







文章目录
Collection 接口
Collection结构图
这里直接放动力节点的图了
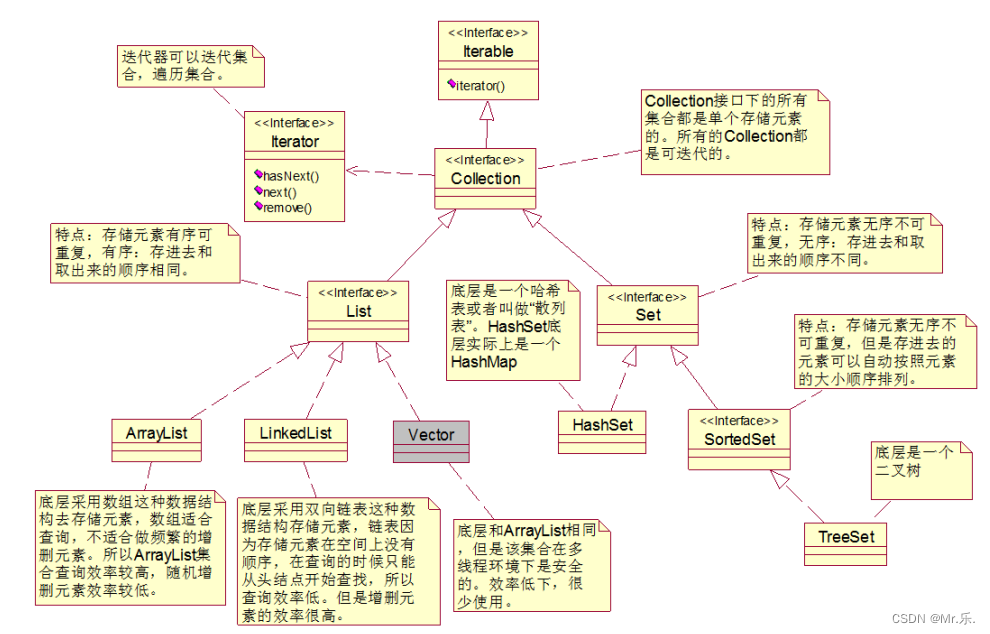
虚线是实现,实线是继承
Collection接口中的方法
- boolean add(Object o):在集合末尾添加元素
- boolean addAll(Collection c):把另一个集合添加到这个集合
- boolean remove(Object o):删除集合中和 o 一样的元素,有就返回 >true 没有 false
- boolean removeAll (Collection c):从此集合中删除另一个集合在此集合中有的元素
- boolean contains(Object o):判断集合是否包含此元素
- boolean containsAll (Collection c):判断另一个集合的元素是否都在此集合中
- boolean isEmpty():判断集合是否为空
- int size():返回集合内元素个数
- object[] toArray:返回一个包含本类所有集合的数组
- void clear():清空集合内元素
- Iterator iterator():返回一个迭代器【因为继承了 iterable 然后又实现了 iterator,触发 iterator 多态】
contain remove 底层用 equals 判断
public class T {
public static void main(String[] args) {
Collection collection = new ArrayList();
//s1 和 s2 地址不一样,s1 加入 collection
String s1 = new String("abc");
collection.add(s1);
String s2 = new String("abc");
//这里 s2 没有加入 s1 但是返回 true 因为底层调用的是 equals
// String 重写了 equals 比较的是内容所以返回 ture;
System.out.println(collection.contains(s2));
}
}
Iterator 与 Iterable 接口
Collection 接口 继承了 Iterable 接口,所以有 Iterator() 方法,调用 Iterator() 方法 返回 一个 Iterator 类型的迭代器,而 Collection 又实现了 Iterator 接口,然后用 Iterator 类型的变量 接收 Iterator 方法返回的迭代器,就能 触发多态 使用 Iterator 里的方法
public class T {
public static void main(String[] args) {
Collection c = new ArrayList<>();
//Collection 继承了 Iterable 所以可以使用 Iterable 中的 iterator()
//返回一个 Iterator 类型的变量
//Collection 又实现了 Iterator,那肯定重写了方法,这里触发多态
Iterator iterator = c.iterator();
iterator.hasNext();
iterator.next();
}
}
注意点:
- 注意迭代器最初并没有指向第一个元素
- 当集合的结构发生改变时,迭代器必须重写获取,用老的迭代器会出现ConcurrentModificationException异常
public class T {
public static void main(String[] args) {
Collection c1 = new ArrayList();
c1.add(100);
c1.add(200);
c1.add(300);
Iterator iterator = c1.iterator();
while (iterator.hasNext()) {
Object o = iterator.next();
//删除元素集合结构发生改变抛出ConcurrentModificationException异常
//c1.remove(o);
//使用迭代器删除: 删除指向的这个元素,并更新迭代器
iterator.remove();
System.out.println(o);
}
System.out.println(c1.size());
}
}
Collection集合遍历方式
迭代器遍历
IDEA 可以用 itit快捷键快速创建迭代器
public class test {
public static void main(String[] args) {
Collection<Integer> collection = new ArrayList<>();
collection.add(1);
collection.add(2);
collection.add(3);
collection.add(4);
collection.add(5);
Iterator<Integer> iterator = collection.iterator();
while (iterator.hasNext()) {
Integer num = iterator.next();
System.out.println(num);
}
}
}
增强 for 遍历
public class test {
public static void main(String[] args) {
Collection<Integer> collection = new ArrayList<>();
collection.add(1);
collection.add(2);
collection.add(3);
collection.add(4);
collection.add(5);
for (Integer num : collection) {
System.out.println(num);
}
}
}
List(线性表)
特点
- 添加顺序和取出顺序一致
- 可以插入重复的元素
- List 容器中的元素都对应一个整数型的序号记载其在容器中的位置,可以根据序号存取容器中的元素
List特有方法
- void add(int index, Object element):在特定下标插入元素
- Object remove(int index):删除特定下标元素
- Object set(int index, Object element):修改特定下标的值,返回修改前的值
- Object get(int index):返回此下标的位置的元素
- int indexOf(Object o):返回 o 在集合中第一次出现的索引,没找到返回 -1
- int lastIndexOf(Object o):返回 o 在集合中最后一次出现的索引
- List subList(int fromIndex, int toIndex):截取集合返回List,左闭右开
public class test {
public static void main(String[] args) {
List<Integer> list = new ArrayList<Integer>();
//add 在特定位置插入元素
list.add(0, 1);
list.add(1, 2);
list.add(2, 3);
//remove 删除特定下标元素
//删掉 0下标 元素,后面元素前移
list.remove(0);
//set 修改特定下标的值
//把 0下标 改为 1
list.set(0, 1);
//get 返回此下标元素
//返回 1
System.out.println(list.get(0));
//indexOf 返回元素第一次出现的索引
//下标为 0 找到 1
System.out.println(list.indexOf(1));
//lastIndex 返回最后一次出现的索引
// 1 只出现了一次还是返回 1
System.out.println(list.lastIndexOf(1));
//subList 截取集合,左闭右开
//截取 list 结合 [0, 2] 返回 一个 list 对象
List<Integer> list2 = list.subList(0, 2);
}
}
ArrayList(可变数组)
- 可以加入 null
- 底层是非线程安全的 Object[] 数组
- 因为是数组所以,查询效率高,随机增删效率低
ArrayList 底层原理
维护了一个 Object 类型的数组 transient Object[] elementData;
如果使用无参构造,则 初始elementData 容量为 0,第一次添加则扩容 elementData 为 10,后面扩容都是扩容 1.5倍
第一次无参构造添加刨析
先观察一下基本的元素
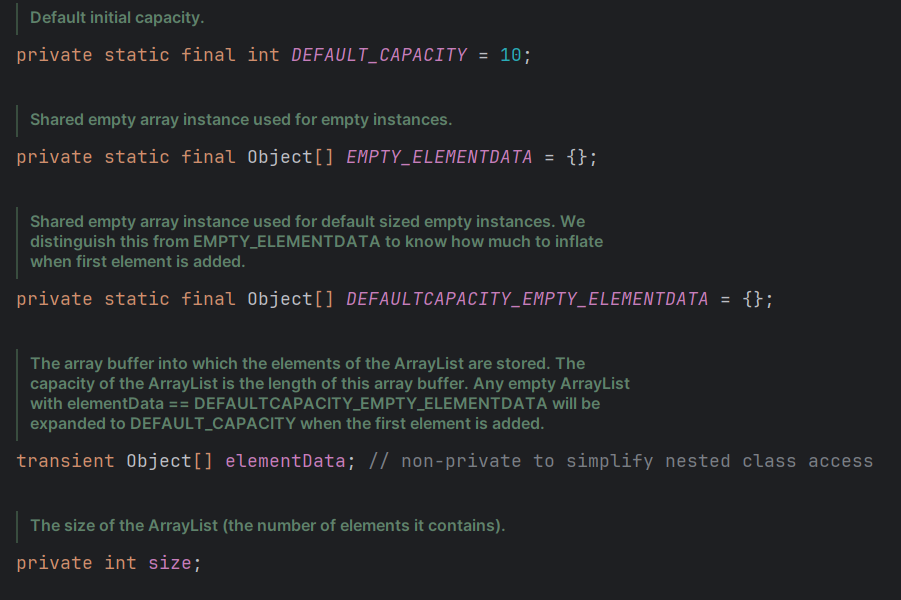
- 第一步:进入无参构造,默认是 ElEMENTDATA,这个数组默认为空,前面观察过

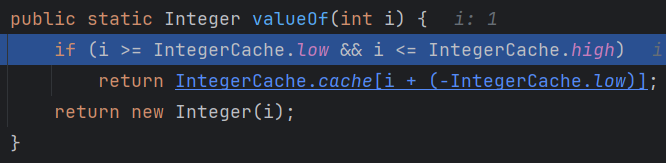
- 第二步:如果是基本数据类型,要先装箱
- 第三步:开始添加,先进如第一个函数确保空间足够
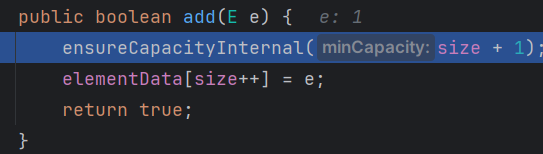
这里传入的 size + 1 = 1; 前面我们观察过 size 默认为0
- 第五步:进入函数,当元素为空,那就直接给 10
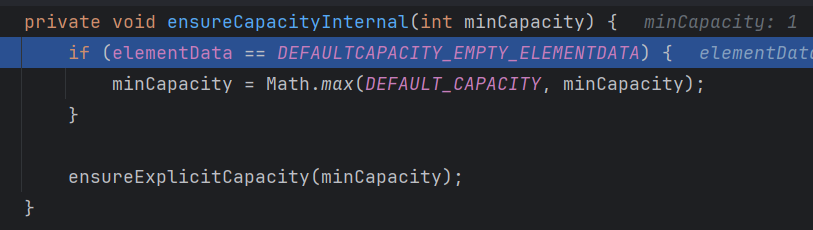
这里 DEFAULTACAPCITY这个数组是空,DEFAULT_CAPACITY这个元素是 10 ,之前观察过
第六步:这时候我们的 minCapacity 变成 10了,正式进入扩容,如果minCapacity > elementData.length 就开始扩容
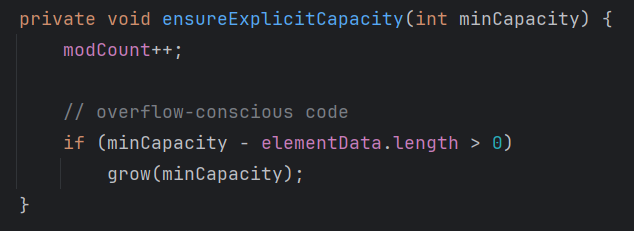
此时 10 - 0 > 0 开始走 grow
- 第七步:grow 扩容
第一次添加 时 数组还是空的,所以 oldCapacity 是 0 ,所以 new Capacity 也是 0 , minCapacity 从前面知道是 10, 0 - 10 < 0 直接 newCapacity = 10;最后 elementData 利用 copyof 扩容出十个元素
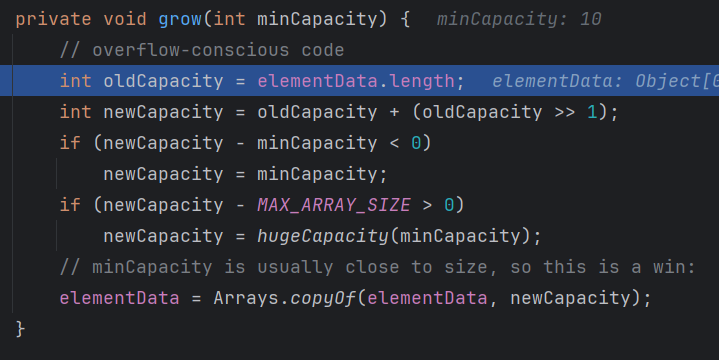
这里 oldCapacity >> 1 就是 oldCapacity 的 一半
- 有参构造情况
除了构造这里不一样,其他地方和无参构造完全一样
initialCapacity 就是传进来的数,因为有数了后面 grow 里的 oldCapacity + (oldCapacity >> 1) 就有数可以扩容了,所以需要扩容时直接就扩容 1.5 倍
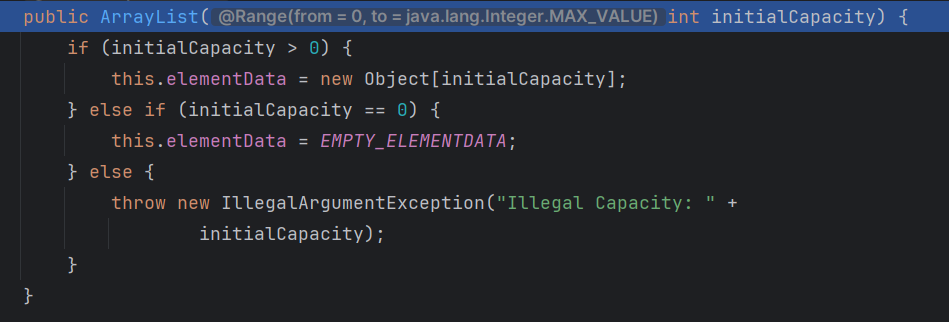
ArrayList 底层原理总结
第一次开始 默认是 0 ,所以 oldCapacity + (oldCapacity >> 1) 是 0, 直接把 10 给 newCapacity,扩容为10
第二次开始,有了前面的 10 了 所以 oldCapacity + (oldCCapacity >> 1) 开始扩容 1.5倍。
Vector(线程安全的可变数组)
- 线程安全
- 底层是可变数组
- 因为是数组所以,查询效率高,随机增删效率低
Vector 底层原理
如果是无参构造,默认10,满了就按 2 倍扩容
如果是有参构造,满了直接 2 倍扩容
第一次无参构造扩容刨析
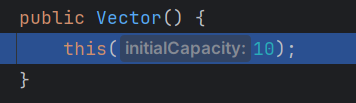
- 第一步:调用构造器
第一层this 里面传个 10 跳到
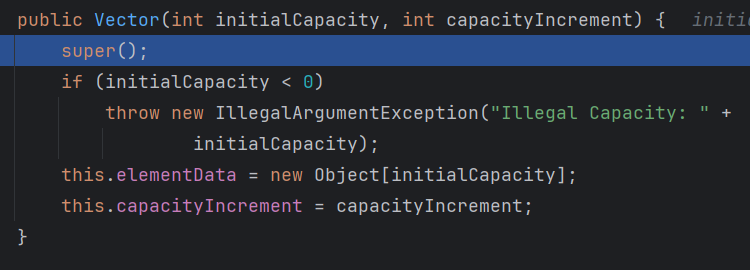
有参构造,把 10 和 0继续跳到下一层
另一个有参构造,此时initwialCapacity = 10,elementData = new Object[initialCapacity],所以这里是初始容量为 10

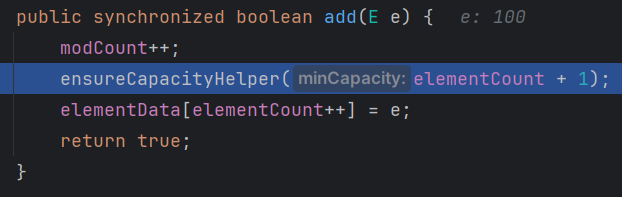
- 第二步:开始添加元素
确保元素够不够,不够就扩容,因为构造时已经是 10 了所以不用扩容了。
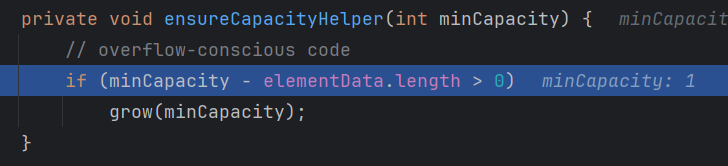
- 满后开始扩容的算法
newCapacity = oldCapacity + ((CapacityIncrement > 0) ? capacityIncrement : oldCapacity); 这里的 capacityincrement 构造完肯定是大于 0 的所以扩容直接 双倍oldCapacity,也就是两倍扩容
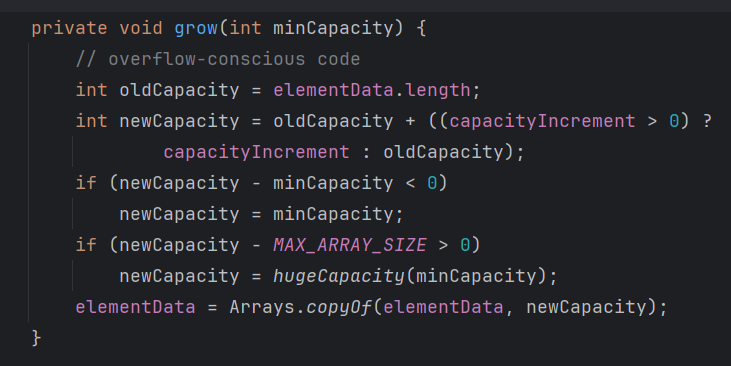
Vector 和 ArrayList 比较
两者都是可变数组
Arraylist:线程不安全,所以效率比 Vector 高,无参构造,第一次扩容为10,后面开始 1.5 倍,有参构造直接 1.5倍扩容
Vector:线程安全,所以效率比 ArrayLIst 低,无参构造默认为10, 满了之后后面按 1.5 倍扩容,如果是有参构造,每次直接 2 被扩容
Arraylist 的无参构造时,默认空数组,add时才开始扩容,而 Vector 是构造的时候直接就扩容了
LinkedList(双向链表)
- 可以添加任意元素,包括null
- 线程不安全
- 因为是链表所以,增删效率高,改查效率低
LinkList 特有的方法
- 头插和尾插:addFirst(),addLast()
- 头删和尾删:removeFirst(), removeLast()
- 头取和尾取:getFirst(),getLast()
LinkList 底层原理
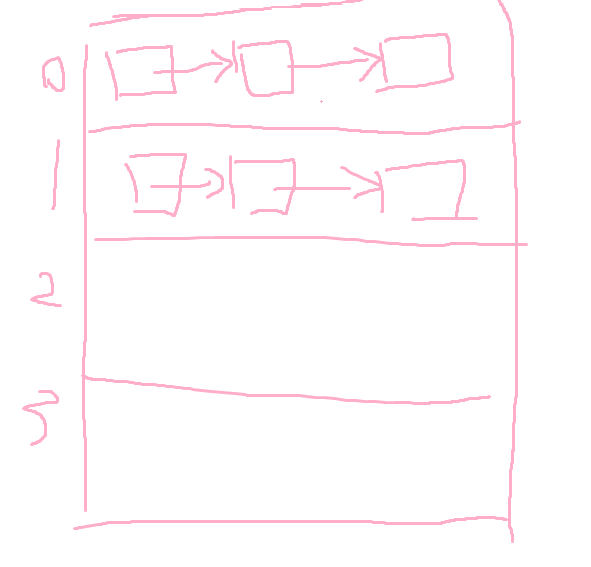
类中维护了两个属性 first 和 last 分别指向首节点和尾节点
每个节点(Node对象),里面又维护了 prew, next, item 三个属性,其中通过 prev 指向前一个节点,next 指向后一个节点
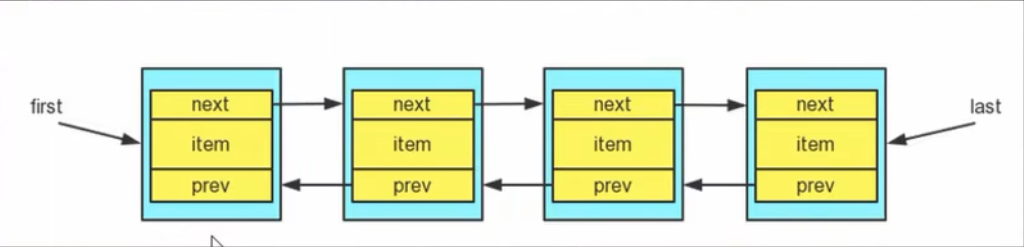
底层添加元素刨析
先观察一下基本元素

- 增加节点
l 指向 最后一个元素,创建一个新节点,然后,last 指向这个新创建节点,如果 l 指向的元素 last 是 null ,那 first 就指向这个新创建的节点,如果 l 不是空,那就然后 l 的后一个元素指向新的节点(新节点弄到链表最后)
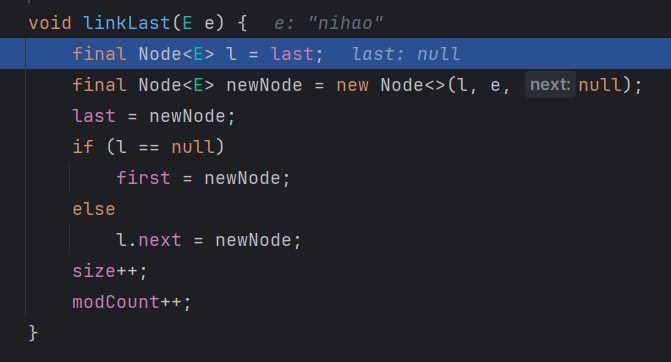
new 出来的 Node 节点底层
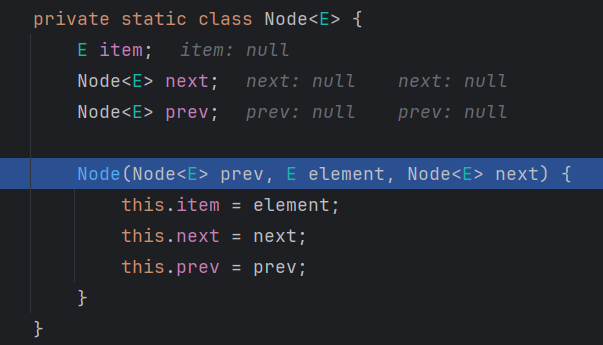
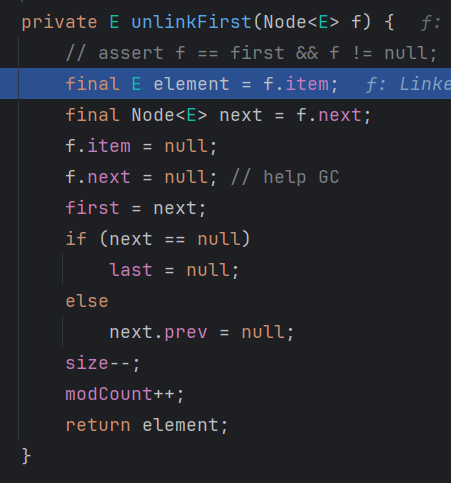
- 删除节点
f 指向第一个元素先,如果没有第一个元素抛出异常,有的话进 unlinkFirst函数
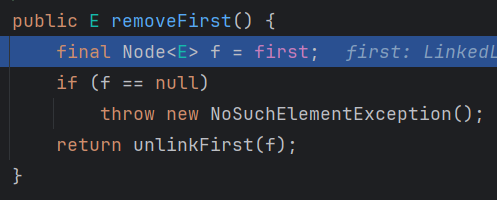
element 放 第一个节点的元素
用 f 把第一个节点的 next 和 元素变 null,然后 first 指向第二个元素,然后判断,第二个元素是不是空,是的话 last 也空,不是的话 第二个元素的 prev 断掉,最后返回删掉的元素
头删法
Set
- 添加和取出的顺序不一致,不可以通过索引获取元素
- 不允许重复元素,所以最后一个 null
- 取出的顺序虽然不是添加顺序,但他是固定的,比如取出十次还是这个顺序
HashSet(哈希表)
- 底层是 Hashmap
- 可以存放 null,但只能有一个
- 不能有重复元素
- 线程不安全
HashSet 底层原理
底层是:数组+链表 + 红黑树
1. HashMap底层维护了Node类型的数组table,默认为null当创建对象时,将加载因子(loadfactor)初始化为0.75.
———————————————————————————————————————————————
2. 当添加key-val时,通过key的哈希值得到在table的索引。然后判断该索引处是否有元素,如果没有元素直接添加。如果该索引处有元素,继续用 equals 判断该元素的key和准备加入的key相是否等,如果相等,则直接替换,如果不相等需要判断是树结构还是链表结构,做出相应处理。如果添加时发现容量不够,则需要扩容。
———————————————————————————————————————————————
3. 第1次添加,则需要扩容table容量为16,临界值(threshold)为12 (16*0.75)
———————————————————————————————————————————————
4. 以后再扩容,则需要扩容table容量为原来的2倍(32),临界值为原来的2倍,即24,依次类推
———————————————————————————————————————————————
5. 在Java8中,如果一条链表的元素个数超过 TREEIFY_THRESHOLD(默认是8),并且table的大小 >= MIN TREEIFY_CAPACITY(默认64),就会进行树化(红黑树),如果 链表到 8 了 table 没到 64,会把 table 按 2 倍扩容
String 的 hash 值是通过数据算出来的,所以数据一样 hash 值就一样
HashSet 添加和寻找原理
元素的唯一性是靠所存储元素类型是否重写hashCode()和equals()方法来保证的,如果没有重写这两个方法,则无法保证元素的唯一性
//如果当前索引位置对应的链表的第一个元素和准备添加的key的hash值相同(p.hash == hash)
//并且满足下面两个条件之一,就不能往里面加
//1. 准备加入的 key 和 p 指向的 Node 结点的 key 是同一个对象
//2. p 指向的 Node 结点的 key 的 equals() 和 准备加入的 key比较后相同
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
这里还是放动力节点的图

同一个单项链表上所有节点的 hashCode 相同,因为数组下标一样。但同一个链表上 key 和 key 的 equals 方法肯定不一样,以此保证 key 不重复
重写 hashCode() 和 equals() 问题
重写 hashCode() 问题
- 如果hashCode 返回固定值:那就是数组同一个位置,变成单向链表了,这种情况称为 散列分布不均匀
- 如果hashCode 全返回不一样的值:变成一维数组了,没有链表了
- 散列分布均匀:需要重写 hashCode 方法时有一定技巧
如果不重写 hashCode,可能发生对象内容一样,内存地址不一样,然后下标就一定不一样。然后底层直接就存进去了,不比较 equals 了。然后就发生了 key 值的重复
为什么重写 hashCode() 还要重写 equals
equals 默认比较的是地址,如果不重写 equals,(两个对象内容完全一样,地址一定不一样了),然后就加进去了,直接重复了
为什么重写 equals 必须重写 hashCode()
equals 方法返回 true 表示两个对象相同,那他们的 hash值一定是一样的,因为在同一个单向链表上,他们的哈希值相同,所以 hashCode() 方法返回值也必须一样
我们一般在属性一样时返回一样的 hash值,这样就一样了,就可以去重了
如果要哪两个参数不相等,就重写哪两个参数的 hash,eqauls,如果是多个类,就多个类都写
LinkedHashSet
- HashSet 的一个子类
- 底层是 LinkedHashMap,底层维护了一个数组 + 双向链表 + 红黑树
- LinkedHash 根据元素的 hashCode 决定存储位置,同时使用链表维护元素次序,这使得元素看起来是以插入顺序保存的
基本和 HashSet一样,只是他是双向链表,插入顺序和输出顺序看起来是一样的
TreeSet (二叉树)
- 底层是 TreeMap
- 使用无参构造,会用自然排序(要求元素实现了 Comparable 接口并重写 CompareTo 方法)
- 使用有参构造,可以传入一个 Comparator 对象作为参数,实现自定义排序
- TreeSet 集合中的元素:无序不可重复,但是可以按照元素大小顺序自动排序:可排序集合
- 放到 TreeSet集合 key 部分的元素,等同于放到 TreeMap集合 key 部分
两种比较使用
1. 自定义排序 (Compatator)
TreeSet treeSet = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
o1 o2 //前者大返回正数
o2 o1 //后者大了所以返回负数所以结果反过来了
@Override
return ((String)o1).compareTo((String)o2);
}
});
默认是升序,从小到大
返回正数,那么大值会放后面,实现升序
返回负数,那么小值放后面,实现降序
2. 自然排序(Comparable)
pubilc class Student implements comparable {
@public int compareTo(Student s) {
...
}
}
如果compareTo方法返回负数,那么表示当前对象(this)在排序顺序上应该位于指定对象的前面。
如果compareTo方法返回正数,那么表示当前对象(this)在排序顺序上应该位于指定对象的后面
如果compareTo方法返回0,那么表示两个对象在排序顺序上是相等的,则不添加
TreeSet 去重机制:
如果传入一个comparator 匿名对像,就是用 compare 去重,如果方法返回 0,就认为是相同的元素,不添加,没传入就以添加的对象实现的 Compareable接口的 compareTo 去重
Comparator<? super K> cpr = comparator;
if (cpr != null) {//cpr 就是我们的匿名内部类(对象
do {
parent = t;
//动态绑定到我们的匿名内部类(对象)compare
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else //如果相等,即返回0,这个Key就没有加入
return t.setValue(value);//这里不是替换,是加入不了,但是 key一样就是替换
} while (t != null);
}
当比较规则不会发生改变的时候,或者说比较规则只有一个的时候,建议实现 Comaprable 接口
如果比较规则有多个,并且需要多个比较规则之间频切换,建议实现 Comparator 接口
Comaprator 接口的设计符合二 OCP 原则
如果对象没有实现自然排序,你自己又不传一个自定义排序器,那就会报错
Map接口
Map接口图
这里放动力节点的图

Map接口中的方法
- void clear():清空集合
- boolean containsKey(Object key):查询 Map 中是否包含指定的 key 包含就返回 true
- boolean containValue(Object value):查询 Map中是否包含指定value, 包含就 true
- boolean isEmpty():查询 Map 是否为空,如果空返回 true
- Object put(Object key, Object value):添加一个 (K,V),如果有相同的 K 就覆盖掉
- Object remove(Object key):删除 k 对应的 v,返回删除后的 v,如果k不存在,返回 null
- Object get(Object key):返回指定 k 对应的 v,不包含 k 就返回 null
- void putAll(Map m):将指定的 Map中的 K V 复制过来
- Set keySet():返回 Map 中所有 key 所组成的 Set 集合
- Collection values():返回 Map 中所有 value 组成的 Collection 集合
- Set<Entry》entrySet() :返回 Map 中所有的 K,V组成的 Set 集合,每个元素都是 Map.Entry对象(实际是HashMapNode$类型,因为这个Node实现了 Entry,所以这里是向上转型,多态)
- int size():返回该Map 里的键值对个数
内部类Map.Entry 里的方法
用 Set entrySet():返回的里面都是Map.Entry 的集合
- Object getKey():返回该Entry 里包含的Key值
- Object getValue():返回该Entry里包含的 Value 值
- Object setValue():设置该Entry里包含的 Value ,并返回这个Value
Map集合遍历方式
利用 KeySet:查找 Key 是否存在
//取出所有 Key, 通过 Key 取出对应 Value
Set keyset = map.keySet();
//1. 增强 for
for (Object key : keyset) {
System.out.println(key + "-" + map.get(key));
}
//2. 迭代器
Iterator iterator = keyset.iterator();
while (iterator.hasNext()) {
Object key = iterator.next();
System.out.println(key + "-" + map.get(key));
}
利用 Collection value:获取所有的 Value
//第二组: 把所有 value 取出
Collection values = map.values();
//1. 增强 for
//2. 迭代器
利用 entrySet:获取 K-V
Set entrySet = map.entrySet(); //EntrySet<Map.Entry<K, V>>
//1. 增强 for
for (Object entry : entrySet) {
//将entry 转成 Map.Entry
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue());
}
System.out.println("-----");
//2. 迭代器
Iterator iterator1 = entrySet.iterator();
while (iterator1.hasNext()) {
Object next = iterator1.next();
System.out.println(next); //HashMap$Node -实现 -> Map.Entry (getKey, getValue)
}
HashMap(哈希表)
HashMap特点
- 线程不安全
- Key 值一样,最后一个会覆盖,允许使用 K-V 可以是 null
- 输入输出顺序不一样,因为底层是 哈希表
其他东西基本和 HashSet一样,因为HashSet底层是 HashMap,只是 HashSet 的 V 位置用 PRESENT 占位了,详细看HashSet那里
HashTable
HashTable特点
- 线程安全
- K-V 都不能为 null
扩容机制
构造时默认大小是 11,到达某个阈值就触发扩容机制,阈值因子是0.75,就是被填充到 75% 时就会开始扩容
扩容过程中,创建新数组,大小一般时原数组两倍,然后 Hashtable 会遍历原数组中每个元素的位置,并使用哈希函数重新计算他们在新数组的位置,重新哈希后,元素会被转移到新数组对应位置
hashtabl 和 hashmap 的区别
- HashMap集合key部分允许 null
- Hashtable 的 key 和 value 都不能为 null,会报 NullPointerException
- Hashtable 线程安全(但是效率低有其他方案),HashMap 线程不安全
LinkedHashMap
- HashMap的子类,基本和 HashMap差不多,而它自己是LinkedHashSet 的底层所以基本和 前面讲的 LinkedHashSet 一样
Properties
底层是 Hashtable
专用用于读取配置文件的集合类
配置文件的格式:
key = 值
value = 值
K-V 不需要有空格,V 不需要用引号引起来,默认类型位String
Properties常用方法
- load(InputStream inStream): 加载配置文件的 k-v 到 Properties 对象
- list: 将数据显示到指定设备
- getProperty(key): 根据 k 获取 v
- setProperty(key, value):设置 k-v 到 Properties 对象
- store(outputstream out, string comments):将 Properties 中的 k-v 存储到配置文件,在 idea 中,保存信息到配置文件,如果含有中文会存储 unicode 码
public class test {
public static void main(String[] args) throws IOException {
//1. 创建 properties 对象
Properties properties = new Properties();
//2. 加载指定配置文件
properties.load(new FileReader("e:\\mysql.properties"));
//3. 把 k-v 显示到控制台
properties.list(System.out);
//4. 根据 key 获取对应的值
String user = properties.getProperty("user");
String pwd = properties.getProperty("pwd");
System.out.println("用户名是:" + user);
System.out.println("密码是:" + pwd);
}
}
创建新配置文件
public class test {
public static void main(String[] args) throws IOException {
//使用 properties 来创建配置文件,修改配置文件内容
//1. 如果该文件没有这个key,就是创建
//2. 如果有这个 key 就是覆盖
Properties properties = new Properties();
//创建
properties.setProperty("charest", "utf8");
properties.setProperty("user", "汤姆");
properties.setProperty("pwd", "abc111");
//将 k-v 存储到文件中
properties.store(new FileOutputStream("e:\\mysql2.Properties"), null);
System.out.println("保存配置文件成功");
}
}
TreeMap
基本和TreeSet一样
- TreeMap 和 HashMap 用法基本一样,只不过需要 key 排序的时,就可以使用 TreeMap
- TreeMap 的 key 不能是 null
让 TreeMap 集合的 key 可排序
- 第一种:key 实现了 Compaarable 接口,并且提供了 compareTo 方法,在该方法中添加了比较规则。
- 第二种:创建 TreeMap集合时,传一个 比较器,比较器实现 Comparator 接口,在 compare 方法中添加比较规则
也需要重写 hashcode() 和 equals()
Collection 工具类
提供了一系列静态方法,对集合进行操作
常用方法
- reverse(List):反转 List 中元素的顺序
- shuffle(List):对 List 集合元素进行随机排序
- swap(List, int, int):将指定List 集合中的 i 处元素 和 j 处元素进行交换
- int frequency(Collection, Object):返回指定集合中指定元素的出现次数
- void copy(List dest, List src):将 sec 中内容赋值到 dest 中
- boolean replaceAll(List list, Object oldVal, Object newVal):使用新值替换 List 对象的所有旧值
- Object max/min(Collection):根据元素的自然顺序,返回给定集合中的最大元素,或最小元素(实现Comparable 类的排序)
- Object max/min(Colleciton, Comparator):根据 Comparator 指定的顺序排序,返回最大元素,或最小元素
- sort(List):根据元素自然元素对指定的 List集合元素按升序排序(就是实现Comparable 类的排序)
- sort(List, Comparator):根据指定的 comparator 产生的顺序 对 List 集合元素进行排序)
这里多次谈到比较,所以再总结一次比较
- 自然排序
就是类实现了 Comparable ,并且重写里面的 CompareTo 方法,如果没有自定义排序对象,类中又没有自带的CompareTo 就要自己实现
pubilc class Student implements comparable {
@public int compareTo(Student s) {
...
}
}
- 比较器排序
reeSet treeSet = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
o1 o2 //前者大返回正数
o2 o1 //后者大了所以返回负数所以结果反过来了
@Override
return ((String)o1).compareTo((String)o2);
}
});
两种比较返回值升降序问题
返回正数:大的数放后面 (o1 > o2)
返回负数:小的数放后面 (o1 < o2)
相等:直接放一样的后面 (o1 = o2)















 934
934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









