









以太坊源码阅读2——RLP编码
RLP介绍
目前网上的资料都是RLP(Recursive Length prefix),叫递归长度前缀编码,但目前源码的doc.go的第20行里面的注释写的是
The purpose of RLP (Recursive Linear Prefix) is to encode arbitrarily nested arrays of
binary data
即:RLP(递归线性前缀)的目的是对任意嵌套的二进制数据数组进行编码
先按照RLP(Recursive Length prefix),递归长度前缀来看吧,感觉更加符合其算法定义。
RLP是以太坊中用于序列化对象的主要编码方法。RLP的唯一目的是对结构进行编码
优点
- 实现简单,数据密度高(主要是和json等序列化方式比较)
- 便于编码结构
RLP编码原理
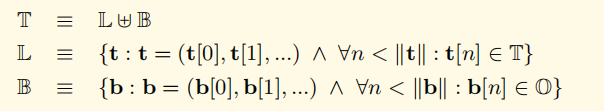
定义一个集合T,T由L和B两部分组成:
-
B代表了所有可能的字节数组,
-
L代表了不只一个单一节点的树形结构(比如结构体,或者是树节点的分支节点, 非叶子节点)
以太坊使用RLP函数来对以上两种类型(L和B)进行编码:
RLP给字符数组和列表两种类型的数据进行编码
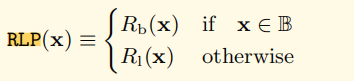
字符数组
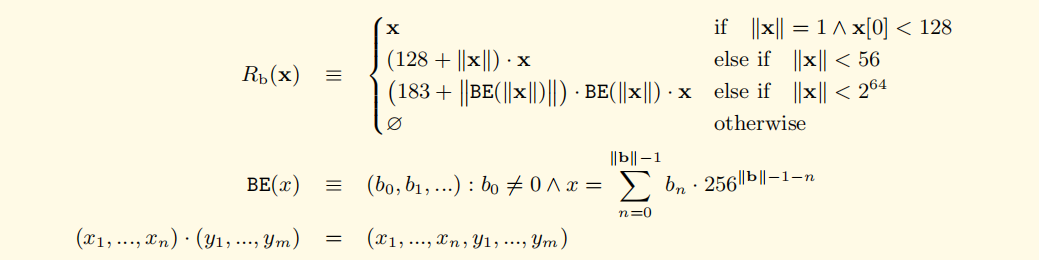
注:
-
这里的 “.” 相当于字符的分割,"+"是正常的加法运算,比如 (128+2).56 ==> 数组 [130 , 56]
-
||x|| ==> len(x)
-
BE(x) ==> 将x去除前导0。BE(x)函数来把x转换成最简大端模式(去掉了开头的00),然后把BE(x)的结果当成是字节数组来进行编码
以上的公式可以简单地转换为以下三个规则:
**规则1:**对于值在[0, 127]之间的单个字节,其编码是其本身。
例:a 的编码是 97 。
规则2: 如果byte数组长度l <= 55,编码的结果是数组本身,再加上128+l作为前缀。
例:abc 编码结果是131 97 98 99,其中131=128+len(“abc”),97 98 99依次是a b c
规则3: 如果数组长度大于55, 编码结果第一个是183加上字符串长度所占用的字节数,然后是数组长度的本身的编码,最后是byte数组的编码。
编码下面这段字符串:
The length of this sentence is more than 55 bytes, I know it because I pre-designed it
这段字符串共86个字节,而86的编码只需要一个字节,那就是它自己,因此,编码的结果如下:
184 86 84 104 101 32 108 101 110 103 116 104 32 111 102 32 116 104 105 115 32 115 101 110 116 101 110 99 101 32 105 115 32 109 111 114 101 32 116 104 97 110 32 53 53 32 98 121 116 101 115 44 32 73 32 107 110 111 119 32 105 116 32 98 101 99 97 117 115 101 32 73 32 112 114 101 45 100 101 115 105 103 110 101 100 32 105
其中前三个字节的计算方式如下:
184 = 183 + 1,因为数组长度86编码后仅占用一个字节。
86即数组长度86
84是T的编码
列表
这里黄皮书说是树形结构,但实际理解为列表(List)为多
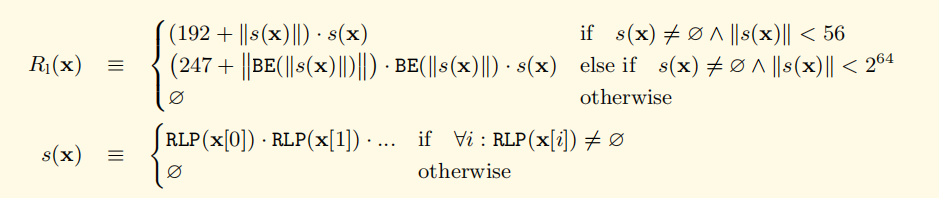
规则4:如果列表长度小于55,编码结果第一位是192加列表长度的编码的长度,然后依次连接各子列表的编码。
例6:[“abc”, “def”]的编码结果是 200 131 97 98 99 131 100 101 102。
其中 abc 的编码为 131 97 98 99 , def 的编码为131 100 101 102。其中 131=RLP(“abc”)=128 + len(“abc”)= 128+3 = 131 , 两个子字符串的编码后总长度是8,因此编码结果第一位计算得出:192 + 8 = 200。
规则5:如果列表长度超过55,编码结果第一位是247加列表长度的编码长度所占用的字节数,然后是列表长度本身的编码,最后依次连接各子列表的编码。
["The length of this sentence is more than 55 bytes, ", "I know it because I pre-designed it"]
编码结果:
248 88 179 84 104 101 32 108 101 110 103 116 104 32 111 102 32 116 104 105 115 32 115 101 110 116 101 110 99 101 32 105 115 32 109 111 114 101 32 116 104 97 110 32 53 53 32 98 121 116 101 115 44 32 163 73 32 107 110 111 119 32 105 116 32 98 101 99 97 117 115 101 32 73 32 112 114 101 45 100 101 115 105 103 110 101 100 32 105 116
其中前两个字节的计算方式如下:
列表长度 88 = 86 + 2,在规则3的示例中,长度为86,而在此例中,由于有两个子字符串,每个子字符串本身的长度的编码各占1字节,因此总共占2字节。
列表长度的编码长度为 1
第1个字节为248 = 247 +1
第2个字节为 88
第3个字节179依据规则2得出179 = 128 + 51
第55个字节163同样依据规则2得出163 = 128 + 35
RLP编码-原代码
以RLP中的Encode方法为例:
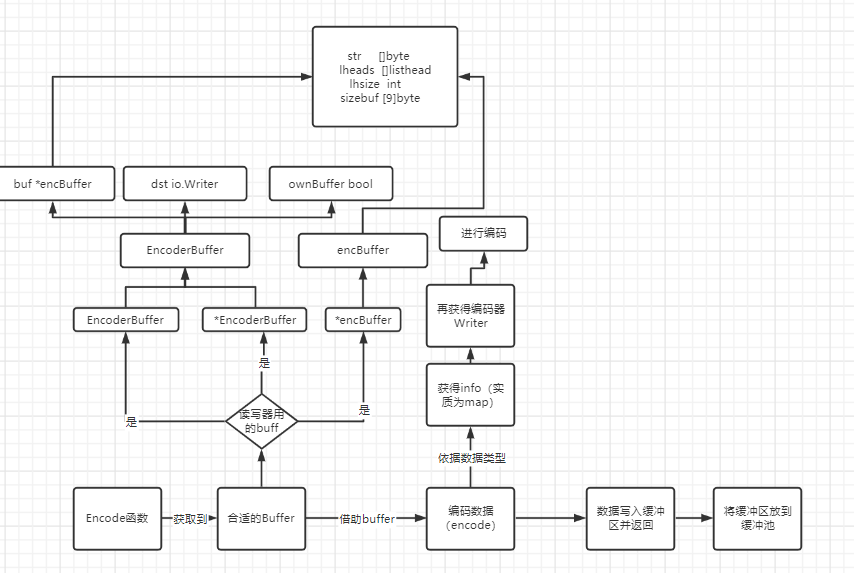
这个方法先使用encBufferFromWriter函数获取了encBuffer对象, 然后调用这个对象的encode方法。
func Encode(w io.Writer, val interface{}) error {
// Optimization: reuse *encBuffer when called by EncodeRLP.
if buf := encBufferFromWriter(w); buf != nil {
return buf.encode(val)
}
buf := getEncBuffer()
defer encBufferPool.Put(buf) //defer延迟执行,使得在write或报错完成后将buff缓冲放入到buff缓冲池
if err := buf.encode(val); err != nil {
return err
}
return buf.writeTo(w)
}
encBufferFromWriter函数会根据传入的Writer选择合适的缓冲区(buffer)
func encBufferFromWriter(w io.Writer) *encBuffer {
switch w := w.(type) {
case EncoderBuffer:
return w.buf
case *EncoderBuffer:
return w.buf
case *encBuffer:
return w
default:
return nil
}
}
encode方法中,首先获取了对象的反射类型,根据反射类型获取它的编码器(Writer),然后调用编码器的writer方法进行编码。
func (buf *encBuffer) encode(val interface{}) error {
rval := reflect.ValueOf(val)
writer, err := cachedWriter(rval.Type())
if err != nil {
return err
}
return writer(rval, buf)
}
在write的时候就是按照上面编码原理部分来的即可
len(x)===1 ,编码后还是自己
func (buf *encBuffer) writeBytes(b []byte) {
if len(b) == 1 && b[0] <= 0x7F {
// fits single byte, no string header
buf.str = append(buf.str, b[0])
} else {
buf.encodeStringHeader(len(b))
buf.str = append(buf.str, b...)
}
}
len(x)< 56 ,编码后为128(十六进制0x80 = 十进制128 )+len(x) 和其他字符
func (buf *encBuffer) encodeStringHeader(size int) {
if size < 56 {
buf.str = append(buf.str, 0x80+byte(size))
} else {
sizesize := putint(buf.sizebuf[1:], uint64(size))
buf.sizebuf[0] = 0xB7 + byte(sizesize)
buf.str = append(buf.str, buf.sizebuf[:sizesize+1]...)
}
}
回到Encode函数,最后如果借助writeTo返回的话,会将buffer内的数据写入到解码器Writer中
func (buf *encBuffer) writeTo(w io.Writer) (err error) {
strpos := 0
for _, head := range buf.lheads {
// write string data before header
if head.offset-strpos > 0 {
n, err := w.Write(buf.str[strpos:head.offset])
strpos += n
if err != nil {
return err
}
}
// write the header
enc := head.encode(buf.sizebuf[:])
if _, err = w.Write(enc); err != nil {
return err
}
}
if strpos < len(buf.str) {
// write string data after the last list header
_, err = w.Write(buf.str[strpos:])
}
return err
}
RLP解码原理
解码时,首先根据编码结果第一个字节f的大小,执行以下的规则判断:
如果f∈ [0,128), 那么它是一个字节本身。
如果f∈[128,184),那么它是一个长度不超过55的byte数组,数组的长度为 l=f-128
如果f∈[184,192),那么它是一个长度超过55的数组,长度本身的编码长度ll=f-183,然后从第二个字节开始读取长度为ll的bytes,按照BigEndian编码成整数l,l即为数组的长度。
如果f∈(192,247],那么它是一个编码后总长度不超过55的列表,列表长度为l=f-192。递归使用规则1~4进行解码。
如果f∈(247,256],那么它是编码后长度大于55的列表,其长度本身的编码长度ll=f-247,然后从第二个字节读取长度为ll的bytes,按BigEndian编码成整数l,l即为子列表长度。然后递归根据解码规则进行解码。
RLP解码代码
其实和编码那边差不多,就不过多解释了,后面 “typecache.go” 部分也有涉及
func (s *Stream) Decode(val interface{}) error {
if val == nil {
return errDecodeIntoNil
}
rval := reflect.ValueOf(val)
rtyp := rval.Type()
if rtyp.Kind() != reflect.Ptr {
return errNoPointer
}
if rval.IsNil() {
return errDecodeIntoNil
}
decoder, err := cachedDecoder(rtyp.Elem())
if err != nil {
return err
}
err = decoder(s, rval.Elem())
if decErr, ok := err.(*decodeError); ok && len(decErr.ctx) > 0 {
// Add decode target type to error so context has more meaning.
decErr.ctx = append(decErr.ctx, fmt.Sprint("(", rtyp.Elem(), ")"))
}
return err
}
typecache.go
基本介绍
**typeCache:**关键结构,由于GO语言本身不支持重载, 也没有泛型,所以要自己实现函数派发
next map[typekey]*typeinfo 借助typekey(主要是用switch case来实现)来寻找合适的编码器函数和解码器函数
type typeCache struct {
cur atomic.Value //保证原子性
mu sync.Mutex //读写锁,用来在多线程的时候保护cur
next map[typekey]*typeinfo
}
**newTypeCache:**创建TypeCache用于派发编码器和解码器
var theTC = newTypeCache()
func newTypeCache() *typeCache {
c := new(typeCache)
c.cur.Store(make(map[typekey]*typeinfo))
return c
}
**typeinfo :**记录编码器和解码器,以及对应的error
// typeinfo is an entry in the type cache.
type typeinfo struct {
decoder decoder
decoderErr error // error from makeDecoder
writer writer
writerErr error // error from makeWriter
}
具体获得编解码器:
对外暴露的方法,依据类型(Type)生成编码器或者解码器,它们都调用了info这个方法
func cachedDecoder(typ reflect.Type) (decoder, error) {
info := theTC.info(typ)
return info.decoder, info.decoderErr
}
func cachedWriter(typ reflect.Type) (writer, error) {
info := theTC.info(typ)
return info.writer, info.writerErr
}
在info这个方法中,尝试去缓存中寻找这个类型(type)是否已经生成过,没有就创建一个新的(即调用generate方法)
func (c *typeCache) info(typ reflect.Type) *typeinfo {
key := typekey{Type: typ}
//Load返回最近的Store设置的值。如果没有对该值的Store调用,则返回nil。
//这里是去map中寻找这个key是否已经存在
if info := c.cur.Load().(map[typekey]*typeinfo)[key]; info != nil {
return info
}
// 不在缓存(map)中,需要生成此类型的信息
return c.generate(typ, rlpstruct.Tags{})
}
generate方法主要是进行上锁
func (c *typeCache) generate(typ reflect.Type, tags rlpstruct.Tags) *typeinfo {
c.mu.Lock() //加读锁来保护,
defer c.mu.Unlock() //最后再解锁
cur := c.cur.Load().(map[typekey]*typeinfo) //获取map中的value
if info := cur[typekey{typ, tags}]; info != nil {
return info
}
// 将调用者的next指针指向新创建出来的map
c.next = make(map[typekey]*typeinfo, len(cur)+1)
for k, v := range cur {
c.next[k] = v
}
// Generate.
info := c.infoWhileGenerating(typ, tags)
// next -> cur
c.cur.Store(c.next)
c.next = nil
return info
}
将调用者的next指向新创建的info
func (c *typeCache) infoWhileGenerating(typ reflect.Type, tags rlpstruct.Tags) *typeinfo {
key := typekey{typ, tags}
if info := c.next[key]; info != nil {
return info
}
// 在生成之前,将一个虚拟值放入缓存。
// 如果生成器尝试查找自身,它将得到这个虚拟值
// 这个虚拟值不会递归地调用自己。
info := new(typeinfo)
c.next[key] = info
info.generate(typ, tags)
return info
}
真正依据类型来生成编解码器,并赋给上个方法中的info,之后编码器为例
func (i *typeinfo) generate(typ reflect.Type, tags rlpstruct.Tags) {
i.decoder, i.decoderErr = makeDecoder(typ, tags)
i.writer, i.writerErr = makeWriter(typ, tags)
}
依据类型(type)分发请求,创建解码器,之后以writeBytes为例
func makeDecoder(typ reflect.Type, tags rlpstruct.Tags) (dec decoder, err error) {
kind := typ.Kind()
switch {
case typ == rawValueType:
return decodeRawValue, nil
case typ.AssignableTo(reflect.PtrTo(bigInt)):
return decodeBigInt, nil
case typ.AssignableTo(bigInt):
return decodeBigIntNoPtr, nil
case kind == reflect.Ptr:
return makePtrDecoder(typ, tags)
case reflect.PtrTo(typ).Implements(decoderInterface):
return decodeDecoder, nil
case isUint(kind):
return decodeUint, nil
case kind == reflect.Bool:
return decodeBool, nil
case kind == reflect.String:
return decodeString, nil
case kind == reflect.Slice || kind == reflect.Array:
return makeListDecoder(typ, tags)
case kind == reflect.Struct:
return makeStructDecoder(typ)
case kind == reflect.Interface:
return decodeInterface, nil
default:
return nil, fmt.Errorf("rlp: type %v is not RLP-serializable", typ)
}
}
接着向下调用writeBytes
func writeBytes(val reflect.Value, w *encBuffer) error {
w.writeBytes(val.Bytes())
return nil
}
依据黄皮书的示例,len(b) == 1 && b[0] <= 0x7F,编码后为自己
func (buf *encBuffer) writeBytes(b []byte) {
if len(b) == 1 && b[0] <= 0x7F {
// fits single byte, no string header
buf.str = append(buf.str, b[0])
} else {
buf.encodeStringHeader(len(b))
//之后便是小于56和2^64的部分了
buf.str = append(buf.str, b...)
}
}
创建小于56和2^64部分的编码头
func (buf *encBuffer) encodeStringHeader(size int) {
if size < 56 {
buf.str = append(buf.str, 0x80+byte(size))//这里出事的buf.str内容为空
} else {
sizesize := putint(buf.sizebuf[1:], uint64(size))
buf.sizebuf[0] = 0xB7 + byte(sizesize)
buf.str = append(buf.str, buf.sizebuf[:sizesize+1]...)
}
}














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









