






首先我们要对双指针算法有个基本的认识.
//i作为扫描仪
for(int i=0,j=0;i<n;i++)
while(j<i&&check(i,j)j++;
//对位于合法范围内的元素i进行某种检验,然后移动它
双指针算法的作用就在于**它将复杂度为 O ( n 2 ) O(n_2) O(n2)的双重循环算法简化为复杂度为 O ( 2 n ) O(2n) O(2n)的算法。**这一点 可以从上面的代码中看出来,对于i,j,它们各自的使用次数不会超过n。
双指针算法应用:分割单词
给定一个字符串,字符串内包含若干用空格隔开的单词,输出里面的单词。
为了方便说明,这里我们假设开头无空格,单词之间的空格只有一个。
> #include <iostream>
> #include <cstring>//必须是cstring,否则strlen()方法不能用
> #include <stdio.h> using namespace std;
>
> int main() {
> char a[40000];
> gets_s(a);//必须是char型数组,不能是其他类型数组
> int len = strlen(a);//得到char型数组的实际长度
> int n = strlen(a);
> //i代表每个单词的具体开头
> for (int i = 0; i < n; i++) {
> int j = i;
> while (j < n && a[j] != ' ');
>
> for (int k = i; k < j; k++)cout << a[k];
>
> //输出单词后i指向j,然后下一步i++就会来到新单词的头部
> i = j;
> }
> return 0; }
上面只是最简单的一种情况,接下来我们加大难度。
给定一个长度为 n 的整数序列,请找出最长的不包含重复的数的连续区间,输出它的长度。
输入格式
第一行包含整数 n。
第二行包含 n 个整数(均在 0∼105 范围内),表示整数序列。
输出格式
共一行,包含一个整数,表示最长的不包含重复的数的连续区间的长度。
数据范围
1≤n≤105
输入样例:
5
1 2 2 3 5
输出样例:
3
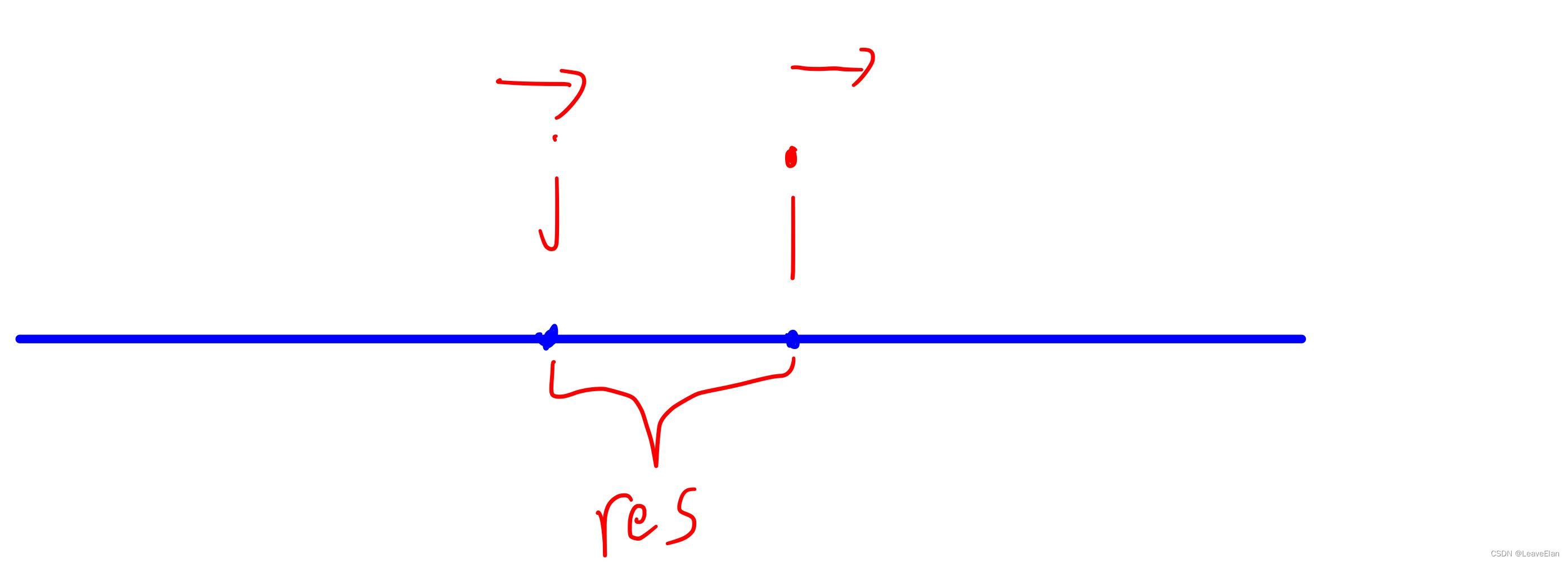
对于已有的一段数字序列,我们将i置于j的右侧,让j从i的位置出发,向左移动,探寻最长的非连续整数序列。
为什么要这么做呢?按照正常的想法,不应该式把
i
i
i放于
j
j
j的左侧,然后
j
j
j向右探测吗?
下面用图来说明这一原因。
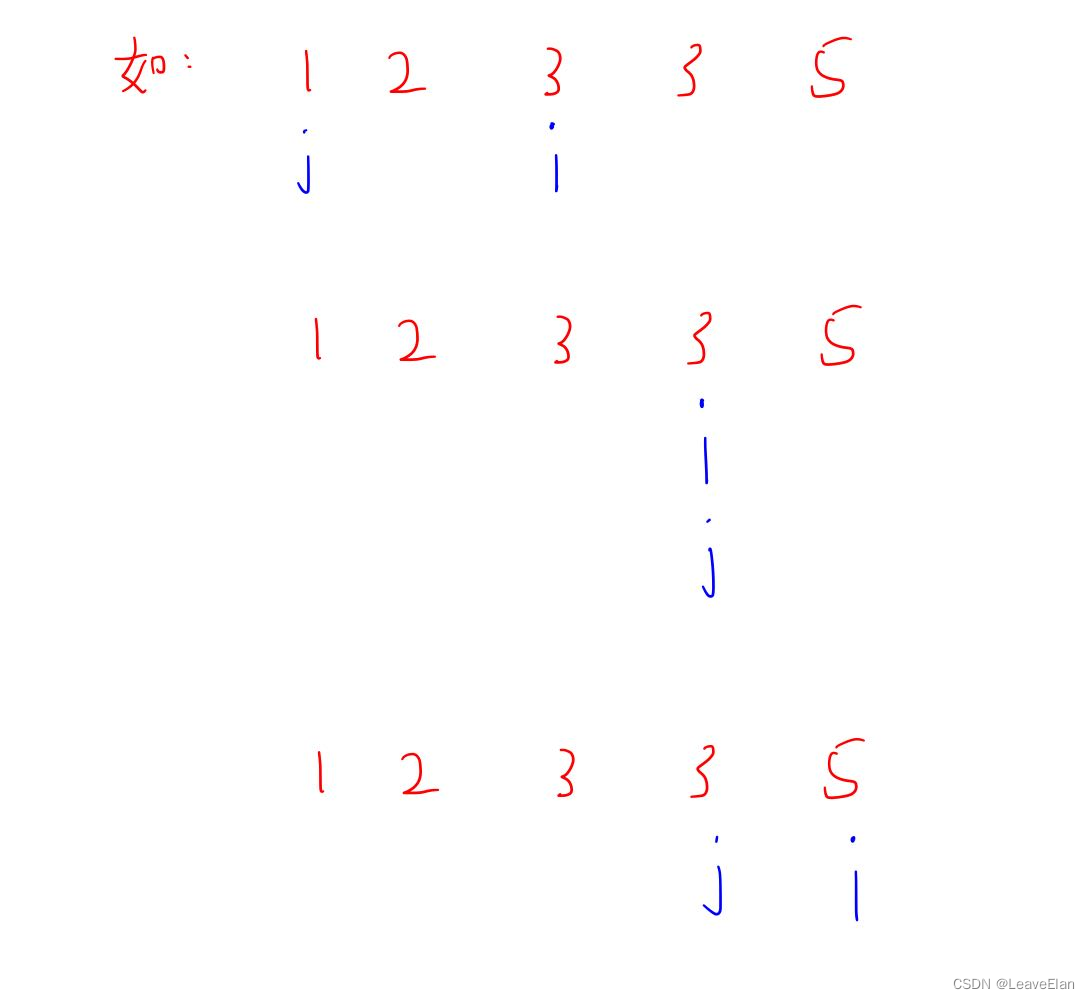
我们有以下结论:随着
i
i
i的向右移动,
j
j
j的位置也将一直向右移动,且每次移动中
j
j
j的位置永远与上次的位置重合或在上次位置的右边。这点我们可以从
j
j
j本身代表的意义来理解,
j
j
j的位置是离
i
i
i最远的非重复整数序列的下标,即
j
j
j的左边的相邻数字包含着
[
j
,
i
]
[j,i]
[j,i]区间中的一个数字,因此无论后面的
i
i
i去到哪里,
j
j
j绝不会越过上一次自己位置的左边,因为一旦越过左边,在
j
i
ji
ji之间就会出现重复数字,位置为
j
j
j,与
[
j
,
i
]
[j,i]
[j,i]区间中的某一位。
伪代码如下
for(int i=0;i<n;i++)
while(j<=i&&check(i,j))j++;
res=max(i-j+1,res);
那么 我们只剩一个问题,就是如何实现这个check函数。
check函数的实现
基本思想:设置一个计数数组S[N],统计在 [ i , j ] [i,j] [i,j]区间中出现的数字次数,如 1 , 2 , 3 , 3 1,2,3,3 1,2,3,3那么对应的数组元素就是S[1]=1,S[2]=1,S[3]=2。在整个check函数的执行过程中,S[N]中一旦出现某一位元素大于1,就说明出现了重复元素。
代码
#include <iostream>
#include <cstring>//必须是cstring,否则strlen()方法不能用
#include <stdio.h>
using namespace std;
const int N=100010;
int a[N], s[N];
int n;
int main()
{
cin >> n;
for (int i = 0; i < n; i++)cin >> a[i];
int res = 0;
for (int i = 0, j = 0; i < n; i++)
{
s[a[i]]++;
while (s[a[i]] > 1) {
s[a[j]]--;
j++;
}
res = max(res, i - j + 1);
}
cout << res << endl;
return 0;
}
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









