







 文章讲述了如何利用Python的sklearn库中的PCA进行数据降维,并结合DecisionTreeClassifier对乳腺癌数据集进行分类。通过PCA将特征降至11维,然后用决策树模型进行训练和预测。
文章讲述了如何利用Python的sklearn库中的PCA进行数据降维,并结合DecisionTreeClassifier对乳腺癌数据集进行分类。通过PCA将特征降至11维,然后用决策树模型进行训练和预测。
目录
第三关 — sklearn 中的 PCA
任务描述
本关任务:你需要调用 sklearn 中的 PCA 接口来对数据继续进行降维,并使用 sklearn 中提供的分类器接口(可任意挑选分类器)对癌细胞数据进行分类。
相关知识
为了完成本关任务,你需要掌握 sklearn 中的 PCA 类。
数据介绍
乳腺癌数据集,其实例数量是 569,实例中包括诊断类和属性,帮助预测的属性一共 30 个,各属性包括 radius 半径(从中心到边缘上点的距离的平均值), texture 纹理(灰度值的标准偏差)等等,类包括:WDBC-Malignant 恶性和 WDBC-Benign 良性。用数据集的 80% 作为训练集,数据集的 20% 作为测试集,训练集和测试集中都包括特征和诊断类。
sklearn 中已经提供了乳腺癌数据集的相关接口,想要使用该数据集可以使用如下代码:
from sklearn import datasets#加载乳腺癌数据集cancer = datasets.load_breast_cancer()#X表示特征,y表示标签X = cancer.datay = cancer.target- 数据集中部分数据与标签如下图所示(其中 0 表示良性,1 表示恶性):数据集中部分数据与标签如下图所示(其中 0 表示良性,1 表示恶性):
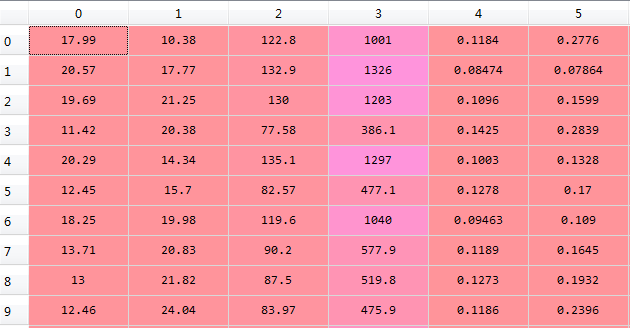
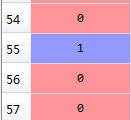
数据集中部分数据与标签如下图所示(其中 0 表示良性,1 表示恶性):
PCA
PCA 的构造函数中有一个常用的参数可以设置:
-
n_components :表示想要将数据降维至 n_components 个维度。
PCA 类中有三个常用的函数分别为: fit 函数用于训练 PCA 模型; transform 函数用于将数据转换成降维后的数据,当模型训练好后,对于新输入的数据,也可以用 transform 方法来降维;fit_transform 函数用于使用数据训练 PCA 模型,同时返回降维后的数据。
其中 fit 函数中的参数:
-
X :大小为[样本数量,特征数量]的 ndarray ,存放训练样本。
transform 函数中的参数:
-
X :大小为[样本数量,特征数量]的 ndarray ,存放训练样本。
fit_transform 函数中的参数:
-
X :大小为[样本数量,特征数量]的 ndarray ,存放训练样本。
PCA 的使用代码如下:
from sklearn.decomposition import PCA#构造一个将维度降至11维的PCA对象pca = PCA(n_components=11)#对数据X进行降维,并将降维后的数据保存至newXnewX = pca.fit_transform(X)
编程要求
在 begin-end 之间填写cancer_predict(train_sample, train_label, test_sample)函数实现降维并对癌细胞进行分类的功能,其中:
- train_sample :训练样本,类型为 ndarray;
- train_label :训练标签,类型为 ndarray;
- test_sample :测试样本,类型为 ndarray。
代码
from sklearn.decomposition import PCA
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
def cancer_predict(train_sample, train_label, test_sample):
'''
使用PCA降维,并进行分类,最后将分类结果返回
:param train_sample:训练样本, 类型为ndarray
:param train_label:训练标签, 类型为ndarray
:param test_sample:测试样本, 类型为ndarray
:return: 分类结果
'''
#********* Begin *********#
pca = PCA(n_components=11)
#对数据进行降维
train_sample = pca.fit_transform(train_sample)
test_sample = pca.transform(test_sample)
clf = DecisionTreeClassifier(max_depth=10)
clf.fit(train_sample, train_label)
result = clf.predict(test_sample)
return result
#********* End *********#



















 941
941

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











