







目录
一、线性回归问题

import sklearn.linear_model as lm
# 创建模型
model=lm.LinearRegression()
# 训练模型
# 输入为一个二维数组表示的样本矩阵
# 输出为每个样本最终的结果
model.fit(输入,输出) # 通过梯度下降法计算模型参数
# 预测输出
# 输出array是一个二维数组,每一行是一个样本,每一列是一个特征。
result=model.predict(array)二、评估训练结果误差
线性回归模型训练完毕后,可以利用测试集评估训练结果误差。sklearn.metrics提供了计算模型误差的几个常用算法:
from sklearn.metrics import mean_absolute_error,mean_squared_error,median_absolute_error,r2_score
# 平均绝对值误差: 1/mE|实际输出-预测输出|
mean_absolute_error(y,y_pred)
# 平均平方误差: SQRT(1/mE(实际输出-预测输出)^2)
mean_squared_error(y,y_pred)
# 中位绝对值误差:MEDIAN(|实际输出-预测输出|)
median_absolute_error(y,y_pred)
# R2得分,(0,1]区间的分值。分值越高,误差越小
r2_score(y,y_pred)三、模型的保存于加载
模型训练是一个耗时的过程,一个优秀的机器学习是非常宝贵的。可以将模型保存到磁盘中,也可以在需要使用的时候从磁盘中重新加载模型。不需要重新训练。
模型保存和加载相关的api:
import pickle
pickle.dumps(内存对象,磁盘文件) # 保存模型
model=pickle.load(磁盘文件) # 加载模型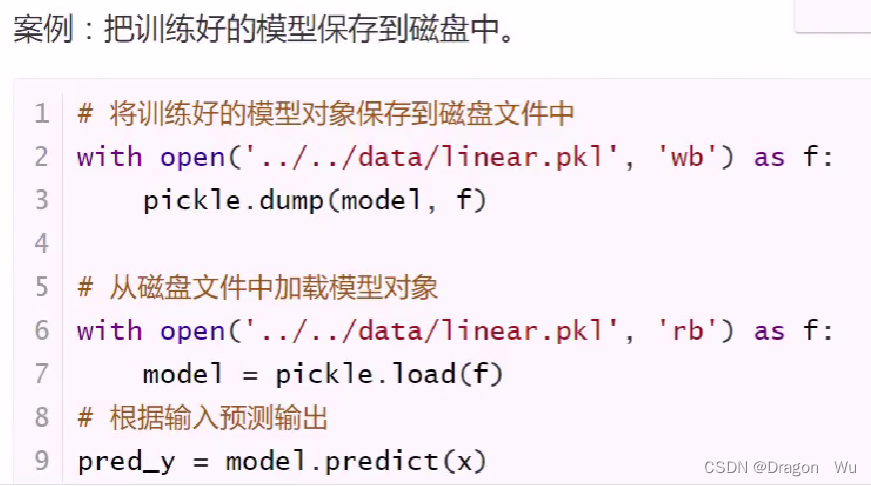
总结到此。















 2691
2691











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









