







1、查找之有序表
有序表是建立在元素有序的前提下,一般元素都是小到大
1、折半查找
折半查找(Binary Search)技术,又称为二分查找。它的前提是线性表中的记录必须是关键码有序(通常从小到大有序),线性表必须采用顺序存储。折半查找的基本思想是:在有序表中,取中间记录作为比较对象,若给定值与中间记录的关键字相等,则查找成功;若给定值小于中间记录的关键字,则在中间记录的左半区继续查找;若给定值大于中间记录的关键字,则在中间记录的右半区继续查找。不断重复上述过程,直到查找成功,或所有查找区域无记录,查找失败为止。
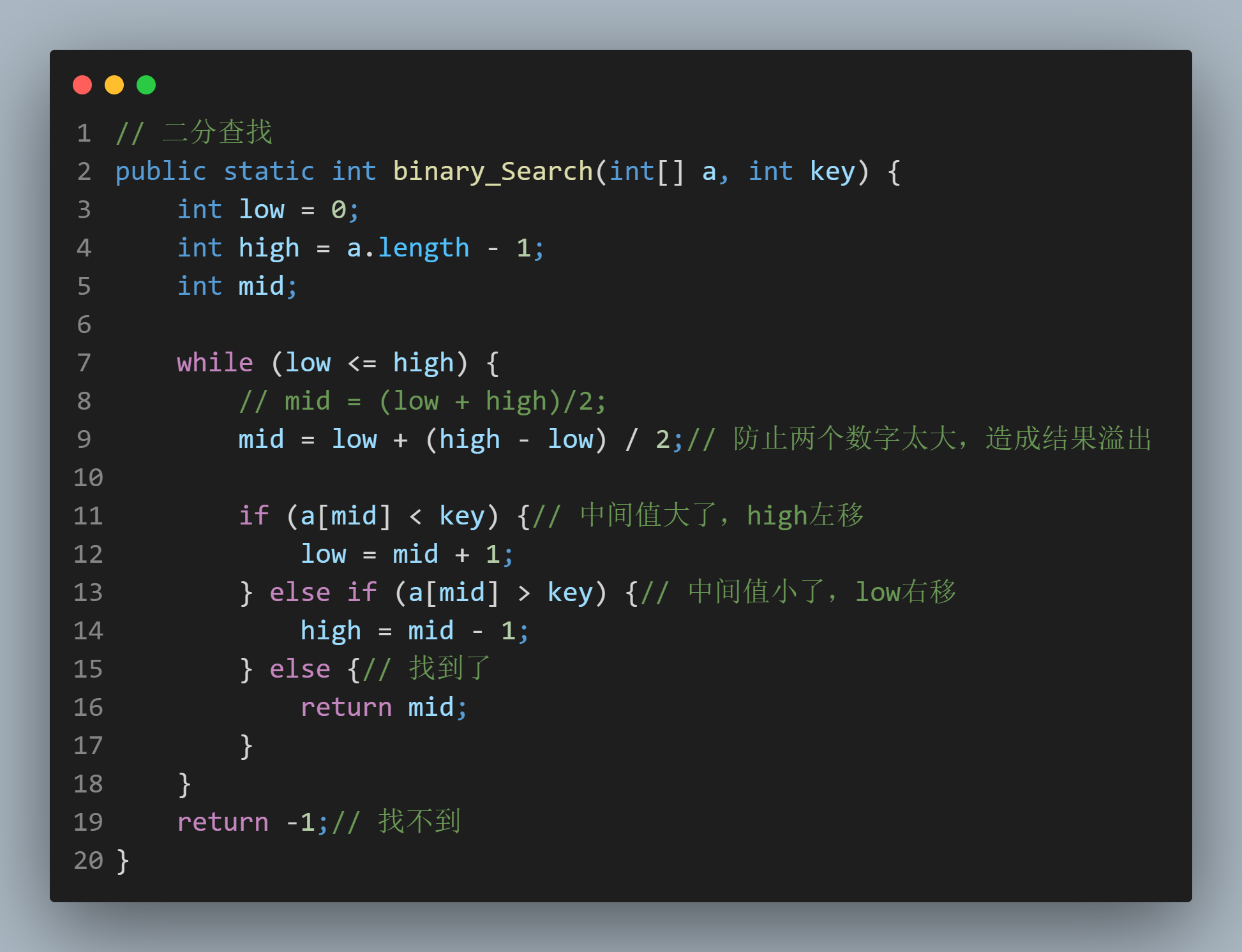
2、插值查找
算法科学家在折半查找的基础上做了改进
2.1折半查找与插值查找的对比
折半查找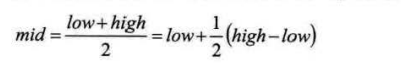
插值查找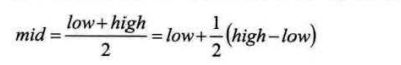
将1/2更改为如图所示,但是不稳定,在数据分布不均匀时,有时候报by zero除零异常,或在计算mid时总是计算到相同的值,陷入死循环
3、斐波那契查找
与折半查找不同的是利用了黄金分割比例0.618,折半查找是0.5
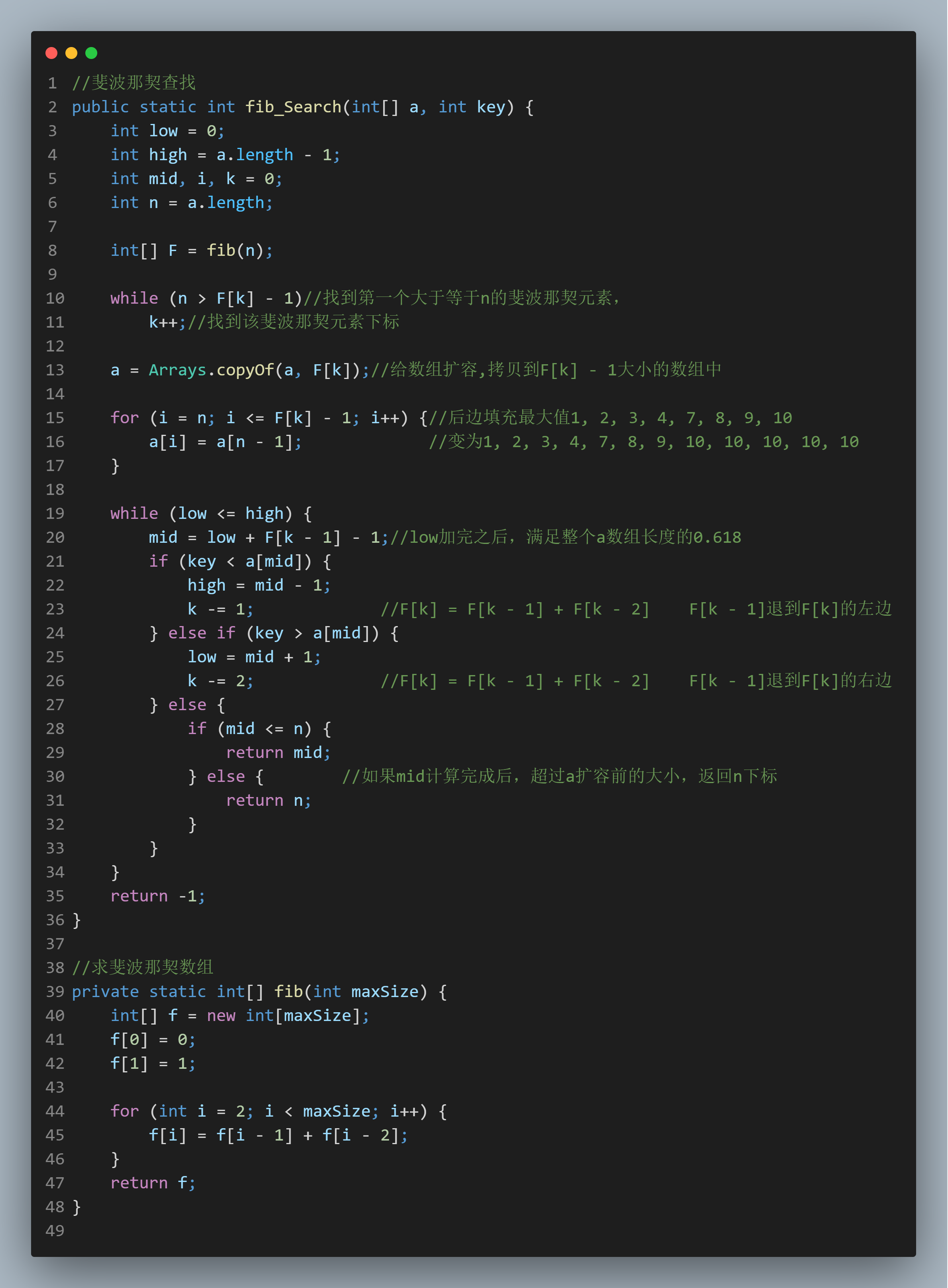
4、代码实现
package main.algorithems;
import java.util.Arrays;
public class Search {
//斐波那契查找
public static int fib_Search(int[] a, int key) {
int low = 0;
int high = a.length - 1;
int mid, i, k = 0;
int n = a.length;
int[] F = fib(n);
while (n > F[k] - 1)//找到第一个大于等于n的斐波那契元素,
k++;//找到该斐波那契元素下标
a = Arrays.copyOf(a, F[k]);//给数组扩容,拷贝到F[k] - 1大小的数组中
for (i = n; i <= F[k] - 1; i++) {//后边填充最大值1, 2, 3, 4, 7, 8, 9, 10
a[i] = a[n - 1]; //变为1, 2, 3, 4, 7, 8, 9, 10, 10, 10, 10, 10
}
while (low <= high) {
mid = low + F[k - 1] - 1;//low加完之后,满足整个a数组长度的0.618
if (key < a[mid]) {
high = mid - 1;
k -= 1; //F[k] = F[k - 1] + F[k - 2] F[k - 1]退到F[k]的左边
} else if (key > a[mid]) {
low = mid + 1;
k -= 2; //F[k] = F[k - 1] + F[k - 2] F[k - 1]退到F[k]的右边
} else {
if (mid <= n) {
return mid;
} else { //如果mid计算完成后,超过a扩容前的大小,返回n下标
return n;
}
}
}
return -1;
}
//求斐波那契数组
private static int[] fib(int maxSize) {
int[] f = new int[maxSize];
f[0] = 0;
f[1] = 1;
for (int i = 2; i < maxSize; i++) {
f[i] = f[i - 1] + f[i - 2];
}
return f;
}
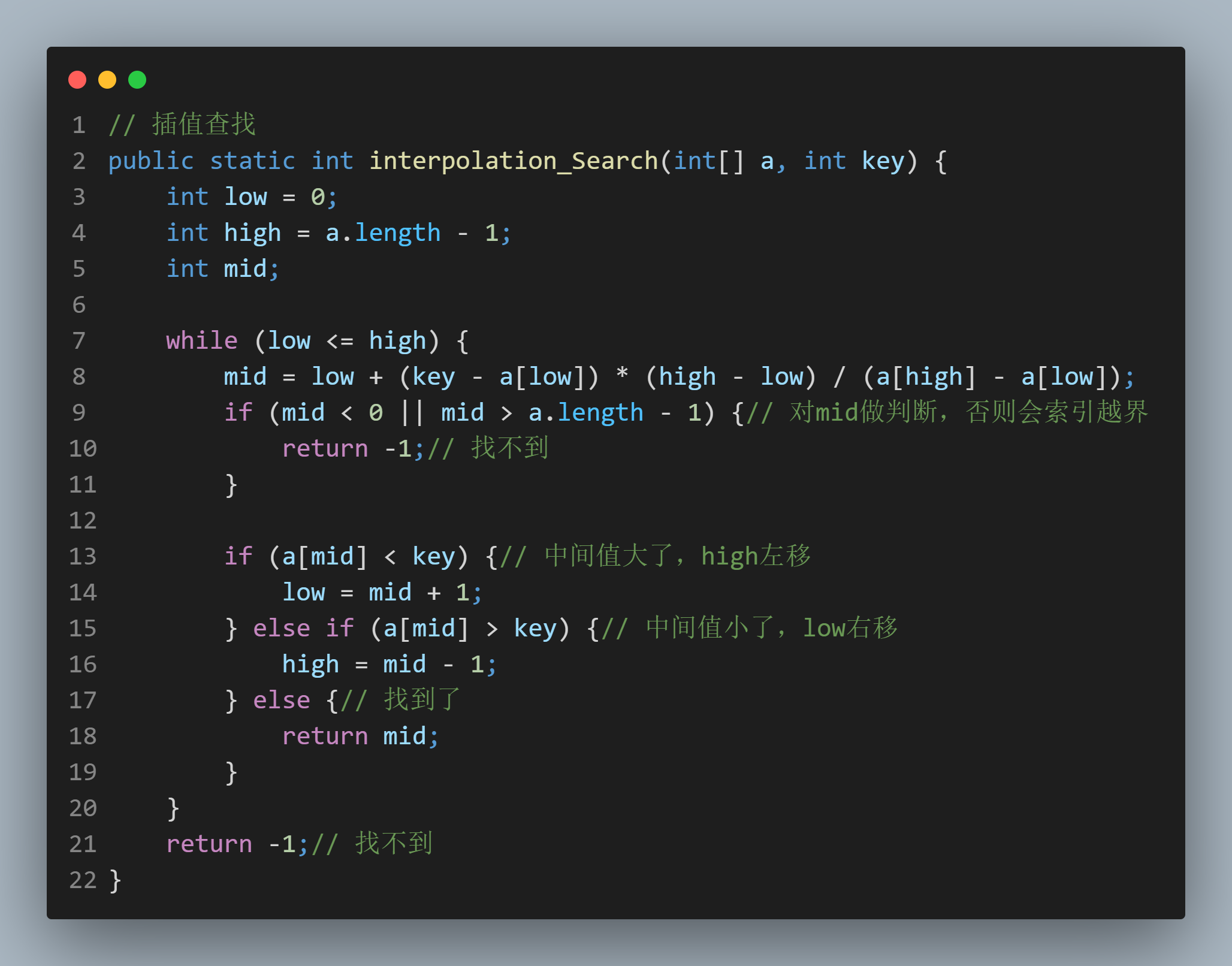
// 插值查找
public static int interpolation_Search(int[] a, int key) {
int low = 0;
int high = a.length - 1;
int mid;
while (low <= high) {
mid = low + (key - a[low]) * (high - low) / (a[high] - a[low]);
if (mid < 0 || mid > a.length - 1) {// 对mid做判断,否则会索引越界
return -1;// 找不到
}
if (a[mid] < key) {// 中间值大了,high左移
low = mid + 1;
} else if (a[mid] > key) {// 中间值小了,low右移
high = mid - 1;
} else {// 找到了
return mid;
}
}
return -1;// 找不到
}
// 二分查找
public static int binary_Search(int[] a, int key) {
int low = 0;
int high = a.length - 1;
int mid;
while (low <= high) {
// mid = (low + high)/2;
mid = low + (high - low) / 2;// 防止两个数字太大,造成结果溢出
if (a[mid] < key) {// 中间值大了,high左移
low = mid + 1;
} else if (a[mid] > key) {// 中间值小了,low右移
high = mid - 1;
} else {// 找到了
return mid;
}
}
return -1;// 找不到
}
public static void main(String[] args) {
// int[] a = { 1, 3, 5, 7, 9, 11, 18 };// 插值查找17会除零异常
// // int[] a = { 1, 2, 3, 4, 6, 7, 8, 9, 10 };//插值查找5会卡住
// int index = interpolation_Search(a, 17);
// System.out.println(index);
System.out.println("===========================");
int[] a = { 1, 2, 3, 4, 7, 8, 9, 10 };
int idx = fib_Search(a, 9);
System.out.println(idx);
}
}
5、缺点
- 斐波那契查找是按照黄金分割比例0.618,确定mid值,但是当要查找的数据在左半区时,比如1,则查找效率要低于折半查找
- 插值查找需要在数据分布均匀的情况下才能发挥较好,否则会报除零异常或计算mid值时陷入死循环
- 折半查找和插值查找查找在计算mid会进行四则运算,斐波那契查找仅仅是加减运算,在查找海量数据时细微的差别会影响最终的效率
- 斐波那契查找是按照黄金分割比例0.618,确定mid值,但是当要查找的数据在左半区时,比如1,则查找效率要低于折半查找
- 插值查找需要在数据分布均匀的情况下才能发挥较好,否则会报除零异常或计算mid值时陷入死循环
- 折半查找和插值查找查找在计算mid会进行四则运算,斐波那契查找仅仅是加减运算,在查找海量数据时细微的差别会影响最终的效率















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









