






模型:
https://huggingface.co/google-bert/bert-base-chinese
BERT-base-chinese模型:

问题:
line1 = '在大众传媒兴起之前,一个人出名的方式通常是缓慢而“自然”的,能够在历史长河中留下印记的往往都是英雄豪杰或风流才俊。在大众传媒出现之后,人类开始利用媒体快速制造声名,围绕名人的生产已经形成了一个庞大的产业链。'
token1 = config.tokenizer.tokenize(line1)
token1: ['在', '大', '众', '传', '媒', '兴', '起', '之', '前', ',', '一', '个', '人', '出', '名', '的', '方', '式', '通', '常', '是', '缓', '慢', '而', '[UNK]', '自', '然', '[UNK]', '的', ',', '能', '够', '在', '历', '史', '长', '河', '中', '留', '下', '印', '记', '的', '往', '往', '都', '是', '英', '雄', '豪', '杰', '或', '风', '流', '才', '俊', '。', '在', '大', '众', '传', '媒', '出', '现', '之', '后', ',', '人', '类', '开', '始', '利', '用', '媒', '体', '快', '速', '制', '造', '声', '名', ',', '围', '绕', '名', '人', '的', '生', '产', '已', '经', '形', '成', '了', '一', '个', '庞', '大', '的', '产', '业', '链', '。']
双引号这个符号,因为词表里面没有,所以tokenize的时候变成[UNK]
解决方案:
打开vocab.txt文件,发现【unused1】这些都是没有使用的,所以可以把他们替换掉:
讲双引号添加进去,变成:
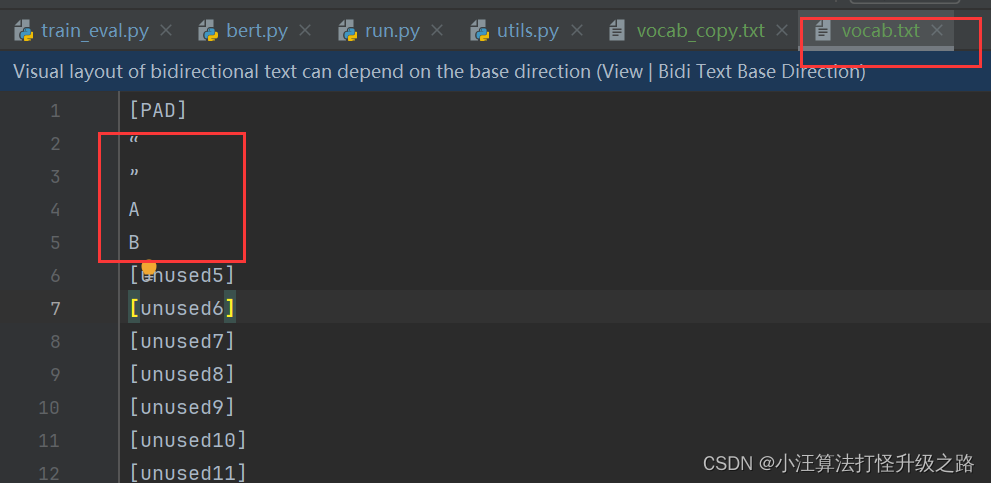
我这里添加了 双引号,A,B字符,
记住后面导入tokenizer的时候,一定要包含这个新vocab.txt的路径:


line1 = '在大众传媒兴起之前,一个人出名的方式通常是缓慢而“自然”的,能够在历史长河中留下印记的往往都是英雄豪杰或风流才俊。在大众传媒出现之后,人类开始利用媒体快速制造声名,围绕名人的生产已经形成了一个庞大的产业链。'
token1 = config.tokenizer.tokenize(line1)
token1
['在', '大', '众', '传', '媒', '兴', '起', '之', '前', ',', '一', '个', '人', '出', '名', '的', '方', '式', '通', '常', '是', '缓', '慢', '而', '“', '自', '然', '”', '的', ',', '能', '够', '在', '历', '史', '长', '河', '中', '留', '下', '印', '记', '的', '往', '往', '都', '是', '英', '雄', '豪', '杰', '或', '风', '流', '才', '俊', '。', '在', '大', '众', '传', '媒', '出', '现', '之', '后', ',', '人', '类', '开', '始', '利', '用', '媒', '体', '快', '速', '制', '造', '声', '名', ',', '围', '绕', '名', '人', '的', '生', '产', '已', '经', '形', '成', '了', '一', '个', '庞', '大', '的', '产', '业', '链', '。']
token_id1 = config.tokenizer.convert_tokens_to_ids(token1)
token_id1
[1762, 1920, 830, 837, 2054, 1069, 6629, 722, 1184, 8024, 671, 702, 782, 1139, 1399, 4638, 3175, 2466, 6858, 2382, 3221, 5353, 2714, 5445, 1, 5632, 4197, 2, 4638, 8024, 5543, 1916, 1762, 1325, 1380, 7270, 3777, 704, 4522, 678, 1313, 6381, 4638, 2518, 2518, 6963, 3221, 5739, 7413, 6498, 3345, 2772, 7599, 3837, 2798, 916, 511, 1762, 1920, 830, 837, 2054, 1139, 4385, 722, 1400, 8024, 782, 5102, 2458, 1993, 1164, 4500, 2054, 860, 2571, 6862, 1169, 6863, 1898, 1399, 8024, 1741, 5312, 1399, 782, 4638, 4495, 772, 2347, 5307, 2501, 2768, 749, 671, 702, 2425, 1920, 4638, 772, 689, 7216, 511]
token_return = config.tokenizer.convert_ids_to_tokens(token_id1)
token_return
['在', '大', '众', '传', '媒', '兴', '起', '之', '前', ',', '一', '个', '人', '出', '名', '的', '方', '式', '通', '常', '是', '缓', '慢', '而', '“', '自', '然', '”', '的', ',', '能', '够', '在', '历', '史', '长', '河', '中', '留', '下', '印', '记', '的', '往', '往', '都', '是', '英', '雄', '豪', '杰', '或', '风', '流', '才', '俊', '。', '在', '大', '众', '传', '媒', '出', '现', '之', '后', ',', '人', '类', '开', '始', '利', '用', '媒', '体', '快', '速', '制', '造', '声', '名', ',', '围', '绕', '名', '人', '的', '生', '产', '已', '经', '形', '成', '了', '一', '个', '庞', '大', '的', '产', '业', '链', '。']
line1 = '在大众传媒兴起之前,一个人出名的方式通常是缓慢而“自然”的,能够在历史长河中留下印记的往往都是英雄豪杰或风流才俊。在大众传媒出现之后,人类开始利用媒体快速制造声名,围绕名人的生产已经形成了一个庞大的产业链。'
token1 = config.tokenizer.tokenize(line1)
token1
['在', '大', '众', '传', '媒', '兴', '起', '之', '前', ',', '一', '个', '人', '出', '名', '的', '方', '式', '通', '常', '是', '缓', '慢', '而', '“', '自', '然', '”', '的', ',', '能', '够', '在', '历', '史', '长', '河', '中', '留', '下', '印', '记', '的', '往', '往', '都', '是', '英', '雄', '豪', '杰', '或', '风', '流', '才', '俊', '。', '在', '大', '众', '传', '媒', '出', '现', '之', '后', ',', '人', '类', '开', '始', '利', '用', '媒', '体', '快', '速', '制', '造', '声', '名', ',', '围', '绕', '名', '人', '的', '生', '产', '已', '经', '形', '成', '了', '一', '个', '庞', '大', '的', '产', '业', '链', '。']
token_id1 = config.tokenizer.convert_tokens_to_ids(token1)
token_id1
[1762, 1920, 830, 837, 2054, 1069, 6629, 722, 1184, 8024, 671, 702, 782, 1139, 1399, 4638, 3175, 2466, 6858, 2382, 3221, 5353, 2714, 5445, 1, 5632, 4197, 2, 4638, 8024, 5543, 1916, 1762, 1325, 1380, 7270, 3777, 704, 4522, 678, 1313, 6381, 4638, 2518, 2518, 6963, 3221, 5739, 7413, 6498, 3345, 2772, 7599, 3837, 2798, 916, 511, 1762, 1920, 830, 837, 2054, 1139, 4385, 722, 1400, 8024, 782, 5102, 2458, 1993, 1164, 4500, 2054, 860, 2571, 6862, 1169, 6863, 1898, 1399, 8024, 1741, 5312, 1399, 782, 4638, 4495, 772, 2347, 5307, 2501, 2768, 749, 671, 702, 2425, 1920, 4638, 772, 689, 7216, 511]
token_return = config.tokenizer.convert_ids_to_tokens(token_id1)
token_return
['在', '大', '众', '传', '媒', '兴', '起', '之', '前', ',', '一', '个', '人', '出', '名', '的', '方', '式', '通', '常', '是', '缓', '慢', '而', '“', '自', '然', '”', '的', ',', '能', '够', '在', '历', '史', '长', '河', '中', '留', '下', '印', '记', '的', '往', '往', '都', '是', '英', '雄', '豪', '杰', '或', '风', '流', '才', '俊', '。', '在', '大', '众', '传', '媒', '出', '现', '之', '后', ',', '人', '类', '开', '始', '利', '用', '媒', '体', '快', '速', '制', '造', '声', '名', ',', '围', '绕', '名', '人', '的', '生', '产', '已', '经', '形', '成', '了', '一', '个', '庞', '大', '的', '产', '业', '链', '。']
现在就没问题啦~~~















 5135
5135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









