







目录
3.从一个文件中读取中文的代码,严格来说是读取中英文混合的文件的代码
一、简单理解文件的读和写
在Java标准库中,有很多关于读和写的类,此处我们只用两个类
InputStream/FileInputStream
文件读取操作,按照字节为单位进行读文件
OutputStream/FileOutputStream
文件写入操作,按照字节为单位进行写文件
Stream,意思是“流”
上面的读写操作本质上是对字节流的操作,那么该如何理解“流”呢?
我们可以从“流”想到水,水在自然界是源源不断地,我们想象瀑布,而字节也是那种感觉进行运动的。
而字节流就类似于水流
我们举一个例子:通过水龙头接100ml水,我们采取的措施可以是
一次直接接满100ml;
两次,每次接50ml;
两次,一次接30ml,一次接70ml;
十次,每次接10ml。
而从文件中读取100个字节的数据的话,可以
一次直接读100字节;
两次,每次读50字节;
两次,一次读30字节,一次读70字节;
十次,每次读10字节。
字节流的最小单位是字节
在Java中,除了字节流之外,还有字符流,它是以字符为单位进行读写。
二、资源泄露
当读取完文件之后,调用inputStream.close()方法非常重要,它的作用是关闭文件,如果没有及时关闭,就可能会造成资源泄露。
关于资源泄露,我们都知道,系统中的很多资源都是有限的,比如内存、文件描述符。系统可分为用户态和内核态,在用户态中打开一个应用程序,在内核态中会创建一个相应的PCB,在这个PCB中有一个文件描述符表(类似于数组的一个顺序表),每次这个PCB打开一个文件,就会具体的产生一个文件描述符(是一个小的整数),然后把这个文件描述符放到这个文件描述符表中。更准确地说,这个文件描述符表类似于与一个数组,数组的元素是一个struct File,而数组的下标叫做文件描述符。每次打开一个文件,就要在文件描述符表中申请一项,每次关闭一个文件,就会把相应的表项释放掉,供后面使用,由于这个文件描述符表的长度是存在上限的,如果一直持续不断的打开文件,而且又不关闭的话,很快就会把这个文件描述符表给用完,此时再尝试打开文件,就会失败。这个就类似于一个大水缸,缸满后就不能再装水了,要不然,水就会溢出来。而泄露就是这个意思,千万别理解成不安全,被别人给偷了的意思。
三、读取文件的简单写法
以下是读取文件内容的最简单的两个代码,推荐第二种,因为第二种写法应用了try with resources语法,更简单明了。
1.read()一次读取一个字节
这是调用read()一次读取一个字节的情况
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
public class FileDemo9 {
public static void main(String[] args) {
//第一种写法,比较繁琐,更推荐第二种写法
InputStream inputStream=null;
try{
//这个创建实例的过程就相当于是打开文件的过程
//要先打开文件才能读写文件
inputStream=new FileInputStream("hello.txt");
//通过逐个字节的方式把文件的内容读出来
while(true){
//调用read可以读取出一些数据出来
//read有好几个版本,其中无参数版本是一次读取一个字节
//对于无参数版本的read来说,返回值是这次操作读到的字节
//返回值的范围是0~255
//如果读到文件末尾(EOF,end of file),此时如果继续调用read,就会返回-1
int b=inputStream.read();
if (b == -1) {
break;
}
System.out.printf("%c",b);
}
}catch (IOException e){
e.printStackTrace();
}finally {
try {
inputStream.close();//关闭文件,防止资源泄露
//即使这样,当代码前面出现异常时,这条代码还是不能执行,即还是会出现资源泄露
//解决这个问题的方法是加try catch finally,将这条代码写在finally中
} catch (IOException e) {
throw new RuntimeException(e);
}
}
System.out.println();
//第二种写法
//这种写法应用了try with resources语法
//能更简单地完成这个任务
try(InputStream inputStream1=new FileInputStream("hello.txt")){
while(true){
int b=inputStream1.read();
if (b == -1) {
break;
}
System.out.printf("%c",b);
}
}catch (IOException e){
e.printStackTrace();
}
}
}2.调用read()一次调用多个字节的代码
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
//一次读取1024个字节
public class FileDemo10 {
public static void main(String[] args) {
try(InputStream inputStream=new FileInputStream("hello.txt")){
byte[] buffer=new byte[1024];
while(true){
int len=inputStream.read(buffer);
if (len == -1) {
break;
}
for (int i = 0; i < len; i++) {
System.out.printf("%c",buffer[i]);
}
}
}catch (IOException e){
e.printStackTrace();
}
}
}这个代码的执行过程是
代码中的read会尝试把参数中的buffer数组给填满,buffer是1024个字节
假设该文件的大小是2049字节,读写过程为:
第一次循环,读取出1024个字节,放到buffer数组中,read返回一个1024
第二次循环,读取出1024个字节,放到buffer数组中,read返回一个1024
第三次循环,读取出1个字节,放到buffer数组中,read返回一个1
第四次循环,此时已经读到文件末尾了(EOF),read返回一个-1,结束循环
当调用read()一次调用多个字节的代码的时候,假如打开的文件中有中文,那么就会报这个异常
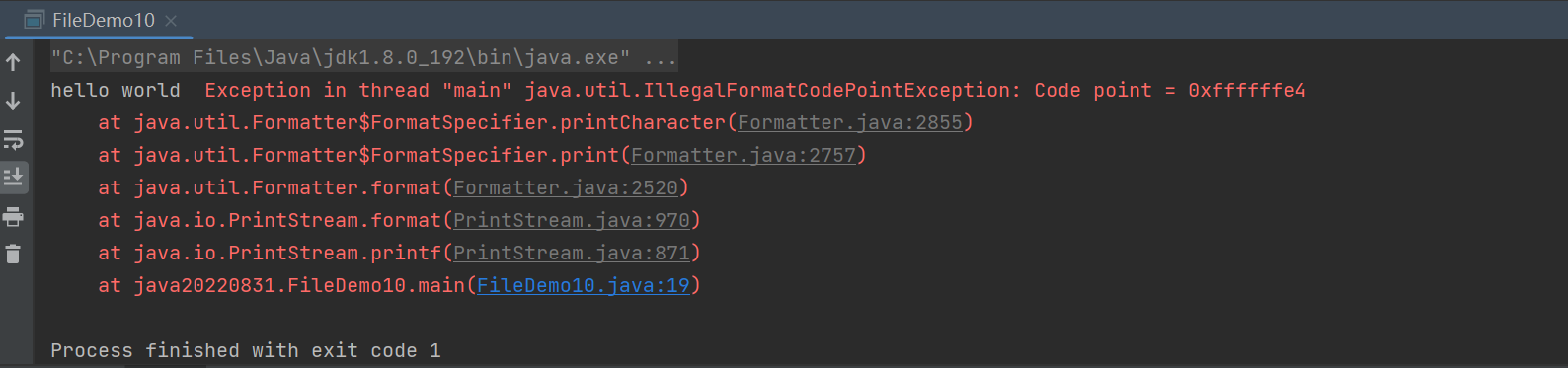
出现这个异常的原因是中文的编码方式和英文的是不太一样的,英文直接用ASCII编码,而中文用UTF-8或者GBK编码,代码中的%c其实相当于是按照ASCII的方式来进行打印,这个时候读取的字节刚好有一部分是UTF-8或者GBK,此时读取的结果就不是一个合法的ASCII值,于是就会出现异常。
一个汉字在UTF-8中,是由三个字节构成的
解决这个问题的办法是以下代码
3.从一个文件中读取中文的代码,严格来说是读取中英文混合的文件的代码
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.Scanner;
//从文件中读取中文,借助标准库中内置的处理字符集的方式
//Scanner不光能从控制台读取标准输入,也可以从文件中读取数据
public class FileDemo11 {
public static void main(String[] args) {
try(InputStream inputStream=new FileInputStream("hello.txt")) {
//这里需要注意的是,Scanner里面也有一个close方法,这个close其实也是用来关闭Scanner里面包含的InputStream的
try(Scanner scanner=new Scanner(inputStream,"UTF-8")){
while(scanner.hasNext()){
String s= scanner.next();
System.out.print(s);
}
}
}catch (IOException e){
e.printStackTrace();
}
}
}运行的结果为
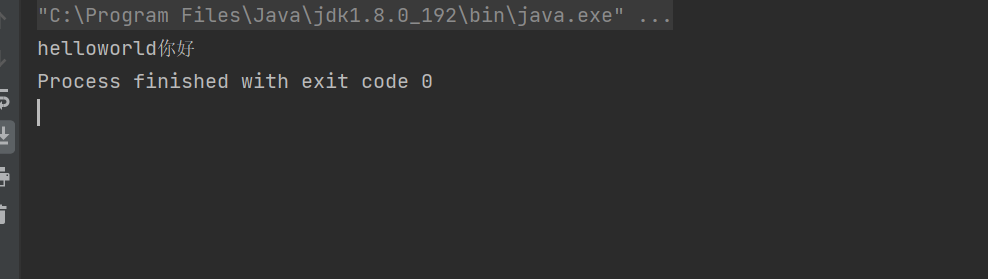
这里面需要注意的是Scanner
在上述代码中Scanner是有close()方法的,目的是关闭Scanner内的文件
当Scanner内部持有的是InputStream是System.in(标准输入)
标准输入这个文件一般不关闭,这个文件是每个进程被创建出来之后,默认打开的文件















 433
433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









