







 该文详细介绍了如何利用Hadoop生态中的Hive进行陌陌聊天数据的处理,包括数据清洗、需求指标统计,并通过FineBI实现数据可视化报表。主要步骤涉及建库建表、ETL过程以及各类统计分析,如消息量、用户数、Top10用户等,最后通过FineBI构建了数据分析报表。
该文详细介绍了如何利用Hadoop生态中的Hive进行陌陌聊天数据的处理,包括数据清洗、需求指标统计,并通过FineBI实现数据可视化报表。主要步骤涉及建库建表、ETL过程以及各类统计分析,如消息量、用户数、Top10用户等,最后通过FineBI构建了数据分析报表。
文章目录
四、Hadoop生态综合案例 ——陌陌聊天数据分析
1、陌陌聊天数据分析案例需求
1.1、背景介绍
背景介绍
陌陌作为聊天平台每天都会有大量的用户在线,会出现大量的聊天数据,通过对 聊天数据的统计分析 ,可以更好的对用户构建 精准的用户画像 ,为用户提供更好的服务以及实现 高ROI的平台运营推广 ,给公司的发展决策提供精确的数据支撑。
1.2、目标需求
目标
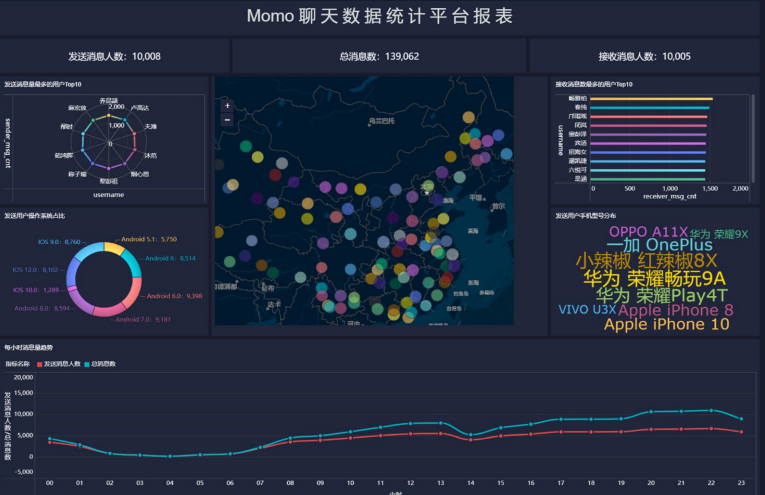
基于Hadoop和Hive实现聊天数据统计分析,构建聊天数据分析报表
需求
-
统计今日总消息量
-
统计今日每小时消息量、发送和接收用户数
-
统计今日各地区发送消息数据量
-
统计今日发送消息和接收消息的用户数
-
统计今日发送消息最多的To p 1 0用户
-
统计今日接收消息最多的To p 1 0用户
-
统计发送人的手机型号分布情况
-
统计发送人的设备操作系统分布情况
1.3、数据内容
-
数据大小:两个文件共14万条数据
-
列分隔符:制表符 \t
-
数据字典及样例数据

2、基于Hive数仓实现需求开发
2.1、建库建表、加载数据
建库建表
--------------1、建库-------------------
--如果数据库已存在就删除
drop database if exists db_msg cascade;
--创建数据库
create database db_msg;
--切换数据库
use db_msg;
--------------2、建表-------------------
--如果表已存在就删除
drop table if exists db_msg.tb_msg_source;
--建表
create table db_msg.tb_msg_source(
msg_time string comment "消息发送时间"
, sender_name string comment "发送人昵称"
, sender_account string comment "发送人账号"
, sender_sex string comment "发送人性别"
, sender_ip string comment "发送人ip地址"
, sender_os string comment "发送人操作系统"
, sender_phonetype string comment "发送人手机型号"
, sender_network string comment "发送人网络类型"
, sender_gps string comment "发送人的GPS定位"
, receiver_name string comment "接收人昵称"
, receiver_ip string comment "接收人IP"
, receiver_account string comment "接收人账号"
, receiver_os string comment "接收人操作系统"
, receiver_phonetype string comment "接收人手机型号"
, receiver_network string comment "接收人网络类型"
, receiver_gps string comment "接收人的GPS定位"
, receiver_sex string comment "接收人性别"
, msg_type string comment "消息类型"
, distance string comment "双方距离"
, message string comment "消息内容"
)
--指定分隔符为制表符
row for 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











