






图虫网
前言
继续来实践学习多线程
一、目标网站
二、分析步骤
1.进入目标网站,摸索摸索,看看
1.1 进一步得到url
当当当,就是这个页面啦

我们就点几个看一看 我点开了 树 标签和 人像,可以看出这个标签个构成还是很简单的,我们可以自主的输入名字来获取我们想要的标签。
对于中文的转化 我们则可以采用request库中的quote 函数,

1.2再进一步来得到 单个相册的 url
我们点开人像后,啊呀,发现了一些单个图册

发现了这个好像是异步加载 啊呀 这个时候就需要我们来使用工具啦,你可以选择 在network上操作,也可以采用 fidder 上操作
那我们就来 try 一 try ,请看图

我们先打开这个url 然后我们试一试改变一下page 的数字啊 看看 是否其他数字也有内容 ,果不其然,其他页面也有哎 ,那估计这个异步加载所需要的东西了 如果还有疑问 我们还可以验证验证嘛
我们来打开单个相册进去看一看它的url
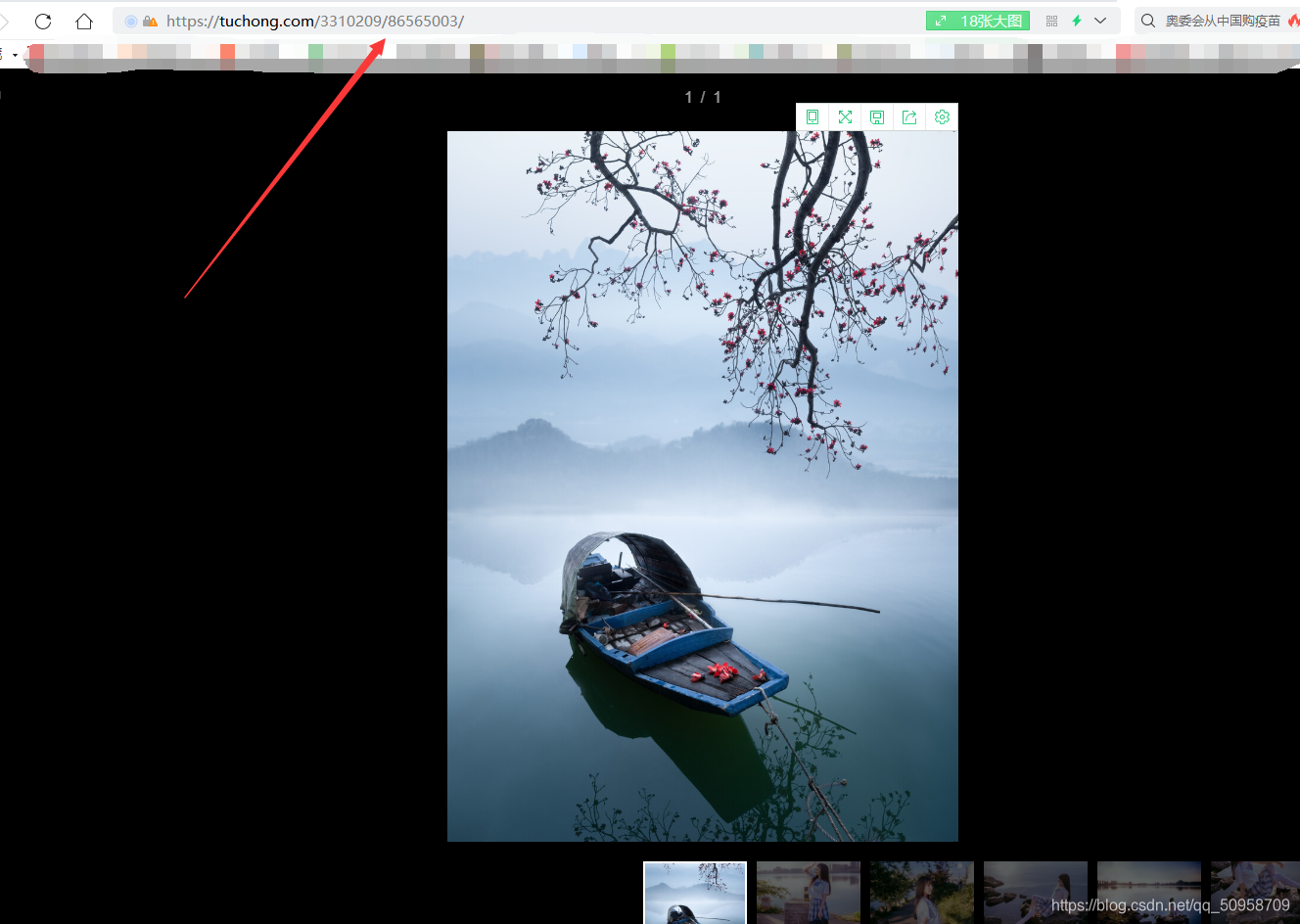
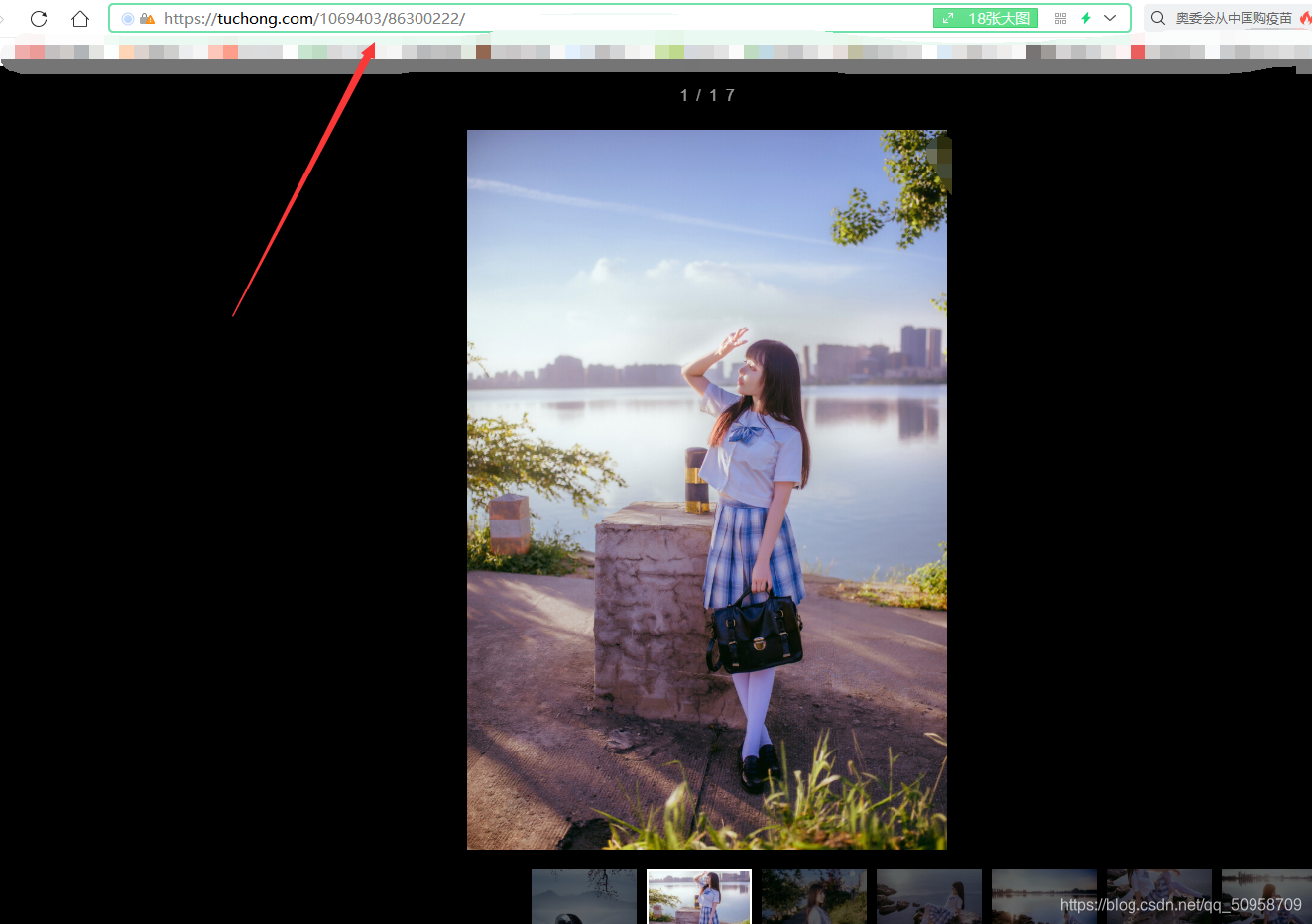
看看这个url的格式 是不是 和 我们在通过抓包得到的 url 中的内容是不是有些一样呢

至于为啥没得相同的,可能是因为加载一次它推送的内容会变化 ,但这不妨碍我们找到规律噻,如果你还是不相信的话 那你可以去试一试绝对可以在我们抓包得到的url中 找到相同的 单个相册的url
2.在单个相册里面获取单个图片的url
这个当时把我卡住了 啊啊啊,我必须吐槽一哈自己的知识的浅薄
2.1最开始的分析 ,我以为我行了

我以为我见识到了希望的光芒,但是没想到啊 ,在我写好了 xpath的时候,正准备 等待胜利的果实,没想到,居然返回了空空的果树。 我也不断地改xpath啊 就是不行啊。 太难了
2.2第二次分析,我以为我又行了
上一种不行了,好吧,我以为这应该也是一个异步加载,再一次开干。 没想到打开工具后 的第一步就不行了,加载不出来东西啊 又失败了啊
2.3第三次,我终于行了
我在这里,发现了打开新世界的大门啊 好像也只有在点了 f12 后再刷新才能进入啊

刷新后 就像有了一把进入另一扇门的钥匙

在这个界面我们 来 查看网页源代码

好吧,到这我们的分析过程就完全结束了
下面进入代码部分
代码
我想经过前面的分析, 思路也就很清晰了吧,对于单线程的思路 还是 很清晰滴
下面是单线程滴
import requests
from urllib import request
import re,os
from lxml.html import fromstring
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
def get_urls(key):
urls = []
for i in range(1,3):
url=f'https://tuchong.com/rest/tags/{key}/posts?page={i}&count=20&order=weekly'
resp=requests.get(url,headers=headers).text
pat='"type":"multi-photo","url":"(.*?)"'
txts=re.compile(pat).findall(resp)
for txt in txts:
txt = txt.replace('\\', '')
print(txt)
urls.append(txt)
return urls
def picture_url(urls):
picture_urls=[]
for url in urls:
resp = requests.get(url, headers=headers).text
txt = fromstring(resp)
purl = txt.xpath('//article[@class="post-content"]/img/@src')
picture_urls.append(purl)
return picture_urls
def load(p_urls):
path='tuchong'
if not os.path.exists(path):
os.mkdir(path)
for index,p_url in enumerate(p_urls):
path=os.path.join('tuchong',str(index))
if not os.path.exists(path):
os.mkdir(path)
if(len(p_url)>1):
for number,url in enumerate (p_url):
request.urlretrieve(url,os.path.join(path,f'第{number+1}.jpg'))
else:
url=p_url[0]
request.urlretrieve(url,os.path.join(path,'1.jpg'))
print(f'第{index}个相册 已下载完成')
def main():
key=input("需要的标签")
key=request.quote(key)
#key = request.quote('人像')
urls=get_urls(key)
p_urls=picture_url(urls)
load(p_urls)
if __name__ == '__main__':
main()
下面是多线程滴
多线程也不是很难 详细的可以看看这里 [这个也是我写滴,小小的推销一下],嘿嘿我自己感觉还算是详细滴。嘿嘿(https://blog.csdn.net/qq_50958709/article/details/113183815)
import requests
from urllib import request
import re,os
from lxml.html import fromstring
import threading
import queue
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
class product(threading.Thread):
def __init__(self,picture_urls,load_picture,urls):
super(product, self).__init__()
self.picture_urls=picture_urls
self.load_picture=load_picture
self.urls=urls
def get_picture(self):
while not self.picture_urls.empty():
urls=self.picture_urls.get()
url=urls['url']
number=urls['number']
resp = requests.get(url, headers=headers).text
txt = fromstring(resp)
purls = txt.xpath('//article[@class="post-content"]/img/@src')
path = os.path.join('tuchong', str(number))
if not os.path.exists(path):
os.mkdir(path)
self.load_picture.put({'purls':purls,'path':path})
def run(self) -> None:
for number,url in enumerate(self.urls):
self.picture_urls.put({'url':url,'number':number})
self.get_picture()
class consumer(threading.Thread):
def __init__(self,load_picture):
super(consumer, self).__init__()
self.load_picture=load_picture
def run(self) -> None:
while True:
try:
urls=self.load_picture.get(timeout=10)
p_url=urls['purls']
path=urls['path']
except:
break
if (len(p_url) > 1):
for number, url in enumerate(p_url):
request.urlretrieve(url, os.path.join(path, f'第{number + 1}.jpg'))
print(f'{number} 已下载')
else:
url = p_url[0]
request.urlretrieve(url, os.path.join(path, '1.jpg'))
print(' 01 已下载')
def get_urls(key):
urls = []
for i in range(1,3):
url=f'https://tuchong.com/rest/tags/{key}/posts?page={i}&count=20&order=weekly'
resp=requests.get(url,headers=headers).text
pat='"type":"multi-photo","url":"(.*?)"'
txts=re.compile(pat).findall(resp)
for txt in txts:
txt = txt.replace('\\', '')
urls.append(txt)
return urls
def main():
picture_urls=queue.Queue(5)
load_picture=queue.Queue(10)
key = request.quote('人像')
#key = input("需要的标签:")
#key = request.quote(key)
urls=get_urls(key)
for i in range(10):
th1=product(picture_urls,load_picture,urls)
th1.start()
for i in range(10):
th2=consumer(load_picture)
th2.start()
if __name__ == '__main__':
main()
如果有什么瑕疵,感谢各位大佬指出。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









