






什么是温度?什么是topk,top-p?什么是采样sample?什么是贪心搜索(Greedy Search)?什么是束搜索(Beam Search)?
白话讲解这些概念,需要有点点概率的基础。
什么是温度?
gpt2的源码中可以看到这个 logits = logits[:, -1, :] / temperature logits = top_k_logits(logits, k=top_k) log_probs = F.softmax(logits, dim=-1)
假如我数字,3,2,1对应的输出,除以temprature=0.2,那么,3-->15,2-->10,1-->5
原始的3,2,1经过softmax后对应的概率是0.66,0.24,0.09,3,2,1除以温度后经过softmax得到的概率是0.9932,0.006,0.000045,所以,温度越低,概率分布就会越尖锐,得到的结果就会越确定。
什么是贪心搜索Greedy Search?
很简单,我通过当前词预测下 一个词,选择预测的词语中最大的概率就好了。
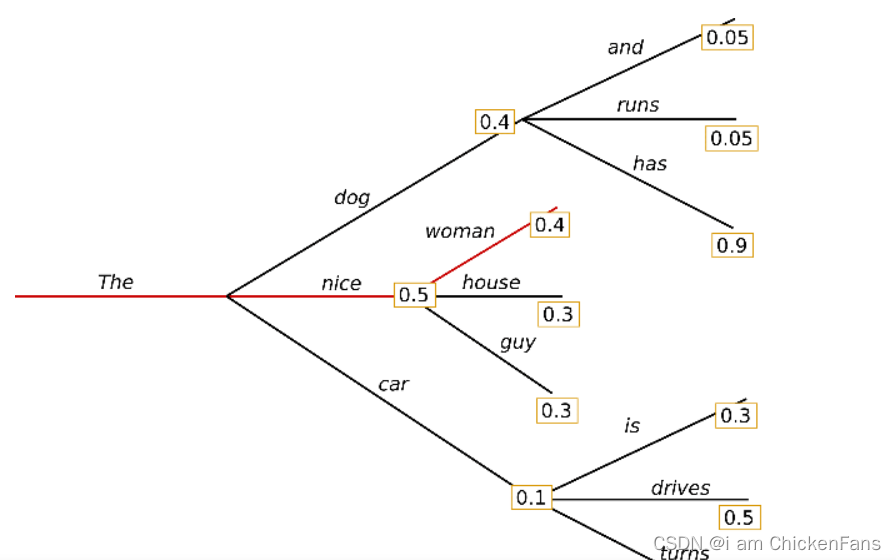
对应的是红色线,每次都找概率最大的那个词,最后生成的就是The nice woman。
缺点很明显:
-
输出确定性太强,没有任何随机性。
-
容易出现一直重复
这也是语言模型中最常见的问题。在greedy search和后面要说的beam search中很常见。
什么是Beam Search?
刷过leetcode的小伙伴都会知道,贪心算法容易陷入局部最优,那么有什么方法去做到全局最优呢,那最简单的方法就是全局搜索,但是全局搜索的时间复杂度太高!所以有没有折中的方法呢,Beam Search就是这个折中的方法。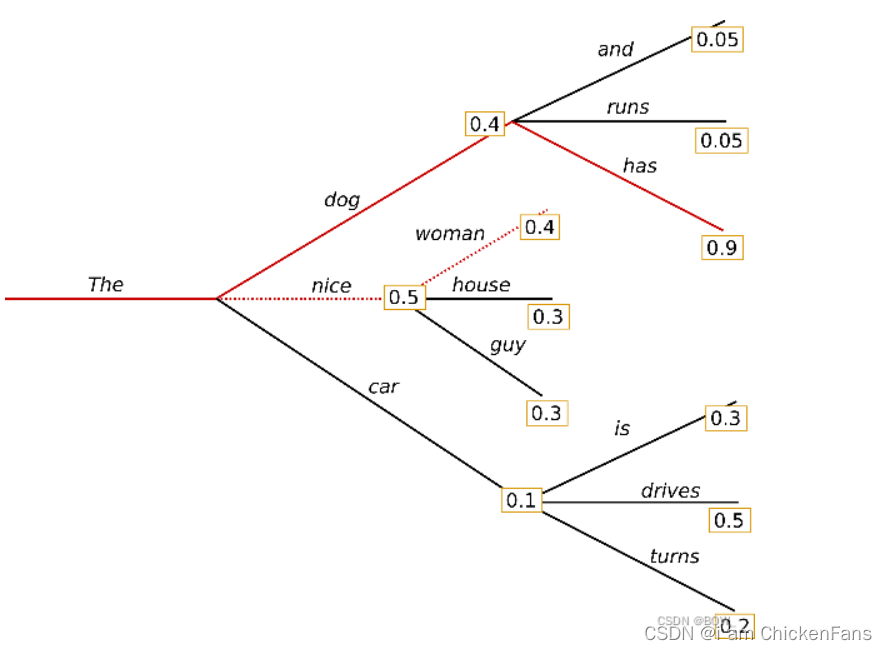
Beam search,我们设置3个分支,然后当前词会预测三个分支对应词的概率,像图上的dog,nice,car就是三个分支,然后预测到dog以后又会有三个分支对应着三个概率,我们选择概率最大的分支The dog has。
概率最大是怎样计算的呢?
p(dog)*p(has)=0.4*0.9,大于p(nice)*p(woman)=0.5*0.4
beam_output = model.generate( input_ids, max_length=50, num_beams=5, early_stopping=True #num_return_sequences=5 ) num_beams指定分支的数量。 no_repeat_ngram_size=2
但还是会出现大量的重复,所以使用no_repeat_ngram_size参数去限制重复的次数为两次。但是如果原始文本中出现大量的地名或者重复的词语的时候,这个会将输出变得很奇怪。
与此同时我们也可以设置参数返回多个分支的结果:
num_return_sequences=5
此时会有多个输出。
结论:
-
在开放的生成中,beam search可能不是最好的原因(如果是想固定答案,这样做可能效果会好?在机器翻译或者摘要这种结果的长度或多或少可以被预测的任务中表现很好)根据任务选择
-
beam search会有严重的重复生成问题。所以在生成中使用n-gram或者其他惩罚都很难控制,在强制"不重复"和重复特定的n-gram上寻找一个好的平衡需要大量的微调 -
开放的场景中,人类的语言不是一个高概率问题,我们不希望,总是出现可预测的答案。
所以就出现了sample采样
sample采样的意思就是说,我的词语有个概率分布值,比如,nice为0.5,dog是0.4,car是0.1,采样就是说我随机选择nice的概率是0.5,选择dog的概率是0.4,car的概率是0.1,虽然说我的nice比car的概率更大,这也只是说明你nice更容易被选中,但我的car也有几率被选中。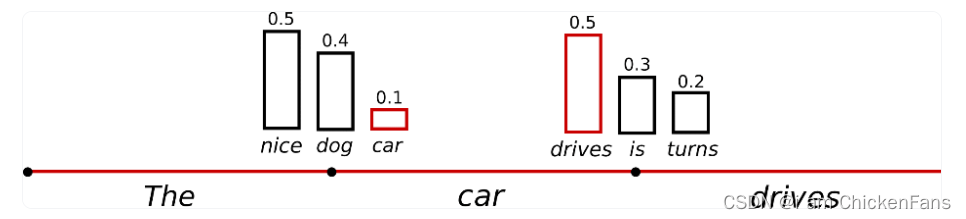
如果使用了do_sample=True,就会出现胡说八道的情况,听起来不像是人写的。
然后就可以通过去控制温度(参考第一个解答)让nice的概率变成0.9,那我dog就是0.08,car就是0.02,那1次采样采到car的概率就会低很多,当然,温度系数等于0的时候,nice的概率就无限接近于1了,所以就等于贪婪解码。
topk采样
刚刚提到的都是基于完整的词表的采样,但是呢,我们不需要整个词表,我们只需要和当前词语更相关的几个或者几十个词语就好了,这里的topk选择的是6,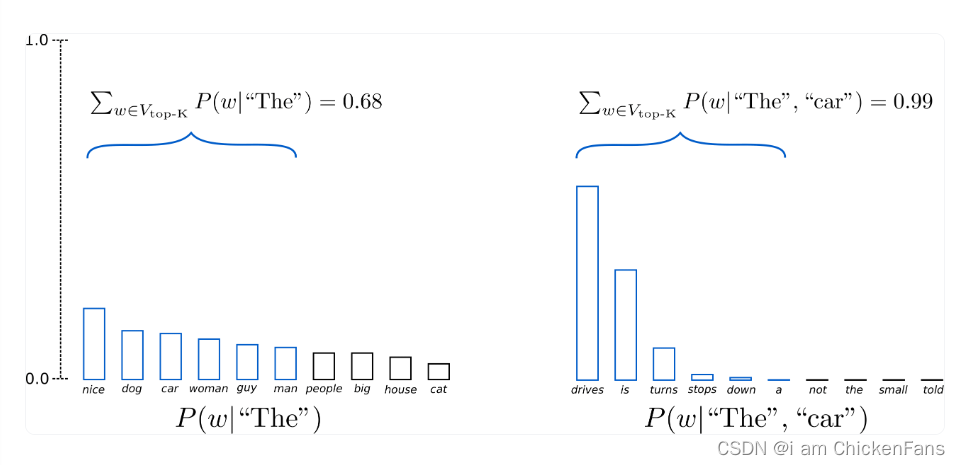
可以看到,在上面图像中的第二幅图,消除掉了not,the,small,told这些看着和当前词语没有任何关系的词语,
#参数设置 top_k=50
但是,还是会出现,stops,down等和当前词语没有任何关系的词语,因此固定topk的时候,会造成胡说八道的危险。
所以,这个时候引用到了一个思想,像主成分分析的思想,我选择累计概率大于>0.9的部分就好了。
top-p采样
我不再是固定K个单词了,我要从累计概率超过p的单词集中开始进行选择。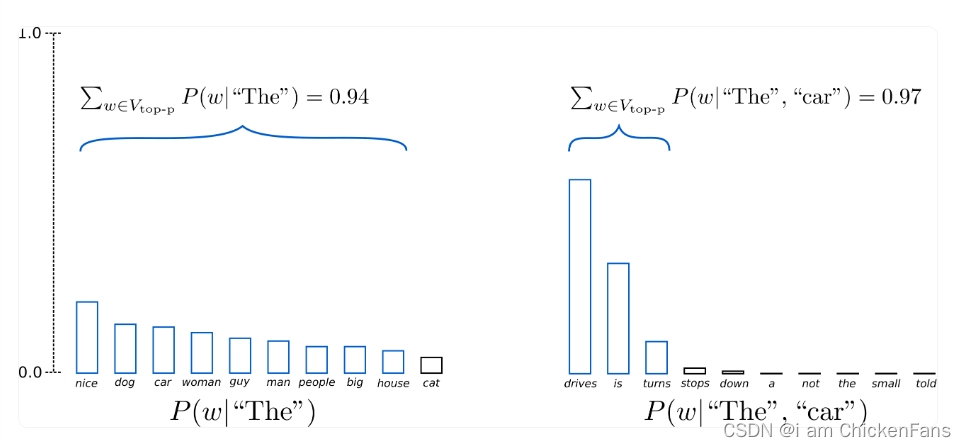
设置p的值为0.92,,这张图是什么意思呢,就是说,当前词为the,预测的下一个单词的对应的词表和概率如图一所示,p(nice)+p(dog)+...+p(house)=0.94>0.92,然后我就选择这些词语作为我的topk,同理,p(driver)+p(is)+p(turns)>0.97,作为我的topk,这样做的好处就是,把一些概率很低的词语删除,这样是不是就会生成的更好了?
参数 top_p=0.92, top_k=0
topk还可以和top-p合起来使用,动态选择。
sample_outputs = model.generate( **model_inputs, max_new_tokens=40, do_sample=True, top_k=50, top_p=0.95, num_return_sequences=3, )


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









