







参考资料:算法设计与分析_北航_中国大学MOOC
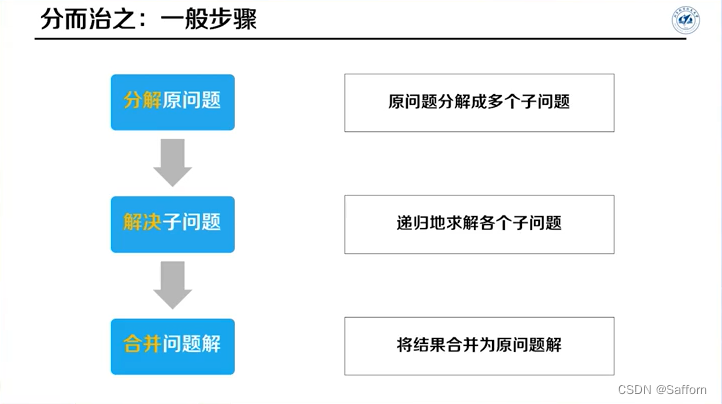
分治算法
概要
最大子数组问题1



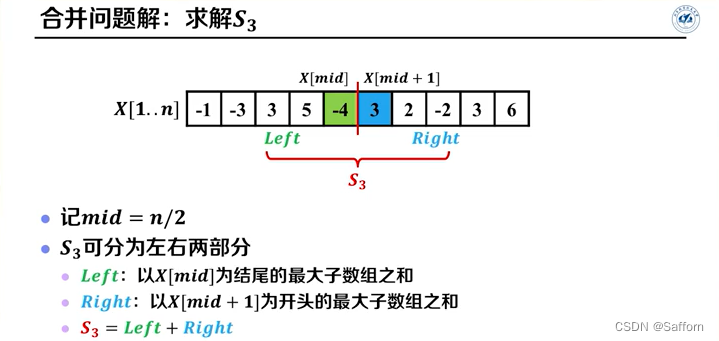
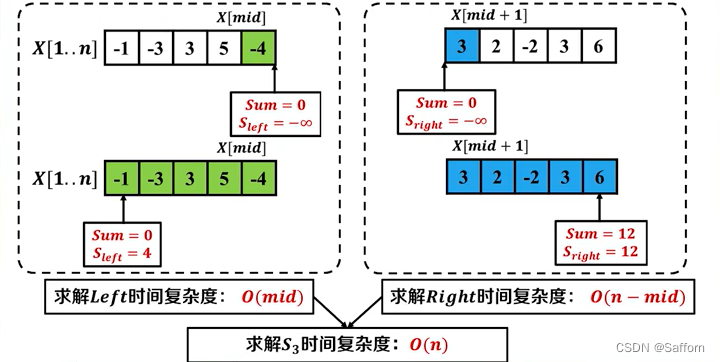

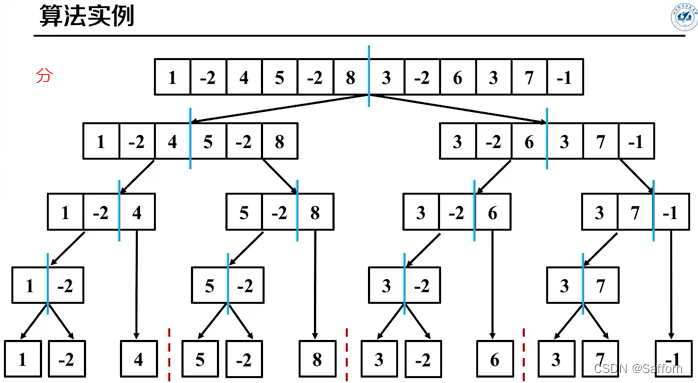
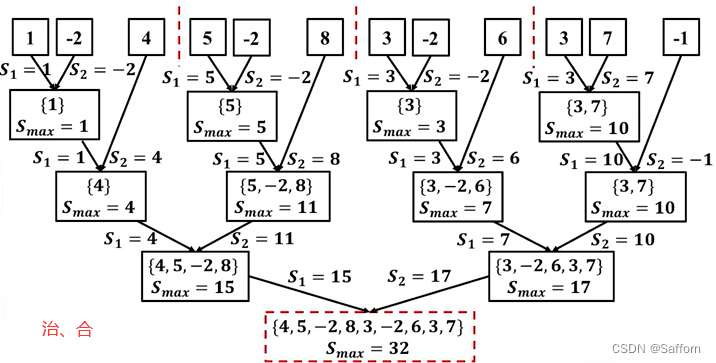
伪代码:
MaxSubArray(X, low, high)
输入:数组X, 数组下标 low, high
输出:最大子数组S_max
if low = high then //递归终止条件
return X[low]
end
else
mid <- ⌊(low+high)/2⌋ //拆分原问题
S1 <- MaxSubArray(X, low, mid) //求解子问题, T(n/2)
S2 <- MaxSubArray(X, mid+1, high)
S3 <- CrossingSubArray(X, low, mid, high) //合并问题解, O(n)
S_max <- max{S1, S2, S3} //合并问题解
return S_max
end
时间复杂度:
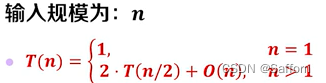
由递归树方法得,递归树深度
l
o
g
n
logn
logn,每层代价为
n
n
n,整体时间复杂度为
T
(
n
)
=
n
l
o
g
n
T(n)=nlogn
T(n)=nlogn
动态规划(DP)
概要

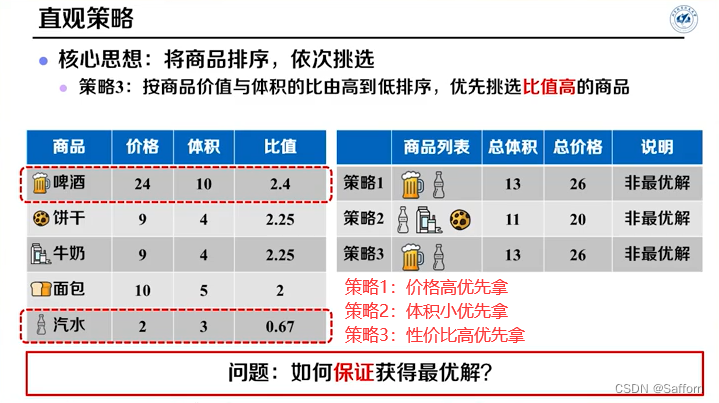
0-1背包问题
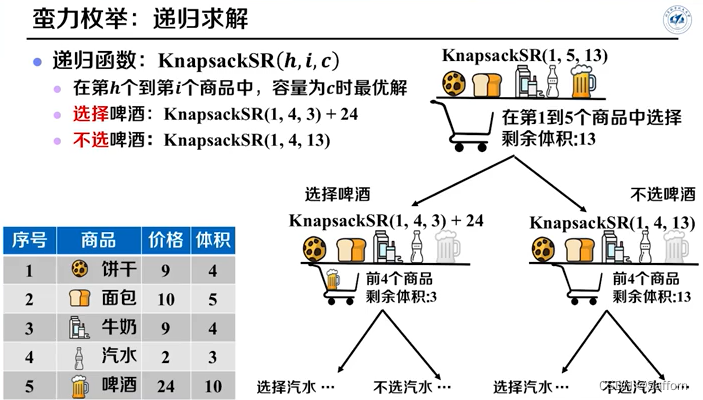
1. 蛮力枚举法:
递归式关系:
K
n
a
p
s
a
c
k
S
R
(
h
,
i
,
c
)
=
m
a
x
{
K
n
a
p
s
a
c
k
S
R
(
h
,
i
−
1
,
c
−
v
i
)
+
p
i
,
K
n
a
p
s
a
c
k
S
R
(
h
,
i
−
1
,
c
)
}
KnapsackSR(h, i, c) = max\{ KnapsackSR(h, i-1, c-v_i)+p_i, KnapsackSR(h, i-1, c)\}
KnapsackSR(h,i,c)=max{KnapsackSR(h,i−1,c−vi)+pi,KnapsackSR(h,i−1,c)}
伪代码:
KnapsackSR(h, i, c) //从第h个到第i个商品中, 容量为c时最优解
输入:商品集合{h, ..., i}, 背包容量c
输出:最大总价格 P
if c < 0 then //超出背包容量
return -∞
end
if i <= h-1 then //所有商品已决策完成
return 0
end
P1 <- KnapsackSR(h, i-1, c-v_i) //选择商品i
P2 <- KnapsackSR(h, i-1, c) //不选择商品i
P <- max{P1 + p_i, P2} //确定最优解
return P
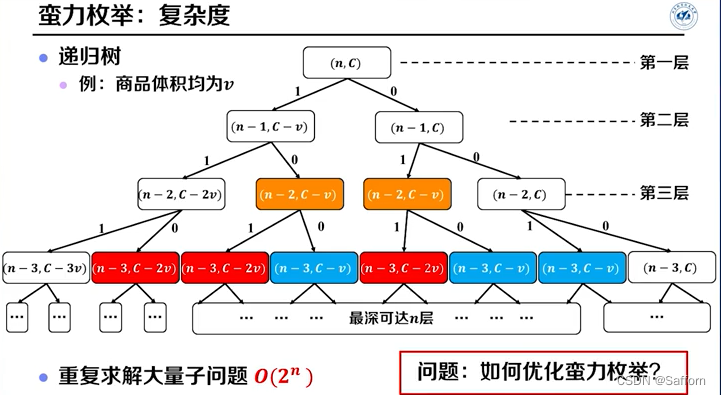
2. 带备忘的递归
为了减少 蛮力枚举 的 重复计算 问题,建立备忘录
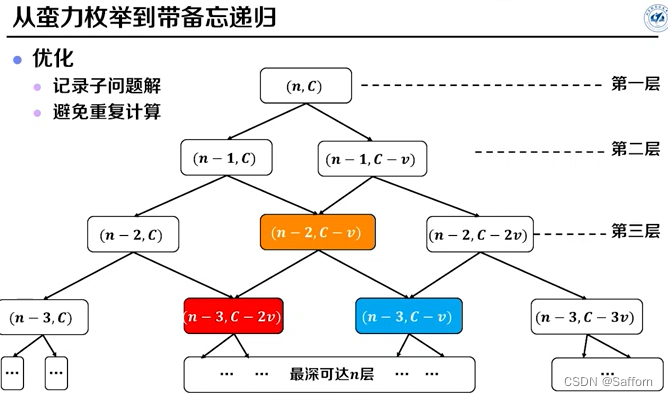
伪代码:
KnapsackMR(i, c) //前i个商品中, 容量为c时最优解
输入:商品集合{1, ..., i}, 背包容量c
输出:最大总价格 P[i, c]
P[i, c]表示在前i个商品中选择,背包容量为c时的最优解
if c < 0 then //超出背包容量
return -∞
end
if i <= 0 then //所有商品已决策完成
return 0
end
if P[i, c] != NULL then
return P[i, c] //避免重复计算
end
P1 <- KnapsackMR(i-1, c-v_i) //选择商品i
P2 <- KnapsackMR(i-1, c) //不选择商品i
P[i, c] <- max{P1 + p_i, P2} //构造备忘录
return P[i, c]
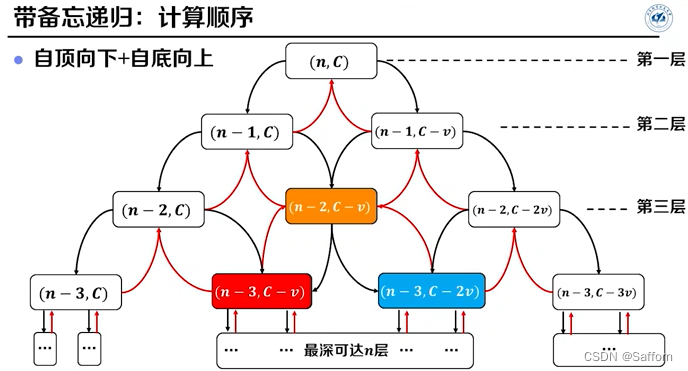
3. 递推计算
忽略掉 带备忘录递归 的 自顶向下 过程的优化方法,直接计算备忘录
P
[
i
,
c
]
P[i, c]
P[i,c]
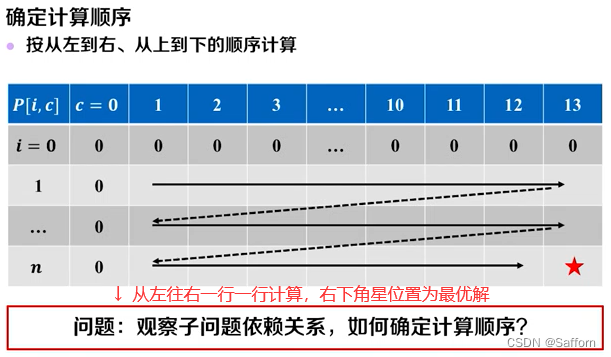
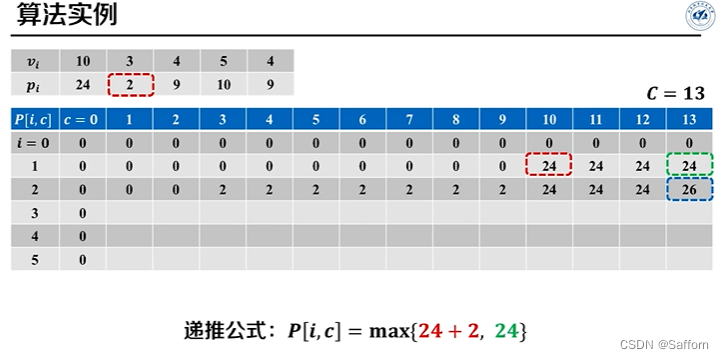
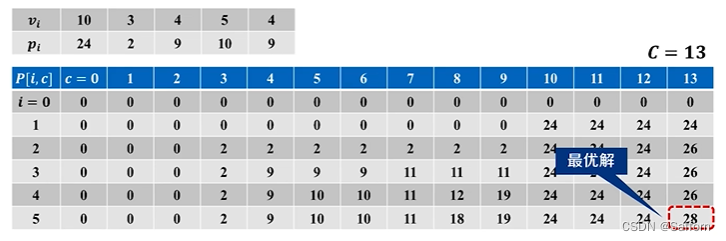
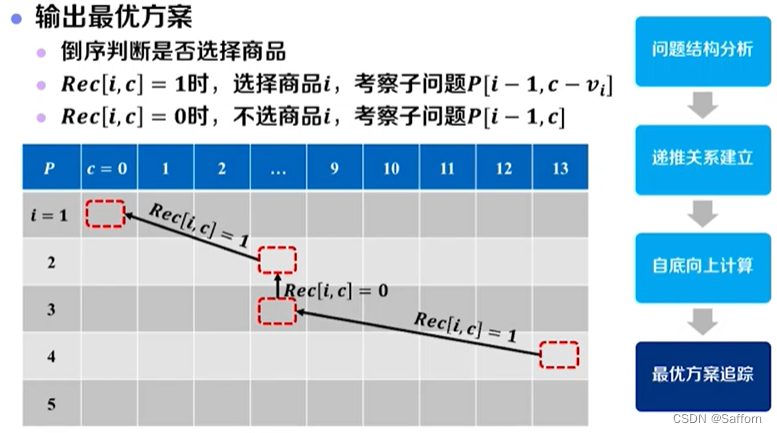
最优解追踪:
① 倒叙判断是否选择商品
② 根据选择结果,确定最优子问题
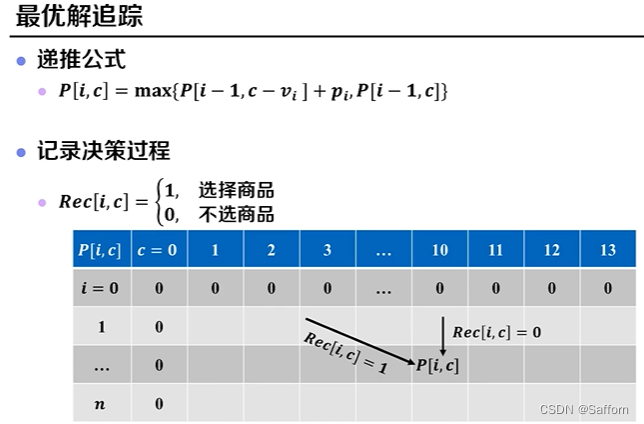
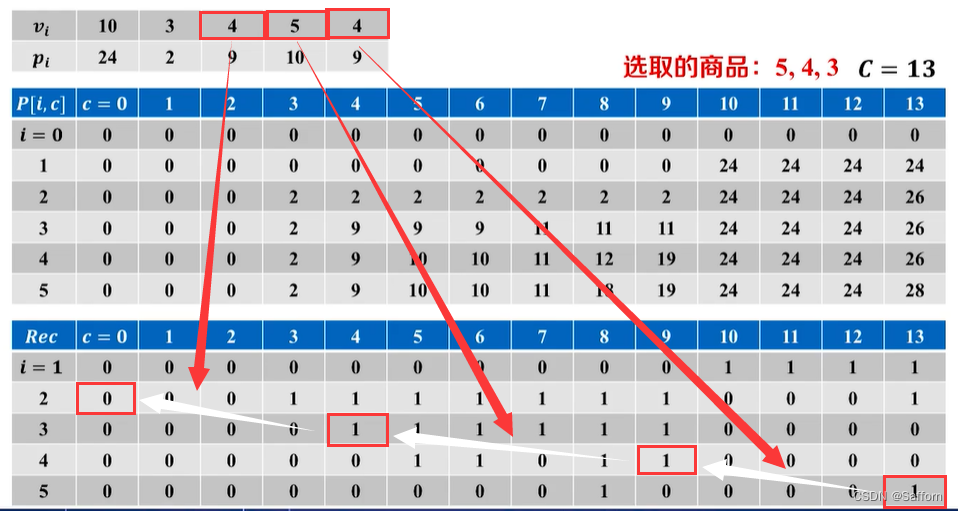
伪代码:
KnapsackDP(n, p, v, C) //前i个商品中, 容量为c时最优解
输入:商品数量n, 各商品的价值p, 各商品的体积v, 背包容量C
输出:商品总价格的最大值, 最优解方案
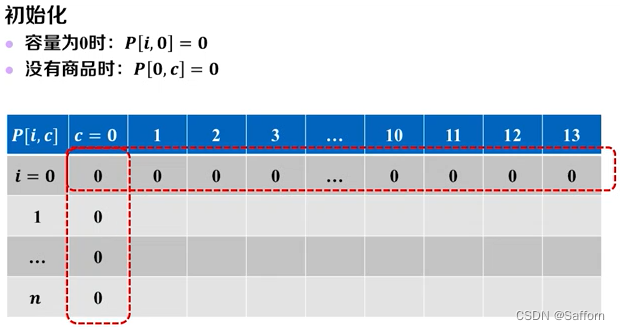
创建二维数组 P[0..n, 0..C] 和 Rec[0..n, 0..C] // 初始化
for i <- 0 to C do
P[0, i] <- 0
end
for i <- 0 to n do
P[i, 0] <- 0
end
//求解表格
for i <- 1 to n do //依次计算子问题
| for c <- 1 to C do
| | if (v[i] <= c) and (p[i] + P[i-1, c-v[i]] > P[i-1, c]) then //选择商品i
| | P[i, c] <- p[i] + P[i-1, c-v[i]] //记录价格和决策
| | Rec[i, c] <- 1
| | end
| | else //不选商品i
| | P[i, c] <- P[i-1, c]
| | Rec[i, c] <- 0
| | end
| end
end
// 输出最优解方案
K <- C
for i <- n to 1 do //倒序判断是否选择是否选择该商品
| if Rec[i, K] = 1 then
| print 选择商品i
| K <- K-v[i] //回溯子问题
| end
| else
| print 不选商品i
| end
end
return P[n, C]
时间复杂度:
求解表格阶段,整体复杂度为
O
(
C
∗
n
)
O(C*n)
O(C∗n),其中 n 是商品数量,C 是背包容量
总结:
贪心(Greedy)
概要
步骤:① 提出贪心策略 → ② 证明策略正确
部分背包问题

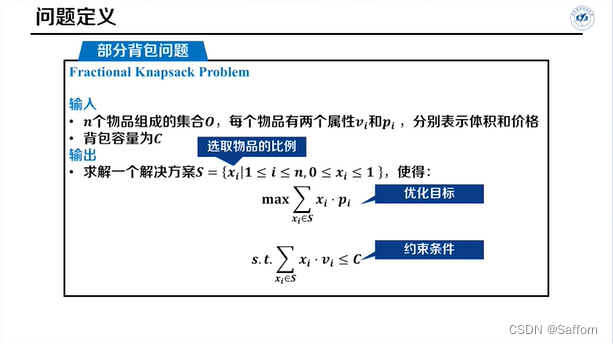
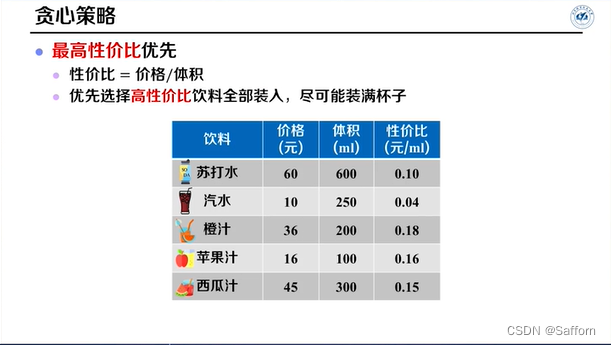
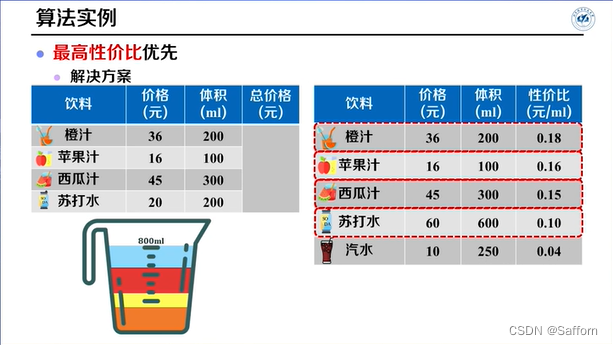
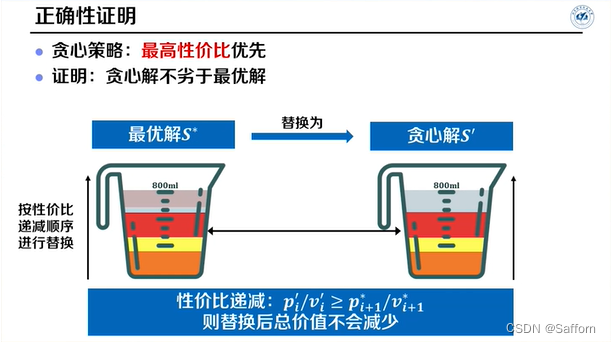
↑替换后单位体积的价值均不减少,故贪心解不劣于最优解(或者说贪心解即为最优解)
伪代码:
输入:商品数量 n, 各商品的价值 p, 各商品的体积 v, 背包容量 C
输出:商品价格的最大值, 最优解方案
计算商品性价比 Radio[1..n] 并按降序排序
// Radio[i], p[i], v[i]分别表示性价比第i大的商品的性价比、价格和体积
i ← 1
ans ← 0
while C > 0 and i <= n do
if v[i] <= C then
选择商品
ans ← ans + p[i]
C ← C - v[i]
end
else
选择C体积的商品i
ans ← ans + p[i] * (C / v[i])
C ← 0
end
i ← i + 1
end
return ans
算法时间复杂度:
排序部分时间复杂度
O
(
n
l
o
g
n
)
O(n log n)
O(nlogn),贪心求解部分时间复杂度
O
(
n
)
O(n)
O(n),整体时间复杂度为
O
(
n
l
o
g
n
)
O(n log n)
O(nlogn)
对比0-1背包问题:(需要用DP算法求解)
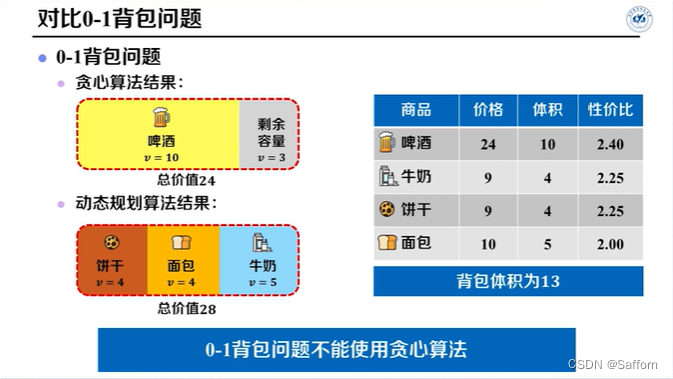
Huffman编码
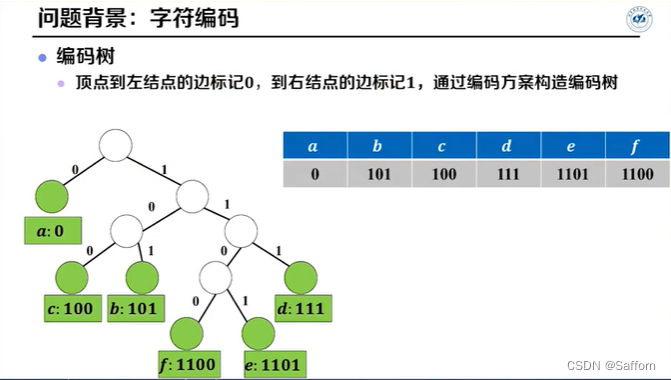
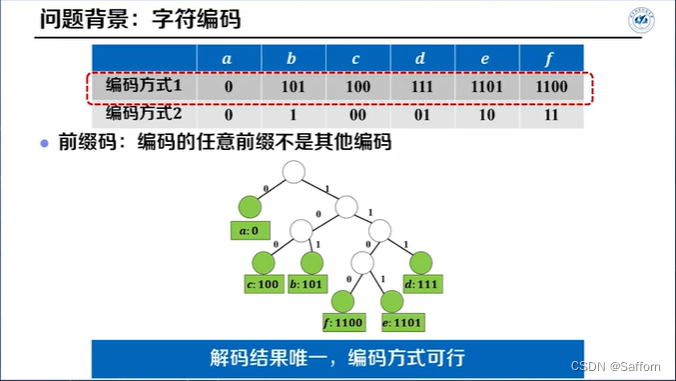
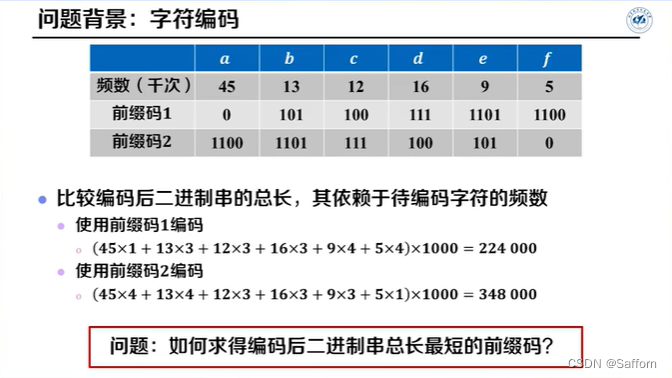
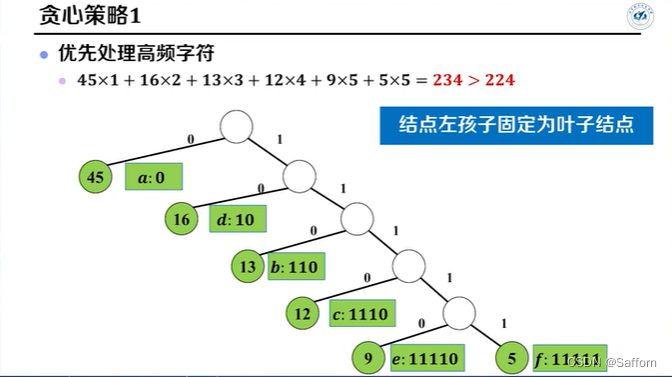
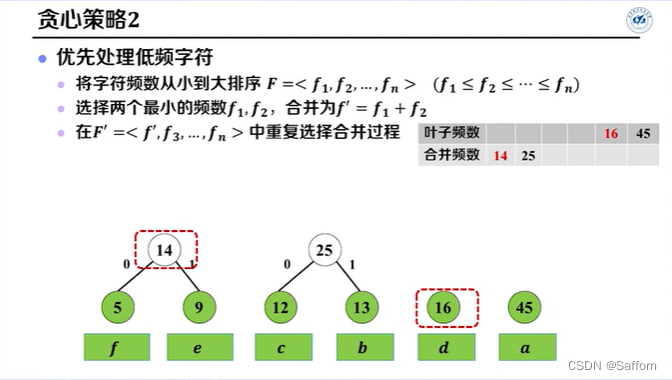

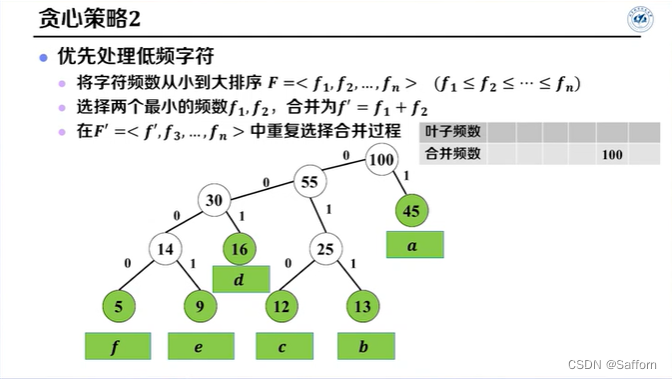
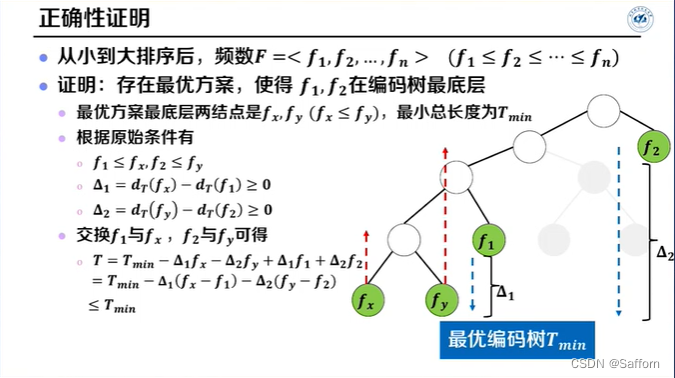
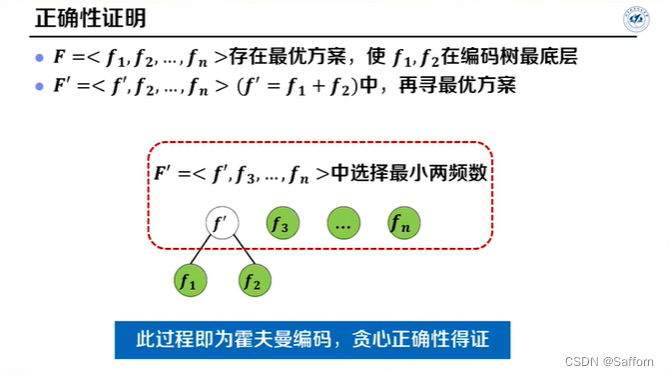
输入:字符数 n, 各字符频数 F
输出:霍夫曼编码数
将F递增排序(字符频数按从小到大排序)
新建节点数组 P[1..n] 和 Q[1..n] //初始化结点数组
for i ← 1 to n do
P[i].freq ← F[i]
P[i].left ← NULL
P[i].right ← NULL
end
Q ← {}
for i ← 1 to n-1 do //共需合并n-1次
x ← ExtractMin(P, Q) //选择频数最小的结点
y ← ExtractMin(P, Q)
z.freq ← x.freq + y.freq //合并两个选择的结点
z.left ← x
z.right ← y
Q.Add(z) //存储合并后的结点
end
return ExtractMin(P, Q) //返回编码树的根节点
算法时间复杂度:
排序部分时间复杂度
O
(
n
l
o
g
n
)
O(n log n)
O(nlogn),初始化部分时间复杂度
O
(
n
)
O(n)
O(n),数组开头查找最小值、合并、存储共计
O
(
n
)
O(n)
O(n),整体时间复杂度为
O
(
n
l
o
g
n
)
O(n log n)
O(nlogn)
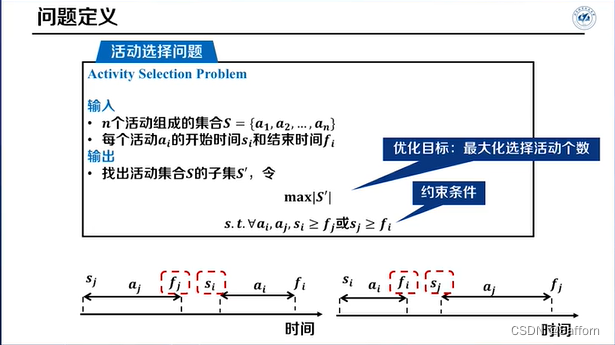
活动选择问题
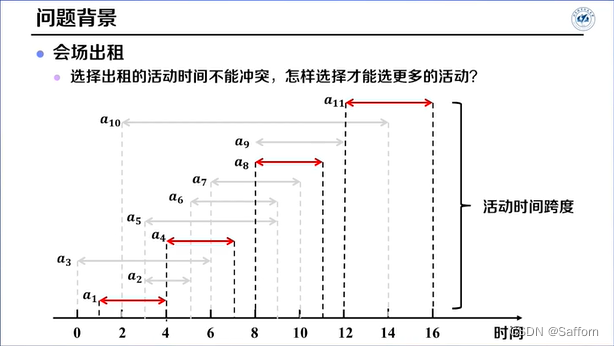
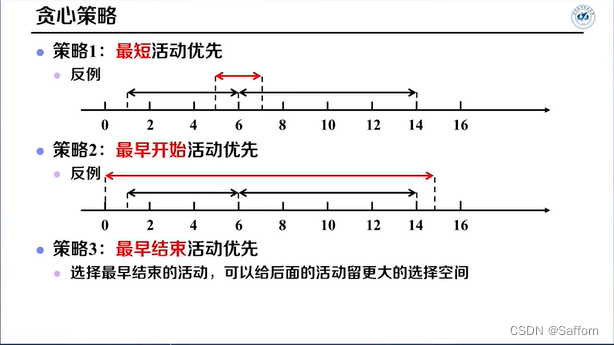
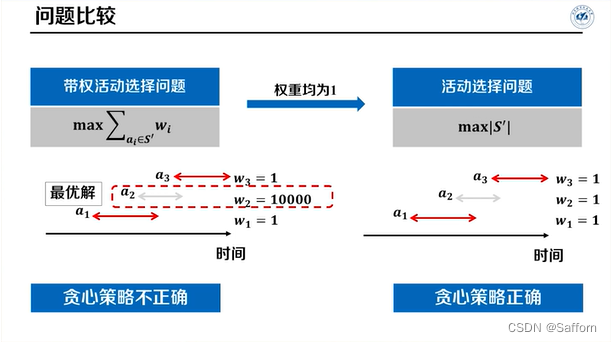
证明贪心算法得不到最优解,举一反例即可:

伪代码:
输入:活动集合 S = {a_1, a_2, ..., a_n}, 每个活动a_i的起止时间s_i, f_i
输出:不冲突活动的最大子集 S'
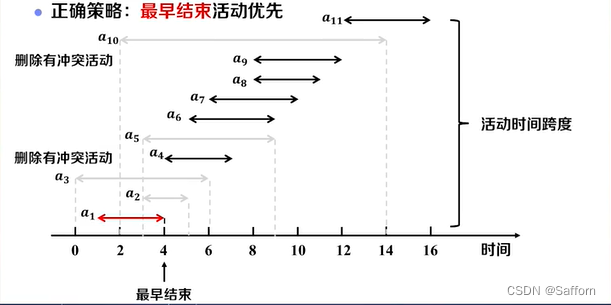
把活动按照结束时间升序排序
S' ← {a_1} //把最早结束的活动加入到集合
k ← 1 //记录当前选择的活动
for i ← 2 to n do //检查每个活动
if s_i >= f_k then //如果没有冲突,则加入子集
S' ← S'∪{a_i}
k ← i //更新当前选择的活动
end
end
return S'
算法时间复杂度:
排序部分时间复杂度
O
(
n
l
o
g
n
)
O(n log n)
O(nlogn),贪心求解部分时间复杂度
O
(
n
)
O(n)
O(n),整体时间复杂度为
O
(
n
l
o
g
n
)
O(n log n)
O(nlogn)
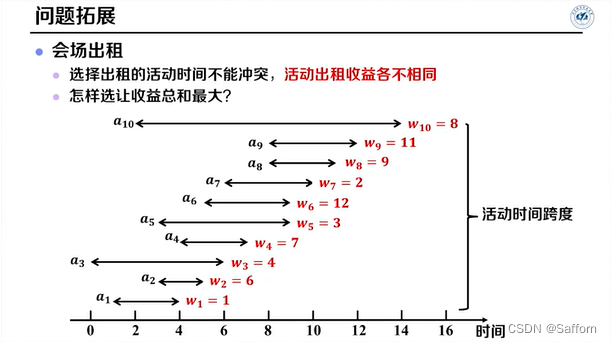
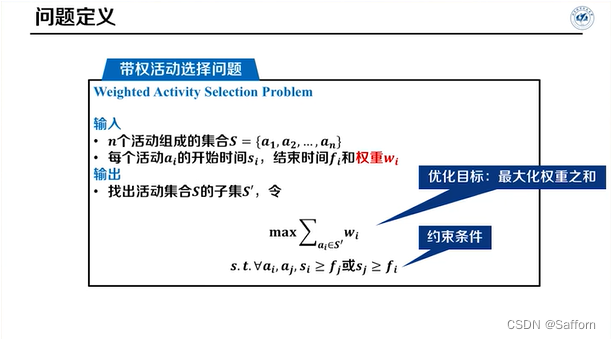
带权重的活动选择问题:不适用贪心算法,需要用动态规划算法解决















 386
386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









