






如何观察load指标
本文的源码出自谢宝友老师的文章《Load高故障分析》
load指标代表系统运行负载,表示在一段时间内,系统又多少个正在运行的任务,一般通过top、uptime命令查看最近1min、5min、15min的平均load指标以及iowait指标
可利用如下指令去模拟高负载场景
while :;do :;done &模拟CPU密集型任务

sudo sh -c "while :; do fio -name=mytest -filename=test.data -direct=0 -thread -rw=randread -ioengine=psync -bs=4k -size=1M -numjobs=2 -runtime=10 -group_reporting;echo 1 > /proc/sys/vm/drop_caches; done"利用fio工具模拟IO密集型任务

编写工具
Makefile
OS_VER := UNKNOWN
UNAME := $(shell uname -r)
ifneq ($(findstring 6.2.0-34-generic,$(UNAME)),)
OS_VER := UBUNTU_2204
endif
ifneq ($(KERNELRELEASE),)
obj-m += $(MODNAME).o
$(MODNAME)-y := main.o
ccflags-y := -I$(PWD)/
else
export PWD=`pwd`
ifeq ($(KERNEL_BUILD_PATH),)
KERNEL_BUILD_PATH := /lib/modules/`uname -r`/build
endif
ifeq ($(MODNAME),)
export MODNAME=load_monitor
endif
all:
make CFLAGS_MODULE=-D$(OS_VER) -C /lib/modules/`uname -r`/build M=`pwd` modules
clean:
make -C $(KERNEL_BUILD_PATH) M=$(PWD) clean
endif
main.c
#include <linux/version.h>
#include <linux/module.h>
#include <linux/kallsyms.h>
#include <linux/sched/loadavg.h>
#include <linux/stacktrace.h>
#include "load.h"
struct hrtimer timer;
//static unsigned long *ptr_avenrun;
//static unsigned long avnrun[3];
// #define FSHIFT 11 /* nr of bits of precision */
// #define FIXED_1 (1<<FSHIFT)/* 1.0 as fixed-point */
// #define LOAD_INT(x) ((x) >> FSHIFT)
// #define LOAD_FRAC(x) LOAD_INT(((x) & (FIXED_1-1)) * 100)
#define BACKTRACE_DEPTH 20
static void print_all_task_stack(void)//打印全部调用栈
{
struct task_struct *g, *p; //用于遍历进程
unsigned long backtrace[BACKTRACE_DEPTH]; //存放每一个调用的具体信息
struct stack_trace trace; //专门保存进程调用栈信息的
memset(&trace, 0, sizeof(trace)); //清空
memset(backtrace, 0, BACKTRACE_DEPTH * sizeof(unsigned long)); //清空
trace.max_entries = BACKTRACE_DEPTH; //设置调用栈的最大深度
trace.entries = backtrace; //将trace结构体的entries成员设置为 backtrace 指针的值即将堆栈跟踪信息存储在结构体中
printk("!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!\n");
printk("\tLoad: %lu.%02lu, %lu.%02lu, %lu.%02lu\n", //输出近期平均负载
LOAD_INT(avenrun[0]), LOAD_FRAC(avenrun[0]),
LOAD_INT(avenrun[1]), LOAD_FRAC(avenrun[1]),
LOAD_INT(avenrun[2]), LOAD_FRAC(avenrun[2]));
rcu_read_lock(); //rcu --read-copy-update锁,防止在读取进程链表的过程中,进程的信息被修改,适用于读多写少的状况
/* 由于load的值受TASK_RUNNING和TASK_UNINTERRUPTIBLE两个状态的进程影响,故需要打印这两种状态的进程内核栈*/
printk("dump running task.\n");
unsigned long store;
do_each_thread(g, p) {//遍历队列
if (p->__state == TASK_RUNNING) { //TASK_RUNNING--正在等待CPU或者正在使用CPU的进程
printk("running task, comm: %s, pid %d\n",p->comm, p->pid);
//dump_stack();
printk("--------------------------------\n");
//stack_trace_save_tsk_reliable(p, &store,20);
save_stack_trace_tsk(p, &trace);
print_stack_trace(&trace, 0);
}
} while_each_thread(g, p);
printk("dump uninterrupted task.\n");
do_each_thread(g, p) {
if (p->__state & TASK_UNINTERRUPTIBLE) { //TASK_UNINTERRUPTIBLE--正处于关键流程的进程,且不可打断,例如等待IO响应的进程
printk("uninterrupted task, comm: %s, pid %d\n",p->comm, p->pid);
save_stack_trace_tsk(p, &trace);
print_stack_trace(&trace, 0);
}
} while_each_thread(g, p);
rcu_read_unlock();
}
static void check_load(void)//检查系统正在运行的任务数和等待的任务数
{
printk("check_load\n");
static ktime_t last; /hrtimer保存时间的一个数据结构:ktime_t,last保存的是上一次打印时的系统时间
u64 ms;
int load = LOAD_INT(avenrun[0]); /* 最近1分钟的Load值 */
printk("load=%d \n",load);
if (load <3) //将load的阈值设置为3
return;
/**
* 如果上次打印时间与当前时间相差不到20秒,就直接退出
*/
ms = ktime_to_ms(ktime_sub(ktime_get(), last));
if (ms < 20 * 1000)
return;
last = ktime_get();
print_all_task_stack();
}
//定时器到期时的处理(回调)函数,然而对于回调函数我们在返回前需要手动设定下一次超过的时间,并且在中断上下文中我们要求函数执行时间不能过长,所以我们设定每隔10ms检查以下系统的负载值
static enum hrtimer_restart monitor_handler(struct hrtimer *hrtimer)
{
enum hrtimer_restart ret = HRTIMER_RESTART; //先赋返回值为重启定时器
check_load(); //检查当前系统的负载值
hrtimer_forward_now(hrtimer, ms_to_ktime(10)); //将定时器下次重启的时间定为10ms后,
return ret;//返回定时器重启信号
}
static void start_timer(void){
/*
通过hrtimer_init对定时器进行初始化,其中which_clock有3种状态,CLOCK_REALTIME:实际时间用户可以进行修改CLOCK_MONOTONIC:单调时间即从某个时间点开始到现在过去的时间。用户不能修改这个时间,但是当系统进入休眠,这个值是不会增加的。CLOCK_BOOTTIME:系统运行时间。与单调时间不同的是它包含睡眠时间。当休眠时,此值会增加。
*/
hrtimer_init(&timer, CLOCK_MONOTONIC, HRTIMER_MODE_PINNED);
timer.function = monitor_handler; //定时器到期时,需要回调的函数。这里将monitor_handler赋给了timer的function字段
hrtimer_start_range_ns(&timer, ms_to_ktime(10),0, HRTIMER_MODE_REL_PINNED);//定义了定时器到期的时间为10ms
}
static int load_monitor_init(void)
{
//ptr_avenrun = (void *)kallsyms_lookup_name("avenrun");
start_timer();
printk("load-monitor loaded.\n");
return 0;
}
static void load_monitor_exit(void)
{
hrtimer_cancel(&timer);
printk("load-monitor unloaded.\n");
}
module_init(load_monitor_init)
module_exit(load_monitor_exit)
MODULE_LICENSE("GPL v2");
load.h
/*无实际内容*/
在打印进程栈时需要遍历系统的进程链表,但在这个过程中进程链表可能会发生变化,就会对遍历链表产生影响,所以要对其进行加锁。
对于被rcu锁保护的结构,读者不需要任何锁就可以访问它,但是写者写时,需要先拷贝一个副本,然后对副本进行修改,最后使用callback回调机制当所有cpu都退出对共享数据的操作时将指向原来数据的指针重新指向新的被修改的数据,适用于读多写少的情况。
报错解决
在插入模块时会导致虚拟机崩溃。
认为是没有对ptr_avenrun进行初始化
使用kallsyms_lookup_name函数获取avenrun
ptr_avenrun = (void *)kallsyms_lookup_name(“avenrun”),在低版本中可用,但本文使用Linux 6.2.0版本,其接口没有被EXPORT出来,我们不能对该函数进行调用。
直接获取
查看源码,可以看到
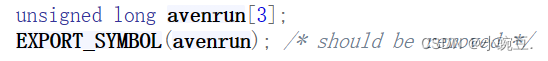
我们将ptr_avenrun这层嵌套去掉,直接引入头文件后\#include <linux/sched/loadavg.h> 直接读取avenrun
规范化
//以下的这些宏,在源码中用于规范读取load average的值(10进制读取)
#define FSHIFT 11 /* nr of bits of precision */
#define FIXED_1 (1<<FSHIFT) //1左移FSHIFT位得到的固定点数中的1.0
#define LOAD_INT(x) ((x) >> FSHIFT)//x右移FSHIFT位来提取整数部分即将固定点数转换为整数
#define LOAD_FRAC(x) LOAD_INT(((x) & (FIXED_1-1)) * 100)
avenrun中低11位存放load的小数部分,第11位开始存放load的整数部分,我们只需要其整数部分所以需要相关宏进行处理
(x) & (FIXED_1-1): 通过与运算将x的整数部分清零,只保留小数部分。
((x) & (FIXED_1-1)) * 100: 将保留的小数部分乘以100,以将其转换为0到99之间的值。
LOAD_INT(…): 通过调用LOAD_INT宏将结果转换为整数即固定点数的小数部分转换为0到99之间的整数。
比如说x=123456,那么我们左移动11位即* 2^11 = 2073600,可以知道它的固定点数是1.23456,通过LOAD_INT宏将它右移11位提取整数部分1,通过LOAD_FRAC宏首先通过与运算将x的整数部分清零,只保留小数部分23456。将它保留的小数部分乘以100,以将其转换为0到99之间的值。最后,它调用LOAD_INT`宏将结果转换为整数。
报错

提示不知道trace的空间,查看源码

查看CONFIG_ARCH_STACKWALK宏定义

发现CONFIG_ARCH_STACKWALK值为y,判断时会跳过编译此段定义,于是尝试性的将源码复制到代码中,发现即可使用
//编译后报错
save_stack_trace_tsk(p, &trace);
print_stack_trace(&trace, 0);
后续报错

在源码中查看

发现其在stacktrace.h文件中有声明,但没有在x86架构下的相关实现,通过查看源码中的history,发现其已被删除,且经尝试发现其中有相应的内部函数没有实现,不能复现其函数内容。
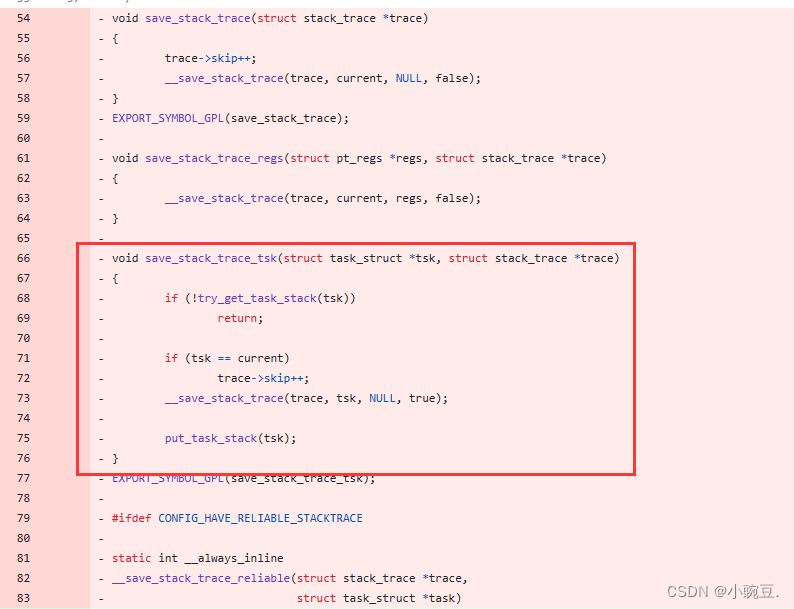
阅读源码后,找到有类似的功能的函数,其函数原型如下
stack_trace_save_tsk(struct task_struct *task, unsigned long *store, unsigned int size, unsigned int skipnr)
在源码中进行查找,可以看到有两组实现,其是由CONFIG_ARCH_STACKWALK这个宏的值决定的

当CONFIG_ARCH_STACKWALK值为0时

当CONFIG_ARCH_STACKWALK值为1时

通过cat config-6.2.0-34-generic | grep CONFIG_ARCH_STACKWALK命令查看配置文件获取其值

所以我们对其对应的实现进行分析,并加以注释
unsigned int stack_trace_save_tsk(struct task_struct *tsk, unsigned long *store,unsigned int size, unsigned int skipnr)//参数是任务指针 tsk、存储数组指针 store、存储数组的大小 size,以及要跳过的栈帧数目 skipnr
{
stack_trace_consume_fn consume_entry = stack_trace_consume_entry_nosched;//函数指针用于处理每个栈帧的信息。
struct stacktrace_cookie c = {//结构体包含了存储数组的指针 store、存储数组的大小 size,以及一个用于跳过栈帧的标志
.store = store,
.size = size,
/* skip this function if they are tracing us */
.skip = skipnr + (current == tsk),
};
if (!try_get_task_stack(tsk))//判断语句用于尝试获取任务 tsk 的堆栈信息
return 0;
arch_stack_walk(consume_entry, &c, tsk, NULL);//行了堆栈遍历操作,使用了函数指针 consume_entry 处理每个栈帧,并将 c 结构体传递给堆栈遍历函数以指示如何存储栈帧信息。
put_task_stack(tsk);//这一步用于释放之前获取的任务堆栈信息,确保没有资源泄漏
return c.len;//函数返回了存储在存储数组中的栈帧数量
}
这个函数的主要作用是获取指定任务的调用栈信息,并将栈帧信息存储到一个数组中,同时可以跳过一定数量的栈帧,但尝试时发现不能调用,发现其在源码中与先前的kallsyms_lookup_name函数同样没有EXPORT出来,我们不能使用。
于是设想,有没有一种方法可以调用没有EXPORT的函数?
经询问师兄,我们使用kprobes技术来执行它,我们对源码 main.c进行了修改
#include <linux/stacktrace.h> /* for stack_trace_print */
#include <linux/module.h> /* for module_*, MODULE_*, printk */
#include <linux/hrtimer.h> /* for hrtimer_*, ktime_* */
#include <linux/sched/loadavg.h> /* for avenrun, LOAD_* */
#include <linux/sched.h> /* for struct task_struct */
#include <linux/sched/signal.h> /* for do_each_thread, while_each_thread */
#include "load.h" /* for find_kallsyms_lookup_name */
#define BACKTRACE_DEPTH 20 /* 最大栈深度 */
void (*ShowStack)(struct task_struct *task, unsigned long *sp, const char *loglvl); /* 将要指向stack_show函数,可以直接输出进程控制块的调用栈 */
unsigned int (*StackTraceSaveTask)(struct task_struct *tsk, unsigned long *store, unsigned int size, unsigned int skipnr); /* 将要指向stack_trace_save_tsk */
static void print_all_task_stack(void) { /* 打印全部进程调用栈 */
struct task_struct *g, *p; /* 用于遍历进程 */
unsigned long backtrace[BACKTRACE_DEPTH]; /* 用于存储调用栈的函数地址 */
unsigned int nr_bt; /* 用于存储调用栈的层数 */
printk("!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!\n");
printk("Load: %lu.%02lu, %lu.%02lu, %lu.%02lu\n", /* 输出近期平均负载 */
LOAD_INT(avenrun[0]), LOAD_FRAC(avenrun[0]),
LOAD_INT(avenrun[1]), LOAD_FRAC(avenrun[1]),
LOAD_INT(avenrun[2]), LOAD_FRAC(avenrun[2]));
rcu_read_lock(); /* 为运行队列上锁 */
printk("dump running task.\n");
do_each_thread(g, p) { /* 遍历运行队列 */
if(p->__state == TASK_RUNNING) {
printk("running task, comm: %s, pid %d\n", p->comm, p->pid);
// show_stack(p, NULL, ""); /* 可以取代下面两个语句 */
nr_bt = StackTraceSaveTask(p, backtrace, BACKTRACE_DEPTH, 0); /* 保存栈 */ // 和下面一个语句一起可以取代上面一条语句
stack_trace_print(backtrace, nr_bt, 0); /* 打印栈 */
}
} while_each_thread(g, p);
printk("dump uninterrupted task.\n");
do_each_thread(g, p) { /* 和上面的遍历类似 */
if(p->__state & TASK_UNINTERRUPTIBLE) {
printk("uninterrupted task, comm: %s, pid %d\n", p->comm, p->pid);
// show_stack(p, NULL, ""); /* 可以取代下面两个语句 */
nr_bt = StackTraceSaveTask(p, backtrace, BACKTRACE_DEPTH, 0); /* 保存栈 */ // 和下面一个语句一起可以取代上面一条语句
stack_trace_print(backtrace, nr_bt, 0); /* 打印栈 */
}
} while_each_thread(g, p);
rcu_read_unlock(); /* 为运行队列解锁 */
}
struct hrtimer timer; /* 创建一个计时器 */
static void check_load(void) { /* 主要的计时器触发后的程序 */
static ktime_t last; /* 默认值是0 */
u64 ms;
int load = LOAD_INT(avenrun[0]);
if(load < 3) /* 近1分钟内平均负载不超过3,没问题 */
return;
ms = ktime_to_ms(ktime_sub(ktime_get(), last)); /* 计算打印栈时间间隔 */
if(ms < 20*1000) /* 打印栈的时间间隔小于20s,不打印 */
return;
last = ktime_get(); /* 获取当前时间 */
print_all_task_stack(); /* 打印全部进程调用栈 */
}
static enum hrtimer_restart monitor_handler(struct hrtimer *hrtimer) { /* 计时器到期后调用的程序 */
enum hrtimer_restart ret = HRTIMER_RESTART;
check_load();
hrtimer_forward_now(hrtimer, ms_to_ktime(10)); /* 延期10ms后到期 */
return ret;
}
static void start_timer(void) {
hrtimer_init(&timer, CLOCK_MONOTONIC, HRTIMER_MODE_PINNED); /* 初始化计时器为绑定cpu的自开机以来的恒定时钟 */
timer.function = monitor_handler; /* 设定回调函数 */
hrtimer_start_range_ns(&timer, ms_to_ktime(10), 0, HRTIMER_MODE_REL_PINNED); /* 启动计时器并设定计时模式为绑定cpu的相对时间,计时10ms,松弛范围为0 */
}
static int load_monitor_init(void) { /* 模块初始化 */
// ShowStack = find_kallsyms_lookup_name("show_stack"); /* 使用show_stack时将此三行取消注释 */
// if(!ShowStack)
// return -EINVAL;
StackTraceSaveTask = find_kallsyms_lookup_name("stack_trace_save_tsk"); /* 使用stack_trace_save_tsk时将此三行取消注释 */
if(!StackTraceSaveTask)
return -EINVAL;
start_timer();
printk("load-monitor loaded.\n");
return 0;
}
static void load_monitor_exit(void) { /* 模块退出 */
hrtimer_cancel(&timer); /* 取消计时器 */
printk("load-monitor unloaded.\n");
}
module_init(load_monitor_init);
module_exit(load_monitor_exit);
MODULE_DESCRIPTION("load monitor module");
MODULE_AUTHOR("Baoyou Xie <baoyou.xie@gmail.com>");
MODULE_LICENSE("GPL");
load.h
#include <linux/kprobes.h> /* for *kprobe* */
/* 调用kprobe找到kallsyms_lookup_name的地址位置 */
int noop_pre(struct kprobe *p, struct pt_regs *regs) { return 0; } /* 定义探针前置程序 */
void *find_kallsyms_lookup_name(char *sym) { /* 通过kprobe找到函数入口地址 */
int ret;//存储kprobe返回值
void *p; /* 用于保存要返回的函数入口地址 */
struct kprobe kp = { /* 初始化探针 */
.symbol_name = sym, /* 设置要跟踪的内核函数名 */
.pre_handler = noop_pre /* 放置前置程序 */
};
if ((ret = register_kprobe(&kp)) < 0) { /* 探针注册失败就报告错误信息并返回空指针 */
printk(KERN_INFO "register_kprobe failed, error\n", ret);
return NULL;
}
/* 保存探针跟踪地址,即函数入口;输出注册成功信息,注销探针,返回地址 */
p = kp.addr;//kp.addr中包含我们要查找的内核函数地址
printk(KERN_INFO "%s addr: %lx\n", sym, (unsigned long)p);//打印内核函数名称以及地址
unregister_kprobe(&kp);//注销kprobe
return p;//返回找到的内核函数地址
}
kprobes技术作用是跟踪内核函数的执行状态,即可以在运行的内核中动态的插入探测跟踪点,当内核运行到我们设定的探测跟踪点的时候,我们可以执行预定义的回调函数,得到内核函数的地址,kprobes包括kprobe、jprobe和kretprobe三种探测手段
kprobe:实现jprobe和kretprobe的基础。可以在内核中任意位置放置探测点并且提供了三种回调方式,分别是pre_handler(在被探测指令执行前调用)、post_handler(在被探测指令执行后调用)和fault_handler(在内存访问出错时调用)。
jprobe:获取被探测函数的入参值。函数入口插入探测点,当函数被调用时,jprobe会捕获到函数的参数,并在pre_handler中将这些参数传递给用户定义的回调函数。
kretprobe:获取被探测函数的返回值。函数出口插入探测点,当函数执行完毕返回时,kretprobe会捕获到函数的返回值,并在post_handler中将返回值传递给用户定义的回调函数。

我们首先要用kprobe找到函数的入口地址,并定义需要用到的结构体,我们预期是将struc kprobe结构体引申到内核kprobes子系统上以实现我们跟踪探测进程的目的,那么我们可以采用kprobes提供的接口即register_kprobe向内核中注册kprobe探测点,并进行判断返回值<0我们就返回空指针打印错误报告,返回0则注册成功。

我们可以查看struct kprobe结构体并选择打印内核函数名称以及内核函数的地址

探测完成后我们调用 unregister_kprobe函数从内核中卸载kprobe探测点,在整个探测过程中,当产生中断异常的时候,我们为了让kprobe执行pre_handler以及单步执行指令,那么我们探测的内核函数的执行就会被暂停中断,所以说当kprobe执行完成之后,我们探测的内核函数的执行继续后可以成功运行,可以找到stack_trace_save_tsk的地址,可以打印出相关load指标和相关进程及其调用栈
同样的,先前的kallsyms_lookup_name函数我们也可以通过kprobe方法进行调用
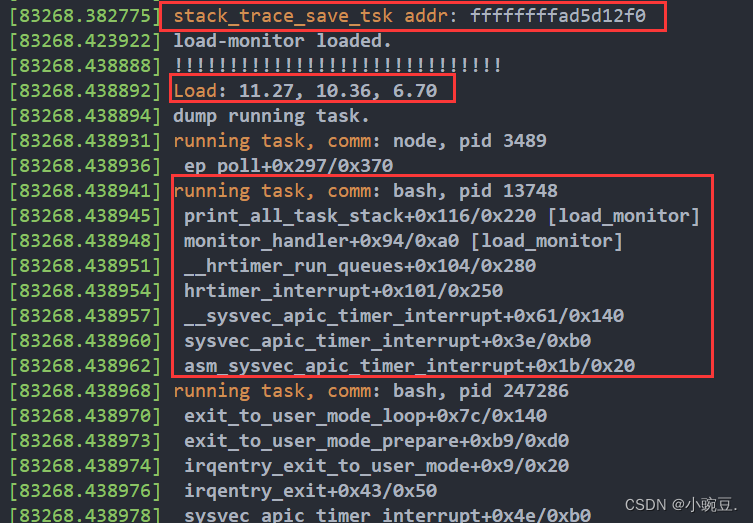
可以看到相应进程对应的函数调用栈被打印了出来,其具体各个字段的含义如下,每个进程会从下至上依次调用相应函数

问题解答
1、为什么要定义OS_VER这个变量?
OS_VER := UNKOWN
UNAME := $(shell uname -r)
ifneq ($(findstring 6.2.0-34-generic,$(UNAME)),)
OS_VER := UBUNTU_2204
endif
当在$(UNAME)中找不到6.2.0-34-generic时,将OS_VER定义为UBUNTU_2204
make CFLAGS_MODULE=-D$(OS_VER) -C /lib/modules/`uname -r`/build M=`pwd` modules
这部分设置了一个名为 CFLAGS_MODULE 的环境变量,并将其值设置为 -D$(OS_VER)。-D 标志通常用于在 C/C++ 程序中定义预处理宏。
OS_VER用于在编译时指定某个操作系统的版本或其他相关信息,以便进行版本控制,在源程序中可以配合条件编译,使其编译对应部分的代码,从而提高程序兼容性
2、load.h里面什么都没有,这有什么用?
认为是便于更新和维护,后期方便添加各种功能函数以便使用,而不影响其代码主体
如后面添加了find_kallsyms_lookup_name函数,通过调用kprobe找到stack_trace_save_tsk的地址位置,从而可以调用该函数,即使该函数并没有被内核文件所EXPORT
3、文中讲了那么久了,还没有切入正题。作者是不是忘记了是在解Load高的问题?
在解决问题前,需要先对问题对象进行介绍,并使用工具或语句来模拟相关的环境,构造测试用例,通过一步步的添加代码,从定时器入手,到一步步的监测,让读者能更好的看到程序的框架和脉络,有助于读者的理解,也为后文做了铺垫
4、某些版本的Linux内核不能直接调用kallsyms_lookup_name,有哪些办法获得内核函数/变量的地址?
1、可以通过kprobe找到其地址来进行调用,如本例中调用stack_trace_save_tsk函数
2、查看System.map,其为内核的符号表,在内核编译时被构建
sudo cat System.map-6.2.0-34-generic |grep kallsyms_lookup_name
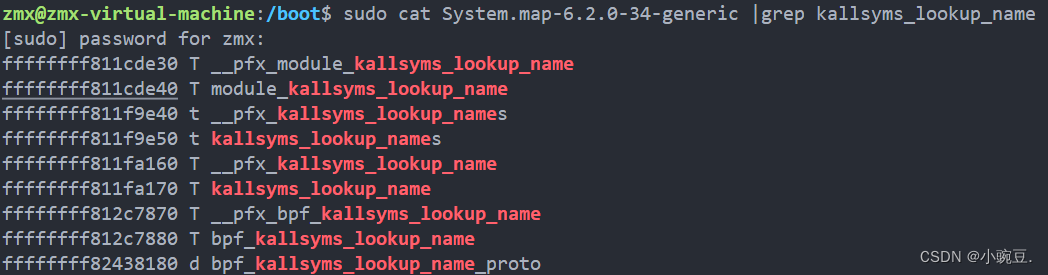
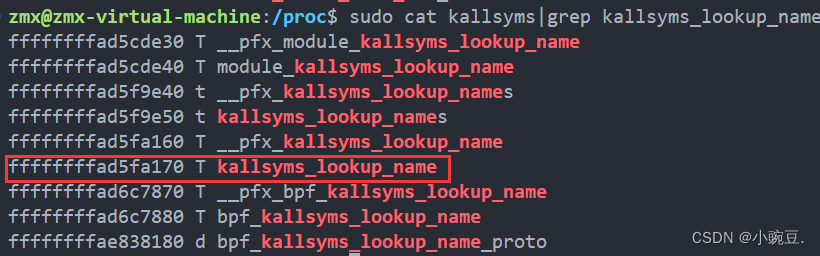
3、使用 /proc/kallsyms
cat /proc/kallsyms |grep "name"
5、模块代码还有哪些值得改进的地方?
1、可以将判断标准与时间间隔写成宏定义的形式,便于后续修改代码
#define CHECK_TIME 10
#define PRINT_TIME 20
2、在计算间隔时,又于每一次进入check_load()函数都间隔10ms,所以我们可以使用cnt来进行判断,而不使用相关的变量及**ktime_to_ms**(**ktime_sub**(**ktime_get**(), last))函数,这样就可以减轻由于监控系统负载而产生的负载,但精度可能会低、没有准确保障。
static void check_load(void)
{
int load =LOAD_INT(ptr_avenrun[0]);
int cnt=0;
if(load<2)
return ;
cnt++;
if(cnt<PRINT_TIME*1000/CHECK_TIME)
return;
print_all_task_stack();
cnt=0;
}
6、你还有其他方法跟踪Load高问题吗?不同的方法什么优缺点?
1、使用top、htop、ps来看进程列表和相关资源使用情况,优点可以快速查看到系统的负载,查看哪些进程占用了资源,便于定位问题进程,缺点是需要手动分析
2、查看系统日志文档,如var/log/messages以及var/log/syslog以查找可能与负载高相关的错误消息或警告,优点是可以捕获系统事件和错误,有助于了解系统问题的根本原因,缺点是需要具备日志分析的技能,而且可能需要花费时间来查找相关信息
3、使用性能分析工具如 perf, strace, dtrace 或 systemtap 来分析进程的系统调用和性能瓶颈。优点是提供详细的系统性能数据缺点,缺点是会引入额外的开销。
4、使用监控工具如 Nagios, Zabbix, Prometheus 等来实时监控系统性能,优点是自动化监控,提供实时警报,有助于快速响应问题,缺点是需要配置和管理监控系统,会引入一些性能开销
int_all_task_stack();
cnt=0;
}
**6、你还有其他方法跟踪Load高问题吗?不同的方法什么优缺点?**
1、使用top、htop、ps来看进程列表和相关资源使用情况,优点可以快速查看到系统的负载,查看哪些进程占用了资源,便于定位问题进程,缺点是需要手动分析
2、查看系统日志文档,如`var/log/messages`以及`var/log/syslog`以查找可能与负载高相关的错误消息或警告,优点是可以捕获系统事件和错误,有助于了解系统问题的根本原因,缺点是需要具备日志分析的技能,而且可能需要花费时间来查找相关信息
3、使用性能分析工具如 `perf`, `strace`, `dtrace` 或 `systemtap` 来分析进程的系统调用和性能瓶颈。优点是提供详细的系统性能数据缺点,缺点是会引入额外的开销。
4、使用监控工具如 `Nagios`, `Zabbix`, `Prometheus` 等来实时监控系统性能,优点是自动化监控,提供实时警报,有助于快速响应问题,缺点是需要配置和管理监控系统,会引入一些性能开销















 1204
1204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









