







目录
nginx

介绍
nginx是一个http和高性能的开源Web服务器和反向代理服务器、邮件服务器软件、
方向代理服务器:作用就是负载均衡
协议 protocol:理解为一种语言,不同的程序之间沟通交流使用的,规定了数据在传输的过程中应该是什么样子的,由哪些组成,里面包含哪些内容等等。
协议在本质就是一个程序,用来封装我们的数据,把它想象成python里的字典等。(很多协议都是使用c语言编写)
超文本传输协议(Hypertext Transfer Protocol,简称HTTP):是一种用于在网络中传输超文本和其他资源的应用层协议。HTTP是Web应用程序的基础,用于客户端(如Web浏览器)与服务器之间的通信。
超文本(Hypertext)是一种文本的形式,可以包含引用其他文本的链接,使用户能够非线性地浏览和导航信息。与传统线性文本不同,超文本通过嵌入链接(超链接)将文本与其他相关内容或资源连接起来,使用户可以通过点击链接跳转到相关的文本、图像、音频、视频或其他多媒体元素。
超文本:html、css、js等语言编写的内容。
http协议使用场景:Web浏览器、Web应用程序开发、API交互、文件传输、数据推送、资源获取和缓存等
代理
正向代理(Forward Proxy)和反向代理(Reverse Proxy)是代理服务器的两种常见配置方式,它们在网络通信中扮演不同的角色和提供不同的功能。
-
正向代理(Forward Proxy):
正向代理是位于客户端和目标服务器之间的代理服务器。当客户端需要访问互联网上的资源时,它首先向正向代理发送请求,然后代理服务器将请求转发给目标服务器,并将目标服务器的响应返回给客户端。客户端对目标服务器的存在和身份信息一般是不可见的。使用场景:
- 突破网络限制:正向代理可以用于绕过网络限制,访问被屏蔽的网站或服务。
- 隐藏客户端身份:正向代理可以隐藏客户端的真实IP地址和身份,提高用户的隐私和安全性。
- 缓存和加速:正向代理可以缓存常用的响应结果,减少对目标服务器的请求,提高访问速度。
-
反向代理(Reverse Proxy):
反向代理是位于目标服务器和客户端之间的代理服务器。当客户端发送请求时,它并不直接与目标服务器通信,而是向反向代理发送请求。反向代理根据配置和负载均衡算法,将请求转发给一个或多个目标服务器,并将目标服务器的响应返回给客户端。客户端对目标服务器的存在和身份信息一般是不可见的。使用场景:
- 负载均衡:反向代理可以将客户端的请求分发给多个目标服务器,平衡服务器的负载,提高系统的性能和可扩展性。
- 安全性和保护:反向代理可以作为一个安全屏障,隐藏和保护后端目标服务器的真实IP地址和身份,提供额外的安全层。
- 缓存和加速:反向代理可以缓存目标服务器的响应结果,减少对目标服务器的请求,提高访问速度。
总结:
正向代理和反向代理是两种常见的代理服务器配置方式。正向代理位于客户端和目标服务器之间,隐藏客户端的身份和提供缓存等功能。反向代理位于目标服务器和客户端之间,平衡负载、提供安全性和缓存等功能。它们在网络通信中扮演不同的角色,并在突破网络限制、提高性能和保护后端服务器等方面发挥重要作用。
集群
集群(Cluster)是指将多个计算机或服务器组合在一起,作为一个整体来共同完成特定任务或提供某种服务的系统。集群的目的是通过将计算和资源分布在多台机器上,提高系统的性能、可扩展性、可靠性和容错性。
-
架构和工作原理:
- 水平扩展:集群使用水平扩展的方式增加系统的处理能力。通过在集群中添加更多的计算机或服务器,可以平均分担负载,提高系统的处理能力。
- 负载均衡:集群中的负载均衡器将客户端请求分发给集群中的各个节点,以均衡负载和提高系统性能。负载均衡器可以根据不同的算法将请求分发给最空闲或最适合的节点。
- 高可用性:集群中的节点可以相互冗余和备份,当某个节点发生故障或不可用时,其他节点可以接管服务,保证系统的高可用性。
- 数据同步和共享:集群中的节点之间需要进行数据同步和共享,以保证数据的一致性和可靠性。
-
使用场景:
- Web应用负载均衡:通过集群,可以将客户端的请求分发到多个服务器上,实现Web应用的负载均衡,提高网站的访问性能和响应速度。
- 大规模数据处理:集群可以用于大规模数据处理和分布式计算。通过将数据分片和并行处理,可以提高数据处理的速度和效率。
- 分布式存储系统:集群可以用于构建分布式存储系统,将数据分散存储在多个节点上,提高存储容量和可靠性。
- 高可用性和容错性:通过将多个节点组成集群,可以提供高可用性和容错性。当某个节点发生故障时,其他节点可以接管服务,保证系统的连续性和可靠性。
-
技术和工具:
- 负载均衡器:常见的负载均衡器包括Nginx、HAProxy、F5等,用于将请求分发到集群中的节点。
- 分布式文件系统:如Hadoop的HDFS、GlusterFS、Ceph等,用于在集群中分布存储和管理大规模数据。
- 分布式计算框架:如Apache Hadoop、Apache Spark等,用于在集群中进行大规模数据处理和分布式计算。
安装
安装脚本。
[root@localhost nginx]# cat onekey_install_mjh_nginx.sh
#!/bin/bash
#新建一个文件夹用来存放下载的nginx源码包
mkdir -p /opt/nginx
cd nginx
#新建用户
useradd -s /sbin/nologin yandonghao
#下载 nginx
curl -O http://nginx.org/download/nginx-1.25.0.tar.gz
#解压nginx 源码包
tar xf nginx-1.25.0.tar.gz
#解决依赖关系
yum install gcc openssl openssl-devel pcre pcre-devel automake make -y
#编译前的配置,创建Makefile文件。
./configure --prefix=/usr/local/ydhnginx --user=yandonghao --with-http_ssl_module --with-http_v2_module --with-threads --with-http_stub_status_module --with-stream
#编译,开启2个进程同时编译,make其实就是安装Makefile的配置去编译程序成二进制文件,二进制文件就是执行可以运行的程序。
make -j 2
#安装: 将编译好的二进制代码文件复制到指定的安装路径目录下
make install
# 启动nginx
/usr/local/ydhnginx/sbin/nginx
#修改PATH变量
#临时修改
PATH=$PAth:/usr/local/ydhnginx/sbin
#永久修改
echo "PATH=$PATH:/usr/local/ydhnginx/sbin" >>/root/.bashrc
#设置nginx的开机启动
echo "/usr/local/ydhnginx/sbin" >>/etc/rc.local
chomd +x /etc/rc.d/rc.local
#selinux和firewalld防火墙都关闭
service firewalld stop
systemctl disable firewalld
#临时关闭selinux
setenforec 0
#永久关闭selinux
sed -i '/^SELINUX=/ s/enforcing/disabled' /etc/selinux/confug
编译安装的参数:
-
–with-http_ssl_module :用于启用 HTTP SSL 模块
-
–with-http_v2_module :用于启用 HTTP/2 协议支持的模块
-
–with-threads :用于启用 Nginx 的线程支持
-
–with-http_stub_status_module :状态统计功能
-
–with-stream:4层负载均衡功能
配置文件
并发(Concurrency):
- 并发指的是多个任务在同一时间段内执行,通过任务之间的切换来实现同时进行的假象。
- 在并发模型中,任务可能以交替的方式执行,每个任务分配到的时间片很小,通过任务切换的方式来实现任务之间的共享处理器资源。
- 并发适用于处理任务的交替执行,重点在于任务的调度和管理,而不是真正的同时执行。
并行(Parallelism):
- 并行指的是多个任务同时进行,实际上是多个任务同时在不同的处理器上执行。
- 在并行模型中,每个任务都有自己的处理器资源,它们可以独立地执行而不需要等待其他任务。
- 并行适用于真正同时执行的任务,重点在于任务的分解和并发执行,可以通过多处理器、多核心或分布式系统来实现。
#user nobody; #指定使用nobody用户去启动nginx worker进程,也可以改成 user xiaoli,需要用户存在才可以。
worker_processes 1; #启动一个worker进制,也可以改成其他数字。启动4个worker进程,看cpu核心的数量,一般是cpu核心数量一致 ,16核心启动16个进程。
user xiaoli
worker_processer 2;
#error_log logs/error.log; #指定错误日志存放的路径
#error_log logs/error.log notice; #日志的等级
#error_log logs/error.log info;
#pid logs/nginx.pid; #记录master进程的进程号
日志的等级
在Linux系统中,通常使用以下几个常见的日志级别(从高到低):
Emergency(紧急):表示系统无法使用,需要立即采取行动修复。例如,系统崩溃、关键服务不可用等。
Alert(警报):表示必须立即采取行动,但系统仍然可以使用。这个级别通常用于通知关键事件的发生,需要管理员的干预。
Critical(严重):表示关键错误或故障发生,但系统仍可以继续运行。需要注意并立即处理。
Error(错误):表示非常重要的错误事件,但系统仍然可以正常运行。需要检查和修复。
Warning(警告):表示可能会引起问题的情况。需要关注和调查,但不会影响系统的正常运行。
Notice(注意):表示正常但重要的事件,通常用于记录系统运行状态的变化或其他需要注意的情况。
Info(信息):表示一般信息,用于记录系统的一般操作和状态。
Debug(调试):用于调试目的的详细信息,通常只在调试过程中启用。
None:
不同的日志工具和应用程序可能会有不同的命名和细分级别,但上述日志级别是常见的标准级别,可供参考。根据实际需求,可以根据这些级别进行适当的配置和过滤。
events {
worker_connections 1024;
}
#表示每个工作进程可以支持最多 1024 个并发连接。
在 Nginx 的配置文件(通常是 nginx.conf)中,events 部分用于配置与服务器事件处理相关的参数。其中,worker_connections 是一个重要的指令,用于设置每个工作进程(Worker Process)所能够支持的最大并发连接数。
以下是对 events 部分和 worker_connections 指令的详细解释:
events部分:events部分用于配置与服务器事件处理相关的参数,例如并发连接数、文件描述符限制等。- 该部分通常位于 Nginx 配置文件的顶层,与其他部分(如
http、server)并列。 - 在
events部分中,可以设置多个与事件处理相关的指令。
worker_connections指令:worker_connections指令用于设置每个工作进程(Worker Process)所能够支持的最大并发连接数。- 每个客户端连接到 Nginx 服务器都会占用一个连接数,因此该指令的值决定了服务器能够同时处理的最大连接数。
- 默认情况下,Nginx 设置的最大连接数是 512。
- 通常,您可以根据服务器的硬件资源和预期的并发负载来调整此值。较高的值可以支持更多的并发连接,但可能需要更多的系统资源。
请注意,worker_connections 的值应该根据服务器的实际情况进行调整。过小的值可能导致并发连接过载,从而影响服务器的性能和可靠性。过大的值可能会占用过多的系统资源,导致服务器负载过高。
用进程和线程解释
1个进程里可以包含很多线程,一个连接:1个线程
进程process:pcb(进程控制块process contorl block 、程序代码、程序产生的数据
其中pcb(进程控制块)理解为进程的身份证,包含pid,用于启动,内存里的地址,进程的状态等信息
线程thread:tcb(线程控制块)、程序代码块、程序产生的数据
线程比进程更加节约内存资源,因为所有的线程都共享同一份程序代码。
http
http {
include mime.types;
default_type application/octet-stream;
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
#access_log logs/access.log main;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
server {
listen 8088;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
root html;
index index.html index.htm;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
# proxy the PHP scripts to Apache listening on 127.0.0.1:80
#
#location ~ \.php$ {
# proxy_pass http://127.0.0.1;
#}
# pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000
#
#location ~ \.php$ {
# root html;
# fastcgi_pass 127.0.0.1:9000;
# fastcgi_index index.php;
# fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;
# include fastcgi_params;
#}
# deny access to .htaccess files, if Apache's document root
# concurs with nginx's one
#
#location ~ /\.ht {
# deny all;
#}
}
# another virtual host using mix of IP-, name-, and port-based configuration
#
#server {
# listen 8000;
# listen somename:8080;
# server_name somename alias another.alias;
# location / {
# root html;
# index index.html index.htm;
# }
#}
# HTTPS server
#
#server {
# listen 443 ssl;
# server_name localhost;
# ssl_certificate cert.pem;
# ssl_certificate_key cert.key;
# ssl_session_cache shared:SSL:1m;
# ssl_session_timeout 5m;
# ssl_ciphers HIGH:!aNULL:!MD5;
# ssl_prefer_server_ciphers on;
# location / {
# root html;
# index index.html index.htm;
# }
#}
}
在 Nginx 的配置文件 nginx.conf 中,您看到的是关于日志格式的配置部分。具体来说,log_format 指令用于定义日志的格式,而 main 是该日志格式的名称。下面是对该配置段的详细解释:
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
log_format:这是 Nginx 的指令,用于定义日志的格式。main:这是日志格式的名称,您可以根据需要自定义一个名称,这里使用了main。'...':这是定义日志格式的字符串,使用单引号包围。在字符串中,您可以使用变量和文本来构建日志的输出格式。
解析字符串中的变量和文本:
$remote_addr:客户端的 IP 地址。$remote_user:通过基本身份验证(Basic Authentication)认证的远程用户。[$time_local]:请求发生的本地时间。"$request":请求的内容,包括请求方法、URI和协议。$status:响应的状态码。$body_bytes_sent:发送给客户端的响应内容的大小(以字节为单位)。"$http_referer":引用页面的 URL,从那个网址引流过来的,从那个网址跳转过来的。"$http_user_agent":客户端使用的用户代理(浏览器、爬虫等)。"$http_x_forwarded_for":通过代理服务器传递的客户端真实 IP 地址。
通过定义日志格式,您可以在 Nginx 的访问日志中记录这些变量的值,以及其他自定义的文本,以满足您对日志的需求和分析要求。
#keepalive_timeout 0;
keepalive_timeout 65;
在 Nginx 的配置文件中,keepalive_timeout 指令用于设置与客户端的 keep-alive 连接的超时时间。在配置文件中,可能会有两个相关的 keepalive_timeout 指令的设置。
-
keepalive_timeout 0;:keepalive_timeout 0;的设置意味着关闭 keep-alive 连接,即客户端和服务器之间的连接每次请求结束后都会立即关闭。- 这通常用于在高负载环境中,为了释放服务器上的连接资源,或者由于某些特殊要求需要禁用 keep-alive 连接。
-
keepalive_timeout 65;:- 这是一个实际启用的
keepalive_timeout设置,超时时间为 65 秒。 keepalive_timeout设置的默认单位是秒(s),即客户端和服务器之间的 keep-alive 连接在经过指定的时间后如果没有新的请求,则会自动关闭。- 在设置较短的超时时间可以减少服务器上的连接数,但可能会增加客户端与服务器之间建立和断开连接的频率。
- 这是一个实际启用的
server {
listen 8088;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
root html;
index index.html index.htm;
}
上述是一个简单的 Nginx 配置文件中的 server 块的示例。下面是对其中各项配置的详细解释:
-
listen 8088;:指定该服务器块监听的端口号为 8088。这意味着 Nginx 将监听来自该端口的请求。 -
server_name localhost;:设置该服务器块的域名或主机名为 “localhost”。这意味着只有使用 “localhost” 访问该 Nginx 服务器时,该服务器块中的配置将生效。 -
location / { ... }:定义了一个请求位置(location)“/”。这表示所有匹配到根路径"/"的请求将由此位置块处理。 -
root html;:指定了网站根目录为 “html”。这意味着服务器将在配置文件所在的目录下的 “html” 目录中查找文件来响应请求。 -
index index.html index.htm;:定义了索引文件的顺序。在该示例中,当访问一个目录时,服务器将依次查找 “index.html” 和 “index.htm” 文件,最左边的优先级最高,以作为默认的索引文件返回给客户端。 -
#charset koi8-r;:- 这个指令用于设置字符集编码,具体是
koi8-r字符集。该字符集通常用于俄罗斯和其他一些东欧语言。 - 注释掉该指令意味着使用默认的字符集编码。
- 这个指令用于设置字符集编码,具体是
-
#access_log logs/host.access.log main;:- 这个指令用于定义访问日志的配置。
access_log指令用于启用或禁用访问日志,并指定日志文件的路径和格式。 - 在示例中,日志文件路径是
logs/host.access.log,日志格式是main。logs是相对于 Nginx 配置文件的路径。 - 注释掉该指令意味着禁用访问日志,不会记录访问日志文件。
- 这个指令用于定义访问日志的配置。
虚拟主机的配置
- 基于端口
- 基于ip
- 基于域名:推荐
一个域名对应一个server(虚拟主机)
只安装一个nginx,开启三个server(虚拟主机),对应三个域名,一个域名就是一个网站。
使用
[root@localhost ydhnginx]# ls
logs sbin conf html
- logs:存放日志文件
- sbin:存放nginx的启动文件
- conf:存放nginx的配置文件
- html:目录,存放网站的网页文件
[root@localhost logs]# ls
access.log error.log nginx.pid
- nginx.pid :放置master的进程号
- access.log: 正常的访问网站
- error.log: 访问错误的日志
日志的好处:
- 排错故障:根据日志的记录
- 进行数据分析
nginx -t
用于测试 Nginx 配置文件的语法和正确性。它会检查**配置文件(nginx.config)**的语法错误并输出相关的错误信息。
以下是运行成功的情况:
[root@localhost conf]# nginx -t
nginx: the configuration file /usr/local/ydhnginx/conf/nginx.conf syntax is ok
nginx: configuration file /usr/local/ydhnginx/conf/nginx.conf test is successful
修改ngixn.config文件
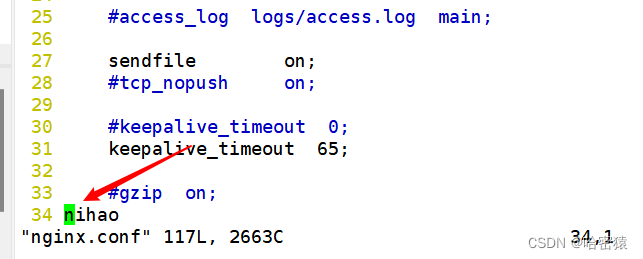
这个时候会报错:
[root@localhost conf]# nginx -t
nginx: [emerg] unknown directive "nihao" in /usr/local/ydhnginx/conf/nginx.conf:35
nginx: configuration file /usr/local/ydhnginx/conf/nginx.conf test failed
启动nginx
[root@localhost ydhnginx]# cd sbin/
[root@localhost sbin]# ls
nginx
[root@localhost sbin]# ./nginx
查看是否启动了
查看进程号:
[root@localhost sbin]# ps aux|grep nginx
root 30983 0.0 0.3 149820 5632 pts/5 S+ 19:42 0:00 vim onekey_install_mjh_nginx.sh
root 34527 0.0 0.0 46240 1164 ? Ss 21:33 0:00 nginx: master process ./nginx
yandong+ 34528 0.0 0.1 46700 2152 ? S 21:33 0:00 nginx: worker process
root 34582 0.0 0.0 112824 988 pts/1 S+ 21:45 0:00 grep --color=auto nginx
查看端口:
netstat -anplut|grep nginx #查看ngixn进程网络的状态
lsof -i:80
ss -anpluts
[root@localhost sbin]# netstat -anplut|grep nginx
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 34527/nginx: master
查看是否在网页上能正常显示
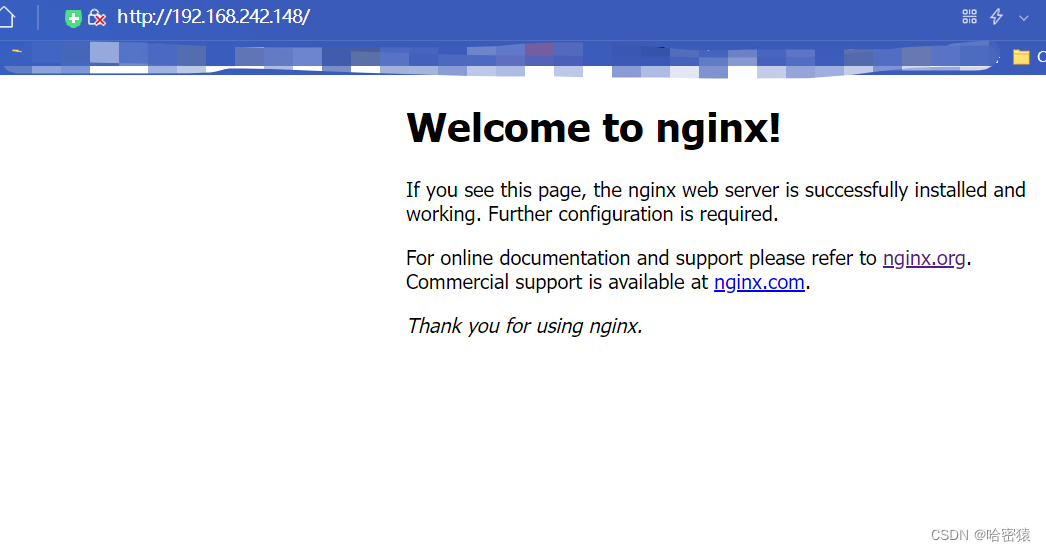
出现这样的画面就是表示nginx安装成功了。
如果前面都配置好了,画面显示不出来,考虑是不是防火墙没关的原因。
停止nginx服务
[root@localhost sbin]# /usr/local/ydhnginx/sbin/nginx -s stop
#使用绝对路径停止服务
[root@localhost sbin]# ./nginx -s stop
#使用相对路径停止服务
查看nginx服务是否已经停止了
[root@localhost sbin]# ps aux|grep nginx
root 30983 0.0 0.3 149820 5632 pts/5 S+ 19:42 0:00 vim onekey_install_mjh_nginx.sh
root 34603 0.0 0.0 112824 984 pts/1 S+ 21:50 0:00 grep --color=auto nginx
yun安装的nginx和编译安装的nginx是否冲突?
冲突的点:默认都想抢占80端口
如果不使用相同的端口,不冲突的
能否在机器里编译安装多个nginx?
可以,如果不使用相同的端口,不冲突的
[root@localhost nginx]# ps aux|grep nginx
root 40988 0.0 0.0 46240 1168 ? Ss 18:34 0:00 nginx: master process ./nginx
yandong+ 40989 0.0 0.1 46700 1916 ? S 18:34 0:00 nginx: worker process
root 41071 0.0 0.0 39308 972 ? Ss 18:34 0:00 nginx: master process /usr/sbin/nginx
nginx 41072 0.0 0.0 39728 1852 ? S 18:34 0:00 nginx: worker process
nginx 41073 0.0 0.0 39728 1852 ? S 18:34 0:00 nginx: worker process
root 41145 0.0 0.0 112824 988 pts/2 S+ 18:36 0:00 grep --color=auto nginx
master和worker
在Linux中,Nginx是一个流行的高性能Web服务器和反向代理服务器。Nginx的架构涉及两个主要组件:Master进程和Worker进程。下面是对Nginx的Master进程和Worker进程的详细介绍和区别:
-
Master进程:
- Master进程是Nginx的控制进程,负责启动和管理整个Nginx服务器。
- Master进程通常以root权限运行,并负责处理系统信号、读取和解析配置文件以及启动Worker进程。
- Master进程还负责监听网络端口,接收客户端请求,并将请求分发给Worker进程进行处理。
- Master进程通常只有一个实例。
-
Worker进程:
- Worker进程是Nginx的工作进程,负责处理客户端请求和提供服务。
- Worker进程由Master进程创建和管理,通常以非特权用户的身份运行。
- 每个Worker进程都是独立的,具有独立的事件循环和线程池,可以并发地处理多个客户端请求。
- Worker进程负责接收来自Master进程的任务,处理请求,执行业务逻辑,并向客户端返回响应。
区别:
- Master进程和Worker进程的功能不同。Master进程负责管理和控制整个Nginx服务器的运行,包括配置解析、进程管理和任务分发;而Worker进程负责实际的请求处理和服务提供。
- Master进程通常只有一个实例,而Worker进程可以有多个实例,每个实例对应一个CPU核心或处理器,以实现并行处理和提高性能。
- Master进程以root权限运行,而Worker进程以非特权用户的身份运行,以提高服务器的安全性和稳定性。
Nginx的Master-Worker架构使其能够处理大量并发请求,并在高负载下保持高性能和可靠性。Master进程负责监控和管理Worker进程的运行状态,并在需要时重启或回收Worker进程,从而实现动态的负载均衡和故障恢复。
需要注意的是,Nginx的Master-Worker架构是一种常见的服务器架构,并不仅限于Nginx。许多其他Web服务器和应用服务器也采用类似的架构,以实现高性能、可扩展和稳定的服务。
[root@localhost local]# ps aux|grep nginx
root 40988 0.0 0.0 46240 1344 ? Ss 18:34 0:00 nginx: master process ./nginx
yandong+ 42598 0.0 0.1 46700 1916 ? S 19:03 0:00 nginx: worker process
root 42929 0.0 0.0 112824 988 pts/3 S+ 19:09 0:00 grep --color=auto nginx
杀死master进程
[root@localhost local]# ps aux|grep nginx
yandong+ 42598 0.0 0.1 46700 1916 ? S 19:03 0:00 nginx: worker process
root 45678 0.0 0.0 112824 988 pts/3 S+ 19:10 0:00 grep --color=auto nginx
可以看到master进程杀死后,不会再生成了,同时剩下的worker进制变成父进程了。
这个时候我们去重新加载nginx的配置文件,会出错:
[root@localhost local]# nginx -s reload
nginx: [alert] kill(40988, 1) failed (3: No such process)
这是因为是master进程去重新加载配置文件,随后再将信息转递给下面的worker进程。
nginx -s reload
只是杀死worker进程,而master进程不会。父进程的pid不会发生改变。
重新启动nginx服务:
[root@localhost local]# ps aux|grep nginx
root 45907 0.0 0.0 46240 1172 ? Ss 19:14 0:00 nginx: master process nginx
yandong+ 45908 0.0 0.1 46700 1920 ? S 19:14 0:00 nginx: worker process
root 45918 0.0 0.0 112824 988 pts/3 S+ 19:14 0:00 grep --color=auto nginx
- 这次选择杀死worker进程。
[root@localhost local]# ps aux|grep nginx
root 45907 0.0 0.0 46240 1348 ? Ss 19:14 0:00 nginx: master process nginx
yandong+ 45969 0.0 0.1 46700 1920 ? S 19:15 0:00 nginx: worker process
root 45978 0.0 0.0 112824 988 pts/3 S+ 19:16 0:00 grep --color=auto nginx
可以看到 进程号为45908的worker进程已经被杀死,新的worker进程号为45969。
升级问题
-
重新编译安装一个新的
先去卸载以前版本的nginx,先删除安装指定的目录(–prefix指定的路径),随后,在PATH变量里删除nginx的安装路径,最后就可以编译安装了。
-
热升级
- 备份老的准备nginx二进制文件
- 准备新的nginx二进制文件,新的nginx二进制各配置路径保持一致
- 向老的nginx进程发送“SIGUSR2 (12)”信号,启动新的进程(新老进程并存)
- 向老的nginx进程发送“SIGQUIT (3)”信号停掉老的nginx进程
基于域名的虚拟主机
修改配置文件nginx.config。一个server对应一个服务。
将server的内容修改如下,同时增加两个server。
server {
listen 80;
server_name www.yan.com;
access_log logs/yan.com.access.log main;
location / {
root html/yan;
index shouye.html index.html index.htm;
}
error_page 404 /404.html;
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
server {
listen 80;
server_name www.d.com;
access_log logs/d.com.access.log main;
location / {
root html/d;
index shouye.html index.html index.htm;
}
error_page 404 /404.html;
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
server {
listen 80;
server_name www.hao.com;
access_log logs/hao.com.access.log main;
location / {
root html/hao;
index shouye.html index.html index.htm;
}
error_page 404 /404.html;
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
listen:指定服务器监听的端口号,这里设置为 80,表示使用 HTTP 协议的默认端口。server_name:指定虚拟主机的域名,分别为 www.yan.com、www.d.com 和 www.hao.com。access_log:指定访问日志的路径和文件名,用于记录访问日志。这里的路径为logs/,文件名为域名.access.log。访问www.hao.com时会生成hao.com.access.log等文件location /:定义请求的 URL 路径匹配规则,这里的/表示匹配所有请求。root:指定静态文件的根目录,用于查找请求的资源文件。对于 www.yan.com,根目录为html/yan;对于 www.d.com,根目录为html/d;对于 www.hao.com,根目录为html/hao。我们需要去创建对应的文件,同时在对应的文件要创建shouye.html index.html index.htm其中的一个页面,或者会报错的。index:指定当请求的 URL 不包含具体文件名时,默认返回的文件。这里定义了三个默认文件名,按照优先级依次为shouye.html、index.html和index.htm。
error_page:定义错误页面的处理方式。404:指定当出现 404 错误时,返回的 URL 路径为/404.html。500 502 503 504:指定当出现 500、502、503 或 504 错误时,返回的 URL 路径为/50x.html。
location = /50x.html:定义对/50x.htmlURL 路径的处理方式。root:指定错误页面文件的根目录,这里为html。
总结起来,这段代码配置了三个虚拟主机,每个主机有自己的域名、访问日志路径和根目录。当请求到达时,会根据 URL 匹配规则查找相应的资源文件,并设置了错误页面的处理方式。
- 最后结果
修改好配置文件nginx.config以及创建好对应的html文件后,我们需要创建新的域名解析,在C:\Windows\System32\drivers\etc目录下的hosts文件中添加域名解析可以实现本地的域名解析功能:
192.168.242.149 www.yan.com
192.168.242.149 www.d.com
192.168.242.149 www.hao.com
当你在浏览器中输入www.yan.com、www.d.com或www.hao.com时,系统将会使用hosts文件中的域名解析规则进行解析,将这些域名映射到指定的IP地址192.168.242.149。
注意,修改hosts文件需要管理员权限。在编辑hosts文件之前,建议先备份原始文件,以防修改错误导致问题。我们可以将hosts文件先复制到桌面上去,然后对该文件进行修改,随后将修改好的文件替换C:\Windows\System32\drivers\etc中的hosts文件即可,同样的可以先将hosts文件进行备份才进行操作。
将上面的操作完成后:
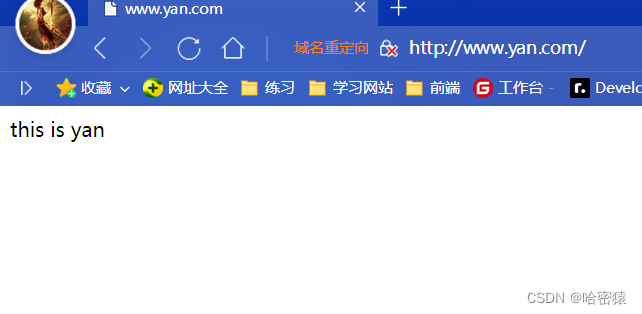
在html/yan下面创建404.html后:
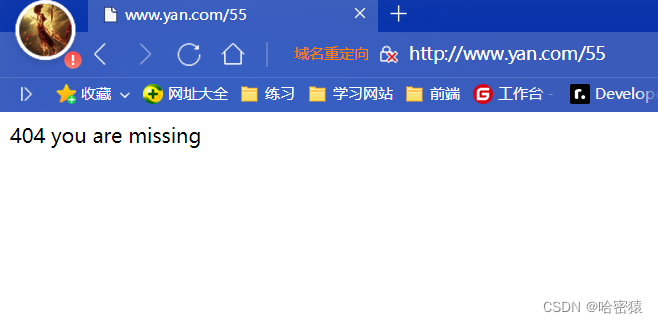
- 问题
同一个服务器,一个进程,相同的端口,用户访问的时候,ngixn是如何区分开不同的网站的?
http协议:
1.请求报文
当用户发送HTTP请求时,请求中通常包含了目标网站的域名信息(Host头字段)。Nginx可以通过检查请求中的域名信息来确定用户访问的是哪个网站。通过在配置文件中定义不同的虚拟主机,并将每个虚拟主机与对应的域名进行绑定,Nginx可以根据请求的域名来将请求分发到相应的虚拟主机,从而实现对不同网站的区分。
2.响应报文
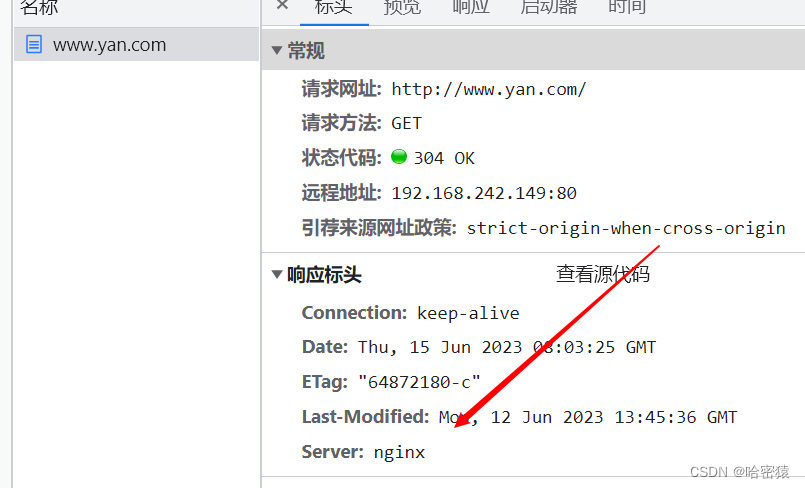
隐藏nginx的版本信息
安装nginx的时候,server_tokens是默认开启的。
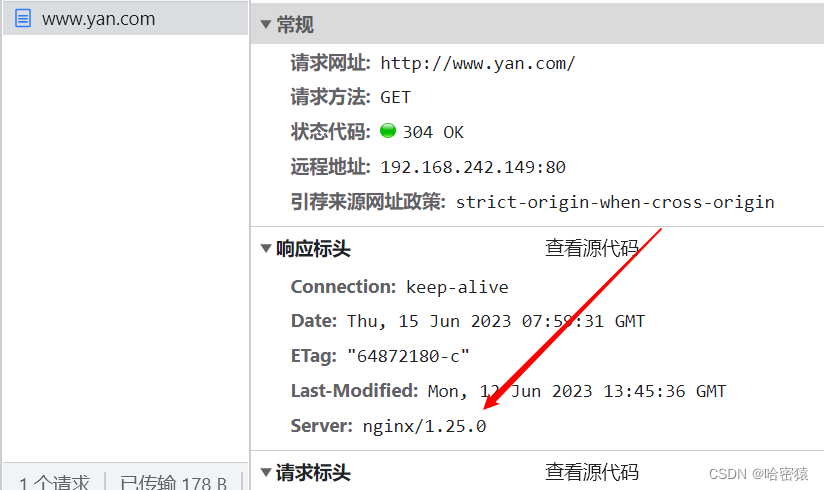
我们可以在nginx.config中的http里面添加server_tokens off;
配置完成后,重新加载nginx
供别人下载的网站
-
可以放到指定server的location中,这样只会在该server生效
-
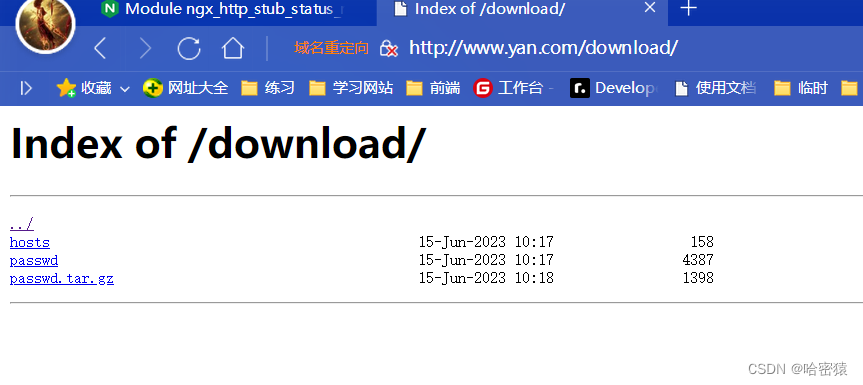
这个时候访问www.hao.com/download是禁止的。 -
同样的也可以放到http的里面,这样所有的主机都可以生效了。
autoindex on; 不放在指定的server里面了。 server_tokens off; #gzip on; server {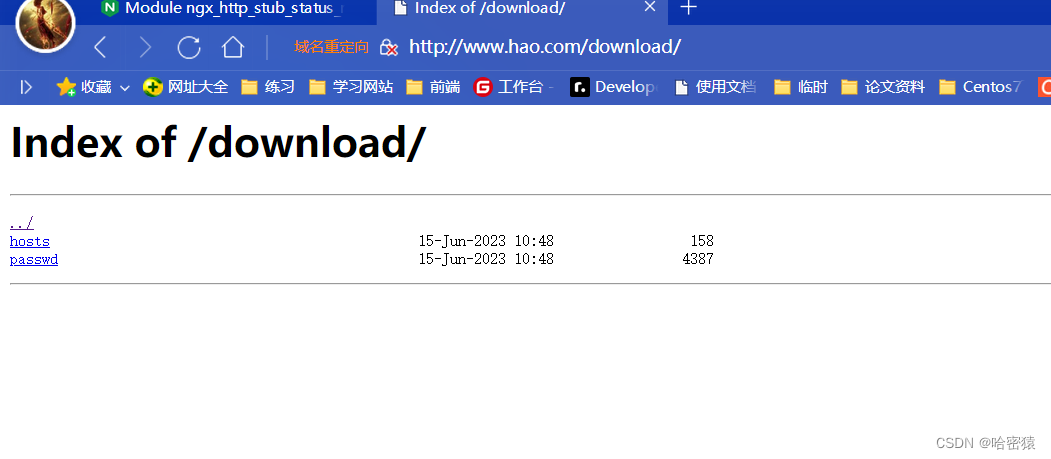
这样基本的具有下载功能的页面就完成了。
统计的信息的页面
可以在指定的server添加一个单独的路由
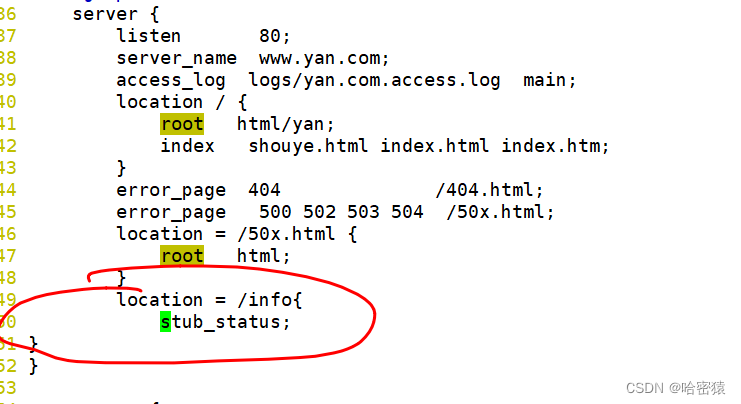
加上access_log off;再访问**/info**不会记录信息到access_log中去了。
访问页面如下:
同样的,我们也可以不放指定的server里面,放在http上面的位置,以便所有的域名都可以访问统计信息。
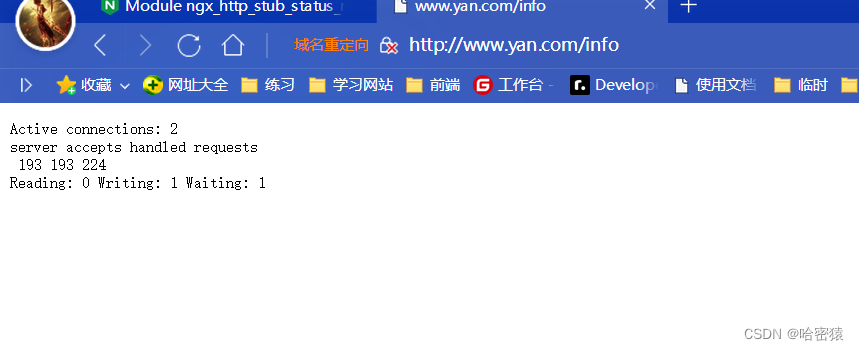
- Active connections: 2(活动连接数:2):这表示服务器当前有两个活动连接。
- Server accepts handled requests(服务器接受处理的请求):这三个数字分别表示服务器接受、处理和响应的请求数量。根据您提供的数据,服务器已接受了202个请求,处理了202个请求,并成功响应了245个请求。
- Reading: 0(读取中的连接数:0):这表示当前没有正在读取数据的连接。
- Writing: 1(写入中的连接数:1):这表示当前有一个连接正在向服务器写入数据。
- Waiting: 1(等待中的连接数:1):这表示当前有一个连接处于等待状态,即等待服务器的响应(占着茅坑不拉屎0.0)。
这些信息通常用于监视服务器的性能和负载情况。
pv介绍
在Linux中,Nginx是一款常用的开源Web服务器软件,它可以处理静态资源、反向代理、负载均衡和HTTP缓存等功能。在Nginx中,“pv"代表"Page View”,即页面浏览量。
“pv”(或者有时也称为"ngx_http_stub_status_module")是Nginx提供的一个模块,用于收集和展示服务器的状态信息,包括请求的总数、活跃连接数、各个URI的访问量等。这些信息对于监控服务器性能、调优和故障排查非常有用。
要启用"pv"模块,需要在Nginx的配置文件中进行相应的设置。首先,确保你的Nginx已经编译安装了该模块,通常在编译安装Nginx时,可以通过添加 --with-http_stub_status_module 参数来启用它。然后,在Nginx的配置文件(通常是nginx.conf)中,添加以下配置块:
location /nginx_status {
stub_status on;
access_log off;
allow 127.0.0.1; # 允许访问的IP地址
deny all; # 拒绝其他IP地址的访问
}
上述配置中,location /nginx_status 定义了一个URI路径,用于获取服务器状态信息。stub_status on; 表示开启状态信息的收集,access_log off; 则是为了禁止将访问日志写入磁盘,避免不必要的IO开销。allow 和 deny 分别指定了允许访问的IP地址和禁止访问的IP地址。
配置完成后,通过访问指定的URI路径(例如:http://your_server_address/nginx_status)即可获取服务器的状态信息。返回的信息通常是一组文本,包含了请求数、连接数、各个URI的访问量等统计数据,可以通过解析这些数据进行分析和监控。
需要注意的是,为了安全起见,通常只允许本地或可信任的IP地址访问"pv"页面,以防止未经授权的访问。
ngixn续
nginx认证
ngx_http_auth_basic_module
49 location = /info{
50 stub_status;
51 access_log off;
52 auth_basic "ydh website" #add
53 auth_basic_user_file htpasswd; #add
54 }
查看htpasswd的来源
[root@localhost conf]# yum provides htpasswd
httpd-tools-2.4.6-98.el7.centos.7.x86_64 : Tools for use with the
: Apache HTTP Server
源 :updates
匹配来源:
文件名 :/usr/bin/htpasswd
下载httpd-tools
[root@localhost conf]# yum install httpd-tools -y
nginx的allow和deny
ngx_http_access_module
在Linux中,Nginx的allow和deny是用于控制访问权限的指令。它们通常在Nginx的配置文件中与location指令一起使用。下面是对它们的详细解析和使用说明:
-
allow指令:
allow指令用于允许特定的IP地址或IP地址段访问Nginx服务器的特定区域。只有匹配allow指令中定义的IP地址的请求才会被允许通过。如果没有定义allow指令,则默认情况下所有IP地址都是被允许的。使用示例:
allow 192.168.1.100; allow 10.0.0.0/24;上述示例中,第一行允许IP地址为192.168.1.100的请求通过,而第二行允许10.0.0.0/24网段内的IP地址通过。
-
deny指令:
deny指令用于拒绝特定的IP地址或IP地址段访问Nginx服务器的特定区域。只有匹配deny指令中定义的IP地址的请求才会被拒绝。如果没有定义deny指令,则默认情况下所有IP地址都是被允许的。使用示例:
deny 192.168.1.200; deny 10.0.0.0/24;上述示例中,第一行拒绝IP地址为192.168.1.200的请求,而第二行拒绝10.0.0.0/24网段内的IP地址。
-
allow和deny的使用:
这两个指令可以单独使用,也可以结合使用。它们通常与location指令一起使用,以定义特定区域的访问权限。使用示例:
location /private { allow 192.168.1.0/24; deny all; }上述示例中,
location指令匹配路径为/private的请求。然后,allow指令允许192.168.1.0/24网段内的IP地址访问该路径,而deny all指令拒绝其他所有IP地址的请求。
使用allow和deny指令可以有效地控制Nginx服务器的访问权限,限制特定IP地址或IP地址段的访问或拒绝访问。这对于保护服务器安全和限制资源访问非常有用。
请注意,在配置文件中的顺序很重要。allow和deny的顺序会影响访问规则的优先级。一般情况下,最好将deny指令放在allow指令之前,以确保拒绝规则优先生效。
修改nginx.conf中的server中的数据如下
49 location = /info{
50 stub_status;
51 access_log off;
52 auth_basic "ydh website";
53 auth_basic_user_file htpasswd;
54 allow 192.168.2.67; #add
55 deny all; #add
56 }
nginx限制并发数
- ngx_http_limit_conn_module
用于设置连接限制的区域.
limit_conn_zone $binary_remote_addr zone=addr:10m;
zone=addr:10m表示将创建一个名为"addr"的共享内存区域,大小为10兆字节(MB)。
location /download/ {
limit_conn addr 1;
autoindex on;
root html/yan;
}
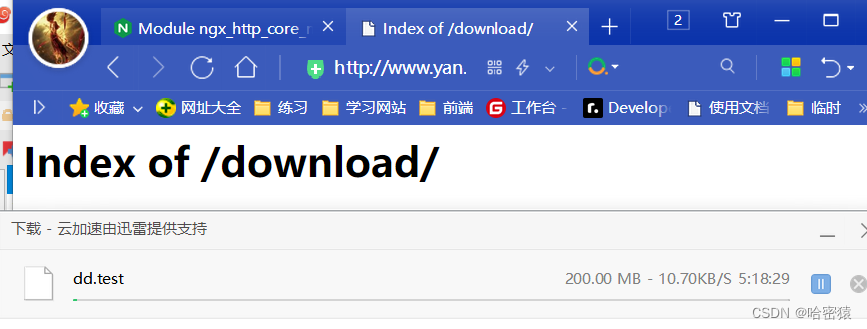
该配置块的作用是限制每个客户端IP地址在/download/位置上的并发连接数为1,并在请求该位置时自动列出并返回html/yan目录下的文件和子目录的目录索引页面。
在/usr/local/ydhnginx/html/yan/download生产大文件机进行测试。
[root@localhost download]# dd if=/dev/zero of=dd.test bs=1M count=200
当我同时打开两个窗口进行下载大文件的时候,在一方没有下载完的时候,再打开另一个进行下载的时候,会出现下面的报错。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1CN9yeD6-1687870647700)(C:\Users\asus\AppData\Roaming\Typora\typora-user-images\image-20230616101757493.png)]](https://img-blog.csdnimg.cn/2406e143bba745769ce94211dcc7a46b.png)
下面是日志里记录的信息,可以清晰的看到503的错误。

至此,基本的并发数的限制设置完成了.
下面的配置将同时限制每个客户端IP对服务器的连接数以及对虚拟服务器的总连接数。
limit_conn_zone $binary_remote_addr zone=perip:10m;
limit_conn_zone $server_name zone=perserver:10m;
server {
...
limit_conn perip 10;
limit_conn perserver 100;
}
limit_conn_zone $binary_remote_addr zone=perip:10m;: 这行指令定义了一个名为perip的连接限制区域,并将客户端的二进制远程地址(IP地址)作为键来识别连接。$binary_remote_addr表示客户端的二进制远程地址。zone=perip:10m表示将创建一个名为perip的共享内存区域,大小为10兆字节(MB)。limit_conn_zone $server_name zone=perserver:10m;: 这行指令定义了一个名为perserver的连接限制区域,并将服务器名称作为键来识别连接。$server_name表示服务器的名称。zone=perserver:10m表示将创建一个名为perserver的共享内存区域,大小为10兆字节(MB)。limit_conn perip 10;: 这行指令设置了名为perip的连接限制区域的连接数限制为10。这表示每个客户端IP地址最多可以同时建立10个连接。limit_conn perserver 100;: 这行指令设置了名为perserver的连接限制区域的连接数限制为100。这表示每个服务器名称(可以是多个域名或虚拟主机)最多可以同时建立100个连接。
nginx限速
ngx_http_core_module中的limit_rate、limit_rate_after
limit_rate 10k; #限制每秒10k的速度
limit_rate_after 100k; #下载速度达到100k每秒的时候,进行限制
这段代码放在http里或者指定的server都都会生效,http针对全局,而server针对特定的。
可以通过下载测试看到,下载的速度在10k左右了。
至此,基本的限速就完成了。
限速的算法
Nginx中的令牌桶和漏桶算法都是用于流量控制的算法,用于平滑限制和管理请求的处理速率。它们在处理请求流量时有不同的工作方式和效果。
- 令牌桶算法:
令牌桶算法是一种基于令牌的流量控制算法。在令牌桶算法中,系统以固定的速率生成令牌,并将这些令牌放入一个令牌桶中。每当一个请求到达时,它需要获取一个令牌才能被处理。如果令牌桶中有足够的令牌,则请求被允许处理,并从令牌桶中取走一个令牌。如果令牌桶为空,则请求被暂时阻塞或丢弃。这样可以控制请求的处理速率,使其不超过设定的速率限制。
令牌桶算法的优点是可以应对突发请求。如果请求速率超过了设定的速率限制,令牌桶算法可以使用令牌桶中的剩余令牌来处理这些请求,但处理速率会受限制。它可以提供较为平滑的请求处理速率。
- 漏桶算法:
漏桶算法是一种基于容量的流量控制算法。在漏桶算法中,系统以固定的速率处理请求,并将请求放入一个漏桶中。如果请求到达时漏桶还有剩余容量,则请求被接受并加入漏桶中。如果漏桶已满,则请求被丢弃或者以某种形式进行处理(例如返回错误)。
漏桶算法的特点是无论请求的到达速率如何,处理速率始终保持恒定。这意味着即使有突发请求,漏桶算法也能保持固定的处理速率。它可以用于平滑请求流量和保护后端服务器免受突发请求的影响。
区别:
- 工作方式:令牌桶算法基于令牌生成和消费,请求需要获取令牌才能被处理;漏桶算法基于容量限制和固定的处理速率,请求被放入漏桶并以固定速率处理。
- 效果:令牌桶算法可以应对突发请求,使用令牌桶中的剩余令牌来处理,但处理速率会受限制;漏桶算法保持固定的处理速率,能够平滑流量和保护后端服务器。
- 弹性:令牌桶算法具有一定的弹性,
nginx 限制请求数
ngx_http_limit_req_module
http {
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;
...
server {
...
location / {
root html/yan;
index shouye.html index.html index.htm;
limit_req zone=one burst=5;
}
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;解释
-
limit_req_zone指令用于定义一个请求限制区域(zone),该区域用于跟踪来自特定客户端地址的请求频率。它具有以下参数: -
$binary_remote_addr:这是一个Nginx变量,表示客户端的二进制远程地址。 -
zone=one:10m:这个参数定义了请求限制区域的名称为"one",并且指定了该区域的大小为10兆字节(可以根据需要进行调整)。 -
rate=1r/s:这个参数表示限制每秒钟来自客户端的请求速率为1个请求。
limit_req zone=one burst=5;解释
-
limit_req指令,将请求限制区域应用于该位置。它具有以下参数: -
zone=one:这个参数指定要使用的请求限制区域的名称,即上面定义的"one"。 -
burst=5:这个参数表示在超过请求速率限制之前,可以临时允许的最大突发请求数。在这种情况下,最多允许突发请求达到5个。
多次请求www.yan.com网页后,出现的情况如下
这是日志记录的信息:

至此,基本的nginx的请求数的限制已经设置完成了。
nginx 的 location
ngx_http_core_module中的location
Syntax: location [ = | ~ | ~* | ^~ ] uri { ... }
- = 开头表示精确匹配
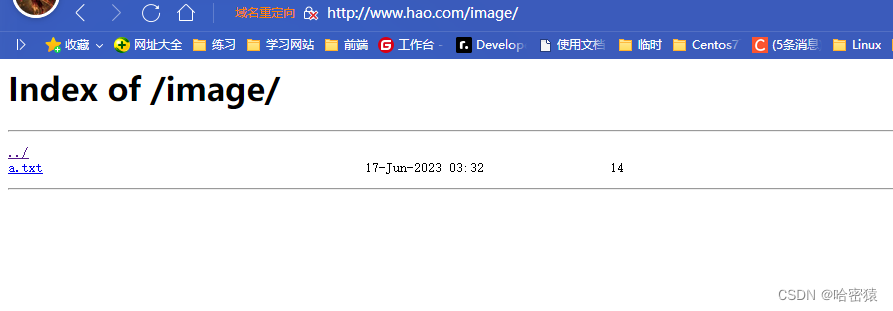
- ^~ 开头表示uri以某个常规字符串开头,理解为匹配 url路径即可。nginx不对url做编码,因此请求为/image,可以被规则^~ /image/ /a.txt匹配到(注意是没有空格)。
- ~ 开头表示区分大小写的正则匹配
- ~* 开头表示不区分大小写的正则匹配
- !和!*分别为区分大小写不匹配及不区分大小写不匹配 的正则
- / 通用匹配,任何请求都会匹配到。
(location `=` ) > (location `完整路径` ) > (location `^~` 路径) > (location `~`,`~*` ) > (location 普通匹配) > (`/`)
至此,基本的nginx的请求数的限制已经设置完成了。
nginx 的 location
ngx_http_core_module中的location
Syntax: location [ = | ~ | ~* | ^~ ] uri { ... }
- = 开头表示精确匹配
- ^~ 开头表示uri以某个常规字符串开头,理解为匹配 url路径即可。nginx不对url做编码,因此请求为/image,可以被规则^~ /image/ /a.txt匹配到(注意是没有空格)。
- ~ 开头表示区分大小写的正则匹配
- ~* 开头表示不区分大小写的正则匹配
- !和!*分别为区分大小写不匹配及不区分大小写不匹配 的正则
- / 通用匹配,任何请求都会匹配到。
(location `=` ) > (location `完整路径` ) > (location `^~` 路径) > (location `~`,`~*` ) > (location 普通匹配) > (`/`)
先进行精准匹配,如果匹配成功,立即返回结果并结束匹配过程。
进行普通匹配,如果有多个location匹配成功,将“最长前缀”的location作为临时结果.
通常,匹配成功了普通字符串location后还会进行正则表达式location匹配。有两种方法改变这种行为,精准匹配成功后就终止;另外一种就是使用“^~”前缀,如果把这个前缀用于一个常规字符串那么告诉nginx 如果路径匹配那么不测试正则表达式。
修改server的代码如下:
location /download/ {
root html/hao;
}
location ~/download/sc {
root html/hao;
}
location ~* /download/ {
root html/hao;
}
location ^~/image//a.txt{
root html/hao;
}
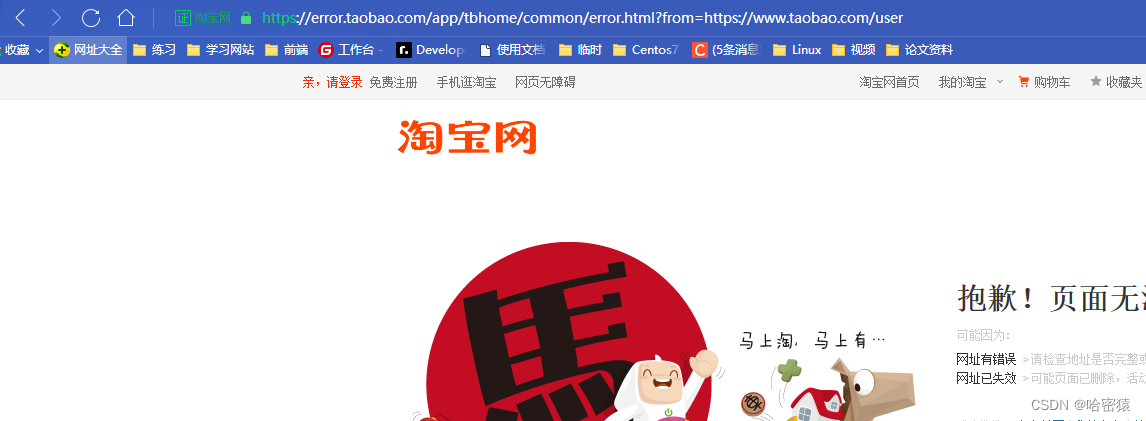
location /user/ {
proxy_pass http://www.jd.com;
}
location = /user {
proxy_pass http://www.taobao.com;
}
-
location /download/ { ... }:- 当请求的URL以
/download/开头时,NGINX会在html/hao目录中查找相应的文件或资源。 - 例如,
http://example.com/download/file.txt会尝试在html/hao目录中查找file.txt文件。
- 当请求的URL以
-
location ~/download/sc { ... }:- 此location块使用了正则表达式匹配,表示当URL以
/download/sc开头时,NGINX会在html/hao目录中查找相应的文件或资源。 - 注意,此处的
~表示区分大小写的正则匹配。
- 此location块使用了正则表达式匹配,表示当URL以
-
location ~* /DOWNLODA/ { ... }:- 类似于前一个location块,此处的
~*表示不区分大小写的正则匹配。 - 当请求的URL以
/DOWNLOAD/开头时,NGINX会在html/hao/download目录中查找相应的文件或资源。
- 类似于前一个location块,此处的
-
location ^~/image//a.txt { ... }:- 当请求的URL精确匹配
/image//a.txt时(注意双斜杠),NGINX会在html/hao目录中查找相应的文件或资源。 - 这是一个精确匹配的location块,其中的
^~表示匹配到此处后停止继续匹配其他location块。
- 当请求的URL精确匹配
-
location /user/ { proxy_pass http://www.jd.com; }:- 当请求的URL以
/user/开头时,NGINX会将请求代理到http://www.jd.com网站。 - 例如,
http://example.com/user/login会将请求代理到http://www.jd.com/login。
- 当请求的URL以
-
location = /user { proxy_pass http://www.taobao.com; }:- 当请求的URL精确匹配
/user时,NGINX会将请求代理到http://www.taobao.com网站。 - 这也是一个精确匹配的location块,其中的
=表示精确匹配。
- 当请求的URL精确匹配
有如下的图:
这是以image开头的:
这是进行跳转的
至此,可看到进行location配置已经基本完成了。
nginx压力测试
python代码
import requests
import time
from concurrent.futures import ThreadPoolExecutor
URL = 'http://192.168.2.67' # 待测试的网页URL
NUM_REQUESTS = 4097 # 并发请求数量
def make_request(url):
start_time = time.time()
response = requests.get(url)
end_time = time.time()
elapsed_time = end_time - start_time
return elapsed_time
def test_website():
print(f'Testing website: {URL}')
print(f'Number of concurrent requests: {NUM_REQUESTS}\n')
with ThreadPoolExecutor(max_workers=NUM_REQUESTS) as executor:
# 提交并发请求
futures = [executor.submit(make_request, URL) for _ in range(NUM_REQUESTS)]
total_time = 0.0
for future in futures:
elapsed_time = future.result()
total_time += elapsed_time
print(f'Response time: {elapsed_time:.3f} seconds')
avg_time = total_time / NUM_REQUESTS
print(f'\nAverage response time: {avg_time:.3f} seconds')
if __name__ == '__main__':
test_website()
健康检测
Nginx提供了健康检测功能,它能够自动检测后端服务器的可用性,并根据检测结果来动态调整负载均衡。下面是关于Nginx健康检测的详细信息:
-
健康检测类型:
Nginx支持两种健康检测类型:主动健康检测(Active Health Checks)和被动健康检测(Passive Health Checks)。-
主动健康检测(Active Health Checks):Nginx通过定期发送检测请求到后端服务器来主动检测服务器的健康状况。可以配置检测请求的频率、超时时间和响应码等参数,以及定义成功和失败的检测条件。
-
被动健康检测(Passive Health Checks):Nginx根据来自后端服务器的请求和响应情况来判断服务器的健康状态。如果后端服务器未能及时响应请求或返回错误码,Nginx将标记该服务器为不可用。
-
-
健康检测配置:
在Nginx配置文件中,可以使用"health_check"指令来配置健康检测。通过指定检测请求的URL、间隔时间、超时时间、检测成功和失败的条件等参数,以及定义健康检测的类型(主动或被动),来设置健康检测的行为。 -
健康状态标记:
当Nginx发现后端服务器不可用时,它会将服务器标记为不可用状态,并暂时停止将请求分发给该服务器。当服务器恢复正常后,Nginx会重新将其标记为可用状态,继续将请求分发给该服务器。 -
健康检测事件:
Nginx提供了一些相关的事件,可以用于监控和记录健康检测的结果。例如,可以使用"proxy_next_upstream"指令来配置在健康检测失败时如何处理请求。
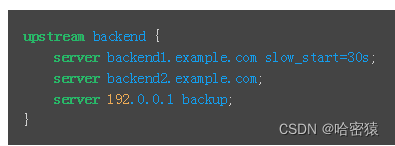
参数
- fail_timeout –设置必须多次尝试失败才能将服务器标记为不可用的时间,以及将服务器标记为不可用的时间(默认为10秒)。
- max_fails –设置在fail_timeout服务器标记为不可用的时间内必须发生的失败尝试次数(默认为1次尝试)。
- backup 备份:当其他的服务器都不提供服务的时候,再启用这台服务器提供服务 --》备胎
- slow_start 慢启动
- down 将上游的服务器标识为不可用,不会再发送任何的请求给这台服务器

















 723
723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











