






一、前提声明
1、数据读取
df = pandas.read_csv('a.csv',header=16) #从第16行开始读

2、读取出错

原因: 解码方式不对,Windows打开文件默认是以'gbk'编码的
Unicode解码错误: 'utf-8'编解码器无法解码位置(第38行)中的字节:因为这个字节是无效的延续字节
0xd6:0x开始能区分十六进制与十进制表达,这里是0xd6(十六进制)=6*1+13*16=214(十进制)=1101 0110(二进制),即本次无法解码:1101 0110解决方式:
df = pandas.read_csv('a.csv',header=16,encoding='gbk')
3、保存警告,可以忽略
#交易时间分析
#index:横坐标,values:纵坐标 aggfunc=(sum,len,max,np.mean):列
df2 = pandas.pivot_table(df,index=['月份'],values=['金额'],aggfunc=(sum,len,max,numpy.mean))
原因:
实际上,将字符串 'mean' 传递给 aggfunc 参数是正确的方式,但对于某些聚合函数,确实会触发 FutureWarning。在 Pandas 1.3.0 及更高版本中,这个警告已被取消,因此您可以忽略它。
如果您使用的是 Pandas 1.3.0 或更新的版本,可以放心地继续使用之前的代码。这个警告不会影响代码的功能。如果您的 Pandas 版本较旧,可以考虑升级到最新版本以避免这个警告。
如果您想消除警告,您可以使用函数名字符串 'mean',并将 Pandas 升级到 1.3.0 或更高版本,这将解决警告问题。不过在较新的 Pandas 版本中,不再需要使用字符串 'mean'。
4、lambda模块简介
lambda是Python中的一个匿名函数,它可以在一行代码中定义简单的函数。lambda函数的语法如下:
lambda arguments: expression
其中,arguments是函数的参数,expression是函数的返回值。lambda函数可以有多个参数,用逗号隔开。下面是一个简单的例子:
f = lambda x, y: x + y
print(f(1, 2)) # 输出3
在这个例子中,我们定义了一个lambda函数f,它有两个参数x和y,返回值是x+y。我们可以直接调用f(1, 2)来计算1+2的结果
二、完整代码及结果
1、代码
import pandas #操作数据的函数
import numpy
df = pandas.read_csv('a.csv',header=16,encoding='gbk')
df['金额'] = pandas.to_numeric(df['金额(元)'].str[1:],errors='ignore') #去掉¥
df['交易时间'] = pandas.to_datetime(df['交易时间'],errors='ignore') #交易时间转化
df['时段'] = df['交易时间'].apply(lambda x: x.strftime('%H')) #交易时间的小时段
df['月份'] = df['交易时间'].apply(lambda x: x.strftime('%Y-%m'))
out_file_name = 'out.xlsx' #起文件名
write = pandas.ExcelWriter(out_file_name)
df.to_excel(excel_writer=write,sheet_name='原始数据')
#交易时间分析
#index:横坐标,values:纵坐标 aggfunc=(sum,len,max,np.mean):列
df2 = pandas.pivot_table(df,index=['月份'],values=['金额'],aggfunc=(sum,len,max,numpy.mean))
#保存结果搭配excel
df2.to_excel(excel_writer=write,sheet_name='交易时间分析')
write._save()
write.close()2、结果

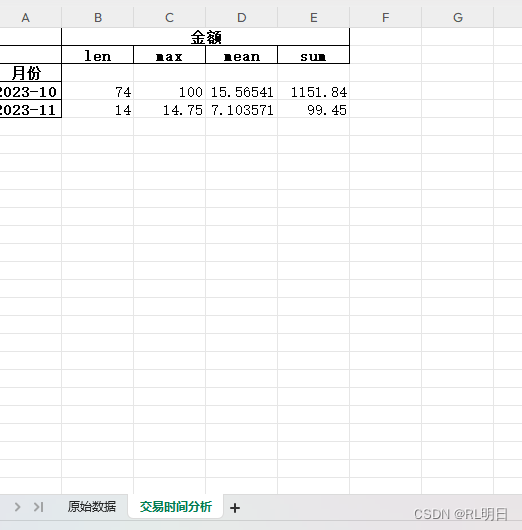
3、优化后的代码
# -*- coding: gbk -*-
import pandas as pd
import numpy as np
# 读取CSV文件
def read_csv_file(file_path, header_row, encoding='utf-8'):
try:
df = pd.read_csv(file_path, header=header_row, encoding=encoding)
return df
except Exception as e:
print("Error reading CSV file:", str(e))
return None
# 处理数据
def process_data(df):
df['金额'] = pd.to_numeric(df['金额(元)'].str[1:], errors='ignore') # 去掉¥
df['交易时间'] = pd.to_datetime(df['交易时间'], errors='ignore') # 交易时间转化
df['时段'] = df['交易时间'].apply(lambda x: x.strftime('%H')) # 交易时间的小时段
df['月份'] = df['交易时间'].apply(lambda x: x.strftime('%Y-%m'))
return df
# 保存结果到Excel
def save_to_excel(df, out_file_name):
try:
with pd.ExcelWriter(out_file_name) as writer:
df.to_excel(excel_writer=writer, sheet_name='原始数据')
# 交易时间分析
df2 = pd.pivot_table(df, index=['月份'], values=['金额'], aggfunc={'金额': [np.sum, len, np.max, 'mean']})
df2.to_excel(excel_writer=writer, sheet_name='交易时间分析')
print("Data saved to Excel successfully.")
except Exception as e:
print("Error saving to Excel:", str(e))
if __name__ == '__main__':
# CSV文件路径
csv_file = 'a.csv'
header_row = 16 # 适当调整标题行的位置
encoding_type = 'gbk' # 根据实际情况选择编码类型
# 读取CSV文件
data = read_csv_file(csv_file, header_row, encoding_type)
if data is not None:
out_file_name = 'out.xlsx' # 输出文件名
# 处理数据
processed_data = process_data(data)
# 保存到Excel
save_to_excel(processed_data, out_file_name)















 608
608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









