






Hadoop生态系统
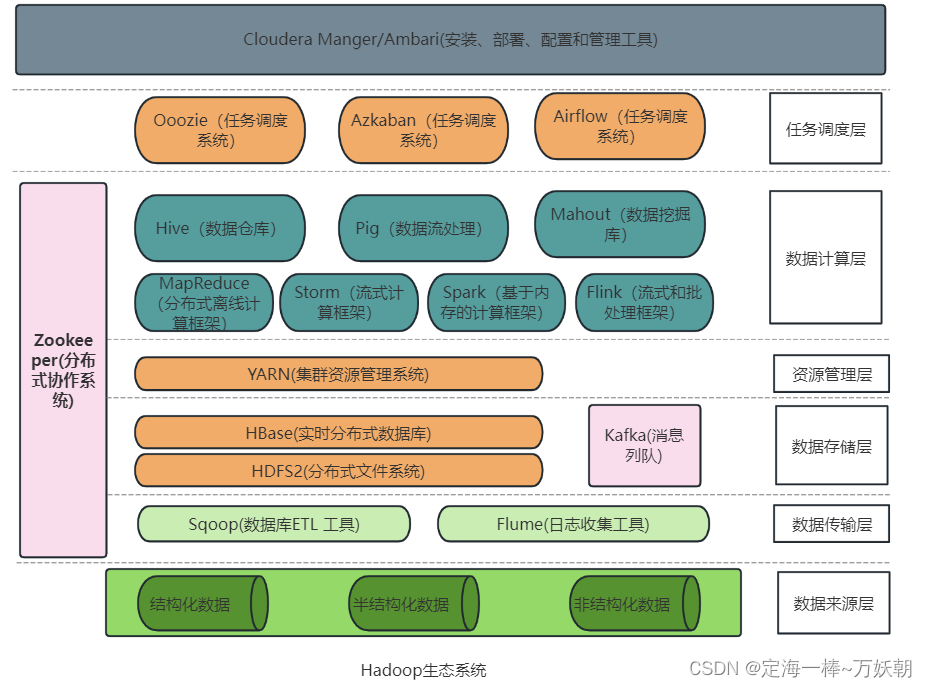
部分组件的简单介绍
Hue:
一个可以和Hadoop生态交互的应用程序。可视化界面使得我们对和Hadoop相关的软件的操作变得简化。
HDFS:
实质上就是一个存储系统,可以存储海量的文件,且存储的是大文件不是小文件;具有容错机制(存储的文件在节点上存储了副本,心跳机制),可以为其他组件提供支持;
它的存储对硬件的要求不高,使用低廉的硬件就可以实现动态扩容;高吞吐,可以并发执行读写操作。
Hive:
是一个数仓工具,用来进行数据的提取,转化,加载(ETL),将结构化的数据进行(ETL)后映射成hive表;
对于这些hive表我们可以使用类SQL的hiveSQL语言进行增删改查的操作(本质上是将SQl语言转变成MapReduce任务来执行);
学习难度低,使用类SQL语句快速实现MapReduce统计,不必开发专门的MapReduce程序。
Yarn:
进行Hadoop作业的资源调度,包含的主要组件:资源管理器(ResourceManage),节点管理器(NodeManage)(对每台计算机节点的资源进行调度),应用程序管理器(ApplicationMaster),容器(Container),调度器(scheduler)。
Oozie:
进行Hadoop作业的任务调度,包含的主要组件:工作流(WorkFlow),协调器(Coordinator)(可以将多个工作流协调成一个工作流),捆、束(Bundle)(将一堆的协调器汇总处理)。
Sqoop:
数据传输层的重要工具,用于hdfs/hive与RDBMS之间,RDBMS到HBase的数据传输;
创建工作流使用sqoop脚本,sqoop中的任务翻译器会将脚本中的命令转换成MapReduce任务,然后减肥数据进行转换。
DataX:
实现异构数据源之间的高效数据同步,利用读插件(Reader)对来源数据进行读取,使用写插件(Writer)把数据写入目标数据源,使用数据传输通道(Framework)来连接读写插件,并处理缓冲,流控,并发,数据转换等技术问题。
Spark:
Spark是一个分布式数据处理引擎,Spark可以将Hadoop集群中的应用在内存中的运行速度提升100倍,甚至能够将应用在磁盘上的运行速度提升10倍。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaing)、机器学习(Spark MLlib)、图计算(GraphX)。
Flink:
Flink 是目前唯一能同时集高吞吐、低延迟、高性能三者于一身的分布式流式数据处理框架。Apache Spark 只有高吞吐、高性能。Apache Storm 只有低延迟、高性能,但达不到高吞吐。
HBase:
一种分布式、可扩展、支持海量数据存储的Nosql数据库。
主要特点:
面向列
多版本
稀疏性:空列不占存储空间
高可靠:底层是HDFS有备份
高性能:主键索引和缓存机制,查询可达毫秒级
















 3769
3769











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









