



 本文介绍了如何使用数组来模拟单链表和双链表,详细阐述了初始化、插入、删除等操作的实现,并通过示例解释了操作过程。文章提供了完整的C++代码实现,并给出了相关操作题目的输入输出样例,帮助读者理解数据结构的操作和应用。
本文介绍了如何使用数组来模拟单链表和双链表,详细阐述了初始化、插入、删除等操作的实现,并通过示例解释了操作过程。文章提供了完整的C++代码实现,并给出了相关操作题目的输入输出样例,帮助读者理解数据结构的操作和应用。
本系列文章仅作笔记复习用,笔者水平有限,望大家不吝赐教
整个过程时用数组去模拟一些经典的数据结构。原因是如果用常见的struct结构,已模拟链表为例:
new的过程是相当慢的,数组是更好的选择。而这篇文章的任务就是拿数组模拟链表。
单链表
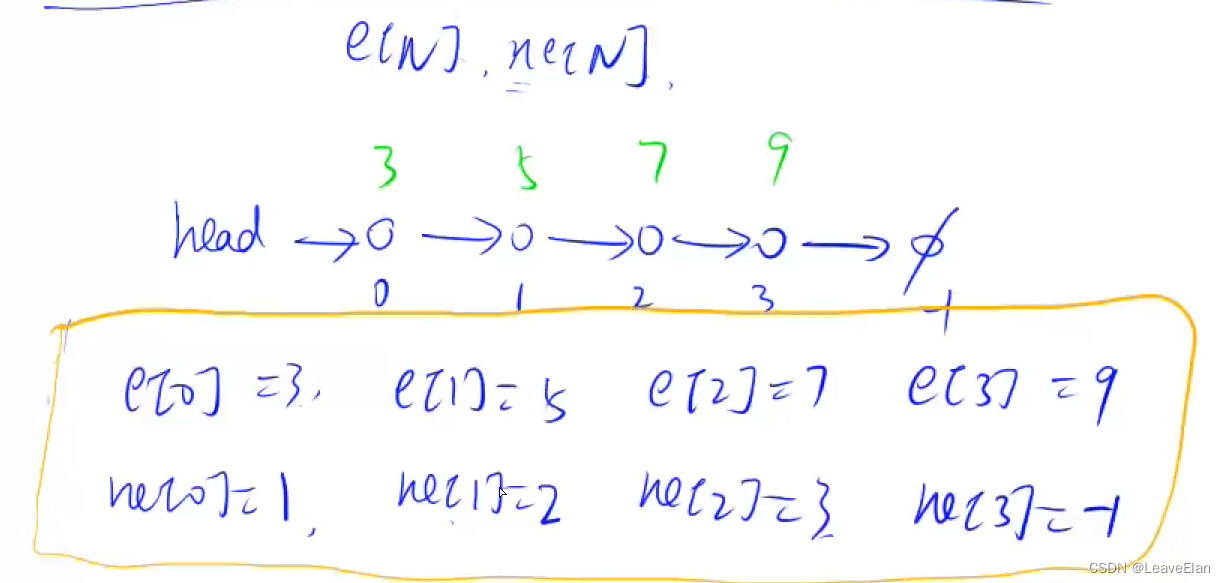
e[N]e[N]e[N]代表第N个结点的值,ne[N]ne[N]ne[N]代表第N+1个结点的下标,空结点的下标用-1表示、
单链表的代码
初始化:
#include<iostream>
using namespace std;
const int N = 100010;
//head代表头节点下标,e[N]为结点的值,ne[N]为下一个节点的编号.idx存储当前用到了哪个结点
int head, e[N], ne[N],idx;
void init() {
head = -1;
idx = 0;
}
插入到头部
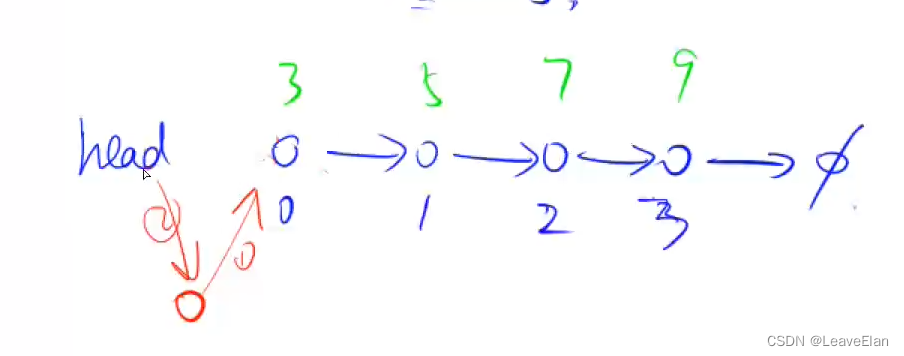
y总在这里的下标不是对应数组的下标,而是指对于当前原始链表来说,它是几号结点
//将x插到头节点的位置,注意链表元素的顺序
void add_to_head(int x) {
e[idx] = x;
ne[idx] = head;
head = idx;
idx++;
}
插入
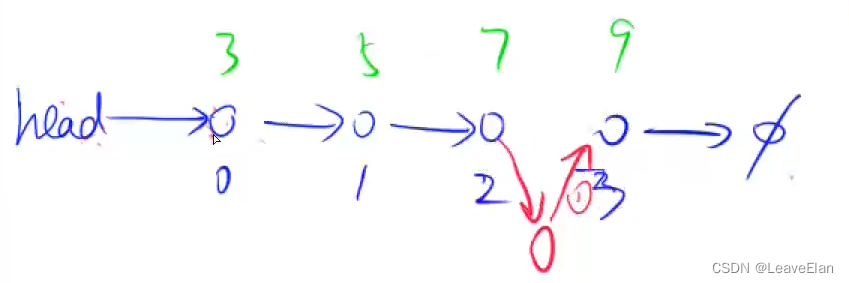
//一般插入,x插到第k个输入的结点的后方,见上方图
void add(int k,int x) {
e[idx] = x;
//把k结点的下一个指针赋给新插入结点x的ne指针
ne[idx] = ne[k];
//让ne[k]指向新插入结点
ne[k] = ne[idx];
idx++;
}
删除
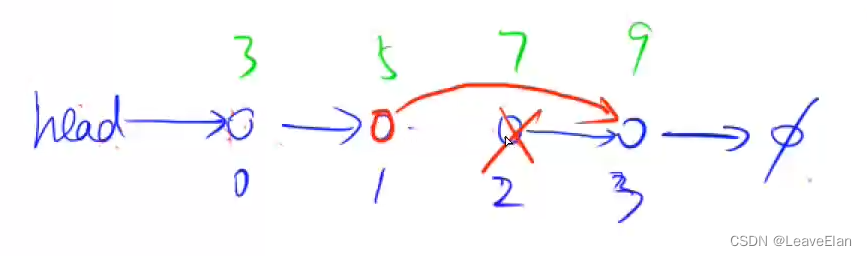
//删除在第k个输入结点之后蔡输入的结点
void remove(int k) {
ne[k] = ne[ne[k]];
}
我自己的记忆方法是看到ne就想像当前点往右滑一个单位。
单链表题目
实现一个单链表,链表初始为空,支持三种操作:
向链表头插入一个数;
删除第 k 个插入的数后面的数;
在第 k 个插入的数后插入一个数。
现在要对该链表进行 M 次操作,进行完所有操作后,从头到尾输出整个链表。
注意:题目中第 k 个插入的数并不是指当前链表的第 k 个数。例如操作过程中一共插入了 n 个数,则按照插入的时间顺序,这 n 个数依次为:第 1 个插入的数,第 2 个插入的数,…第 n 个插入的数。
输入格式
第一行包含整数 M,表示操作次数。
接下来 M 行,每行包含一个操作命令,操作命令可能为以下几种:
H x,表示向链表头插入一个数 x。
D k,表示删除第 k 个插入的数后面的数(当 k 为 0 时,表示删除头结点)。
I k x,表示在第 k 个插入的数后面插入一个数 x(此操作中 k 均大于 0)。
输出格式
共一行,将整个链表从头到尾输出。
数据范围
1≤M≤100000
所有操作保证合法。
输入样例:
10
H 9
I 1 1
D 1
D 0
H 6
I 3 6
I 4 5
I 4 5
I 3 4
D 6
输出样例:
6 4 6 5
对于“删除第 k 个插入的数后面的数”这个问题,我们认为第一个插入的点下标为1 ,因此删除第k个插入的数后面的数实际上是删掉下标为k-1的数后面的数。同理,“在第 k 个插入的数后插入一个数。”其实就是在下标为k-1的数后面插一个数。
下面以题目例子说明:
H9:在头结点的位置插入9
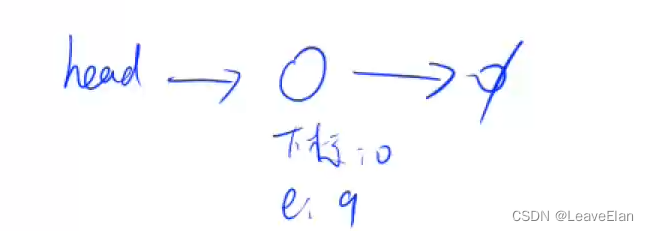
I 1 1:在第一个插入的点(即9)后面插入一个新的点1
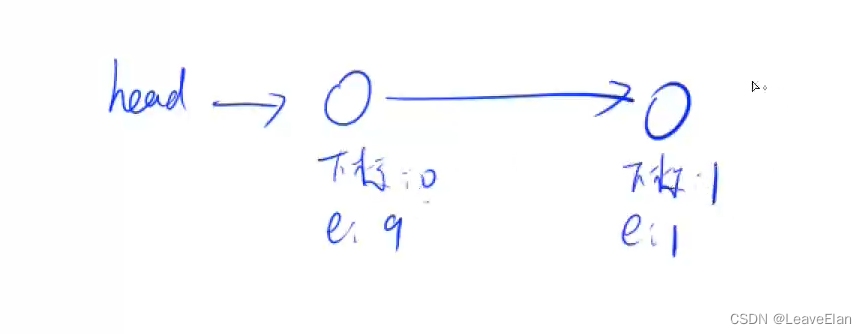
D1:删除第一个插入的点:

D0:删除头节点:

H6;头节点处插入6,下标(idx)为2,因为是第三个插入的结点
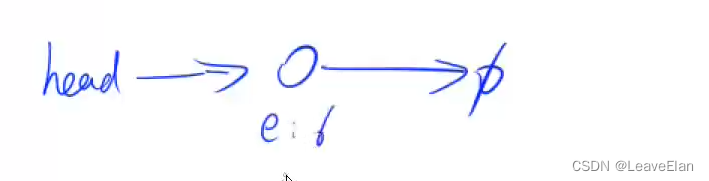
I 3 6:在第三个插入点插入新的点6
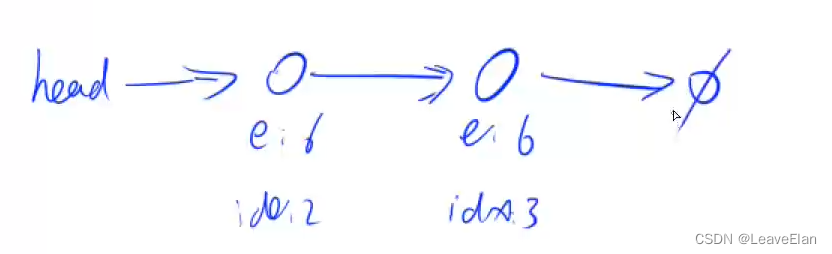
剩下的以此类推
最后的结果是:
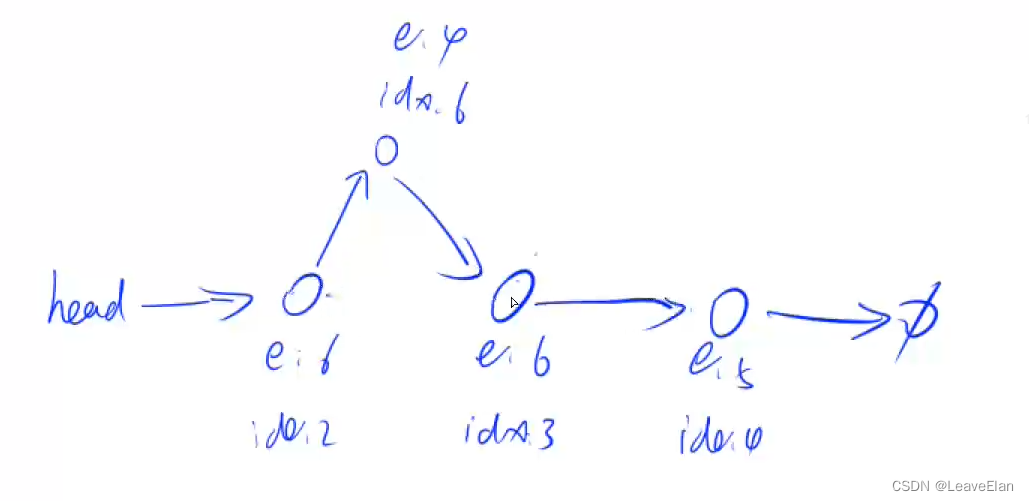
接下来让我们完成代码,具体的功能函数都已实现,只缺Main函数
#include<iostream>
using namespace std;
const int N=100010;
int idx,head,n[N],ne[N];
int a;
void add_head(int x){
n[idx]=x;
ne[idx]=head;
head=idx++;
}
void add(int k,int x){
n[idx]=x;
ne[idx]=ne[k];
ne[k]=idx++;
}
void remove(int k){
ne[k]=ne[ne[k]];
}
int main(){
head=-1;idx=0;
cin>>a;
while(a--){
string op;
int k,x;
cin>>op;
if(op=="D")
{
cin>>k;
if(!k)head=ne[head];
remove(k-1);
}
else if(op=="H")
{
cin>>x;
add_head(x);
}
else if(op=="I"){
int k,x;
cin>>k>>x;
add(k-1,x);
}
}
for(int i=head;i!=-1;i=ne[i])
cout<<n[i]<<" ";
return 0;
}
双链表
有了单链表的铺垫,我们直接写代码介绍双链表。
实现一个双链表,双链表初始为空,支持 5 种操作:
在最左侧插入一个数;
在最右侧插入一个数;
将第 k 个插入的数删除;
在第 k 个插入的数左侧插入一个数;
在第 k 个插入的数右侧插入一个数
现在要对该链表进行 M 次操作,进行完所有操作后,从左到右输出整个链表。
注意:题目中第 k 个插入的数并不是指当前链表的第 k 个数。例如操作过程中一共插入了 n 个数,则按照插入的时间顺序,这 n 个数依次为:第 1 个插入的数,第 2 个插入的数,…第 n 个插入的数。
输入格式
第一行包含整数 M,表示操作次数。
接下来 M 行,每行包含一个操作命令,操作命令可能为以下几种:
L x,表示在链表的最左端插入数 x。
R x,表示在链表的最右端插入数 x。
D k,表示将第 k 个插入的数删除。
IL k x,表示在第 k 个插入的数左侧插入一个数。
IR k x,表示在第 k 个插入的数右侧插入一个数。
输出格式
共一行,将整个链表从左到右输出。
数据范围
1≤M≤100000
所有操作保证合法。
输入样例:
10
R 7
D 1
L 3
IL 2 10
D 3
IL 2 7
L 8
R 9
IL 4 7
IR 2 2
输出样例:
8 7 7 3 2 9
本质上。我们只用实现“往某个数的右边插入一个数“与”将第k各插入的数删除“。比如说在右端点插入一个数,本质上是”在右端点的左边一个点的右边插入一个数“,其余位置也是相似思想。同时,双链表没有空指针一说
代码:
#include<iostream>
#include<algorithm>
using namespace std;
const int N = 100010;
//e[N]为结点对应的值,l[N]为第N个结点左侧结点的地址,r[N]为第N个结点右侧的地址
int e[N], l[N],r[N], idx;
void init() {
//o表示左端点,1表示右端点。
r[0] = 1;
l[1] = 0;
//目前有0,1两个点插入
idx = 2;
}
//在第k个结点之后插入一个新结点x
void add(int k,int x) {
e[idx] = x;
r[idx] = r[k];
l[idx] = k;
l[r[k]] = idx;
r[k] = idx;
idx++;
}
//删除第k个点
void remove(int k) {
r[l[k]] = r[k];
l[r[k]] = l[k];
}
int main() {
int m;
cin >> m;
init();
while (m--)
{
string op;
cin >> op;
int k, x;
if (op == "R")
{
cin >> x;
add(l[1], x); //! 0和 1 只是代表 头和尾 所以 最右边插入 只要在 指向 1的 那个点的右边插入就可以了
}
else if (op == "L")//! 同理 最左边插入就是 在指向 0的数的左边插入就可以了 也就是可以直接在 0的 有右边插入
{
cin >> x;
add(0, x);
}
else if (op == "D")
{
cin >> k;
remove(k + 1);
}
else if (op == "IL")
{
cin >> k >> x;
add(l[k + 1], x);
}
else
{
cin >> k >> x;
add(k + 1, x);
}
}
for (int i = r[0]; i != 1; i = r[i]) cout << e[i] << ' ';
return 0;
}

















 820
820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









