







Protobuf
Protobuf
Google Protocol Buffer( 简称 Protobuf)是Google公司内部的混合语言数据标准,他们主要用于RPC系统和持续数据存储系统。
Protobuf应用场景
Protocol Buffers可以用于结构化数据串行化,或者说序列化。它很适合做数据存储或RPC数据交换格式。它的优点在于以高效的二进制方式存储,比XML小3到10倍,快20到100倍。
Protobuf在go语言中的编程实现
Go语言中有对应的实现Protobuf协议的库,Github地址:https://github.com/golang/protobuf
安装
使用Go语言的Protobuf库之前,需要相应的环境准备:
1.安装protobuf编译器
可以在如下地址:https://github.com/protocolbuffers/protobuf/releases选择适合自己系统的Proto编译器程序进行下载并解压。
2.配置环境变量
windows系统下可以直接在Path目录中进行添加:

Protobuf 协议语法
Protobuf 协议的格式
Protobuf协议规定:使用该协议进行数据序列化和反序列化操作时,首先定义传输数据的格式,并命名为以**".proto"**为扩展名的消息定义文件。
message 定义一个消息
先来看一个非常简单的例子。假设想定义一个“订单”的消息格式,每一个“订单"都含有一个订单号ID、订单金额Num、订单时间TimeStamp字段。可以采用如下的方式来定义消息类型的.proto文件:
message Order{
required string order_id = 1;
required int64 num = 2;
optional int32 timestamp = 3;
}
可以看到在结构体字段类型的前面,还存在着三种关键字:
- 1、required:该规则规定,消息体中该字段的值是必须要设置的。
- 2、optional:消息体中该规则的字段的值可以存在,也可以为空,optional的字段可以根据defalut设置默认值。
- 3、repeated:消息体中该规则字段可以存在多个(包括0个),该规则对应java的数组或者go语言的slice。
注意:使用required弊多于利;在实际开发中更应该使用optional和repeated而不是required。
但是在protobuf 3中,直接去掉了 required 和 optional 修饰符,所有字段都是 optional 的,使用上更加简便。
使用Protobuf的步骤
1、创建扩展名为 .proto的文件 ,并编写代码。比如创建person.proto文件,内容如下:
syntax = "proto3";
package example;
// 表示生成到当前目录下,然后当前的这个proto文件属于example包
option go_package = "./;example";
message Person {
required string Name = 1;
required int32 Age = 2;
required string From = 3;
}
2、编译.proto文件,生成Go语言文件。执行如下命令:
protoc ./test.proto --go_out=./
然后会生成对应的 person.pb.go 文件。
3、在程序中使用Protobuf 在程序中有如下代码:
package main
import (
"fmt"
"ProtocDemo/example"
"github.com/golang/protobuf/proto"
"os"
)
func main() {
msg_test := &example.Person{
Name: proto.String("Davie"),
Age: proto.Int(18),
From: proto.String("China"),
}
//序列化
msgDataEncoding, err := proto.Marshal(msg_test)
if err != nil {
panic(err.Error())
return
}
msgEntity := example.Person{}
err = proto.Unmarshal(msgDataEncoding, &msgEntity)
if err != nil {
fmt.Println(err.Error())
os.Exit(1)
return
}
fmt.Printf("姓名:%s\n\n", msgEntity.GetName())
fmt.Printf("年龄:%d\n\n", msgEntity.GetAge())
fmt.Printf("国籍:%s\n\n", msgEntity.GetFrom())
}
Protobuf序列化原理
之前已经做过描述,Protobuf的message中有很多字段,每个字段的格式为:修饰符 字段类型 字段名 = 域号;
Varint
Varint是一种紧凑的表示数字的方法。它用一个或多个字节来表示一个数字,值越小的数字使用越少的字节数。这能减少用来表示数字的字节数。
Varint中的每个byte的最高位bit有特殊的含义,如果该位为1,表示后续的byte也是该数字的一部分,如果该位为0,则结束。其他的7个bit都用来表示数字。因此小于128的数字都可以用一个byte表示。大于128的数字,比如300,会用两个字节来表示:1010 1100 0000 0010。下图演示了 Google Protocol Buffer 如何解析两个bytes。注意到最终计算前将两个byte的位置相互交换过一次,这是因为 Google Protocol Buffer 字节序采用little-endian的方式。
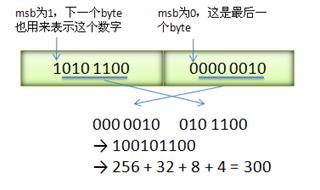
在序列化时,Protobuf按照TLV的格式序列化每一个字段,T即Tag,也叫Key;V是该字段对应的值value;L是Value的长度,如果一个字段是整形,这个L部分会省略。
序列化后的Value是按原样保存到字符串或者文件中,Key按照一定的转换条件保存起来,序列化后的结果就是 KeyValueKeyValue…依次类推的样式,示意图如下所示:
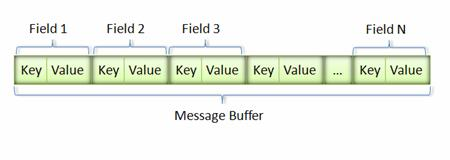
采用这种Key-Pair结构无需使用分隔符来分割不同的Field。对于可选的Field,如果消息中不存在该field,那么在最终的Message Buffer中就没有该field,这些特性都有助于节约消息本身的大小。比如,我们有消息order1:
Order.id = 10;
Order.desc = "bill";
则最终的 Message Buffer 中有两个Key-Value对,一个对应消息中的id;另一个对应desc。Key用来标识具体的field,在解包的时候,Protocol Buffer根据Key就可以知道相应的Value应该对应于消息中的哪一个field。
Key 的定义如下:
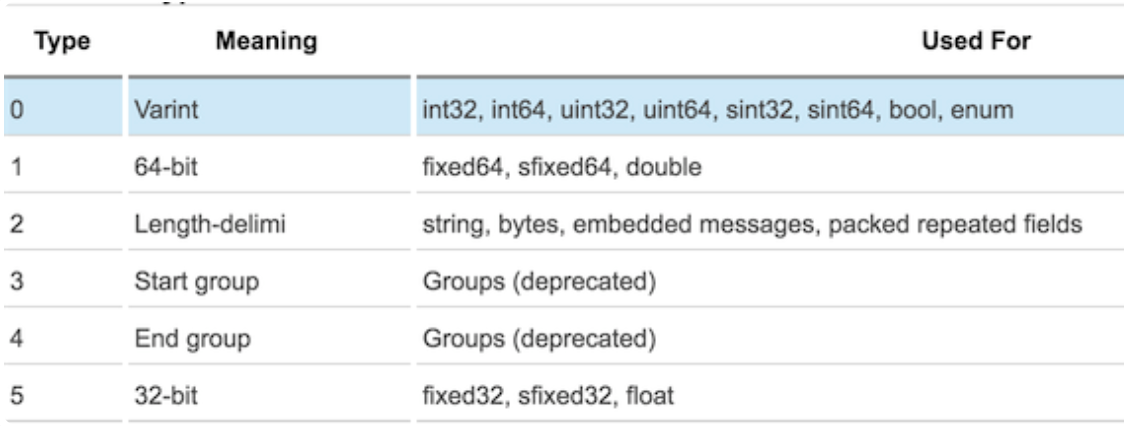
(field_number << 3) | wire_type
可以看到 Key 由两部分组成。第一部分是 field_number,比如消息lm.helloworld中field id 的field_number为1。第二部分为wire_type。表示 Value的传输类型。而wire_type有以下几种类型:















 4352
4352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









