






汇编编译器(Assembler)
背景知识
机器语言一般分为两类:符号型(symbolic)和二进制型(binary)。二进制代码代表一跳实际的机器指令,它能被底层硬件所理解。指令最左边的8位代表操作码(比如LOAD),接着的8位代表寄存器(比如R3),剩下的16位表示地址(比如7)。根据硬件的逻辑设计和相应的机器语言,整个32-位指令可以让硬件去执行操作“将Memory[7]的内容加载到寄存器R3中。”现代计算机平台支持数十个(即使不是成白上千个)这样的基本操作。
解决此复杂性的方法之一是,用约定的语法表示机器指令,例如用LOAD R3 ,7来表示机器语言。由于将符号表示翻译成二进制代码是直接了当的,所以允许用符号表示法来编写底层程序,并用计算机程序将底层程序翻译成二进制代码是很有意义的。符号化的语言被称为汇编(assembly),翻译程序称为汇编编译器(assembler)。汇编编译器对每个汇编命令的所有部分进行解析,将每个部分翻译成它对应的二进制码,并将生成的二进制码汇编成真正能被硬件执行的二进制指令。
符号(Symbols) 二进制指令用二进制代码表示。根据定义,它们使用实际的数字来指代内存地址。比如假设某个程序用变量weight来表示不同事物的重量,假设该变量已经被映射到计算机内存地址为7的内存单元内。在二进制码层级上,操纵weight变量的指令必须使用明确的地址7来指代它。然而,一旦进入汇编级,我们可以允许编写命令LOAD R3,weight来取代LOAD R3,7。两种情况都会执行相同的操作:“将R3设为Memory[7]的内容”。同样,假设在程序某一处标有符号loop来指代地址250,那么我们可以使用玲明goto loop来取代goto 250。 符号在汇编程序通常有两个用途:
变量(variables):程序员可以使用符号的变量名称,翻译器会“自动地”为其分配内存地址。需要注意的是,这些地址的实际值是没有意义的,只要再程序的整个编译过程中,每个符号始终被指代为同一地址就可以了。标签(Labels):程序员可以在程序中用符号来标注不同的位置。比如,可以用标签loop来指代特定代码的起始地址。程序中的其他命令就可以有条件或无条件地指令goto loop指令。
符号解析(Symbol Resolution) 图6.1列出了一个用某种低级语言编写的简单程序。该程序包含4个用户自定义符号:2个变量名称(i和sum);2个标签(loop和end)。那么,如何将其系统化地转换为不包含符号的代码?
首先制定两个任意性规则:其一,编译后的代码讲被存储到计算机中起始地址为0的内存中;其二,变量将会被分配到起始地址为1024的内存中(这些规则依赖于特定的目标硬件平台)。接下来,我们构建一个符号表(symbol table)。在源代码中,每遇到一个新符号xxx,我们就在符号表中添加一行(xxx,n)。根据规则约定n是分配给对应符号的内存地址。
根据我们定义的规则,变量i和sum被分配的内存地址分别是1024和1025。当然,只要程序中对i的所有引用都指代其所对应的同一物理地址,并且对sum的所有引用也都指代同一物理地址,那么为这两个变量各自分配一下其他任意地址也是可以的。最后一条语句可以让计算机进入无线循环。

这里有三点要进行说明
- 我们定义的变量分配规则决定了能运行的程序最多只能有1024条指令。然而实际的程序(比如操作系统)显然要大很多,因此存储变量的基地址也应该设得距离代码存储区更远一些。
- 每条源代码命令映射到一个字(word)的假设太天真了,一般来说,某些汇编命令(比如,if i=101 goto end)会被翻译成好几条机器指令,因此它会占据好几个内存单元。为了解决此问题,翻译程序会记录每条源代码产生的字的个数,然后相应地更新它的“指令内存计数器(Instvachionmemory counter)”。
- 对于每个变量用一个单独的内存单元来表示的假设可能也不切实际。编程语言支持多种类型的变量,它们在目标计算机上占用不同的内存空间。比如,C语言数据类型short和double分别代表16-位和64-位数字。当C程序在16-位机器上运行时,short变量将占用1个单独内存单元,long变量将占用4个连续单元组成的块。因此,当位变量分配内存空间时,编译程序必须考虑它们的数据类型和硬件内存的宽度。
汇编编译器(Assembler) 汇编程序在被计算机执行之前,必须被翻译成计算机的二进制语言。编译任务是由称为汇编编译器的程序来完成的。汇编编译器的输入是一串汇编命令,然后产生一串等价的二进制指令作为输出。生成的代码被加载到计算机的内存中然后被硬件执行。
汇编编译器实际上主要是个文本处理程序,设计目的的用来提供翻译服务。编写汇编编译器的程序员必须有完整的汇编语法说明文档和相应的二进制代码。有了这样的约定(通常称为机器语言规范),就不难编写程序,让其对每个符号命令执行下面的任务(顺序无关,不分前后):
- 解析出符号命令内在的域。
- 对于每个域,产生机器语言中相应的位域
- 用内存单元的数字地址来替换所有的符号引用
- 将二进制代码汇编成完整的机器指令
其中三个任务(解析、代码生成和汇编)是相当容易使海鲜的,而符号处理则相对来说比较复杂,是汇编编译器的主要内容。
Hack汇编到二进制翻译规范详述
语法规范和文件格式
文件名称 习惯上,二进制机器代码表示的程序和汇编代码表示的程序被存储在后缀名为“hack”和“asm”的文本文件中。因此,prog.asm文件会被汇编编译器翻译成prog.hack文件。
二进制代码(.hack)文件 二进制代码文件由文本行组成。每一行由16个0/1组成的ASCII码构成一个序列,该序列对一个单一的16-位机器语言指令进行编码。因此,文件中的所有行在整体上代表一个机器语言程序。当机器语言程序被加载进计算机的指令内存中时,文件的第n行二进制码被存储到地址为n的指令内存单元内(设程序命令行的技术和指令内存的起始地址都是从0开始的)。
汇编语言(.asm)文件 汇编语言文件由文本行组成,每一行代表一条指令(instruction)或者一个符号声明(symbol declaration)。
- 指令(Instruction): A-指令或C-指令
- 符号(Symbol): 该伪命令将Symbol绑定到该程序中下一条命令的地址上。因为它并不产生机器代码,所以称之为“
伪命令(pseudo-command)”。
常数(Constants)和符号(Symbols) 常数必须是非负的,用十进制表示。用户定义的符号是可以由字母、数字、下划线、点、美元符号、和冒号组成的字符序列,但是不能以数字开头。
注释 以两条斜线开头的文本行被认为是一条注释,注释不会被计算机执行。
空格 空格字符和空行被忽略。
大小写习惯 所有的汇编助记符必须大写。剩余的部分(用于自定义符号和变量名称)是区分大小写的。一般的习惯是,标签(label)大写,变量名称小写。
指令
Hack机器语言包含两种指令类型,分别称为寻址指令(A-指令,addressing Instruction)和计算指令(C-指令,Compute Instruction)。指令格式如下:
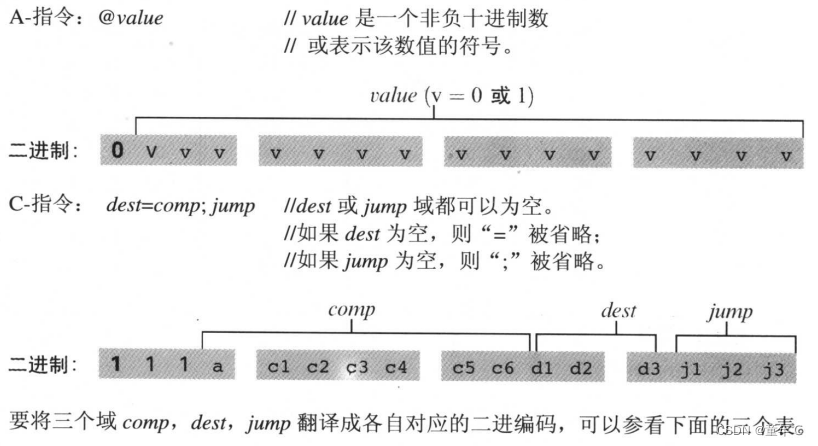
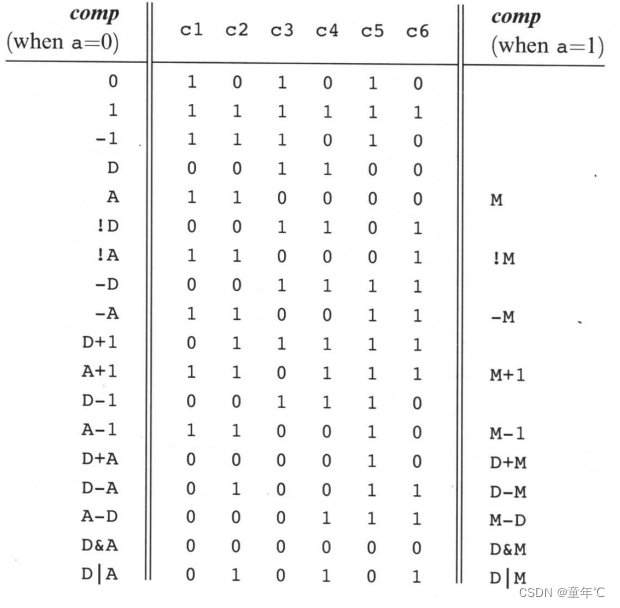
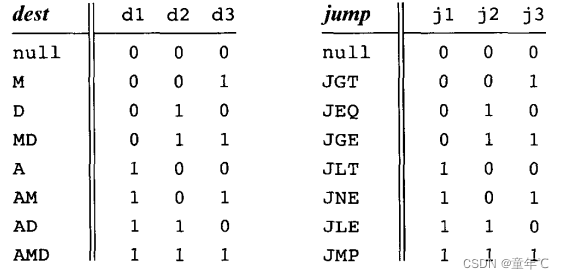
符号
Hack汇编命令通过使用常数和符号来指代内存单元(地址)。汇编程序中的符号来源于三个方面。
预定义符号(Predefined Symbols) 任何Hack程序允许使用下面的预定义符号。

注意到表中的RAM地址0到5可以使用两个预定义符号来指代。比如说,R2或者ARG都可以被用来指代RAM[2]。
标签符号(Label Symbols) 伪命令(xxx)定义符号xxx来指代存有程序中下一条命令在指令内存中的地址。每个标签只能被定义一次,可以在程序中的任何地方使用,甚至可以在它自身被定义的那一行之前使用。

范例
以下是从1加到100的整数累加程序。

实现(Implementation)
Parser模块
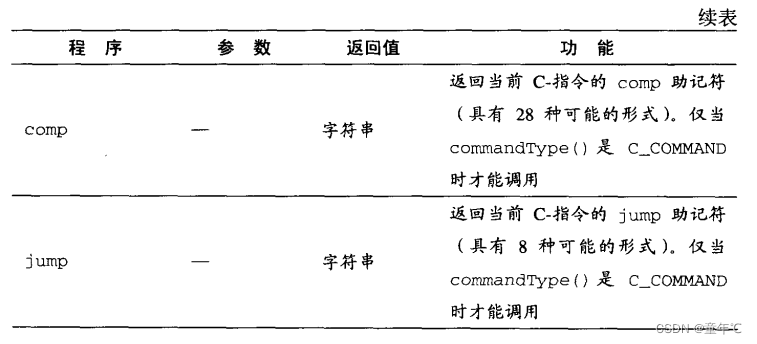
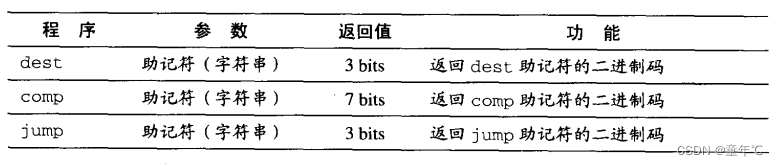
语法分析器(parser)的主要功能是,将汇编命令分解为其所表达的内在含义(域和符号)。它的API如下表示:
Parser:封装对输入代码的访问操作。功能包括:读取汇编语言命令并对其进行解析:提供“方便访问汇编命令成分(域和符号)”的方案;去掉所有的空格和注释。

Code模块
code:将Hack汇编语言助记符翻译成二进制代码。
无符号程序的汇编编译器
建议将编译器的构建分为两个阶段。第一阶段,编写汇编编译器来翻译无符号汇编程序。这可以通过前面描述的Parser和Code模块来实现。在第二阶段,将其扩展成具有符号处理能力的汇编编译器,下一节中有介绍。
在第一阶段的约定是:输入的prog.asm程序不包含符号。这意味着(a)在所有的地址命令中@xxx中,xxx常数是十进制数而不是符号;(b)输入文件不包含标记命令,也就是没有(xxx)命令
实现代码
以下是python程序版的代码
import os
import re
symbolkey = ['R0','R1','R2','R3','R4','R5','R6','R7','R8','R9','R10','R11'
,'R12','R13','R14','R15','SCREEN','KBD','SP','LCL','ARG','THIS'
,'THAT']
symbolvalue = ['0','1','2','3','4','5','6','7','8','9','10','11','12','13'
,'14','15','16384','24576','0','1','2','3','4','5']
symbol_dict = dict(zip(symbolkey,symbolvalue)) # 预定义符号字典,包含虚拟寄存器与预定义指针均包含其中,此外还有屏幕和键盘
print(symbol_dict)
f = open('D:/wokespace/nand2tetris/nand2tetris/projects/06/pong/Pong.asm','r') # 打开文件
label_dict = {}
inFile = []
for line in f.readlines(): # readlines函数可以每次读取一行,循环读取
line = re.sub("[\s]*","",line) # 查找每一行中是否有空格,若有直接删除
line = re.sub("//.*","",line) # 查询每一行中是否有注释// 若有,直接删除
if line=="": # 若该行无内容,则直接进入下一个循环
continue
elif (line[0]=="(" and line[len(line)-1]==")"): # 这里是查询每一行是否为标签符号,并为标签符号赋值
labelString = line[1:len(line)-1] # 切片获得标签符号的自定义符号
labelNum = str(len(inFile)) # 这里是地址,查询真正执行的命令的行数即可获得
label_dict[labelString] = labelNum # 以字典记录标签符号的地址
continue
inFile.append(line) # inFile的作用是记录执行命令行数
f.close() # 关闭文件
print("0..0.0.0.0.0.0.0.0.0")
print(inFile)
print(label_dict)
variablePos = 16 # 这里初始值为16是因为自己定义的变量符号是从16开始的。
variable_dict = {}
first_result = []
for opt in inFile: # 这里的循环是预处理,先替换掉@后的变量符号与标签符号,以及预定义符号和键盘鼠标,让汇编处理器得以识别
if opt[0]=="@": # 识别出@
sub = opt[1:] # sub为@后的内容
if sub in symbol_dict.keys(): # 查询预定义符号和鼠标键盘
opt = "@" + symbol_dict[sub] # 替换
elif sub in label_dict.keys(): # 查询标签符号
opt = "@" + label_dict[sub] # 替换
elif re.match("[0-9]+",sub): # 查询如果@后为数字的话,则不用替换
opt = "@" + sub # 保留原值
else:
if(not (sub in variable_dict.keys())): # 若以上均不符合,则为变量符号,变量符号字典内若没有该值
print(sub)
variable_dict[sub] = str(variablePos) # 添加到字典中,并把值给出
variablePos+=1 # 内存地址+1
print(variablePos)
opt = "@" + variable_dict[sub] # 替换
first_result.append(opt) # 将预处理的结果添加到first_result中。
print(opt)
# print(f.readline())
jumpTable_key = ['JGT','JEQ','JGE','JLT','JNE','JLE','JMP']
jumpTable_value = ['001','010','011','100','101','110','111']
# 将jump域的所有内容都添加到字典中
destTable_key = ['M','D','MD','A','AM','AD','AMD']
destTable_value = ['001','010','011','100','101','110','111']
# 将dest域的所有内容添加到字典中
compTable_key = ['0','1','-1','D','A','!D','!A','-D','-A','D+1','A+1','D-1','A-1','D+A','D-A',
'A-D','D&A','D|A','M','!M','-M','M+1','M-1','D+M','D-M','M-D','D&M','D|M']
compTable_value = ['0101010','0111111','0111010','0001100','0110000','0001101','0110001','0001111',
'0110011','0011111','0110111','0001110','0110010','0000010','0010011','0000111',
'0000000','0010101','1110000','1110001','1110011','1110111','1110010','1000010',
'1010011','1000111','1000000','1010101']
# 将comp域的所有内容添加到字典中
jumpTable = dict(zip(jumpTable_key,jumpTable_value))
destTable = dict(zip(destTable_key,destTable_value))
compTable = dict(zip(compTable_key,compTable_value))
second_result = []
for line in first_result: # 进入循环,进行二进制转换
if line[0] == "@": # 若该行第一个字符为@
numStr = line[1:] # 则取出字符后的数字
num = int(numStr) # 转为整型
binNumStr = "{0:b}".format(num) # 二进制转换
binLine = "0000000000000000" # 这里是16位的计算机,所以不够的要补齐,这里是默认的16位
binLine = binLine[:-len(binNumStr)] + binNumStr # 补齐操作
else: # 若第一个字符不是@
semicolonPos = -1 # ;记录,这里是默认值
jumpBinNum = "000" # jump的默认值,若无;则表示不跳转,为默认值
semicolonPos = line.find(";") # 查询该行是否有;
if semicolonPos != -1: # 若查询到了;
jumpBinNum = jumpTable[line[semicolonPos+1:]] # 切片是包含前不包含后,因此用jump字典匹配;后的内容
equalPos = -1 # 等号记录,默认值
destBinNum = "000" # 同jump,表示无
equalPos = line.find("=") # 查询该行是否有=
if equalPos != -1: # 若查询到了
destBinNum = destTable[line[0:equalPos]] # 这里其实分了两步, =左边为dest域,右边为comp域
compBinNum = "0000000" # comp域默认值,这里其实默认值随便写就可以,因为一定可以匹配上的
if equalPos != -1 and semicolonPos != -1: # 若有跳转和存储
compBinNum = compTable[line[equalPos+1:semicolonPos]] #
# 取出=后与;前的内容从字典中匹配更换,至于为什么是因为上面已经对=前的内容以及;后的内容进行了处理
elif equalPos != -1: # 若有存储
compBinNum = compTable[line[equalPos+1:]] # 取出=后的内容,与字典匹配更换
elif semicolonPos != -1: # 若有跳转
compBinNum = compTable[line[0:semicolonPos]] # 取出;前的内容,与字典匹配更换
binLine = "111" + compBinNum + destBinNum + jumpBinNum # 最后将更换后的内容,按照顺序进行相加,这里是C-指令,所以前缀固定为111
print(binLine)
second_result.append(binLine) # 添加到second_result中
print(second_result)
f = open("D:/wokespace/nand2tetris/nand2tetris/projects/06/pong/Pong.hack","w")
for final_line in second_result: # 循环写入文件
f.writelines(final_line+"\n")
f.close() # 结束


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









