







目录
第二关—主要算法之K-Means 聚类
任务描述
本关任务:使用python语言编程,按要求完成任务。
相关知识
随着聚类分析技术的蓬勃发展,目前已有很多类型的聚类算法。但很难对聚类方法进行简单的分类,因为这些类别的聚类可能重叠,从而使得一种方法具有一些交叉的特征。一般而言,聚类算法被划分为以下几类:基于划分的方法;基于层次的方法;基于密度的方法;局域网格的方法。聚类分析中最广泛使用的算法为 K-Means 聚类算法。这里对 K-Means 聚类算法及其改进算法进行介绍。
K-Means聚类
-
原理
K-Means 算法的基本思想是初始随机给定 K 个聚类中心,按照最邻近原则把待分类样本点分到各个类。然后按平均法重新计算各个类的聚类中心,从而确定新的聚类中心。一直迭代,直到聚类中心保持不变或移动距离小于某个给定的值。
-
步骤
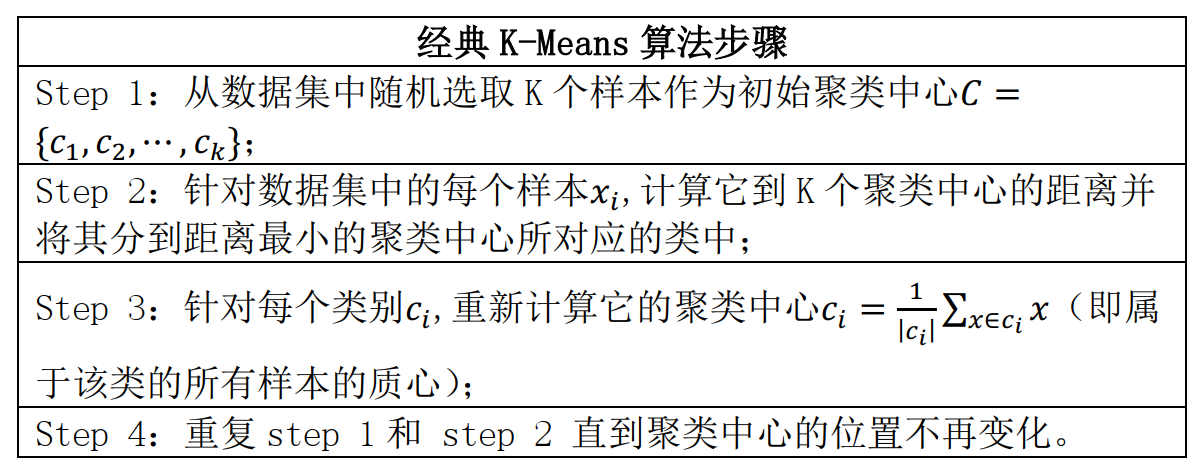
用于划分的 K-Means 算法,其中每个簇的中心都用簇中所有对象的均值来表示。K-Means 聚类模型所采用的迭代算法直观易懂且非常实用。但是具有容易收敛到局部最优解和需要预先设定簇的数量的缺陷。
-
K-means++算法
-
原理
将经典 K-Means 算法的 step 1 初始化类中心更改为: a)使用随机方法选取第一个(n=1)聚类中心; b) 选取第 n+1 个聚类中心(0<n<K)时:距离当前 n 个聚类中心越远的点会有更高的概率被选为第 n+1 个聚类中心。
-
buzh

编程要求
根据提示,在右侧编辑器Begin-End部分补充代码。
任务描述:使用Python语言,对给定数据进行聚类,数据可视化如下:
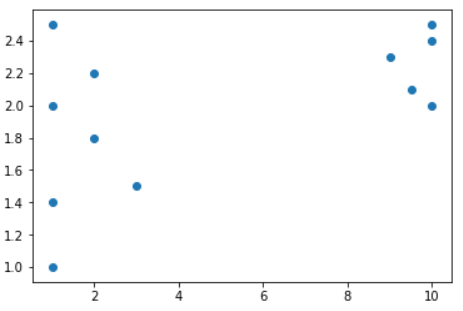
- 创建 KMeans 对象,令 n_clusters=2;提示:可以使用 sklearn.cluster 中的 KMeans 模型。
- 调用 fit 函数执行训练过程。
- 调用 predict 函数进行预测,预测的数据为 [0,0], [8,2], [10,3]。
# 从 sklearn.cluster 导入 KMeans from sklearn.cluster import KMeans import numpy as np # 加载数据集 X = np.array([[1, 2], [2, 2.2], [3, 1.5], [2, 1.8], [1, 1.4], [1, 2.5], [1, 1], [10, 2], [10, 2.5], [9, 2.3], [10, 2.4], [9.5, 2.1]]) # 任务1:创建 KMeans 对象,令 n_clusters=2 ########## Begin ########## kmeans = KMeans(n_clusters=2, random_state=0) ########## End ########## # 任务2:调用 fit 函数执行训练过程 ########## Begin ########## kmeans = kmeans.fit(X) ########## End ########## # 任务3:调用 predict 函数进行预测,预测的数据为 [0,0], [8,2], [10,3] ########## Begin ########## y_pred = kmeans.predict([[0,0], [8,2], [10,3]]) ########## End ########## # 打印结果 print(y_pred)
















 731
731











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











