2、Lambda 表达式支持的方法引用
常见的引用方法:
- 引用类方法
- 引用对象的实例方法
- 引用类的实例方法
- 引用构造器
3、方法引用
3.1、引用类方法
引用类方法,其实就是引用类的静态方法
- 格式:类名::静态方法
- 范例:Integer::parseInt
- Integer 类的方法:public static int parseInt(String s) 将此 String 转换为 int 类型数据
练习:
- 定义一个接口(Converter),里面定义一个抽象方法
- int convert(String s)
- 定义一个测试类(ConverterDemo),在测试类中提供两个方法
- 一个方法是:useConverter(Converter c)
- 一个方法是主方法,在主方法中调用 useConverter 方法
代码如下:
public interface Converter {
int convert(String s);
}public class ConverterDemo {
public static void main(String[] args) {
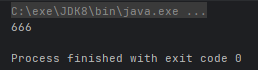
useConverter(Integer::parseInt);
}
private static void useConverter(Converter c) {
int number = c.convert("665") + 1;
System.out.println(number);
}
}运行结果:
3.2、引用对象的实例方法
引用对象的实例方法,其实就是引用类中的成员方法
- 格式:对象::成员方法
- 范例:"HelloWorld"::toUpperCase
- String 类中的方法:public String toUpperCase() 将此 String 所有字符转换为大写
练习:
- 定义一个类(PrintString),里面定义一个方法
- public void printUpper(String s):把字符串参数变成大写的数据,然后在控制台输出
- 定义一个接口(Printer),里面定义一个抽象方法
- void printUpperCase(String s)
- 定义一个测试类(PrinterDemo),在测试类中提供两个方法
- 一个方法是:usePrinter(Printer p)
- 一个方法是主方法,在主方法中调用 usePrinter 方法
代码如下:
public class PrintString {
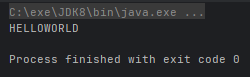
public void printUpper(String s) {
System.out.println(s.toUpperCase());
}
}public interface Printer {
void printUpperCase(String s);
}public class PrinterDemo {
public static void main(String[] args) {
PrintString ps = new PrintString();
usePrinter(ps::printUpper);
}
private static void usePrinter(Printer p) {
p.printUpperCase("helloWorld");
}
}运行结果:
3.3、引用类的实例方法
引用类的实例方法,其实就是引用类中的成员方法
- 格式:类名::成员方法
- 范例:String::substring
- String 类中的方法:public String substring(int beginIndex, int endIndex),从 beginIndex 开始到 endIndex 结束,截取字符串。返回一个字串,字串的长度为 endIndex-beginIndex
练习:
- 定义一个接口(MyString),里面定义一个抽象方法
- String mySubString(String s, int x, int y);
- 定义一个测试类(MyStringDemo),在测试类中提供两个方法
- 一个方法是:useMyString(MyString my)
- 一个方法是主方法,在主方法中调用 useMyString 方法
代码如下:
public interface MyString {
String mySubString(String s, int x, int y);
}public class MyStringDemo {
public static void main(String[] args) {
useMyString(String::substring);
}
private static void useMyString(MyString my) {
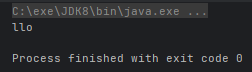
String s = my.mySubString("HelloWorld", 2, 5);
System.out.println(s);
}
}运行结果:
3.4、引用构造器
引用构造器,其实就是引用构造方法
- 格式:类名::new
- 范例:Student::new
练习:
- 定义一个类(Student),里面有两个成员变量(name,age)
- 并提供无参构造方法和带参构造方法,以及成员变量对应的 get 和 set 方法
- 定义一个接口(StudentBuilder),里面定义一个抽象方法
- Student build(String name, int age)
- 定义一个测试类(StudentDemo),在测试类中提供两个方法
- 一个方法是:useStudentBuilder(StringBuilder s)
- 一个方法是主方法,在主方法中调用 useStudentBuilder 方法
代码如下:
public class Student {
private String name;
private int age;
// 省略get/set/满参构造方法
}public interface StudentBuilder {
Student build(String name, int age);
}public class StudentDemo {
public static void main(String[] args) {
useStudentBuilder(Student::new);
}
private static void useStudentBuilder(StudentBuilder sb) {
Student student = sb.build("张三", 18);
System.out.println(student.getName() + "," + student.getAge());
}
}运行结果:

三、函数式接口
1、函数式接口概述
函数式接口:有且仅有一个抽象方法的接口
- Java 中的函数式编程体现就是 Lambda 表达式,所以函数式接口就是可以适用于 Lambda 使用的接口
- 只有确保接口中有且仅有一个抽象方法,Java 中的 Lambda 才能顺利地进行推导
如何检测一个接口是不是函数式接口呢?
- @FunctionalInterface
- 放在接口定义的上方:如果接口是函数式接口,编译通过;如果不是,编译失败
注意:
- 我们自己定义函数式接口的时候,@FunctionalInterface 是可选的,就算我不写这个注解,只要保证满足函数式接口定义的条件,也照样是函数式接口,但是,建议加上该注解
2、函数式接口作为方法的参数
需求:
- 定义一个类(RunnableDemo),在类中提供两个方法
- 一个方法是:startThread(Runnable r) 方法参数 Runnable 是一个函数式接口
- 一个方法是主方法,在主方法中调用 startThread 方法
代码如下:
public class RunnableDemo {
public static void main(String[] args) {
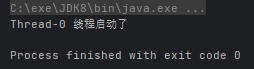
startThread(() -> System.out.println(Thread.currentThread().getName() + " 线程启动了"));
}
private static void startThread(Runnable r) {
new Thread(r).start();
}
}运行结果:
3、函数式接口作为方法的返回值
需求:
- 定义一个类(ComparatorDemo),在类中提供两个方法
- 一个方法是:Comparator <String> getComparator() 方法返回值 Comparator 是一个函数式接口
- 一个方法是主方法,在主方法中调用 getComparator 方法
代码如下:
public class ComparatorDemo {
public static void main(String[] args) {
ArrayList<String> array = new ArrayList<>();
array.add("ccc");
array.add("aa");
array.add("b");
array.add("ddd");
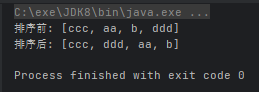
System.out.println("排序前: " + array);
array.sort(getComparator());
System.out.println("排序后: " + array);
}
private static Comparator<String> getComparator() {
// 如果方法的返回值是一个函数式接口,我们可以使用 Lambda 表达式作为结果返回
return (s1, s2) -> s2.length() - s1.length();
}
}运行效果:
4、常用的函数式接口
Java 8 在 java.util.function 包下与定义了大量的函数式接口供我们使用
我们重点来学习下面的 4 个接口
- Supplier 接口
- Consumer 接口
- Predicate 接口
- Function 接口
4.1、Supplier 接口
Supplier<T>:包含一个无参的方法:
- T get():获得结果
- 该方法不需要参数,它会按照某种实现逻辑(由 Lambda 表达式实现)返回一个数据
- Supplier<T> 接口也被称为生产型接口,如果我们指定了接口的泛型是什么类型,那么接口中的 get 方法就会生产什么类型的数据供我们使用
练习:
- 定义一个类(SupplierTest),在类中提供两个方法
- 一个方法是:int getMax(Supplier<Integer> sup) 用于返回一个 int 数组中的最大值
- 一个方法是主方法,在主方法中调用 getMax 方法
代码如下:
public class SupplierTest {
public static void main(String[] args) {
int[] arr = {1, 3, 4, 5, 2};
int max = getMax(() -> {
Arrays.sort(arr);
return arr[arr.length - 1];
});
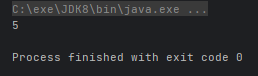
System.out.println(max);
}
private static int getMax(Supplier<Integer> sup) {
return sup.get();
}
}运行效果:
4.2、Consumer 接口
Consumer<T>:包含两个方法
- void accept(T t):对给定的参数执行此操作
- default Consumer<T> andThen(Consumer after):返回一个组合的 Consumer,依次执行此操作,然后执行 after 操作
- Consumer<T> 接口也被称为消费型接口,它消费的数据的数据类型由泛型指定
练习:
- String[] strArray = {"林青霞,30", "张曼玉,35", "王祖贤,33"};
- 字符串数组中有多条信息,请按照格式:"姓名: xx,年龄: xx" 的格式将信息打印出来
- 要求:
- 把打印姓名的动作作为第一个 Consumer 接口的 Lambda 实例
- 把打印年龄的动作作为第二个 Consumer 接口的 Lambda 实例
- 将两个 Consumer 接口按照顺序组合到一起使用
代码如下:
public class ConsumerTest {
public static void main(String[] args) {
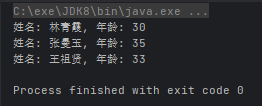
operatorString(s1 -> System.out.print("姓名: " + s1.split(",")[0] + ", "), s2 -> System.out.println("年龄: " + s2.split(",")[1]));
}
private static void operatorString(Consumer<String> con1, Consumer<String> con2) {
String[] strArray = {"林青霞,30", "张曼玉,35", "王祖贤,33"};
for (String s : strArray) {
con1.andThen(con2).accept(s);
}
}
}运行效果:
4.3、Predicate 接口
Predicate<T>:常用的四个方法
- boolean test(T t):对给定的参数进行判断(判断逻辑由 Lambda 表达式实现),返回一个布尔值
- default Predicate<T> negate():返回一个逻辑的否定,对应逻辑非
- default Predicate<T> and(Predicate other):返回一个组合判断,对应短路与
- default Predicate<T> or(Predicate other):返回一个组合判断,对应短路或
- Predicate<T> 接口通常用于判断参数是否满足指定的条件
练习:
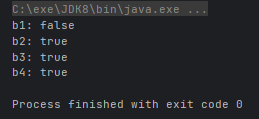
public class PredicateDemo01 {
public static void main(String[] args) {
boolean b1 = checkString1(s -> s.length() > 8);
System.out.println("b1: " + b1);
boolean b2 = checkString2(s -> s.length() > 8);
System.out.println("b2: " + b2);
boolean b3 = checkString3(s -> s.contains("hello"), s -> s.length() > 5);
System.out.println("b3: " + b3);
boolean b4 = checkString4(s -> s.contains("hello"), s -> s.length() > 20);
System.out.println("b4: " + b4);
}
// 判断给定的字符串是否满足要求
private static boolean checkString1(Predicate<String> pre) {
return pre.test("hello");
}
private static boolean checkString2(Predicate<String> pre) {
return pre.negate().test("hello");
}
// 同一个字符串给出两个不同的判断条件,最后把这两个判断的结果做逻辑与运算的结果作为最终的结果
private static boolean checkString3(Predicate<String> pre1, Predicate<String> pre2) {
String s = "hello,world";
return pre1.and(pre2).test(s);
}
private static boolean checkString4(Predicate<String> pre1, Predicate<String> pre2) {
String s = "hello,world";
return pre1.or(pre2).test(s);
}
}运行结果:
4.4、Function 接口
Function<T,R>:常用的两个方法
- R apply(T t):将此函数应用于给定的参数
- default <V> Function andThen(Function after):返回一个组合函数,首先将该函数应用于输入,然后将 after 函数应用于结果
- Function<T,R> 接口通常用于对参数进行处理,转换(处理逻辑由 Lambda 表达式实现),然后返回一个新的值
练习:
- String s = "林青霞,30";
- 请按照以下指定的要求进行操作:
- 将字符串截取得到数字年龄部分
- 将上一步的年龄字符串转换成 int 类型的数据
- 将上一步的 int 数据加 70,得到一个 int 结果,在控制台输出
- 请通过 Function 接口来实现函数拼接
代码如下:
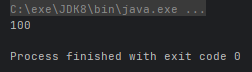
public class FunctionTest {
public static void main(String[] args) {
convert1(s -> s.split(",")[1], Integer::parseInt, i -> i + 70);
}
private static void convert1(Function<String, String> fun1, Function<String, Integer> fun2, Function<Integer, Integer> fun3) {
String s = "林青霞,30";
Integer i = fun1.andThen(fun2).andThen(fun3).apply(s);
System.out.println(i);
}
}运行结果:
四、Stream 流
4.1、Stream 流的使用
- 生成流
- 通过数据源(集合,数组等)生成流
- 中间操作
- 一个流后面可以跟随零个或多个中间操作,其目的主要是打开流,做出某种程度的数据过滤/映射,然后返回一个新的流,交给下一个操作使用
- 终结操作
- 一个流只能有一个终结操作,当这个操作执行后,流就被使用 “光了” ,无法再被操作。所以这必定是流的最后一个操作
4.2、Stream 流的生成方式
Stream 流的常见生成方式
- Collection 体系的集合可以使用两个默认方法生成流
- default Stream stream():返回一个串行流
- default Stream parallelStream():返回一个并行流
- 数组可以使用 Arrays 的静态方法 stream() 获取数组流
- static Stream stream(T[] array):返回一个流
- public static IntStream stream(int[] array)
- public static LongStream stream(long[] array)
- public static DoubleStream stream(double[] array)
- Stream 类的静态方法 of() 可以将显示值生成一个流
- public static Stream of(T... values):返回一个流
- 可以使用静态方法 Stream.iterate() 和 Stream.generate() 创建无限流(了解)
- 迭代:public static Stream iterate(final T seed, final UnaryOperator f)
- 生成:public static Stream generate(Supplier s)
代码如下:
- Collection 体系的集合可以使用两个默认方法生成流
@Test
public void test01() {
ArrayList<Object> list = new ArrayList<>();
Stream<Object> stream1 = list.stream(); // 串行流
Stream<Object> stream2 = list.parallelStream(); // 并行流
}- 数组可以使用 Arrays 的静态方法 stream() 获取数组流
@Test
public void test02() {
String[] arr1 = {"hello", "world"};
Stream<String> stream1 = Arrays.stream(arr1);
int[] arr2 = {1, 2, 3};
IntStream stream2 = Arrays.stream(arr2);
}- Stream 类的静态方法 of() 可以将显示值生成一个流
@Test
public void test03() {
Stream<Integer> stream = Stream.of(1, 2, 3);
}- 可以使用静态方法 Stream.iterate() 和 Stream.generate() 创建无限流(了解)
@Test
public void test04() {
Stream<Integer> stream1 = Stream.iterate(0, x -> x + 2).limit(10);
Stream<Double> stream2 = Stream.generate(() -> Math.random() + 10).limit(10);
}4.3、Stream 流的中间操作
- Stream<T> filter(Predicate predicate):筛选符合条件的元素,返回一个新的流
- Predicate 接口中的方法 boolean test(T t):对给定的参数进行判断,返回一个布尔值
- Stream<T> limit(long maxSize):返回此流中的元素组成的流,截取前指定参数个数的数据
- Stream<T> skip(long n):跳过指定参数个数的数据,返回由该流的剩余元素组成的流
- Stream<T> distinct():返回该流的不同元素(根据 Object.equals(Object))组成的流
- Stream<T> peek(Consumer action):对流中的每个元素执行指定的操作,不改变流中的元素
- <T> Stream<R> map(Function mapper):返回由给定函数应用于此流的元素的结果组成的流
- Function 接口中的方法 R apply(T t)
- IntStream mapToInt(ToIntFunction mapper):返回一个 IntStream,其中包含将给定函数应用于此流的元素的结果
- <R> Stream<R> flatMap(Function mapper):把一个对象转换成多个对象作为流中的元素
- IntStream flatMapToInt(Function mapper):将一个 Stream 中的元素分解成基本的 int 值并返回一个表示这些值的 IntStream
- Stream<T> sorted():返回由此流的元素组成的流,根据自然顺序排序
- Stream<T> sorted(Comparator comparator):返回由该流的元素组成的流,根据提供的 Comparator 进行排序
- static<T> Stream<T> concat(Stream a, Stream b):合并 a 和 b 两个流为一个流
- Stream<T> paraller():将串行流转为并行流
- boolean isParallel():判断一个流是否是一个并行流,返回一个布尔值
- Stream<T> sequential():返回一个串行流
- Stream<T> unordered():返回一个无序流(如果你想要一个无序的流,请使用无序集合作为数据源)
代码如下:
- Stream<T> filter(Predicate predicate):筛选符合条件的元素,返回一个新的流
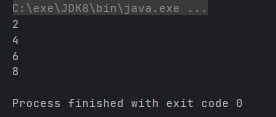
@Test
public void test() {
int[] arr = {1, 2, 3, 4, 5, 6, 7, 8, 9};
// 保留偶数
Arrays.stream(arr).filter(x -> x % 2 == 0).forEach(System.out::println);
}运行结果:
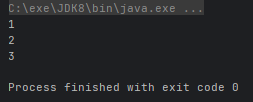
- Stream<T> limit(long maxSize):返回此流中的元素组成的流,截取前指定参数个数的数据
@Test
public void test() {
int[] arr = {1, 2, 3, 4, 5, 6, 7, 8, 9};
// 截取前三个元素
Arrays.stream(arr).limit(3).forEach(System.out::println);
}运行结果:
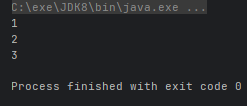
- Stream<T> skip(long n):跳过指定参数个数的数据,返回由该流的剩余元素组成的流
@Test
public void test() {
int[] arr = {1, 2, 3, 4, 5, 6, 7, 8, 9};
// 跳过前三个元素
Arrays.stream(arr).skip(3).forEach(System.out::println);
}运行结果:
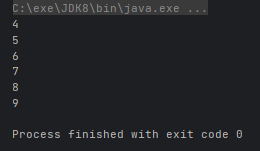
- Stream<T> distinct():返回该流的不同元素(根据 Object.equals(Object))组成的流
@Test
public void test() {
int[] arr = {1, 1, 2, 2, 3, 3};
Arrays.stream(arr).distinct().forEach(System.out::println);
}运行结果:
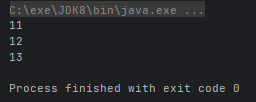
- Stream<T> peek(Consumer action):对流中的每个元素执行指定的操作,不改变流中的元素
@Test
public void test() {
int[] arr = {1, 2, 3};
IntStream stream = Arrays.stream(arr);
stream.peek(n -> System.out.println(n + 10)).count();
}运行结果:
- <T> Stream<R> map(Function mapper):返回由给定函数应用于此流的元素的结果组成的流
@Test
public void test() {
String[] numbers = {"1", "2", "3"};
Stream<Integer> stream = Arrays.stream(numbers).map(Integer::parseInt);
}- IntStream mapToInt(ToIntFunction mapper):返回一个 IntStream,其中包含将给定函数应用于此流的元素的结果
@Test
public void test() {
// 类似的还有mapToLong、mapToDouble
String[] number = {"1", "2", "3"};
IntStream stream = Arrays.stream(number).mapToInt(Integer::parseInt);
}- <R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper):把一个对象转换成多个对象作为流中的元素
@Test
public void test() {
class User {
public String[] hobby;
public User(String[] hobby) {
this.hobby = hobby;
}
}
ArrayList<User> list = new ArrayList<>();
Collections.addAll(list, new User("溜冰,滑雪,篮球".split(",")), new User("乒乓球,足球,网球".split(",")));
Stream<String> stream = list.stream().flatMap(user -> Arrays.stream(user.hobby));
stream.forEach(System.out::println);
}运行结果:
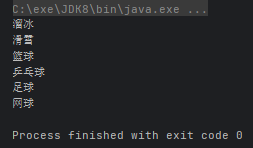
- IntStream flatMapToInt(Function mapper):将一个 Stream 中的元素分解成基本的 int 值并返回一个表示这些值的 IntStream
@Test
public void test() {
class Number {
public int[] nums;
public Number(int[] nums) {
this.nums = nums;
}
}
ArrayList<Number> list = new ArrayList<>();
Collections.addAll(list, new Number(new int[]{1, 2, 3}), new Number(new int[]{4, 5, 6}));
// 类似的还有flatMapToLong、flatMapToDouble
IntStream stream = list.stream().flatMapToInt(n -> Arrays.stream(n.nums));
stream.forEach(System.out::println);
}运行结果:
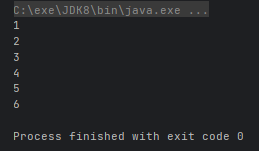
- Stream<T> sorted():返回由此流的元素组成的流,根据自然顺序排序
@Test
public void test() {
Stream.of(3, 1, 2).sorted().forEach(System.out::println);
}运行结果:
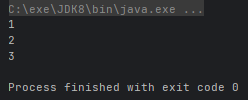
- Stream<T> sorted(Comparator comparator):返回由该流的元素组成的流,根据提供的 Comparator 进行排序
@Test
public void test() {
class Student {
public String name;
public int chinese;
public int mathematics;
public int english;
// 省略满参构造和toString方法
}
ArrayList<Student> list = new ArrayList<>();
Collections.addAll(list, new Student("lisi", 90, 85, 70), new Student("zhangsan", 90, 85, 60), new Student("wangwu", 99, 75, 75));
// 如果语文成绩相等,就比较数学成绩,如果数学成绩相等,就比较英语成绩
list.stream().sorted((n1, n2) -> n1.chinese == n2.chinese ? n1.mathematics == n2.mathematics ? n1.english - n2.english : n1.mathematics - n2.mathematics : n1.chinese - n2.chinese).forEach(System.out::println);
}运行结果:

- static<T> Stream<T> concat(Stream a, Stream b):合并 a 和 b 两个流为一个流
@Test
public void test() {
Stream<Integer> stream1 = Stream.of(1, 2, 3);
Stream<Integer> stream2 = Stream.of(3, 2, 1);
Stream.concat(stream1, stream2).forEach(System.out::println);
}运行结果:
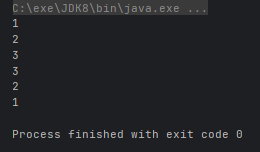
- Stream<T> paraller():将串行流转为并行流
@Test
public void test() {
Stream<Integer> parallelStream = Stream.of(1, 2, 3).parallel();
}- boolean isParallel():判断一个流是否是一个并行流,返回一个布尔值
@Test
public void test() {
int[] arr = {1, 2, 3};
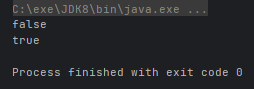
System.out.println(Arrays.stream(arr).isParallel()); // 串行流
System.out.println(Arrays.stream(arr).parallel().isParallel()); // 并行流
}运行结果:
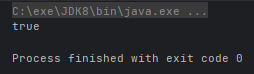
- Stream<T> sequential():返回一个串行流
@Test
public void test() {
ArrayList<Integer> list = new ArrayList<>();
Stream<Integer> stream = list.parallelStream().sequential();
System.out.println(stream.isParallel());
}运行结果:
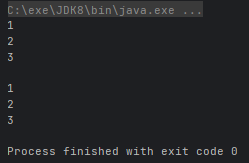
- Stream<T> unordered():返回一个无序流(如果你想要一个无序的流,请使用无序集合作为数据源)
@Test
public void test() {
ArrayList<Integer> arrayList = new ArrayList<>();
Collections.addAll(arrayList, 1, 2, 3);
Stream<Integer> stream1 = arrayList.stream().unordered();
stream1.forEach(System.out::println); // 输出 1 2 3
System.out.println();
// unordered()方法并不能保证输出的结果一定是无序的,而只是告诉Stream类,在进行后续操作时,可以不保留元素的原始顺序,以提高并行处理性能。
LinkedList<Object> linkedList = new LinkedList<>();
Collections.addAll(linkedList, 1, 2, 3);
Stream<Object> stream2 = linkedList.stream().unordered();
stream2.forEach(System.out::println);
}运行结果:
4.4、Stream 流的终结操作
- void forEach(Consumer action):对流中的每个元素执行此操作
- <A> A[] toArray(IntFunction<A[]> generator):将流中的元素转换为指定类型的数组
- long count():返回流中的元素总数
- sum():返回流中所有数值类型的总和,返回类型为 int 或 long 或 duble
- boolean anyMatch(Predicate<? super T> predicate):判断是否有任意符合匹配条件的元素
- boolean allMatch(Predicate<? super T> predicate):判断是否都符合匹配条件
- boolean noneMatch(Predicate<? super T> predicate):判断流中的元素是否都不符合匹配条件
- Optional<T> max(Comparator<? super T> comparator):根据比较器返回流中最大值的 Optional
- Optional<T> min(Comparator<? super T> comparator):根据比较器返回流中最小值的 Optional
- Optional<T> findAny():获取流中的任意一个元素
- Optional<T> findFirst():获取流中的第一个元素
- Iterator<T> iterator():返回一个迭代器
- reduce 归并,对流中的数据按照你制定的计算方式计算出一个结果(缩减操作)
- Optional reduce(BinaryOperator accumulator)
- T reduce(T identity, BinaryOperator accumulator)
代码如下:
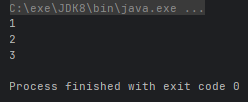
- void forEach(Consumer action):对流中的每个元素执行此操作
@Test
public void test() {
Stream.of(1, 2, 3).forEach(System.out::println);
}运行结果:
- <A> A[] toArray(IntFunction<A[]> generator):将流中的元素转换为指定类型的数组
@Test
public void test() {
Integer[] arr = Stream.of(1, 2, 3).toArray(Integer[]::new);
}- long count():返回流中的元素总数
@Test
public void test() {
long count = Stream.of(1, 2, 3).count();
System.out.println(count);
}运行结果:

- sum():返回流中所有数值类型的总和,返回类型为 int 或 long 或 duble
@Test
public void test() {
ArrayList<String> list = new ArrayList<>();
int sum1 = list.stream().mapToInt(Integer::valueOf).sum();
long sum2 = list.stream().mapToLong(Long::valueOf).sum();
double sum3 = list.stream().mapToDouble(Double::valueOf).sum();
}- boolean anyMatch(Predicate<? super T> predicate):判断是否有任意符合匹配条件的元素
@Test
public void test() {
boolean b = Stream.of(1, 2, 3).anyMatch(n -> n == 2);
System.out.println(b);
}运行结果:
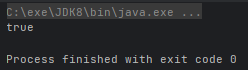
- boolean allMatch(Predicate<? super T> predicate):判断是否都符合匹配条件
@Test
public void test() {
boolean b = Stream.of(1, 2, 3).allMatch(n -> n == 2);
System.out.println(b);
}运行结果:
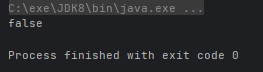
- boolean noneMatch(Predicate<? super T> predicate):判断流中的元素是否都不符合匹配条件
@Test
public void test() {
boolean b = Stream.of(1, 2, 3).allMatch(n -> n != 0);
System.out.println(b);
}运行结果:

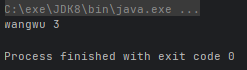
- Optional<T> max(Comparator<? super T> comparator):根据比较器返回流中最大值的 Optional
@Test
public void test() {
class User {
public String name;
public int age;
public User(String name, int age) {
this.name = name;
this.age = age;
}
}
ArrayList<User> list = new ArrayList<>();
Collections.addAll(list, new User("zhangsan", 2), new User("lisi", 1), new User("wangwu", 3));
Optional<User> maxOptional = list.stream().max((n1, n2) -> n1.age - n2.age);
System.out.println(maxOptional.get().name + " " + maxOptional.get().age);
}运行结果:
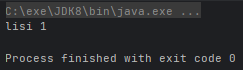
- Optional<T> min(Comparator<? super T> comparator):根据比较器返回流中最小值的 Optional
@Test
public void test() {
class User {
public String name;
public int age;
public User(String name, int age) {
this.name = name;
this.age = age;
}
}
ArrayList<User> list = new ArrayList<>();
Collections.addAll(list, new User("zhangsan", 2), new User("lisi", 1), new User("wangwu", 3));
Optional<User> maxOptional = list.stream().min((n1, n2) -> n1.age - n2.age);
System.out.println(maxOptional.get().name + " " + maxOptional.get().age);
}运行结果:
- Optional<T> findAny():获取流中的任意一个元素
@Test
public void test() {
Optional<Integer> optional = Stream.of(1, 2, 3, 4, 5, 6, 7).parallel().filter(i -> i % 2 == 0).findAny();
System.out.println(optional.get());
}运行结果:

- Optional<T> findFirst():获取流中的第一个元素
@Test
public void test() {
Optional<Integer> optional = Stream.of(1, 2, 3).findFirst();
System.out.println(optional.get());
}运行结果:
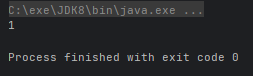
- Iterator<T> iterator():返回一个迭代器
@Test
public void test() {
Iterator<Integer> iterator = Stream.of(1, 2, 3).iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}运行结果:
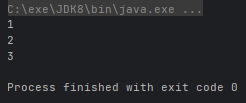
- reduce 归并,对流中的数据按照你制定的计算方式计算出一个结果(缩减操作)
@Test
public void test1() {
// Optional reduce(BinaryOperator accumulator)
Integer[] arr = {1, 2, 3};
Optional<Integer> optional = Arrays.stream(arr).reduce((n1, n2) -> n1 + n2);
System.out.println("sum: " + optional.get());
}
@Test
public void test2() {
// T reduce(T identity, BinaryOperator accumulator)
Integer[] arr = {1, 2, 3};
Integer sum1 = Arrays.stream(arr).reduce(0, (n1, n2) -> n1 + n2);
Integer sum2 = Arrays.stream(arr).reduce(10, (n1, n2) -> n1 + n2);
System.out.println("sum1: " + sum1);
System.out.println("sum2: " + sum2);
}运行结果:
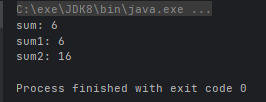
4.5、Stream 流的收集操作
对数据使用 Stream 流的方式操作完毕后,我想把流中的数据收集到集合中,该怎么办呢?
Stream 流的收集方法
- R collect(Collector collector)
- 但是这个收集方法的参数是一个 Collector 接口
工具类 Collectors 提供了具体的收集方法
- public static <T> Collector toList():把元素收集到 List 集合中
- public static <T> Collector toSet():把元素收集到 Set 集合中
- public static Collector toMap(Function keyMapper, Function valueMapper):把元素收集到 Map 集合中
- public static Collector toCollection(Supplier<C> collectionFactory):把元素收集到创建的集合
- public static <T> Collector counting():计算流中元素的个数
- public static <T> Collector summingInt(ToIntFunction<? super T> mapper) :对流中的整数属性求和
- public static <T> Collector averagingInt(ToIntFunction<? super T> mapper):计算流中元素 Integer 属性的平均值
- public static <T> Collector summarizingInt(ToIntFunction<? super T> mapper):收集流中 Integer 属性的统计值。如最大值、最小值等等
- public static Collector joining():连接流中每个字符串
- public static <T> Collector maxBy(Comparator<? super T> comparator):根据比较器选择最大值
- public static <T> Collector minBy(Comparator<? super T> comparator):根据比较器选择最小值
- public static <T> Collector reducing(T identity, BinaryOperator<T> op):从一个累加器的初始值开始,利用 BinaryOperator 与流中元素逐个结合,从而归约成单个值
- public static<T,A,R,RR> Collector<T,A,RR> collectingAndThen(Collector<T,A,R> downstream,Function<R,RR> finisher):它是一个将流中的元素先进行收集,然后再对收集的结果执行一些操作的收集器
- public static <T, K> Collector groupingBy(Function<? super T, ? extends K> classifier):根据某属性对流分组,属性为 K,结果为 V
- public static <T> Collector partitioningBy(Predicate<? super T> predicate):根据 true 或 false 进行分区
代码如下:
- public static <T> Collector toList():把元素收集到 List 集合中
@Test
public void test() {
String[] arr = {"1", "1", "2", "2", "3", "3"};
List<Integer> list = Arrays.stream(arr).map(Integer::valueOf).map(n -> n + 10).collect(Collectors.toList());
System.out.println(list);
}运行结果:

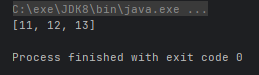
- public static <T> Collector toSet():把元素收集到 Set 集合中
@Test
public void test() {
String[] arr = {"1", "1", "2", "2", "3", "3"};
Set<Integer> set = Arrays.stream(arr).map(Integer::valueOf).map(n -> n + 10).collect(Collectors.toSet());
System.out.println(set);
}运行结果:
- public static Collector toMap(Function keyMapper, Function valueMapper):把元素收集到 Map 集合中
@Test
public void test() {
String[] arr = {"1", "2", "3"};
Map<String, String> map = Arrays.stream(arr).map(Integer::valueOf).map(n -> n + 10).collect(Collectors.toMap(n -> "key: " + n, n -> "value: " + n));
System.out.println(map);
}运行结果:

- public static Collector toCollection(Supplier<C> collectionFactory):把元素收集到创建的集合
@Test
public void test() {
String[] arr = {"1", "2", "3"};
ArrayList<Integer> arrayList = Arrays.stream(arr).map(Integer::valueOf).map(n -> n + 10).collect(Collectors.toCollection(ArrayList::new));
LinkedList<Integer> linkedList = Arrays.stream(arr).map(Integer::valueOf).map(n -> n + 10).collect(Collectors.toCollection(LinkedList::new));
}- public static <T> Collector<T, ?, Long> counting():计算流中元素的个数
@Test
public void test() {
String[] arr = {"1", "2", "3"};
Long count = Arrays.stream(arr).collect(Collectors.counting());
System.out.println(count);
}运行结果:
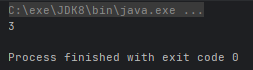
- public static <T> Collector<T, ?, Integer> summingInt(ToIntFunction<? super T> mapper) :对流中的整数属性求和
@Test
public void test() {
class User {
public String name;
public int age;
public User(String name, int age) {
this.name = name;
this.age = age;
}
}
User[] users = {new User("jack", 18), new User("tom", 19), new User("rose", 20)};
// 类似的还有summingDouble、summingLong
Integer sum = Arrays.stream(users).collect(Collectors.summingInt(user -> user.age));
System.out.println(sum);
}运行结果:
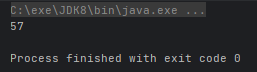
- public static <T> Collector averagingInt(ToIntFunction<? super T> mapper):计算流中元素 Integer 属性的平均值
@Test
public void test() {
class User {
public String name;
public int age;
public User(String name, int age) {
this.name = name;
this.age = age;
}
}
User[] users = {new User("jack", 18), new User("tom", 19), new User("rose", 20)};
// 类似的还有averagingDouble、averagingLong
Double avg = Arrays.stream(users).collect(Collectors.averagingInt(user -> user.age));
System.out.println(avg);
}运行结果:

- public static <T> Collector summarizingInt(ToIntFunction<? super T> mapper):收集流中 Integer 属性的统计值。如最大值、最小值等等
@Test
public void test() {
class User {
public String name;
public int age;
public User(String name, int age) {
this.name = name;
this.age = age;
}
}
ArrayList<User> list = new ArrayList<>();
Collections.addAll(list, new User("jack", 18), new User("tom", 19), new User("rose", 20));
// 类似的还有 summarizingDouble、summarizingLong
IntSummaryStatistics intSummaryStatistics = list.stream().collect(Collectors.summarizingInt(u -> u.age));
System.out.println(intSummaryStatistics);
}运行结果:

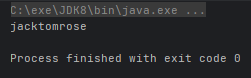
- public static Collector joining():连接流中每个字符串
@Test
public void test() {
class User {
public String name;
public int age;
public User(String name, int age) {
this.name = name;
this.age = age;
}
}
ArrayList<User> list = new ArrayList<>();
Collections.addAll(list, new User("jack", 18), new User("tom", 19), new User("rose", 20));
String str = list.stream().map(u -> u.name).collect(Collectors.joining());
System.out.println(str);
}运行结果:
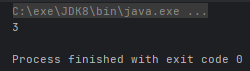
- public static <T> Collector maxBy(Comparator<? super T> comparator):根据比较器选择最大值
@Test
public void test() {
Optional<Integer> optional = Stream.of(2, 3, 1).collect(Collectors.maxBy((n1, n2) -> n1 - n2));
System.out.println(optional.get());
}运行结果:
- public static <T> Collector minBy(Comparator<? super T> comparator):根据比较器选择最小值
@Test
public void test() {
Optional<Integer> optional = Stream.of(2, 3, 1).collect(Collectors.minBy((n1, n2) -> n1 - n2));
System.out.println(optional.get());
}运行结果:
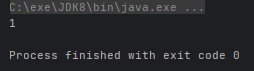
- public static <T> Collector reducing(T identity, BinaryOperator<T> op):从一个累加器的初始值开始,利用 BinaryOperator 与流中元素逐个结合,从而归约成单个值
@Test
public void test() {
Integer sum = Stream.of(1, 2, 3).collect(Collectors.reducing(0, Integer::sum));
System.out.println(sum);
}运行结果:
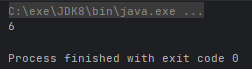
- public static<T,A,R,RR> Collector<T,A,RR> collectingAndThen(Collector<T,A,R> downstream,Function<R,RR> finisher):它是一个将流中的元素先进行收集,然后再对收集的结果执行一些操作的收集器
@Test
public void test() {
Integer size = Stream.of(1, 2, 3).collect(Collectors.collectingAndThen(Collectors.toList(), list -> list.size()));
System.out.println(size);
}运行结果:

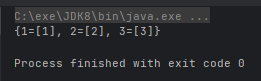
- public static <T, K> Collector groupingBy(Function<? super T, ? extends K> classifier):根据某属性对流分组,属性为 K,结果为 V
@Test
public void test() {
Map<Integer, List<Integer>> map = Stream.of(1, 2, 3).collect(Collectors.groupingBy(n -> n));
System.out.println(map);
}运行结果:
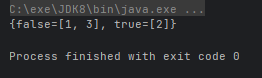
- public static <T> Collector partitioningBy(Predicate<? super T> predicate):根据 true 或 false 进行分区
@Test
public void test() {
Map<Boolean, List<Integer>> map = Stream.of(1, 2, 3).collect(Collectors.partitioningBy(n -> n % 2 == 0));
System.out.println(map);
}运行结果:
五、Optional
我们在编写代码的时候出现最多的就是空指针异常。所以在很多情况下我们需要做各种非空的判断。例如:
if (xxx!=null){
}而过多的判断语句会让我们的代码显得臃肿不堪。
所以在 JDK8 引入了 Optional,养成使用 Optional 的习惯后你可以写出更优雅的代码来避免空指针异常。
1、创建对象
- Optional.of(T t):创建一个 Optional 实例,t 必须非空
- Optional.empty():创建一个空的 Optional 实例
- Optional.ofNullable(T t):t 可以为 null
代码如下:
Cat cat = new Cat("tom", 3);
Optional<Cat> optionalCat1 = Optional.of(cat);
Optional<Cat> optionalCat2 = Optional.empty();
Optional<Cat> optionalCat3 = Optional.ofNullable(cat);2、消费值
- void ifPresent(Consumer<? super T> consumer):如果有值,就执行 Consumer 接口的实现代码,并且该值会作为参数传给它
代码如下:
Cat cat = new Cat("tom", 3);
Optional<Cat> optionalCat = Optional.ofNullable(cat);
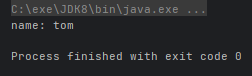
optionalCat.ifPresent(s -> System.out.println("name: " + s.getName()));运行结果:
3、获取值
- T get():如果调用对象包含值,返回该值,否则抛异常(不推荐)
- T orElse(T other):如果有值则将其返回,否则返回指定的 other 对象
- T orElseGet(Supplier<? extends T> other):如果有值则将其返回,否则返回由 Supplier 接口实现提供的对象
- T orElseThrow(Supplier<? extends X> exceptionSupplier):如果有值则将其返回,否则抛出由 Supplier 接口实现提供的异常
代码如下:
- T get():如果调用对象包含值,返回该值,否则抛异常(不推荐)
System.out.println(Optional.ofNullable(new Cat("tom", 3)).get());
System.out.println(Optional.ofNullable(null).get());运行结果:

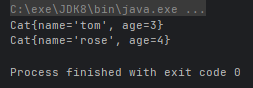
- T orElse(T other):如果有值则将其返回,否则返回指定的 other 对象
System.out.println(Optional.ofNullable(new Cat("tom", 3)).orElse(new Cat("rose", 4)));
System.out.println(Optional.ofNullable(null).orElse(new Cat("rose", 4)));运行结果:
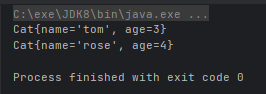
- T orElseGet(Supplier<? extends T> other):如果有值则将其返回,否则返回由 Supplier 接口实现提供的对象
System.out.println(Optional.ofNullable(new Cat("tom", 3)).orElseGet(() -> new Cat("rose", 4)));
System.out.println(Optional.ofNullable(null).orElseGet(() -> new Cat("rose", 4)));运行结果:
- T orElseThrow(Supplier<? extends X> exceptionSupplier):如果有值则将其返回,否则抛出由 Supplier 接口实现提供的异常
System.out.println(Optional.ofNullable(new Cat("tom", 3)).orElseThrow(() -> new RuntimeException("cat为空")));
System.out.println(Optional.ofNullable(null).orElseThrow(() -> new RuntimeException("cat为空")));运行结果:

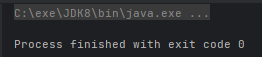
4、过滤数据
我们可以使用 filer 方法对数据进行过滤。如果原本是有数据的,但是不符合判断,也会变成一个无数据的 Optional 对象
代码如下:
Optional.ofNullable(new Cat("tom", 3)).filter(c -> c.getAge() > 5).ifPresent(System.out::println);运行结果:
5、判断
- boolean isPresent():判断是否包含对象
代码如下:
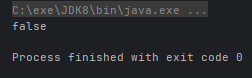
System.out.println(Optional.ofNullable(null).isPresent());运行结果:
6、数据转换
- Optional<U> map(Function<? super Object,? extends U> mapper):对数据进行转换
- Optional<U> flatMap(Function<? super T, ? extends Optional<? extends U>> mapper):对数据进行转换
代码如下:
@Test
public void test() {
String str = "hello";
// map() 方法用于将 Optional 对象中的值进行转换,而 flatMap() 方法用于将 Optional 对象中的值进行转换,并返回一个包含值的 Optional 对象
Optional<String> s1 = Optional.ofNullable(str).map(String::toUpperCase);
Optional<String> s2 = Optional.ofNullable(str).flatMap(s -> Optional.of(s.toUpperCase()));
}7、注意
- 无论 Optional 对象中的值是否为空,orElse() 函数都会执行,而 orElseGet() 函数只有在 Optional 对象中的值为空时,orElseGet() 中的 Supplier 方法才会执行















 473
473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









