







文章目录
为什么引入HTTP协议
HTTP的影子
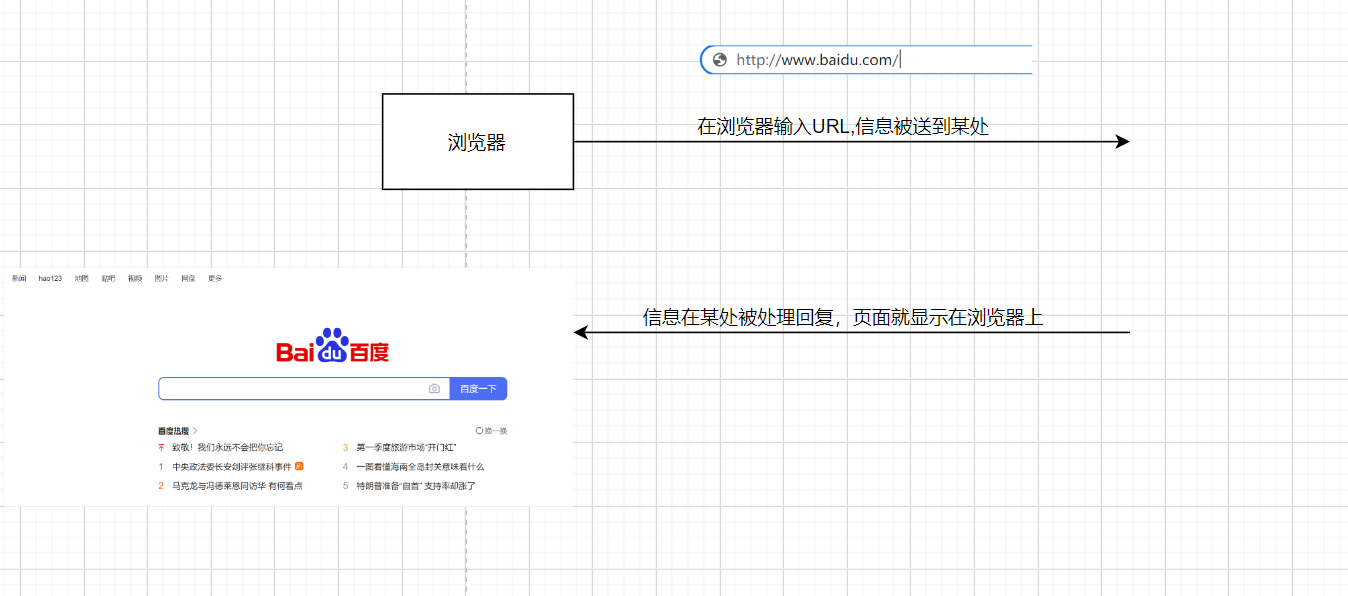
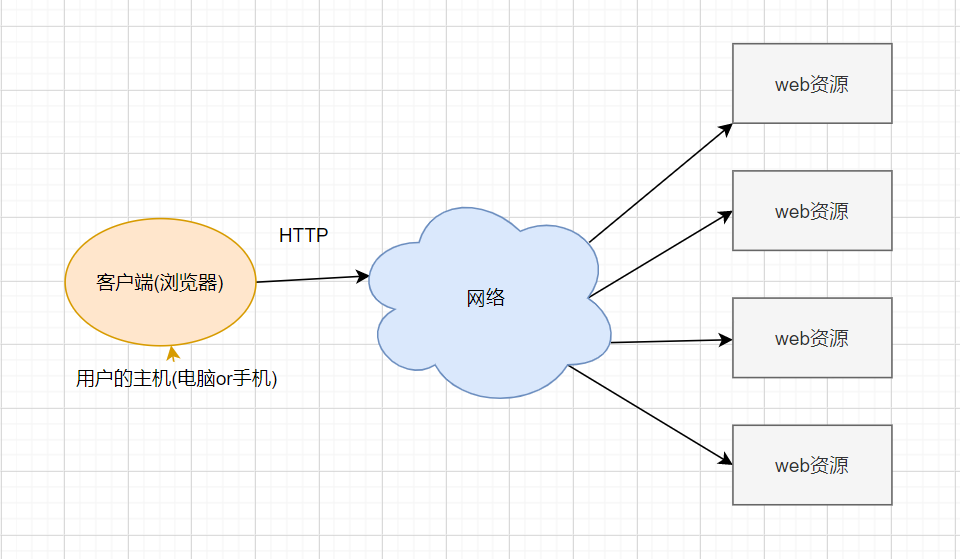
- WEB应用中的基本单位是web资源,但是WEB资源是分布在网络中的任意主机上,所以本机的浏览器想要获取这些WEB资源,必须通过一种网络协议来实现——HTTP协议,而协议是指规则的约定
- Hyper 超Text 文本Transer传输 Protocol协议
- HTTP协议的是以WEB资源为基本单位,每次请求也是针对一个WEB资源进行
- HTTP协议设计之初,是为传输超文本,HTML的前身,随着互联网的发展,HTTP协议传输的不仅仅是超文本,目前其实任意类型都是可以的,其前端三剑客的主流,但是其他多媒体资源也是可以的
HTTP的发展
- HTTP协议是一套应用层协议,(一开始是专注于业务,但现在HTTP协议本身也成为了基础的协议之一了),所以HTTP协议必须在一套传输层协议(TCP UDP)的基础上进行传输,
- HTTP在1.0,1.1,2.0是基于TCP协议进行工作,HTTP本身没有做什么可靠性的服务,必须依靠传输层的可靠性(我们从HTTP1.0,1.1协议)
- HTTP在3.0之后,开始基于UDP协议进行,(HTTP协议内部自己完成了可靠性的工作)
认识 URL
URL基本格式
作用:平时我们俗称的 “网址” 其实就是说的 URL (Uniform Resource Locator 统一资源定位符). 互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它.

-
协议方案名:常见的有 http 和 https, 也有其他的类型,换句话说,URL不仅仅针对HTTP协议设计的,网络中是所有资源都可以用URL来命名- 例如访问 mysql 时用的jdbc:mysql
- ftp://协议,文件传输协议
-
登录信息名:指定用户名和密码作为从服务器端获取资源时毕业的登录信息,这项是可选的- 登陆信息. 现在的网站进行身份认证一般不再通过 URL 进行了. 一般都会省略
-
服务器地地址:www.exanple.jp此处是一个 “域名”, 域名会通过 DNS 系统解析成一个具体的 IP 地址.(通过 ping 命令可以看到)- 通过IP来确定处于网络中的那台主机
- 这里的类型可以是DNS可解析的名称、或者192.168.1.1这种IPv4的地址名、也可以是[0:0:0:0:0:0:0:1]这种方括号括起来的IPv6地址名
-
端口号: 指定服务器连接的网络端口号,此项也是可选项,如果省略,则使用默认端口号- 端口号来确定资源是由服务器的那个进程提供的(因为进程需要绑定在端口号上,一个进程只能有一个端口号,但是一个端口号可以绑定多个进程).
- 当端口号省略的时候, 浏览器会根据协议类型自动决定使用 哪个端口. 例如 http 协议默认使用 80 端口, https 协议默认使用 443 端口
- 通常我们使用ip+端口来指明主机
-
带层次的文件路径因为即便是同一个进程,也会管理着多个资源,所以我们指定服务器上的文件路径来定位特指的资源 -
查询字符串(query string)针对已指定的文件路径的资源,可以使用查询字符串传入任意的参数- 本质是一个键值对结构. 键值对之间使用& 分隔. 键和值之间使用 = 分隔.其形式是?name1=v1&name=v2
-
片段标识此 URL 中省略了片段标识. 片段标识主要用于页面内跳转.
URI和URL的区别
- URL(统一资源定位符)是唯一资源路径
- URI(统一资源标识符)是唯一的资源标识符,URL是URI的子集
什么是URI
URI(统一资源标识符)就类似一个独一无二的身份标识。准确的说是某个网络资源的特有标识(用来区别于其他资源的独一无二的标识)有这样一个需求:
要求找到一本书(书就是资源),这本书在A省份/B市/C区/D街道/xx栋/392-1住户/1号房间/名字叫做《xxx》 (这里就是模拟我们输入网址进行HTTP请求)
- 那么此时的 《xxx》 这本书 对于 1号房间 来说就是URI
- 此时的D街道/xx栋/392-1住户/1号房间/名字叫做《xxx》这本书 对于 A省份/B市/C区 来说就是URI
- 可以看出URI是不固定的,是相对来说的,具体是什么就看你的参照角度是什么。(不同请求参照角度不一样,所以他们的返回uri有差异)
- 由此总结:URI是一个标识,用来区别于其他资源的标识。
什么是URL
那么再来说一说什么是URL(统一资源定位符)。URL就是每次我们输入网址访问某个网站时,浏览器上输入的那一行内容。比如:http://baidu.com这是一个URL
- 类比上面的例子,我们的A省份/B市/C区/D街道/xx栋/392-1住户/1号房间/名字叫做《xxx》就是一个URL,类似一个绝对地址,根据这个地址肯定能找到这本书
- 但是只根据URI,我们是找不到这本书的,必须有前提条件
- 我们的URL包含了协议,ip地址,端口号,和资源的在服务器下的相对路径,类似绝对路径,也就肯定能找到这个数据
URI和URL的关系
URI是URL的父级,URL是URI的子级。
明明是URL包含了URI为啥URI反而是父级
- 请注意,我这里用的是级别来描述,而不是包含。
- 我没有说URL是URI的一部分,而是说是他的子级。
- 想要理解这个概念,最好的说明就是Java的继承关系。URL继承了URI。这样来看是不是瞬间就明白了。
- 因为URL继承了所有URI的内容,所以它比URI更加详细,但是URI是它的父级。
有什么作用
URL的作用
- URL一般是一个完整的链接,我们可以直接通过这个链接(url)访问到一个网站,或者把这个url复制到浏览器访问网站。
URI的作用
- URI并不是一个直接访问的链接,而是相对地址(当然如果相对于浏览器那么uri等同于url了)。这种概念更多的是用于编程中,因为我们没必要每次编程都用绝对url来获取一些页面,这样还需要进行分割“http://xx/xxx”前面那一串,所以编程的时候直接request.getRequestURI就行了,当然如果是重定向的话,就用URL。
URL中的可省略部分
-
协议名: 可以省略, 省略后默认为 http://
-
ip 地址 / 域名: 在 HTML 中可以省略(比如 img, link, script, a 标签的 src 或者 href 属性).
- 省略后表示服务器的 ip / 域名与当前 HTML 所属的 ip / 域名一致.
-
端口号: 可以省略. 省略后如果是 http 协议, 端口号自动设为 80; 如果是 https 协议, 端口号自动设为 443.
-
带层次的文件路径: 可以省略. 省略后相当于访问 /
- 有些服务器会在发现 / 路径的时候,自动访问 /index.html
-
查询字符串: 可以省略
-
片段标识: 可以省略
情景一

情景二通过资源来引用另一个资源
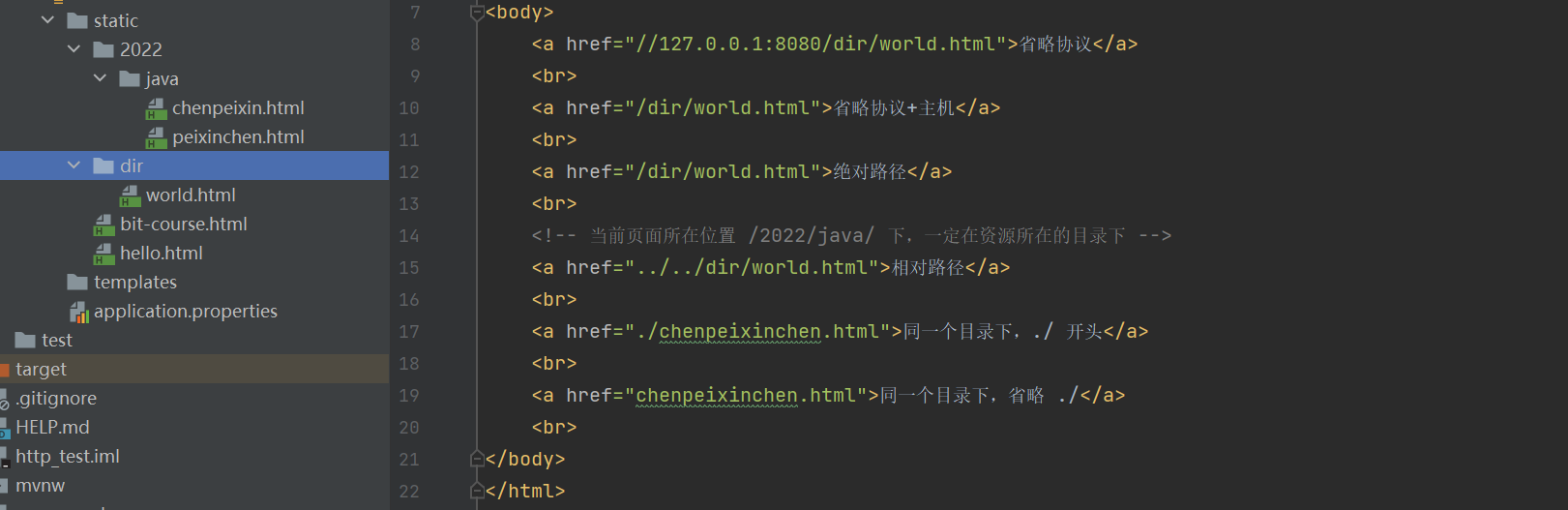
- /dir/world.html表示的是绝对路径,以static为根目录
- ./chengoeixin.html相对路径,以当前文件所在的目录为根目录./表示就是当前文件目录java,…/表示当前文件目录的父级目录
URL内容的要求
- URL中的字符是有一定的要求,出现在URL中的字符必须在一个特定的集合中,比如汉字这种都有不允许出现在URL中的,但是如果想在URL中携带这些非标准的字符,就需要通过URL编码,将其转换为标准字符集

URL编码的大体规则

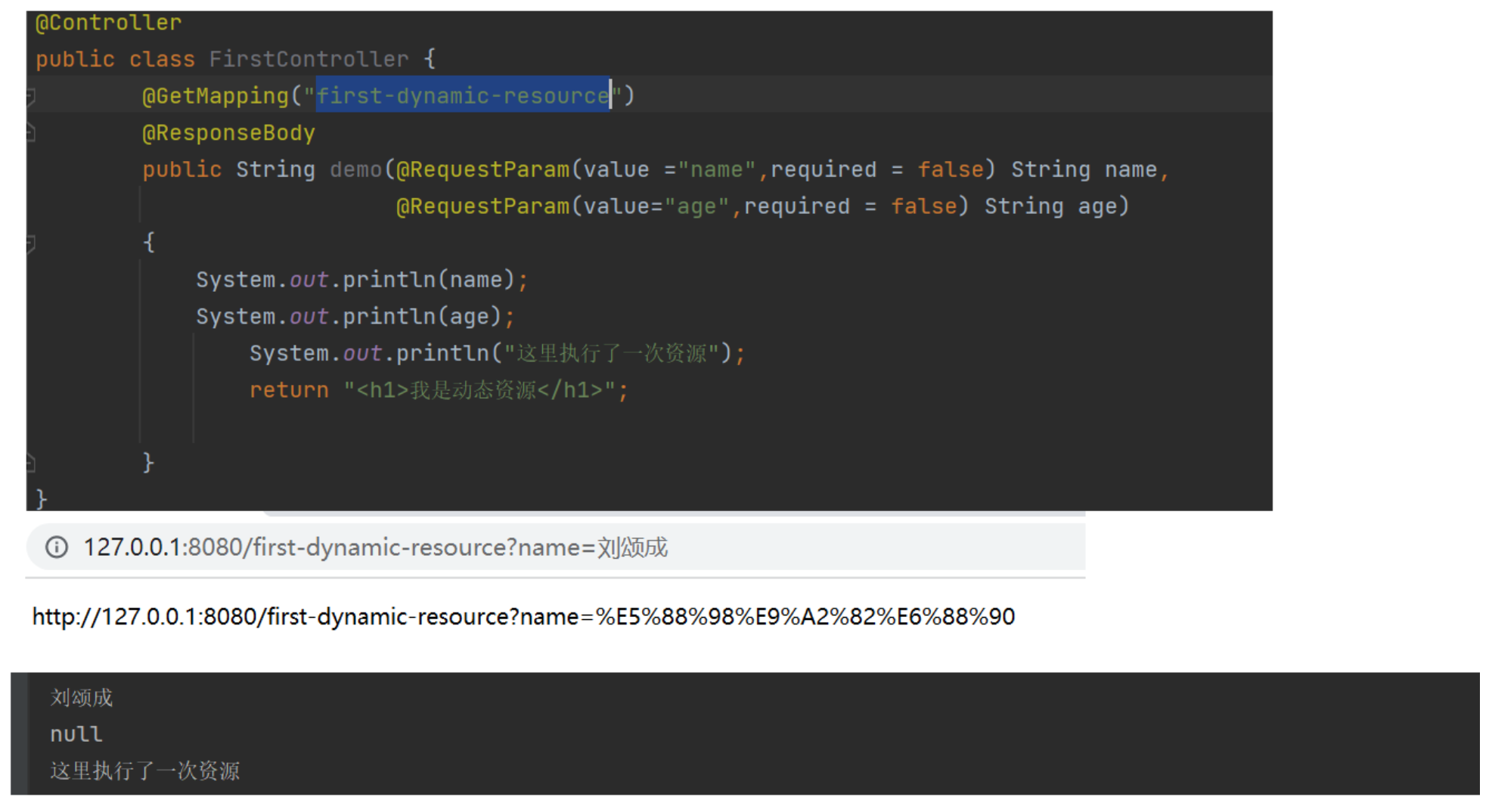
- 并且有些字符有着特定的用途,?# & /都有其标准的含义的
HTTP协议流程
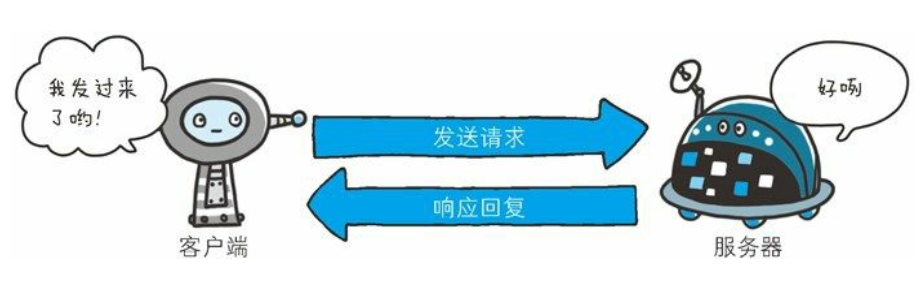
一次完整的HTTP分为
- 请求 客户端发起 服务器接收
- 响应 客户端接收 服务器发起
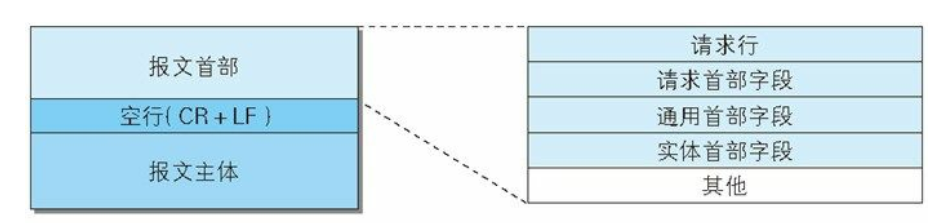
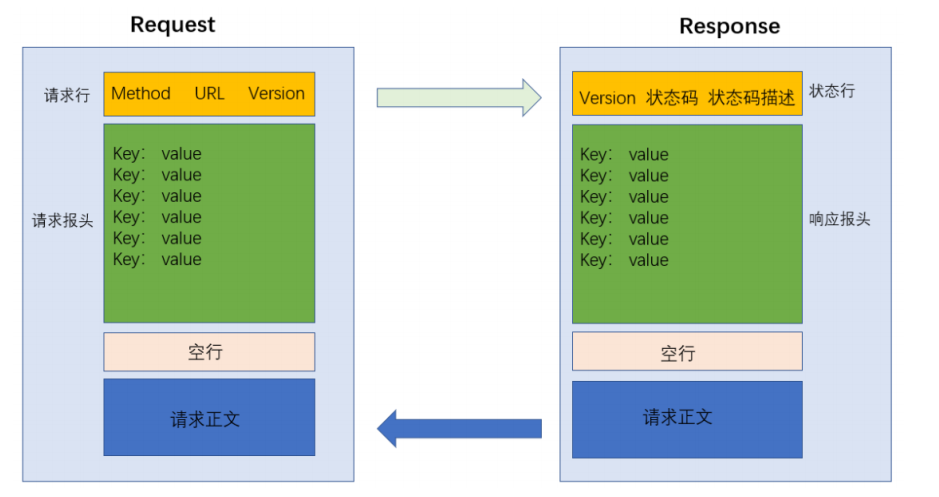
所以对应着两种格式:请求报文格式,响应报文格式
请求报文中携带的信息有哪些
从需求分析应该有哪些内容
- 当前对服务器想做什么(是想从服务器获取资源,还是上传资源等,用方法类型来标识)
- 访问的是那个web资源(URL来标识)
- 本次采用的是那个HTTP协议(请求行带有协议的版本号)
- 本次请求的一些描述信息(请求头)
- 如果本次是要提交信息给服务器,这些信息也得携带
报文主体和实体主体的差异
- 报文( message)是 HTTP 通信中的基本单位, 由 8 位组字节流(octet sequence,其中 octet 为 8 个比特) 组成, 通过 HTTP 通信传输。
- 实体( entity)作为请求或响应的有效载荷数据(补充项) 被传输, 其内容由实体首部和实体主体组成。
- HTTP 报文的主体用于传输请求或响应的实体主体。
- 通常, 报文主体等于实体主体。 只有当传输中进行编码操作时, 实体主体的内容发生变化, 才导致它和报文主体产生差异。
例子
当涉及到编码时,此时我们的实体主体应该是
This is the data in the first chunk and this is the second one consequence而报文主体则为
25 This is the data in the first chunk 1C and this is the second one 3 con 8 sequence那么此时,报文主体和此时的实体主体就变得不一致了。
- 报文和实体这两个术语在之后会经常出现, 请事先理解两者的差异。
例子

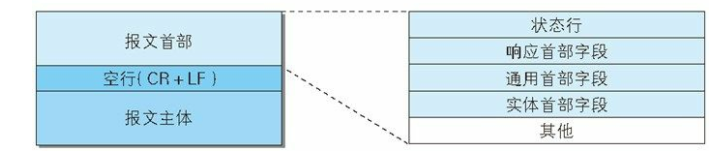
响应报文携带的信息有哪些
- 本次响应的协议类型(响应行带有版本号)
- 本次响应的结果和对应的描述(响应行带有状态)
- 本次响应的一些描述信息(响应头)
- 返回给请求方的资源(响应体)
例子
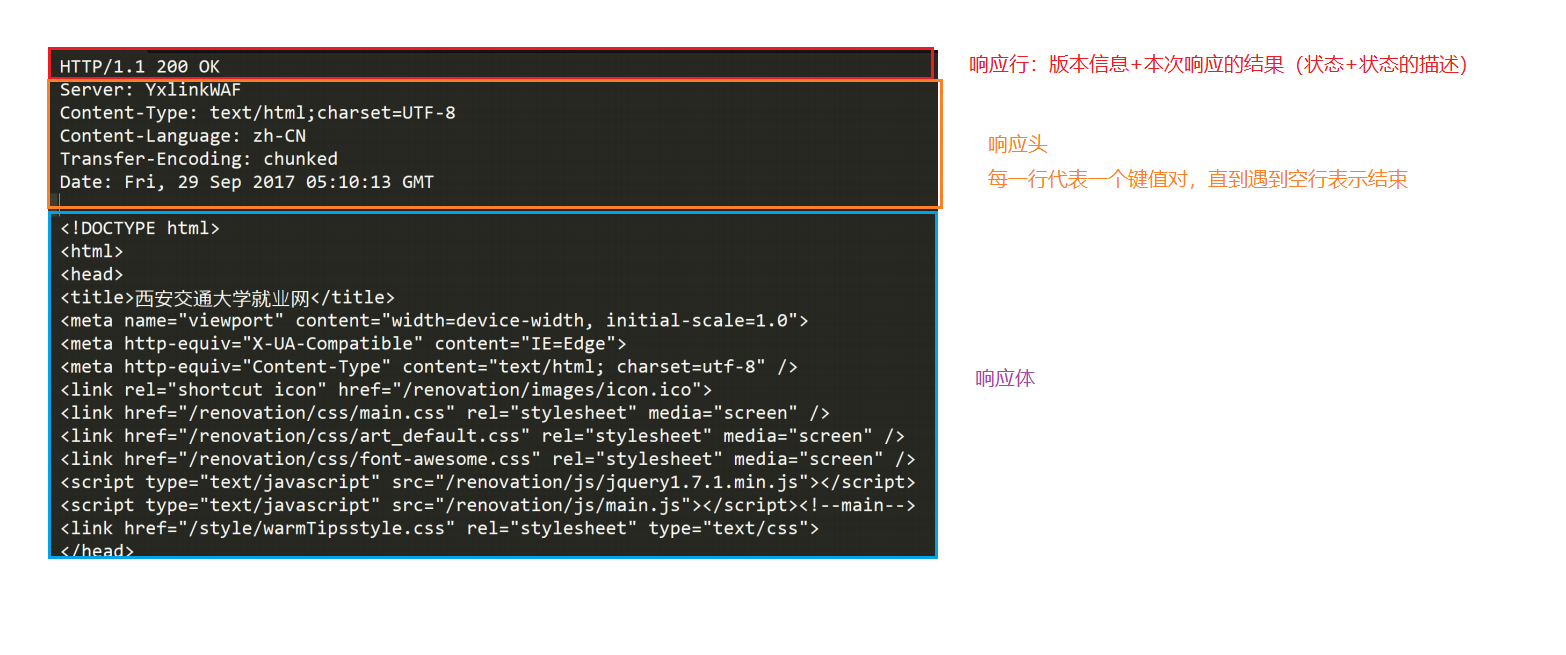
 (
(
为什么 HTTP 报文中要存在 “空行”?
- 因为 HTTP 协议并没有规定报头部分的键值对有多少个. 空行就相当于是 “报头的结束标记”, 或者 是 “报头和正文之间的分隔符”.
- HTTP 在传输层依赖 TCP 协议, TCP 是面向字节流的. 如果没有这个空行, 就会出现 “粘包问题”.
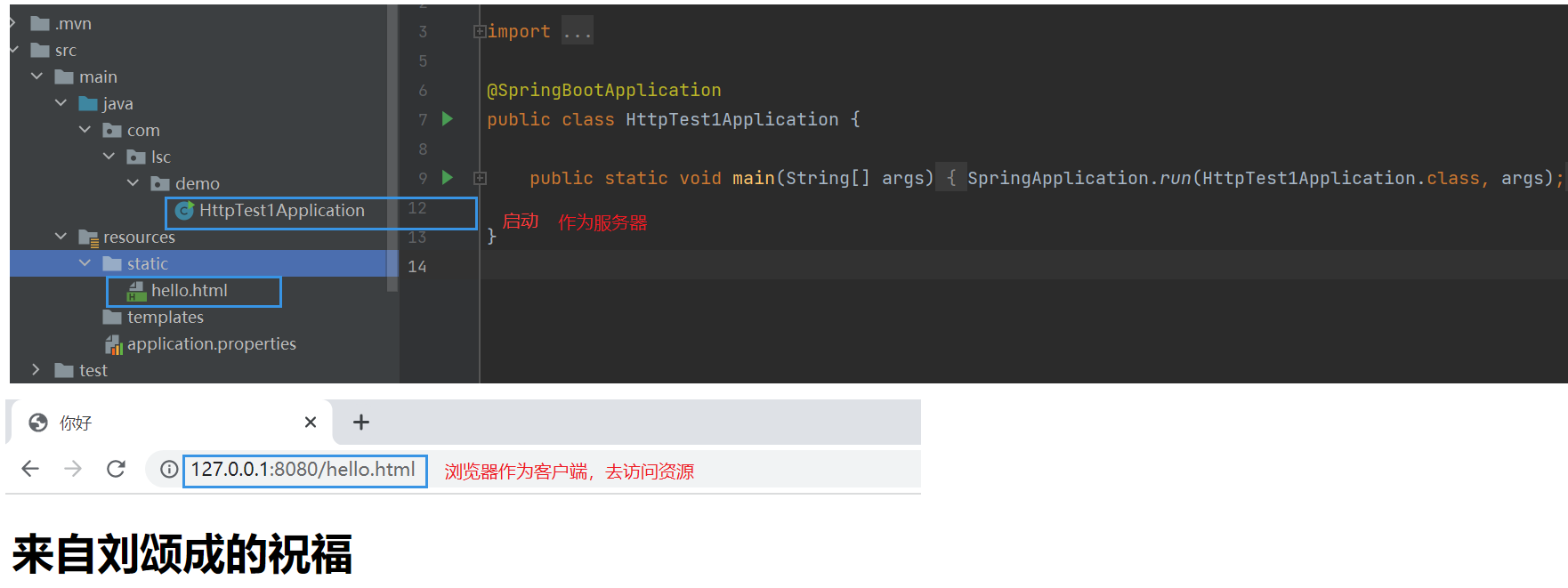
模拟一个HTTP
 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-59PNlaad-1681456831779)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-59PNlaad-1681456831779)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]
如何写一个HTTP客户端

自己写的HTTP请求——模拟HTTP客户端
package com.lsc.demo;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.Socket;
import java.net.UnknownHostException;
import java.nio.charset.StandardCharsets;
import java.util.Scanner;
public class MyHttpClient {
public static void main(String[] args) throws Exception {
// 只能进行一次请求-响应的 HTTP 客户端
// 主机 127.0.0.1
// 端口(进程) 8080
// 资源路径 /hello.html
try (Socket socket = new Socket("127.0.0.1", 8080)) {
// 准备 HTTP 请求内容
// 文本 String
// 格式:请求行
String requestLine = "GET /hello.html HTTP/1.0\r\n";
// 请求头:完全可以没有,但必须一个空行结尾
String requestHeader1 = "Name: LSC\r\n\r\n"; // 请求头中共有 1对 key-value
String requestHeader2 = "Name: LSC\r\nAge: 1993\r\n\r\n"; // 请求头中共有 2对 key-value
String requestHeader3 = "\r\n"; // 请求头中共有 0 对 key-value
// 请求体,GET 是没有请求体
// 最终的请求 —— 要发送给服务器的东西
String request = requestLine + requestHeader3;
// 发送服务器的过程
byte[] requestBytes = request.getBytes("ISO-8859-1"); // 字符集编码
// 发送(数据会经由 TCP、IP、以太网发送给服务器)
OutputStream os = socket.getOutputStream();
os.write(requestBytes);
os.flush();
// 请求既然已经发送,我们要做的就是等待响应
InputStream is = socket.getInputStream();
Scanner scanner = new Scanner(is, "UTF-8"); // 响应的前面字符集应该是 ISO-8859-1,后边是 UTF-8
while (scanner.hasNextLine()) {
String line = scanner.nextLine();
System.out.println(line);
}
}
}
}
自己模拟的HTTP服务器
package com.lsc.demo;
import java.io.IOException;
import java.io.OutputStream;
import java.net.ServerSocket;
import java.net.Socket;
import java.nio.charset.StandardCharsets;
public class MyHttpServer {
public static void main(String[] args) throws IOException {
try (ServerSocket serverSocket=new ServerSocket(8080)){
while (true){
Socket socket=serverSocket.accept();//三次握手建立结束
// 读取用户的请求 这里就不具体读了,一律采用相同的方式回应
//发送响应 响应体 资源内容
// Content-Type: 浏览器应该按照什么格式来看到我们响应的资源内容的(资源内容放在响应体中)
//响应体的资源
String responseBody="<h1>Welcome MyHttpServer</h1>";
byte[] responseBodyBytes=responseBody.getBytes(StandardCharsets.UTF_8);
int contentLength=responseBody.length();
String response="HTTP/1.0 200 OK \r\n"
+"Sever: lsc\r\n"
+"ContentType: text/html; charset=utf-8\r\n"
+"ContentLength:"+contentLength+"\r\n"
+"\r\n";
byte[] responseBytes=response.getBytes("ISO-8859-1");
OutputStream os=socket.getOutputStream();
os.write(responseBytes);
os.write(responseBodyBytes);
os.flush();
//发送完毕之后,直接关闭TCP连接
socket.close();
}
}
}
}
我们自己写的服务器的信息
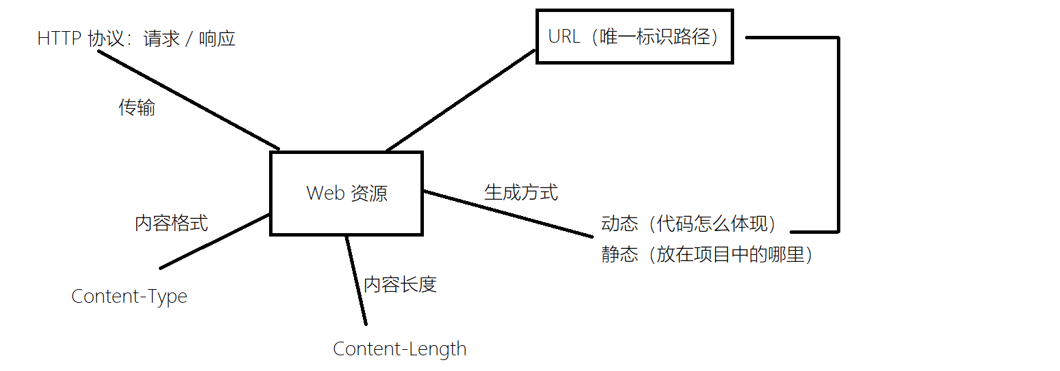
- 首先我们每次传输资源对应的是一个web资源
- 我们请求报头和回应报头
- web资源的生成方式有两种 一种是动态资源,一种是静态资源
- 我们在浏览器通过URL这个唯一标识符来找到我们的对应的资源
HTTP方法
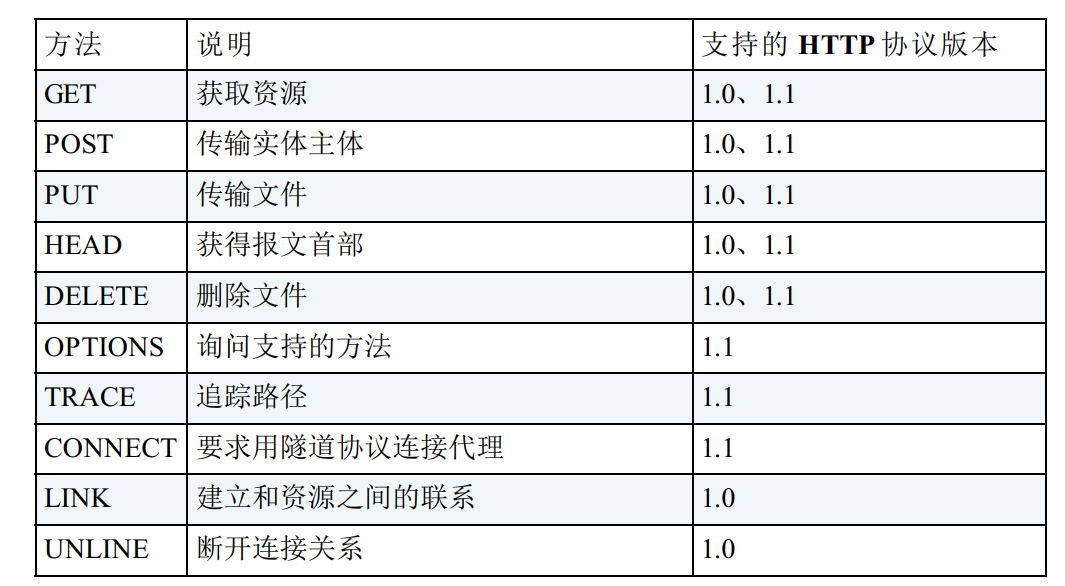
-
什么方式能够激发GET方法
- 我们在浏览器直接输入URL访问,都是GET方法,
- 另外, HTML 中的 link, img, script 等标签, 也会触发 GET 请求,浏览器会自动发起对资源的请求,不需要用户介入
<a herf="">,需要用户点击之后,才会发起新的资源请求
-
POST,不借助第三方的工具的情况下,只有两种方法可以做到
- ajax
- 表单
Get方法
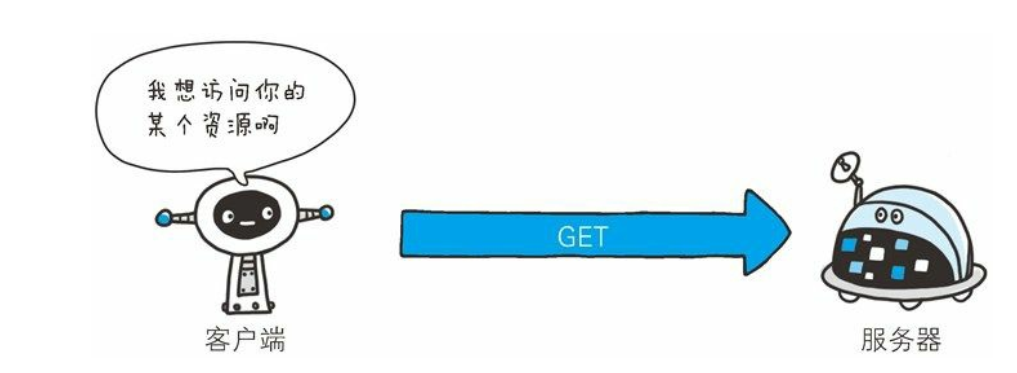
- GET 方法用来请求访问已被 URI 识别的资源。 指定的资源经服务器端解析后返回响应内容。 也就是说, 如果请求的资源是文本, 那就保持原样返回; 如果是像 CGI(Common Gateway Interface, 通用网关接口) 那样的程序, 则返回经过执行后的输出结果
- 我的理解,比如我们的SpringMVC模式,我们访问的资源是静态资源,那么就直接返回,但是如果我们访问的是动态资源,那么返回也就是我们对应Java代码的执行结果,可以是JSON格式,
标签的默认的GET方法
img标签的自动请求

a标签的点击之后请求
POST方法
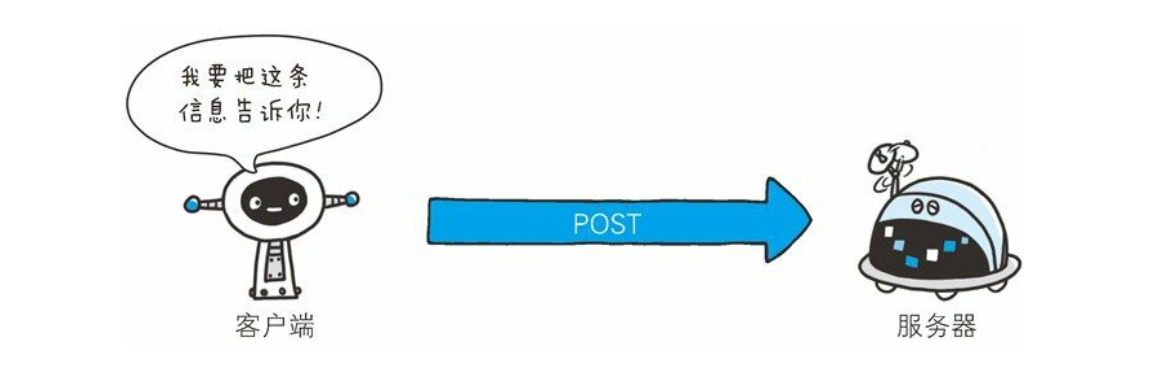
- 虽然用 GET 方法也可以传输实体的主体, 但一般不用 GET 方法进行传输, 而是用 POST 方法。 虽说 POST 的功能与 GET 很相似, 但POST 的主要目的并不是获取响应的主体内容
- GET方法通过将信息放在我们query String中进行传输
POST的两种做法(不借助第三方工具)
- 利用
<from>表单<form method="post">,from表单的提交浏览器会使用post方法,如果默认不写,就是GET - 使用JS发起HTTP请求(一般称为ajax)
使用JavaScripts来发起请求 (ajax)
//1实例化一个XMLHttpRequest对象
var xhr=new XMLHttpRequest()
//2调用对象的open方法, 设置发送请求的方法 资源路径
//xhr.open('get','/demo')
xhr.open('post,'/demo')
//设置回调函数,当/demo资源响应返回的时候,应该干什么
//提供事件绑定机制
//事件:load事件(当响应返回的时候)
//事件处理 回调函数
xhr.onload=function(){
console.log(xhr.status)//打印响应的状态 成功是200
console.log(xhr.responseText)//打印响应的响应体
//还有其他东西,现在不关心
}
//4真正的发送请求出去
xhr.send()
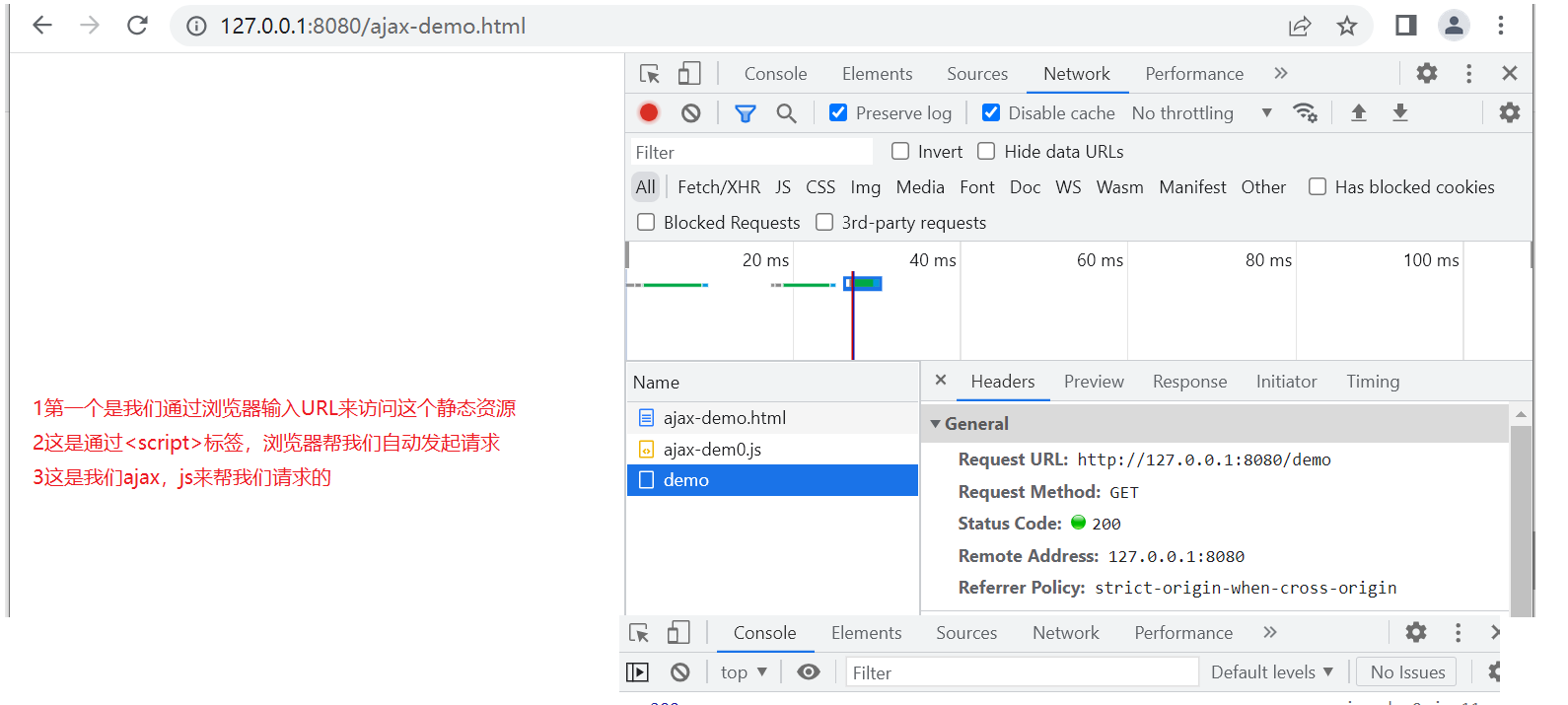
执行顺序
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0QfdCRXG-1681456831784)(C:\Users\lsc07\Desktop\学习资料\19typora笔记\5计算机网络\HTTP.assets\0613d54e02d24764809af7a55f517522.png)]
- 这里我们写的AJAX请求是通过原生的JS写的,在实际开发中,会通过框架如Axios的帮助进行发送请求
关于form表单发起POST
PUT方法
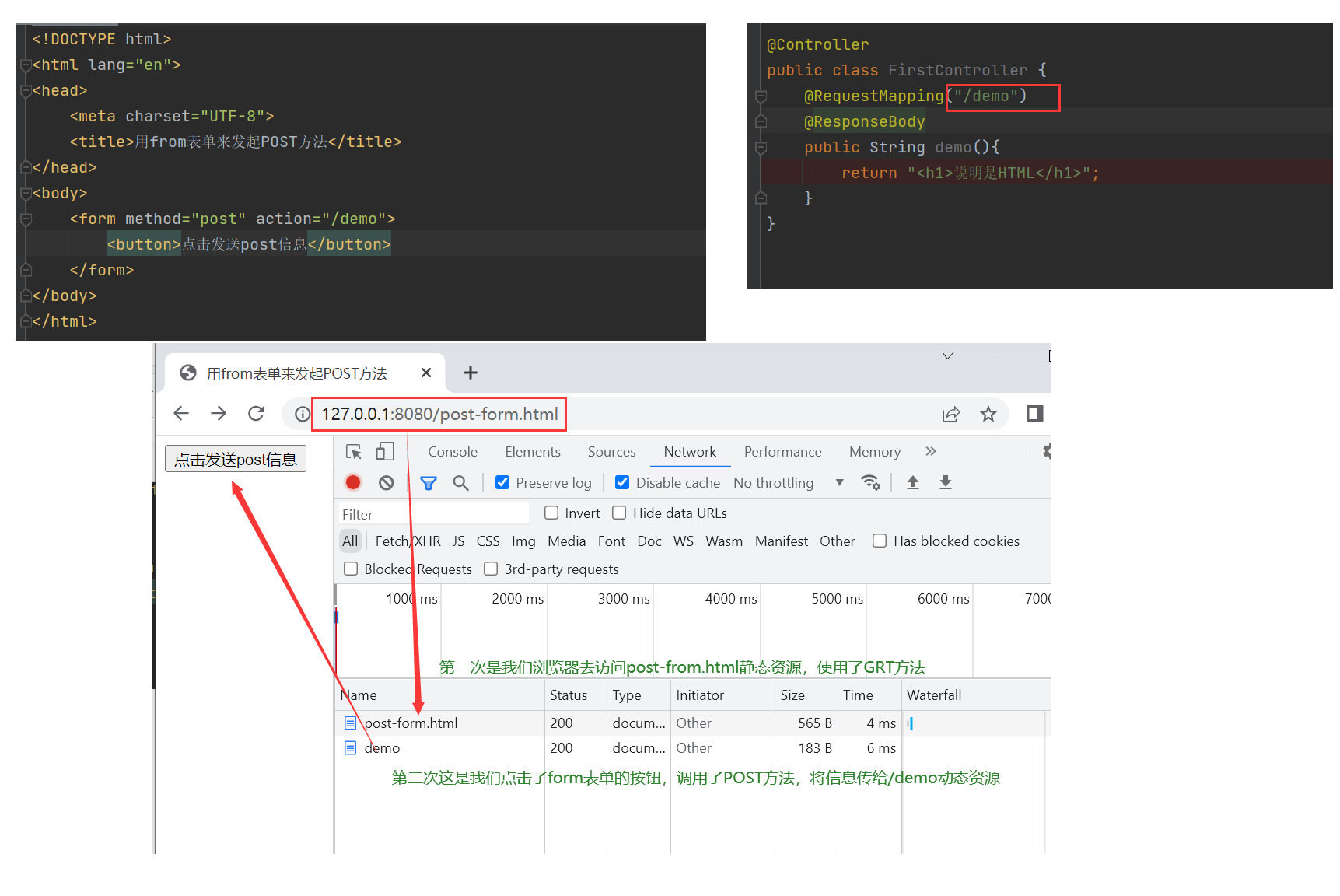
- PUT 方法用来传输文件。 就像 FTP 协议的文件上传一样, 要求在请求报文的主体中包含文件内容, 然后保存到请求 URI 指定的位置。
- 鉴于 HTTP/1.1 的 PUT 方法自身不带验证机制, 任何人都可以上传文件 , 存在安全性问题, 因此一般的 Web 网站不使用该方法。
- 若配合 Web 应用程序的验证机制, 或架构设计采用REST(REpresentational State Transfer, 表征状态转移) 标准的同类Web 网站, 就可能会开放使用 PUT 方法。
HEAD方法
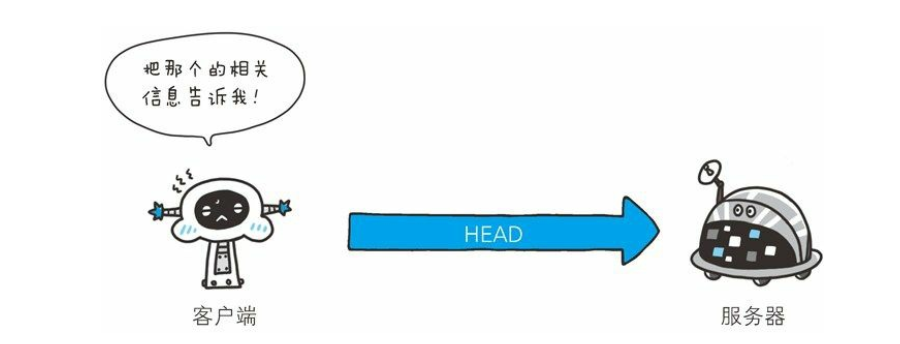
- HEAD 方法和 GET 方法一样, 只是不返回报文主体部分。 用于确认URI 的有效性及资源更新的日期时间等
DELETE 方法

-
DELETE 方法用来删除文件, 是与 PUT 相反的方法。
-
DELETE 方法按请求 URI 删除指定的资源。
-
HTTP/1.1 的 DELETE 方法本身和 PUT 方法一样不带验证机制, 所以一般的 Web 网站也不使用 DELETE 方法。 当配合 Web 应用程序的验证机制, 或遵守 REST 标准时还是有可能会开放使用的。
OPTIONS方法
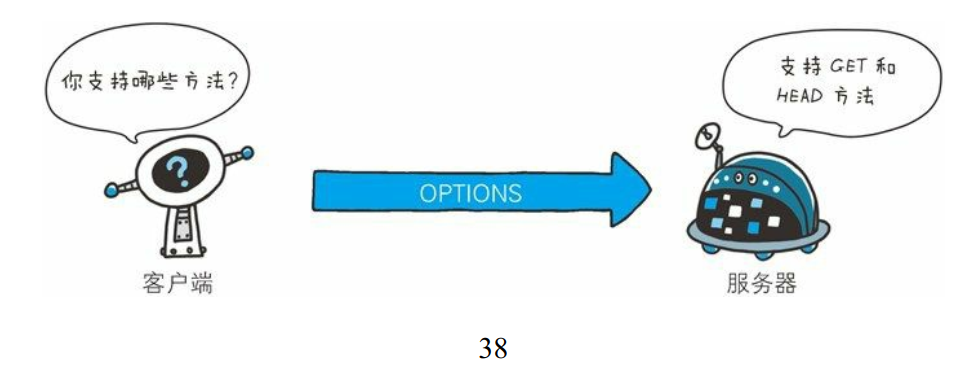
- OPTIONS 方法用来查询针对请求 URI 指定的资源支持的方法。
TRACE 方法
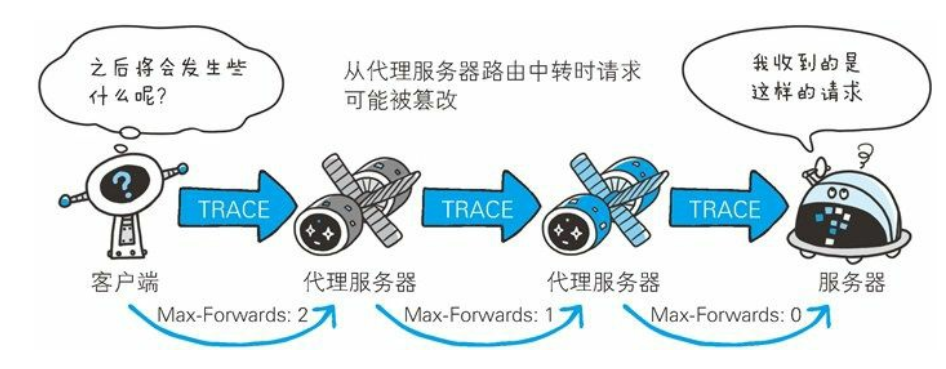
TRACE 方法是让 Web 服务器端将之前的请求通信环回给客户端的方法。
- 发送请求时, 在 Max-Forwards 首部字段中填入数值, 每经过一个服务器端就将该数字减 1, 当数值刚好减到 0 时, 就停止继续传输, 最后接收到请求的服务器端则返回状态码 200 OK 的响应。
- 客户端通过 TRACE 方法可以查询发送出去的请求是怎样被加工修改/ 篡改的。 这是因为, 请求想要连接到源目标服务器可能会通过代理中转, TRACE 方法就是用来确认连接过程中发生的一系列操作。
- 但是, TRACE 方法本来就不怎么常用, 再加上它容易引发XST(Cross-Site Tracing, 跨站追踪) 攻击, 通常就更不会用到了
CONNECT方法
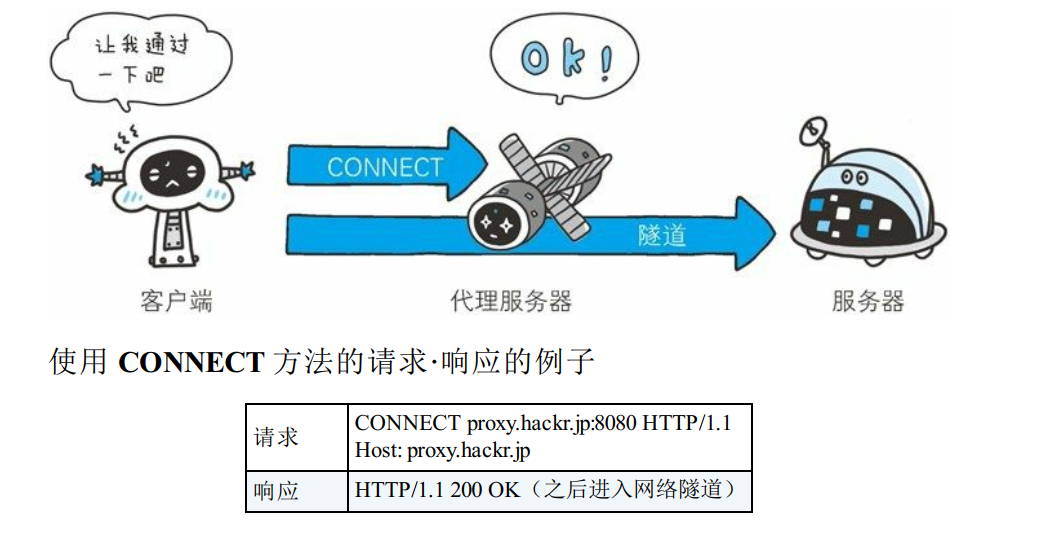
- CONNECT 方法要求在与代理服务器通信时建立隧道, 实现用隧道协议进行 TCP 通信。 主要使用 SSL(Secure Sockets Layer, 安全套接层) 和 TLS(Transport Layer Security, 传输层安全) 协议把通信内容加密后经网络隧道传输。
面试题 GET VS POST
- 两个方法表示的语义不同,GET表示的是获取,POST表示的是发布
-
对比成sql语句去理解
- GET理解成我们对Web资源进行SELECT的操作
- POST对比成对Web资源进行INSERT的操作
- PUT理解成对Web资源进行UPDATE的操作
- DELETE理解成对Web资源进行DELETE的操作
-
这种理解方式其实也就是我们俗称的RESTful的理解形式
-
REST:Representational State Transfer,表现层资源状态转移
- RESTFUL是一种网络应用程序的设计风格和开发方式,基于HTTP,可以使用 XML 格式定义或 JSON 格式定义。最常用的数据格式是JSON。由于JSON能直接被JavaScript读取,所以,使用JSON格式的REST风格的API具有简单、易读、易用的特点。
- REST 是面向资源的,每个资源都有一个唯一的资源定位符(URI)。每个URI代表一种资源(resource),所以URI中不能有动词,只能有名词,而且所用的名词往往与数据库的表名对应。一般来说,数据库中的表都是同种记录的"集合"(collection),所以URI中的名词也应该使用复数。
RESTful的实现
具体说,就是 HTTP 协议里面,四个表示操作方式的动词:GET、POST、PUT、DELETE。它们分别对应四种基本操作:GET 用来获取资源,POST 用来新建资源,PUT 用来更新资源,DELETE用来删除资源。
REST 风格提倡 URL 地址使用统一的风格设计,从前到后各个单词使用斜杠分开,不使用问号键值对方式携带请求参数,而是将要发送给服务器的数据作为 URL 地址的一部分,以保证整体风格的一致性。
操作 传统方式 REST风格
查询操作 getUserById?id=1 user/1–>get请求方式
保存操作 saveUser user–>post请求方式
删除操作 deleteUser?id=1 user/1–>delete请求方式
更新操作 updateUser user–>put请求方式
没有RESTful之前的用法
http://127.0.0.1/user/query/1 GET 根据用户id查询用户数据
http://127.0.0.1/user/save POST 新增用户
http://127.0.0.1/user/update POST 修改用户信息
http://127.0.0.1/user/delete/1 GET/POST 删除用户信息RESTful用法:
http://127.0.0.1/user/1 GET 根据用户id查询用户数据
http://127.0.0.1/user POST 新增用户
http://127.0.0.1/user PUT 修改用户信息
http://127.0.0.1/user/1 DELETE 删除用户信息
- 之前的操作有什么问题呢?你每次请求的接口或者地址,都在做描述,例如查询的时候用了query,新增的时候用了save,其实完全没有这个必要,我使用了get请求,就是查询.使用post请求,就是新增的请求,我的意图很明显,完全没有必要做描述,这就是为什么有了restful.
- 表现现象不同,GET应该具有幂等性的,并且无副作用,POST应该不具备幂等性,并且有副作用,具有幂等性且无副作用的HTTP请求的资源是可以被缓存的
- 根据GET的语义,是具有幂等性,并且无副作用
- 对比成我们的select语句,我们每次用GET方法去访问资源,不会造成资源的改变,这种特性也就是无副作用
- 如果环境不改变,我们每次去访问资源都是一样的,这种效果就被称为幂等性
- 对比POST,它不具有幂等性,且有副作用
- 我们第一次去插入一条id为3的数据,第一次能成功,id是唯一的,第二次就成功不了
- 我们执行操作,改变了表的结构,所以是具有副作用的
- 当无副作用的时候,肯定幂等,当不幂等的时候,肯定有副作用
- 根据GET的语义,是具有幂等性,并且无副作用

- GET请求不允许有HTTP请求体,但是POST方法请求允许有请求体(不是必须有)
- 类比SELECT,原则上认为没有任何数据要携带,所以并没有请全体,但是我们的SELECT请求语句具有where条件,把这些数据称为查询字符串——URL中的query string
- POST稍微比GET安全一点点,对于GET数据放在URL中很容易被看到,POST放在了请求体中(两者都是不安全的),GET是通过query string中不论携带什么数据,总体上必须满足key=value的形式,但是POST非常灵活
HTTP与Web服务器
用单台虚拟主机实现多个域名
- HTTP/1.1 规范允许一台 HTTP 服务器搭建多个 Web 站点。 比如, 提供 Web 托管服务(Web Hosting Service) 的供应商, 可以用一台服务器为多位客户服务, 也可以以每位客户持有的域名运行各自不同的网站。 这是因为利用了虚拟主机(Virtual Host, 又称虚拟服务器) 的功能。
- 即使物理层面只有一台服务器, 但只要使用虚拟主机的功能, 则可以假想已具有多台服务器。
客户端使用 HTTP 协议访问服务器时, 会经常采用类似 www.hackr.jp这样的主机名和域名。
- 在互联网上, 域名通过 DNS 服务映射到 IP 地址(域名解析) 之后访问目标网站。 可见, 当请求发送到服务器时, 已经是以 IP 地址形式访问了。
- 所以, 如果一台服务器内托管了 www.tricorder.jp 和 www.hackr.jp 这两个域名, 当收到请求时就需要弄清楚究竟要访问哪个域名。
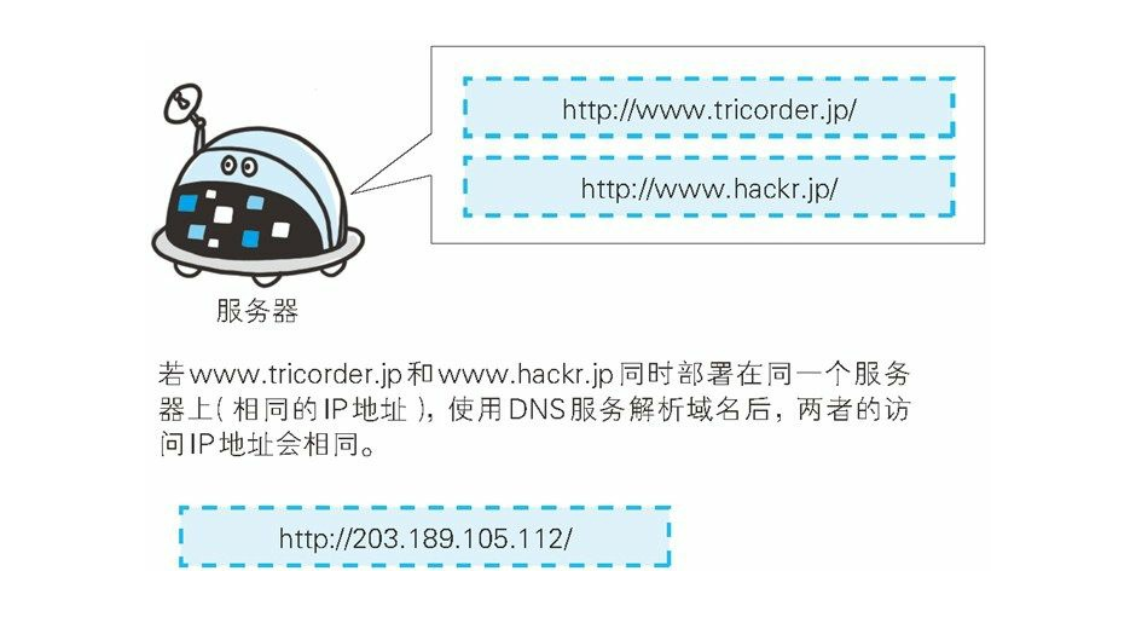
在相同的 IP 地址下, 由于虚拟主机可以寄存多个不同主机名和域名的 Web 网站, 因此在发送 HTTP 请求时, 必须在 Host 首部内完整指定主机名或域名的 URI。
通信数据转发程序 : 代理、 网关、 隧道
HTTP 通信时, 除客户端和服务器以外, 还有一些用于通信数据转发的应用程序, 例如代理、 网关和隧道。 它们可以配合服务器工作。
这些应用程序和服务器可以将请求转发给通信线路上的下一站服务器, 并且能接收从那台服务器发送的响应再转发给客户端。
代理
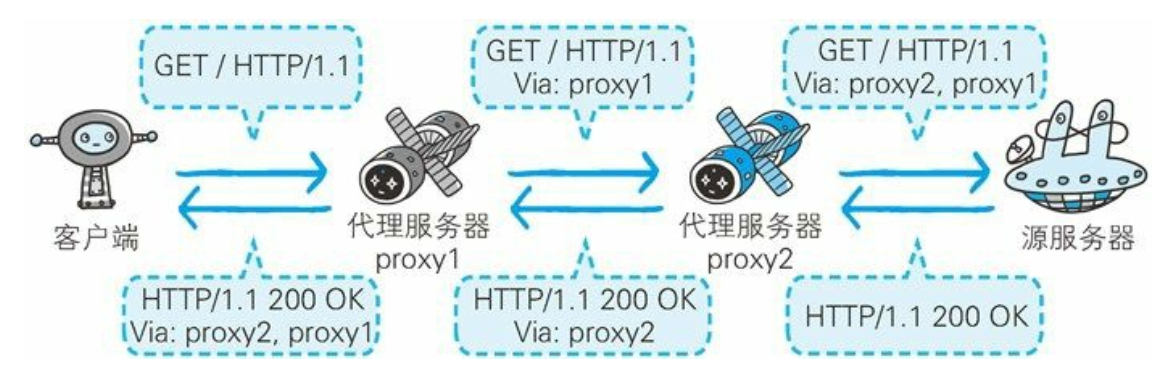
- 代理是一种有转发功能的应用程序, 它扮演了位于服务器和客户端“中间人”的角色, 接收由客户端发送的请求并转发给服务器, 同时也接收服务器返回的响应并转发给客户端。
- 在 HTTP 通信过程中, 可级联多台代理服务器。 请求和响应的转发会经过数台类似锁链一样连接起来的代理服务器。 转发时, 需要附加Via 首部字段以标记出经过的主机信息。
代理有多种使用方法, 按两种基准分类。 一种是是否使用缓存, 另一种是是否会修改报文。
缓存代理
- 代理转发响应时, 缓存代理(Caching Proxy) 会预先将资源的副本(缓存) 保存在代理服务器上。当代理再次接收到对相同资源的请求时, 就可以不从源服务器那里获取资源, 而是将之前缓存的资源作为响应返回。
透明代理
- 转发请求或响应时, 不对报文做任何加工的代理类型被称为透明代理(Transparent Proxy) 。 反之, 对报文内容进行加工的代理被称为非透明代理。
为什么使用代理
使用代理服务器的理由有: 利用缓存技术减少网络带宽的流量, 组织内部针对特定网站的访问控制, 以获取访问日志为主要目的, 等等。
网关
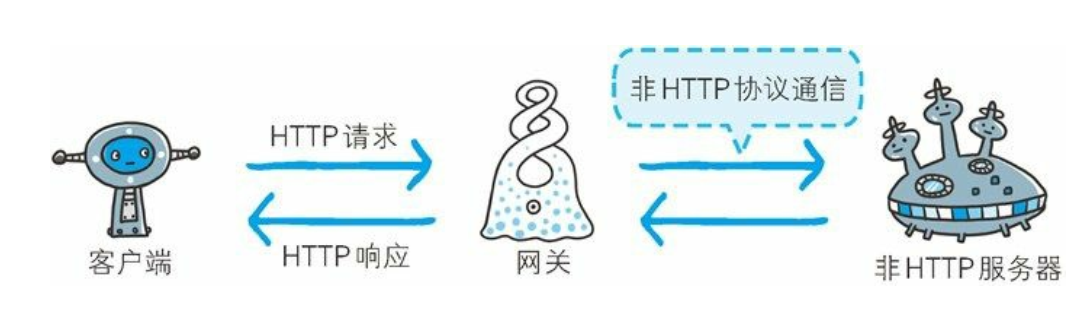
网关是转发其他服务器通信数据的服务器, 接收从客户端发送来的请求时, 它就像自己拥有资源的源服务器一样对请求进行处理。 有时客户端可能都不会察觉, 自己的通信目标是一个网关。
网关能使通信线路上的服务器提供非 HTTP 协议服务。利用网关能提高通信的安全性, 因为可以在客户端与网关之间的通信线路上加密以确保连接的安全。 比如, 网关可以连接数据库, 使用SQL语句查询数据。 另外, 在 Web 购物网站上进行信用卡结算时,网关可以和信用卡结算系统联动。
隧道
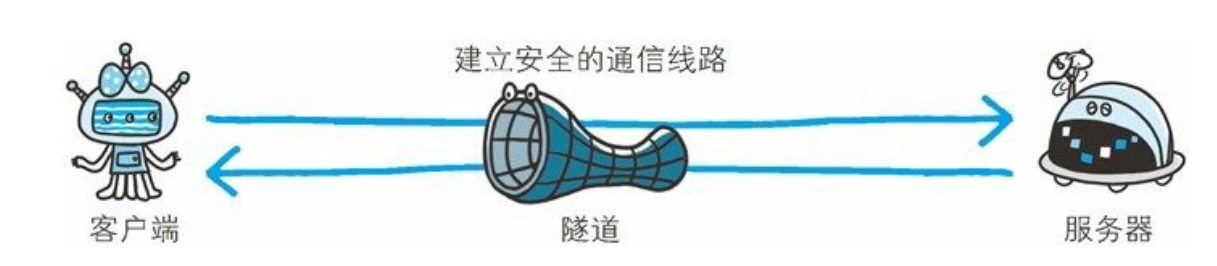
-
隧道可按要求建立起一条与其他服务器的通信线路, 届时使用 SSL等加密手段进行通信。 隧道的目的是确保客户端能与服务器进行安全的通信。
-
隧道本身不会去解析 HTTP 请求。 也就是说, 请求保持原样中转给之后的服务器。 隧道会在通信双方断开连接时结束。
-
隧道是在相隔甚远的客户端和服务器两者之间进行中转, 并保持双方通信连接的应用程序。
缓存技术
- 缓存是指代理服务器或客户端本地磁盘内保存的资源副本。 利用缓存可减少对源服务器的访问, 因此也就节省了通信流量和通信时间。缓存服务器是代理服务器的一种, 并归类在缓存代理类型中。 换句话说, 当代理转发从服务器返回的响应时, 代理服务器将会保存一份资源的副本。
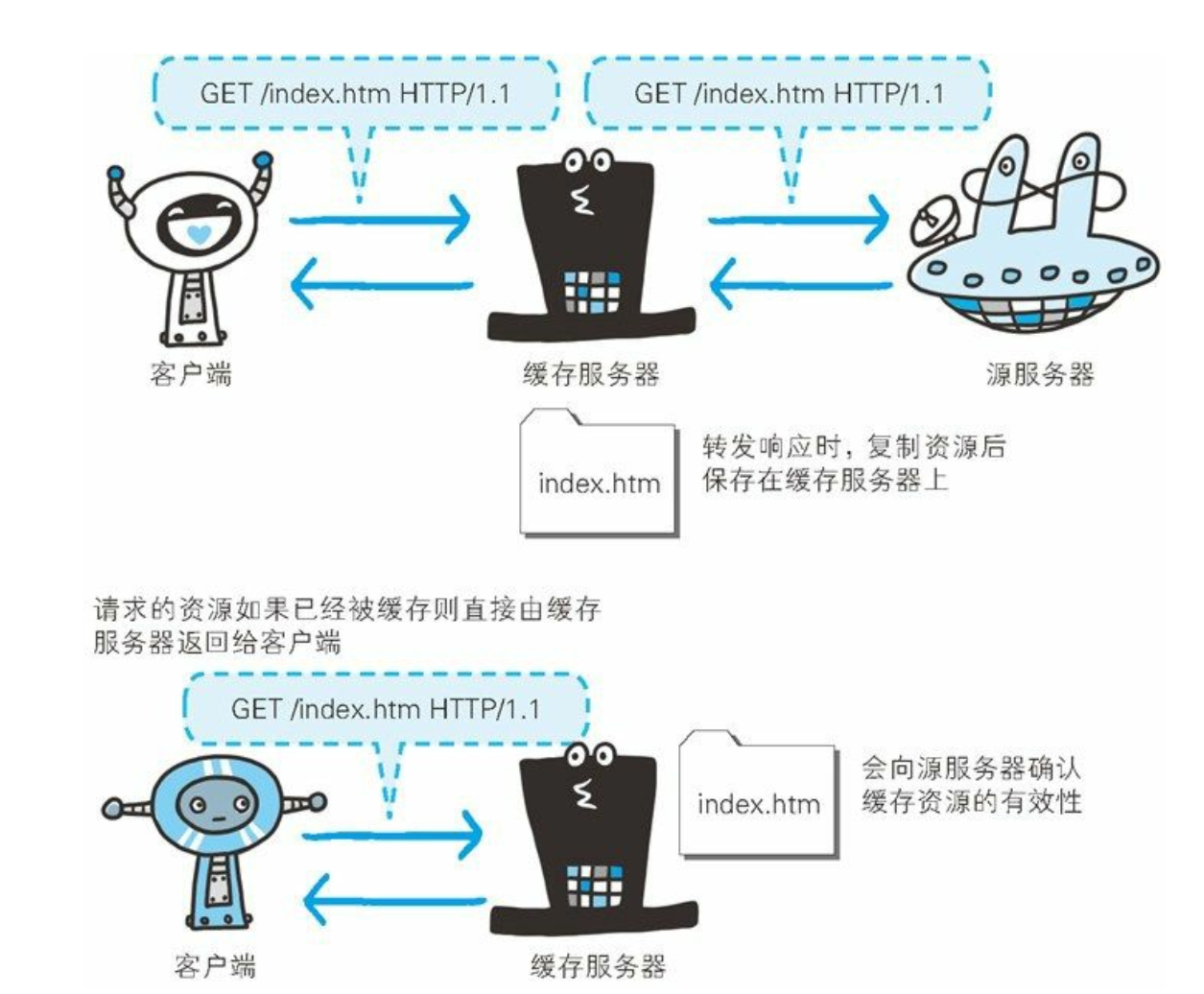
缓存服务器的优势在于利用缓存可避免多次从源服务器转发资源。 因此客户端可就近从缓存服务器上获取资源, 而源服务器也不必多次处理相同的请求了。
缓存的有效期限
- 即便缓存服务器内有缓存, 也不能保证每次都会返回对同资源的请求。 因为这关系到被缓存资源的有效性问题。
- 当遇上源服务器上的资源更新时, 如果还是使用不变的缓存, 那就会演变成返回更新前的“旧”资源了。
- 即使存在缓存, 也会因为客户端的要求、 缓存的有效期等因素, 向源服务器确认资源的有效性。 若判断缓存失效, 缓存服务器将会再次从源服务器上获取“新”资源。
客户端的缓存
- 缓存不仅可以存在于缓存服务器内, 还可以存在客户端浏览器中。 以Internet Explorer 程序为例, 把客户端缓存称为临时网络文件(Temporary Internet File) 浏览器缓存如果有效, 就不必再向服务器请求相同的资源了, 可以直接从本地磁盘内读取。另外, 和缓存服务器相同的一点是, 当判定缓存过期后, 会向源服务器确认资源的有效性。 若判断浏览器缓存失效, 浏览器会再次请求新资源。
构建 Web 内容的技术
- HTML(HyperText Markup Language, 超文本标记语言): 是为了发送Web 上的超文本(Hypertext) 而开发的标记语言。 超文本是一种文档系统, 可将文档中任意位置的信息与其他信息(文本或图片等) 建立关联, 即超链接文本。 标记语言是指通过在文档的某部分穿插特别的字符串标签, 用来修饰文档的语言。 我们把出现在 HTML文档内的这种特殊字符串叫做 HTML标签(Tag) 。平时我们浏览的 Web 页面几乎全是使用 HTML写成的。 由 HTML构成的文档经过浏览器的解析、 渲染后, 呈现出来的结果就是 Web 页面
- CSS (Cascading Style Sheets, 层叠样式表): 可以指定如何展现 HTML内的各种元素, 属于样式表标准之一。 即使是相同的 HTML文档,通过改变应用的 CSS, 用浏览器看到的页面外观也会随之改变。 CSS的理念就是让文档的结构和设计分离, 达到解耦的目的。
- JavaScripts:实现动态HTML,所谓动态 HTML(Dynamic HTML, 是指使用客户端脚本语言将静态的 HTML内容变成动态的技术的总称。 鼠标单击点开的新闻、
Google Maps 等可滚动的地图就用到了动态 HTML。动态 HTML技术是通过调用客户端脚本语言 JavaScript, 实现对HTML的 Web 页面的动态改造。 利用 DOM(Document ObjectModel, 文档对象模型) 可指定欲发生动态变化的 HTML元素 - Web 应用:指通过 Web 功能提供的应用程序 。 比如购物网站、 网上银行、 SNS、 BBS、 搜索引擎和 e-learning 等。 互联网(Internet) 或企业内网(Intranet) 上遍布各式各样的 Web 应用。原本应用 HTTP 协议的 Web 的机制就是对客户端发来的请求, 返回事前准备好的内容。 可随着 Web 越来越普及, 仅靠这样的做法已不足以应对所有的需求, 更需要引入由程序创建 HTML内容的做法。类似这种由程序创建的内容称为动态内容, 而事先准备好的内容称为静态内容。 Web 应用则作用于动态内容之上。
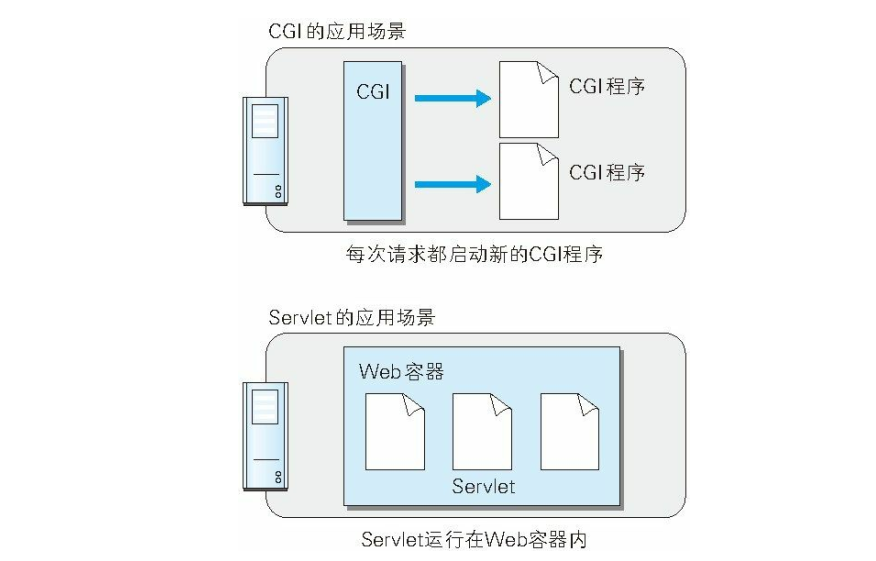
- CGI(Common Gateway Interface, 通用网关接口) 是指 Web 服务器在接收到客户端发送过来的请求后转发给程序的一组机制。 在 CGI 的作用下, 程序会对请求内容做出相应的动作, 比如创建 HTML等动态内容。使用 CGI 的程序叫做 CGI 程序, 通常是用 Perl、 PHP、 Ruby 和 C 等编程语言编写而成。 也就是将客户端的请求对应到具体的代码上
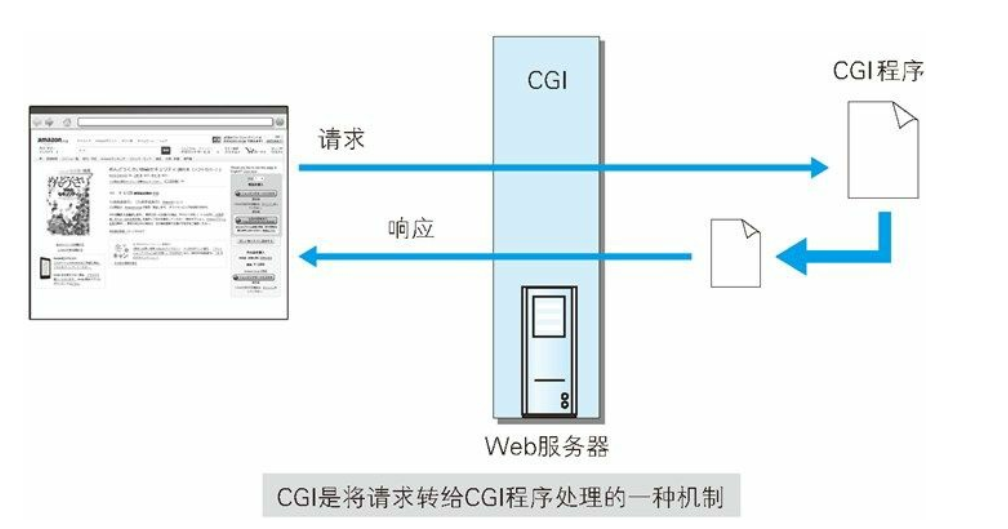
- Servlet是一种能在服务器上创建动态内容的程序。 Servlet 是用 Java语言实现的一个接口, 属于面向企业级 Java(JavaEE, JavaEnterprise Edition) 的一部分。之前提及的 CGI, 由于每次接到请求, 程序都要跟着启动一次。 因此一旦访问量过大, Web 服务器要承担相当大的负载。 而 Servlet 运行在与 Web 服务器相同的进程中, 因此受到的负载较小 2。 Servlet 的运行环境叫做 Web 容器或 Servlet 容器(比如我们的TomCat)。
- Servlet 常驻内存, 因此在每次请求时, 可启动相对进程级别更为轻量的
- 没有对应中文译名, 全称是 Java Servlet。 名称取自 Servlet=Server+Applet, 表示轻量服务程序。
- XML( eXtensible Markup Language, 可扩展标记语言) 是一种可按应用目标进行扩展的通用标记语言。 旨在通过使用 XML, 使互联网数据共享变得更容易。XML 和 HTML 都是从标准通用标记语言 SGML( Standard GeneralizedMarkup Language) 简化而成。 与 HTML 相比, 它对数据的记录方式做了特殊处理
- JSON(JavaScript Object Notation) 是一种以JavaScript(ECMAScript) 的对象表示法为基础的轻量级数据标记语言。 能够处理的数据类型有 false/null/true/ 对象 / 数组 / 数字 / 字符串, 这 7 种类型。JSON 让数据更轻更纯粹, 并且 JSON 的字符串形式可被 JavaScript轻易地读入。 当初配合 XML使用的 Ajax 技术也让 JSON 的应用变得更为广泛。 另外, 其他各种编程语言也提供丰富的库类, 以达到轻便操作 JSON 的目的。
状态码
仅记录在 RFC2616 上的 HTTP 状态码就达 40 种, 若再加上WebDAV(Web-based Distributed Authoring and Versioning, 基于万维网
的分布式创作和版本控制) (RFC4918、 5842) 和附加 HTTP 状态码(RFC6585) 等扩展, 数量就达 60 余种。 别看种类繁多, 实际上经
常使用的大概只有 14 种。 接下来, 我们就介绍一下这些具有代表性的 14 个状态码。
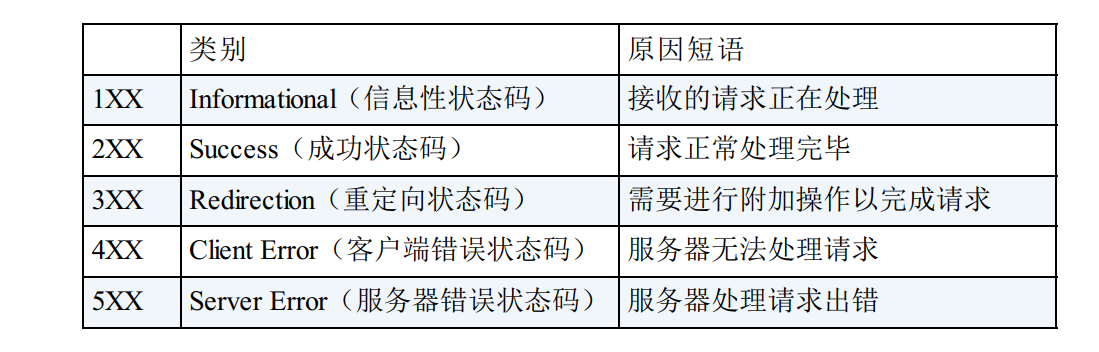
- 1xx表示处于一定的流程中,基本很少见到 HTTP->WebSocket
- 2xx表成功
- 3xx表示重定向/缓存等操作
- 4xx客户端导致的失败
- 5xx服务器导致的失败
2xx系列

200(成功)
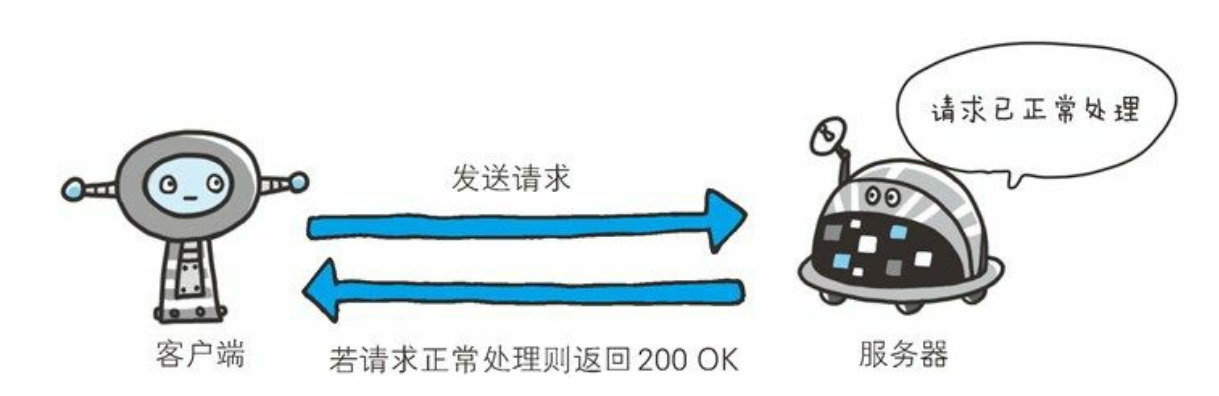
表示从客户端发来的请求在服务器端被正常处理了。在响应报文内, 随状态码一起返回的信息会因方法的不同而发生改变。 比如, 使用 GET 方法时, 对应请求资源的实体会作为响应返回; 而使用 HEAD 方法时, 对应请求资源的实体首部不随报文主体作为响应返回(即在响应中只返回首部, 不会返回实体的主体部分) 。
-
如何做到200
-
访问正确的资源路径
-
使用正确的方法
-
参数必须符合
-
204 No Content
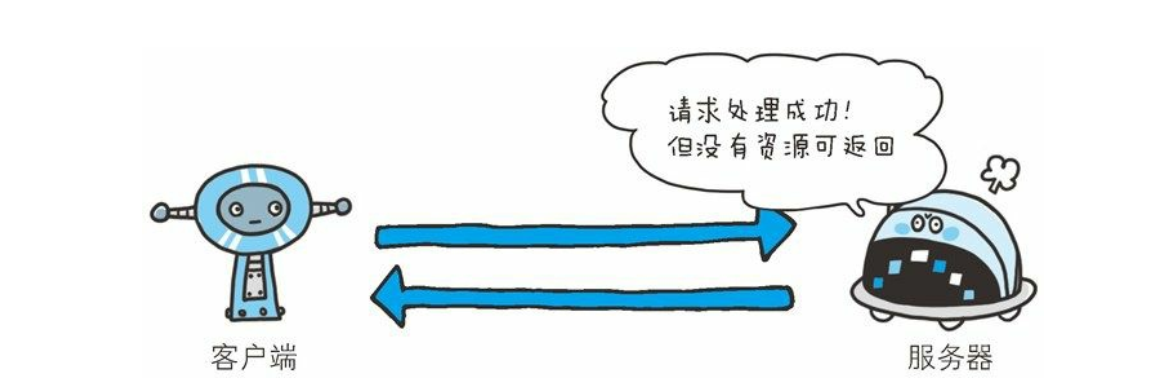
- 该状态码代表服务器接收的请求已成功处理, 但在返回的响应报文中不含实体的主体部分。 另外, 也不允许返回任何实体的主体。 比如,当从浏览器发出请求处理后, 返回 204 响应, 那么浏览器显示的页面不发生更新。
- 一般在只需要从客户端往服务器发送信息, 而对客户端不需要发送新信息内容的情况下使用。
比如

206 Partial Content
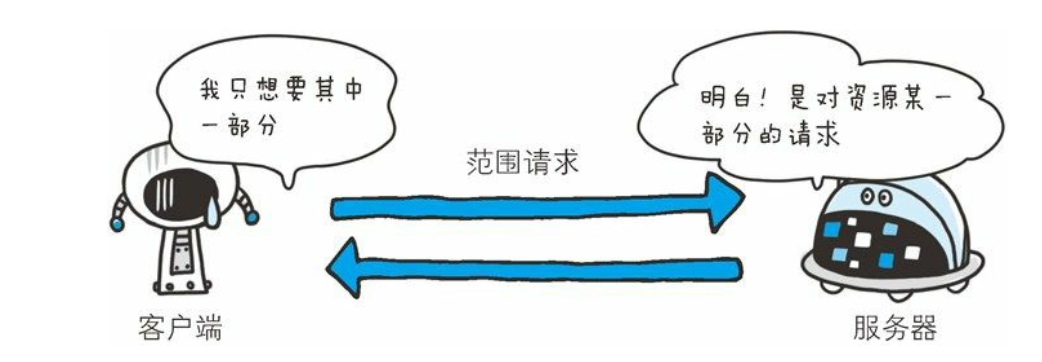
- 该状态码表示客户端进行了范围请求, 而服务器成功执行了这部分的GET 请求。
- 响应报文中包含由 Content-Range 指定范围的实体内容
3XX 重定向
比喻
- 我是客户端 书店老板是服务器
- 我去书店买书,买《石头记》 第一次请求
- 老板说石头记没有了,要我去买《红楼梦》 第一次响应——重定向
- 然后我在书店买红楼梦 第二次请求
- 我买到了红楼梦 第二次响应
站内和站外重定向
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tWFRFdlE-1681456831800)(C:\Users\lsc07\Desktop\学习资料\19typora笔记\5计算机网络\HTTP.assets\0f5bae79bf1a4021bbe3380639c56a22.png)][外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YHM9f82i-1681456831800)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]
永久重定向和临时重定向
- 永久重定向的意思就是我去买石头记,说石头记以后都没有,要买就买红楼梦了,永久重定向的状态码是301,用的非常少
- 临时重定向的意思,这几天没有了石头记,先买红楼梦,以后再买石头记就可以直接买302
永久重定向301
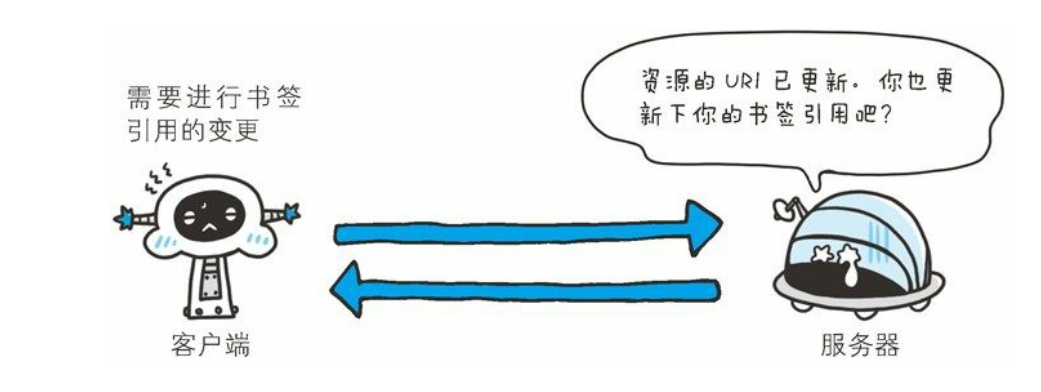
- 永久性重定向。 该状态码表示请求的资源已被分配了新的 URI, 以后应使用资源现在所指的 URI。 也就是说, 如果已经把资源对应的 URI保存为书签了, 这时应该按 Location 首部字段提示的 URI 重新保存。
临时重定向
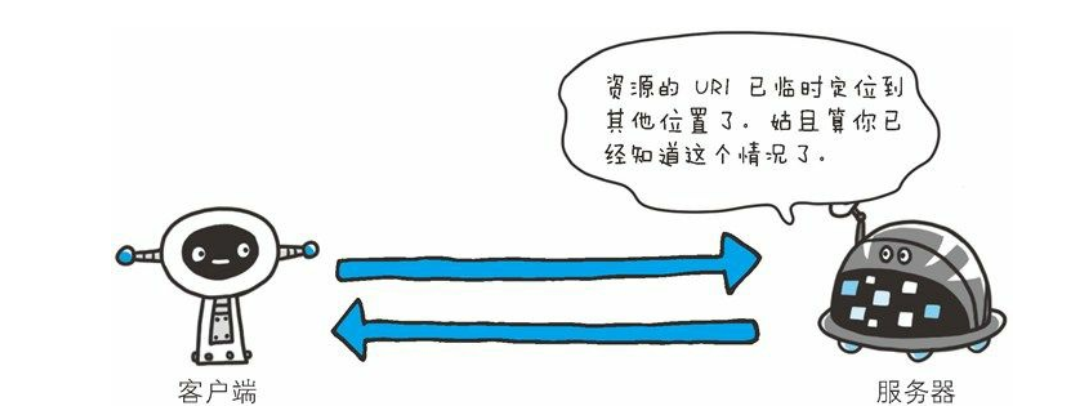
- 临时性重定向。 该状态码表示请求的资源已被分配了新的 URI, 希望用户(本次) 能使用新的 URI 访问。
- 和 301 Moved Permanently 状态码相似, 但 302 状态码代表的资源不是被永久移动, 只是临时性质的。 换句话说, 已移动的资源对应的URI 将来还有可能发生改变。 比如, 用户把 URI 保存成书签, 但不会像 301 状态码出现时那样去更新书签, 而是仍旧保留返回 302 状态码的页面对应的 URI
临时重定向的继续划分
我们知道重定向是两次请求响应
- 第一次的请求是我们自己发送,可以确定类型,第二次是浏览器帮助我们发的,所以方法类型是什么呢
- HTTP1.0没有去考虑这个问题,标准也没有规定使用什么方法
- 但是很多现存的浏览器将 302 响应视为 303 响应, 并且使用 GET方式访问在Location 中规定的 URI, 而无视原先请求的方法。
- 301、 302 标准是禁止将 POST 方法改变成 GET 方法的, 但实际使用时大家都会这么做。
- HTTP1.1进行了明确规定
- 请求方法保留第一次的请求方法
- 请求方法退化成GET
- HTTP1.0没有去考虑这个问题,标准也没有规定使用什么方法
303 See Other
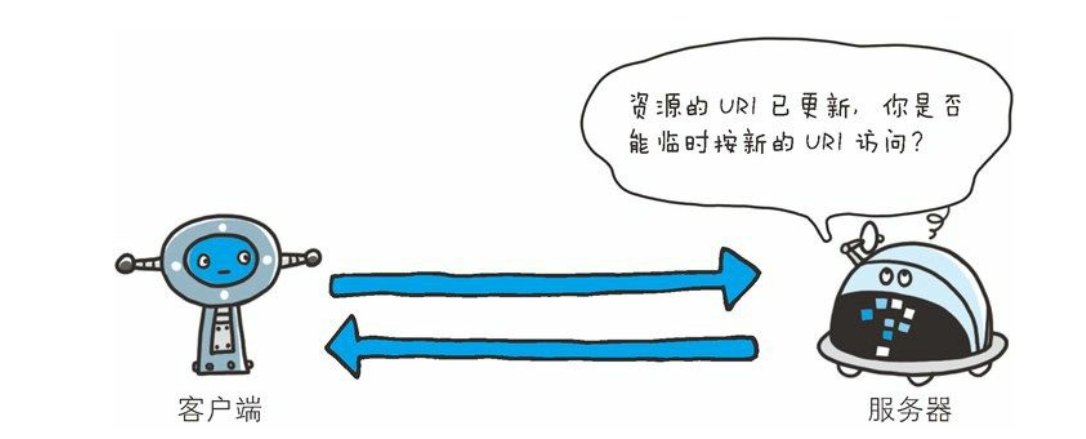
- 该状态码表示由于请求对应的资源存在着另一个 URI, 应使用 GET方法定向获取请求的资源。
- 303 状态码和 302 Found 状态码有着相同的功能, 但 303 状态码明确表示客户端应当采用 GET 方法获取资源, 这点与 302 状态码有区别。
307 Temporary Redirect
- 临时重定向。 该状态码与 302 Found 有着相同的含义。 尽管 302 标准禁止 POST 变换成 GET, 但实际使用时大家并不遵守。
- 307 会遵照浏览器标准, 不会从 POST 变成 GET。 但是, 对于处理响应时的行为, 每种浏览器有可能出现不同的情况
304 Not Modified

改状态码标识客户端发送附带条件的请求,服务器段允许请求访问资源,但因为请求为满足条件的情况后,直接返回304 Not Modified(服务器端资源为改变,可直接使用客户端为未期的缓存)。304状态返回后,不包含任何响应的主体部分
-
304状态码: 客户端有缓存情况下服务端的一种响应。自从上次请求后,请求的网页未修改过。服务器返回此响应时,不会返回网页内容。
-
1 附带条件的请求是指采用 GET方法的请求报文中包含 If-Match, If-ModifiedSince, If-None-Match, If-Range, If-Unmodified-Since 中任一首部。
如何做到304
- 如果客户端发送了一个带条件的GET请求且该请求已被允许,而文档的内容(自上次访问以来或者根据请求的条件)并没有改变,则服务器返回一个304状态码。简单理解成:客户端访问服务器时,服务器已经执行了GET,但文件未变化。
转发和重定向的区别
- 转发:Java纯后端有套机制,称为forward转发
- 以做手术为例子
- 小明是患者 是客户端 服务端是医院 李医生是服务端的组件
- 当小明要做手术治病,找李医生做手术
- 当小明已经躺倒床上了,麻醉了,李医生发现自己做不了这个手术,请求王医生来做手术,这是转发,小明以为是李医生帮他做的手术
- 小明还没有做手术,李医生说我做不了这个手术,让小明去找王医生,这是重定向,小明全程是知道的
- 转发是纯后端的事情,跟我们的HTTP协议没关系
4XX 客户端错误
400 Bad Request
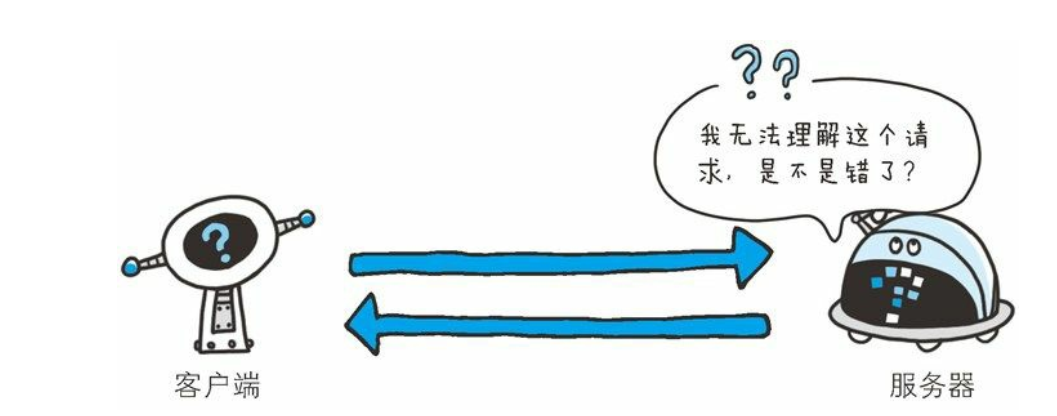
- 该状态码表示请求报文中存在语法错误。 当错误发生时, 需修改请求的内容后再次发送请求。 另外, 浏览器会像 200 OK 一样对待该状态码。
如何做到400
- 访问正确的资源路径
- 访问正确的方法
- 由于客户端的错误,可能是用户没有按照资源的要求来
- 请求参数不对
- 或者参数的类型不对,反正就是没有安装资源的要求来
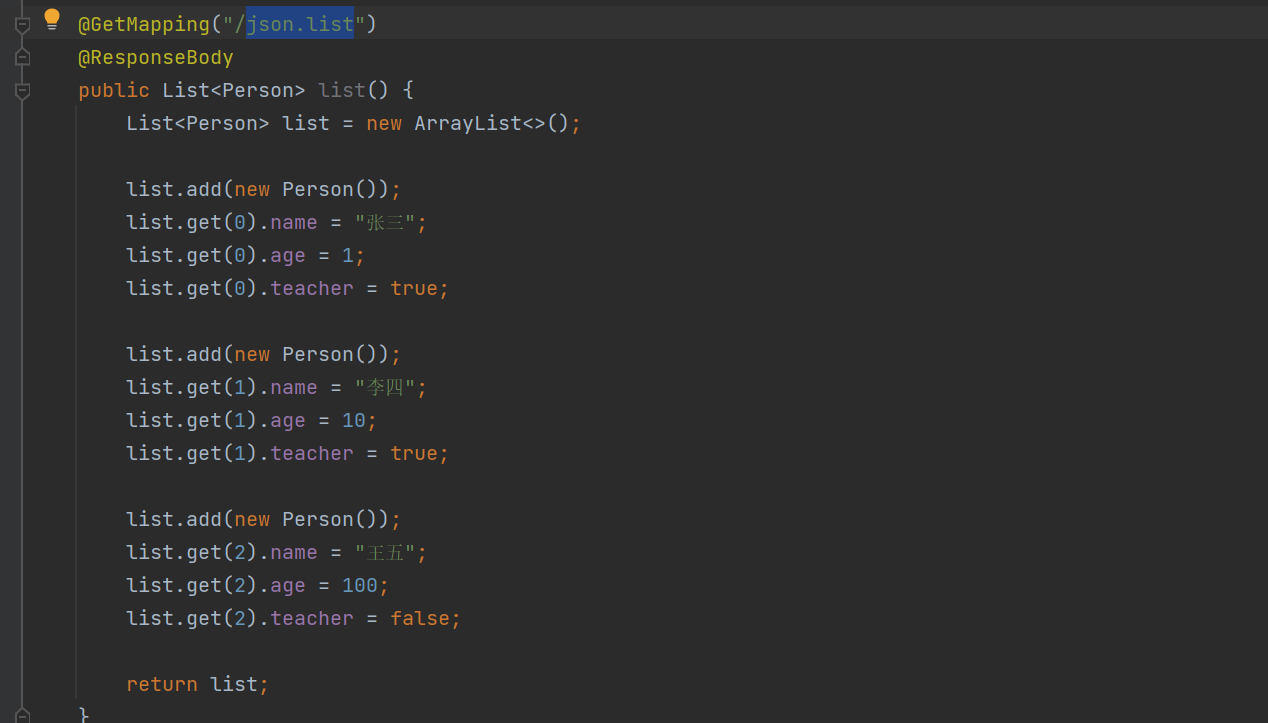
@RequestMapping(
value = {"test1","test2"},
method = {RequestMethod.GET,RequestMethod.POST},
params = {"username","password!=123","!gender","age=22"}
)
public String test(){
return "test";
}
- 这里我们params规定 请求时必须有username属性,有password属性但是不能是123,不能存在gender,必须有年龄属性,但是必须是22,不然会报错
- 如:HTTP Status 400 - Parameter conditions “username, password!=123, !gender, age=22” not met for actual request parameters: username={lsc}, password={123456}, age={2}
403 Forbidden
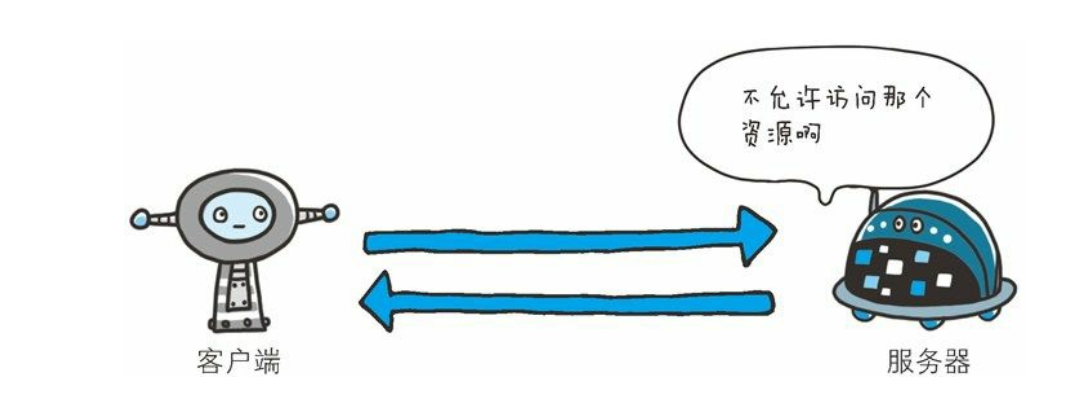
- 该状态码表明对请求资源的访问被服务器拒绝了。 服务器端没有必要给出拒绝的详细理由, 但如果想作说明的话, 可以在实体的主体部分对原因进行描述, 这样就能让用户看到了。
- 未获得文件系统的访问授权, 访问权限出现某些问题(从未授权的发送源 IP 地址试图访问) 等列举的情况都可能是发生 403 的原因。
如何做到403
- 表示访问被拒绝. 有的页面通常需要用户具有一定的权限才能访问(登陆后才能访问). 如果用户没有登陆直接访问, 就容易见到 403.
404 NOT FOUND
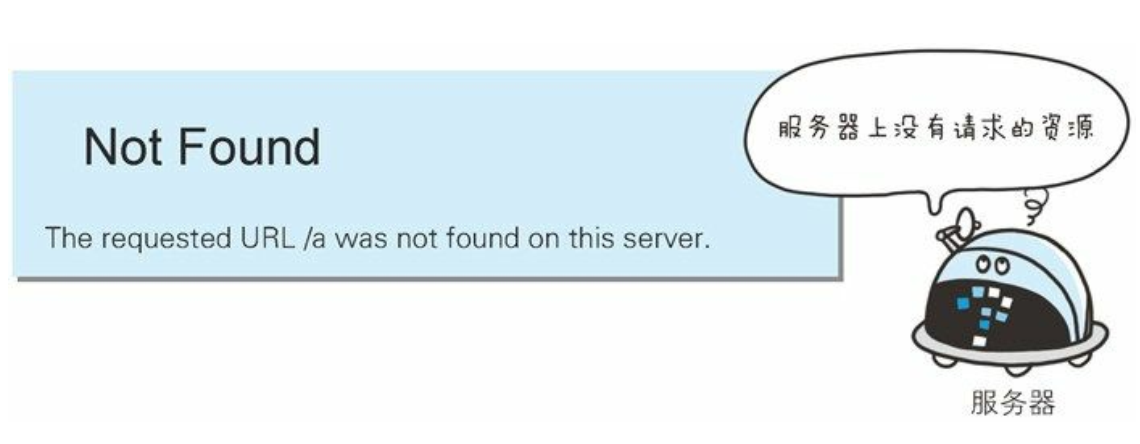
该状态码表明服务器上无法找到请求的资源。 除此之外, 也可以在服务器端拒绝请求且不想说明理由时使用。
如何做到404
- 访问不正确的资源路径
405
- 资源路径正确,但是访问的HTTP方法不正确
5XX 服务器错误
500 Internal Server Error
该状态码表明服务器端在执行请求时发生了错误。 也有可能是 Web应用存在的 bug 或某些临时的故障。
如何做到500
- 服务器出现异常,服务器的代码出现了问题
504
- Gateway Timeout当服务器负载比较大的时候, 服务器处理单条请求的时候消耗的时间就会很长, 就可能会导致出现超时的情况.
503 Service Unavailable
- 该状态码表明服务器暂时处于超负载或正在进行停机维护, 现在无法处理请求。 如果事先得知解除以上状况需要的时间, 最好写入RetryAfter 首部字段再返回给客户端。
状态码和状况的不一致不少返回的状态码响应都是错误的, 但是用户可能察觉不到这点。比如 Web 应用程序内部发生错误, 状态码依然返回 200 OK, 这种情况也经常遇到。
响应内容的形式
content-type(内容类型)
- 也就是我们返回的数据是按照什么类型显式的(跟编码的功能差不多)
- 基本结构 类型/子类型 如果是文本类型,开源通过以下的格式 text/plain;charset=utf-8
- 大类型是 text 表示是文本类型
- 小类型 plain(无格式) 表示是没有任何具体格式的文本类型——纯文本
- charset=utf-8 文本的字符集采用UTF-8
- 如果没有指定charset,默认采用西文字符集(ISO-8895-2 ?),中文就会乱码
常见的类型
大文本类型
- text/plain 纯文本
- 注意:我们返回的内容完全可以是一个HTML,只是浏览器会把内容当中纯文本,而不是按照HTML去处理
- text/html HTML结构的文本
- text/css CSS结构的文本
- text/javascript JavaScript结构的文本
应用类型
- application/javascript JavaScript结构的应用
- application/json JavaScript Object Notation
- 比较便捷的携带人类可识别的结构化数据,主要用于前后端分类的开发模式
- application/x-www-form-urlencoded form表单提交时,默认采用的请求体编码格式
多媒体
- image/jpeg jpg图片
- image/png png图片
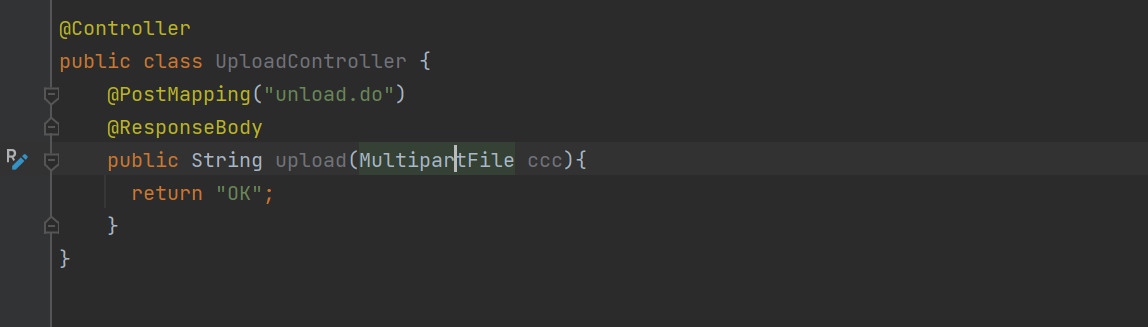
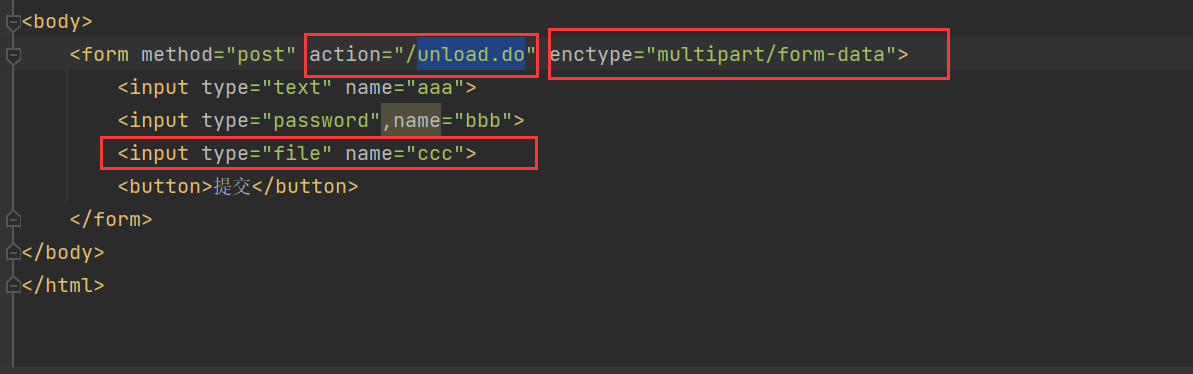
from表单文件上传
- multipart/form-data
- 大类型 multipart 多部分——表示正文是由多个小部分组成
- 小类型 form-data 每个部分是form提交数据
<form enctype="multipart/form-data">主要和<input type="file" name="...">配合
JSON格式
具体了解看博客——http://t.csdn.cn/8sJrb
Web动态资源中输出JSON格式的内容
- 支持返回类型是某个类,或者是Map,List等集合类
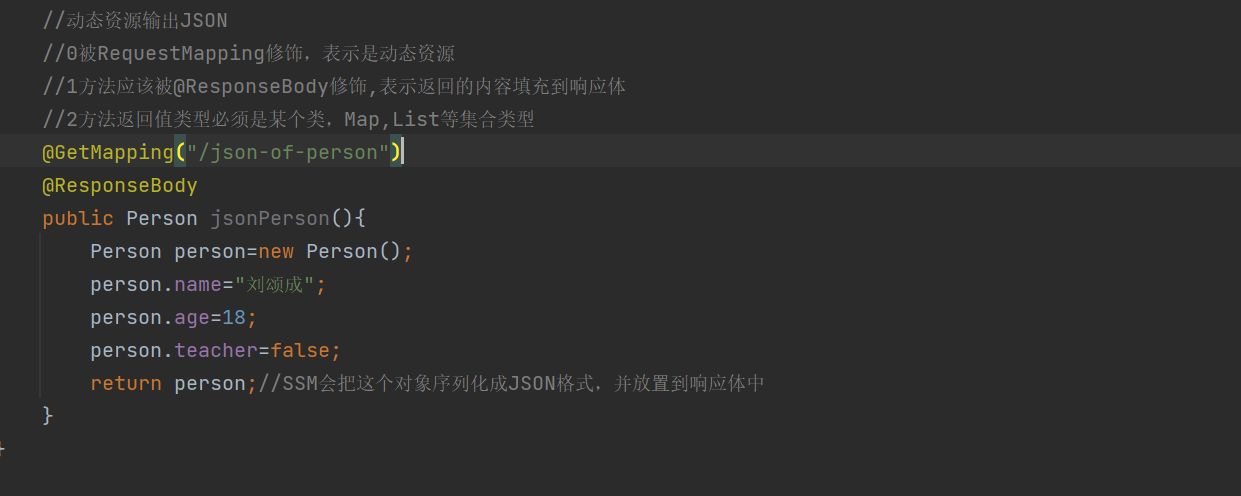
返回类对象
 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qVCPqjuB-1681456831806)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qVCPqjuB-1681456831806)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]
返回集合类对象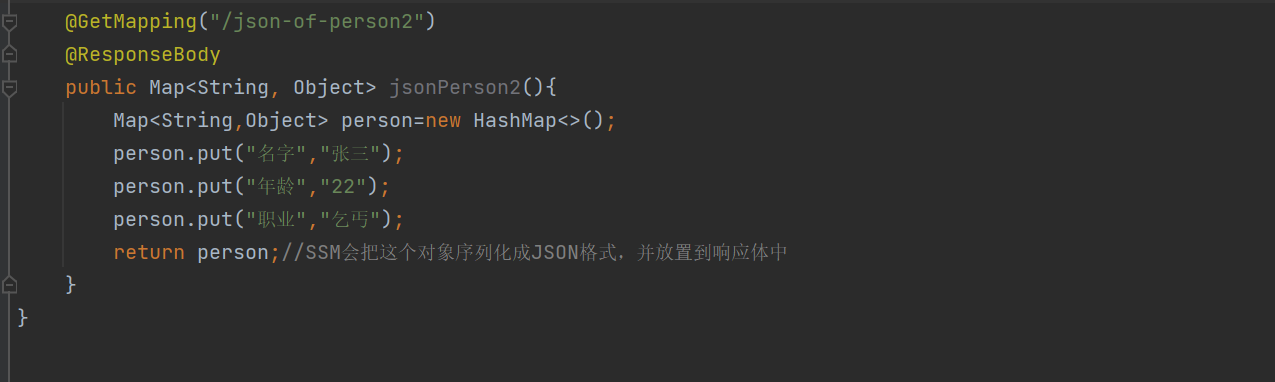
客户端发送POST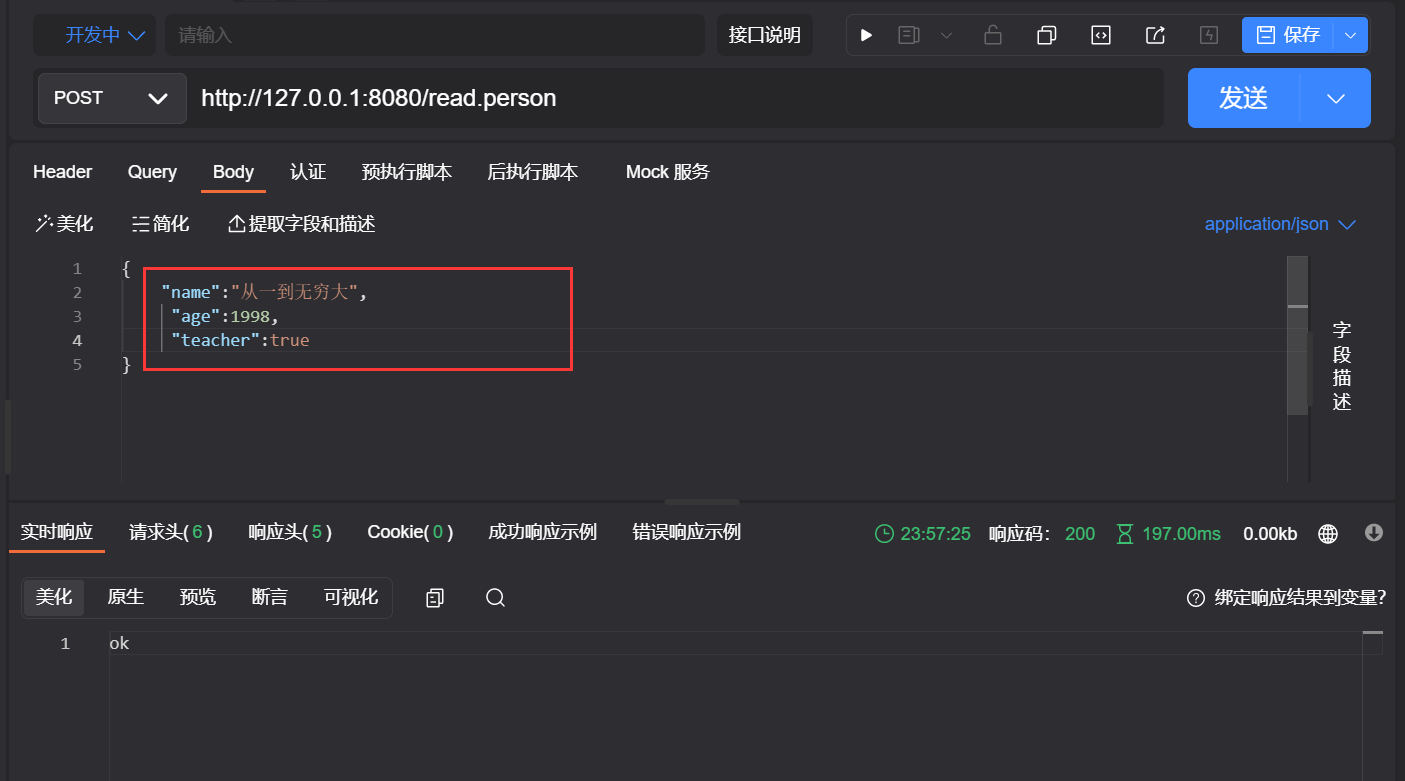

form表单提交的Content-Type两种格式
- application/x-www.form.urlencooded
- multipart/form-date,主要用于文件上传。用于
<input type="file">

动态资源
 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EyNX0b5G-1681456831809)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EyNX0b5G-1681456831809)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]
 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-puibeRuD-1681456831810)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-puibeRuD-1681456831810)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TrCmRZ1q-1681456831810)(C:\Users\lsc07\Desktop\学习资料\19typora笔记\5计算机网络\HTTP.assets\9f71ce2743f24ec081ec16760ec02e8c.png)]
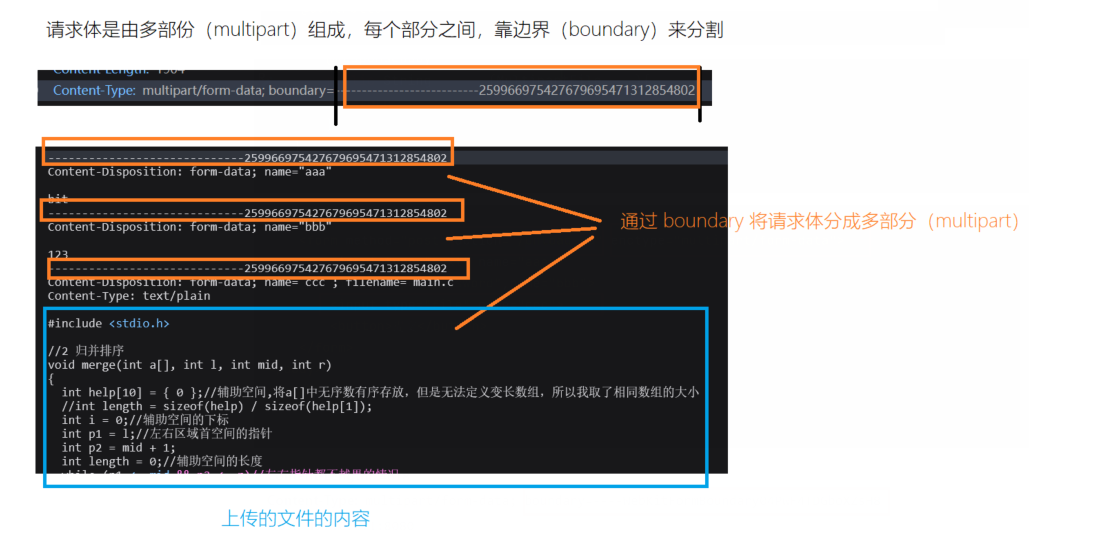
总之,文件上传的时候(通过from表单上传),必须指定enctype为multipart/form-date.这样请求体中不仅仅携带要上传的文件名,还包含文件的内容信息
Cookie-Session体系
为什么引入Cookie体系
前提:一开始设计的HTTP协议,本身是无状态的协议
HTTP 是一种不保存状态, 即无状态(stateless) 协议。 HTTP 协议自身不对请求和响应之间的通信状态进行保存。 也就是说在 HTTP 这个级别, 协议对于发送过的请求或响应都不做持久化处理
不可否认, 无状态协议当然也有它的优点。 由于不必保存状态, 自然可减少服务器的 CPU 及内存资源的消耗。 从另一侧面来说, 也正是因为 HTTP 协议本身是非常简单的, 所以才会被应用在各种场景里。
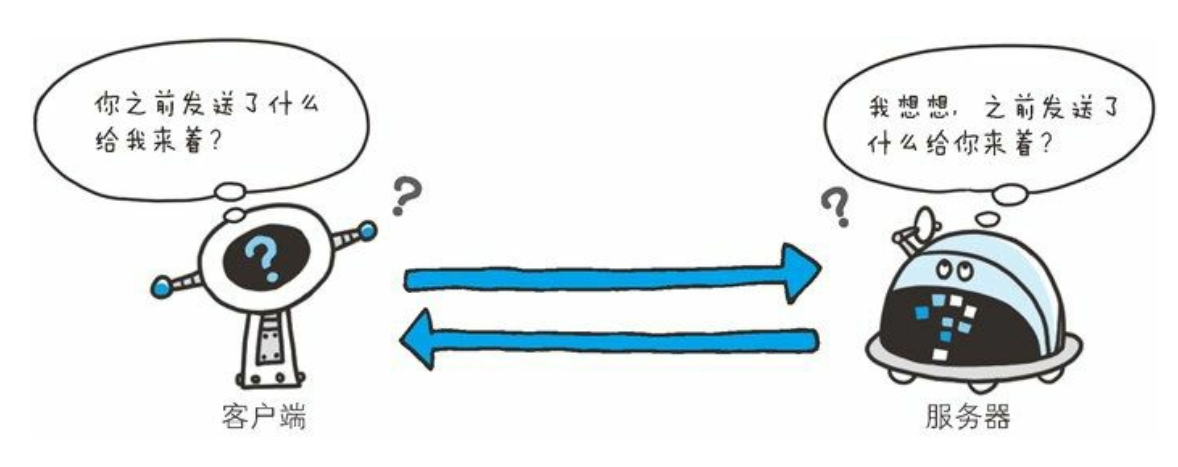
- 无状态的意思换句话说,服务器记不住你,可能你每刷新一次网页,就要重新输入一次账号密码进行登录。这显然是让人无法接受的,cookie 的作用就好比服务器给你贴个标签,然后你每次向服务器再发请求时,服务器就能够 cookie 认出你。
- 再比如可能我们有需求,比如我们需要区分不同请求-响应,请求响应是不是同一个用户发送的,比如用户购买的越多,折扣就越大,那我们就需要分辨出不同的请求响应之间的逻辑关系,所以引入cookie体系
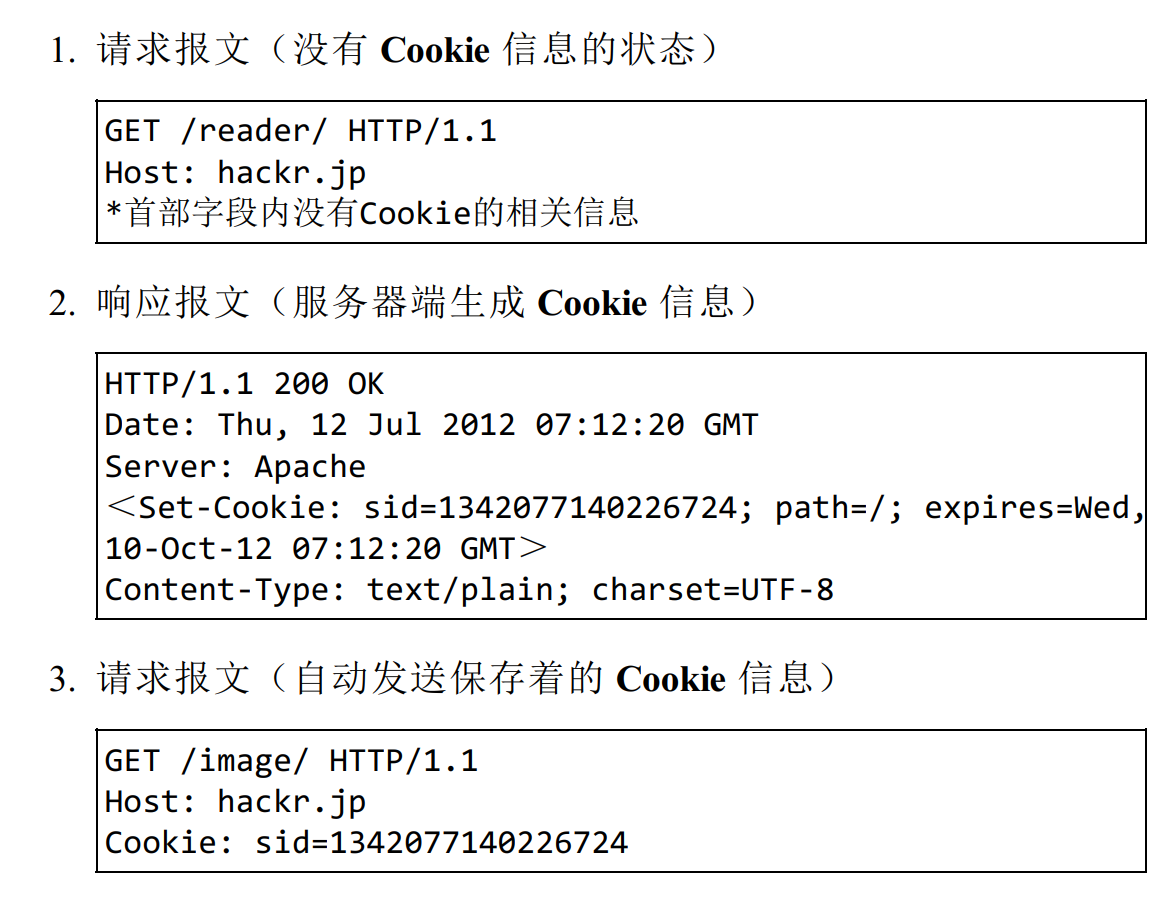
客户端第一次发送请求给服务器
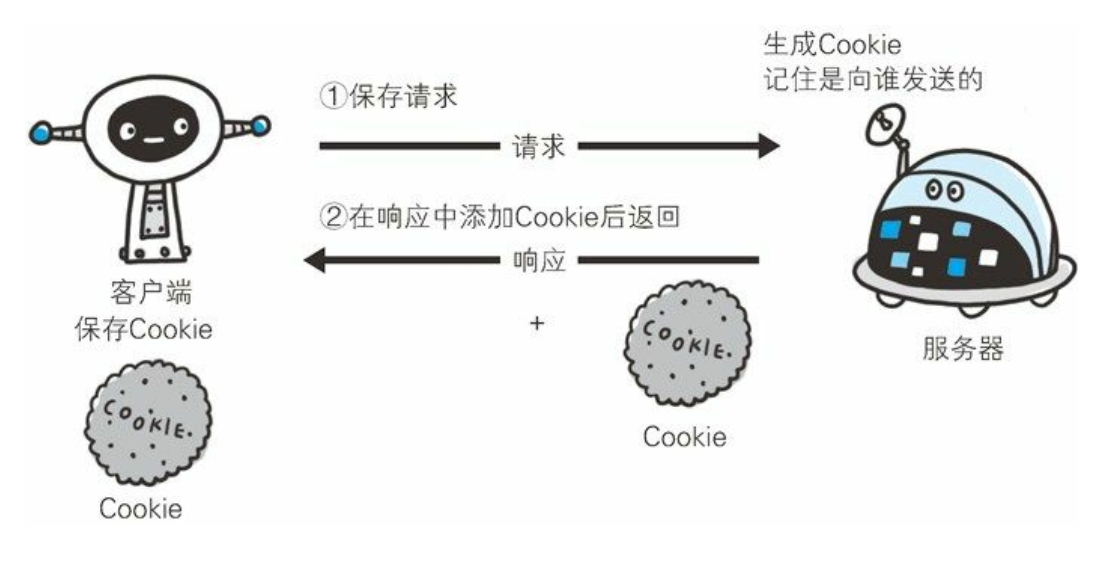
同一个客户端第二次发信息给服务器
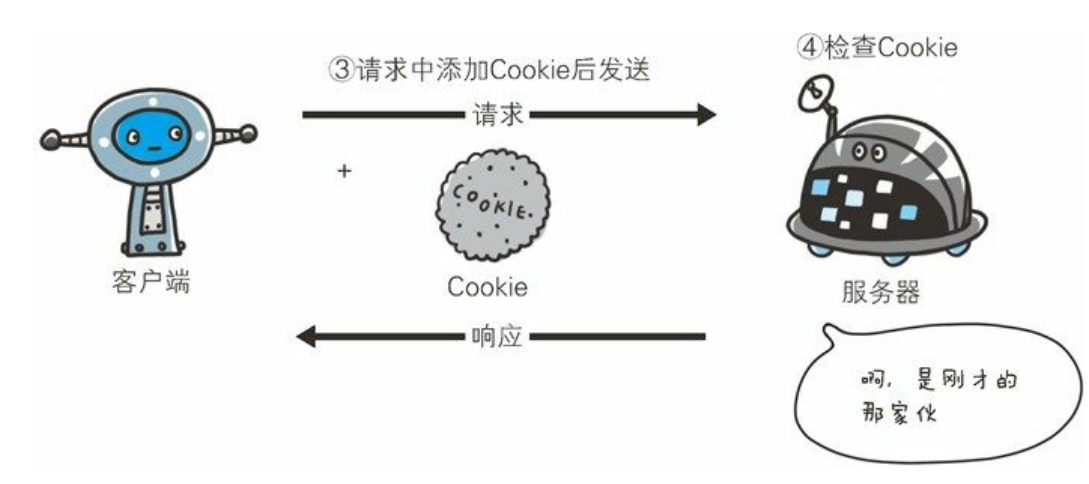
- Cookie:就相当于A(服务器)发给每个客户(客户端)的一个凭证,客户必须有保存这个凭证的责任(你丢了,我就不知道你是不是你了),也必须在每次接收服务的时候带着这个凭证(你不带,我也不知道你是不是你)
- 发凭证:从服务器到客户端,所以肯定是在响应体中,Set-Cookie
- 携带凭证:从客户端到服务器,所以肯定在请求体中 Cookie
- 我说的是「一个」cookie 可以认为是一个变量,形如
name=value,但是服务器可以一次设置多个 cookie,所以有时候说 cookie 是「一组」键值对儿,这也可以说得通。
实验
在服务器颁发Cookie
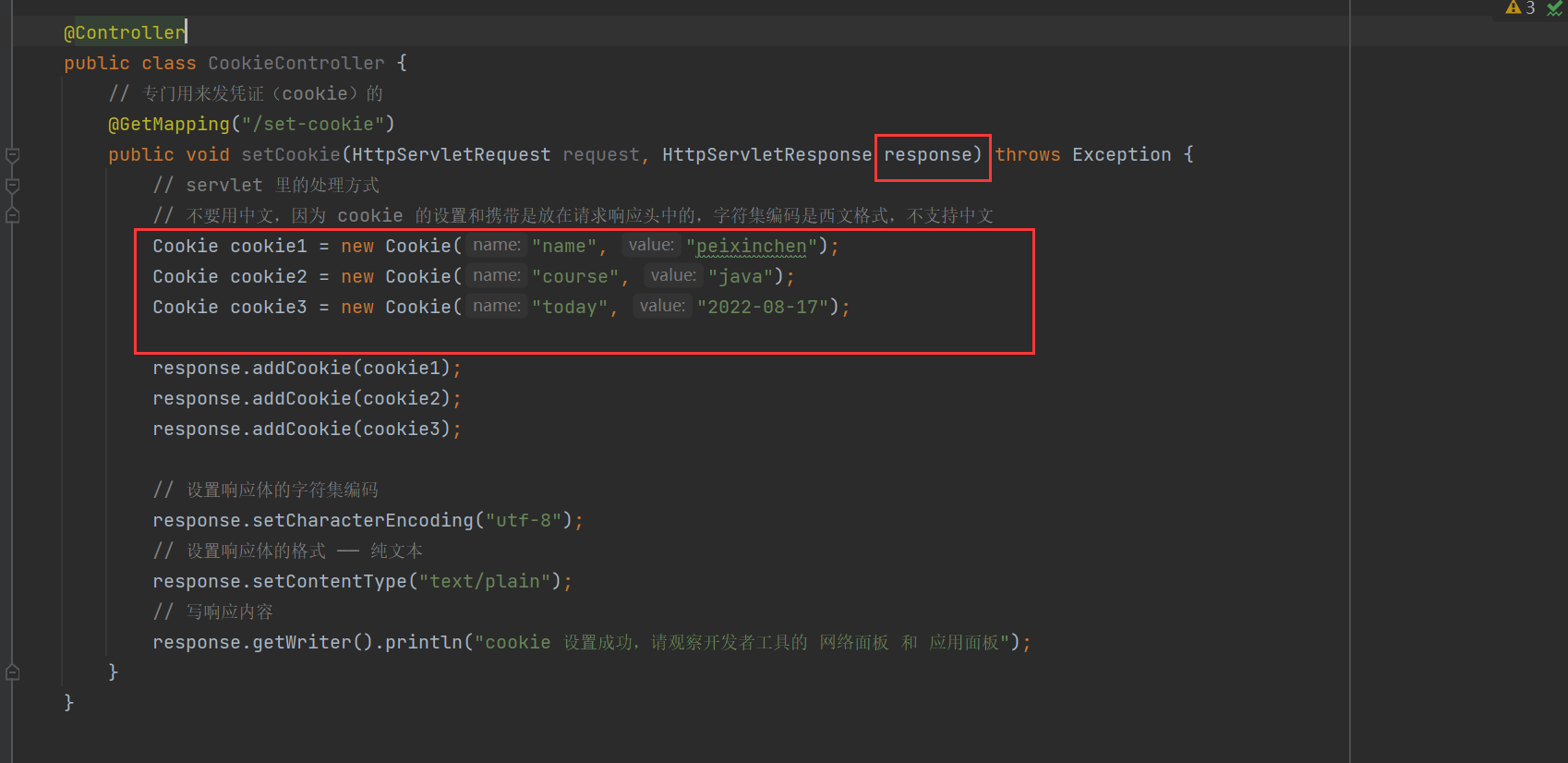
响应头返回了设置的相应的cookie信息
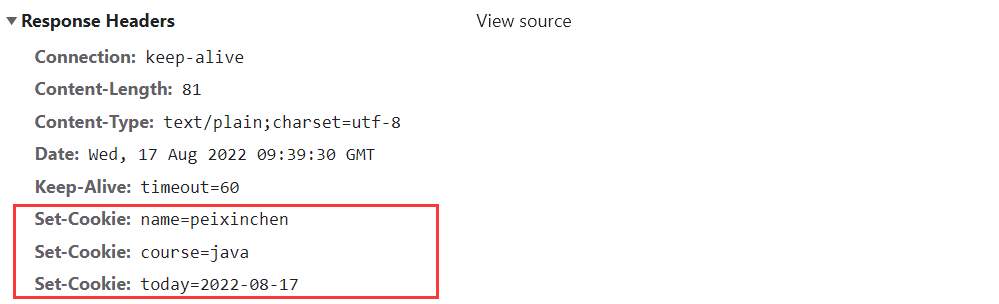
在浏览器找到对应Cookie的存储位置
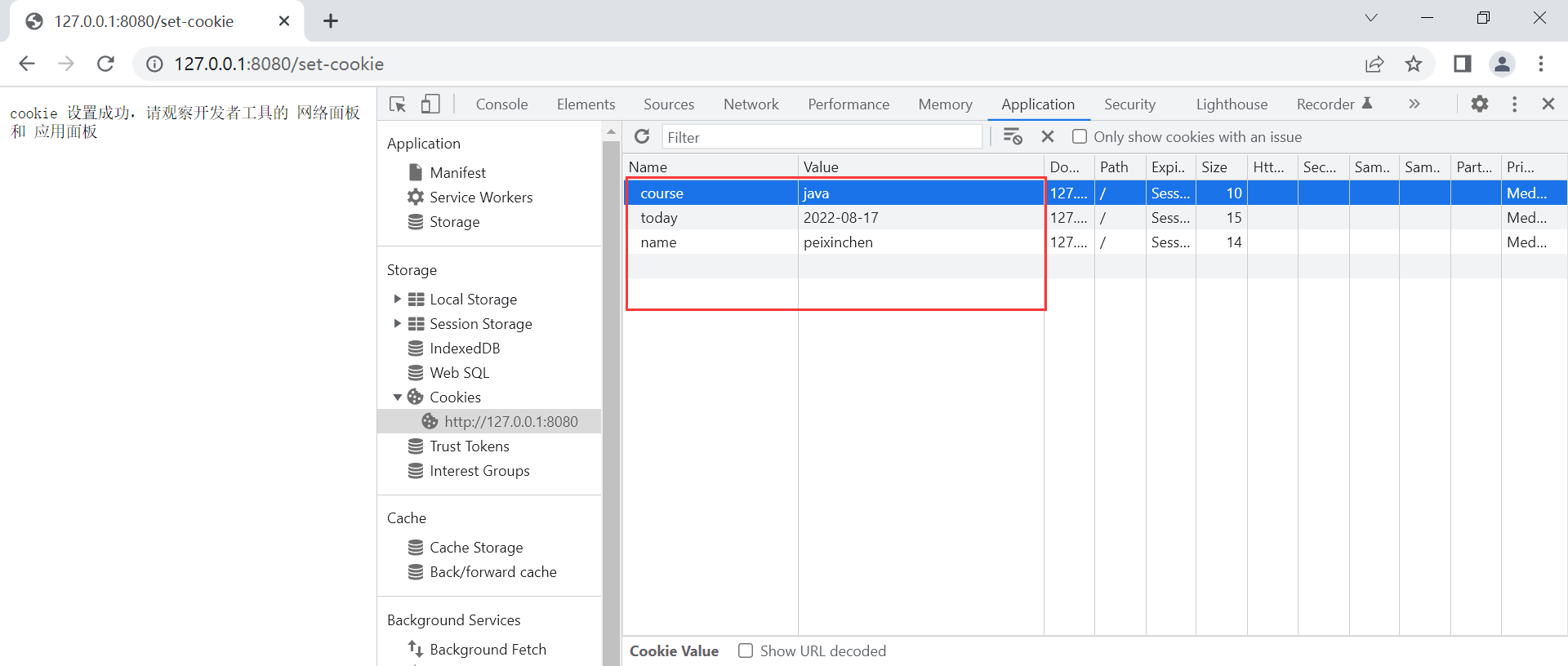
- 我们发现客户端保存了cookie,根据域(协议+服务器地址+端口)区分
下次请求携带Cookie
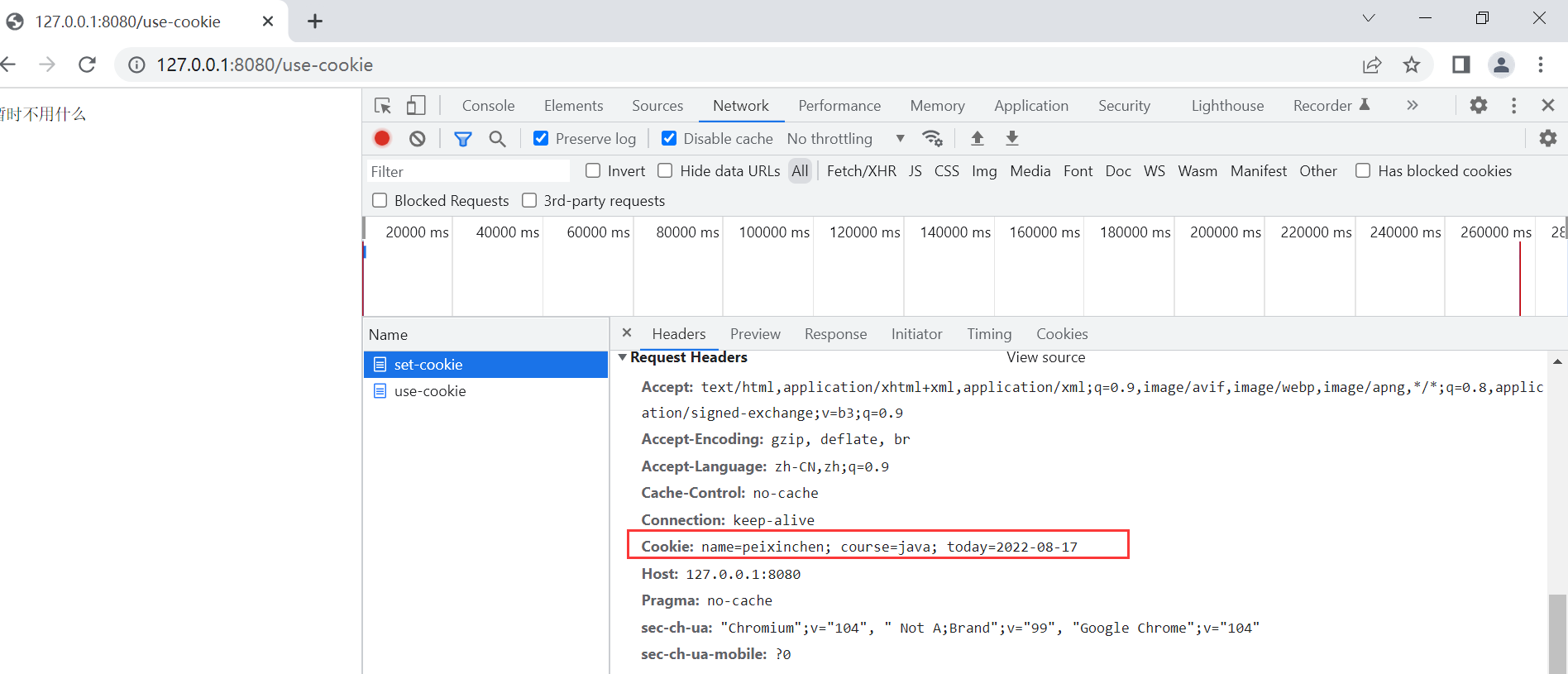
Cookie总结
-
要利用Cookie做到HTTP协议有状态(跨请求-响应有逻辑关系)
-
对于服务器,需要有设置凭证的职责,在HTTP中的表现为HTTP响应中,添加Set-Cookie响应头,value是要设置的cookie信息
-
对于客户端,有保存凭证的职责,在HTTP的具体表现为,客户端需要理解Set-Cookie这个响应头的职责,根据响应中的Set-Cookie的value,将Cookie的信息解析并保存
-
对于客户端,在发送任意请求时,都有携带属于本网站的所有的Cookie的职责
-
经过这一套cookie的流程,我们就可以实现http的有状态,能让我们的服务器能够认识我们的客户
碰到的问题
- 安全问题:如果我们把cookie完全交给客户端,我们服务器完全信任cookie,那么如果碰到恶意用户或者恶意程序进行修改伪造别人的cookie,那么是不安全的
- 性能问题:我们也知道现在的很多网站功能很复杂,而且涉及很多的数据交互,比如说电商网站的购物车功能,信息量大,而且结构也比较复杂,无法通过简单的 cookie 机制传递这么多信息,而且要知道 cookie 字段是存储在 HTTP header 中的,就算能够承载这些信息,也会消耗很多的带宽,比较消耗网络资源。
- 解决方法:拆分保存数据,把敏感的数据保存到服务器的内部,cookie只携带不敏感的信息,通常来说就是一个卡号,也就引入我们的session这个数据结构
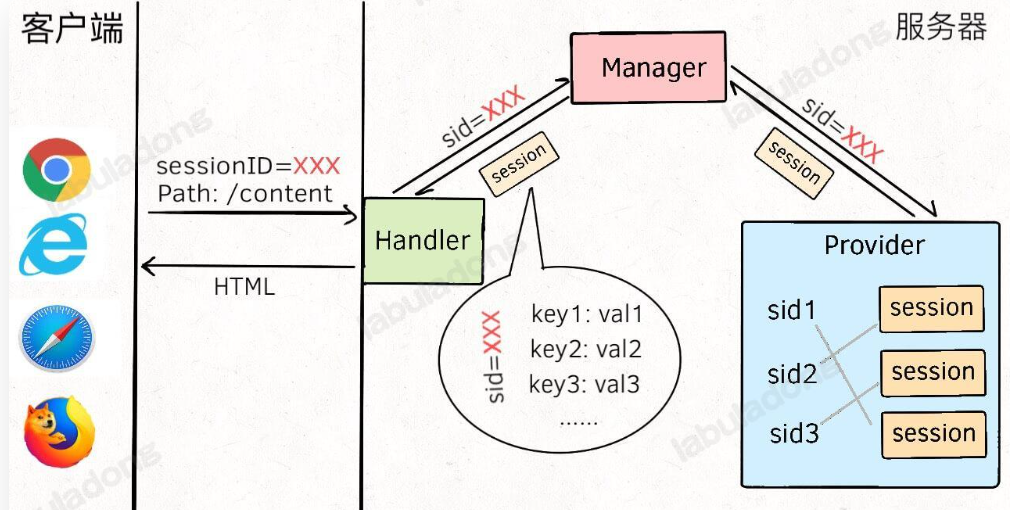
- 服务器就类似我们去洗浴的澡堂(澡堂是服务器),我们洗澡需要把随身物品放在柜子里(柜子就是Session),然后浴池给我了一个手牌,我们可以凭借手牌拿到对应的随身物品(手牌就是SessionID)
Session
-
Session:是保存在服务器的,专属某次会话的,一组数据,可以跨请求访问到(生命周期是跨请求的),通常Session中保存的数据也可以视为name-value.,一般cookie设置session-id.这样客户端和服务器之间仍然使用cookie机制,只是cookie只传递SessionId即可(cookie还是放在我们的请求头和响应头中的,存储的是session-id),大头数据全部保存在服务器
-
HttpServletRequest类下,有一个HttpSession getSession(boolean create)来获取session
- 如果能获取到HttpSession对象,则create为true/false都没有关系
- 如果获取不到对应的HttpSession对象
- create==true,创建一个新的Session对象
- create==false,不创建新的,返回null
-
HttpSession对象就是用来获得相应的session的信息,是通过 getSession函数获得,根据请求头的cookie信息来获得

Seesion结构
- session类似一个卡号对应着一个柜子的结构,然后一个柜子也是一个Map的结构,因为柜子要存储name:value这种类型的数据
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0GsJfNdy-1681456831816)(C:\Users\lsc07\Desktop\学习资料\19typora笔记\5计算机网络\HTTP.assets\3b8e85ead117493bb17b6e84a823241d.png)]
private final Map<String,Map<String,Object>> 模拟session的结构=new HashMap<>();
- Map<String,Object>就理解成一个HttpSession对象
确保 Web 安全的HTTPS
到现在为止, 我们已了解到 HTTP 具有相当优秀和方便的一面, 然而HTTP 并非只有好的一面, 事物皆具两面性, 它也是有不足之处的。HTTP 主要有这些不足, 例举如下。
- 通信使用明文( 不加密) , 内容可能会被窃听
- 不验证通信方的身份, 因此有可能遭遇伪装
- 无法证明报文的完整性, 所以有可能已遭篡改
- 这些问题不仅在 HTTP 上出现, 其他未加密的协议中也会存在这类问题。除此之外, HTTP 本身还有很多缺点。 而且, 还有像某些特定的 Web服务器和特定的 Web 浏览器在实际应用中存在的不足(也可以说成是脆弱性或安全漏洞) , 另外, 用 Java 和 PHP 等编程语言开发的Web 应用也可能存在安全漏洞
HTTPS 是身披 SSL 外壳的 HTTP
HTTPS 并非是应用层的一种新协议。 只是 HTTP 通信接口部分用SSL(Secure Socket Layer) 和 TLS(Transport Layer Security) 协议代替而已。通常, HTTP 直接和 TCP 通信。 当使用 SSL时, 则演变成先和 SSL通信, 再由 SSL和 TCP 通信了。 简言之, 所谓 HTTPS, 其实就是身披SSL协议这层外壳的 HTTP。
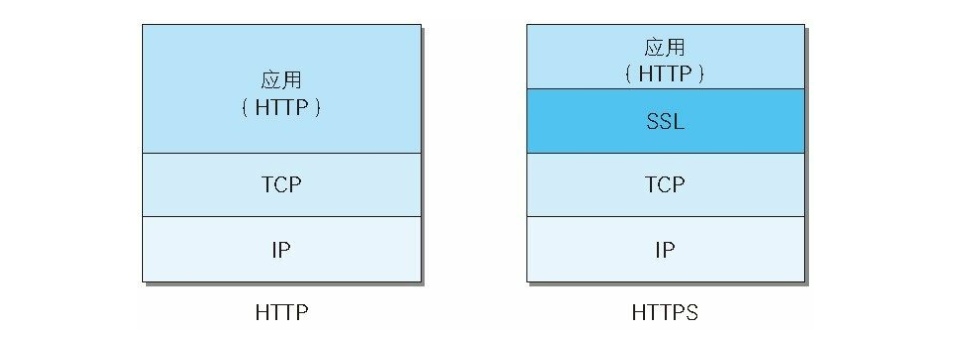
在采用 SSL后, HTTP 就拥有了 HTTPS 的加密、 证书和完整性保护这些功能
- SSL是独立于 HTTP 的协议, 所以不光是 HTTP 协议, 其他运行在应用层的 SMTP 和 Telnet 等协议均可配合 SSL协议使用。 可以说 SSL是当今世界上应用最为广泛的网络安全技术。
为什么内容可能被窃听
- HTTP(1.0,1.1)基于了TCP的一种应用层协议,HTTP(1.0,1.1)协议本身没有做过任何的可靠性机制,但是依托于TCP的可靠性传输,所以HTTP协议也是可靠的
- 由于 HTTP 本身不具备加密的功能, 所以也无法做到对通信整体(使用 HTTP 协议通信的请求和响应的内容) 进行加密。 即, HTTP 报文使用明文(指未经过加密的报文) 方式发送。
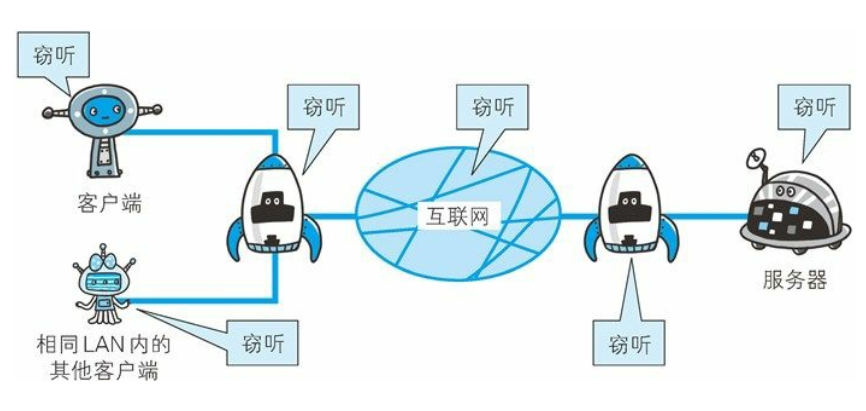
- 网络数据本身是明文的+网络数据在传递过程中是一跳一跳的传输(路由器),所以这意味着中间的节点(网络层,传输层,应用层)都是有可能被窃听,篡改,伪造数据的,但是HTTP协议本身没有在这个环节做过任何的解决措施,TCP也没有(只保证了可靠,但不是保证安全),HTTP是一种不安全的协议,HTTPS就是为了解决这个问题
TCP/IP 是可能被窃听的网络
如果要问为什么通信时不加密是一个缺点, 这是因为, 按TCP/IP 协议族的工作机制, 通信内容在所有的通信线路上都有可能遭到窥视。所谓互联网, 是由能连通到全世界的网络组成的。 无论世界哪个角落的服务器在和客户端通信时, 在此通信线路上的某些网络设备、 光缆、 计算机等都不可能是个人的私有物, 所以不排除某个环节中会遭到恶意窥视行为。
即使已经过加密处理的通信, 也会被窥视到通信内容, 这点和未加密的通信是相同的。 只是说如果通信经过加密, 就有可能让人无法破解报文信息的含义, 但加密处理后的报文信息本身还是会被看到的。
比如之前臭名昭著的运营商劫持
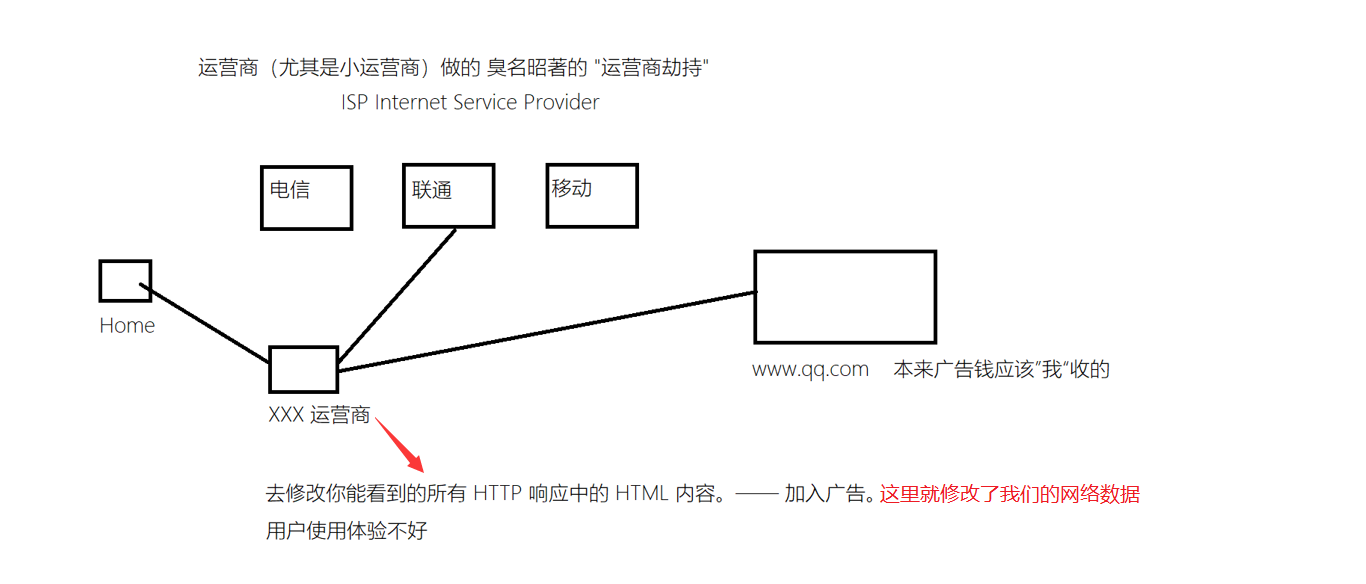
如何解决安全问题
- 传输安全就是防窃听,防篡改,防伪造

在目前大家正在研究的如何防止窃听保护信息的几种对策中, 最为普及的就是加密技术。 加密的对象可以有这么几个。
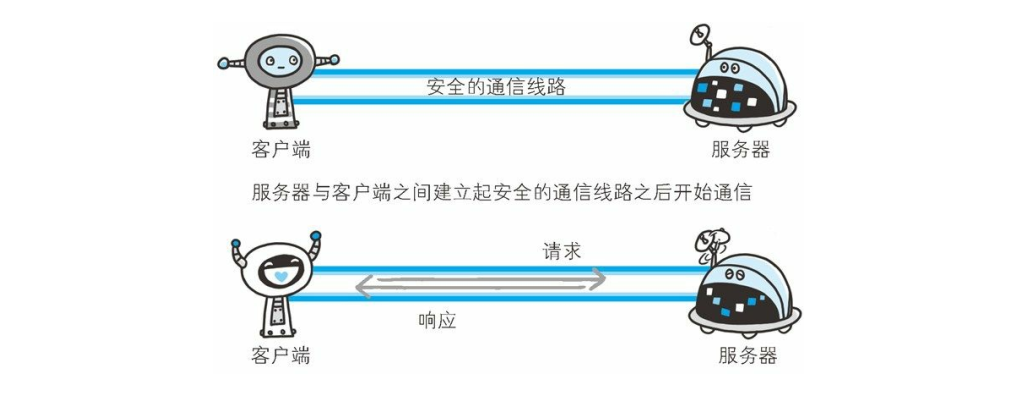
通信的加密
- 一种方式就是将通信加密。 HTTP 协议中没有加密机制, 但可以通过和 SSL(Secure Socket Layer, 安全套接层) 或TLS(Transport Layer Security, 安全层传输协议) 的组合使用,加密 HTTP 的通信内容。用 SSL建立安全通信线路之后, 就可以在这条线路上进行 HTTP通信了。 与 SSL组合使用的 HTTP 被称为 HTTPS(HTTPSecure, 超文本传输安全协议) 或 HTTP over SSL。
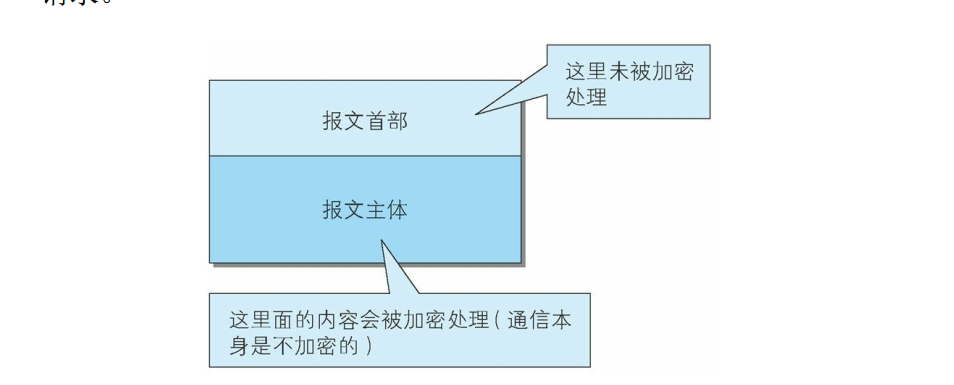
内容的加密
还有一种将参与通信的内容本身加密的方式。 由于 HTTP 协议中没有加密机制, 那么就对 HTTP 协议传输的内容本身加密。 即把HTTP 报文里所含的内容进行加密处理。在这种情况下, 客户端需要对 HTTP 报文进行加密处理后再发送请求。诚然, 为了做到有效的内容加密, 前提是要求客户端和服务器同时具备加密和解密机制。 主要应用在 Web 服务中。 有一点必须引起注意, 由于该方式不同于 SSL或 TLS 将整个通信线路加密处理, 所以内容仍有被篡改的风险。
安全传输的解决流程
前提了解相关加密算法
共享密钥传输时存在的窘境
我们可以利用对称加密算法来实现明文到密文的转换,来进行传输,但是如何传输对称算法的密钥却是一种问题
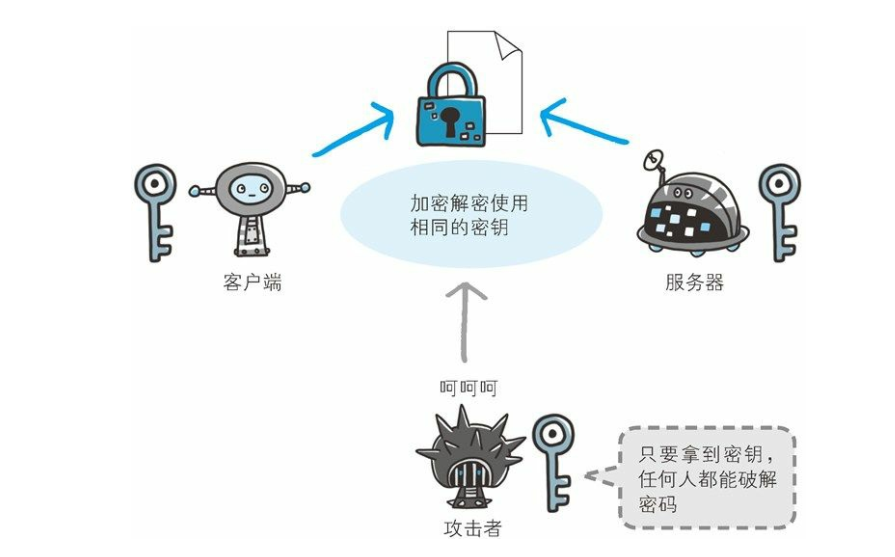
以共享密钥方式加密时必须将密钥也发给对方。 可究竟怎样才能安全地转交? 在互联网上转发密钥时, 如果通信被监听那么密钥就可会落入攻击者之手, 同时也就失去了加密的意义。 另外还得设法安全地保管接收到的密钥。
解决共享密钥传输存在风险的方法
解决通信使用明文( 不加密) , 内容可能会被窃听的问题
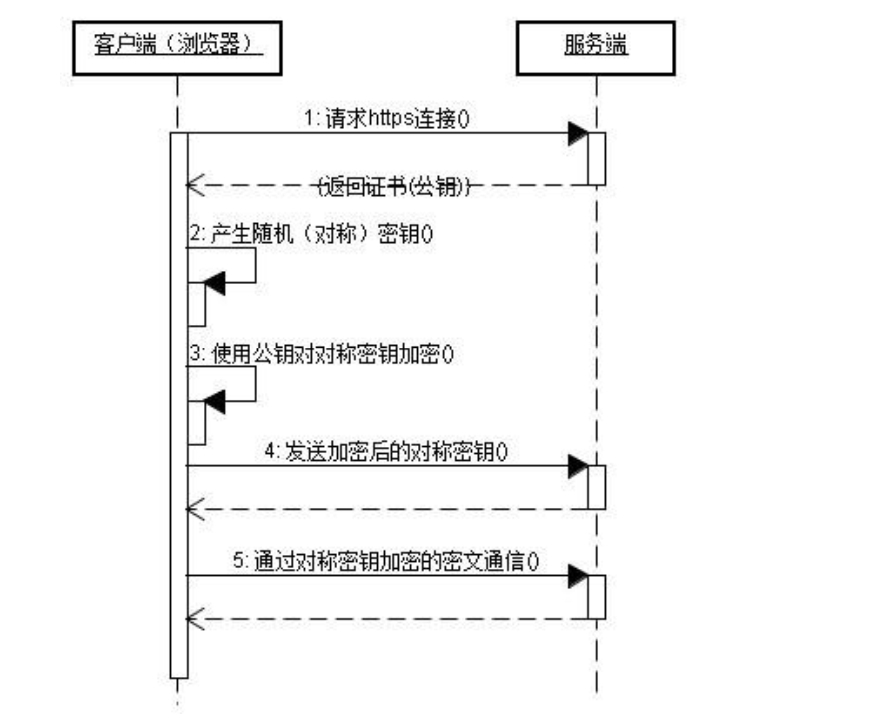
-
首先服务器要准备好非对称算法公钥和私钥(私钥不能泄露)
-
首先我们的客户端去申请回来服务器的公钥(明文传输),因为这个公钥是用来将数据加密的,不能解密,所以别人知道了也无所谓
-
客户端生成一段随机数,来作为对称算法的密钥,然后通过非对称算法公钥来加密(只有服务器的私钥才能解密),所以其他人是不知道这个对称密钥的明文的,发送给服务器
-
服务接收到这段密文,然后通过非对称算法的私钥来获得对称算法的密钥(完成了对称算法的密钥的安全传输)
-
得到这个对称算法的密钥,服务器和客户端就可以通过对称算法来完成数据的加密传输
为啥要用对称算法传输数据,而不直接用非对称算法呢?
因为公开密钥加密处理起来比对称算法的共享密钥更复杂,若在通信时使用非对称算法,效率会很低
但是这套流程还是存在着漏洞
不验证通信方的身份就可能遭遇伪装
不验证通信方的身份就可能遭遇伪装,HTTP 协议中的请求和响应不会对通信方进行确认。 也就是说存在“服务器是否就是发送请求中 URI 真正指定的主机, 返回的响应是否真的返回到实际提出请求的客户端”等类似问题。
任何人都可发起请求
- 在 HTTP 协议通信时, 由于不存在确认通信方的处理步骤, 任何人都可以发起请求。 另外, 服务器只要接收到请求, 不管对方是谁都会返回一个响应(但也仅限于发送端的 IP 地址和端口号没有被 Web 服务器设定限制访问的前提下) 。
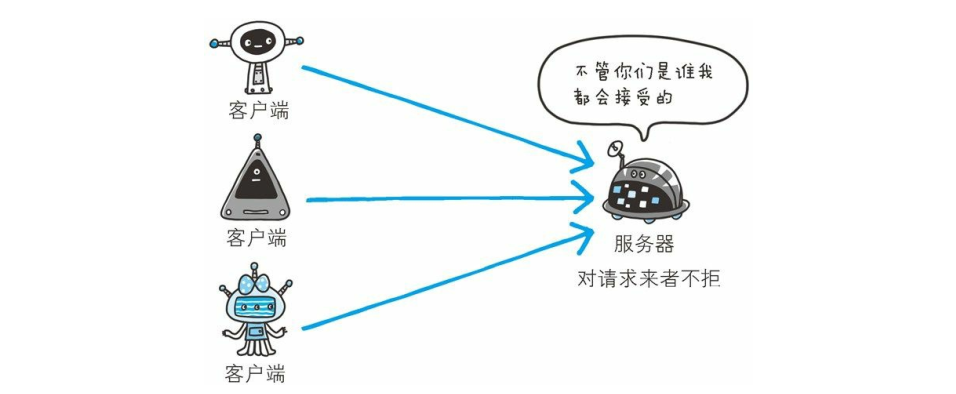
- HTTP 协议的实现本身非常简单, 不论是谁发送过来的请求都会返回响应, 因此不确认通信方, 会存在以下各种隐患。
- 无法确定请求发送至目标的 Web 服务器是否是按真实意图返回响应的那台服务器。 有可能是已伪装的 Web 服务器。
- 无法确定响应返回到的客户端是否是按真实意图接收响应的那个客户端。 有可能是已伪装的客户端。
- 无法确定正在通信的对方是否具备访问权限。 因为某些Web 服务器上保存着重要的信息, 只想发给特定用户通信的权限。
- 无法判定请求是来自何方、 出自谁手。
- 即使是无意义的请求也会照单全收。 无法阻止海量请求下的 DoS 攻击( Denial of Service, 拒绝服务攻击)。
实验到我们的非对称加密算法的公钥出现的问题
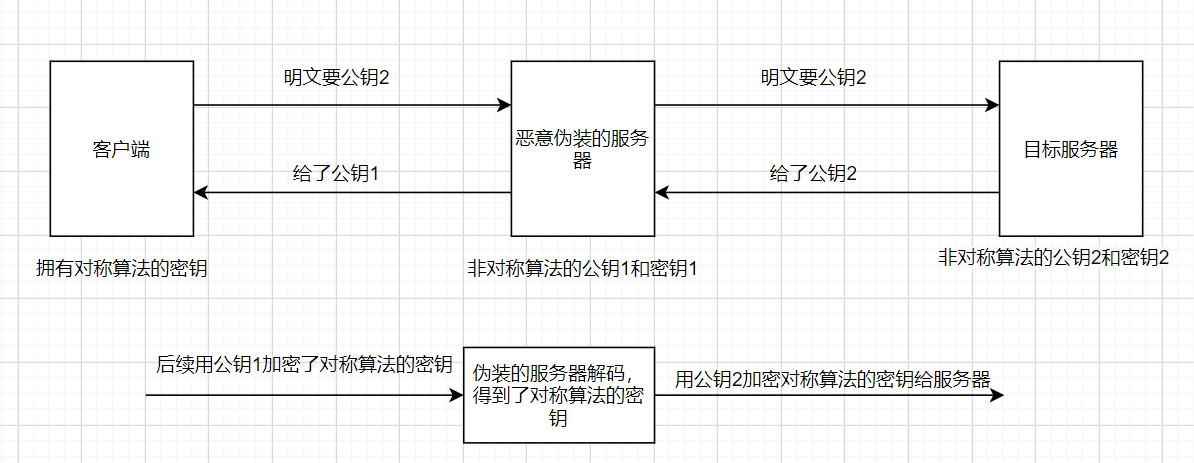
- 因为中间恶意的篡改,让客户端接收的不是真正服务器的公钥,客户端发出的公钥加密算法的对称密钥能被中间恶意的人知道,这样对称加密算法的传输也没有了加密效果
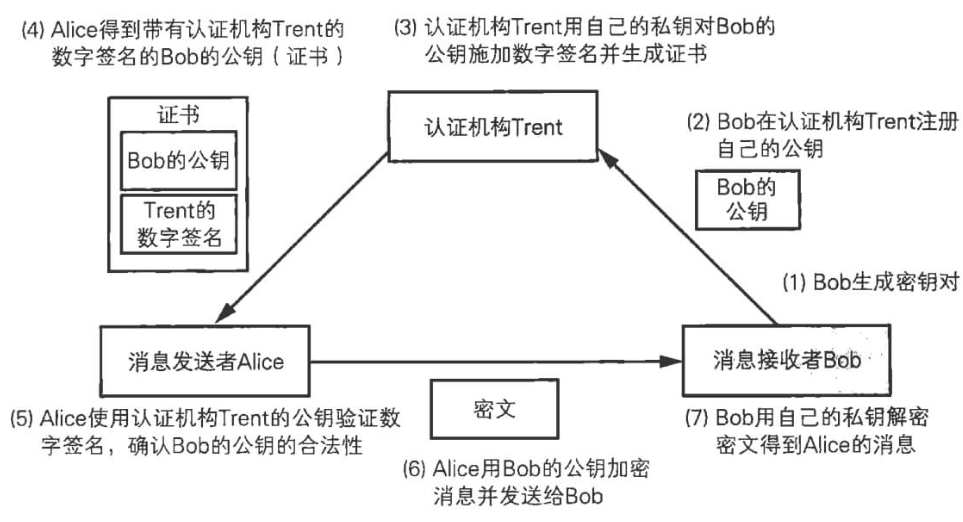
证书(CA解决)确认对方身份问题
- 首先,明确证书的作用,证书是由公正处给服务器颁发一个证书(运营执照),上面写明了服务器是谁,提供什么服务,公证处的的签名,所以我们的客户端收到的不仅仅是一个公钥本身,而是一套围绕公钥建立的证明体系
为了解决上述问题, 可以使用由数字证书认证机构(CA, CertificateAuthority) 和其相关机关颁发的公开密钥证书。数字证书认证机构处于客户端与服务器双方都可信赖的第三方机构的立场上。 威瑞信(VeriSign) 就是其中一家非常有名的数字证书认证机构。
我们来介绍一下数字证书认证机构的业务流程。 首先, 服务器的运营人员向数字证书认证机构提出公开密钥的申请。 数字证书认证机构在判明提出申请者的身份之后, 会对已申请的公开密钥做数字签名, 然后分配这个已签名的公开密钥, 并将该公开密钥放入公钥证书后绑定在一起。
- 服务器会将这份由数字证书认证机构颁发的公钥证书发送给客户端,
- 以进行公开密钥加密方式通信。 公钥证书也可叫做数字证书或直接称为证书。
服务器对于CA应该做什么
-
服务器生成了自己的非对称算法的公钥和私钥
-
然后服务器找CA为它颁发证书(现在中,要开店,需要先找工商局办理营业执照)
- 服务器需要提供直接的信息,比如不限于 1域名 2服务器相关的信息:谁,何处,3我们服务器的公钥
- 将上述信息进行数字摘要的摘要信息
- 然后通过CA的私钥对数据加密,得到了数字证书
- 当服务器启动的时候,需要配置,把自己的证书,公钥,私钥存在地址里,类比于(开店的时候把营业执照挂到墙上)
-
当我们的客户端发起的请求的时候,服务器把带有机构认证的证书直接给到客户端,我们的客户端会有CA机构的公钥,对证书进行解密
- 数字签名也是利用了非对称性密钥的特性,但是和公钥加密完全颠倒过来:仍然公布公钥,但是用你的私钥加密数据,然后把加密的数据公布出去,这就是数字签名。证明这些数据确实是由你本人发出的
-
客户端再经过摘要技术算法,(域名为主的信息+公钥信息)得出了新的摘要和证书中的老摘要做对比,说明我们的数据是原始的数据
- 解决之前HTTP无法证明报文的完整性, 所以有可能已遭篡改
-
然后我们的服务端就拿到了服务器的公钥,下面的操作就跟上面实现加密传输对称加密算法的私钥,就可以完成安全进行传输数据
关于客户端怎么知道的公钥的
- CA公钥我们怎么知道的呢?CA机构是写死再系统中的,安装OS的软件的时候自带了或者植入到我们的浏览器中,甚至再硬件中我们就烧录了信任的CA机构,当然CA机构很多,不可能写死或者烧录所有的CA机构
- 我们通过信任链这种方式来完成,我们只写死ROOT CA,然后我们可以通过ROOT CA为新的CA来担保是可信任的
- 如果CA中有叛徒,那么风险就会非常大,类似公安局跟黑社会串在一起了
为什么证书起作用和其他证书
证明组织真实性的 EV SSL 证书
证书的一个作用是用来证明作为通信一方的服务器是否规范, 另外一个作用是可确认对方服务器背后运营的企业是否真实存在。拥有该特性的证书就是 EV SSL证书(Extended Validation SSLCertificate) 。EV SSL证书是基于国际标准的认证指导方针颁发的证书。 其严格规定了对运营组织是否真实的确认方针, 因此, 通过认证的Web 网站能够获得更高的认可度。持有 EV SSL证书的 Web 网站的浏览器地址栏处的背景色是绿色的, 从视觉上就能一眼辨别出。 而且在地址栏的左侧显示了 SSL
- 证书中记录的组织名称以及颁发证书的认证机构的名称。
- 上述机制的原意图是为了防止用户被钓鱼攻击(Phishing) , 但就效果上来讲, 还得打一个问号。 很多用户可能不了解 EV SSL证书相关的知识, 因此也不太会留意它。
用以确认客户端的客户端证书
- HTTPS 中还可以使用客户端证书。 以客户端证书进行客户端认证, 证明服务器正在通信的对方始终是预料之内的客户端, 其作用跟服务器证书如出一辙。
- 但客户端证书仍存在几处问题点。 其中的一个问题点是证书的获取及发布。
- 想获取证书时, 用户得自行安装客户端证书。 但由于客户端证书是要付费购买的, 且每张证书对应到每位用户也就意味着需支付和用户数对等的费用。 另外, 要让知识层次不同的用户们自行安装证书, 这件事本身也充满了各种挑战。
- 现状是, 安全性极高的认证机构可颁发客户端证书但仅用于特殊用途的业务。 比如那些可支撑客户端证书支出费用的业务。
- 例如, 银行的网上银行就采用了客户端证书。 在登录网银时不仅要求用户确认输入 ID 和密码, 还会要求用户的客户端证书, 以确认用户是否从特定的终端访问网银。
- 客户端证书存在的另一个问题点是
- 客户端证书毕竟只能用来证明客户端实际存在, 而不能用来证明用户本人的真实有效性。 也就是说, 只要获得了安装有客户端证书的计算机的使用权限, 也就意味着同时拥有了客户端证书的使用权限。
认证机构信誉第一
- SSL机制中介入认证机构之所以可行, 是因为建立在其信用绝对可靠这一大前提下的。 然而, 2011 年 7 月, 荷兰的一家名叫DigiNotar 的认证机构曾遭黑客不法入侵, 颁布了 google.com 和twitter.com 等网站的伪造证书事件。 这一事件从根本上撼动了SSL的可信度。
- 因为伪造证书上有正规认证机构的数字签名, 所以浏览器会判定该证书是正当的。 当伪造的证书被用做服务器伪装之时, 用户根本无法察觉到。
- 虽然存在可将证书无效化的证书吊销列表(Certificate RevocationList, CRL) 机制, 以及从客户端删除根证书颁发机构(RootCertificate Authority, RCA) 的对策, 但是距离生效还需要一段时间, 而在这段时间内, 到底会有多少用户的利益蒙受损失就不得而知了。
由自认证机构颁发的证书称为自签名证书
-
如果使用 OpenSSL这套开源程序, 每个人都可以构建一套属于自己的认证机构, 从而自己给自己颁发服务器证书。 但该服务器证书在互联网上不可作为证书使用, 似乎没什么帮助。
-
独立构建的认证机构叫做自认证机构, 由自认证机构颁发的“无用”证书也被戏称为自签名证书。
-
浏览器访问该服务器时, 会显示“无法确认连接安全性”或“该网站的安全证书存在问题”等警告消息。
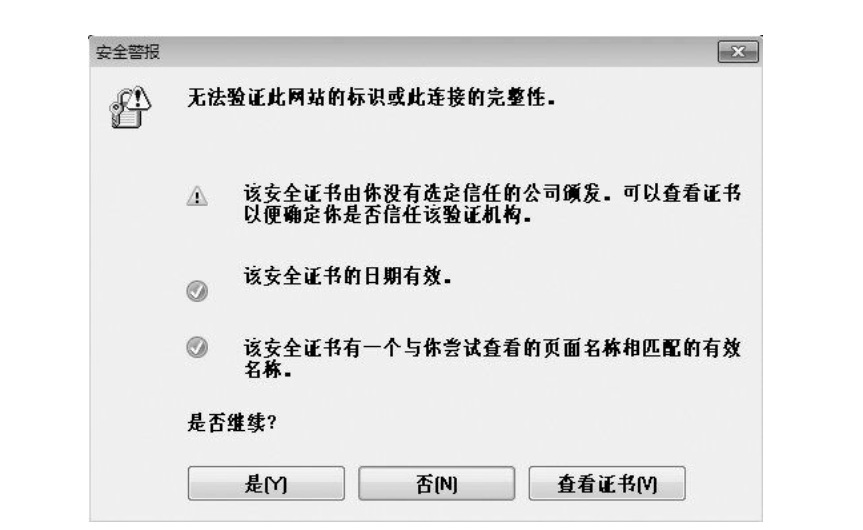
-
由自认证机构颁发的服务器证书之所以不起作用, 是因为它无法消除伪装的可能性。 自认证机构能够产生的作用顶多也就是自己对外宣称“我是○○”的这种程度。 即使采用自签名证书, 通过 SSL加密之后, 可能偶尔还会看见通信处在安全状态的提示, 可那也是有问题的。 因为就算加密通信, 也不能排除正在和已经过伪装的假服务器保持通信。
-
值得信赖的第三方机构介入认证, 才能让已植入在浏览器内的认证机构颁布的公开密钥发挥作用, 并借此证明服务器的真实性。
-
中级认证机构的证书可能会变成自认证证书
-
多数浏览器内预先已植入备受信赖的认证机构的证书, 但也有一小部分浏览器会植入中级认证机构的证书。对于中级认证机构颁发的服务器证书, 某些浏览器会以正规的证书来对待, 可有的浏览器会当作自签名证书。
完整的安全的传输机制
- 服务器开始之前,我们需要找CA去颁布证书:证书里面包含(服务器的核心信息+服务的公钥+经过信息的摘要),然后用CA的私钥进行加密得到我们的CA证书
- 客户端请求服务器的证书,客户端验证证书的安全性(通过CA的公钥进行解密)和准确性(通过比较证书中的消息摘要和我们收到信息的算出的摘要),通过验证了安全性和准确性,我们得到了对应服务器的公钥
- 按生成对称加密密钥的公钥加密我们的客户端的对称加密的私钥,传递我们的客户端的对称加密的密钥给我们服务器,服务器得到了对称加密密钥
- 双方就通过对称加密密钥+对称加密算法,进行请求/响应的加密传输
HTTPS存在的问题
HTTPS 也存在一些问题, 那就是当使用 SSL时, 它的处理速度会变慢。
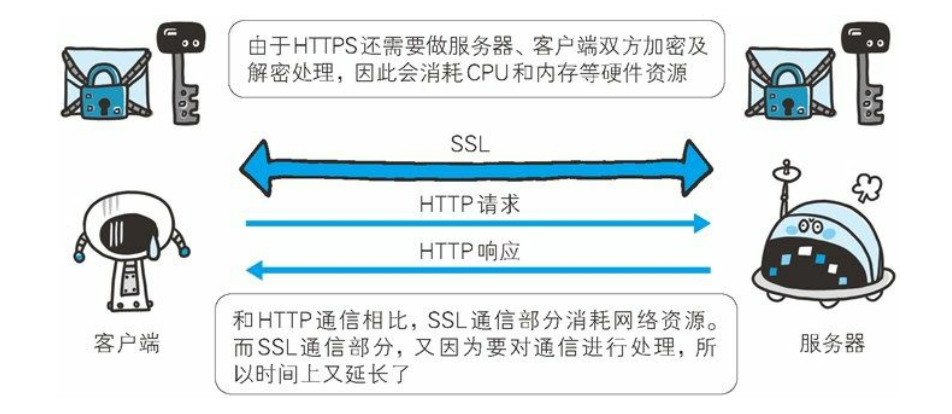
SSL的慢分两种
- 一种是指通信慢。
- 另一种是指由于大量消耗CPU 及内存等资源, 导致处理速度变慢。
HTTPS和使用 HTTP 相比, 网络负载可能会变慢 2 到 100 倍。 除去和TCP 连接、 发送 HTTP 请求 • 响应以外, 还必须进行 SSL通信,因此整体上处理通信量不可避免会增加。另一点是 SSL必须进行加密处理。 在服务器和客户端都需要进行加密和解密的运算处理。 因此从结果上讲, 比起 HTTP 会更多地消耗服务器和客户端的硬件资源, 导致负载增强。针对速度变慢这一问题, 并没有根本性的解决方案, 我们会使用SSL加速器这种(专用服务器) 硬件来改善该问题。 该硬件为SSL通信专用硬件, 相对软件来讲, 能够提高数倍 SSL的计算速度。 仅在 SSL处理时发挥 SSL加速器的功效, 以分担负载。
为什么不一直使用 HTTPS
既然 HTTPS 那么安全可靠, 那为何所有的 Web 网站不一直使用HTTPS ?
- 其中一个原因是, 因为与纯文本通信相比, 加密通信会消耗更多的CPU 及内存资源。 如果每次通信都加密, 会消耗相当多的资源, 平摊到一台计算机上时, 能够处理的请求数量必定也会随之减少。因此, 如果是非敏感信息则使用 HTTP 通信, 只有在包含个人信息等敏感数据时, 才利用 HTTPS 加密通信。
- 特别是每当那些访问量较多的 Web 网站在进行加密处理时, 它们所承担着的负载不容小觑。 在进行加密处理时, 并非对所有内容都进行加密处理, 而是仅在那些需要信息隐藏时才会加密, 以节约资源。
- 除此之外, 想要节约购买证书的开销也是原因之一。要进行 HTTPS 通信, 证书是必不可少的。 而使用的证书必须向认证机构(CA) 购买。 证书价格可能会根据不同的认证机构略有不同。 通常, 一年的授权需要数万日元(现在一万日元大约折合 600人民币) 。那些购买证书并不合算的服务以及一些个人网站, 可能只会选择采用 HTTP 的通信方式。
确认访问用户身份的验证
因为我们对于某些Web资源,我们有只限定给某些人看的需求,所以我们需要进行对访问服务器的用户进行验证
何为认证
计算机本身无法判断坐在显示器前的使用者的身份。 进一步说, 也无法确认网络的那头究竟有谁。为了弄清究竟是谁在访问服务器, 就得让对方的客户端自报家门。可是, 就算正在访问服务器的对方声称自己是ueno, 身份是否属实这点却也无从谈起。 为确认 ueno 本人是否真的具有访问系统的权限,就需要核对“登录者本人才知道的信息”、 “登录者本人才会有的信息”。核对的信息通常是指以下这些。
- 密码: 只有本人才会知道的字符串信息。
- 动态令牌: 仅限本人持有的设备内显示的一次性密码。
- 数字证书: 仅限本人( 终端) 持有的信息。
- 生物认证: 指纹和虹膜等本人的生理信息。
- IC 卡等: 仅限本人持有的信息。
HTTP1.1 使用的认证方式
- BASIC 认证( 基本认证)
- DIGEST 认证( 摘要认证)
- SSL 客户端认证
- FormBase 认证( 基于表单认证)
BASIC 认证
BASIC 认证(基本认证) 是从 HTTP/1.0 就定义的认证方式
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uQaMbm1E-1681456831822)(C:\Users\lsc07\Desktop\学习资料\19typora笔记\5计算机网络\HTTP.assets\202304100902789.png)]
- 步骤 1: 当请求的资源需要 BASIC 认证时, 服务器会随状态码 401Authorization Required, 返回带 WWW-Authenticate 首部字段的响应。该字段内包含认证的方式(BASIC) 及 Request-URI 安全域字符串(realm) 。
- 步骤 2: 接收到状态码 401 的客户端为了通过 BASIC 认证, 需要将用户 ID 及密码发送给服务器。 发送的字符串内容是由用户 ID 和密码构成, 两者中间以冒号(:) 连接后, 再经过 Base64 编码处理。假设用户 ID 为 guest, 密码是 guest, 连接起来就会形成 guest:guest 这样的字符串。 然后经过 Base64 编码, 最后的结果即是Z3Vlc3Q6Z3Vlc3Q=。 把这串字符串写入首部字段 Authorization 后,发送请求。当用户代理为浏览器时, 用户仅需输入用户 ID 和密码即可, 之后,浏览器会自动完成到 Base64 编码的转换工作。
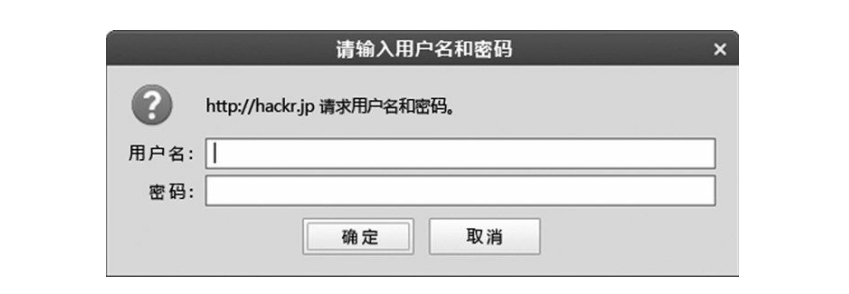
- 步骤 3: 接收到包含首部字段 Authorization 请求的服务器, 会对认证信息的正确性进行验证。 如验证通过, 则返回一条包含 Request-URI资源的响应。
BASIC 认证虽然采用 Base64 编码方式, 但这不是加密处理。 不需要任何附加信息即可对其解码。 换言之, 由于明文解码后就是用户 ID和密码, 在 HTTP 等非加密通信的线路上进行 BASIC 认证的过程中, 如果被人窃听, 被盗的可能性极高。
另外, 除此之外想再进行一次 BASIC 认证时, 一般的浏览器却无法实现认证注销操作, 这也是问题之一。BASIC 认证使用上不够便捷灵活, 且达不到多数 Web 网站期望的安全性等级, 因此它并不常用。
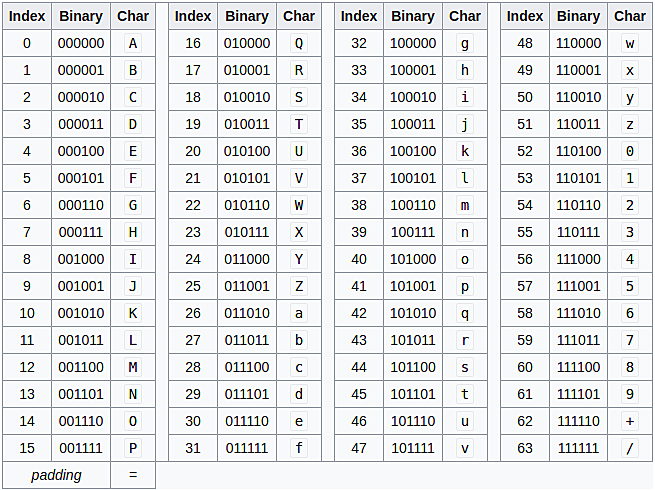
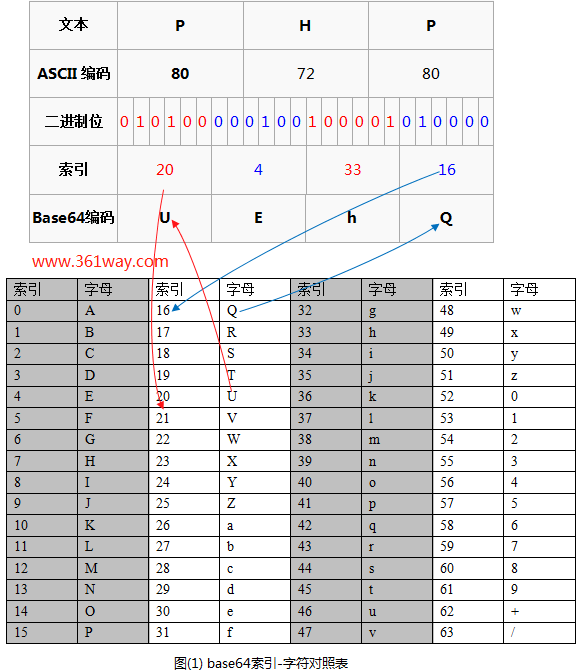
Base64,顾名思义,就是包括小写字母a-z、大写字母A-Z、数字0-9、符号"+“、”/“一共64个字符的字符集,(另加一个“=”,实际是65个字符,至于为什么还会有一个“=”,这个后面再说)。任何符号都可以转换成这个字符集中的字符,这个转换过程就叫做base64编码。
字符串abc对应3个字节,一共24位,按6位为一组可分为4组,在每组的高位补上00,经过转换,abc 的 base64 编码是 YWJj, 由原来的3个字母变成了4个,所以base64会比原字符串更长。
那问题来了,假设原始字符串不够3个字节,只有一个字节或者两个字节怎么办?
以BC两个字节为例, 按照上面的转换逻辑,经过编码转换,第三个字节只有4位,需要在第三组前后都要加两个0,转换后的字符串是 QkM。 为了凑齐4个字节,还要在末尾补上一个"="号,最后得到的base64编码就是: "QkM=

DIGEST 认证
为弥补 BASIC 认证存在的弱点, 从 HTTP/1.1 起就有了 DIGEST 认证。 DIGEST 认证同样使用质询 / 响应的方式(challenge/response) , 但不会像 BASIC 认证那样直接发送明文密码。
- 所谓质询响应方式是指, 一开始一方会先发送认证要求给另一方, 接着使用从另一方那接收到的质询码计算生成响应码。 最后将响应码返回给对方进行认证的方式。因为发送给对方的只是响应摘要及由质询码产生的计算结果, 所以比起 BASIC 认证, 密码泄露的可能性就降低了

- 步骤 1: 请求需认证的资源时, 服务器会随着状态码 401Authorization Required, 返回带 WWW-Authenticate 首部字段的响应。该字段内包含质问响应方式认证所需的临时质询码(随机数,nonce) 。
- 首部字段 WWW-Authenticate 内必须包含 realm 和 nonce 这两个字段的信息。 客户端就是依靠向服务器回送这两个值进行认证的。nonce 是一种每次随返回的 401 响应生成的任意随机字符串。 该字符串通常推荐由 Base64 编码的十六进制数的组成形式, 但实际内容依赖服务器的具体实现。
- 步骤 2: 接收到 401 状态码的客户端, 返回的响应中包含 DIGEST 认证必须的首部字段 Authorization 信息。首部字段 Authorization 内必须包含username、 realm、 nonce、 uri 和response 的字段信息。
- 其中, realm 和 nonce 就是之前从服务器接收到的响应中的字段。
- username 是 realm 限定范围内可进行认证的用户名。
- uri(digest-uri) 即 Request-URI 的值, 但考虑到经代理转发后Request-URI 的值可能被修改, 因此事先会复制一份副本保存在 uri内。
- response 也可叫做 Request-Digest, 存放经过 MD5 运算后的密码字符串, 形成响应码。
- 响应中其他的实体请参见第 6 章的请求首部字段 Authorization。
- 步骤 3: 接收到包含首部字段 Authorization 请求的服务器, 会确认认证信息的正确性。 认证通过后则返回包含 Request-URI 资源的响应。并且这时会在首部字段 Authentication-Info 写入一些认证成功的相关信息。
DIGEST 认证提供了高于 BASIC 认证的安全等级, 但是和 HTTPS 的客户端认证相比仍旧很弱。 DIGEST 认证提供防止密码被窃听的保护机制, 但并不存在防止用户伪装的保护机制。DIGEST 认证和 BASIC 认证一样, 使用上不那么便捷灵活, 且仍达不到多数 Web 网站对高度安全等级的追求标准。 因此它的适用范围也有所受限。
SSL 客户端认证
- 从使用用户 ID 和密码的认证方式方面来讲, 只要二者的内容正确,即可认证是本人的行为。 但如果用户 ID 和密码被盗, 就很有可能被第三者冒充。 利用 SSL客户端认证则可以避免该情况的发生。SSL客户端认证是借由 HTTPS 的客户端证书完成认证的方式。 凭借客户端证书认证, 服务器可确认访问是否来自已登录的客户端。
SSL 客户端认证的认证步骤
为达到 SSL客户端认证的目的, 需要事先将客户端证书分发给客户端, 且客户端必须安装此证书。
- 步骤 1: 接收到需要认证资源的请求, 服务器会发送 Certificate Request 报文, 要求客户端提供客户端证书。
- 步骤 2: 用户选择将发送的客户端证书后, 客户端会把客户端证书信息以 Client Certificate 报文方式发送给服务器
- 步骤 3: 服务器验证客户端证书验证通过后方可领取证书内客户端的公开密钥, 然后开始 HTTPS 加密通信。
SSL 客户端认证采用双因素认证
- 在多数情况下, SSL客户端认证不会仅依靠证书完成认证, 一般会和基于表单认证 组合形成一种双因素认证(Two-factorauthentication) 来使用。 所谓双因素认证就是指, 认证过程中不仅需要密码这一个因素, 还需要申请认证者提供其他持有信息, 从而作为
- 另一个因素, 与其组合使用的认证方式。换言之, 第一个认证因素的 SSL客户端证书用来认证客户端计算机,另一个认证因素的密码则用来确定这是用户本人的行为。通过双因素认证后, 就可以确认是用户本人正在使用匹配正确的计算机访问服务器。
基于表单认证
基于表单的认证方法并不是在 HTTP 协议中定义的。 客户端会向服务器上的 Web 应用程序发送登录信息(Credential) , 按登录信息的验证结果认证。
根据 Web 应用程序的实际安装, 提供的用户界面及认证方式也各不相同。
- 多数情况下, 输入已事先登录的用户 ID(通常是任意字符串或邮件地址) 和密码等登录信息后, 发送给 Web 应用程序, 基于认证结果来决定认证是否成功。
认证多半为基于表单认证
- 由于使用上的便利性及安全性问题, HTTP 协议标准提供的 BASIC 认证和 DIGEST 认证几乎不怎么使用。 另外, SSL客户端认证虽然具有高度的安全等级, 但因为导入及维持费用等问题, 还尚未普及。
- 比如 SSH 和 FTP 协议, 服务器与客户端之间的认证是合乎标准规范的, 并且满足了最基本的功能需求上的安全使用级别, 因此这些协议的认证可以拿来直接使用。 但是对于 Web 网站的认证功能, 能够满足其安全使用级别的标准规范并不存在, 所以只好使用由 Web 应用程序各自实现基于表单的认证方式。不具备共同标准规范的表单认证, 在每个 Web 网站上都会有各不相同的实现方式。 如果是全面考虑过安全性能而实现的表单认证, 那么就能够具备高度的安全等级。 但在表单认证的实现中存在问题的 Web网站也是屡见不鲜。
Session 管理及 Cookie 应用
-
基于表单认证的标准规范尚未有定论, 一般会使用 Cookie 来管理Session(会话) 。
-
基于表单认证本身是通过服务器端的 Web 应用, 将客户端发送过来的用户 ID 和密码与之前登录过的信息做匹配来进行认证的。但鉴于 HTTP 是无状态协议, 之前已认证成功的用户状态无法通过协议层面保存下来。 即, 无法实现状态管理, 因此即使当该用户下一次继续访问, 也无法区分他与其他的用户。 于是我们会使用 Cookie 来管理 Session, 以弥补 HTTP 协议中不存在的状态管理功能。
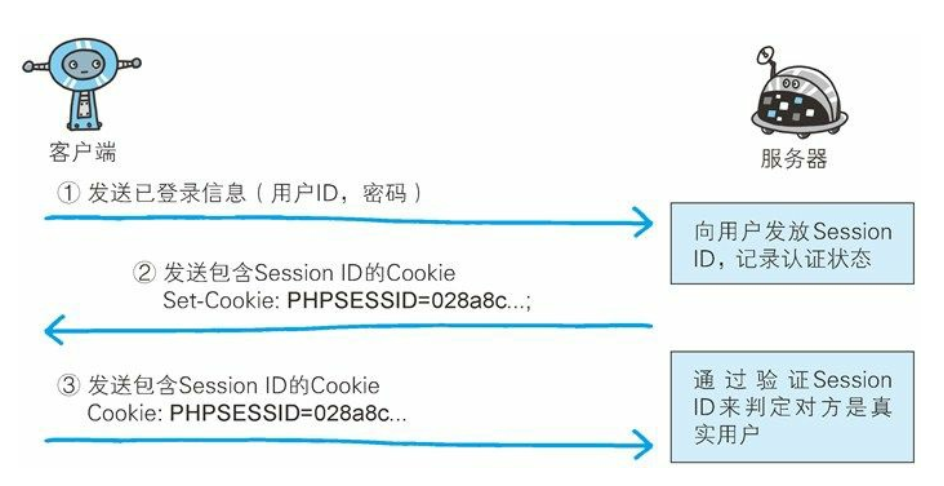
-
步骤 1: 客户端把用户 ID 和密码等登录信息放入报文的实体部分,通常是以 POST 方法把请求发送给服务器。 而这时, 会使用 HTTPS通信来进行 HTML表单画面的显示和用户输入数据的发送。
-
步骤 2: 服务器会发放用以识别用户的 Session ID。 通过验证从客户端发送过来的登录信息进行身份认证, 然后把用户的认证状态与Session ID 绑定后记录在服务器端。向客户端返回响应时, 会在首部字段 Set-Cookie 内写入 SessionID(如 PHPSESSID=028a8c…) 。你可以把 Session ID 想象成一种用以区分不同用户的等位号。然而, 如果 Session ID 被第三方盗走, 对方就可以伪装成你的身份进行恶意操作了。 因此必须防止 Session ID 被盗, 或被猜出。 为了做到这点, Session ID 应使用难以推测的字符串, 且服务器端也需要进行有效期的管理, 保证其安全性。另外, 为减轻跨站脚本攻击(XSS) 造成的损失, 建议事先在 Cookie内加上 httponly 属性。
-
步骤 3: 客户端接收到从服务器端发来的 Session ID 后, 会将其作为Cookie 保存在本地。 下次向服务器发送请求时, 浏览器会自动发送Cookie, 所以 Session ID 也随之发送到服务器。 服务器端可通过验证接收到的 Session ID 识别用户和其认证状态。
除了以上介绍的应用实例, 还有应用其他不同方法的案例。另外, 不仅基于表单认证的登录信息及认证过程都无标准化的方法,服务器端应如何保存用户提交的密码等登录信息等也没有标准化。通常, 一种安全的保存方法是, 先利用给密码加盐(salt)的方式增加额外信息, 再使用散列(hash) 函数计算出散列值后保存。 但是我们也经常看到直接保存明文密码的做法, 而这样的做法具有导致密码泄露的风险。
- 而现在我们更为常见的一种验证用户的方式是token
基于 HTTP 的功能追加协议
- 虽然 HTTP 协议既简单又简捷, 但随着时代的发展, 其功能使用上捉襟见肘的疲态已经凸显。 本章我们将讲解基于 HTTP 新增的功能的协议
- 在建立 HTTP 标准规范时, 制订者主要想把 HTTP 当作传输 HTML文档的协议。 随着时代的发展, Web 的用途更具多样性, 比如演化成在线购物网站、 SNS(Social Networking Service, 社交网络服务) 、 企业或组织内部的各种管理工具, 等等。而这些网站所追求的功能可通过 Web 应用和脚本程序实现。 即使这些功能已经满足需求, 在性能上却未必最优, 这是因为 HTTP 协议上的限制以及自身性能有限。
- HTTP 功能上的不足可通过创建一套全新的协议来弥补。 可是目前基于 HTTP 的 Web 浏览器的使用环境已遍布全球, 因此无法完全抛弃HTTP。 有一些新协议的规则是基于 HTTP 的, 并在此基础上添加了新的功能。
具体存在那些缺陷的例子
- 一条连接上只可发送一个请求。
- 请求只能从客户端开始。 客户端不可以接收除响应以外的指令。
- 请求 / 响应首部未经压缩就发送。 首部信息越多延迟越大。
- 发送冗长的首部。 每次互相发送相同的首部造成的浪费较多。
- 可任意选择数据压缩格式。非强制压缩发送。
消除 HTTP 瓶颈的 SPDY
Google 在 2010 年发布了 SPDY(取自 SPeeDY, 发音同 speedy) , 其开发目标旨在解决 HTTP 的性能瓶颈, 缩短 Web 页面的加载时间(50%) 。SPDY - The Chromium Projects
Ajax 的解决方法
Ajax(Asynchronous JavaScript and XML, 异 步 JavaScript 与 XML技术) 是一种有效利用 JavaScript 和 DOM(Document Object Model, 文档对象模型) 的操作, 以达到局部 Web 页面替换加载的异步通信手段。
- 和以前的同步通信相比, 由于它只更新一部分页面, 响应中传输的数据量会因此而减少, 这一优点显而易见。Ajax 的核心技术是名为 XMLHttpRequest 的 API, 通过 JavaScript 脚本语言的调用就能和服务器进行 HTTP 通信。
- 借由这种手段, 就能从已加载完毕的 Web 页面上发起请求, 只更新局部页面。而利用 Ajax 实时地从服务器获取内容, 有可能会导致大量请求产生。 另外, Ajax 仍未解决 HTTP 协议本身存在的问题。
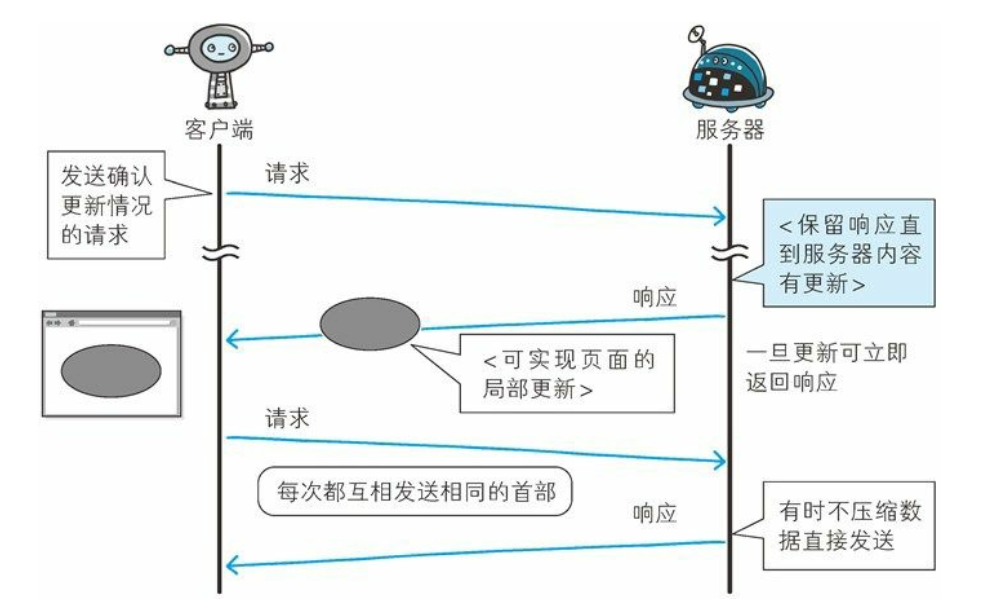
Comet 的解决方法
一旦服务器端有内容更新了, Comet 不会让请求等待, 而是直接给客户端返回响应。 这是一种通过延迟应答, 模拟实现服务器端向客户端推送(Server Push) 的功能。
-
通常, 服务器端接收到请求, 在处理完毕后就会立即返回响应, 但为了实现推送功能, Comet 会先将响应置于挂起状态, 当服务器端有内容更新时, 再返回该响应。 因此, 服务器端一旦有更新, 就可以立即反馈给客户端。
-
内容上虽然可以做到实时更新, 但为了保留响应, 一次连接的持续时间也变长了。 期间, 为了维持连接会消耗更多的资源。 另外, Comet也仍未解决 HTTP 协议本身存在的问题。
SPDY的设计与功能
SPDY的目标
- 陆续出现的 Ajax 和 Comet 等提高易用性的技术, 一定程度上使 HTTP得到了改善, 但 HTTP 协议本身的限制也令人有些束手无策。 为了进行根本性的改善, 需要有一些协议层面上的改动。处于持续开发状态中的 SPDY 协议, 正是为了在协议级别消除 HTTP所遭遇的瓶颈。
SPDY 没有完全改写 HTTP 协议, 而是在 TCP/IP 的应用层与运输层之间通过新加会话层的形式运作。 同时, 考虑到安全性问题, SPDY 规定通信中使用 SSL。
SPDY 以会话层的形式加入, 控制对数据的流动, 但还是采用 HTTP建立通信连接。 因此, 可照常使用 HTTP 的 GET 和 POST 等方 法、Cookie 以及 HTTP 报文等。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ShOdYRwI-1681456831826)(C:\Users\lsc07\Desktop\学习资料\19typora笔记\5计算机网络\HTTP.assets\image-20230411191754894.png)]
使用 SPDY 后, HTTP 协议额外获得以下功能。
多路复用流
- 通过单一的 TCP 连接, 可以无限制处理多个 HTTP 请求。 所有请求的处理都在一条 TCP 连接上完成, 因此 TCP 的处理效率得到提高。
赋予请求优先级
- SPDY 不仅可以无限制地并发处理请求, 还可以给请求逐个分配优先级顺序。 这样主要是为了在发送多个请求时, 解决因带宽低而导致响应变慢的问题。
压缩 HTTP 首部
- 压缩 HTTP 请求和响应的首部。 这样一来, 通信产生的数据包数量和发送的字节数就更少了。
推送功能
- 支持服务器主动向客户端推送数据的功能。 这样, 服务器可直接发送数据, 而不必等待客户端的请求。
服务器提示功能
- 服务器可以主动提示客户端请求所需的资源。 由于在客户端发现资源之前就可以获知资源的存在, 因此在资源已缓存等情况下, 可以避免发送不必要的请求。
SPDY消除 Web 瓶颈了吗
- 希望使用 SPDY 时, Web 的内容端不必做什么特别改动, 而 Web 浏览器及 Web 服务器都要为对应 SPDY 做出一定程度上的改动。 有好几家 Web 浏览器已经针对 SPDY 做出了相应的调整。
- 另外, Web 服务器也进行了实验性质的应用, 但把该技术导入实际的 Web 网站却进展不佳。因为 SPDY 基本上只是将单个域名( IP 地址) 的通信多路复用, 所以当一个 Web 网站上使用多个域名下的资源, 改善效果就会受到限制。
- SPDY 的确是一种可有效消除 HTTP 瓶颈的技术, 但很多 Web 网站存在的问题并非仅仅是由 HTTP 瓶颈所导致。 对 Web 本身的速度提升, 还应该从其他可细致钻研的地方入手, 比如改善 Web 内容的编写方式等。
浏览器进行全双工通信的WebSocket
浏览器进行全双工通信的
利用 Ajax 和 Comet 技术进行通信可以提升 Web 的浏览速度。 但问题在于通信若使用 HTTP 协议, 就无法彻底解决瓶颈问题。 WebSocket网络技术正是为解决这些问题而实现的一套新协议及 API。
当时筹划将 WebSocket 作为 HTML5 标准的一部分, 而现在它却逐渐变成了独立的协议标准。 WebSocket 通信协议在 2011 年 12 月 11 日,
被 RFC 6455 - The WebSocket Protocol 定为标准。
WebSocket 的设计与功能
WebSocket, 即 Web 浏览器与 Web 服务器之间全双工通信标准。 其中, WebSocket 协议由 IETF 定为标准, WebSocket API 由 W3C 定为标准。 仍在开发中的 WebSocket 技术主要是为了解决 Ajax 和 Comet里 XMLHttpRequest 附带的缺陷所引起的问题。
一旦 Web 服务器与客户端之间建立起 WebSocket 协议的通信连接,之后所有的通信都依靠这个专用协议进行。 通信过程中可互相发送JSON、 XML、 HTML或图片等任意格式的数据。
由于是建立在 HTTP 基础上的协议, 因此连接的发起方仍是客户端,而一旦确立 WebSocket 通信连接, 不论服务器还是客户端, 任意一方都可直接向对方发送报文。
WebSocket 协议的主要特点
- 推送功能:支持由服务器向客户端推送数据的推送功能。 这样, 服务器可直接发送数据, 而不必等待客户端的请求。
- 减少通信量:只要建立起 WebSocket 连接, 就希望一直保持连接状态。 和 HTTP 相比, 不但每次连接时的总开销减少, 而且由于 WebSocket 的首部信息很小, 通信量也相应减少了。
- 为了实现 WebSocket 通信, 在 HTTP 连接建立之后, 需要完成一次“握手”(Handshaking) 的步骤。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uW5jCqUF-1681456831827)(C:\Users\lsc07\Desktop\学习资料\19typora笔记\5计算机网络\HTTP.assets\image-20230411193502276.png)]
期盼已久的 HTTP/2.0
目前主流的 HTTP/1.1 标准, 自 1999 年发布的 RFC2616 之后再未进行过改订。 SPDY 和 WebSocket 等技术纷纷出现, 很难断言 HTTP/1.1仍是适用于当下的 Web 的协议。
HTTP/2.0 的特点
HTTP/2.0 的目标是改善用户在使用 Web 时的速度体验。 由于基本上都会先通过 HTTP/1.1 与 TCP 连接, 现在我们以下面的这些协议为基础
- SPDY
- HTTP Speed + Mobility
- Network-Friendly HTTP Upgrade
HTTP Speed + Mobility 由微软公司起草, 是用于改善并提高移动端通信时的通信速度和性能的标准。 它建立在 Google 公司提出的 SPDY与 WebSocket 的基础之上。
- Network-Friendly HTTP Upgrade 主要是在移动端通信时改善 HTTP 性能的标准。
- HTTP/2.0 的 7 项技术及讨论
- HTTP/2.0 围绕着主要的 7 项技术进行讨论, 现阶段(2012 年 8 月 13日) , 大都倾向于采用以下协议的技术。 但是, 讨论仍在持续, 所以不能排除会发生重大改变的可能性。
| 压缩 | SPDY、 Friendly |
|---|---|
| 多路复用 | SPDY |
| TLS 义务化 | Speed+ Mobility |
| 协商 | Speed+ Mobility, Friendly |
| 客户端拉曳(Client Pull) /服务器推送 (Server Push) | Speed+ Mobility |
| 流量控制 | SPDY |
| WebSocket | Speed+ Mobility |
注: HTTP Speed + Mobility 简写为 Speed + Mobility, Network-Friendly HTTP Upgrade 简写为 Friendly。
详解多路复用
在 HTTP/2 中,有两个非常重要的概念:帧(frame)和流(stream)。
帧(frame)
HTTP/2 中数据传输的最小单位,因此帧不仅要细分表达 HTTP/1.x 中的各个部分,也优化了 HTTP/1.x 表达得不好的地方,同时还增加了 HTTP/1.x 表达不了的方式。 每一帧都包含几个字段,有length、type、flags、stream identifier、frame playload等,
- 其中type 代表帧的类型,在 HTTP/2 的标准中定义了 10 种不同的类型, HEADERS frame 和 DATA frame。此外还有:
PRIORITY(设置流的优先级)RST_STREAM(终止流)SETTINGS(设置此连接的参数)PUSH_PROMISE(服务器推送)PING(测量 RTT)GOAWAY(终止连接)WINDOW_UPDATE(流量控制)CONTINUATION(继续传输头部数据)在 HTTP 2.0 中,它把数据报的两大部分分成了 header frame 和 data frame。也就是头部帧和数据体帧。
流(stream)
流: 存在于连接中的一个虚拟通道。流可以承载双向消息,每个流都有一个唯一的整数 ID。 HTTP/2 长连接中的数据包是不按请求-响应顺序发送的,一个完整的请求或响应(称一个数据流 stream,每个数据流都有一个独一无二的编号)可能会分成非连续多次发送。它具有如下几个特点:
- 双向性:同一个流内,可同时发送和接受数据。
- 有序性:流中被传输的数据就是二进制帧 。帧在流上的被发送与被接收都是按照顺序进行的。
- 并行性:流中的 二进制帧 都是被并行传输的,无需按顺序等待。
- 流的创建:流可以被客户端或服务器单方面建立, 使用或共享。
- 流的关闭:流也可以被任意一方关闭。
- HEADERS 帧在 DATA 帧前面。
- 流的 ID 都是奇数,说明是由客户端发起的,这是标准规定的,那么服务端发起的就是偶数了
持久连接
HTTP 协议的初始版本中, 每进行一次 HTTP 通信就要断开一次 TCP连接。
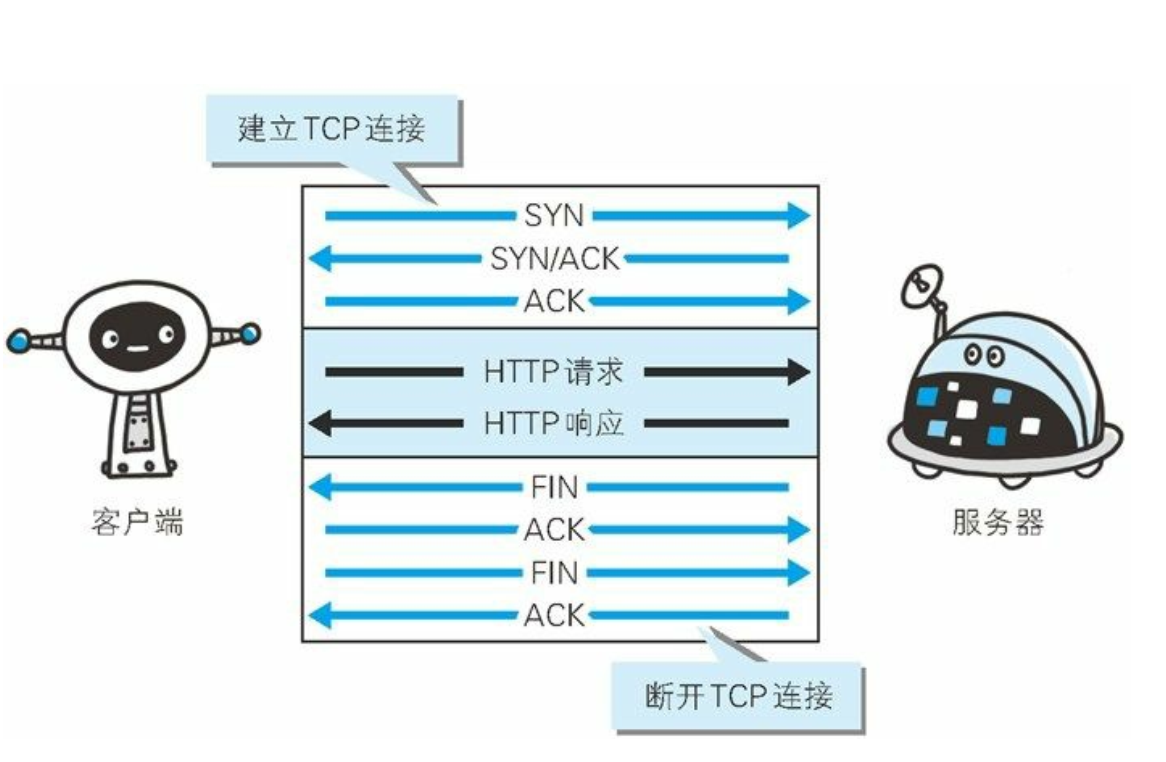
- 以当年的通信情况来说, 因为都是些容量很小的文本传输, 所以即使这样也没有多大问题。 可随着 HTTP 的普及, 文档中包含大量图片的情况多了起来。比如, 使用浏览器浏览一个包含多张图片的 HTML页面时, 在发送请求访问 HTML页面资源的同时, 也会请求该 HTML页面里包含的其他资源。 因此, 每次的请求都会造成无谓的 TCP 连接建立和断开, 增加通信量的开销。
- 为解决上述 TCP 连接的问题, HTTP/1.1 和一部分的 HTTP/1.0 想出了持久连接(HTTP Persistent Connections, 也称为 HTTP keep-alive 或HTTP connection reuse) 的方法。 持久连接的特点是, 只要任意一端没有明确提出断开连接, 则保持 TCP 连接状态。
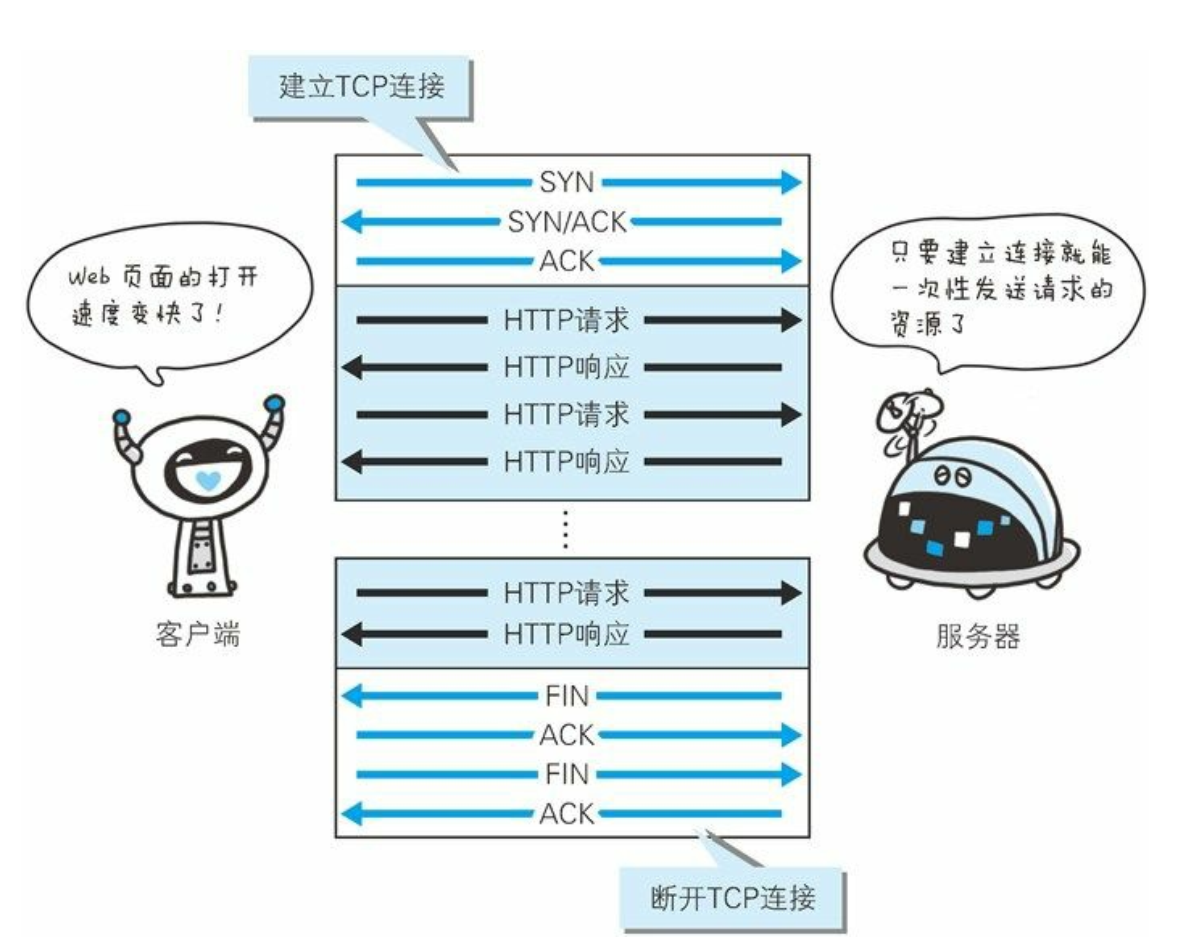
- 持久连接的好处在于减少了 TCP 连接的重复建立和断开所造成的额外开销, 减轻了服务器端的负载。 另外, 减少开销的那部分时间, 使HTTP 请求和响应能够更早地结束, 这样 Web 页面的显示速度也就相应提高了。
- 在 HTTP/1.1 中, 所有的连接默认都是持久连接, 但在 HTTP/1.0 内并未标准化。 虽然有一部分服务器通过非标准的手段实现了持久连接,但服务器端不一定能够支持持久连接。 毫无疑问, 除了服务器端, 客户端也需要支持持久连接。
Keep-Alive还是存在如下问题:
- 串行的文件传输。
- 同域并行请求限制带来的阻塞(6~8)个
管线化
- 持久连接使得多数请求以管线化(pipelining) 方式发送成为可能。 从前发送请求后需等待并收到响应, 才能发送下一个请求。 管线化技术出现后, 不用等待响应亦可直接发送下一个请求。
- 这样就能够做到同时并行发送多个请求, 而不需要一个接一个地等待响应了。
- 但是服务器需要按照顺序一个一个响应
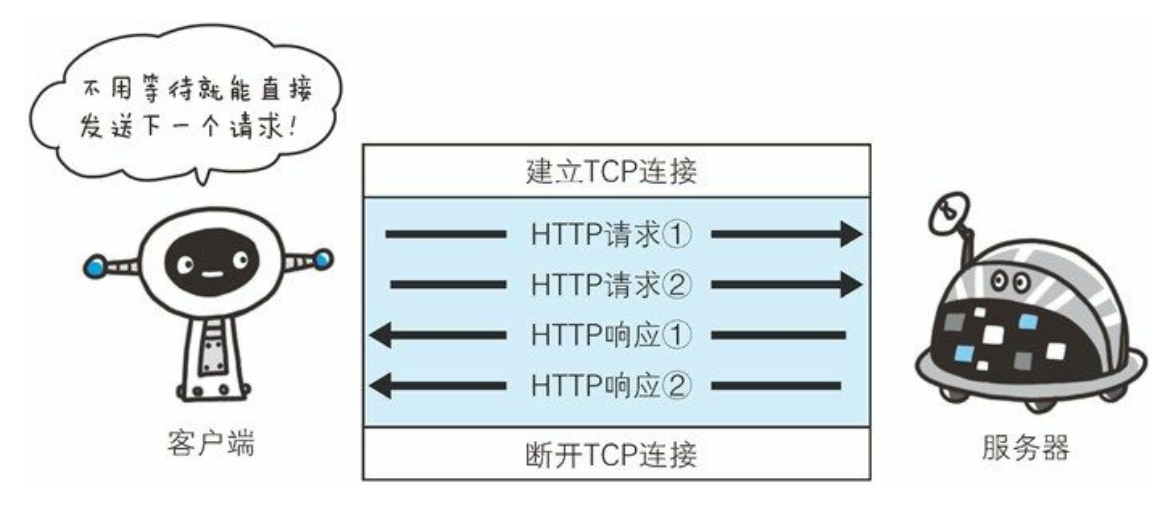
HTTP 管线化仍旧有阻塞的问题,若上一响应迟迟不回,后面的响应都会被阻塞到。
多路复用
多路复用代替原来的序列和阻塞机制。所有就是请求的都是通过一个 TCP 连接并发完成。因为在多路复用之前所有的传输是基于基础文本的,在多路复用中是基于二进制数据帧的传输、消息、流,所以可以做到乱序的传输。多路复用对同一域名下所有请求都是基于流,所以不存在同域并行的阻塞。多次请求如下图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Wp3Ku5hK-1681456831828)(C:\Users\lsc07\Desktop\学习资料\19typora笔记\5计算机网络\HTTP.assets\image-20230411195736520.png)]



















 2274
2274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











