







Mysql逻辑架构
大致分为4层架构:连接层,服务层,引擎层,存储层

连接层
mysql提供给外界客户端连接的接口,不同客户端可以用自己的API连接mysql
-
建立连接
-
认证授权
-
维持和管理连接等
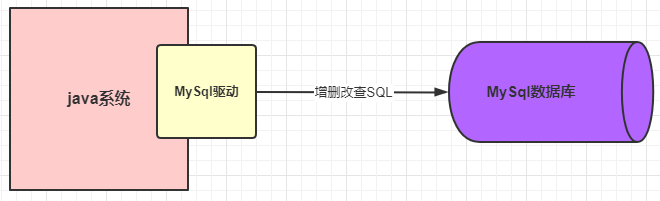
MySQL 驱动
我们的系统是怎么和mysql进行连接和通信的呢?
不可能是平白无故的就能接收和发送请求的吧,此时我们需要了解 MySQL 驱动概念的
就是这个 MySQL 驱动在底层帮我们做了对数据库的连接,只有建立了连接了,才可以发送SQL语句执行CRUD
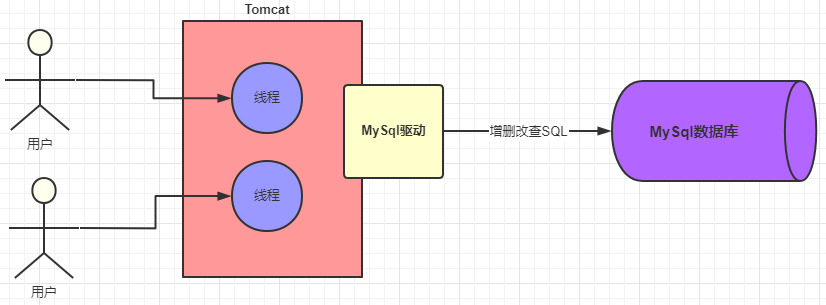
多个连接怎么办?
一次 SQL 请求建立一个连接,多个请求就会建立多个连接
Web系统肯定不是一个人在用,肯定存在多个请求同时去争抢连接的情况!
导致多个请求会去建立数据库连接,然后使用完再都去关闭,这样会有什么问题呢?如下图
java 系统在通过 MySQL 驱动和 MySQL 数据库连接的时候是基于 TCP/IP 协议的
如果每个请求都是新建连接和销毁连接,频繁的创建和销毁连接,造成不必要的浪费和性能下降,非常不合理的。
SO
我们需要被提供一些固定的用来连接的线程,这样是不是不需要反复的创建和销毁连接了呢?
没错,说的就是数据库连接池
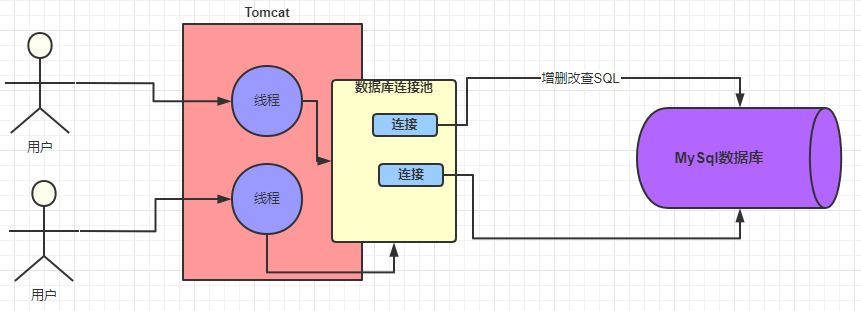
数据库连接池
- 维护一定的连接数,方便系统获取连接,使用就去池子中获取,用完放回去就可以了,
- 我们不需要关心连接的创建与销毁,也不需要关心线程池是怎么去维护这些连接的。
WEB容器中的数据库连接池
- 我们的 web 系统一般是部署在 tomcat 容器中的,而 t**omcat 是可以并发处理多个请求的**
- web客户端通过tomcat配置的**常用的数据库连接池(Druid、C3P0、DBCP)**请求连接到mysql的数据库连接池
这就是有名的「池化」思想,例如线程池,HTPP连接池,都能看到它的身影
常见的数据库连接池有 Druid、C3P0、DBCP,采用连接池
大大节省了不断创建与销毁线程的开销
这就是有名的「池化」思想,例如线程池,HTPP连接池,都能看到它的身影
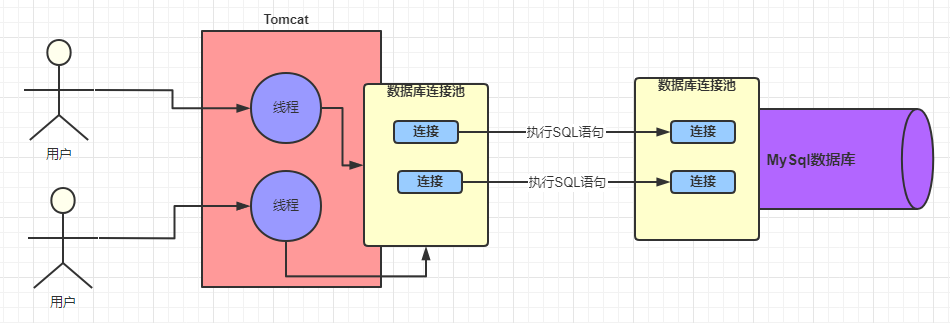
MySQL中的数据库连接池
显然,我们mysql系统也不是每次被请求访问,每次都去建立连接
而是从数据库连接池中去获取,解决反复的创建和销毁连接而带来的性能损耗问题
思考:业务系统是并发的,而 MySQL 接受请求的线程呢,只有一个?
其实 MySQL 的架构体系中也已经提供了这样的一个池子,也是数据库连接池
双方都是通过数据库连接池来管理各个连接的:
Web配置的数据库连接池《=连接=》Mysql数据库连接池
-
一方面不用线程不需要去争抢连接,提高并发性能
-
一方面减少反复创建销毁线程的消耗
至此系统和 MySQL 数据库之间的连接问题已经说明清楚了。那么
MySQL 数据库中的这些连接是怎么来处理的,又是谁来处理呢?
网络连接必须由线程来处理
对计算基础稍微有一点了解的的同学都是知道的,网络中的连接都是由线程来处理的,所谓网络连接说白了就是一次请求,每次请求都会有相应的线程去处理的。
就是说对于 SQL 语句的请求连接成功后,由一个个的线程去获取 SQL 语句去交给 SQL 接口处理
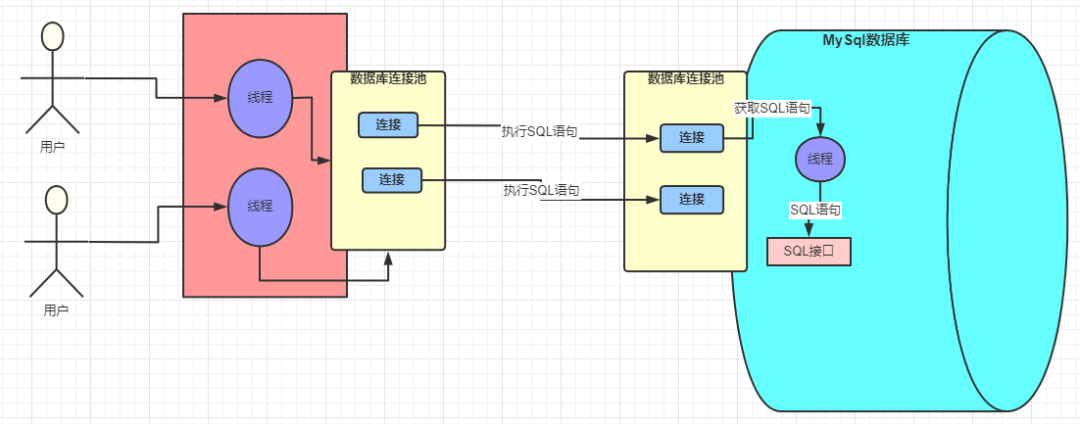
总结
-
web客户端通过tomcat配置的数据库连接池(Druid、C3P0、DBCP)请求连接到mysql的数据库连接池
-
mysql数据库连接池处理连接请求
-
请求成功连接后,由mysql创建的线程去获取sql语句并转交给SQL接口
服务层
总体流程图
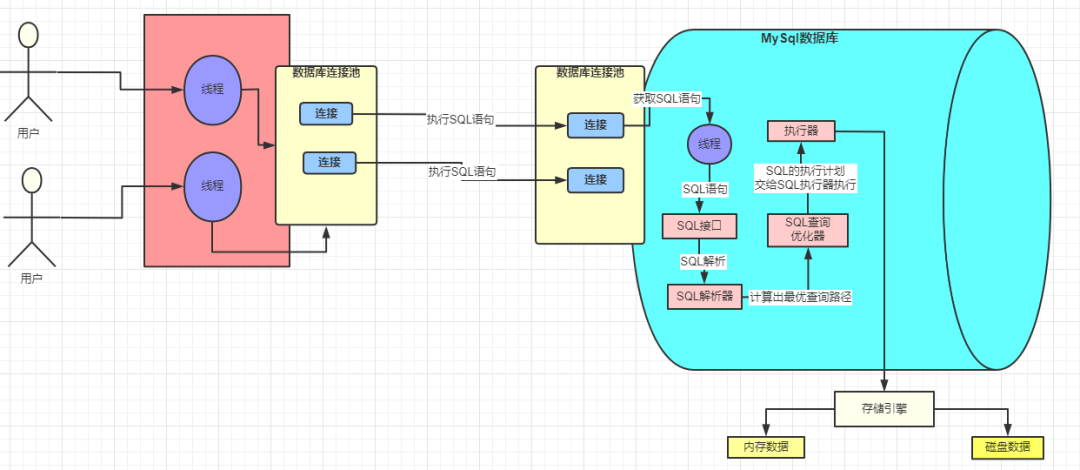
SQL 接口
- 负责用来接收用户的 SQL 命令,并返回sql操作结果
- 数据管理语言和数据定义语言,存储过程,视图,触发器等产生的SQL,并且返回用户需要的查询结果。
- 比如
select from就是调用SQL interface。
查询缓存
简介
查询缓存——它存储SELECT语句以及相应的查询结果集。如果某个查询语句已经位于缓存中,服务器就不会再对查询进行解析、优化、以及执行。这将大大提高系统的性能。
特点
- 如果查询缓存有命中的查询结果,直接去缓存中取数据
- 只要有对一个表的更新,这个表上所有的查询缓存都会被清空
- MySQL 8.0版本直接将查询缓存的整块功能删掉了
如果是查询语句先检查查询缓存,判断缓存里存有一模一样的sql语句?有就是命中,直接返回相应的结果集,没有继续走解析器
解析器(Parser)
SQL是以字符串的形式传过来的,我们要将sql语句解析成mysql自己能认识的语言
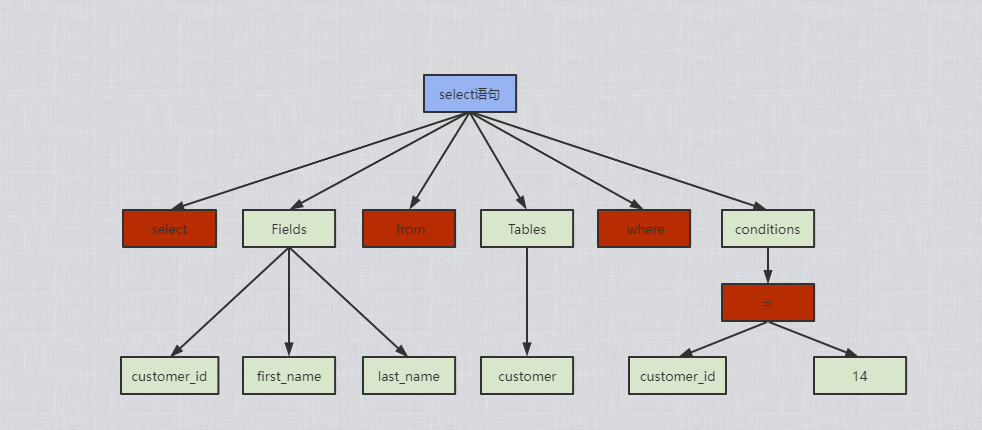
流程图

解析过程主要包含以下五个阶段:
- 词法分析:
- 将整个语句拆分成一个个字段
- 语法分析:
- 将词法分析拆分出的字段,按照MySQL定义的语法规则,生成对应的数据结构解析树
- 解析树:
- 预处理器:
- 去进一步的检查解析树是否合法,比如就是去查看表是否存在,列是否存在。
- 新解析树:
- 通过预处理器核对之后生成的新的解析树,新解析树可能和旧解析树结构一致。
查询优化器
mysql根据自己的优化规则,将查询的IO成本和CPU成本消耗降到最低,
- 在表里面有多个索引的时候,决定使用哪个索引
- 在一个语句有多表关联(join) 的时候,决定各个表的连接顺序
- 例如调换where条件位置,使索引满足最佳左前缀法则
优化器执行选出最优索引等步骤后,会去交给执行器调用存储引擎接口,开始去执行被 MySQL 解析过和优化过的 SQL 语句
解释
IO 成本: 即从磁盘把数据加载到内存的成本,MySQL 是以页的形式读取数据的,即当用到某个数据时,并不会只读取这个数据,而会把这个数据相邻的数据也一起读到内存中,这就是有名的程序局部性原理
CPU 成本:数据在内存中查找和排序等 CPU 操作的成本
IO操作复习
-
数据库的数据文件或者索引文件是以文件形式存在磁盘上的
-
系统从磁盘读取数据到内存时是以磁盘块(block)为基本单位,
-
innodb将数据读到内存时是以页为基本单位(默认为16KB),
-
又因为一个磁盘块往往没那么大,所以innodb读磁盘数据时会将总共16KB的连续若干磁盘块读入内存
执行器
- 所有的操作最终必须通过执行器,会根据表定义的存储引擎定去调用存储引擎对应的接口
- 执行语句,开始执行的时候,要先判断一下你对这个表T有没有执行查询的权限,没有就返回没有权限的错误,有就继续执行,执行器就会根据表的引擎定义,去使用这个引擎提供的接口。
总结:
-
客户端发生请求给mysql数据库连接池后,mysql数据库连接池处理请求、完成身份权限验证
-
创建线程获取请求中的sql语句,将语句交给sql接口
-
如果是查询语句先从查询缓存中查找是否有命中,有就直接返回结果集,没有就走解析器
-
解析器将sql语句按规则解析成各个字段,并生成对应的数据结构解析树,然后交给查询优化器,找到最优查找路径,例如选择哪个索引成本最低
-
最后交给执行器去调用存储引擎(默认是innodb)对应的结构
存储引擎层
存储引擎层:负责了MySQL中数据的存储和提取,服务器通过API与存储引擎进行通信。不同的存储引擎具有的功能不同,可以根据实际需求选取
- 其架构模式是插件式的,支持InnoDB、MyISAM、 Memory等多个存储引擎。
- 现在最常用的存储引擎是InnoDB,它从MySQL 5.5.5版本开始成为了 默认存储引擎。如果建表的时候,不指定引擎类型,默认使用InnoDB
种类
-
InnoDB存储引擎
InnoDB是MySQL的默认事务型引擎,它被设计用来处理大量的短期(short-lived)事务。除非有非常特别的原因需要使用其他的存储引擎,否则应该优先考虑InnoDB引擎。行级锁,适合高并发情况 -
MyISAM存储引擎
MyISAM提供了大量的特性,包括全文索引、压缩、空间函数(GIS)等,但MyISAM不支持事务和行级锁(myisam改表时会将整个表全锁住),有一个毫无疑问的缺陷就是崩溃后无法安全恢复。 -
Archive引擎
Archive存储引擎只支持INSERT和SELECT操作,在MySQL5.1之前不支持索引。
Archive表适合日志和数据采集类应用。适合低访问量大数据等情况。
根据英文的测试结论来看,Archive表比MyISAM表要小大约75%,比支持事务处理的InnoDB表小大约83%。 -
Blackhole引擎
Blackhole引擎没有实现任何存储机制,它会丢弃所有插入的数据,不做任何保存。但服务器会记录Blackhole表的日志,所以可以用于复制数据到备库,或者简单地记录到日志。但这种应用方式会碰到很多问题,因此并不推荐。 -
CSV引擎
CSV引擎可以将普通的CSV文件作为MySQL的表来处理,但不支持索引。
CSV引擎可以作为一种数据交换的机制,非常有用。
CSV存储的数据直接可以在操作系统里,用文本编辑器,或者excel读取。 -
Memory引擎
如果需要快速地访问数据,并且这些数据不会被修改,重启以后丢失也没有关系,那么使用Memory表是非常有用。Memory表至少比MyISAM表要快一个数量级。(使用专业的内存数据库更快,如redis) -
Federated引擎
Federated引擎是访问其他MySQL服务器的一个代理,尽管该引擎看起来提供了一种很好的跨服务器的灵活性,但也经常带来问题,因此默认是禁用的。
存储层
存储层:数据存储层,主要是将数据存储在运行于裸设备的文件系统之上,并完成与存储引擎的交互。














 1455
1455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









