









前言
上文我们讲述了,线性表的顺序表达(顺序表)的原理以及ADT的实现,我们知道顺序表的存储结构在逻辑关系上以及在物理位置上均是连续的。
一文搞定数据结构之线性表的顺序表达(C语言实现)
但是,在许多实际情况下,由于顺序表需要整块的内存,并且当我们进行增删改操作时,也需要对其他的元素进行位序改变,而当我们存储的元素越多,进行位序改变时,需要移动的元素数量也就会变得的更多。所以,这里我们就要引入链表。当然,链表可以弥补顺序表的不足,但是,同样也会失去顺序表可随机存取、结构简单等优点。
线性链表
结点构成
线性表的链式存储结构的特点是用一组任意的存储单元存储线性表的数据元素。我们储存进去的数据元素的存储映像就被称为结点(node)。而对于一个结点来说,它是包含两个域,一个是数据域;一个是指针域。

数据域: 即是存储数据元素信息的域;
指针域: 是用来存放后继存储位置的域,而其中存放的信息就被称作指针或链。
由于这是线性表的链式表达,所以每个结点中只会包含一个指针域,也可以称为 线性链表或 单链表。这些也为后续编写ADT提供了一个良好模型的描述。

上图是在网络中搜罗的一张单链表结构图,我们可以看到一个结点的数据域和指针域,指针域中存放next指针用以寻址下一结点。在初端,我们还会定义一个头指针,作为链表的起始;末端结点的指针域会被设置为空。这个便是一个链表的基本构造。
注意:第一个结点叫做:头结点;指向头结点的指针叫做头指针。
头结点是一个结点,具有内存,包含指针域与数据域;头指针是一个指针只有声明没有内存
且需注意:单链表可以没有头结点,但是不能没有头指针。
#include<stdio.h>
//这里仍以学生为例
typedef struct{
int ID;
char name;
}elemType;
//定义结点
typedef struct{
//定义数据域:数据域中存放的数据元素类型就是刚刚定义的学生类型
elemtype data;
//定义指针域:需要注意的就是这里存放的指针是下一个结点的指针
//对,是结点的指针😏
struct node *next;
}LNode,* linkList;
理解上面的typedef struct {...}LNode,*linkList,首先,typedef是一种在计算机编程语言中用来声明自定义数据类型,也就是说这一条语句是 就是把 struct Node * 定义成了新类型 LinkList,这个类型是一个结构体指针
而这里这样定义的目的就还是因为在C语言中传递参数的“实参”与“形参”的问题。
链表功能实现
链表的初始化
在进行编写该方法之前,我们先来了解一个函数的用法:malloc()
malloc() 这个函数是用来开辟一方内存空间。例如:malloc(int);就是指开辟一个整型大小的空间(4字节)
//初始化链表
//这里因为要传实参所以将函数定义为linkList类型或者LNode *
linkList initList(){
//先创建一个头结点
LNode *p = malloc(sizeof(LNode));
//先来判断头结点是否存值
if(p == NULL){
//当头结点为空,即整个链表均为空,不需要进行初始化
printf("No more student for init! \n");
}
//而我们要初始化一整个链表,其实就是重置一下头结点
//所以就将头指针的数据域与指针与全部清空
p->data.ID = 0;
p->data.name = "^";
p->next = NULL;
printf("List init OK!\n");
return p;
}
链表的销毁
上面我们新建链表的时候是使用malloc()进行的内存空间的分配,而在对链表进行销毁操作的时候我们就要用到函数:free()。
free()是用来释放动态分配的内存空间,可以释放由malloc()函数开辟出来的空间,其原型为:void free(void *ptr);
//销毁链表
//刚刚介绍了free()函数,因此这里我们要将这个方法设置为void型
void destoryList(linkList L){
//定义一个指针用来指向L的后继元素
LNode *p = L->next;
//遍历所有的链表元素,对于单链表而言,只要后继元素不为空,便继续向后移动
while(p != NULL){
//将L结点空间释放掉
free(L);
//将L结点向后遍历移动,p指向的是L的后继,直接让L也指向后继即可
L = p;
//p指针同样也要向后移动指向当前L所指向结点的后继
p = p->next;
}
//遍历且释放结束后我们还会剩下一个尾结点没有被释放
free(L);
printf("List destroy OK!\n");
}
链表遍历
其实,在刚刚进行链表的销毁操作时,我们就已经实现了链表的遍历,我们将遍历到的每一个链表结点进行空间释放,也就将整个链表给销毁了。直接上代码😉
void listTraversal(linkList L){
//定义一个指针用来指向结点
LNode * p = L;
//对于单链表而言,只要元素不为空,便继续向后移动
while(p != NULL){
printf("data[%d].ID = %d, data[%d].name = %c\n",i,p->data.ID,i,p->data.name);
i++;
p = p->next;
}
printf("List travesal OK!\n");
}
增加结点
下面我们就来对链表进行增加结点操作,我们先来看看这张在网上找的图

对,很详细,Right?😁我们只要把结点的指针域改变指向待插入结点,然后,在把待插入结点的指针域指向下一结点就行了😉
对了,进行插入&删除操作我们都要经行安全检测以及位置检测(上一篇顺序表Blog已经讲解过了相信你还没有忘记😏)
int listInsert(linkList L, int pos, elemType e) {
// 安全性检测
// 1<=pos<=L->data.ID+1
if((pos<1) || (pos>L->data.ID+1)){
printf("Bad position for list insert!\n");
return -1;
}
// 定义一个新的结点指针,并分配空间
LNode *p = NULL;
p = (LNode *)malloc(sizeof(LNode));
// 没有多余的空指针就无处可加了。。。😥
if(p == NULL){
printf("No more mem for list insert!\n");
return -2;
}
// 将原处的结点的数据域拷贝一份
p->data.ID = e.ID;
p->data.name = e.name;
// 将这个temp(拷贝)指针的指针域清空
p->next = NULL;
// 从头定义一个链表指针,并赋予链表的头指针,以便于寻址使用
LNode * q = L;
// 寻址操作
// 由于这个链表的物理存储位置是随机散乱的,就不能像顺序表一样推算地址
// 需要从头遍历
int i = 0;
for(i=0;i<pos-1;i++){
q = q->next;
}
// 寻址完成以后,便找到了插入位置的结点(我们是插入到这个结点的后面)
// 现在我们就要把该节点的后继结点指针赋予给待插入结点
p->next = q->next;
// 在把该位置结点的指针域指向待插入结点,这个结点就算插入了
q->next = p;
// 在把链表的长度加长,OK😇
L->data.ID++;
printf("List insert OK!\n");
return 0;
}
链表的删除
这个操作也就是链表增加的逆向操作了,我再去找找图😅

挺清晰的吧😏,也就是捣鼓一下指针了😎,上代码
int listDelete(linkList L, int pos, elemType *e){
// 安全检测
// 1<= pos <= L->data.ID
if((pos < 1) || (pos > L->data.ID)){
printf("Bad position for list delete!\n");
return -3;
}
// 寻址,寻找到待删除结点的位置结点(删除这个结点的后继结点)
LNode *q = L;
LNode *p = NULL;
int i =0;
for(i=0;i<pos-1;i++){
q = q->next;
}
// 将这个位置结点后继结点(待删结点)赋予给这个中间指针p
p = q->next;
// 再让这个位置结点的指针域指向其后继结点(p待删结点)的后继结点
// 这就个指针的连接绕过了要删除的结点,也就删了😙
q->next = p->next;
// 再把删掉的这个赋给e
e->ID = p->data.ID;
e->name = p->data.name;
// 把删掉的结点空间给释放掉
free(p);
// 链表长度减一
L->data.ID--;
// 把删掉的元素打出来
printf("List delete OK! We deleted %d %c\n",e->ID,e->name);
return 0;
}
其他的函数
为了实现链表的一些需求,我们还需要定义一些函数,这些包括:判断链表是否为空、输出链表长度、取出相应位置的元素数据域、取出链表元素的前驱后继元素等等。这些都很简单,在我们实现前面的一些方法后,这些方法都是十分任意被实现的🤨。
// 判断链表是否为空
int listEmpty(linkList L){
// if(L->data.ID == 0){
// printf("List is empty!\n");
// return 1;
// }
// else{
// printf("List is not empty!\n");
// return 0;
// }
if(L->next == NULL){
printf("List is empty!\n");
return 1;
}
else{
printf("List is not empty!\n");
return 0;
}
}
// 输出链表长度
int listLength(linkList L){
printf("List length is %d!\n",L->data.ID);
return L->data.ID;
}
// 取出相应位置的元素数据域
int listGet(linkList L, int pos,elemType *e){
// Safety test
// 1<= pos <= L->data.ID
if((pos < 1) || (pos > L->data.ID)){
printf("Bad position for list get!\n");
return -5;
}
LNode *q = L;
int i =0;
for(i=0;i<=pos-1;i++){
q = q->next;
}
e->ID = q->data.ID;
e->name = q->data.name;
printf("We get %d %c !\n",e->ID,e->name);
return 0;
}
// 取出链表元素的前驱
int listPrior(linkList L,elemType e,elemType * ePrior){
int pos;
pos = listLocate(L,e);
// Safety test
if(pos == 1){
return -1;
}
else{
listGet(L,pos-1,ePrior);
}
}
//取出链表元素的后继
int listNext(linkList L,elemType e,elemType * eNext){
int pos;
pos = listLocate(L,e);
// Safety test
if(pos == L->data.ID){
return -1;
}
else{
listGet(L,pos+1,ePrior);
}
}
循环链表
上面聊了聊线性链表,即:单链表。这里我们顺带提一提这个循环链表(circular linked list)。
顾名思义,循环链表就是把一个单链表的尾结点的指针域中存下头结点的地址。这样就把这个单链表给连接成了一个闭合的环,并且在有的时候循环链表是不设置头指针而设置尾指针。
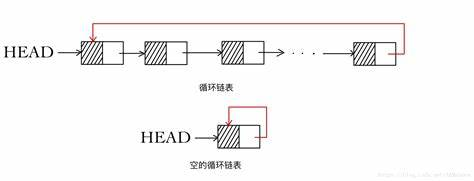
这样就有几个优点:
- 将尾结点的指针域利用起来,以提高查找效率
- 当接入尾指针last时,合并两表时仅需要将一个表的表尾喝另一个表的表头相接
- 循环链表寻找尾结点和头结点的时间复杂度均为O(1),这里我们通过前面的编码实现ADT知道了单链表寻址是需要从头指针开始遍历。
双向链表
双向链表(double linked list)中的结点是具有三个域:前驱指针域、数据域、后继指针域。后继指针域就是存放后继元素的地址,前驱指针域就是用来存放前驱元素的地址。这样以来我们就可以以一个结点为原点前后自如的进行遍历。

于是就打破了单链表的单向传递的局势,注意:单向链表和循环链表寻找前驱元素均不能以O(1)完成,而双向链表却是可以的。
好了这一章也就结束了,下一篇我们就要探讨另一个数据结构——栈(Stack)。😁

















 244
244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











