







一.面向过程编程
(一)“面向过程”(Procedure Oriented)是一种以过程为中心的编程思想。分析出解决问题所需要的步 骤,然后用函数把这些步骤一步一步实现,使用的时候一个一个依次调用就可以了。
(二)面向对象的方法也是含有面向过程的思想。面向过程最重要的是模块化的思想方 法。比如拿学生早上起来这件事说明面向过程,粗略的可以将过程拟为: (1)起床 (2)穿衣 (3)洗脸刷牙 (4)去学校 而这4步就是一步一步地完成,它的顺序很重要,你只需要一个一个地实现就行了。 而如果是用面向对象的方法的话,可能就只抽象出一个学生的类,它包括这四个 方法,但是具体的顺序就不一定按照原来的顺序
(三)特性: 模块化 流程化 优点: 性能比面向对象高, 因为类调用时需要实例化,开销比较大,比较消耗资源; 单片机、嵌入式开发、Linux/Unix等一般采用面向过程开发,性能是最重要的因素。 缺点: 没有面向对象易维护、易复用、易扩展
二.面向对象编程
(一)面向对象是按人们认识客观世界的系统思维方式,把构成问题事务分解成各个对象,建立对 象的目的不是为了完成一个步骤,而是为了描叙某个事物在整个解决问题的步骤中的行为
(二)特性: 抽象 封装 继承 多态 优点: 易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性, 可以设计出低耦合 的系统,使系统更加灵活、更加易于维护 缺点: 性能比面向过程低
三.面向对象编程三大特性
(一)对象和类
类(Class)是现实或思维世界中的实体在计算机中的反映,它将数据以及这些数 据上的操作封装在一起。
对象(Object)是具有类类型的变量。类和对象是面向对象编程技术中的最基本的概念。
实例化是指在面向对象的编程中,把用类创建对象的过程称为实例化。是将一个抽象的概 念类,具体到该类实物的过程。实例化过程中一般由类名 对象名 = 类名(参数1,参数2…参数n) 构成。
# 类(Class),类(Class)是创建实例的模板
class Cat:
# 属性:一般是名词,eg: name, age, gender.....
name = 'name'
kind = 'kind'
# 方法: 一般情况是动词, eg: create, delete, eating, run......
def eat(self):
print('cat like eating fish.....')
# 对象(Object):对类的实例化(具体化),对象(Object)是一个一个具体的实例
fentiao = Cat()
print(Cat) # <class '__main__.Cat'>
print(fentiao) # <__main__.Cat object at 0x00E9FD70>
(二)封装特性
面向对象的三大特性是指:封装、继承和多态
封装,顾名思义就是将内容封装到某个地方,以后再去调用被封装在某处的内容
对于面向对象的封装来说,其实就是使用构造方法将内容封装到 对象 中,然后通过 对象直接或者self间接获取被封装的内容
# 类(Class)
class Cat:
def __init__(self, name, kind): # 形参
"""
1. 构造方法__init__,实例化对象时自动执行的方法
2. self是什么? self实质上是实例化的对象
3. 类方法中, python解释器会自动把对象作为参数传给self
"""
print('正在执行__init__构造方法')
print('self:', self)
# 属性:一般是名词,eg: name, age, gender.....
# 封装: self.name将对象和name属性封装/绑定
self.name = name
self.kind = kind
# 方法: 一般情况是动词, eg: create, delete, eating, run......
def eat(self):
print('cat %s like eating fish.....' %(self.name))
# 对象(Object):对类的实例化(具体化)
fentiao = Cat("花花", "白猫")
print()
print(fentiao.name)
print(fentiao.kind)
print()
fentiao.eat()

"""
练习:
显示如下:
小明,18岁,男,去购物广场购物
小王,22岁,男,去购物广场购物
小红,10岁,女,在学校学习
提示:
属性:name,age,gender
方法:shopping(), playGame(), learning()
"""
class People:
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
def shopping(self):
print(f'{self.name},{self.age}岁,{self.gender},去购物广场购物 ')
def learning(self):
print(f'{self.name},{self.age}岁,{self.gender},在学校学习')
p1 = People('小明', 18, '男')
p2 = People('小王', 22, '男')
p3 = People('小红', 10, '女')
p1.shopping()
p2.shopping()
p3.learning()

(三)继承特性
1.继承
继承描述的是事物之间的所属关系,当我们定义一个class的时候,可以从某个现有的class 继承,新的class称为子类、扩展类(Subclass),而被继承的class称为基类、父类或超类(Baseclass、 Superclass)
(1)单继承
class Student:
"""父类Student"""
def __init__(self, name, age):
self.name = name
self.age = age
def learning(self):
print(f'{self.name}正在学习')
class MathStudent(Student):
"""MathStudent的父类是Student"""
pass
# 实例化
m1 = MathStudent("粉条博士", 8)
print(m1.name)
print(m1.age)
m1.learning() # 不报错,子类里没有,但父类有该方法
# m1.choice_course() # 报错, 子类里没有,父类也没有的方法
重写父类方法: 就是子类中,有一个和父类相同名字的方法,在子类中的方法 会覆盖掉父类中同名的方法
class Student:
"""父类Student"""
def __init__(self, name, age):
self.name = name
self.age = age
def learning(self):
print(f'{self.name}正在学习')
def choice_course(self):
print('正在选课中'.center(50, '*'))
class MathStudent(Student):
"""MathStudent的父类是Student"""
def choice_course(self):
# 需求: 先执行父类的choice_course方法, 在个性化执行自己的方法。
# Student.choice_course(self) # 解决方法1: 直接执行父类的方法,但不建议
# 解决方法2: 通过super找到父类,再执行方法(建议且生产环境代码常用的方式)
super(MathStudent, self).choice_course()
info = """
课程表
1. 高等数学
2. 线性代数
3. 概率论
"""
print(info)
# 实例化
m1 = MathStudent("粉条博士", 8)
m1.choice_course()
s1 = Student("粉条博士", 8)
s1.choice_course()

练习

leetcode解答
"""
参考链接 https://www.cnblogs.com/klyjb/p/11237361.html
数组: 需要连续的内存空间.数组是有下标索引和data两部分组成,Vector、ArrayList都是以数组的形式存储在内存中,所以查询效率高,新增和删除效率不高,线程是安全的
链表: 不需要连续的内存空间,链表是有data和指向下一个数据的指针地址两部分组成,是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的
LinkedList则以链表的形式进行存储,所以查询效率底,新增和删除效率高,并且线程不安全
数组时间复杂度 链表
增加元素 O(n) O(1)
删除元素 O(n) O(1)
修改元素 O(1) O(n)
查看元素 O(1) O(n)
"""
# 封装节点类
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next #0,1,2...
def travel(self, head):
"""遍历链表里面的每一个元素"""
while head:
print(head.val, end=',')
head = head.next
def create_l1(): #列表的封装
# l1 = 2,4,3
# l2 = 5, 6, 4
l1 = ListNode()
node1 = ListNode(val=2)
node2 = ListNode(val=4)
node3 = ListNode(val=3)
l1.next = node1
node1.next = node2
node2.next = node3
return l1.next
def create_l2():
# l1 = 2,4,3
# l2 = 5, 6, 4
l2 = ListNode()
node1 = ListNode(val=5)
node2 = ListNode(val=6)
node3 = ListNode(val=4)
l2.next = node1
node1.next = node2
node2.next = node3
return l2.next
def addTwoNumbers(l1: ListNode, l2: ListNode) -> ListNode:
res = 0
l3 = ListNode()
cur = l3
while(l1 or l2):
if(l1):
res += l1.val # res=2
l1 = l1.next
if(l2):
res += l2.val # res=2+5=7
l2 = l2.next
# res=10, val=0, res=>val val=res%10
# res=14, val=4, 14%10=4
l3.next = ListNode(res%10)
l3 = l3.next
# res=10, 进位为1, 10//10=1
# res=14, 进位为1, 14//10=1
res //= 10
if res == 1:
l3.next = ListNode(1)
return cur.next
if __name__ == '__main__':
l1 = create_l1()
l2 = create_l2()
l3 = addTwoNumbers(l1, l2)
l3.travel(l3)
(2)多继承
a.多继承,即子类有多个父类,并且具有它们的特征
b.在Python 2及以前的版本中,由任意内置类型派生出的类,都属于“新式 类”,都会获得所有“新式类”的特性;反之,即不由任意内置类型派生出的类, 则称之为“经典类”;“新式类”和“经典类”的区分在Python 3之后就已经不存在,在Python 3.x 之后的版本,因为所有的类都派生自内置类型object(即使没有显示的继承 object类型),即所有的类都是“新式类”
c.新式类与经典类最明显的区别在于继承搜索的顺序不同,即: 经典类多继承搜索顺序(深度优先算法):先深入继承树左侧查找,然后再返回,开始查找右侧。 新式类多继承搜索顺序(广度优先算法):先在水平方向查找,然后再向上查找
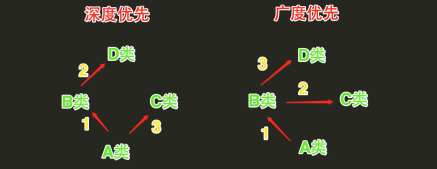
"""
新式类: 广度优先算法
经典类: 深度优先算法(py2中的部分类属于经典类)
python3所有的类都属于新式类。新式类的继承算法是广度优先。
# 分析多继承的相关代码
>pip install djangorestframework
from rest_framework import viewsets
viewsets.ModelViewSet
"""
class D(object):
def hello(self):
print('D')
class C(D):
# def hello(self):
# print('C')
pass
class B(D):
pass
# def hello(self):
# print('B')
class A(B, C):
pass
# def hello(self):
# print('A')
a = A()
a.hello() #D
(3)私有属性与私有方法
在 Python 中,实例的变量名如果以 __ 开头,就变成了一个私有变量/属性 (private),实例的函数名如果以 __ 开头,就变成了一个私有函数/方法(private)只 有内部可以访问,外部不能访问
优点:
1. 确保了外部代码不能随意修改对象内部的状态,这样通过访问限制的保护, 代码更加健壮。 2. 如果又要允许外部代码修改属性怎么办?可以给类增加专门设置属性方 法。 为什么大费周折?因为在方法中,可以对参数做检查,避免传入无效的参数
class Student:
"""父类Student"""
def __init__(self, name, age, score):
self.name = name
self.age = age
# 私有属性,以双下划线开头。
# 工作机制: 类的外部(包括子类)不能访问和操作,类的内部可以访问和操作。
self.__score = score
def learning(self):
print(f'{self.name}正在学习')
def get_score(self): #私有属性
self.__modify_score()
return self.__score
# 私有方法是以双下划线开头的方法,
#工作机制: 类的外部(包括子类)不能访问和操作,类的内部可以访问和操作。
def __modify_score(self): #私有方法
self.__score += 20
class MathStudent(Student):
"""MathStudent的父类是Student"""
def get_score(self): #子类继承
self.__modify_score()
return self.__score
# 报错原因: 子类无法继承父类的私有属性和私有方法。
s1 = MathStudent('张三', 18, 100)
score = s1.get_score()
print(score)
(四)多态特性
1.多态(Polymorphism)按字面的意思就是“多种状态”。在面向对象语言中,接口 的多种不同的实现方式即为多态。通俗来说: 同一操作作用于不同的对象,可以有不 同的解释,产生不同的执行结果
2.多态的好处就是,当我们需要传入更多的子类,只需要继承父类就可以了,而方法既可以直接 不重写(即使用父类的),也可以重写一个特有的。这就是多态的意思。调用方只管调用,不管 细节,而当我们新增一种的子类时,只要确保新方法编写正确,而不用管原来的代码。这就是著 名的“开闭”原则: 对扩展开放(Open for extension):允许子类重写方法函数 对修改封闭(Closed for modification):不重写,直接继承父类方法函数















 7462
7462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}